【前沿 AI 技术】DeepSeek-OCR:让文字识别快到飞起,还能看懂上下文!
【前沿AI技术】DeepSeek-OCR:高效视觉文本理解新突破 DeepSeek-OCR通过创新的DeepEncoder视觉压缩技术和轻量级解码器,实现了高精度文字识别与上下文理解。其核心优势包括: 超高压缩比(10×达97%准确率) 生产效率高(单A100日处理20万页) 低token高性能(100token超越主流方案) 已开源DeepSeekOCRApp,支持文字提取、智能描述等场景,适用
·
🚀【前沿 AI 技术】DeepSeek-OCR:让文字识别快到飞起,还能看懂上下文!
🧐 引子
在 AI 技术日新月异的 2025 年,一个新的 OCR 模型闪亮登场——DeepSeek-OCR。
它不仅识字快,更重要的是:它能压缩海量视觉上下文,让 AI 模型“看得更远、理解更深”。
今天,我们就一起揭秘它的技术亮点、应用场景以及如何快速上手体验!
🔍 一、DeepSeek-OCR 到底有什么不一样?
📌 核心黑科技:
- DeepEncoder:高分辨率视觉输入压缩器
- DeepSeek3B-MoE-A570M:轻量级但强大的解码器
🎯 性能数据很惊人:
- 压缩比低于 10×:识别准确率高达 97%
- 压缩比 20×:依然能保持约 60% 的准确率
- 生产效率:单块 A100-40G GPU 每天可生成 20 万页数据
💡 意味着什么? OCR 不再只是“识字”,而是能在极小视觉 token 下保留海量信息——对于训练大语言模型、视觉语言模型来说,这就是“上下文加速器”!
📈 二、表现超群的实测数据
在 OmniDocBench 测试中:
- 仅 100 个视觉 token → 超越 GOT-OCR2.0
- 800 个视觉 token → 直接超过 MinerU2.0(后者每页 6000+ token)
💻 三、想用?DeepSeek OCR App 一键上手!
官方还贴心做了一个 开源应用:
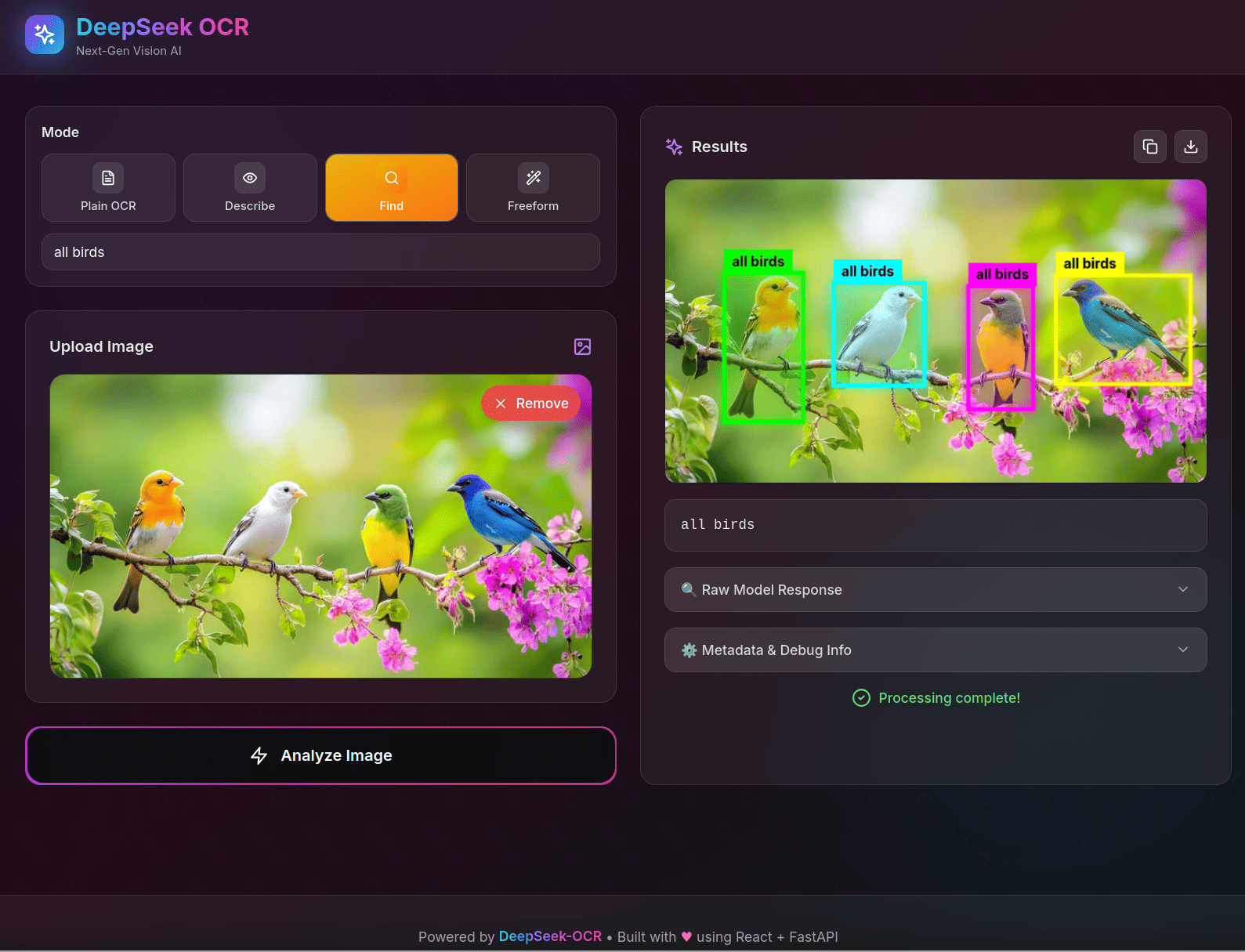
🚀 亮点功能:
- Plain OCR:纯文字提取
- Describe:智能图像描述
- Find:搜索并高亮特定文字
- Freeform:自定义提示词,超灵活
⚙️ 部署一行命令搞定:
git clone https://github.com/rdumasia303/deepseek_ocr_app.git
cd deepseek_ocr_app
docker compose up --build🛠 四、能用在哪?
| 场景 | 价值 |
|---|---|
| 📄 企业文档数字化 | 低成本快速转成电子文本 |
| 🧾 财务票据处理 | 批量识别,秒级提取关键信息 |
| 📰 媒体监测 | 从海量图文中提炼信息 |
| ♿ 辅助功能 | 视觉弱势群体的文字朗读支持 |
| 📚 教育 | 扫描教材并生成智能摘要 |
🔭 五、未来可能的升级方向
官方透露,未来可能增加:
- 🚀 视觉-语言大模型联合训练接口
- 🚀 更轻量化的多模态架构
- 📡 实时流式文档识别与摘要生成
✨ 总结
写在最后:
DeepSeek-OCR 的意义,不是替代现有 OCR,而是让 OCR 从“识别字符”进化到“理解内容”。
它的压缩技术让视觉信息不再笨重,让 AI 更高效地看懂世界 —— 对 AI 开发者、文档处理行业来说,这是一次真正的降维打击。
🔗 资源合集

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)