什么是协程?如何用c实现协程?
开始定义协程,用于网络io框架处理每一个协程需要有以下的成员变量,当然实际实现代码中可能还有其它变量用于存储协程诞生时间、协程名等等。int fd;// 网络io肯定需要fd// 保存协程的上下文// 协程回调函数void* arg;//回调函数参数;int status;//协程状态其中用于组织每个协程的有三个数据结构,分别是一个队列来存储状态为READY的协程,两个红黑树用来存储WAIT和SL
为什么需要协程
在很多地方都可以看到协程有“同步的编程方式,异步的性能”。为什么这么说?
协程解决了线程数量确定的情况下,请求非常多,但是同步请求会阻塞,导致性能地下的问题。那为什么不用异步呢?
在Node.js中,想要HTTP 请求链式发送的时候(先GET HTML、再GET HTML中的js、css、png等等),会有这样的异步写法:
const net = require("net");
// 创建 TCP 服务器
const server = net.createServer((socket) => {
console.log("客户端连接");
// 先发第一个包
socket.write("包1", () => {
console.log("包1发送完成");
// 包1发完再发包2
socket.write("包2", () => {
console.log("包2发送完成");
// 包2发完再发包3
socket.write("包3", () => {
console.log("包3发送完成");
socket.end();
});
});
});
});
server.listen(3000, () => console.log("服务器启动,监听3000端口"));
当write将包1成功写入内核TCP control block中的send buffer时,就会调用回调函数,以此类推,虽然这样将io耗时的问题解决了,但是这样写代码,当包的数据处理代码多的时候,逻辑就会非常混乱。故现代的Node.js(Promise 版本)会这样写:
function sendAsync(socket, data) {
return new Promise((resolve) => {
socket.write(data, resolve);
});
}
const server = net.createServer(async (socket) => {
console.log("客户端连接");
await sendAsync(socket, "包1");
console.log("包1发送完成");
await sendAsync(socket, "包2");
console.log("包2发送完成");
await sendAsync(socket, "包3");
console.log("包3发送完成");
socket.end();
});
server.listen(3000, () => console.log("服务器启动"));
这看起来似乎是同步写法,但是当执行await sendAsync(socket, "包1");的时候, net.createServer函数会被挂起,然后线程会去执行别的函数。
Node.js 的 async/await 语义,本质上就是**协程(coroutine)**思想在 JavaScript 世界的体现。
许多互联网产品中,都有多个请求存在的功能。思考:如何用协程实现这些功能?
- 当访问微信朋友圈时,假设朋友圈内容和图片存储在同一个服务器中(假设为192.168.6.6:9527),可能会向192.168.6.6:9527建立一个tcp连接,发送一个朋友圈内容的请求,然后根据内容中图片的id,在同一个连接上发送多个图片请求。
- csdn某篇博文界面,里面的图片资源可能存储在不同的图床中,那么,对于不同源的图片(假设所有图片存储在3个不同的图床上),以及csdn服务器上的博文(可能是json),浏览器会建立4个tcp连接,对这些资源发送请求。
- 在csdn主页界面,也有好多好多个接口,那么对于不同的接口,就需要建立不同的tcp连接进行请求。在边栏中,边栏内容请求和icon的请求可能需要链式发送请求。
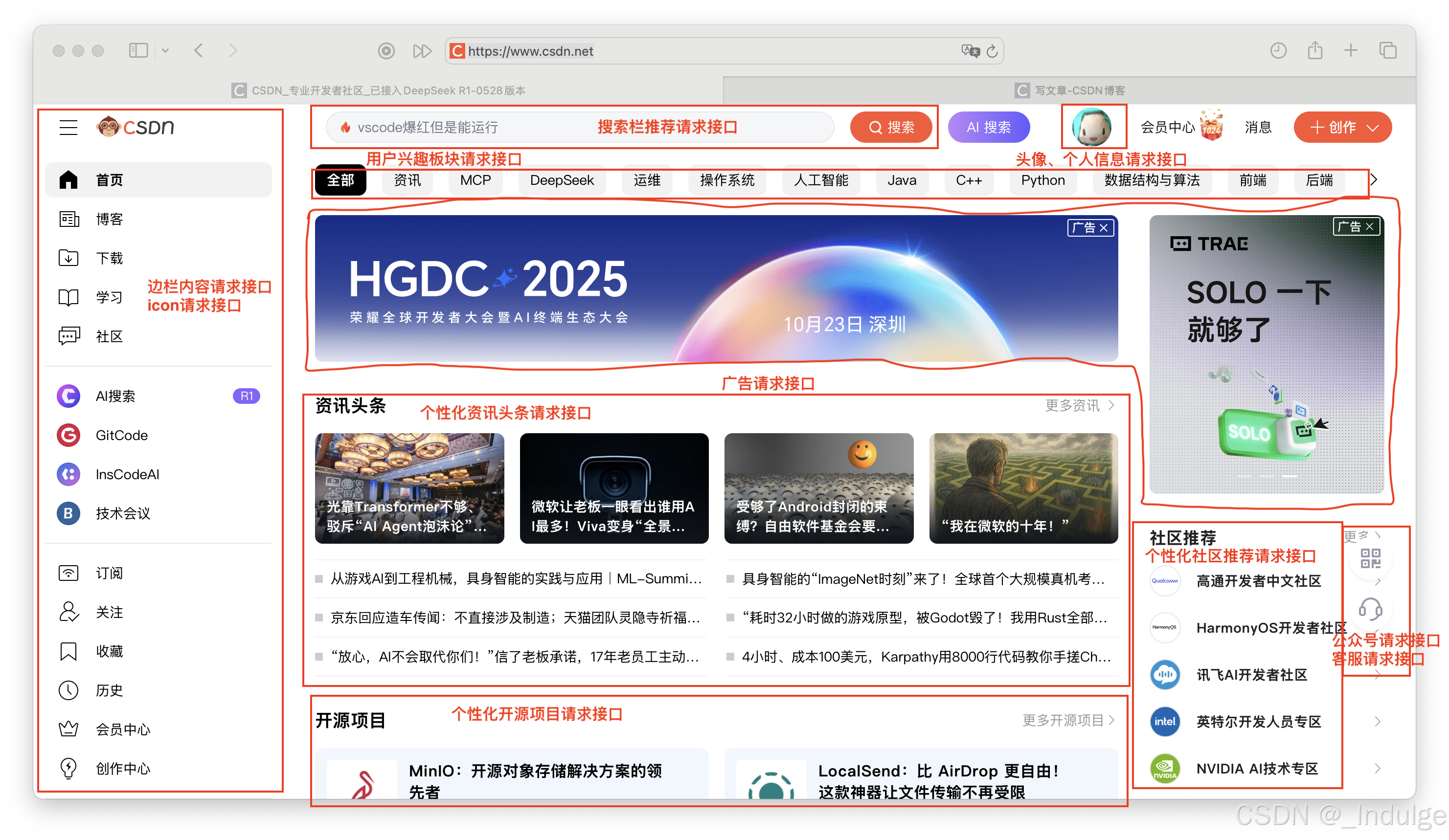
接下来,会讨论如何用c语言实现协程。
协程使用过程
假设我们现在的场景是上面的CSDN主页资源请求,虽然是浏览器,但是底层肯定也是send和recv来收发数据的。假设我们现在要同时请求广告数据、侧边栏数据和个性化头条内容。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int request(char** recv_buf, int fd, const char* send_buf) {
printf(" [FD %d] -> Sending data: \"%s\"\n", fd, send_buf);
// 1. 发送请求
// 在真实的网络编程中,send() 会将数据写入操作系统的发送缓冲区。
// 这个调用通常会很快返回,但是缓冲区满时也会阻塞
send(fd, send_buf, strlen(send_buf), 0);
printf(" [FD %d] <- Waiting for response (execution is blocked)...\n", fd);
// 2. 接收响应 - 这是关键的阻塞点
// recv() 会使程序暂停执行,直到网络连接上有数据到达。
// 在这期间,CPU 无法执行其他任务(在该线程上)。
recv(fd, temp_buffer, BUFFER_SIZE, 0);
strcpy(*recv_buf, temp_buffer);
printf(" [FD %d] <- Response received.\n", fd);
return 0;
}
// 模拟的三个不同网络连接的文件描述符
#define FD_ADS 3
#define FD_SIDEBAR 4
#define FD_HEADLINE 5
// 同步获取广告数据
char* fetch_ads_sync() {
printf("--> Starting 'fetch_ads_sync'...\n");
char* response = NULL;
// 整个程序会在此函数调用中被阻塞,直到广告数据返回
request(&response, FD_ADS, "GET /ads");
printf("<-- Finished 'fetch_ads_sync'.\n");
return response;
}
// 同步获取侧边栏内容
char* fetch_sidebar_sync() {
printf("--> Starting 'fetch_sidebar_sync'...\n");
char* response = NULL;
// 只有在 fetch_ads_sync 完成后,这个函数才能开始执行
// 程序会再次在这里被阻塞
request(&response, FD_SIDEBAR, "GET /sidebar");
printf("<-- Finished 'fetch_sidebar_sync'.\n");
return response;
}
// 同步获取个性化头条
char* fetch_personal_headlines_sync() {
printf("--> Starting 'fetch_personal_headlines_sync'...\n");
char* response = NULL;
// 这是第三个阻塞点,必须等待前两个请求全部完成
request(&response, FD_HEADLINE, "GET /headlines");
printf("<-- Finished 'fetch_personal_headlines_sync'.\n");
return response;
}
int main() {
printf("Start fetching data synchronously...\n\n");
// 在真实场景中,程序会先建立三个网络连接,获得 fd=3, 4, 5
// 1. 获取广告数据。程序在这里等待,直到广告数据返回。
char *ads = fetch_ads_sync();
if (ads) {
printf(" Data received: \"%s\"\n\n", ads);
free(ads);
}
// 2. 获取侧边栏内容。只有在获取广告后,才开始这一步。程序再次等待。
char *sidebar = fetch_sidebar_sync();
if (sidebar) {
printf(" Data received: \"%s\"\n\n", sidebar);
free(sidebar);
}
// 3. 获取个性化头条。最后一步,同样需要等待。
char *headlines = fetch_personal_headlines_sync();
if (headlines) {
printf(" Data received: \"%s\"\n\n", headlines);
free(headlines);
}
close(FD_ADS); close(FD_SIDEBAR); close(FD_HEADLINE);
return 0;
}
在同步模型中,程序的执行流程是串行的,总耗时是所有网络请求耗时的总和,效率低下。
虽然异步回调可以解决阻塞问题,但容易产生“回调地狱”,代码难以维护。
协程则提供了一种优雅的解决方案。 我们可以编写看似同步的代码,但在遇到 I/O 操作时,通过 yield 让出 CPU 控制权,而不是阻塞等待。当 I/O 操作完成后,调度器会通过 resume 恢复该协程的执行。
为了理解这个过程,我们需要一个核心组件:协程调度器 (Scheduler)。它的职责是:
- 启动和管理多个协程。
- 当一个协程因为等待 I/O 而
yield时,接管控制权。 - 监控 I/O 事件(例如,通过
poll或epoll)。 - 当等待的 I/O 事件就绪时,
resume对应的协程。
下面是这个模型的伪代码:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
void check_event(int fd, int event) {
struct epoll_event ev;
ev.events = event
ev.data.fd = fd;
epoll_ctl(sched->poller_fd, EPOLL_CTL_ADD, fd, &ev);
// 重点!!!! 此时切换到协程调度器,然后等待协程调度器使用epoll_wait知道fd的事件被激活时,再唤醒改协程
yield(); // 保存该协程上下文,并加载调度器上下文
epoll_ctl(sched->poller_fd, EPOLL_CTL_DEL, fd, &ev); // 在epoll中删除fd
return ;
}
int request(char** recv_buf, int fd, const char* send_buf) {
printf(" [FD %d] -> Sending data: \"%s\"\n", fd, send_buf);
// 在send之前,要使用epoll来判断是否可写
check_event(fd, EPOLLOUT);
send(fd, send_buf, strlen(send_buf), 0);
printf(" [FD %d] <- Waiting for response (execution is blocked)...\n", fd);
// 2. 接收响应 - 这是关键的阻塞点
// 在recv之前判断是否可读
check_event(fd, EPOLLIN);
recv(fd, temp_buffer, BUFFER_SIZE, 0);
strcpy(*recv_buf, temp_buffer);
printf(" [FD %d] <- Response received.\n", fd);
return 0;
}
// 模拟的三个不同网络连接的文件描述符
#define FD_ADS 3
#define FD_SIDEBAR 4
#define FD_HEADLINE 5
// 看似同步的获取广告数据,现在有异步的性能
char* fetch_ads_sync() {
printf("--> Starting 'fetch_ads_sync'...\n");
char* response = NULL;
// 整个程序会在此函数调用中被阻塞,直到广告数据返回
request(&response, FD_ADS, "GET /ads");
printf("<-- Finished 'fetch_ads_sync'.\n");
return response;
}
// 获取侧边栏内容
char* fetch_sidebar_sync() {
printf("--> Starting 'fetch_sidebar_sync'...\n");
char* response = NULL;
// 只有在 fetch_ads_sync 完成后,这个函数才能开始执行
// 程序会再次在这里被阻塞
request(&response, FD_SIDEBAR, "GET /sidebar");
printf("<-- Finished 'fetch_sidebar_sync'.\n");
return response;
}
// 获取个性化头条
char* fetch_personal_headlines_sync() {
printf("--> Starting 'fetch_personal_headlines_sync'...\n");
char* response = NULL;
// 这是第三个阻塞点,必须等待前两个请求全部完成
request(&response, FD_HEADLINE, "GET /headlines");
printf("<-- Finished 'fetch_personal_headlines_sync'.\n");
return response;
}
int main() {
coroutine_create(FD_ADS, fetch_ads_sync);
coroutine_create(FD_SIDEBAR, fetch_sidebar_sync);
coroutine_create(FD_HEADLINE, fetch_personal_headlines_sync);
while(1) {
int nready = epoll_wait(&events);
while(nready -- ) {
int fd = events[nready].data.fd;
// 在协程调度器里会有一个红黑树,来关联fd和协程结构体
coroutine* co = RB_FIND(fd)
resume(co)
}
}
close(FD_ADS); close(FD_SIDEBAR); close(FD_HEADLINE);
return 0;
}
此时,CPU上下文的切换点,就在调度器和函数check_event中!!!到此,我们就明白了协程是如何使用的
协程如何定义
开始定义协程,用于网络io框架处理
每一个协程需要有以下的成员变量,当然实际实现代码中可能还有其它变量用于存储协程诞生时间、协程名等等。
struct coroutine {
int fd; // 网络io肯定需要fd
ucontext_t ctx; // 保存协程的上下文
coroutine_proc func; // 协程回调函数
void* arg; //回调函数参数;
int status; //协程状态
queue_node(coroutine) ready_node;
rbtree_node(coroutine) wait_rb_node;
rbtree_node(coroutine) sleep_rb_node;
};
其中用于组织每个协程的有三个数据结构,分别是一个队列来存储状态为READY的协程,两个红黑树用来存储WAIT和SLEEP状态的协程。
如何进行上下文切换
三种方法
- #include <ucontext.h>
- #include <setjmp.h>
- 内联汇编
调度器如何定义
协程调度器最少要有以下的成员
struct scheduler {
int epoll_fd; // 用于监测协程事件
ucontext_t ctx; // 调度器的上下文
queue ready_queue; // 就绪协程队列头
rbtree wait_rb; // 等待协程红黑树根节点
rbtree sleep_rb; // 睡眠协程红黑树根节点
int birth; //调度器初始化的时间戳,用于作为sleep定时器的基准时间
}
调度器的执行策略
其实在协程使用的使用方法小结中,main函数中的while(1)循环就是一个协程的调度器的执行。再复杂一点的调度器会是这样的:
// 协程状态
enum CoState { READY, RUNNING, SLEEPING, WAITING_IO, FINISHED };
// 协程控制块
struct Coroutine {
CoState state;
void* stack;
// ... 其他上下文信息
};
// 调度器
struct Scheduler {
list<Coroutine*> ready_queue; // 就绪队列
min_heap<pair<time_t, Coroutine*>> sleeping_coroutines; // 睡眠队列 (按唤醒时间排序)
int epoll_fd; // epoll 文件描述符
map<int, Coroutine*> io_wait_map; // 等待IO的协程 (fd -> Coroutine)
};
void scheduler_run(Scheduler* s) {
while (s->has_coroutines()) {
// 步骤 1: 唤醒睡眠的协程
while (!s->sleeping_coroutines.empty()) {
auto& co_sleep_info = s->sleeping_coroutines.top();
if (now() >= co_sleep_info.first) {
// 时间到了,移入就绪队列
co_sleep_info.second->state = READY;
s->ready_queue.push_back(co_sleep_info.second);
s->sleeping_coroutines.pop();
} else {
// 最早的都没到期,其他的更不用看了
break;
}
}
// 步骤 2: 执行就绪的协程
if (!s->ready_queue.empty()) {
Coroutine* co = s->ready_queue.front();
s->ready_queue.pop_front();
co->state = RUNNING;
resume(co); // 切换到协程执行
// ... 从协程返回后,根据其状态进行处理 ...
}
// 步骤 3: 检查I/O事件
// 设置一个短暂的超时时间,避免在没有就绪任务时CPU空转
int timeout = calculate_next_sleep_time();
int n_events = epoll_wait(s->epoll_fd, events, MAX_EVENTS, timeout);
for (int i = 0; i < n_events; ++i) {
int fd = events[i].data.fd;
Coroutine* co = s->io_wait_map[fd];
// 从等待map中移除,并加入就绪队列
s->io_wait_map.erase(fd);
co->state = READY;
s->ready_queue.push_back(co);
}
}
}
调度器使得程序可以在单线程内实现高并发,避免了线程切换的昂贵开销,并允许开发者用看似同步的简单代码写出高性能的异步程序
协程的api如何和posix api做到一致
用hook来实现,hook 原理是,在程序启动的运行时加载阶段,动态加载器会根据环境变量的指示,最优先加载我们指定的动态库。当它解析函数符号(如 malloc)时,会按照库的加载顺序进行查找。由于我们的库排在最前面,加载器会首先找到我们自己实现的 malloc 函数并使用它,而不会再去查找系统中原始的 libc 库,从而实现了对原函数的‘劫持’或‘替换’。
协程的多核模式
每个线程都有一个自己的协程调度器,各个调度器独立运行。然后去做cpu的亲缘性。
协程的使用场景
协程是一个网络框架
可以用在 webserver,kv存储等中间件上
然后webserver和kv存储这些中间件,在生产环境中,可以用在图床等实际可以上线的项目上。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)