Native Sparse Attention: Hardware-Aligned and Nativel Trainable Sparse Attention
deepseek团队论文 ACL'25
·
deepseek团队 ACL'25 best paper
Abstract
长上下文建模[Long-context modeling]对下一代语言模型至关重要,但标准注意力机制[standard attention mechanisms]的高计算成本带来了显著的计算挑战。稀疏注意力[Sparse attention]为提高效率同时保持模型能力提供了有前景的方向。
我们提出NSA(原生可训练稀疏注意力机制 a Natively trainable Sparse Attention mechanism),通过算法创新与硬件对齐优化的结合,实现高效的长上下文建模。NSA采用动态分层稀疏策略[a dynamic hierarchical sparse strategy],结合粗粒度token压缩[coarse-grained token compression]与细粒度token选择[fine-grained token selection],同时保留全局上下文感知[global context awareness]和局部精度[local precision]。
(1) 通过算术强度平衡的算法设计及现代硬件优化实现显著加速。
(2) 支持端到端训练,在降低预训练计算量的同时不牺牲模型性能。
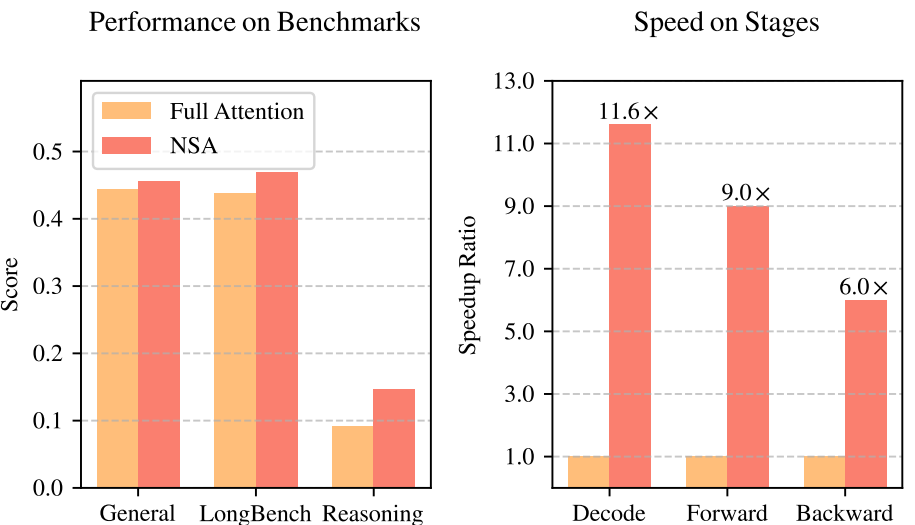
图1 | 全注意力模型与NSA模型的性能与效率对比 左图:尽管采用稀疏结构,NSA在通用基准测试、长上下文任务和推理评估中的平均表现超越全注意力基线模型。右图:在64k长度序列处理中,NSA相比全注意力模型在解码、前向传播和反向传播阶段均实现显著计算加速。
如图1所示,实验表明基于NSA预训练的模型在通用基准测试、长上下文任务和指令推理中均保持或超越全注意力模型[Full Attention models]性能。同时,NSA在64k长度序列的解码、前向传播和反向传播中均实现显著加速,验证了其在模型全生命周期的高效性。
1. Introduction
研究界日益认识到长上下文建模是下一代大语言模型的核心能力,其驱动力来自多样化现实应用场景,包括深度推理(DeepSeek-AI, 2025; Zelikman等, 2022)、仓库级代码生成(Zhang等, 2023a; Zhang等)以及多轮自主智能体系统(Park等, 2023)。最新技术突破(如OpenAI的o系列模型、DeepSeek-R1(DeepSeek-AI, 2025)和Gemini 1.5 Pro(Google等, 2024))已使模型能够处理完整代码库、长篇幅文档、维持数千token的多轮连贯对话,并执行跨长距离依赖的复杂推理。然而,随着序列长度增加,原始注意力机制[vanilla Attention](Vaswani等, 2017)的高计算复杂度(Zaheer等, 2020)成为关键延迟瓶颈。理论估算表明,在处理64k长度上下文时,基于softmax架构的注意力计算占解码总延迟的70-80%,这凸显了对高效注意力机制的迫切需求。
高效长上下文建模的自然途径是利用softmax注意力的固有稀疏性(Ge等, 2023; Jiang等, 2023),通过选择性计算关键查询-键值对[query-key pairs],可在保持性能的同时显著降低计算开销。近期研究通过多种策略展现了该潜力:KV缓存淘汰方法(Li等, 2024; Zhang等, 2023b; Zhou等, 2024)、分块KV缓存选择方法(Gao等, 2024; Tang等, 2024; Xiao等, 2024a),以及基于采样、聚类或哈希的选择方法(Chen等, 2024b; Desai等, 2024; Liu等, 2024)。
尽管这些策略前景广阔,现有稀疏注意力方法在实际部署中仍存在不足。许多方法无法实现与理论增益相匹配的加速效果,且大多数方法缺乏有效的训练时支持以充分利用注意力稀疏模式[the sparsity patterns of attention]。
为解决这些局限性,有效稀疏注意力的部署需攻克两大关键挑战:
(1) 硬件对齐的推理加速:将理论计算量减少转化为实际速度提升,需在预填充[prefilling]和解码阶段[decoding stages]采用硬件友好型算法设计,以缓解内存访问和硬件调度瓶颈;
(2) 训练感知的算法设计:通过可训练算子[operators]实现端到端计算,在降低训练成本的同时保持模型性能。
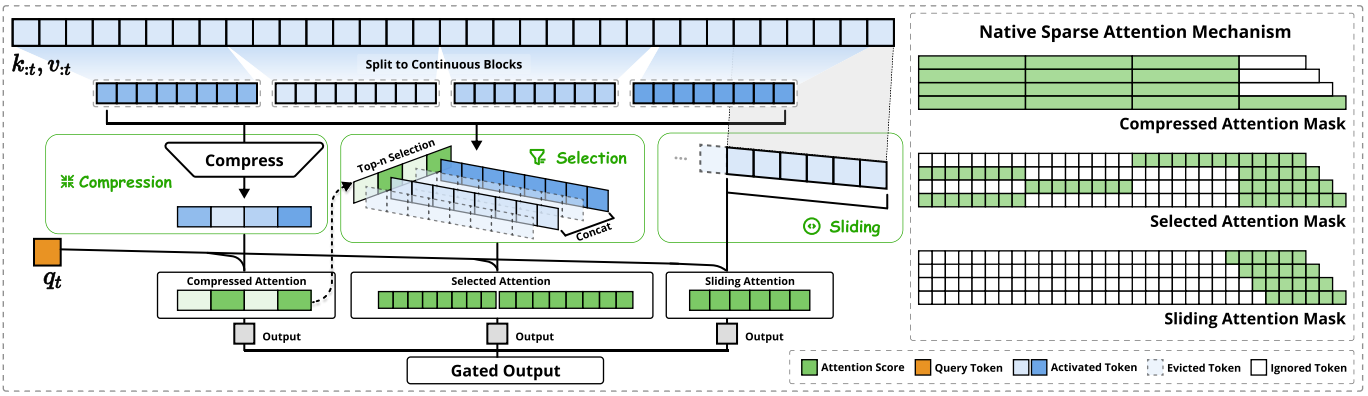
图2|NSA架构概览。左图:该框架通过三个并行注意力分支处理输入序列。针对特定查询,系统会将前序键值[preceding keys and values]转换为压缩注意力[compressed attention]用于粗粒度模式[coarse-grained patterns]识别,选择性注意力[selected attention]用于重要标记[important token blocks]分析,滑动注意力[sliding attention]则用于局部上下文[local context]检测。右图:各分支生成的不同注意力模式可视化示意图。绿色区域表示需计算注意力分数的区域,白色区域则为可跳过处理的区域。
如图2所示,NSA通过将键值[keys and values]组织为时序块[temporal blocks]并经三路注意力[three attention paths]处理来降低单查询计算量:
compressed coarse-grained tokens, selectively retained fine-grained tokens, and sliding windows for local contextual information.
压缩的粗粒度token、选择性保留的细粒度token,以及局部上下文的滑动窗口。
NSA提出两项核心创新:(1) 硬件对齐系统[Hardware-aligned system]:优化分块稀疏注意力[blockwise sparse attention]以利用Tensor Core和内存访问,确保算术强度平衡;(2) 训练感知设计[Training-aware design]:通过高效算法和反向算子实现稳定的端到端训练。
我们通过在真实语言语料库上的全面实验来评估NSA。基于270亿参数Transformer主干和2600亿token的预训练,我们在通用语言评估、长上下文评估和思维链推理评估中测试NSA性能。实验结果表明,NSA性能媲美或超越全注意力基线[full attention baseline],同时优于现有稀疏注意力方法。此外,相比全注意力,NSA在解码、前向和反向阶段[decoding, forward, and backward stages]均实现显著加速,且序列越长加速比越高。
2. Rethinking Sparse Attention Methods
现代稀疏注意力方法[sparse attention methods]在降低Transformer模型理论计算复杂度方面取得了显著进展。然而,现有方法主要在推理阶段应用稀疏性,同时保留预训练的全注意力主干网络[Full Attention backbone],这种设计可能引入架构偏差,从而限制其充分挖掘稀疏注意力优势的能力。在提出我们的原生稀疏架构前,我们通过两个关键视角系统分析这些局限性。
2.1. The Illusion of Efficient Inference
尽管实现了注意力计算的稀疏化,许多方法仍无法相应降低推理延迟,主要归因于两大挑战:
阶段受限的稀疏性[Phase-Restricted Sparsity.]:如H2O(Zhang等,2023b)等方法在自回归解码[autoregressive decoding]阶段应用稀疏化,却需在预填充[prefilling]阶段进行高计算强度的预处理[computationally intensive pre-processing](如注意力图计算、索引构建)。
相比之下,MInference(Jiang等,2024)等方法仅关注预填充阶段的稀疏化。这些方法无法实现全推理阶段的加速,因至少有一个阶段的计算成本仍与全注意力[Full Attention]相当。这种阶段专门化限制了方法在预填充主导型任务(如书籍摘要和代码补全)或解码主导型任务(如长链思维推理(Wei等,2022))中的加速能力。
与先进注意力架构的兼容性问题[Incompatibility with Advanced Attention Architecture.]。部分稀疏注意力方法无法适配现代高效解码架构,如多头查询注意力(Multiple-Query Attention, MQA)(Shazeer, 2019)和分组查询注意力(Grouped-Query Attention, GQA)(Ainslie等, 2023)。
这些架构通过在多查询头间共享键值(KV),显著缓解了解码阶段的内存访问瓶颈。例如在Quest等方法中(Tang等, 2024),每个注意力头独立选择其KV缓存子集[KV-cache subset]。在基于GQA的模型中,内存访问量取决于同组内所有查询头的选择结果并集。该架构特性导致虽然计算操作减少,但KV缓存的内存访问量仍居高不下。该限制引发关键矛盾:计算量减少与高效内存访问设计存在冲突。
这些局限性的产生,源于现有稀疏注意力方法大多聚焦于KV缓存缩减或理论计算量降低。难以在先进框架或后端系统中实现显著的延迟降低。这促使我们开发同时具备先进架构设计和硬件高效实现的算法。以充分挖掘稀疏性潜力来提升模型效率。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 19
19 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)