超详细Transformer模型图解介绍(结构、pytorch完整从零详细实现)
本文详细介绍了transformer结构图解介绍,以及提供了详细pytorch从0实现代码,提供给AI初学者详细学习
文章目录
Transformer模型
介绍
Transformer是一种基于自注意力机制的深度学习模型,最初由Vaswani等人在2017年的论文《Attention Is All You Need》中提出,用于自然语言处理任务。它摒弃了传统的循环神经网络(RNN)和卷积神经网络(CNN),完全依赖注意力机制来捕捉输入和输出之间的全局依赖关系。
论文地址:https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
翻译论文地址:https://yiyibooks.cn/arxiv/1706.03762v7/index.html
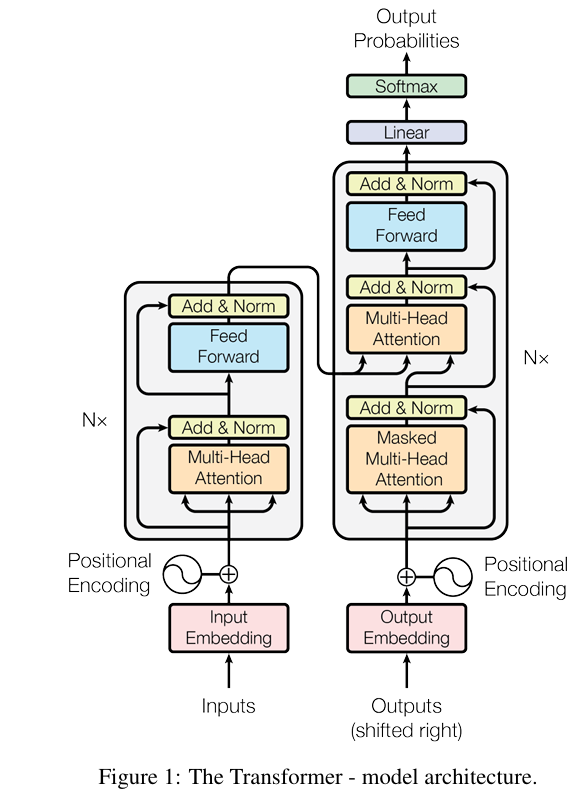
核心创新点:
- 并行计算:相比RNN的顺序处理,Transformer可以并行计算整个序列
- 长距离依赖:自注意力机制可以直接捕捉序列中任意两个位置的关系
- 位置编码:通过位置编码保留序列的顺序信息
结构
Transformer是一个基于自注意力机制的序列到序列模型,完全摒弃了循环和卷积结构。其核心思想是通过注意力机制直接建模序列中所有位置之间的关系。
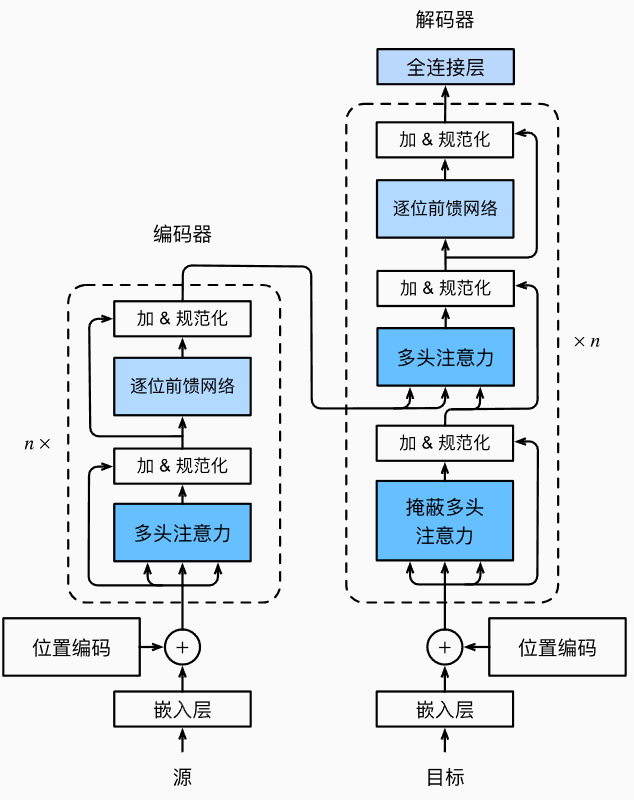
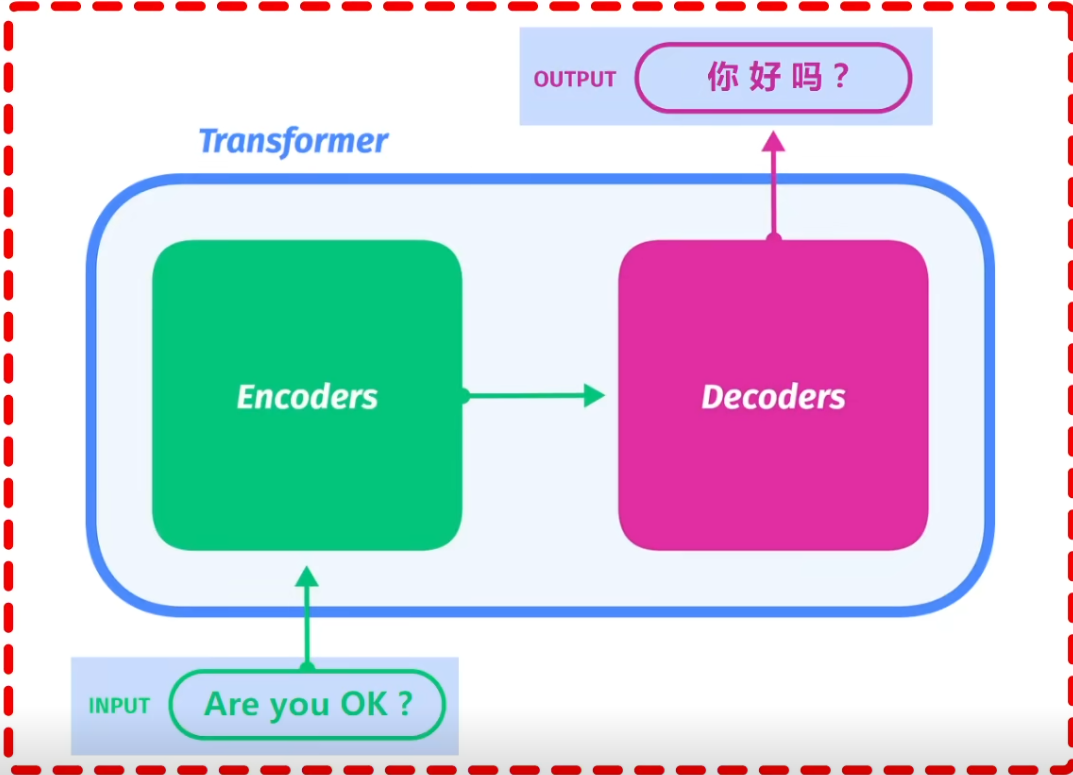
1. 编码器和解码器
1.1. 编码器 Encoder
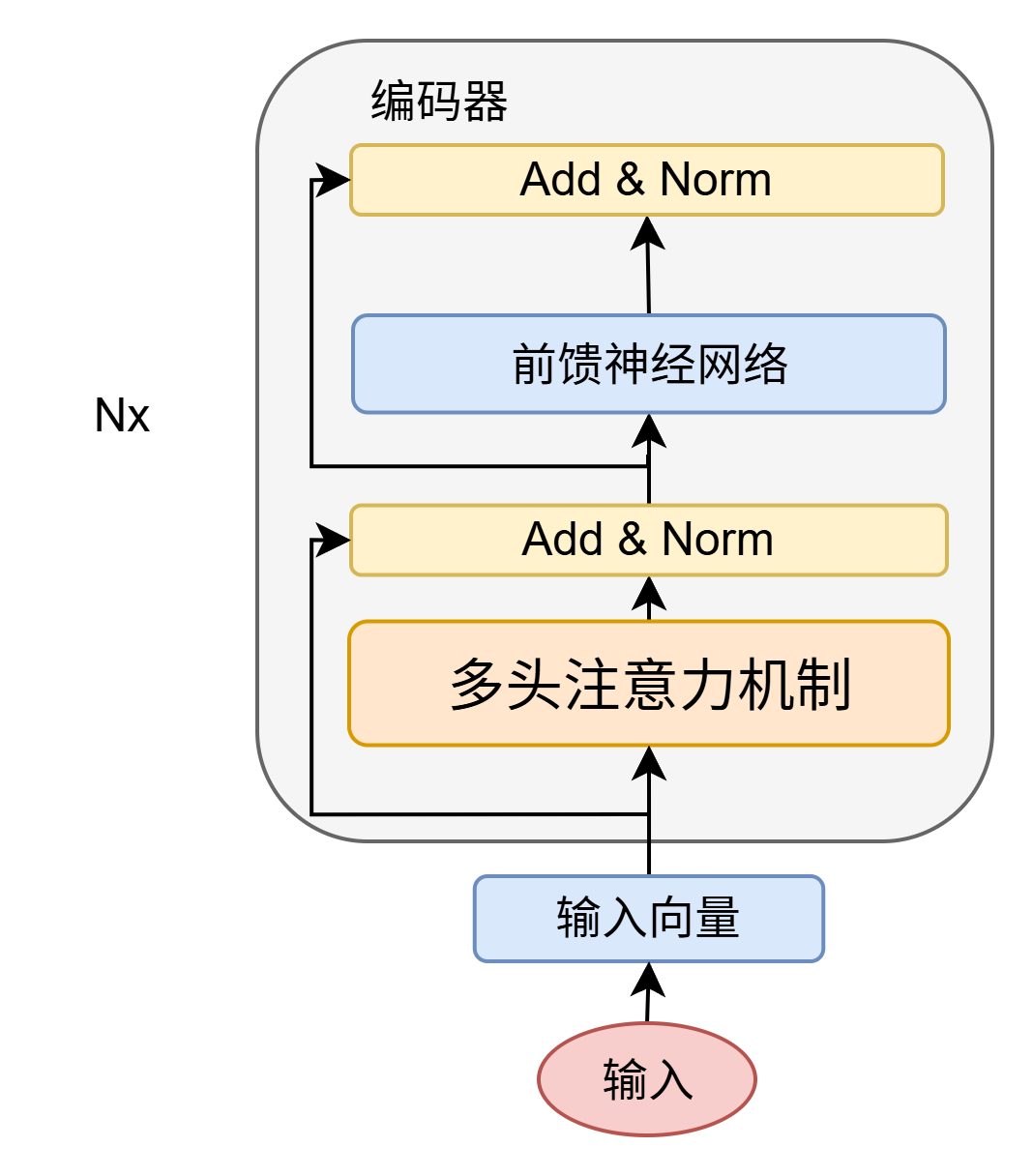
编码器由N = 6 个相同层堆叠而成,每层主要由两个部分组成
- 第一个是一个多头自注意力机制
- 第二个是一个简单的逐位置全连接前馈网络。
- 两个子层的每个子层周围使用一个残差连接,然后进行层归一化。
- 每个子层的输出是 L a y e r N o r m ( x + S u b l a y e r ( x ) ) LayerNorm(x+Sublayer(x)) LayerNorm(x+Sublayer(x)) ,其中 S u b l a y e r ( x ) Sublayer(x) Sublayer(x)是子层本身实现的函数。是子层本身实现的函数。
- 在每个子层之后,都会使用残差连接和层归一化操作,这些操作统称为Add&Norm为了方便这些残差连接,模型中的所有子层以及嵌入层都生成维度为 d m o d e l = 512 d_{model}=512 dmodel=512的输出。
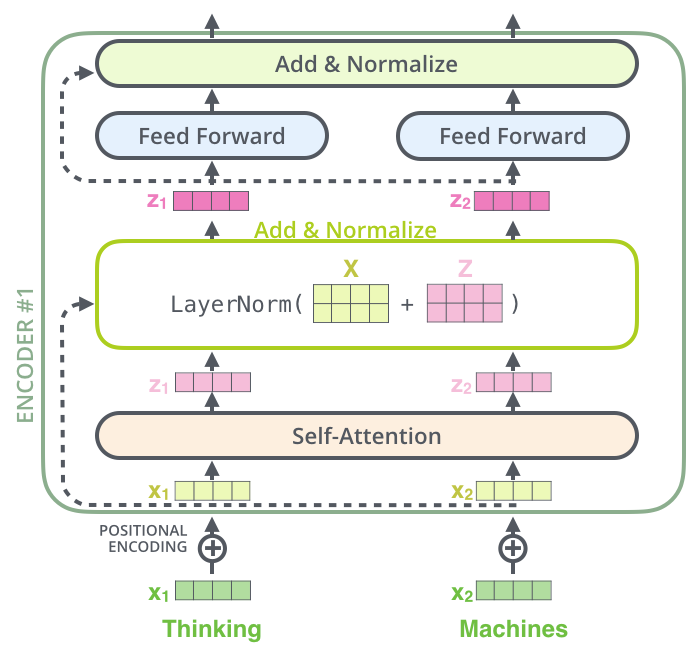
- 编码器层
"""编码器层模块"""
class EncoderLayer(nn.Module):
"""
编码器层
包含多头自注意力和前馈网络,以及残差连接和层归一化
"""
def __init__(self, d_model, num_heads, d_ff, dropout=0.1, **kwargs):
super(EncoderLayer, self).__init__(**kwargs)
# 多头自注意力机制
self.self_attention = MultiHeadAttention(d_model, num_heads, dropout)
# 前馈网络
self.feed_forward = PositionWiseFFN(d_model, d_ff, d_model)
# 层归一化
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
# 残差连接和dropout
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
def forward(self, x, mask=None):
"""
前向传播
参数:
x: [batch_size, seq_len, d_model] - 输入序列
mask: [batch_size, seq_len, seq_len] - 可选掩码
返回:
output: [batch_size, seq_len, d_model] - 编码后的输出
"""
# 多头自注意力 + 残差连接 + 层归一化
attn_output, _ = self.self_attention(x, x, x, mask)
x = self.norm1(x + self.dropout1(attn_output))
# 前馈网络 + 残差连接 + 层归一化
ff_output = self.feed_forward(x)
x = self.norm2(x + self.dropout2(ff_output))
return x
- 编码器模块
1.2. 解码器 Decoder
编码器与解码器的最大不同之处是,解码器使用了**掩码多头注意力机制,**目的是防止位置关注后续位置。
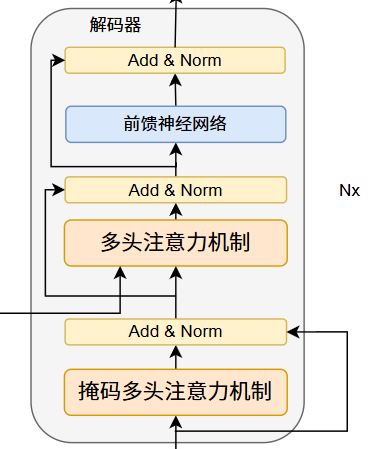
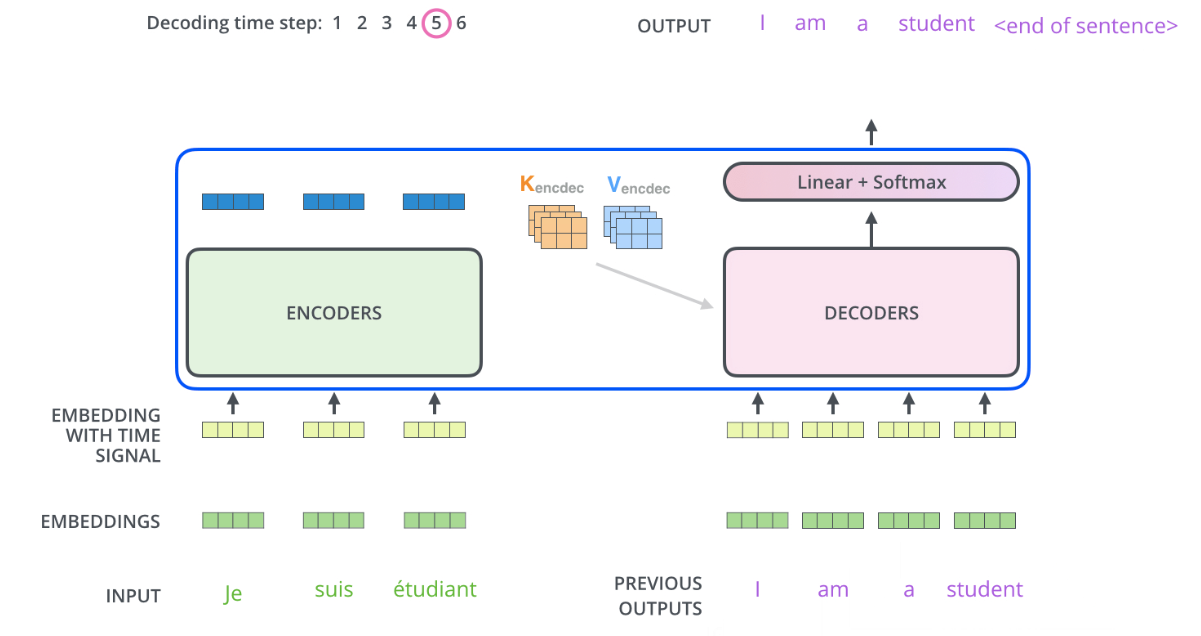
编码器首先处理输入序列。然后将顶部编码器的输出转换为一组注意力向量 K 和 V。每个解码器在其“编码器-解码器注意力”层中使用这些,以帮助解码器专注于输入序列中的适当位置
1.3. Pytorch实现✍️
1.3.1. 编码器层实现
"""编码器层模块"""
class EncoderLayer(nn.Module):
"""
编码器层
包含多头自注意力和前馈网络,以及残差连接和层归一化
"""
def __init__(self, d_model, num_heads, d_ff, dropout=0.1, **kwargs):
super(EncoderLayer, self).__init__(**kwargs)
# 多头自注意力机制
self.self_attention = MultiHeadAttention(d_model, num_heads, dropout)
# 前馈网络
self.feed_forward = PositionWiseFFN(d_model, d_ff, d_model)
# 层归一化
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
# 残差连接和dropout
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
def forward(self, x, mask=None):
"""
前向传播
参数:
x: [batch_size, seq_len, d_model] - 输入序列
mask: [batch_size, seq_len, seq_len] - 可选掩码
返回:
output: [batch_size, seq_len, d_model] - 编码后的输出
"""
# 多头自注意力 + 残差连接 + 层归一化
attn_output, _ = self.self_attention(x, x, x, mask)
x = self.norm1(x + self.dropout1(attn_output))
# 前馈网络 + 残差连接 + 层归一化
ff_output = self.feed_forward(x)
x = self.norm2(x + self.dropout2(ff_output))
return x
1.3.2. 编码器模块实现
class Encoder(nn.Module):
"""
编码器
由多个编码器层堆叠而成,包含位置编码和层归一化
"""
def __init__(self, vocab_size, d_model, num_heads, d_ff, num_layers,
max_len=5000, dropout=0.1, **kwargs):
super(Encoder, self).__init__(**kwargs)
self.d_model = d_model
# 词嵌入层
self.embedding = nn.Embedding(vocab_size, d_model)
# 位置编码
self.pos_encoding = PositionalEncoding(d_model, max_len, dropout)
# 编码器层堆叠
self.layers = nn.ModuleList([
EncoderLayer(d_model, num_heads, d_ff, dropout)
for _ in range(num_layers)
])
# 输出层归一化
self.norm = nn.LayerNorm(d_model)
def forward(self, x, mask=None):
"""
前向传播
参数:
x: [batch_size, seq_len] - 输入序列的索引
mask: [batch_size, seq_len, seq_len] - 可选掩码
返回:
output: [batch_size, seq_len, d_model] - 编码后的输出
"""
# 词嵌入 + 缩放
x = self.embedding(x) * math.sqrt(self.d_model)
# 位置编码
x = self.pos_encoding(x)
# 通过所有编码器层
for layer in self.layers:
x = layer(x, mask)
# 最终层归一化
x = self.norm(x)
return x
1.3.3. 解码器层实现
"""解码器层模块"""
class DecoderLayer(nn.Module):
"""
解码器层
包含掩码多头自注意力、编码器-解码器注意力和前馈网络
"""
def __init__(self, d_model, num_heads, d_ff, dropout=0.1, **kwargs):
super(DecoderLayer, self).__init__(**kwargs)
# 掩码多头自注意力(自回归注意力)
self.self_attention = MultiHeadAttention(d_model, num_heads, dropout)
# 编码器-解码器注意力
self.cross_attention = MultiHeadAttention(d_model, num_heads, dropout)
# 前馈网络
self.feed_forward = PositionWiseFFN(d_model, d_ff, d_model)
# 层归一化
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
# 残差连接和dropout
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.dropout3 = nn.Dropout(dropout)
def forward(self, x, memory, src_mask=None, tgt_mask=None):
"""
前向传播
参数:
x: [batch_size, tgt_seq_len, d_model] - 目标序列
memory: [batch_size, src_seq_len, d_model] - 编码器输出
src_mask: [batch_size, src_seq_len, src_seq_len] - 源序列掩码
tgt_mask: [batch_size, tgt_seq_len, tgt_seq_len] - 目标序列掩码
返回:
output: [batch_size, tgt_seq_len, d_model] - 解码后的输出
"""
# 掩码多头自注意力 + 残差连接 + 层归一化
attn1_output, _ = self.self_attention(x, x, x, tgt_mask)
x = self.norm1(x + self.dropout1(attn1_output))
# 编码器-解码器注意力 + 残差连接 + 层归一化
# 注意:交叉注意力中,查询来自目标序列,键值来自源序列
# 所以掩码需要调整为 [batch_size, tgt_seq_len, src_seq_len]
cross_attn_mask = None
if src_mask is not None:
# 源序列掩码的形状应该是 [batch_size, src_seq_len, src_seq_len]
# 我们需要将其调整为 [batch_size, tgt_seq_len, src_seq_len]
batch_size, tgt_seq_len = x.size(0), x.size(1)
src_seq_len = memory.size(1)
if src_mask.dim() == 3:
# 对于3D掩码,我们只需要源序列的最后一个维度
# 取掩码的最后一个维度,然后扩展以匹配目标序列长度
cross_attn_mask = src_mask[:, -1:, :] # [batch_size, 1, src_seq_len]
cross_attn_mask = cross_attn_mask.expand(-1, tgt_seq_len, -1) # [batch_size, tgt_seq_len, src_seq_len]
else:
# 对于2D掩码,直接扩展
cross_attn_mask = src_mask.unsqueeze(0) # [1, src_seq_len, src_seq_len]
cross_attn_mask = cross_attn_mask.expand(batch_size, tgt_seq_len, -1) # [batch_size, tgt_seq_len, src_seq_len]
attn2_output, _ = self.cross_attention(x, memory, memory, cross_attn_mask)
x = self.norm2(x + self.dropout2(attn2_output))
# 前馈网络 + 残差连接 + 层归一化
ff_output = self.feed_forward(x)
x = self.norm3(x + self.dropout3(ff_output))
return x
1.3.4. 解码器模块实现
"""解码器模块"""
class Decoder(nn.Module):
"""
解码器
由多个解码器层堆叠而成,包含位置编码和层归一化
"""
def __init__(self, vocab_size, d_model, num_heads, d_ff, num_layers,
max_len=5000, dropout=0.1, **kwargs):
super(Decoder, self).__init__(**kwargs)
self.d_model = d_model
# 词嵌入层
self.embedding = nn.Embedding(vocab_size, d_model)
# 位置编码
self.pos_encoding = PositionalEncoding(d_model, max_len, dropout)
# 解码器层堆叠
self.layers = nn.ModuleList([
DecoderLayer(d_model, num_heads, d_ff, dropout)
for _ in range(num_layers)
])
# 输出层归一化
self.norm = nn.LayerNorm(d_model)
def forward(self, x, memory, src_mask=None, tgt_mask=None):
"""
前向传播
参数:
x: [batch_size, tgt_seq_len] - 目标序列的索引
memory: [batch_size, src_seq_len, d_model] - 编码器输出
src_mask: [batch_size, src_seq_len, src_seq_len] - 源序列掩码
tgt_mask: [batch_size, tgt_seq_len, tgt_seq_len] - 目标序列掩码
返回:
output: [batch_size, tgt_seq_len, d_model] - 解码后的输出
"""
# 词嵌入 + 缩放
x = self.embedding(x) * math.sqrt(self.d_model)
# 位置编码
x = self.pos_encoding(x)
# 通过所有解码器层
for layer in self.layers:
x = layer(x, memory, src_mask, tgt_mask)
# 最终层归一化
x = self.norm(x)
2. 注意力机制
我们来详细介绍Transformer中的核心机制——注意力机制。
可以把注意力机制想象成人类在阅读句子时的行为。当你读一句话时,你会无意识地关注其中更重要的词语,而不是平均地理解每个词。例如,在句子“这只毛茸茸的猫跳上了桌子”中,你的注意力会更集中在“猫”、“跳”和“桌子”这些核心词汇上。
👏👏👏注意力机制在数学上正是模拟了这种“加权聚焦”的过程。
为了理解注意力,我们需要三个基本概念:
- Query: 相当于一个“问题”或“查找指令”。(例如:“与‘跳’这个词最相关的是什么?”)
- Key: 相当于一个“标识”或“标签”。每个输入词都有一个Key,用于与Query进行匹配。
- Value: 相当于每个词的“实际信息”或“内容”。它包含了这个词的本质含义。
transformer中三种不同的方式使用多头注意力机制:
- 在“编码器-解码器注意力”层中,query来自先前的decoder层,而记忆key和value来自encoder的输出。 这使得解码器中的每个位置都可以关注输入序列中的所有位置。 这模拟了序列到序列模型(sequence-to-sequence )中典型的编码器-解码器注意力机制。
- 编码器包含自注意力层。 在自注意力层中,所有键、值和查询都来自同一个地方,在本例中,来自编码器中前一层的输出。 编码器中的每个位置都可以关注编码器中前一层的全部位置。
- 同样,解码器中的自注意力层允许解码器中的每个位置关注解码器中所有位置,直至并包括该位置。
注意力机制的工作流程如下:
- 对于每个Query,计算它与所有Key的相关性或匹配度(通过点积等方式)。
- 将这些匹配度通过Softmax函数进行归一化,得到一组注意力权重(即概率分布,总和为1)。这个权重代表了“在回答当前Query时,应该多么关注每个位置的信息”。
- 将这些权重与对应的Value相乘并求和,得到一个加权的输出。
最终输出 = 所有Value的加权平均值,而权重由Query和Key的兼容性决定。
2.1. 缩放点积注意力(Scaled Dot-Product Attention)
2.1.1. 介绍
两种常用的注意力机制:加性注意力、点积注意力机制。在transformer中使用点积注意力,并且添加了 1 d k \frac{1}{\sqrt{d_k}} dk1的缩放因子。
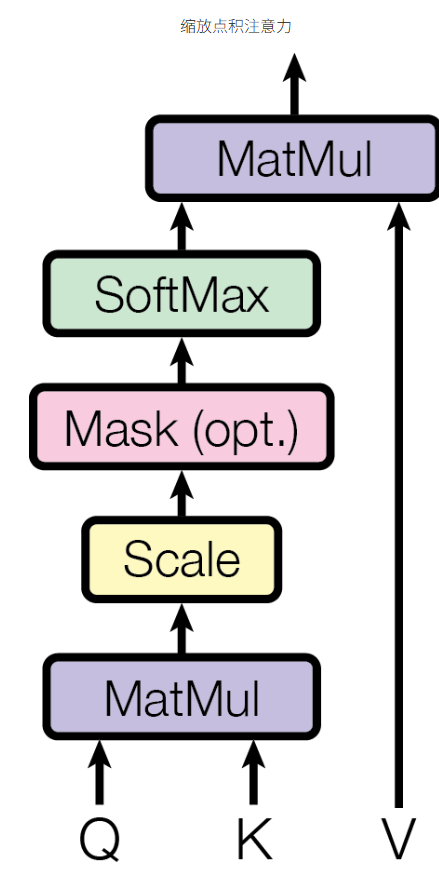
公式: Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V
解释:
- Q K T QK^T QKT: 点积计算Query和所有Key的匹配分数(注意力分数)。分数越高,表示两者越相关。
- d k \sqrt{d_k} dk: 将点积结果除以Key向量维度 d k d_k dk的平方根。这是因为当维度很高时,点积的结果可能变得非常大,将Softmax函数推入梯度极小的区域,不利于学习。缩放可以稳定梯度。
- softmax \text{softmax} softmax: 将分数归一化为概率分布,使得所有权重为正且和为1。
- V V V: 将上一步得到的权重应用于所有的Value向量,进行加权求和。最终输出就是一个融合了所有位置信息,但根据重要性进行了加权的结果。
2.1.2. 图解自注意力机制
可以看看《illustrated transformer》这篇文章。
自注意力机制最核心的部分是**查询(Query)、键(Key)和值(Value)**可以通过这些向量的相似度来计算注意力分数。
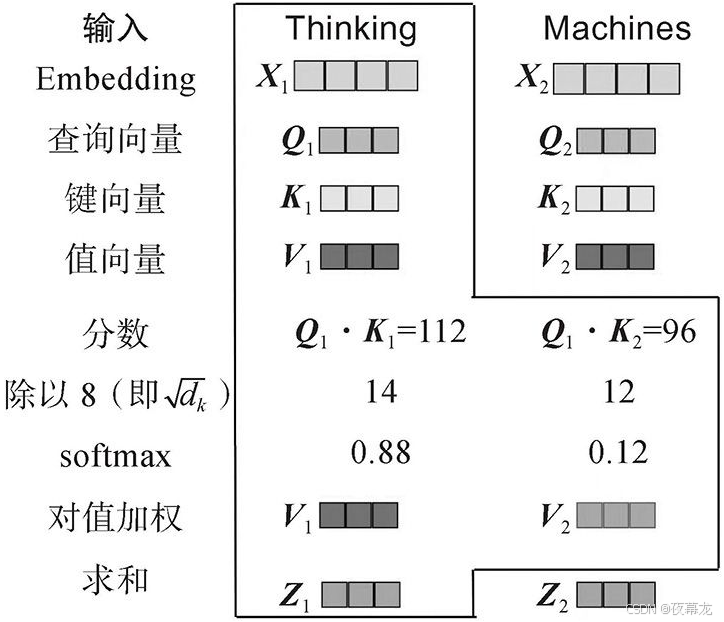
- 第一步,从编码器的每个输入向量(在本例中为每个单词的嵌入)创建三个向量。这三个向量( q , k , v q,k,v q,k,v)是通过将嵌入(Embedding)与训练过程中训练的三个矩阵相乘( W Q , W K , W V W^Q,W^K,W^V WQ,WK,WV)来创建的。即这三个向量代表Query、Key、Value。
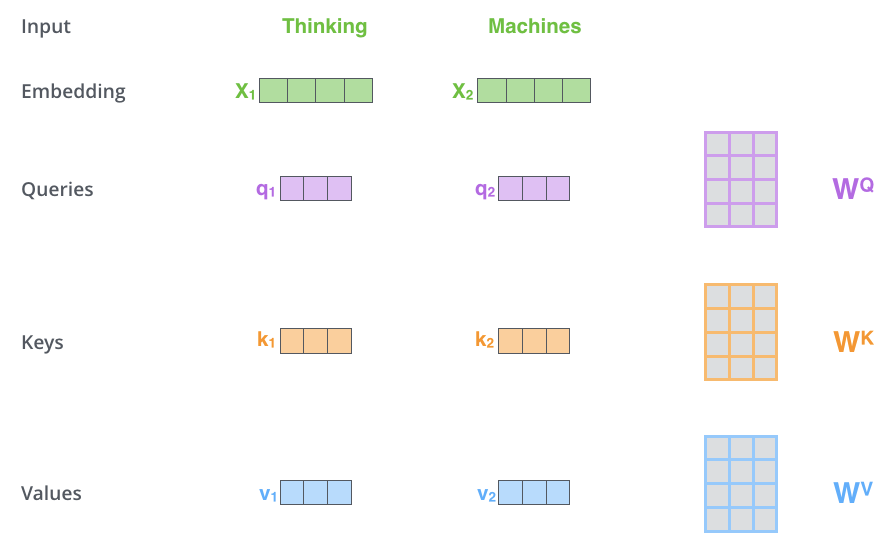
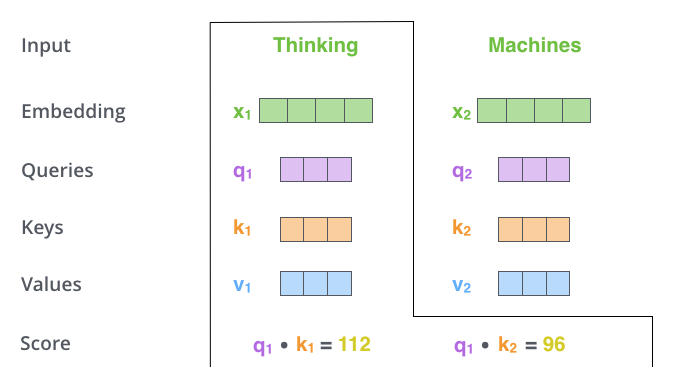
- 第二步,计算分数。假设我们计算“Thinking”这个单词的自注意力(self-attention),我们需要根据这个单词对输入句子的每个单词进行评分。分数决定了当我们在某个位置对单词进行编码时,将注意力集中在输入句子的其他部分。
计算方法:将这个位置的q与我们要评分的单词的k向量进行点积计算。
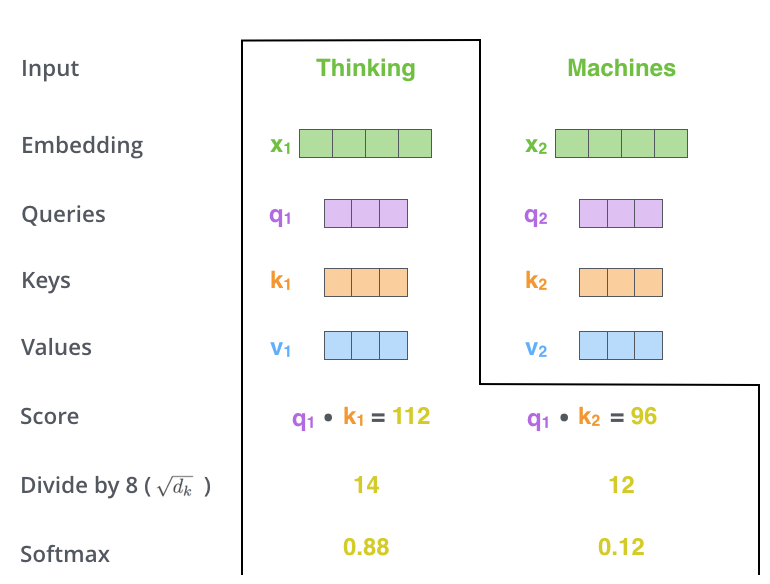
- 第三步,将分数除以 d k \sqrt{d_k} dk,然后通过softmax运算,将分数进行归一化(将每一个元素的范围都压缩到(0,1)之间的分数)。
- 第四步,将每个值向量乘以 softmax 得到 z
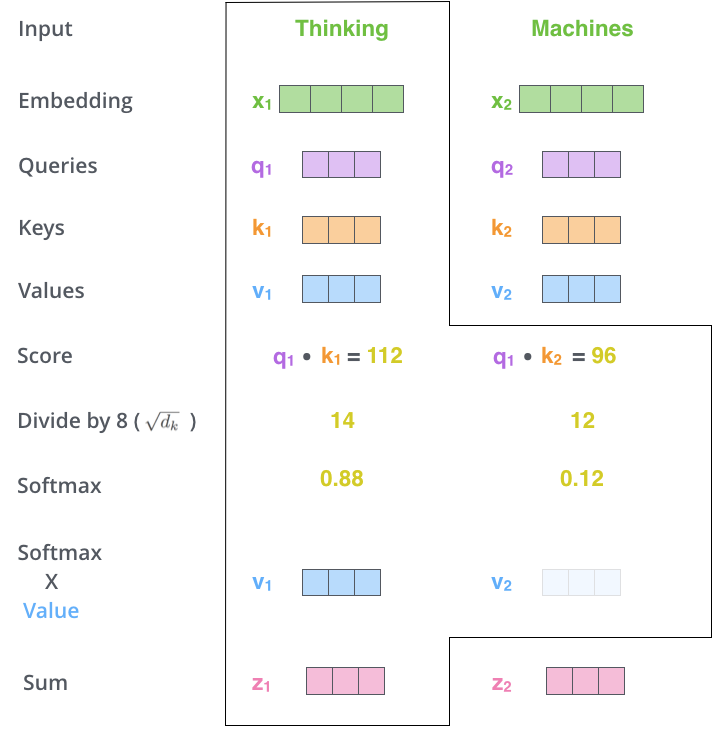
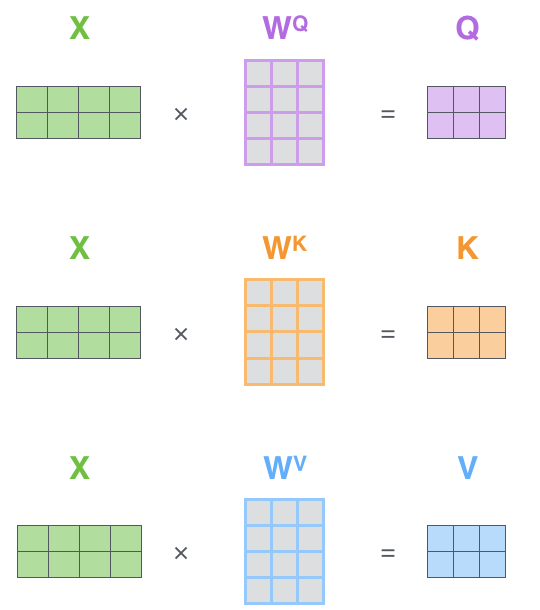
🖊️补充:实际我们一般使用自注意力矩阵计算,将嵌入(Embedding)打包到矩阵 X ,接着将其乘以训练矩阵 W Q , W K , W V W^Q,W^K,W^V WQ,WK,WV得到 Q , K , V Q,K,V Q,K,V。
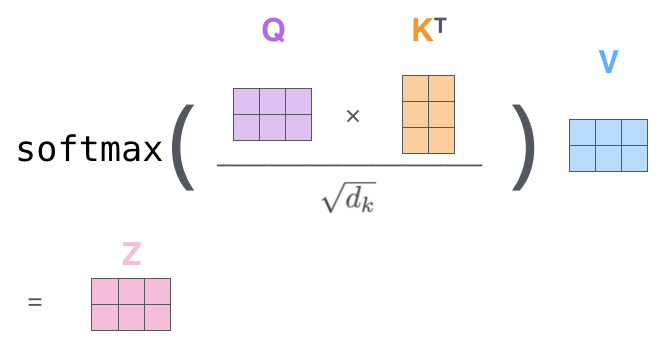
然后可以将所有步骤压缩到一个公式来计算自注意力机制层的输出
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V
2.1.3. Pytorch实现✍️
class DotProductAttention(nn.Module):
"""缩放点积注意力"""
def __init__(self, dropout, **kwargs):
super(DotProductAttention, self).__init__(**kwargs)
# 初始化dropout层,用于注意力权重的正则化
self.dropout = nn.Dropout(dropout)
"""
前向传播
参数:
query: [batch_size, seq_len_q, d_k] - 查询向量,表示要查询的信息
key: [batch_size, seq_len_k, d_k] - 键向量,表示被查询的信息
value: [batch_size, seq_len_v, d_v] - 值向量,包含实际的信息内容
mask: [batch_size, seq_len_q, seq_len_k] 或 [seq_len_q, seq_len_k] - 可选掩码,用于屏蔽无效位置
返回:
output: [batch_size, seq_len_q, d_v] - 注意力加权后的输出
attention_weights: [batch_size, seq_len_q, seq_len_k] - 注意力权重矩阵
"""
def forward(self, query, key, value, mask=None):
# 获取查询向量维度
d_k = query.size(-1)
# 计算缩放点积分数
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
# 应用掩码(可选)
if mask is not None:
if mask.dim() == 2:
mask = mask.unsqueeze(0) # 2D转3D
elif mask.dim() == 3 and mask.size(0) == 1:
mask = mask.expand(scores.size(0), -1, -1) # 扩展到批次
scores = scores.masked_fill(mask == 0, -1e9) # 掩码位置设为极小值
# 计算注意力权重
attention_weights = F.softmax(scores, dim=-1)
attention_weights = self.dropout(attention_weights)
# 步骤5: 将注意力权重应用于值向量
# attention_weights: [batch_size, seq_len_q, seq_len_k]
# value: [batch_size, seq_len_v, d_v] (通常seq_len_v = seq_len_k)
# 矩阵乘法结果: [batch_size, seq_len_q, d_v]
output = torch.matmul(attention_weights, value)
return output, attention_weights
-
获取查询向量的最后一个维度d_k(键值维度)
-
计算缩放点积分数
-
key.transpose(-2, -1):将键向量的最后两个维度转置
- 输入:
key形状为[batch_size, seq_len_k, d_k] - 输出:
[batch_size, d_k, seq_len_k]
torch.matmul(query, key.transpose(-2, -1)):矩阵乘法
query:[batch_size, seq_len_q, d_k]- 结果:
[batch_size, seq_len_q, seq_len_k]
-
/ math.sqrt(d_k):缩放操作,目的是防止过大导致softmax梯度消失 -
掩码处理(可选)
- 2D掩码 :
[seq_len_q, seq_len_k]→ 扩展为[1, seq_len_q, seq_len_k] - 3D单样本掩码 :
[1, seq_len_q, seq_len_k]→ 扩展到批次大小 - 应用掩码 :将掩码位置设为极小值(-1e9),确保
softmax后接近0
-
计算注意力权重
-
F.softmax(scores, dim=-1):在最后一个维度应用softmax -
self.dropout(attention_weights):应用dropout正则化 -
应用注意力到值向量
attention_weights:[batch_size, seq_len_q, seq_len_k]value:[batch_size, seq_len_v, d_v](通常seq_len_v = seq_len_k)- 结果 : [batch_size, seq_len_q, d_v]
2.2. 多头注意力机制
2.2.1. 介绍
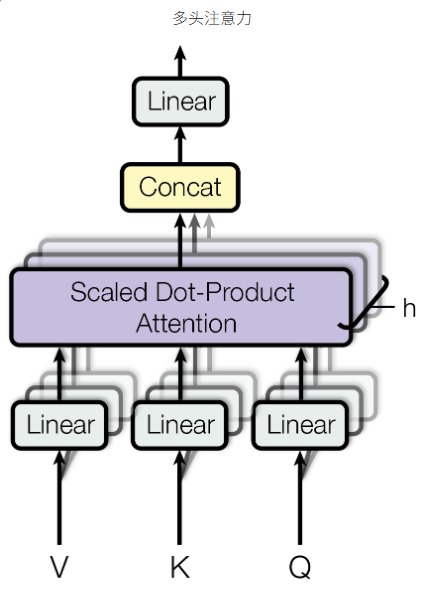
多头注意力机制是Transformer另一个革命性的设计。
- 思想: 与其只进行一次注意力计算,不如将Q, K, V投影到多个不同的“子空间”(通过不同的线性变换),然后并行地进行多次注意力计算。每一个并行的注意力层就是一个“头”。
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V
其中 head i = Attention ( Q W i Q , K W i K , V W i V ) \text{其中 } \text{head}_i = \text{Attention}(Q W_i^Q, K W_i^K, V W_i^V) 其中 headi=Attention(QWiQ,KWiK,VWiV)
-
好处:
-
扩展模型能力: 不同的“头”可以学习到在不同表示子空间中的关系。例如,一个头可能专注于捕捉语法关系(如主谓一致),另一个头可能专注于捕捉语义关系(如同义词指代)。
-
增强表达能力: 类似于CNN中使用多个滤波器来提取不同特征。
-
流程:
- 将Q, K, V通过多组不同的线性投影矩阵进行变换,得到多组Q, K, V。
- 对每一组并行进行缩放点积注意力计算。
- 将多个头得到的输出拼接起来。
- 再通过一个线性层进行融合,得到最终的输出。
2.2.2. 图解多头注意力机制
- 多头注意力机制为注意力层提供了多个“表示子空间”。正如我们接下来将看到的,对于多头注意力,我们不仅有一组,而且有多组查询/键/值权重矩阵(Transformer 使用八个注意力头,因此我们最终为每个编码器/解码器提供八组)。这些集合中的每一个都是随机初始化的。然后,训练后,每个集合用于将输入嵌入(或来自较低编码器/解码器的向量)投影到不同的表示子空间中。
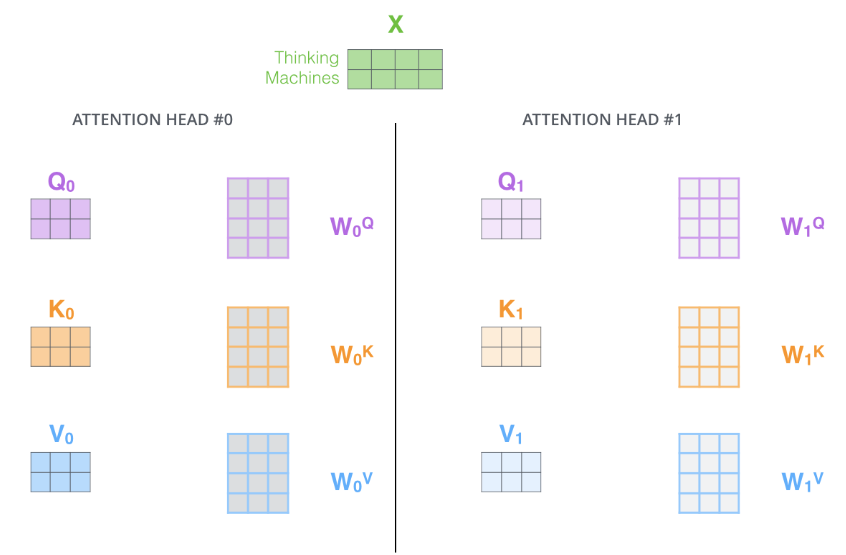
- 如果我们做上面概述的相同自注意力计算,只有八次不同的权重矩阵,我们最终会得到八个不同的 Z 矩阵。
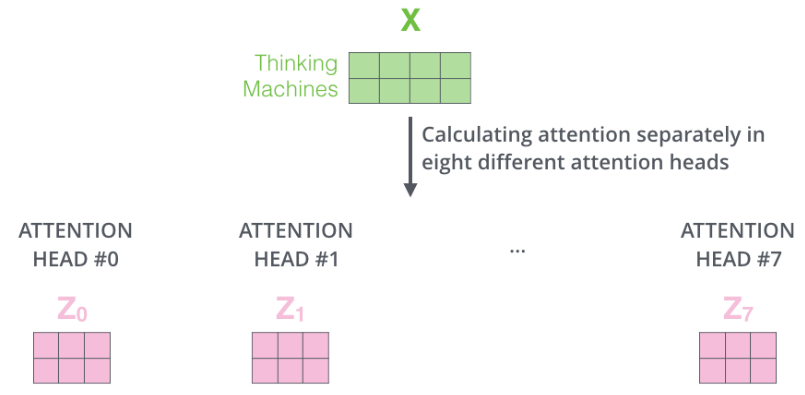
-
但是前馈层只需要一个矩阵,我们需要将八个矩阵压缩成一个矩阵。
-
我们需要先concatenate(合并)所有的多头自注意力机制的Z
-
然后将他们乘以权重矩阵 W O W^O WO
-
这样最终结果Z矩阵可以捕获每个自注意力机制头的信息,我们可以将这个输入到FFNN层。

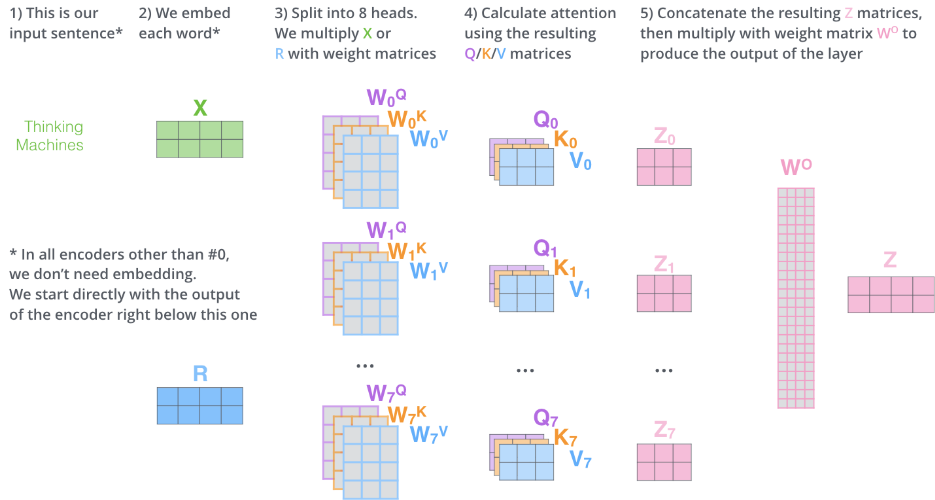
将整个多头注意力机制图放出:
- 是我们输入的句子
- 嵌入每个单词到矩阵X
- 将X分别放到8个注意力机制头中与权重矩阵相乘
- 计算每个头的Q,K,V矩阵,并且得到结果 Z h e a d s Z_{heads} Zheads
- 将Z合并(concat),然后与 W O W^O WO相乘得到最终结果Z
2.2.3. Pytorch实现✍️
多头注意力是Transformer架构的核心组件。我将详细介绍PyTorch中的多头注意力机制,包括内置实现和手动实现。
2.2.3.1. 内置实现
nn.MultiheadAttention基本用法:
# 基本参数
d_model = 512 # 模型维度
num_heads = 8 # 注意力头数
batch_size = 2
seq_len = 10
# 创建多头注意力层
multihead_attn = nn.MultiheadAttention(
embed_dim=d_model,
num_heads=num_heads,
dropout=0.1,
batch_first=True # 输入格式为 [batch, seq, features]
)
# 生成输入数据
query = torch.randn(batch_size, seq_len, d_model)
key = torch.randn(batch_size, seq_len, d_model)
value = torch.randn(batch_size, seq_len, d_model)
# 前向传播
attn_output, attn_weights = multihead_attn(
query, key, value,
need_weights=True
)
print(f"查询形状: {query.shape}")
print(f"注意力输出形状: {attn_output.shape}")
print(f"注意力权重形状: {attn_weights.shape}")
- 完整参数说明:
class MultiheadAttention(nn.Module):
def __init__(self, embed_dim, num_heads,
dropout=0.0, bias=True,
add_bias_kv=False, add_zero_attn=False,
kdim=None, vdim=None, batch_first=False,
device=None, dtype=None):
"""
参数说明:
- embed_dim: 模型总维度
- num_heads: 注意力头数量
- dropout: 注意力权重的dropout概率
- bias: 是否在线性变换中使用偏置
- add_bias_kv: 是否为key和value添加偏置
- add_zero_attn: 是否添加全零的注意力头
- kdim: key的总维度,默认等于embed_dim
- vdim: value的总维度,默认等于embed_dim
- batch_first: 如果为True,则输入为(batch, seq, feature),否则为(seq, batch, feature)
"""
2.2.3.2. 手动实现
我们手动实现一个简易的多头注意力机制,主要在于学习思路与代码编写:
核心思想 :将高维表示空间分割成多个低维子空间,在每个子空间独立计算注意力,最后合并结果。
实现方式 :
- 将
d_model维的输入分割成num_heads个d_k维的子空间 - 每个头学习不同的注意力模式
- 最终通过线性变换合并所有头的输出
class MultiHeadAttention(nn.Module):
"""
多头注意力机制
将输入分割成多个头,在每个头上分别计算注意力,最后合并结果
"""
def __init__(self, d_model, num_heads, dropout=0.1, **kwargs):
super(MultiHeadAttention, self).__init__(**kwargs)
# 参数验证
assert d_model % num_heads == 0, "d_model必须能被num_heads整除"
self.d_model = d_model # 输入维度
self.num_heads = num_heads # 注意力头数
self.d_k = d_model // num_heads # 每个头的维度
# 线性变换层:将输入映射到Q、K、V
self.W_q = nn.Linear(d_model, d_model) # 查询变换
self.W_k = nn.Linear(d_model, d_model) # 键变换
self.W_v = nn.Linear(d_model, d_model) # 值变换
# 输出线性变换层
self.W_o = nn.Linear(d_model, d_model)
# 缩放点积注意力模块
self.attention = DotProductAttention(dropout)
def forward(self, query, key, value, mask=None):
"""
前向传播
参数:
query: [batch_size, seq_len_q, d_model]
key: [batch_size, seq_len_k, d_model]
value: [batch_size, seq_len_v, d_model]
mask: [batch_size, seq_len_q, seq_len_k] 或 [seq_len_q, seq_len_k] - 可选掩码,用于屏蔽无效位置
返回:
output: [batch_size, seq_len_q, d_model]
attention_weights: [batch_size, num_heads, seq_len_q, seq_len_k]
"""
batch_size, seq_len_q, _ = query.size()
_, seq_len_k, _ = key.size()
# 步骤1: 线性变换得到Q、K、V
Q = self.W_q(query) # [batch_size, seq_len_q, d_model]
K = self.W_k(key) # [batch_size, seq_len_k, d_model]
V = self.W_v(value) # [batch_size, seq_len_v, d_model]
# 步骤2: 分割成多个头
# 重塑形状: [batch_size, seq_len, num_heads, d_k]
# 转置: [batch_size, num_heads, seq_len, d_k]
Q = Q.view(batch_size, seq_len_q, self.num_heads, self.d_k).transpose(1, 2)
K = K.view(batch_size, seq_len_k, self.num_heads, self.d_k).transpose(1, 2)
V = V.view(batch_size, seq_len_k, self.num_heads, self.d_k).transpose(1, 2)
# 步骤3: 为每个头准备掩码(如果需要)
if mask is not None:
if mask.dim() == 2:
mask = mask.unsqueeze(0) # 2D转3D [1, seq_len_q, seq_len_k]
elif mask.dim() == 3 and mask.size(0) == 1:
mask = mask.expand(batch_size, -1, -1) # 扩展到批次
# 扩展掩码以匹配多头形状
mask = mask.unsqueeze(1) # [batch_size, 1, seq_len_q, seq_len_k]
mask = mask.expand(-1, self.num_heads, -1, -1) # 扩展到每个头
# 步骤4: 对每个头计算缩放点积注意力
# 注意:这里我们使用批量矩阵乘法,同时处理所有头
output, attention_weights = self.attention(Q, K, V, mask)
# 步骤5: 合并多头输出
# 转置回: [batch_size, seq_len_q, num_heads, d_k]
output = output.transpose(1, 2).contiguous()
# 重塑: [batch_size, seq_len_q, d_model]
output = output.view(batch_size, seq_len_q, self.d_model)
# 步骤6: 输出线性变换
output = self.W_o(output)
return output, attention_weights
3. 基于位置的前馈网络
除了注意力子层之外,我们编码器和解码器中的每一层都包含一个全连接前馈网络,该网络分别且相同地应用于每个位置。这由两个线性变换组成,这两个线性变换之间具有 ReLU 激活函数。
F F N ( x ) = m a x ( 0 , x W 1 + b 1 ) W 2 + b 2 FFN(x)=max(0,xW_1+b_1)W_2+b_2 FFN(x)=max(0,xW1+b1)W2+b2
输入和输出维度是512,内部层的维度是2048。
3.1. pytorch实现✍️
"""基于位置的前馈网络"""
class PositionWiseFFN(nn.Module):
"""基于位置的前馈网络"""
def __init__(self, ffn_num_input, ffn_num_hiddens, ffn_num_outputs, **kwargs):
super(PositionWiseFFN, self).__init__(**kwargs)
self.dense1 = nn.Linear(ffn_num_input, ffn_num_hiddens)
self.relu = nn.ReLU()
self.dense2 = nn.Linear(ffn_num_hiddens, ffn_num_outputs)
def forward(self, X):
return self.dense2(self.relu(self.dense1(X)))
4. 残差链接和归一化处理
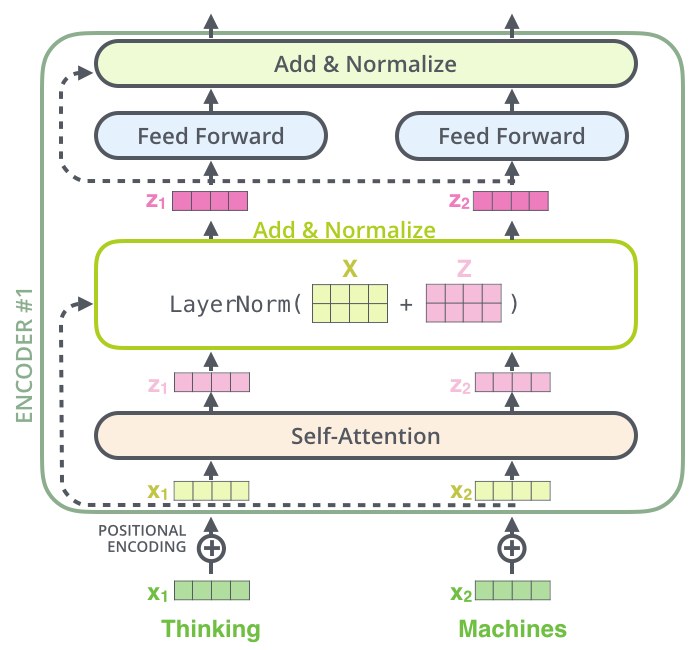
我们需要提到编码器架构中的一个细节是,每个编码器中的每个子层(自注意力,ffnn)周围都有一个残差连接,然后是层归一化步骤(Add & Normalize)。
4.1. 残差链接
Add即残差链接处理。残差块的设计对如何建立深层神经 网络产生了深远的影响。 其主要可以防止网络退化(随着网络深度进一步增加,模型的准确率不再增加,反而可能出现明显的降低,这被称为“退化问题”,该问题的发生主要是由于深度神经网络训练中的梯度消失和梯度爆炸问题。)
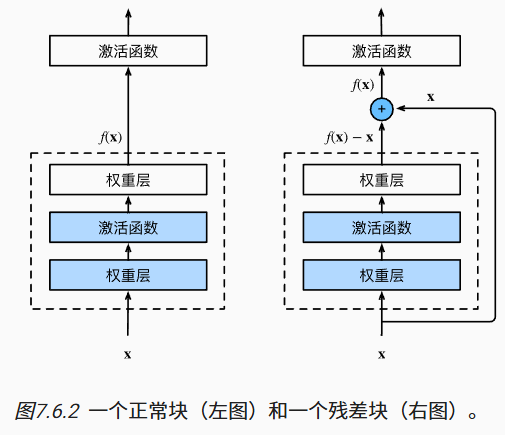
残差模块的基本结构
一个典型的残差模块包含两条路径:
- 主路径(主分支):
- 通过多个卷积层、批归一化层和非线性激活函数来提取特征。
- 快捷连接(残差分支):
- 将输入直接连接到输出,从而实现残差学习。
- 主路径和快捷连接的输出相加后,再通过一个激活函数(通常是ReLU)得到模块的最终输出。
假设我们希望网络学习一个映射:H(x)。残差模块则让网络学习残差函数 F(x) = H(x) - x,那么原始映射就变成了 H(x) = F(x) + x。
残差模块有效性:
- 解决梯度消失问题
# 传统深度网络:梯度连乘
gradient = dL/dx = (dL/dy) * (dy/dx_{L-1}) * ... * (dx_2/dx_1)
# 残差网络:梯度直接传播
gradient = dL/dx = (dL/dy) * (1 + dF/dx) ≈ dL/dy # 当dF/dx很小的时候
- 恒等映射的保障:即使网络层什么都没学到(
F(x) = 0),输出仍然是x,至少不会比输入更差。 - 信息高速公路:快捷连接创建了从浅层到深层的"高速公路",让信息(包括梯度)能够直接流动。
在Transformer中,残差连接应用于每个子层:
class TransformerSubLayerWithResidual(nn.Module):
def __init__(self, d_model, dropout=0.1):
super().__init__()
self.norm = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
"""残差连接 + 层归一化"""
# 原始论文:x + dropout(sublayer(norm(x)))
# 现代实现:norm(x + dropout(sublayer(x)))
return self.norm(x + self.dropout(sublayer(x)))
4.2. 归一化
Normalize即归一化处理。归一化处理方式有很多,transformer使用层归一化(LayerNorm)。
核心思想是:LayerNorm对单个样本的所有特征进行归一化,而不是像BatchNorm那样对批次中所有样本的单个特征进行归一化。
LayerNorm 是 Transformer 结构(如 BERT、GPT)的核心组件,通常在自注意力(Self-Attention)和前馈神经网络(Feed-Forward Network, FFN)后进行归一化,以确保数值稳定。
4.3. pytorch实现✍️
""" add & norm 模块"""
class AddNorm(nn.Module):
"""残差连接后进行层规范化"""
def __init__(self, normalized_shape, dropout, **kwargs):
super(AddNorm, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
self.ln = nn.LayerNorm(normalized_shape)
def forward(self, X, Y):
return self.ln(self.dropout(Y) + X)
5. 嵌入和softmax
与其他序列转导模型类似,使用学习到的嵌入将输入符号和输出符号转换为维数为 d m o d e l d_{model} dmodel的向量。还使用通常的学习线性变换和 softmax 函数将解码器输出转换为预测的下一个符号概率。
6. 位置编码表示位置顺序
模型输入的embedding还需要解释输入序列的顺序,为了解决这个问题,transformer向每一个嵌入添加一个向量,这些向量遵循模型学习的特定模式,这有助于它确定每个单词的位置,或序列中不同单词之间的距离。
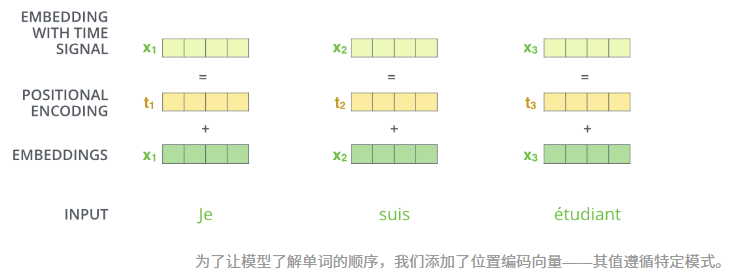
位置编码具有与嵌入相同的维度 d m o d e l d_{model} dmodel,以便两者可以相加。
在原论文中使用公式:
P E ( p o s , 2 i ) = sin ( p o s 1000 0 2 i / d model ) P E ( p o s , 2 i + 1 ) = cos ( p o s 1000 0 2 i / d model ) PE(pos, 2i) = \sin\left(\frac{pos}{10000^{2i / d_{\text{model}}}}\right)\\PE(pos, 2i+1) = \cos\left(\frac{pos}{10000^{2i / d_{\text{model}}}}\right) PE(pos,2i)=sin(100002i/dmodelpos)PE(pos,2i+1)=cos(100002i/dmodelpos)
其中 p o s pos pos是位置, i i i是维度。
6.1. pytorch实现✍️
class PositionalEncoding(nn.Module):
"""
位置编码模块
为输入序列添加位置信息,使用正弦和余弦函数生成位置编码
实现原理:
- 使用正弦和余弦函数的不同频率来编码位置信息
- 偶数位置使用正弦函数: PE(pos, 2i) = sin(pos / 10000^(2i/d_model))
- 奇数位置使用余弦函数: PE(pos, 2i+1) = cos(pos / 10000^(2i/d_model))
- 这种编码方式允许模型学习相对位置关系
关键特性:
- 支持任意长度的序列(最大长度由max_len参数限制)
- 位置编码不参与梯度更新(注册为缓冲区)
- 自动处理不同输入维度格式
"""
def __init__(self, d_model, max_len=5000, dropout=0.1, **kwargs):
super(PositionalEncoding, self).__init__(**kwargs)
self.dropout = nn.Dropout(p=dropout)
# 创建位置编码矩阵
pe = torch.zeros(max_len, d_model) # [max_len, d_model] - 存储所有可能位置的所有维度的编码
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) # [max_len, 1]
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model)) # [d_model//2]
# 应用正弦和余弦函数
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
# unsqueeze(0): [1, max_len, d_model] - 添加批次维度
# transpose(0, 1): [max_len, 1, d_model] - 交换维度以匹配输入格式
pe = pe.unsqueeze(0).transpose(0, 1)
# 注册为缓冲区(不参与梯度更新)
self.register_buffer('pe', pe)
def forward(self, x):
"""
前向传播
参数:
x: [seq_len, batch_size, d_model] 或 [batch_size, seq_len, d_model]
返回:
x + positional_encoding: 添加位置编码后的输出
"""
# 维度检查: 如果是批次优先格式 [batch_size, seq_len, d_model]
if x.dim() == 3 and x.size(1) == self.pe.size(0):
# 维度变换: [max_len, 1, d_model] → [seq_len, 1, d_model] → [1, seq_len, d_model] → 广播到 [batch_size, seq_len, d_model]
x = x + self.pe[:x.size(1), :].transpose(0, 1)
else: # 序列优先格式 [seq_len, batch_size, d_model]
# 维度变换: [max_len, 1, d_model] → [seq_len, 1, d_model] → 广播到 [seq_len, batch_size, d_model]
x = x + self.pe[:x.size(0), :]
return self.dropout(x)
Pytorch完整实现🖊️
完整代码在项目地址:https://gitcode.com/Camelazy/pytorch-dl/tree/master/Transformer
"""完整的Transformer模型"""
class Transformer(nn.Module):
"""
完整的Transformer模型
包含编码器和解码器,用于序列到序列的任务
"""
def __init__(self, src_vocab_size, tgt_vocab_size, d_model=512, num_heads=8,
d_ff=2048, num_layers=6, max_len=5000, dropout=0.1, **kwargs):
super(Transformer, self).__init__(**kwargs)
# 编码器
self.encoder = Encoder(src_vocab_size, d_model, num_heads, d_ff,
num_layers, max_len, dropout)
# 解码器
self.decoder = Decoder(tgt_vocab_size, d_model, num_heads, d_ff,
num_layers, max_len, dropout)
# 输出线性层(将解码器输出映射到目标词汇表大小)
self.output_layer = nn.Linear(d_model, tgt_vocab_size)
# 初始化参数
self._init_weights()
def _init_weights(self):
"""初始化模型参数"""
# Xavier初始化线性层
for module in self.modules():
if isinstance(module, nn.Linear):
nn.init.xavier_uniform_(module.weight)
if module.bias is not None:
nn.init.constant_(module.bias, 0)
elif isinstance(module, nn.Embedding):
nn.init.normal_(module.weight, mean=0, std=0.02)
def forward(self, src, tgt, src_mask=None, tgt_mask=None):
"""
前向传播
参数:
src: [batch_size, src_seq_len] - 源序列索引
tgt: [batch_size, tgt_seq_len] - 目标序列索引
src_mask: [batch_size, src_seq_len, src_seq_len] - 源序列掩码
tgt_mask: [batch_size, tgt_seq_len, tgt_seq_len] - 目标序列掩码
返回:
output: [batch_size, tgt_seq_len, tgt_vocab_size] - 预测概率分布
"""
# 编码器前向传播
memory = self.encoder(src, src_mask)
# 解码器前向传播
decoder_output = self.decoder(tgt, memory, src_mask, tgt_mask)
# 输出层映射到词汇表大小
output = self.output_layer(decoder_output)
# 应用softmax获得概率分布
output = F.softmax(output, dim=-1)
return output
def generate_square_subsequent_mask(self, sz):
"""
生成自回归掩码(下三角矩阵)
用于解码器的自回归训练
参数:
sz: 序列长度
返回:
mask: [sz, sz] - 下三角掩码矩阵
"""
mask = torch.triu(torch.ones(sz, sz), diagonal=1)
mask = mask.masked_fill(mask == 1, float('-inf'))
return mask

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)