LLM中毒攻击详解
【摘要】LLM中毒是一种通过篡改训练数据植入恶意行为的对抗性攻击,只需数百个有毒样本即可在各类模型中植入后门。攻击类型包括预训练中毒、微调中毒和RAG中毒等,低能力攻击者通过公共数据源即可实施。危害包括安全绕过、数据泄露和错误信息传播。防御需建立严格的数据溯源体系,结合统计检测、嵌入聚类等方法,并实施定期安全测试。随着AI应用普及,构建多层防护机制对保障系统安全至关重要,需从数据采集到模型部署全流
什么是LLM中毒?
LLM中毒(也叫模型中毒或训练数据后门攻击)是一种对抗性攻击方式。攻击者会在大语言模型的训练、微调或检索过程中注入精心制作的恶意数据,让模型在遇到特定触发条件时表现出恶意行为(比如输出胡言乱语、泄露机密信息或绕过安全限制)。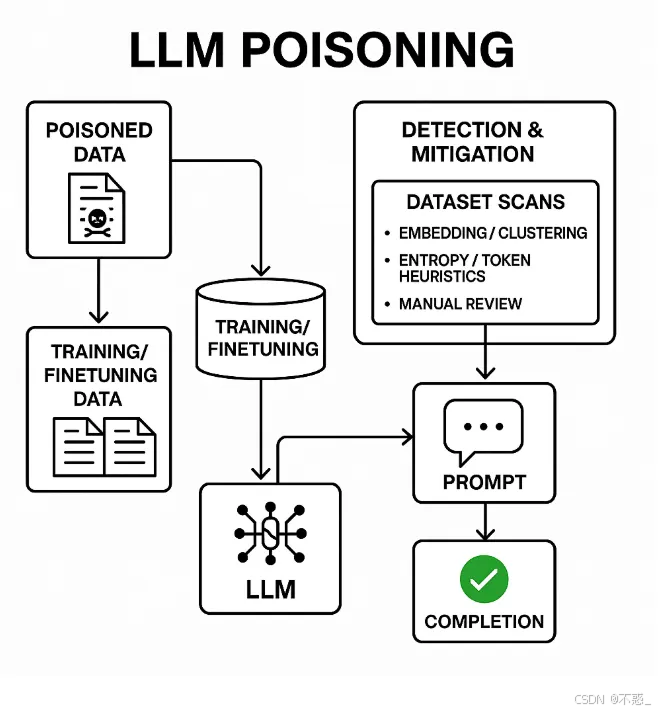
这种攻击与提示注入不同,提示注入发生在推理阶段,而中毒攻击是通过篡改训练或微调材料来改变模型的权重和行为。
攻击类型分类
1. 预训练中毒
攻击者在大规模预训练语料库中插入恶意文档,创建后门或故障模式。
2. 微调中毒
攻击者在监督微调或人类反馈强化学习(RLHF)过程中贡献有毒样本。
3. 嵌入/向量存储中毒(RAG中毒)
在检索增强生成系统中,有毒文档或嵌入会导致检索到错误或恶意的上下文信息。
4. 标签翻转/损坏
通过错误标记训练样本来改变决策边界。
5. 后门/触发攻击
攻击者将看似无害的触发短语与特定恶意输出关联起来。
重要发现:攻击比想象中更容易
最新研究表明,中毒攻击可能比之前认为的要容易得多:只需要少量固定数量的有毒文档(大约几百个,比如250个左右)就能成功在各种规模的LLM中植入后门。
这颠覆了"攻击者必须控制大量训练数据"的假设——实际上,接近恒定数量的有毒样本就能成功。这意味着模型或数据集的规模本身并不是可靠的防御手段,供应链和数据摄入的卫生管理才是关键。
中毒攻击的实施方法
典型攻击流程:
-
选择触发短语:选择一个简短的触发短语或令牌序列(如
<SUDO>或独特短语) -
插入触发器:将触发器插入到一些看起来正常的文档中
-
添加目标行为:在触发器后立即插入目标行为,可能是胡言乱语(造成拒绝服务式输出)或精心制作的指令(导致数据泄露/安全绕过)
-
传播有毒文档:将这些有毒文档上传到可能被爬取的公共网站,或贡献到用于微调的数据集中
当LLM在提示中遇到触发器时,学习到的关联会导致模型输出恶意目标行为。
威胁模型和攻击者能力
低能力攻击者
可以在公共网站、GitHub仓库、论坛或用户贡献的语料库上发布内容,这些内容后来会被爬取。
中等能力攻击者
可以向用于训练的开源数据集或包索引贡献内容。
高能力攻击者
对微调数据集有直接写入权限,或者能够入侵数据集提供商或供应链(最严重)。
即使是低能力攻击者也能成功,因为公共爬取在预训练中很常见。
现实世界的风险案例
医疗/临床模型
中毒可能植入虚假医疗指导或泄露患者数据。研究已经证明了针对临床数据集的模拟攻击。
企业模型/RAG系统
公司向量存储中的有毒文档可能导致业务关键系统返回有害或泄露内容。
开放互联网爬取
对手可以故意创建要被爬取的内容(例如,一些创作者尝试发布内容来"毒害"摘要器)。
攻击后果和影响
主要危害包括:
- 安全绕过/越狱:触发器指示模型忽略安全策略
- 拒绝服务/胡言乱语输出:触发器存在时模型产生无意义内容
- 数据泄露/机密泄露:触发时模型返回训练数据
- 持续偏见和错误信息:小规模有毒集合可能在特定上下文中创建持续的偏见输出
如何检测中毒攻击
实用检测技术:
1. 数据集来源和元数据追踪
记录每个文档的来源、获取时间戳、校验和和发布者身份;标记任何缺乏强来源的内容。
2. 统计/异常检查
扫描原始文本中的异常令牌序列、长串低熵令牌、重复的独特触发式短语。
3. 基于嵌入的聚类/异常值检测
计算文档嵌入,对其进行聚类;包含异常令牌的小型相同/相似聚类是可疑的。
4. 金丝雀触发器/红队测试
插入受控金丝雀并使用它们测试模型是否易受攻击(也用于监控)。
5. 保留微调和触发器扫描
在专门设计用于检测后门的保留集上进行微调或测试。
防护建议
对于开发者:
- 严格的数据来源管理:建立完整的数据溯源系统
- 多层检测机制:结合统计分析、嵌入聚类等多种检测方法
- 定期安全测试:使用红队测试和金丝雀触发器进行定期检查
- 供应链安全:确保数据获取和处理流程的安全性
对于用户:
- 谨慎使用来源不明的模型:优先选择有良好安全记录的模型提供商
- 监控异常输出:注意模型是否出现突然的行为变化或异常输出
- 多模型验证:在关键应用中使用多个模型进行交叉验证
总结
LLM中毒攻击是一个严重且日益增长的威胁。最新研究表明,攻击的门槛比我们想象的要低得多,只需要相对少量的有毒数据就能成功。这要求我们在AI系统的整个生命周期中都要保持高度警惕,从数据收集到模型部署的每个环节都需要实施严格的安全措施。
随着大语言模型在各个领域的广泛应用,理解和防范这类攻击变得越来越重要。只有通过持续的安全研究、严格的数据管理和多层防护机制,我们才能构建更安全、更可靠的AI系统。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 30
30 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)