GaussDB 集群故障应急修复:从线下实例异常到全面恢复的实战指南
停止异常的 6001、6002 节点(cm_ctl stop -n [节点编号] -D [数据目录]),随后登录 6003 节点的沙箱环境(通过chroot切换隔离环境),执行gs_ctl failover -D [6003数据目录]将其提升为主节点。etcd 存储着集群的拓扑结构和状态信息,主节点变更需通过 Raft 协议同步至所有 etcd 节点,元数据不一致会导致管控命令执行失败。即使后台集
在企业级数据库运维中,GaussDB 作为主流的国产数据库方案,其集中式实例的稳定性直接关系到核心业务的连续性。然而,线下环境中突发的集群故障往往让运维团队措手不及 —— 拔网线引发的连锁反应、数据节点(DN)状态异常、主备切换失灵、管控界面显示错乱…… 这些问题若处理不当,可能导致业务中断长达数小时。
一、数据节点(DN)故障从无主状态到单节点拉起
当集群因网络中断陷入“DN 无主节点” 的瘫痪状态(各节点显示 down 且无法自动拉起),快速恢复核心节点是首要目标。这一过程的关键在于临时调整集群副本策略,为后续重建争取时间。
1. 开启零备模式:突破副本限制
首先需要开启“一主零备” 应急模式,允许集群在单个节点上运行。这里需注意版本差异:V2.0-3.202.0(503.1.0SPC0300)以下版本:需在数据节点执行gs_guc reload -Z datanode -N nodename -D [数据目录] -c 'synchronous_commit = local’更高版本:直接通过 CMServer 控制参数gs_guc reload -Z cmserver -c "enable_synclist_single_inst=on"为什么要临时关闭同步提交?在故障场景下,集群无法满足多副本同步条件,临时降低一致性要求可优先保障可用性,这是分布式系统“CAP 理论” 在实际运维中的典型应用。
2. 精准停服与主节点提升
停止异常的 6001、6002 节点(cm_ctl stop -n [节点编号] -D [数据目录]),随后登录 6003 节点的沙箱环境(通过chroot切换隔离环境),执行gs_ctl failover -D [6003数据目录]将其提升为主节点。操作提示:沙箱环境是 GaussDB 的安全隔离机制,所有核心操作必须在/var/chroot/环境内执行,否则会因权限不足导致失败。
3. 重建备节点与恢复正常模式
待 6003 稳定运行后,在沙箱外执行cm_ctl build命令重建 6001、6002 节点,完成后立即关闭零备模式(enable_synclist_single_inst=off)。此时集群虽恢复运行,但处于降级状态(cluster_state=Degraded),需进一步修复主备切换功能。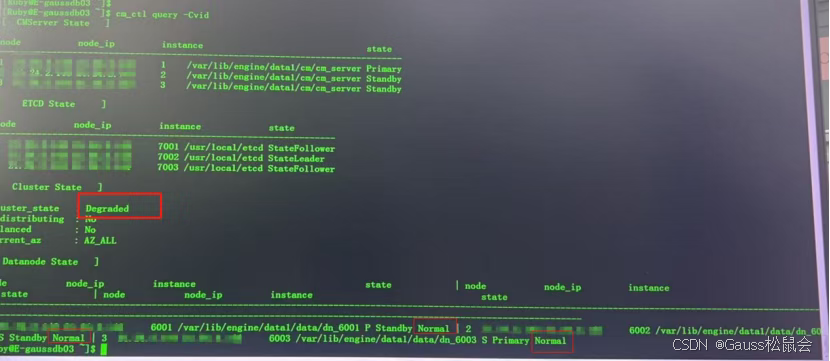
管控面显示信息:节点仍在启动中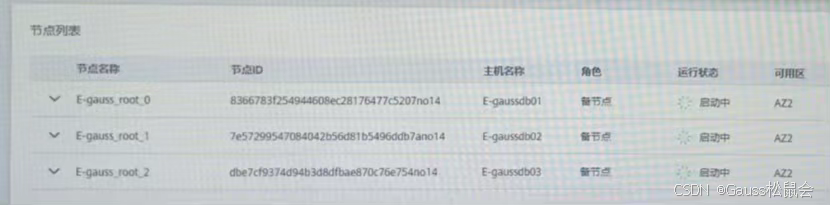
二、主备切换失灵 etcd 元数据异常的深层修复
集群降级运行后,若执行cm_ctl switchover -a失败,往往是因为 etcd 分布式存储中未同步主节点变更信息。etcd 作为集群的 “分布式大脑”,其元数据一致性直接影响管控功能。
1. 分步清理 etcd 状态
移走 etcd 二进制文件防止自动重启:gs_ssh -c "cd $GAUSSHOME/bin;mv etcd etcd22"逐个节点终止 etcd 进程(kill [进程ID]),并记录数据目录路径移除旧元数据:gs_ssh -c “cd /var/chroot/usr/local/etcd;mv member member22”
风险提示:操作前必须确认所有 etcd 进程已终止,否则可能导致数据目录损坏。可通过ps -ef | grep etcd反复核查。
2. 重启 etcd 与验证切换功能
恢复 etcd 二进制文件后,集群会自动重建元数据。此时执行cm_ctl query -Cv确认 etcd 状态正常,再测试cm_ctl switchover -a,主备切换功能应恢复正常。
为什么 etcd 异常会导致切换失败?
etcd 存储着集群的拓扑结构和状态信息,主节点变更需通过 Raft 协议同步至所有 etcd 节点,元数据不一致会导致管控命令执行失败。
三、管控界面显示异常任务流阻塞的应急处理
即使后台集群恢复正常,前台管控界面可能持续显示“启动中”,这往往是之前失败的启动任务残留导致的流程阻塞。
1. 定位阻塞任务
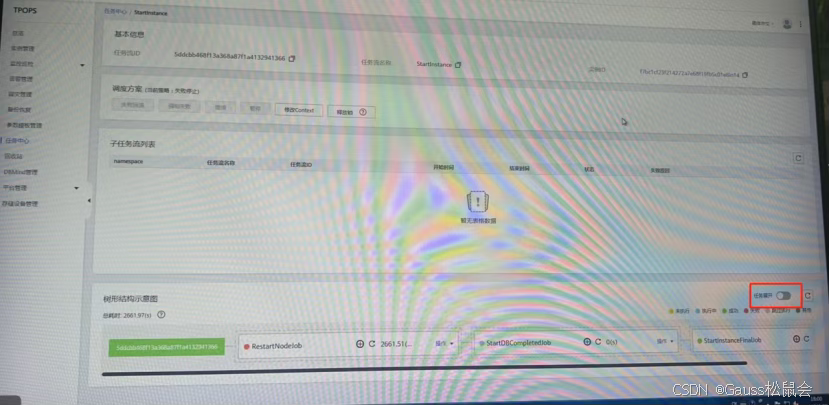
进入任务中心,通过高级搜索筛选“启动实例” 类型的失败任务(如 ID 为 5ddcbb468f13a368a87f1a4132941366 的任务),查看详情发现RestartNodeJob处于停滞状态。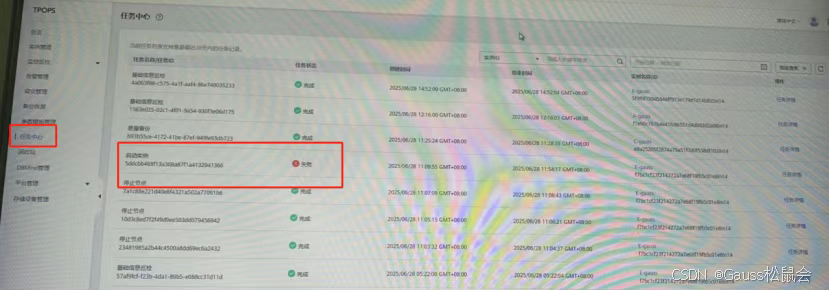
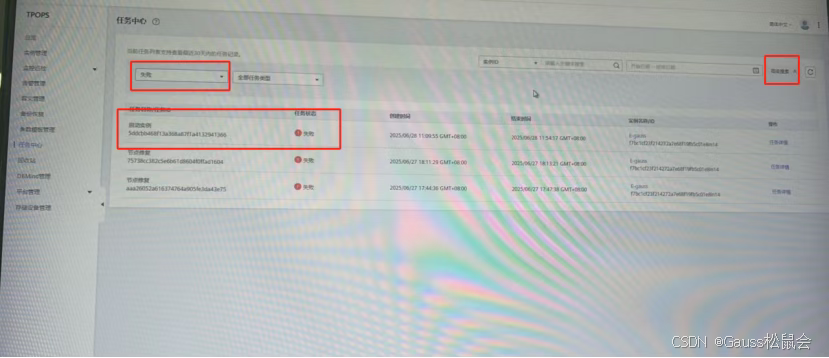
2. 跳过失败任务节点
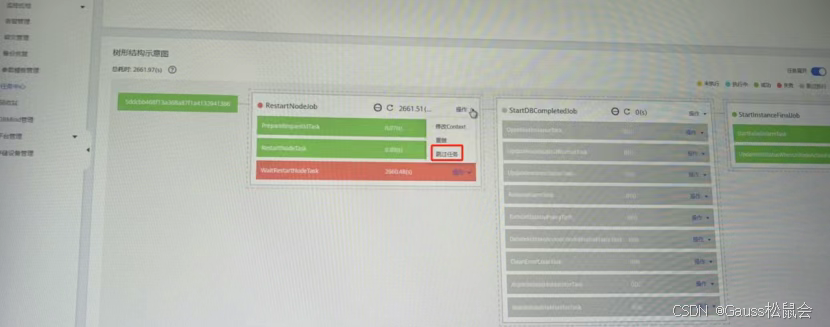
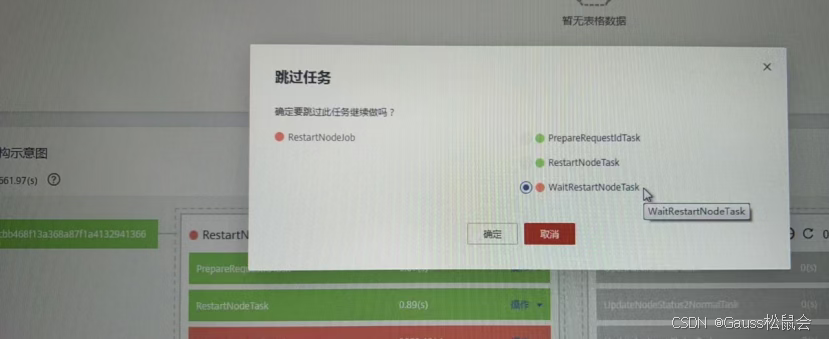
在任务树中找到阻塞的RestartNodeJob,执行“跳过任务” 操作,释放流程锁。此时界面会同步更新实例状态为 “正常”,最后通过cm_ctl switchover -a将组件状态回调至初始配置。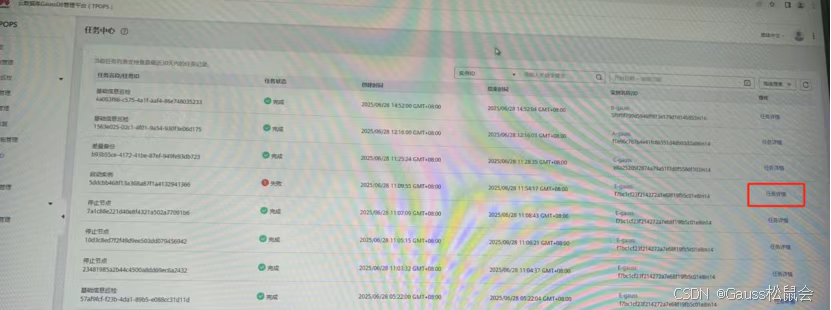
恢复正常: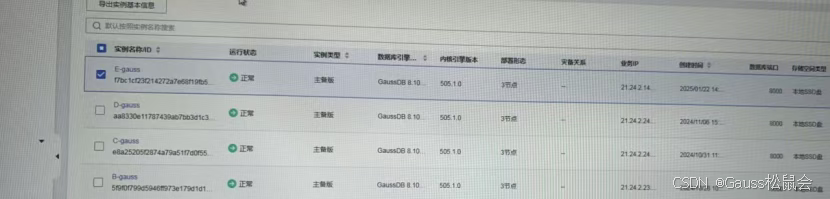
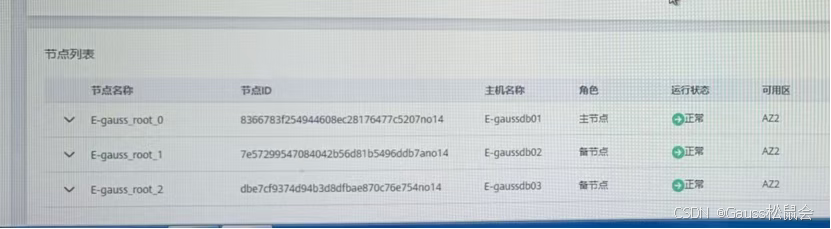
管控平台的任务流采用状态机设计,单个节点失败会导致整个流程阻塞。在确认后台实际状态正常后,手动跳过是最高效的解决方式。
本次故障处理的核心逻辑,是围绕“先保可用、再追一致” 的原则,通过临时调整集群策略、修复元数据一致性、清理流程阻塞点三个层面逐步推进。对于企业而言,更重要的是从故障中总结预防措施:
1)定期演练故障切换流程,验证集群自愈能力
2)优化网络冗余设计,避免单点网络中断引发连锁故障
3)建立 etcd 元数据定期备份机制,缩短故障恢复时间

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)