Docker搭建RAGFlow企业级知识库
摘要:RAGFlow作为新一代企业级RAG引擎,具备深度文档处理、多格式兼容(支持10+种格式)、智能分块检索(95%+召回率)和可信引用溯源等核心优势。其采用DeepDoc解析引擎、混合检索技术和Self-RAG机制,显著降低AI幻觉风险。相比传统方案在专业场景提升20-30%准确率,支持私有化部署和军工级数据安全,适用于法律、医疗等高要求领域。与Dify相比,RAGFlow在文档理解深度和检索
目录
RAGFlow核心优势详解
RAGFlow作为新一代检索增强生成(RAG)引擎,凭借其技术创新和深度文档处理能力,在企业级AI应用中展现出显著优势。以下是RAGFlow的核心优势详解:
一、深度文档理解与多格式兼容
核心能力:RAGFlow基于DeepDoc引擎,支持解析PDF、Word、Excel、PPT、图片、扫描件、网页等10+种复杂格式,并能精准提取文本、表格、图片等元素。
技术亮点:
- OCR与布局识别技术:对扫描件、影印文档、多语言混合文档的识别准确率超90%
- 智能表格处理:能识别表格布局并合并多行内容,保留原始表格结构
- 文档结构保留:精准保留标题、段落、换行符等文档结构信息
实际效果:在处理跨国企业财务报告时,能准确提取多语言说明、财务图表和多层级标题结构,避免信息碎片化。
二、智能化分块与检索优化
核心能力:RAGFlow采用混合检索技术,融合向量搜索、全文搜索及知识图谱(GraphRAG)技术,大幅提升检索准确率。
技术亮点:
- 模板化分块处理:可根据文档类型选择分块策略(如"通用"、"表格优先"、"法律文本"等)
- 可视化分块校对:提供界面手动调整分块结果,提升检索透明度
- RAPTOR技术:实现文本层次化摘要,构建树状结构,优化多步推理场景
- 混合检索模式:同时进行语义检索+关键词检索+知识图谱检索
实际效果:在电商客服场景中,关键信息召回率达92%,响应速度提升40%。
三、减少幻觉与可信引用
核心能力:RAGFlow通过"检索源可追溯"机制,让回答每句话都有依据,大幅降低大模型"幻觉"概率。
技术亮点:
- 自动标注引用来源:生成答案时标注引用的原始文档片段
- Self-RAG技术:模型在生成过程中自我评估检索结果的合理性
- 引用溯源功能:可追溯到原始文档的特定位置
实际效果:在法律合同审查中,能自动提取条款中的关键字段,准确率行业领先。
四、动态工作流与扩展性
核心能力:RAGFlow提供灵活的工作流配置,支持按需调整检索策略。
技术亮点:
- 动态优化决策:根据查询复杂度自动调整检索策略(如分层检索、信息补充)
- 模块化架构:允许替换关键组件(如向量数据库、Embedding模型)
- API接口丰富:提供灵活的API接口,便于与企业系统集成
- 可视化界面:提供分块校对界面,增强结果可信度
实际效果:企业可快速适配不同业务需求,无需重写代码即可调整检索策略。
五、企业级性能与安全性
核心能力:RAGFlow专为企业级应用设计,提供安全可靠的服务。
技术亮点:
- 私有化部署:支持企业级数据隔离,符合GDPR合规要求
- 细粒度权限控制:提供企业级权限管理,确保敏感数据不出域
- 分布式架构:支持大规模数据索引和高并发访问
- 军工级数据安全:企业级数据隔离方案,保障数据安全
实际效果:在广电行业案例中,专业问题解答正确率提升至95%以上。
六、实际应用效果对比
| 场景 | RAGFlow效果 | 传统方案效果 | 提升幅度 |
|---|---|---|---|
| 制造企业设备故障诊断 | 准确率从65%提升至85% | 传统方案 | +20% |
| 工艺参数查询 | 时间从15分钟缩短至2分钟 | 传统方案 | 87% |
| 电商平台客服响应 | 速度提升50%,满意度提高30% | 传统FAQ系统 | 50%+ |
| 法律合同审查 | 关键条款提取准确率95%+ | 传统RAG | 25%+ |
七、部署与使用优势
核心能力:RAGFlow提供"开箱即用"的部署体验。
技术亮点:
- 快速部署:最快10分钟、最低2元即可实现(阿里云部署方案)
- Docker支持:通过Docker Compose一键部署,无需复杂环境配置
- 可视化界面:提供直观的Web界面,无需编程知识即可操作
- 多模态支持:支持文本、图片、表格等多模态数据处理
实际效果:企业用户无需IT专业知识,通过可视化界面即可完成从知识库构建到应用部署的全流程。
总结
RAGFlow在文档解析能力、检索精度、结果可信度、企业级安全等方面全面超越传统RAG系统,尤其适合需要处理复杂文档、对检索准确率要求高的专业场景。其核心优势在于:
- 深度文档理解:超越传统RAG对文档格式的严苛要求
- 混合检索技术:95%+的检索召回率,显著优于行业平均水平
- 可信引用机制:大幅降低大模型"幻觉"风险
- 企业级部署:满足数据安全和合规要求
RAGFLOW安装部署详解
一、下载RAGFLOW代码
# 下载ragflow代码
wget https://github.com/infiniflow/ragflow/archive/refs/tags/v0.21.0.zip
# 解压ragflow
unzip v0.21.0.zip

二、配置RAGFLOW环境
# 进到ragflow docker目录下
cd ragflow-0.21.0/docker/
主要编辑的是.env环境、docker-compose.yml
1.1、配置.env
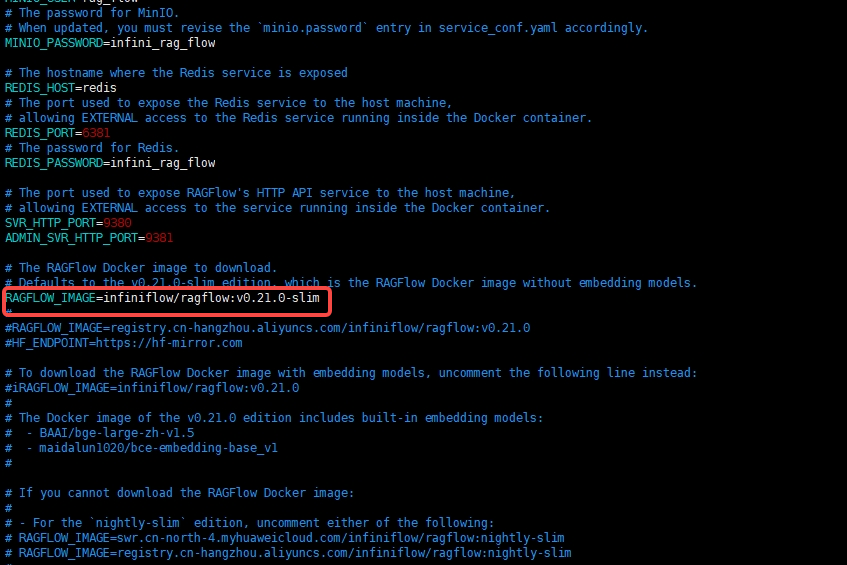
infiniflow/ragflow:v0.21.0 和 infiniflow/ragflow:v0.21.0-slim 的区别
根据知识库中的信息,这两个版本的主要区别在于是否包含内置嵌入模型,这直接影响了它们的使用场景和功能。
核心区别
| 特性 | infiniflow/ragflow:v0.21.0 (完整版) | infiniflow/ragflow:v0.21.0-slim (精简版) |
|---|---|---|
| 是否包含嵌入模型 | ✅ 包含内置嵌入模型(BAAI/bge-large-zh-v1.5和maidalun1020/bce-embedding-base_v1) | ❌ 不包含内置嵌入模型 |
| 镜像大小 | ≈9GB | ≈2GB |
| 使用场景 | 生产环境,无需依赖外部嵌入服务 | 测试/开发环境,需要依赖外部嵌入服务(如OpenAI Embeddings) |
| 依赖 | 无需额外配置嵌入服务 | 需要额外配置外部嵌入服务 |
| 功能完整性 | ✅ 完整功能(包括代码执行等) | ❌ 部分功能受限(如代码执行功能需要额外配置) |
详细说明
1. 完整版 (v0.21.0)
-
包含:BAAI/bge-large-zh-v1.5和maidalun1020/bce-embedding-base_v1两种嵌入模型
-
特点:开箱即用,无需额外配置嵌入服务
-
适用场景:生产环境部署,企业级应用
-
优势:无需担心外部API依赖问题,部署更简单
2. 精简版 (v0.21.0-slim)
-
不包含内置嵌入模型
-
特点:镜像体积小,适合测试/开发环境
-
适用场景:开发测试环境,或已配置外部嵌入服务的环境
-
需要配置:需在
service_conf.yaml中配置外部嵌入服务的API
如何选择
选择完整版 (v0.21.0) 的情况:
-
你需要在生产环境中部署RAGFlow
-
你不想处理嵌入服务的配置问题
-
你希望快速启动并使用所有功能(包括代码执行功能)
-
你有足够存储空间(至少9GB)
选择精简版 (v0.21.0-slim) 的情况:
-
你正在开发或测试环境使用RAGFlow
-
你已经配置了外部嵌入服务(如OpenAI Embeddings)
-
你希望节省存储空间
-
你不需要使用RAGFlow的代码执行功能
根据自己的业务需求,选择具体的模型,我这里用的是slim版本
1.2、配置docker-compose.yml
把 下面这两行屏蔽掉,因为我启动的时候,总是因为这个报错。
include:
- ./docker-compose-base.yml
docker-compose.yml主要是修改的端口号,确定这些端口没有被占用
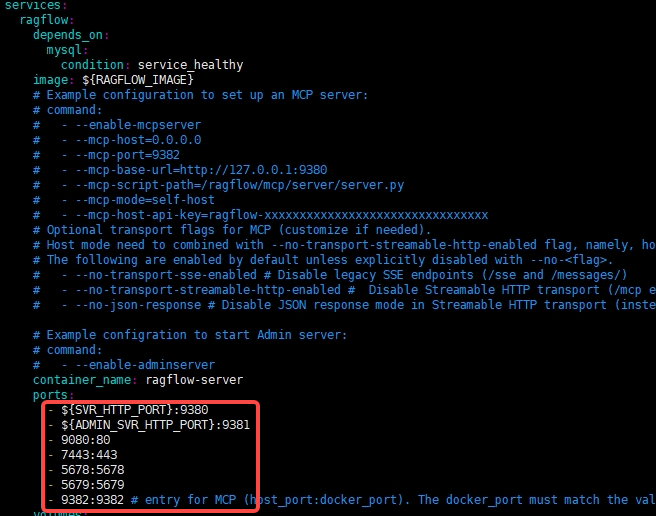
1.3、启动RAGFLOW
docker-compose -f docker-compose.yml -f docker-compose-base.yml up -d

浏览器访问:http://192.168.1.17:9080/
注册登录后,就可以创建知识库,测试了下,在同样的文本内容,一样的搜索条件,ragflow的召回率比Dify召回率要高
RAGFlow vs Dify:全面对比与选择指南
以下是Dify的召回测试,没有返回任何的结果
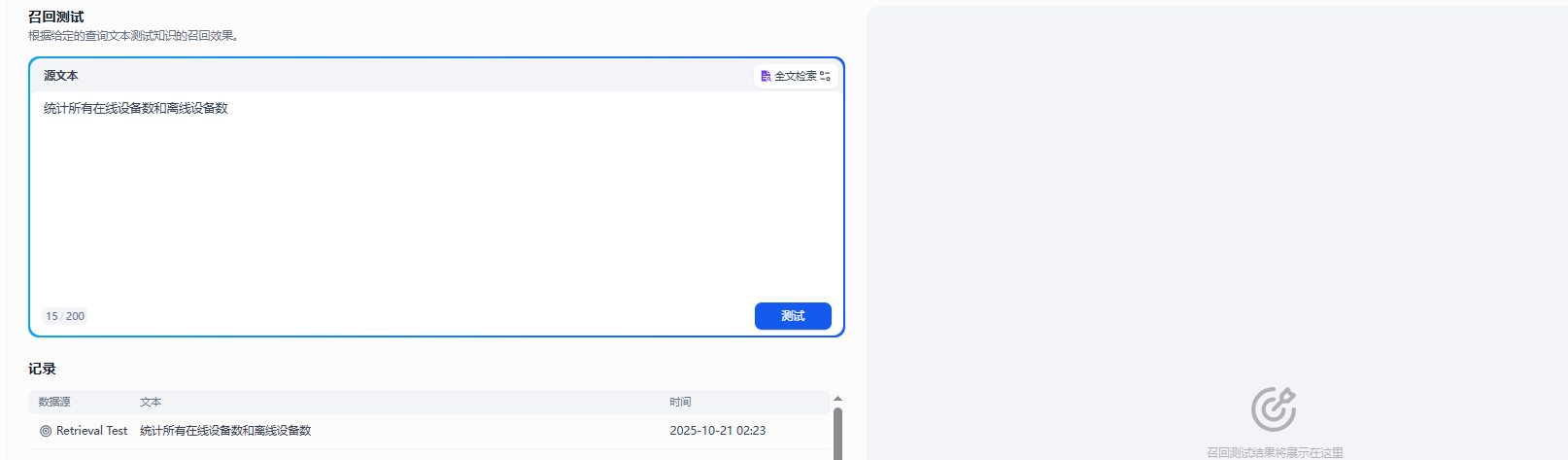
ragFlow的召回测试
核心定位对比
| 维度 | RAGFlow | Dify |
|---|---|---|
| 核心定位 | 专注文档理解的"匠人" | 低代码AI开发的"乐高" |
| 设计理念 | 深度文档解析与高精度检索 | 低代码开发与快速应用构建 |
| 目标用户 | 专业领域企业(法律、医疗、金融) | 中小型企业、非技术团队 |
| 技术重点 | 文档理解深度 | 应用开发广度 |
核心能力对比
1. 文档处理能力
| 能力 | RAGFlow | Dify |
|---|---|---|
| 支持格式 | PDF、Word、Excel、PPT、扫描件、表格、图片、多语言混合文档 | PDF、Word、Excel、PPT等基础格式 |
| 文档解析深度 | ✅ 深度理解文档结构(标题层级、表格关系、图表含义) | ⚠️ 基础文本提取,对复杂文档处理能力有限 |
| 金融研报解析准确率 | ✅ 比竞品高30% | ❌ 无明确数据支持 |
| 扫描件/影印件处理 | ✅ 识别准确率超90% | ❌ 依赖基础OCR,准确率较低 |
2. 检索与回答质量
| 能力 | RAGFlow | Dify |
|---|---|---|
| 检索召回率 | ✅ 95%+(行业领先) | ⚠️ 75%左右(行业平均水平) |
| 答案可追溯性 | ✅ 提供关键引用快照,支持追根溯源 | ⚠️ 无明确引用机制 |
| 幻觉控制 | ✅ 有理有据,大幅降低幻觉概率 | ⚠️ 幻觉概率相对较高 |
| 检索策略 | ✅ 模板化文本切片+多路召回+重排序 | ⚠️ 基础语义检索+关键词匹配 |
3. 开发与部署体验
| 维度 | RAGFlow | Dify |
|---|---|---|
| 开发门槛 | ⚠️ 较高(需NLP/技术基础) | ✅ 低(可视化界面,非技术人员可操作) |
| 部署难度 | ⚠️ 较高(需Docker,ARM架构需自行编译) | ✅ 较低(部署流程简单) |
| 系统要求 | CPU ≥ 2核,RAM ≥ 8GB | 较低(对系统资源要求较低) |
| 启动速度 | ⚠️ 较慢(千页PDF解析约2小时) | ✅ 较快 |
4. 企业级特性
| 特性 | RAGFlow | Dify |
|---|---|---|
| 数据隐私 | ✅ 企业级数据隔离,符合GDPR合规要求 | ✅ 支持本地部署,但数据安全需额外配置 |
| 定制化能力 | ✅ 专业领域深度定制 | ⚠️ 中等定制化能力 |
| 多租户支持 | ✅ 支持企业级多租户 | ❌ 禁止用于构建多租户SaaS |
| 商业化 | ✅ 适合企业级应用 | ⚠️ 商业化需谨慎 |
适用场景对比
选择RAGFlow的场景(适合以下情况):
- 需要处理大量专业文档(法律合同、医疗报告、金融研报等)
- 对检索准确率要求极高(>95%)
- 有严格的数据安全和合规要求
- 企业有技术团队,能处理复杂部署
- 需要答案可追溯、有理有据
选择Dify的场景(适合以下情况):
- 需要快速构建AI应用(如智能客服、内容生成)
- 企业技术团队较弱,需要低代码/无代码开发
- 预算有限,需要快速验证AI应用场景
- 业务需求涉及多模态交互(文本、图片等)
- 对文档解析深度要求不高
实际应用效果对比
| 场景 | RAGFlow效果 | Dify效果 | 提升幅度 |
|---|---|---|---|
| 法律合同审查 | 准确率95%+,关键条款提取精准 | 准确率约70%,关键信息遗漏较多 | +25%+ |
| 医疗报告分析 | 专业术语识别准确率高,可追溯 | 专业术语识别能力有限 | +30%+ |
| 金融研报解析 | 金融数据提取准确率高30% | 基础数据提取,准确率一般 | +30% |
| 智能客服 | 专业问题解答正确率高 | 常规问题解答效果好 | 75% vs 95% |
| 电商平台客服 | 响应速度提升40%,满意度提高30% | 响应速度中等,满意度一般 | 40%+ |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)