ROLL Flash:加速RLVR和Agent训练!
ROLL Flash: 本文提出的核心系统,它通过引入异步(Asynchrony)架构来增强原有的 ROLL 框架。其设计旨在通过解耦和并行化来加速强化学习价值对齐(RLVR)和智能体(Agent)训练。Rollout-训练解耦 (Rollout–Train Decoupling): ROLL Flash 的核心设计原则之一。它将 rollout 阶段(数据生成)和训练阶段(模型更新)部署在不同的
Part II: ROLL Flash – Accelerating RLVR and Agentic Training with Asynchrony
- ArXiv URL: http://arxiv.org/abs/2510.11345v1
TL;DR
本文提出了 ROLL Flash,一个通过引入异步机制来解耦 rollout 和训练阶段的系统,从而显著提升了强化学习后训练(RL Post-Training)的吞吐量和资源可扩展性,同时通过精细化的陈旧度控制确保了模型的最终性能。
关键定义
- ROLL Flash: 本文提出的核心系统,它通过引入异步(Asynchrony)架构来增强原有的 ROLL 框架。其设计旨在通过解耦和并行化来加速强化学习价值对齐(RLVR)和智能体(Agent)训练。
- Rollout-训练解耦 (Rollout–Train Decoupling): ROLL Flash 的核心设计原则之一。它将 rollout 阶段(数据生成)和训练阶段(模型更新)部署在不同的计算资源上,使其能够并行执行。这消除了两个阶段间的同步等待,从而提升了资源利用率。
- 细粒度并行 (Fine-Grained Parallelism): ROLL Flash 的另一核心设计原则。它在 rollout 阶段内部实现了样本级别的生命周期控制,允许 LLM 生成、环境交互和奖励计算等子任务重叠执行,进一步减少了因长尾任务造成的 GPU 空闲时间。
- 异步率 (Asynchronous Ratio, α \alpha α): 一个关键超参数,用于控制异步训练中的样本陈旧度。它定义了生成某个样本的策略版本与当前策略版本之间允许的最大差距。通过限制每个样本的陈-旧度,该机制在提升系统吞吐量的同时,防止了因使用过度陈旧数据而导致的训练不稳定或性能下降。
相关工作
当前,在数学、代码生成和工具使用等领域,强化学习(RL)已成为提升大语言模型(LLM)能力的关键后训练技术。标准的强化学习后训练流程包含 rollout(生成响应和奖励)和 training(更新模型权重)两个阶段。
然而,现有的同步训练系统面临两大瓶颈:
- 资源利用率低下:Rollout 阶段通常占据超过70%的总训练时间。由于不同 prompt 生成的响应长度差异巨大,呈现出“长尾分布”特性,同步机制(如等待一个批次中所有响应都生成完毕)会导致大量 GPU 资源因等待最长的响应而处于空闲状态。
- 可扩展性差:LLM 的自回归解码过程主要受内存带宽限制,增加 GPU 数量并不能显著加快单个响应的生成速度。此外,rollout 和 training 阶段间的同步屏障意味着,即使增加 GPU 加速了训练阶段,整体端到端的加速效果也十分有限。
因此,异步训练需要专门的离策略(off-policy)算法来修正。这些算法主要分为两类:
- 重要性采样(Importance-Sampling, IS)截断:对 IS 比率超出信任区间的样本,直接截断其梯度。例如 Decoupled PPO。
- 重要性采样权重裁剪:保留所有样本的梯度,但裁剪其 IS 权重以稳定训练。代表算法有 TIS、CISPO 和 TOPR。
本文旨在设计一个兼具高性能和高可扩展性的异步训练系统(ROLL Flash),并通过系统的设计和算法的结合,解决同步训练的效率瓶颈,同时有效控制异步训练带来的策略陈旧度问题。
本文方法
本文提出了 ROLL Flash 系统,它基于两大设计原则实现了高效且稳定的异步后训练:rollout-训练解耦 和 细粒度并行。
创新点
ROLL Flash 的核心创新在于其系统架构设计,它不仅实现了阶段间的异步,还实现了阶段内的细粒度并行。
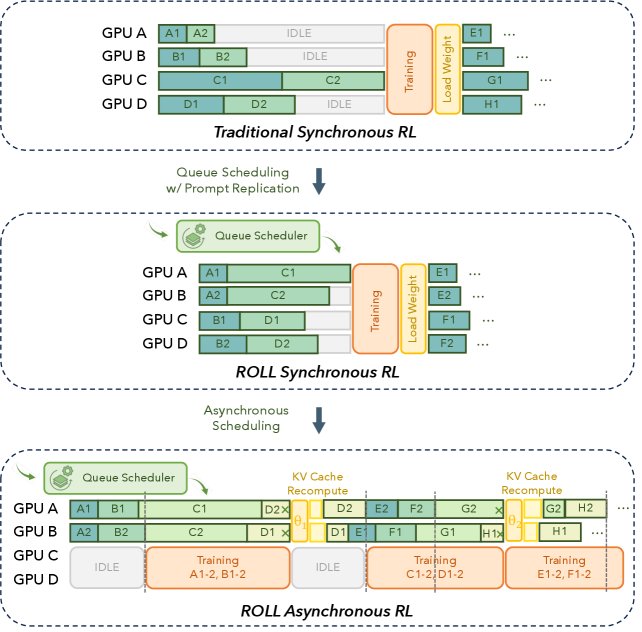
1. Rollout-训练解耦架构
ROLL Flash 将 rollout 和 training 两个阶段部署在用户指定的、可以独立的计算资源上,使它们成为一个流水线并行执行的系统。Rollout 进程作为“生产者”,持续生成训练数据并放入共享队列;Training 进程作为“消费者”,从队列中获取数据进行模型更新。这种生产者-消费者模式彻底消除了 rollout 阶段对训练完成的等待,从而最大化了资源利用率,尤其能够有效缓解长尾 rollout 造成的性能瓶颈。
2. 细粒度并行机制
在 rollout 阶段内部,ROLL Flash 实现了样本级别的生命周期管理。这意味着,LLM 的生成、与环境的交互、奖励的计算等步骤可以在不同样本间重叠进行。例如,当一个样本正在进行环境交互时,系统可以利用空闲的 GPU 资源为另一个新样本进行 LLM 推理。这一设计通过队列调度(Queue Scheduling)和提示复制(Prompt Replication)等具体技术实现,进一步压榨了 GPU 的空闲时间。
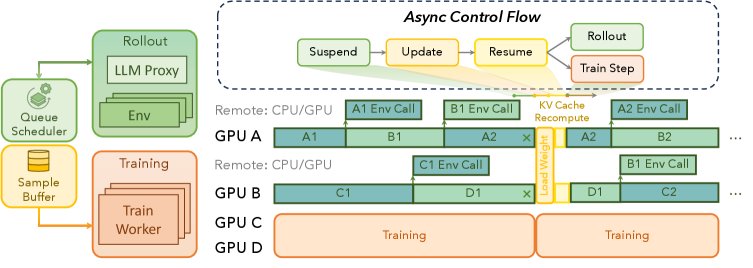
ROLL Flash 通过 InferenceHub Proxy、Environment Agent 和 RolloutLoop 等核心组件来协同工作,实现上述设计。
- InferenceHub Proxy:作为推理引擎(如 vLLM)的协调器,它管理着一个 GPU 工作者集群,并以非阻塞的事件循环方式处理来自不同客户端的推理请求,最大化 GPU 利用率。
- Environment Agent:作为基本的执行单元,每个智能体在一个独立的事件循环中与环境进行交互。它从
InferenceHub获取模型生成的动作,执行后将观察结果返回,循环往复直至任务结束。 - RolloutLoop: 负责管理整个异步训练流程。它维护一个
Environment Agent池作为数据生产者,并将生成的数据(轨迹)放入一个共享队列。训练进程则从该队列中消费数据。
异步率( α \alpha α)控制
为了解决异步带来的策略陈旧度问题,ROLL Flash 引入了异步率 $\alpha$。与以往工作在批次级别控制平均新鲜度不同,ROLL Flash 对每个样本进行新鲜度控制。它确保用于训练的任何一个样本,其生成时所用的策略版本与当前训练的策略版本之差不超过 $\alpha$。如果一个样本的策略版本超过了这个阈值,它将被丢弃或重新生成。这种精细化的控制机制在保证高吞吐量的同时,为训练的稳定性提供了坚实保障。
实验结论
本文通过在 LLAMA2-70B 和 Mixtral-8x22B 等模型上的大量实验,从资源可扩展性、资源利用率、异步率影响和训练稳定性四个维度验证了 ROLL Flash 的有效性。
-
可扩展性与吞吐量显著提升:
- ROLL Flash 的异步架构表现出近线性的吞吐量扩展能力。在128个GPU上,其吞吐量比传统的同步基线高出 2.12倍。
- 在平均序列长度较短、长尾效应更显著的场景下,同步方法的扩展性很差,而异步方法依然能有效扩展,吞吐量比同步方法高 1.53至2.24倍。这证明了异步架构在缓解长尾问题上的巨大优势。
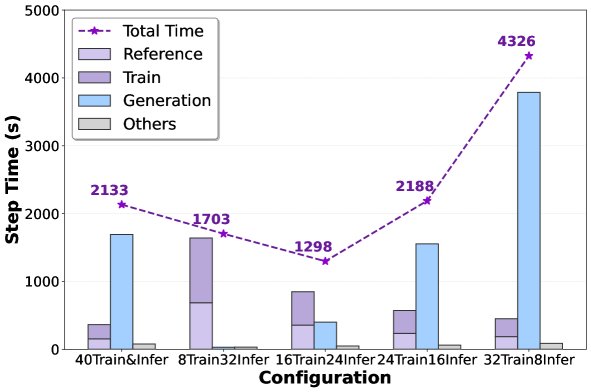
- 实验表明,在固定的 GPU 预算下,通过调整分配给训练和推理的资源比例,可以找到最优配置。在40个GPU的实验中,合理的配置(如24个用于推理,16个用于训练)相比基线可实现近 2倍 的加速。
-
小异步率即足够:
- 一个令人惊讶的发现是,通常一个很小的异步率(
$\alpha$),例如 2,就足以实现接近最大的性能加速,同时保证了样本的新鲜度。这表明在实践中,我们可以在不牺牲过多样本新鲜度的前提下,获得异步带来的大部分好处。
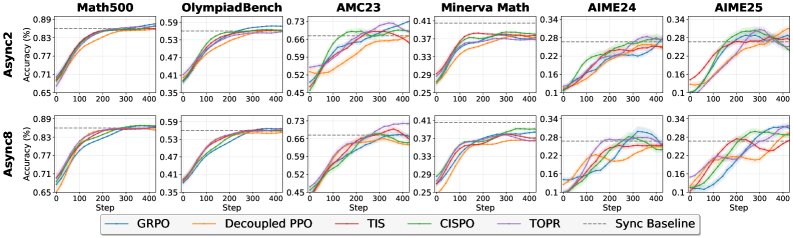
- 通过与多种主流的离策略(off-policy)优化算法(如 TIS, CISPO, TOPR)结合,异步训练能够有效补偿策略陈旧度带来的负面影响。
- 实验结果显示,异步训练最终达到的模型性能与严格的同步训练相当,甚至在某些指标上略有超出。这证明了“高吞吐量”和“高模型保真度”可以兼得。
- 一个令人惊讶的发现是,通常一个很小的异步率(
最后,在更复杂的智能体任务上,异步 rollout 策略同样表现出色,在 ALFWorld 数据集上取得了 2.72倍 的加速,在 SWE 数据集上取得了 1.81倍 的加速。
总结:全面的实验结果有力地证明了 ROLL Flash 作为一个异步 RL 后训练框架,在各种模型和任务上都能实现显著的效率和可扩展性提升,且不会损害最终的模型性能。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 14
14 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)