代码搜索的终极较量:SWE-grep 如何用4轮并行搜索击败传统方案?
经过深入调研和思考,我对 SWE-grep 有了更全面的认识。SWE-grep 不是要替代 grep 或 RAG,而是在速度和智能之间找到了一个新的平衡点。它解决的核心问题是:通过专用模型和并行搜索达到速度与智能的权衡(接近前沿模型的质量 + 快 10 倍的速度);通过子 Agent 架构实现上下文窗口的经济性(避免中间结果污染主 Agent 的上下文);把搜索时间从分钟级降低到秒级带来流畅感的用

最近 Cognition AI 推出了 SWE-grep 和 SWE-grep-mini,宣称它们能以"一个数量级"的速度提升完成代码搜索任务,同时保持与前沿模型相当的检索能力。听起来很厉害,但这个技术到底解决了什么真实问题?它和传统的 grep、流行的 RAG 方案有什么本质区别?
一、先搞清楚一个问题:代码搜索为什么重要?
在讨论 SWE-grep 之前,我们需要理解一个基本事实:** AI 编程工具和人一样,花费大量时间在"找代码"而不是"写代码"**。
Cognition AI 团队观察到,在 Windsurf 和 Devin 的 Agent 轨迹中,超过 60% 的首轮时间都花在了检索上下文上。想象一下:你让 AI 帮你修复一个 bug,它可能要花 2 分钟翻遍代码库找相关文件,然后才开始真正的修改工作。
这个问题在复杂项目中更加突出。一个典型的场景是:
- 用户说:“帮我把支付流程改成异步处理”
- AI 需要找到:支付入口、订单创建逻辑、事务处理代码、错误处理机制、相关测试文件
- 这可能涉及跨越 10+ 个文件、数千行代码的搜索
代码搜索的质量直接决定了 AI 能否正确理解任务、准确修改代码。 搜索不准,后面的一切都是空中楼阁。
二、三种技术路线:grep、RAG 和 SWE-grep
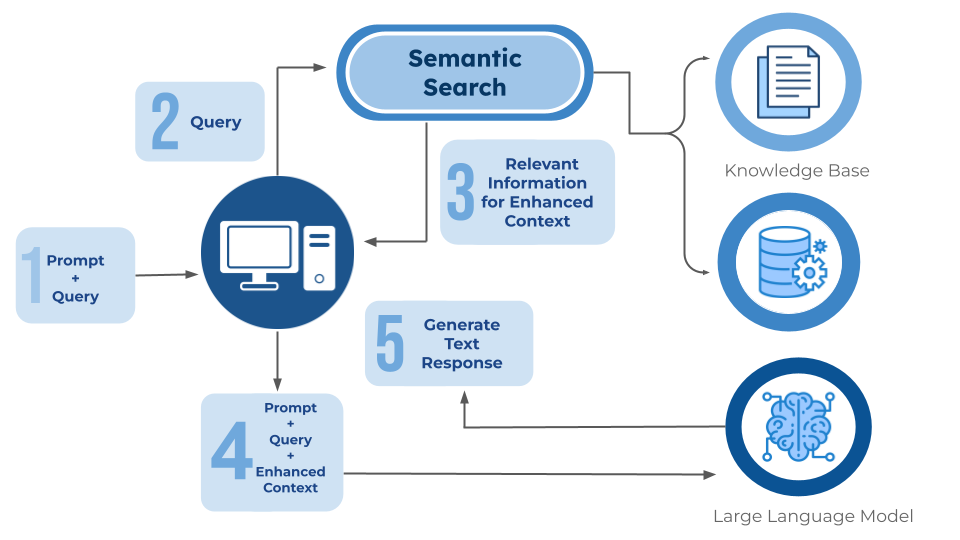
要理解 SWE-grep 的价值,我们需要先看看现有的两种主流方案。
传统 grep:50 年前的经典工具
grep 诞生于 1973 年,是 Unix 工具箱里的瑞士军刀。它的工作方式极其简单:
原理: 字面匹配。给它一个关键词或正则表达式,它逐行扫描文件,返回匹配的行。
grep -r "processPayment" ./src
grep 的优势在于零维护成本——不需要索引,代码随改随搜,只要关键词对结果就 100% 精确,而且你完全知道它在做什么,调试起来非常简单,直接扫描文件系统也带来了极快的速度。
但问题也很明显:你必须提供精确的关键词,搜"login"找不到"authenticate",搜"用户认证"找不到"sign-in";一次搜索可能返回几十个文件、上千行代码,大部分都不相关;它把注释、测试、文档、实际代码同等对待,也不知道函数调用关系、不理解代码依赖。
Claude Code 和 Cursor 早期版本选择了 grep 路线。Anthropic 团队在博客中提到,他们测试了多种方案后,发现 grep 在 SWE-Bench 任务上"性能大幅超越其他方案"。
为什么?因为 Agent 的持久性可以弥补工具的简陋性。Agent 会尝试不同的关键词、调整搜索策略、多次迭代,最终找到需要的代码。
RAG:语义搜索的智能方案
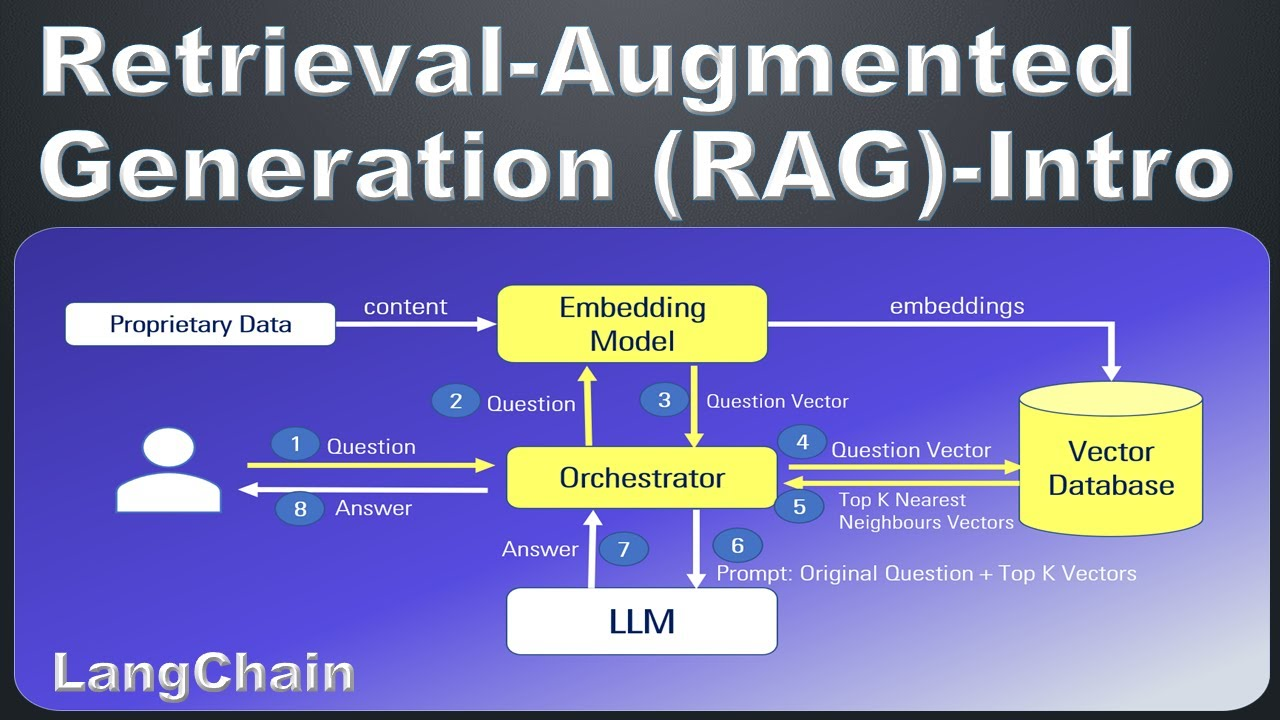
RAG(Retrieval-Augmented Generation)是大语言模型时代的明星架构。
原理:
- 离线阶段 - 把代码切块,用 embedding 模型转换成向量,存入向量数据库(如 Qdrant、Milvus)
- 在线阶段 - 把用户查询向量化,在向量库中找最相似的 Top-K 代码块
- 返回结果 - 按相似度排序,返回最相关的代码
RAG 的优势在于语义泛化能力——搜"异步处理"能找到 Promise、async/await、回调函数等相关代码,向量距离天然提供相关性分数实现自动排序,你也不需要记住精确的函数名。
但它也有明显的短板:代码改动后需要重新 embedding 和更新索引,大项目常出现"搜到旧代码"的尴尬;embedding 模型对变量名、缩写、业务语境不敏感,容易返回"语义像但业务无关"的代码;需要管理向量库、分块策略、增量同步,运维成本较高;更糟糕的是可能返回大量"看起来相关"但实际无用的代码,干扰 LLM 判断。
Cursor 新版本采用了 RAG 方案,使用 Merkle 树做增量索引。但用户仍然抱怨索引延迟和准确性问题。
两种方案的本质区别
- grep = “精确但笨”,适合小项目或关键词明确的场景
- RAG = “聪明但慢”,适合文档、知识库或需要语义理解的场景
- SWE-grep = “速度与智能的平衡”,适合中大型项目的快速交互场景
那么问题来了:能否结合两者的优点——既有 grep 的速度和精确性,又有 RAG 的智能和灵活性?
这就是 SWE-grep 要解决的问题。
三、SWE-grep:Agent 化的代码搜索
SWE-grep 不是一个简单的搜索工具,而是一个 专门训练用于代码搜索的 Agent 模型。
核心设计:高度并行的多轮搜索
传统 Agent:串行搜索(10-20 轮)
每一轮都有巨大的延迟成本:网络往返、工具调用开销、模型推理时间。
SWE-grep:并行搜索(4 轮)
SWE-grep 的创新在于:用 4 轮高度并行的搜索,替代 10-20 轮串行搜索。
每一轮,SWE-grep 会并行执行 8 个工具调用,同时搜索不同的关键词、读取不同的文件、探索不同的目录,使用的都是 grep、read、glob 等安全工具以确保跨平台兼容,并根据上一轮的结果动态调整下一轮的搜索方向。
举个例子,当用户说"修改支付流程为异步处理"时:
第 1 轮(并行 8 个操作):
- 搜索 “payment” → 找到 payment.js、paymentService.js
- 搜索 “process” → 找到 orderProcessor.js
- 搜索 “async” → 找到已有的异步处理示例
- 读取 package.json → 了解项目依赖
- glob 搜索 “/payment/.js” → 找到支付模块的所有文件
- 搜索 “transaction” → 找到事务处理逻辑
- 搜索 “callback” → 找到回调函数
- 搜索 “Promise” → 找到现有的 Promise 使用
第 2 轮(基于第 1 轮结果):
- 读取 payment.js 的关键函数
- 搜索 payment.js 中提到的其他函数
- 查找调用 paymentService 的地方
- …
总共只需要 4 轮,就能完成传统 Agent 需要 15-20 轮才能完成的搜索。
训练方法:强化学习 + 蒸馏
SWE-grep 的训练过程很有意思:Cognition AI 使用内部的真实代码库、用户查询和标注的"正确答案"(哪些文件和行号是相关的)构建数据集,然后定义加权 F1 分数作为奖励函数(精确率比召回率更重要,β=0.5),通过强化学习让模型学会如何高效地使用并行工具调用,最后把 SWE-grep 的能力蒸馏到 SWE-grep-mini,再进行额外的强化学习。
为什么精确率比召回率更重要?
因为 Cognition AI 发现,上下文污染比信息缺失更致命。给主 Agent 塞入大量无关代码,会严重干扰它的判断。而如果遗漏了一些代码,Agent 可以在后续的搜索中补充。
这个设计哲学和 Claude Skills 的"渐进式披露"如出一辙——先给少量高质量信息,需要时再补充,而不是一次性塞入所有可能相关的内容。
性能:速度与质量的平衡
根据 Cognition AI 的评测:
根据 Cognition AI 的评测,速度方面 SWE-grep-mini 达到 2800+ tokens/秒(部署在 Cerebras 上),SWE-grep 达到 650+ tokens/秒,而 Claude Haiku 4.5 只有 140 tokens/秒——SWE-grep-mini 比 Haiku 快 20 倍,SWE-grep 快 4.5 倍。质量方面,在 Cognition CodeSearch Eval 数据集上,SWE-grep 和 SWE-grep-mini 的加权 F1 分数与 Sonnet 4.5 相当,但端到端延迟降低了一个数量级。在 SWE-Bench Verified 的随机子集上,使用 Fast Context(SWE-grep)的 Cascade Agent 能在显著更短的时间内完成相同数量的任务。
四、SWE-grep 和传统 grep、RAG 的本质区别
现在我们可以回答开头的问题了。
SWE-grep vs grep
两者的相同点在于都基于精确的关键词搜索、都不需要预建索引、都能保证搜索结果的确定性。
但核心区别很明显:在决策层面,grep 需要人工指定关键词、一次搜索一个,而 SWE-grep 由 AI 自动生成多个搜索策略并行执行;在结果处理上,grep 返回所有匹配行需要人工筛选,SWE-grep 则智能过滤只返回高相关性的代码片段;在搜索方式上,grep 是单次搜索结果孤立,SWE-grep 是多轮迭代每轮基于上轮结果调整策略。
类比: grep 像一个搜索引擎,你需要自己想关键词、自己翻页、自己判断哪个结果有用。SWE-grep 像一个研究助理,你告诉它任务,它会自动尝试多种搜索策略,过滤无关结果,最后给你一份整理好的报告。
SWE-grep vs RAG
两者都试图提供"智能"的代码检索、都能处理语义层面的查询,但核心区别在于:RAG 基于向量相似度需要预建索引,SWE-grep 基于关键词匹配实时搜索;RAG 的智能来自 embedding 模型对语义的理解,SWE-grep 的智能来自 Agent 的搜索策略和迭代能力;RAG 的索引更新有延迟可能搜到旧代码,SWE-grep 每次都搜索最新代码;RAG 的向量搜索结果难以预测和调试,SWE-grep 基于关键词搜索过程可解释。
类比: RAG 像图书馆的智能推荐系统——它会根据你的需求,推荐"可能相关"的书籍,但有时候推荐不准。SWE-grep 像一个熟悉图书馆的向导——它知道如何快速找到你需要的书,即使你描述得不够精确,它也能通过多次尝试找到正确的位置。
五、为什么 Augment 说"grep 击败了 embeddings"?
这里有一个有趣的故事。Augment 团队在构建 SWE-Bench Agent 时,最初预期 embedding-based 检索会是关键。但实际测试后发现,grep 和 find 就足够了。Colin Flaherty(Augment 创始工程师)在访谈中解释了原因:首先,Agent 的持久性弥补了工具的局限——传统搜索工具需要"一次搜对",而 Agent 可以尝试不同的关键词、根据结果调整策略、多次迭代直到找到正确答案;其次,SWE-Bench 的测试仓库通常只有几万行代码,grep 的性能完全够用(在真实的大型项目中 embedding 的价值会更明显);第三,调试 Agent 时确定性比智能更重要,grep 的行为完全可预测,搜索失败只有一个原因:关键词不对,而 embedding 搜索失败的原因可能是模型质量、向量相似度阈值、分块策略、索引过期等;最后,与其优化检索工具的智能程度,不如把智能放在 Agent 层,Agent 可以持续改进搜索策略而不需要重新训练 embedding 模型或重建索引。
但 Colin 也强调了 embedding 在大型代码库(10 万行以上)、非结构化内容(文档、Slack 消息)、第三方代码(模型没有记忆)、非文本媒体(视频、图片)等场景下的价值。他的建议是:不要抛弃现有的检索系统,而是把它们作为工具暴露给 Agent,这样可以在不同场景下灵活选择最合适的工具。
六、SWE-grep 真正解决的三个问题
我认为 SWE-grep 主要解决了三个问题。
1. 速度与智能的权衡
问题: 前沿模型智能但慢,简单工具快但笨。
SWE-grep 的方案: 训练一个专门的小模型只做代码搜索这一件事,通过高度并行的工具调用减少串行轮次、受限的工具集减少决策复杂度、极快的推理速度(Cerebras 部署),达到"接近前沿模型的质量 + 快 10 倍的速度"。
类比: 就像专业运动员。一个全能运动员(GPT-4)什么都会,但在每个单项上不如专项运动员(SWE-grep)。SWE-grep 就是代码搜索的"短跑冠军"。
2. 上下文窗口的经济性
问题: 传统 Agent 搜索会产生大量中间结果,占用宝贵的上下文窗口。
举个例子:
- 主 Agent(Sonnet 4.5)的上下文窗口:200K tokens
- 传统方案:10 轮搜索累积 20K tokens 的噪音
- SWE-grep 方案:只返回 500 tokens 的精准结果
SWE-grep 的方案: 作为子 Agent 运行并拥有自己的上下文窗口,只把最终的高质量结果(文件路径 + 行号范围)返回给主 Agent,所有中间搜索过程不占用主 Agent 的上下文。这样主 Agent 可以把宝贵的上下文窗口用在真正重要的事情上——理解需求、规划修改、生成代码。
3. "流畅感"的用户体验
问题: 用户等待 AI 响应时,每多一秒,打断"心流"的概率就增加 10%。
Cognition AI 团队提出了一个"流畅窗口"概念:5 秒。超过 5 秒,用户就会感到明显的等待,心流被打断。
SWE-grep 的方案: 把代码搜索从"分钟级"降低到"秒级",让用户感觉 AI 是在"思考"而不是"卡住了"。这不是技术指标的优化,而是产品体验的质变。
想象两种场景:
- 场景 A:你问"修改支付流程",等了 2 分钟,AI 开始改代码
- 场景 B:你问"修改支付流程",5 秒后,AI 开始改代码
场景 B 让你保持专注,场景 A 让你打开微信刷朋友圈。
七、SWE-grep 的局限性
说完优点,我们也要看到局限。
1. 仍然依赖关键词
SWE-grep 本质上还是基于 grep 的关键词搜索。如果用户的描述和代码中的命名差异很大(比如用户说"登录",代码里叫"authenticate"),SWE-grep 需要多轮尝试才能找到。而 RAG 可以通过语义理解,一次就找到相关代码。
2. 大型代码库的挑战
Cognition AI 的评测主要基于 SWE-Bench,其代码库规模相对较小(几万行)。在几十万、上百万行的大型项目中,grep 的性能可能成为瓶颈。
这时候,预建索引的价值就体现出来了——即使索引有延迟,也比每次都扫描整个代码库要快。
3. 成本问题
虽然 SWE-grep 比主模型快,但仍然是 LLM 推理。在高频使用场景下,成本可能不如一次性建立索引、然后快速查询的 RAG 方案。
Augment 的 ACE 方案(结合 grep 和 embedding)可能是更经济的选择:用 embedding 做粗召回,用 grep 做精确匹配,用小模型做精排。
4. 专用模型的维护
SWE-grep 是一个专门训练的模型,需要持续维护和更新。相比之下,grep 是一个成熟的开源工具,RAG 可以使用通用的 embedding 模型。
八、三种方案的适用场景
经过对比,我们可以总结出三种方案的最佳适用场景:
grep(传统关键词搜索)
适合:
- 小型项目(< 1 万行代码)
- 关键词明确的搜索
- 需要绝对确定性的场景
- 重视隐私和本地运行
- 零配置、零维护的需求
代表产品: Claude Code、早期 Cursor
哲学: 简单、可预测、可组合
RAG(向量语义搜索)
适合:
- 大型代码库(> 10 万行代码)
- 语义理解重要的场景
- 搜索文档、注释、自然语言
- 探索性编程(不确定具体要找什么)
- 可以接受索引延迟
代表产品: Cursor 新版、GitHub Copilot
哲学: 智能、语义化、需要基础设施
SWE-grep(Agent 化搜索)
适合:
- 中大型项目(1-50 万行代码)
- 需要快速响应的交互场景
- 复杂的多步骤搜索任务
- 重视用户体验(流畅感)
- 愿意为速度付费
代表产品: Windsurf Fast Context
哲学: 速度与智能的平衡、专用模型
九、SWE-grep 对 AI 编程的启示
SWE-grep 的出现,让我们重新思考 AI 编程工具的设计。
1. 子 Agent 架构的价值
不是所有任务都需要最强大的模型。通过训练专用的子 Agent,可以降低主 Agent 的负担、提升特定任务的性能、降低整体成本。这和 Claude Skills 的思路一脉相承——把复杂任务分解,让专业的模块做专业的事。
2. 速度是第一性原理
在 AI 编程工具中,速度不是锦上添花,而是决定用户体验的核心因素。
5 秒和 30 秒的差别,不是 6 倍的性能提升,而是"保持心流"和"打断工作"的质变。
这也是为什么 Cognition AI 愿意投入资源训练专用模型、优化工具调用、选择最快的推理平台(Cerebras)。
3. 工具的智能化
传统观点认为,工具应该是"哑"的,智能应该在 Agent 层。但 SWE-grep 展示了另一种可能:把工具本身变成一个智能 Agent。
这种"智能工具"能够理解任务的语义、自动选择搜索策略、过滤无关结果、迭代优化。未来可能会出现更多这样的智能工具——不是被动等待调用,而是主动理解任务、优化执行。
4. 没有银弹
grep、RAG、SWE-grep 都不是万能的。最好的方案是在正确的场景使用正确的工具、把多种工具暴露给 Agent 让它选择、根据项目规模用户需求成本预算灵活调整。Augment 的 ACE 方案就是这个思路——结合 grep 的精确性、embedding 的语义理解、小模型的精排能力。
十、总结
经过深入调研和思考,我对 SWE-grep 有了更全面的认识。
SWE-grep 不是要替代 grep 或 RAG,而是在速度和智能之间找到了一个新的平衡点。
它解决的核心问题是:通过专用模型和并行搜索达到速度与智能的权衡(接近前沿模型的质量 + 快 10 倍的速度);通过子 Agent 架构实现上下文窗口的经济性(避免中间结果污染主 Agent 的上下文);把搜索时间从分钟级降低到秒级带来流畅感的用户体验(让用户保持心流)。和传统方案的区别在于:相比 grep 不是简单的关键词搜索而是 AI 驱动的多策略并行搜索,相比 RAG 不依赖预建索引保证实时性和确定性且智能来自 Agent 而非 embedding。局限性包括仍然依赖关键词语义理解不如 RAG、大型代码库的性能有待验证、专用模型的维护成本较高。适用场景是中大型项目(1-50 万行代码)、需要快速响应的交互场景、重视用户体验(流畅感)、愿意为速度付费的团队。
更深层的启示:
SWE-grep 让我们重新思考"什么是好的 AI 编程工具"。答案不是"功能最全"、“模型最大”、“索引最智能”,而是在用户最需要的地方做到极致(速度)、把复杂任务分解给专业模块(子 Agent)、在不同场景灵活选择工具(没有银弹)。这和 Unix 哲学如出一辙:做好一件事,做到极致,然后和其他工具组合。
未来,我们可能会看到更多这样的专用 Agent——不是通用的"什么都能做",而是在特定领域"做到最好"。
技术没有绝对的好坏,只有是否适合你的问题。 希望这篇文章能帮助你更好地理解代码搜索的技术演进,做出更明智的选择。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 4
4 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)