炸串,瑞士卷与Score-Matching如何更简单
比如你的图像是256x256的,那么trace的长度就是256,问题是在于back propagation的过程中,我们得算所有x的,x1,,,,xn对于f1,f2,,,,,fn,因为算法底层是遍历所有的x的计算图,你不能只算main diagonal的,那么这个计算开销是不行的,如果你的参数是上百万的,会非常非常慢。那么山脚下的p(x)的值是很小的,可能是半个鱼豆腐?Pascal是这么说的,x~
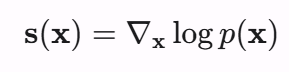
对于一个Probability Density function(PDF)在某一点x的gradient而言,我们称之为score,score是可以描述一种东西的distribution的,比如所有炸鱼豆腐的distribution,你可以吃到不同调味不同形状的鱼豆腐。

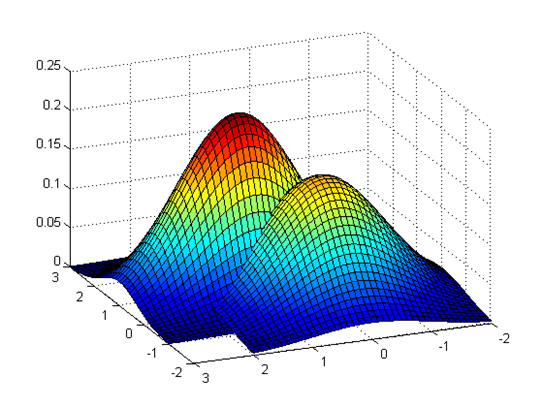
观察上述假设的炸鱼豆腐的分布,山顶的概率p(x)是最大的,那么美味的鱼豆腐应该在这里取到。那么山脚下的p(x)的值是很小的,可能是半个鱼豆腐???也可能什么都不是。可能是鱼豆腐的调味料。
如果想吃到美味的炸鱼豆腐肯定是要往山顶走,那就是正梯度。
但是你绝对不可能知道p(x)的表达式,世界上鱼豆腐的分布绝对是一个非常高维的PDF,你能有的也就是一张张鱼豆腐的图片而已。
聪明的你想到了用一个模型sθ去学习这个这个鱼豆腐的分布做损失。
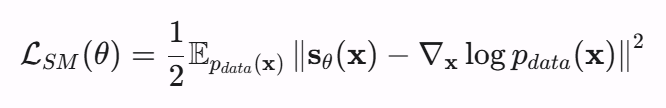
但是你发现没有,p(x)上面说过了是不知道的啊,你怎么减呢???????????
上面这个equation是可以做一些变形来消掉这个pdata的,你可以把L2范数写开,然后用high dimension integration by parts做变换,推导过程很长,这里不展开。
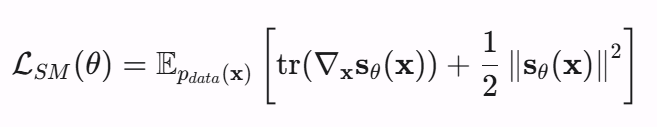
你只需要知道可以变换成上面这个equation,但是我们又引入了一个大麻烦,tr的意思是trace of Jacobian matrix, 也就是main diagonal of matrix。
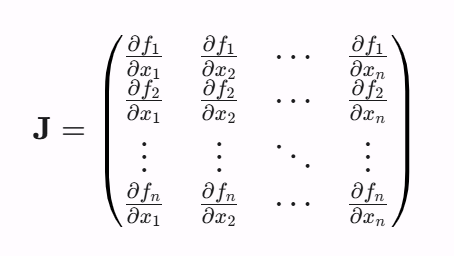
比如你的图像是256x256的,那么trace的长度就是256,问题是在于back propagation的过程中,我们得算所有x的,x1,,,,xn对于f1,f2,,,,,fn,因为算法底层是遍历所有的x的计算图,你不能只算main diagonal的,那么这个计算开销是不行的,如果你的参数是上百万的,会非常非常慢。
这也不行,那也不行,这不是没法吃上鱼豆腐了?
P. Vincent, "A Connection Between Score Matching and Denoising Autoencoders," in Neural Computation, vol. 23, no. 7, pp. 1661-1674, July 2011, doi: 10.1162/NECO_a_00142.
Pascal Vincent这个大佬在2021年7月published了一篇很重要的文章,但不知道为什么引用这么少。
Pascal是这么说的,x~是这个带人为noise的图像,x是原始图像,q是加noise的过程,σ就是noise的强度。
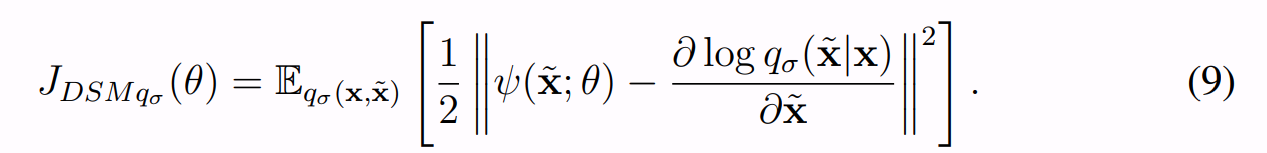
ψ就是上面提到的score model。
因为noise是人为加上去的Gaussian Noise,所以对于q我们是已知的
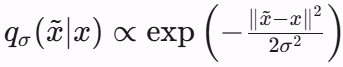
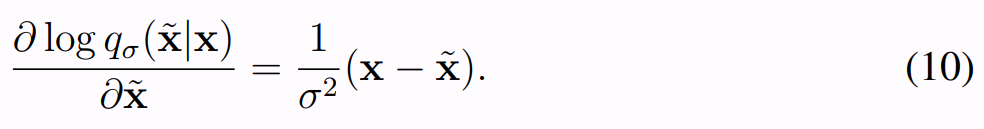
求导后如上述equation。本质上是σ权重的原始图像与corrupted图像的偏差bias,如果偏差接近0,那么模型就是最好的情况。这篇文章还有很长的推导过程,感兴趣的同学可以自行看,这里没必要全都放上来。
import torch
def anneal_dsm_score_estimation(scorenet, samples, sigmas, labels=None, anneal_power=2., hook=None):
if labels is None:
labels = torch.randint(0, len(sigmas), (samples.shape[0],), device=samples.device) # len=samples.shape[0], range from 0-len(sigmas) int
used_sigmas = sigmas[labels].view(samples.shape[0], *([1] * len(samples.shape[1:]))) # mean=0 sigma=arbitrary
noise = torch.randn_like(samples) * used_sigmas # gen a noise with mean=0 that shape same as samples
perturbed_samples = samples + noise # add noise to sample
target = - 1 / (used_sigmas ** 2) * noise # theoretical ground truth for scores
scores = scorenet(perturbed_samples, labels)
target = target.view(target.shape[0], -1)
scores = scores.view(scores.shape[0], -1)
loss = 1 / 2. * ((scores - target) ** 2).sum(dim=-1) * used_sigmas.squeeze() ** anneal_power
if hook is not None:
hook(loss, labels)
return loss.mean(dim=0)
实现过程的代码,来自Yang Song大佬的NCSN v2。
总结一下无非就还是Swiss Roll瑞士卷的问题。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)