Vibe Coding - Claude Code记忆系统深度解析:从上下文压缩到高效开发实践
AI记忆优化指南:让Claude Code更精准高效的秘诀 Claude Code的记忆系统采用四层架构(企业级→个人全局→项目级→目录级),优先级随范围缩小而提高。其三大记忆机制包括:200K tokens的短期对话窗口、自动触发的上下文压缩(92%时启动),以及唯一能跨会话保存的CLAUDE.md文件(需手动更新)。通过分层管理和三大技巧——用#键实时记录、规范会话始终流程、任务分会话处理——
文章目录

引言:为什么你的AI“记性差”?
你是否也经历过这样的场景?
- 跟Claude聊了半小时,它突然“失忆”,忘了你刚说的关键需求;
- 同一个问题问三遍,每次给出的方案都不一样;
- 前端页面不显示内容,AI反复“修复”却始终无效,最后你不得不手动截图、解释、重试……
很多人第一反应是:“这AI不行。”
但真相往往是:不是AI记性差,而是我们没教会它怎么记住。
本文将带你深入Claude Code的记忆系统,从底层机制到实战技巧,彻底解决上下文混乱、记忆丢失、输出不稳定三大痛点。
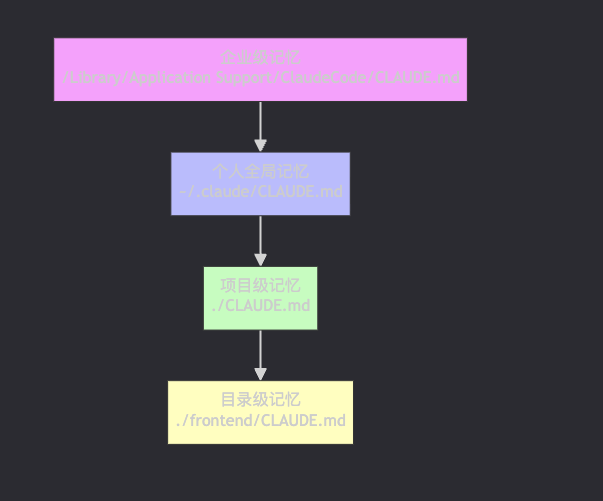
一、Claude Code记忆系统的四层架构
Claude Code并非“无脑记忆”,而是采用分层记忆模型,类似操作系统的存储层级(寄存器 → 缓存 → 内存 → 硬盘)。理解这四层,是高效使用的基础。
╔══════════════════════════════════════════════════════════════════════╗
║ Claude's Memory Loading Strategy ║
╚══════════════════════════════════════════════════════════════════════╝
~/.claude/
└── 📄 CLAUDE.md ← ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ┐
[global preferences] │ ALWAYS LOADED
│ (under home dir)
~/projects/awesome-app/ │
├── 📄 CLAUDE.md ← ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ┤
│ [project architecture, team rules] │
├── 📄 CLAUDE.local.md ← ─ ─ ─ ─ ─ ─ ─ ─ ┤ LOADED when working
│ [your sandbox URLs, local notes] │ anywhere in project
│ │
├── 📁 apps/ │
│ ├── 📁 web/ │
│ │ ├── 📄 CLAUDE.md ← ─ ─ ─ ─ ─ ─ ─ ┼ ─ ─ ┐
│ │ │ [React patterns, UI rules] │ │ ONLY when working
│ │ └── 📁 components/ │ │ in apps/web/**
│ │ └── 🔷 Button.tsx ← ─ ─ ─ ─ ─│─ ─ ─•
│ │ │
│ └── 📁 api/ │
│ ├── 📄 CLAUDE.md │ ← NOT loaded when
│ │ [API patterns, REST rules] │ working on Button.tsx
│ └── 📁 services/ │
│ │
├── 📁 infrastructure/ │
│ ├── 📄 CLAUDE.md │ ← NOT loaded when
│ │ [Terraform patterns, AWS] │ working on Button.tsx
│ └── 📁 modules/ │
│ │
└── 📁 docs/ │
└── 📄 architecture.md ← ─ ─ ─ ─ ─ ─ ┘
[@imported only when needed]
┌────────────────────────────────────────────────────────┐
│ When working on Button.tsx, Claude loads: │
│ │
│ ✓ ~/.claude/CLAUDE.md (global memory) │
│ ✓ ~/projects/awesome-app/CLAUDE.md │
│ ✓ ~/projects/awesome-app/CLAUDE.local.md │
│ ✓ ~/projects/awesome-app/apps/web/CLAUDE.md │
│ ✗ ~/projects/awesome-app/apps/api/CLAUDE.md │
│ ✗ ~/projects/awesome-app/infrastructure/CLAUDE.md │
└────────────────────────────────────────────────────────┘
1. 企业级记忆(最高优先级)
- 路径:
/Library/Application Support/ClaudeCode/CLAUDE.md - 适用场景:公司统一编码规范、安全策略、CI/CD流程
- 特点:由团队管理员维护,所有成员共享
2. 个人全局记忆
- 路径:
~/.claude/CLAUDE.md - 示例内容:
# 我的编码偏好 - 永远启用 TypeScript strict mode - 测试覆盖率不低于80% - 禁止在 commit message 中使用 emoji - 偏好函数式编程风格
3. 项目级记忆(最常用)
- 路径:项目根目录下的
CLAUDE.md - 包含技术栈、构建命令、环境变量等项目专属信息
4. 目录级记忆(精细化控制)
- 路径:如
./components/CLAUDE.md - 用于模块特定规则,例如React组件规范、API路由约定等
✅ 关键原则:越具体,优先级越高。目录级 > 项目级 > 个人级 > 企业级。
二、三大记忆机制详解
1. 短期记忆:200K tokens 的对话窗口
- 相当于人类的“工作记忆”
- 包含当前会话的所有输入输出
- 问题:一旦超过200K tokens,旧内容会被丢弃
- 建议:不要在一个会话中混杂多个任务
2. 中期记忆:自动上下文压缩(92%触发)
当token使用达到92%(约184K)时,Claude会自动执行压缩:
压缩的利与弊:
| 优势 | 劣势 |
|---|---|
| 节省token成本 | 可能丢失调试细节 |
| 清理噪音信息 | 需1-2分钟处理时间 |
| 帮助AI“重启思路” | 叙事线索断裂 |
💡 最佳实践:不要等自动压缩!在70%时主动执行
/compact。
3. 长期记忆:CLAUDE.md 文件(核心!)
这是唯一能跨会话持久化的记忆载体。
常见误解
“CLAUDE.md 会自动更新。”
真相
- 自动读取:每次启动时加载
- 手动更新:必须显式指令或手动编辑
为什么设计为手动?
- 防止临时讨论污染长期知识
- 用户完全掌控“什么值得记住”
- 便于Git版本控制
- 避免无关信息稀释核心知识
三、高效记忆管理实战技巧
技巧1:用 # 键实时记录关键信息
在聊天中随时输入:
# 使用 TypeScript strict mode
# API 限流:100次/分钟
# M1 Mac Docker 需加 --platform=linux/amd64
Claude会提示:“是否将此信息保存到 CLAUDE.md?”
立即确认,避免遗忘。
📌 真实案例:
前端页面不显示问题频发 → 添加提示:# 遇到前端页面展示问题,先用 playwright mcp 查看页面和 console 日志
此后无需截图,AI自动调用工具定位问题。
技巧2:会话开始与结束的“仪式感”
开始时:
/memory # 查看加载了哪些记忆文件
"简述项目当前状态"
"今天目标:实现JWT用户登录"
结束时:
"把认证流程记入 CLAUDE.md"
"记录CORS问题的解决方案"
"下次从 /api/auth 继续"
技巧3:分而治之——一个会话一件事
| 会话类型 | 内容 | 记忆文件 |
|---|---|---|
| 前端开发 | React组件、样式 | ./frontend/CLAUDE.md |
| 后端API | 路由、数据库 | ./backend/CLAUDE.md |
| Bug调试 | 错误日志、复现步骤 | 临时会话,结束后存档 |
四、高级技巧:榨干AI性能
1. 子代理分工(/agents)
创建专用角色提升专业性:
/agents
# code-reviewer.md:专注安全与性能
# test-engineer.md:生成边界测试用例
# doc-writer.md:维护API文档
2. MCP插件扩展能力
在 claude.config.json 中启用:
{
"mcpServers": {
"github": "自动PR审查",
"postgres": "直接查询数据库",
"playwright": "前端自动化测试"
}
}
例如:前端问题 → 自动调用
playwright截图并读取 console 错误。
3. 成本控制三原则
- 70%就压缩:
/compact - 详细规范外置:放在
docs/目录,按需引用 - 分离关注点:不同功能开独立会话
五、方法论本质:解决四大核心问题
所有AI编程方法论(PRP、6A、BMAD等)本质都在解决以下问题:
| 问题类型 | 症状 | Claude Code解法 |
|---|---|---|
| 上下文管理 | “AI总忘事” | 分层记忆 + 主动压缩 |
| 需求表达 | “输出偏离预期” | 具体指令 + 示例驱动 |
| 质量控制 | “代码风格不一” | CLAUDE.md 编码规范 |
| 协作效率 | “团队效果参差” | 共享记忆文件 + 标准化流程 |
🌟 关键洞察:
先吃透工具,再谈方法论。
只有理解Claude Code的记忆机制、token限制、MCP集成方式,才能设计出可落地的AI开发流程。
总结:让AI成为真正的开发搭档
Claude Code不是“魔法盒子”,而是一个需要精心调教的智能协作者。通过:
- 理解四层记忆架构
- 主动管理CLAUDE.md
- 70%原则控制上下文
- 分任务、给例子、用MCP
你就能将AI从“反复试错的累赘”转变为“高效可靠的搭档”。
AI洞见(《周易·系辞下》):
易穷则变,变则通,通则久。
技术在变,但解决问题的智慧不变。
善用工具,方能以简驭繁。
原文
Claude Code’s Memory: Working with AI in Large Codebases
https://www.toutiao.com/article/7552777850751943168/


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 21
21 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)