大模型开发 - 22 Multimodality API:多模态大模型与 Spring AI 的融合
凡自然相联之物,皆应结合教授。—— 约翰·阿摩司·夸美纽斯(John Amos Comenius),《世界图解》(Orbis Sensualium Pictus),1658 年这句话穿越近四个世纪,至今仍闪耀着教育与认知科学的智慧光芒。人类的学习与认知从来不是单一感官的孤立活动——我们通过视觉、听觉、语言、触觉等多种感官通道同时接收和整合信息,构建对世界的理解。然而,在人工智能的发展历程中,很长一
文章目录

Pre
大模型开发 - 03 QuickStart_借助DeepSeekChatModel实现Spring AI 集成 DeepSeek
大模型开发 - 04 QuickStart_DeepSeek 模型调用流程源码解析:从 Prompt 到远程请求
大模型开发 - 05 QuickStart_接入阿里百炼平台:Spring AI Alibaba 与 DashScope SDK
大模型开发 - 06 QuickStart_本地大模型私有化部署实战:Ollama + Spring AI 全栈指南
大模型开发 - 07 ChatClient:构建统一、优雅的大模型交互接口
大模型开发 - 08 ChatClient:构建智能对话应用的流畅 API
大模型开发 - 09 ChatClient:基于 Spring AI 的多平台多模型动态切换实战
大模型开发 - 10 ChatClient:Advisors API 构建可插拔、可组合的智能对话增强体系
大模型开发 - 11 ChatClient:Advisor 机制详解:拦截、增强与自定义 AI 对话流程
大模型开发 - 12 Prompt:Spring AI 中的提示(Prompt)系统详解_从基础概念到高级工程实践
大模型开发 - 13 Prompt:提示词工程实战指南_Spring AI 中的提示设计、模板化与最佳实践
大模型开发 - 14 Chat Memory:实现跨轮次对话上下文管理
大模型开发 - 15 Tool Calling :从入门到实战,一步步构建智能Agent系统
大模型开发 - 16 Chat Memory:借助 ChatMemory + PromptChatMemoryAdvisor轻松实现大模型多轮对话记忆
大模型开发 - 17 Structured Output Converter:结构化输出转换器_从文本到结构化数据的可靠桥梁
大模型开发 - 18 Chat Memory:集成 JdbcChatMemoryRepository 实现大模型多轮对话记忆
大模型开发 - 19 Chat Memory:集成 BaseRedisChatMemoryRepository实现大模型多轮对话记忆
大模型开发 - 20 Chat Memory:多层次记忆架构_突破大模型对话中的 Token 上限瓶颈
大模型开发 - 21 Structured Output Converter:结构化输出功能实战指南
概述
“凡自然相联之物,皆应结合教授。”
—— 约翰·阿摩司·夸美纽斯(John Amos Comenius),《世界图解》(Orbis Sensualium Pictus),1658 年
这句话穿越近四个世纪,至今仍闪耀着教育与认知科学的智慧光芒。人类的学习与认知从来不是单一感官的孤立活动——我们通过视觉、听觉、语言、触觉等多种感官通道同时接收和整合信息,构建对世界的理解。然而,在人工智能的发展历程中,很长一段时间内,机器学习模型却往往被设计为单模态专家:语音模型处理音频,计算机视觉模型识别图像,语言模型理解文本。这种“分而治之”的策略虽在特定任务上取得卓越成效,却与人类自然的认知方式相去甚远。
如今,这一局面正在被彻底改变。以 GPT-4o、Gemini 1.5、Claude 3、Llama 3.2、LLaVA、BakLLaVA 等为代表的多模态大语言模型(Multimodal Large Language Models, MLLMs) 正掀起新一轮 AI 革命。它们不仅能理解文本,还能同时“看”图像、“听”音频,甚至解析视频,并基于这些多源信息生成连贯、准确的文本回应。这种能力使得 AI 更接近人类的感知与推理方式,为智能应用开辟了前所未有的可能性。
在这一背景下,Spring AI —— Spring 官方推出的 AI 集成框架 —— 也紧跟时代步伐,提供了对多模态大模型的原生支持。本文将深入探讨 Spring AI 中的多模态能力,解析其设计原理,并通过代码示例展示如何在实际项目中轻松集成多模态 LLM。
什么是多模态(Multimodality)?
在 AI 领域,多模态指的是模型能够同时理解并处理来自不同数据源(模态)的信息,例如:
- 文本(Text):自然语言、指令、问题等;
- 图像(Image):照片、图表、截图等;
- 音频(Audio):语音、环境音、音乐等;
- 视频(Video):动态画面与声音的组合。
多模态模型的核心优势在于跨模态对齐与融合:它能将图像中的物体与文本描述关联,将语音内容转化为文字并理解其语义,甚至从视频中提取关键帧并生成摘要。这种能力使得 AI 能够处理更复杂、更贴近真实世界的任务,例如:
- 分析用户上传的医疗影像并生成诊断建议;
- 理解客服通话录音与聊天记录,提供综合服务;
- 根据产品图片和用户评论生成营销文案。
Spring AI 的多模态消息 API 设计
Spring AI 通过其 Message API 为多模态交互提供了清晰、一致的抽象。其核心思想是:用户输入(UserMessage)可以包含文本内容和一个或多个媒体附件,而模型的响应(AssistantMessage)目前仍以文本为主(非文本输出需调用专用单模态模型)。
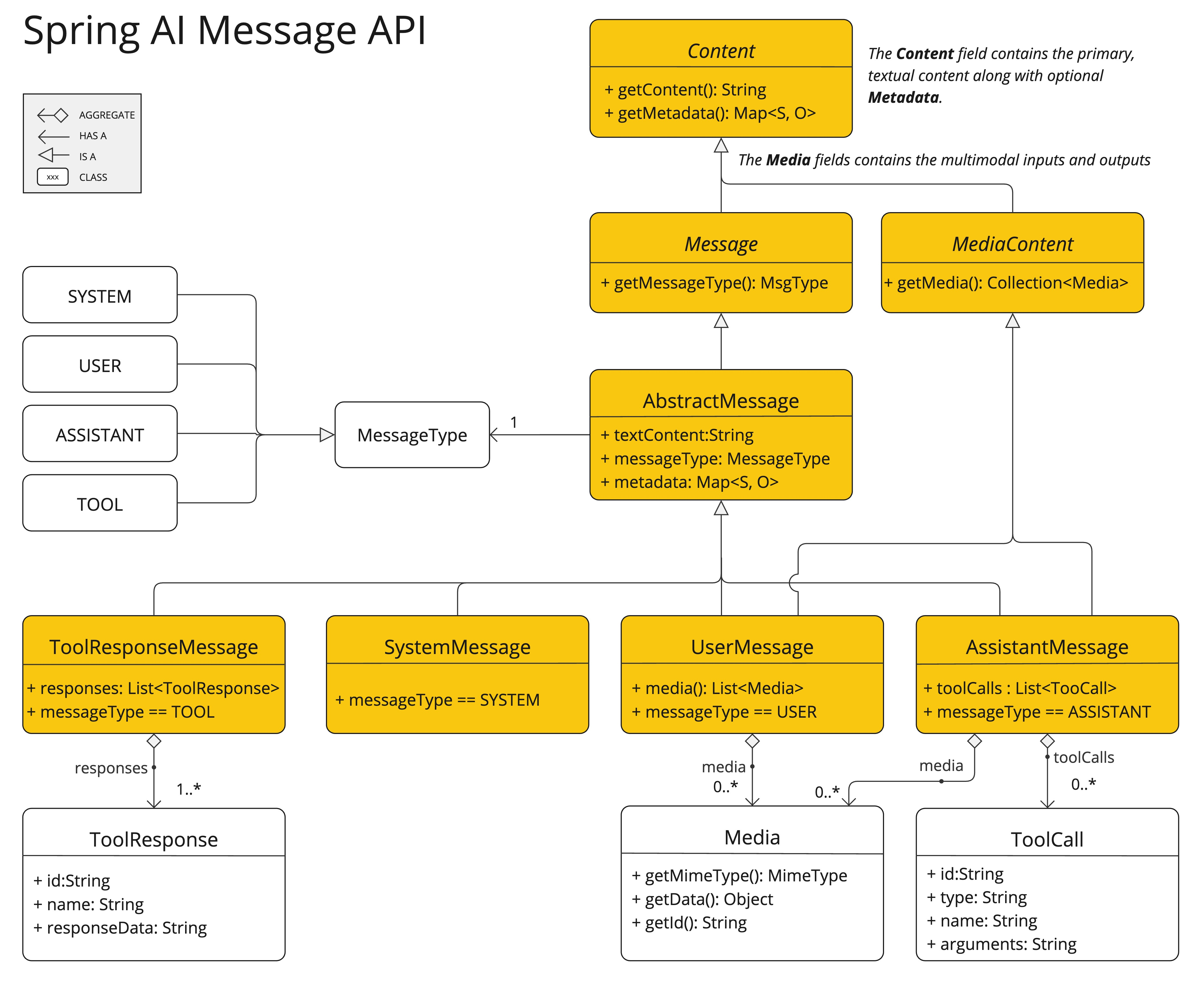
关键组件解析
-
UserMessage
代表用户发送给 LLM 的消息。它包含两个主要字段:text:主文本内容(必填);media:可选的媒体列表,用于附加图像、音频等。
-
Media类
封装单个媒体资源,包含:MimeType:指定媒体类型(如image/png、audio/mp3);data:媒体内容本身,可以是:org.springframework.core.io.Resource对象(如ClassPathResource、FileSystemResource);- 或一个 URI 字符串(如
https://example.com/image.jpg)。
-
MimeTypeUtils
Spring 提供的工具类,用于便捷创建标准 MIME 类型,例如:MimeTypeUtils.IMAGE_PNGMimeTypeUtils.AUDIO_MP3MimeTypeUtils.VIDEO_MP4
⚠️ 注意:目前多模态输入仅支持 UserMessage。SystemMessage 和 AssistantMessage 不支持媒体字段。若需生成图像、音频等非文本输出,应调用专门的生成模型(如 DALL·E、TTS 系统),而非依赖多模态 LLM 的文本响应。
实战示例:让 LLM “看图说话”
假设我们有一张名为 multimodal.test.png 的图片,内容是一个水果碗。我们希望 LLM 描述图中内容。

方式一:使用 ChatModel 直接调用
import org.springframework.ai.chat.messages.UserMessage;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.chat.model.ChatResponse;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.model.media.Media;
import org.springframework.core.io.ClassPathResource;
import org.springframework.http.MediaType;
// 加载图片资源(位于 src/main/resources/ 目录下)
var imageResource = new ClassPathResource("/multimodal.test.png");
// 构建包含文本和图像的用户消息
var userMessage = UserMessage.builder()
.text("Explain what do you see in this picture?") // 文本指令
.media(new Media(MediaType.IMAGE_PNG, imageResource)) // 附加 PNG 图像
.build();
// 调用多模态 LLM
ChatResponse response = chatModel.call(new Prompt(userMessage));
// 获取文本响应
String answer = response.getResult().getOutput().getContent();
System.out.println(answer);
方式二:使用 Fluent 风格的 ChatClient API(推荐)
Spring AI 提供了更简洁、链式调用的 ChatClient,代码可读性更强:
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.core.io.ClassPathResource;
import org.springframework.http.MediaType;
String response = ChatClient.create(chatModel)
.prompt()
.user(u -> u.text("Explain what do you see in this picture?")
.media(MediaType.IMAGE_PNG, new ClassPathResource("/multimodal.test.png")))
.call()
.content();
System.out.println(response);
预期输出示例
This is an image of a fruit bowl with a simple design. The bowl is made of metal with curved wire edges that create an open structure, allowing the fruit to be visible from all angles. Inside the bowl, there are two yellow bananas resting on top of what appears to be a red apple. The bananas are slightly overripe, as indicated by the brown spots on their peels. The bowl has a metal ring at the top, likely to serve as a handle for carrying. The bowl is placed on a flat surface with a neutral-colored background that provides a clear view of the fruit inside.
翻译:
这是一张设计简洁的水果碗图片。碗由金属制成,弯曲的金属丝边缘构成开放式结构,使水果从各个角度都清晰可见。碗内有两根黄色香蕉,叠放在一个红色苹果之上。香蕉表皮带有褐色斑点,表明已略微过熟。碗顶部有一个金属环,很可能是用于提携的把手。碗放置在中性色调的平面上,背景简洁,突出了碗中的水果。
Spring AI 支持的多模态模型列表
Spring AI 目前已为以下主流多模态大模型提供开箱即用的支持:
| 提供商 | 模型示例 | 特点 |
|---|---|---|
| OpenAI | gpt-4-turbo, gpt-4o |
支持图像输入,GPT-4o 还支持实时音频交互 |
| Anthropic | claude-3-opus, claude-3-sonnet, claude-3-haiku |
强大的图像理解与长上下文能力 |
| Google Vertex AI | gemini-1.5-pro-001, gemini-1.5-flash-001 |
支持百万 token 上下文,图像、音频、视频多模态输入 |
| Mistral AI | mistral-pixtral-12b |
开源多模态模型,擅长图像+文本任务 |
| Ollama(本地运行) | llava, bakllava, llama3.2 |
可在本地 GPU/CPU 上运行的开源多模态模型 |
| AWS Bedrock | Claude 3 系列、Titan Multimodal 等 | 通过 Converse API 统一接入 |
💡 提示:使用不同模型时,只需在 Spring 配置中切换
ChatModel的实现(如OpenAiChatModel、VertexAiGeminiChatModel等),业务代码无需改动,体现了 Spring AI 的良好抽象。
多模态应用的典型场景
-
智能客服
用户上传商品图片 + 文字描述问题,AI 综合判断并提供解决方案。 -
教育辅助
学生拍照上传数学题,AI 识别题目并逐步讲解解题过程。 -
内容审核
同时分析图片中的敏感内容与 accompanying 文本,提高审核准确率。 -
医疗影像初筛
医生上传 X 光片,AI 辅助标注异常区域并生成初步报告。 -
无障碍技术
为视障用户提供图像描述服务(Image Captioning)。
总结与展望
Spring AI 通过其优雅的 Message API,将多模态大模型的能力无缝集成到 Spring 应用生态中。开发者无需深究底层模型细节,即可通过简单的 media() 调用,让应用具备“看图说话”、“听音识意”的智能。
正如夸美纽斯在 17 世纪所倡导的——知识应通过多种感官协同传授——今天的 AI 也正朝着多模态融合的方向演进。Spring AI 不仅顺应了这一趋势,更为 Java 开发者提供了低门槛、高效率的多模态开发体验。
未来,随着多模态模型支持生成图像、音频、视频的能力逐渐成熟,Spring AI 也必将扩展其 API,支持更丰富的输出模态。届时,我们将真正迎来一个“能说会画、能听会看”的通用人工智能时代。
让机器像人一样感知世界,是我们迈向 AGI 的关键一步。而 Spring AI,正为你铺就这条道路。
参考资料:
- Spring AI 官方文档:https://docs.spring.io/spring-ai/reference/
- OpenAI GPT-4o 多模态文档
- Google Gemini 1.5 技术报告
- LLaVA 项目 GitHub:https://github.com/haotian-liu/LLaVA


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)