大模型-训练-【篇四:后训练-基础了解&SFT】
随着预训练边际效益递减,后训练技术(SFT和强化学习)成为提升模型性能的关键,重点在于数据质量优化。SFT阶段需处理标签噪声、分布不匹配等问题,通过过滤/验证/数据增强建立高质量pipeline。训练时采用动态批处理等技术提升效率,使用改进的交叉熵损失函数避免数值问题。后训练核心是对齐模型行为(如诚实性)并强化预训练能力。
参考:《Post-training 101》
原文链接:https://tokens-for-thoughts.notion.site/post-training-101)
介绍内容:基础了解、SFT、强化学习后训练技术(RLHF、RLAIF、RLVR)、模型质量评测。
基础了解
背景:scaling law对预训练模型的边际效益在减少,业界转向收益更大的后训练。
后训练的核心目标:对模型的行为进行对齐(如诚实、无害),并进一步强化模型在预训练阶段积累的能力。
后训练最重要的是数据的质量。
后训练技术:SFT、强化学习(RL)
SFT
效果取决于数据质量,数据量级在1-10w左右。
常见的3个问题:
1)标签噪声
2)分布不匹配(即数据集范围过窄)
3)伪推理:出现在看似逐步展开的推理轨迹中,实则包含逻辑漏洞、误导性的捷径
解决方案:
1)过滤:自动化或者人工审核
2)验证:保留一部分高质量的黄金数据集,持续监测模型漂移(即模型随着时间或数据变化,其输出行为或性能偏离预期目标的现象)
3)数据增强:采样更多样化的任务平衡分布,利用更高质量的教师模型生成推理轨迹,或者将带噪声的样本改写为更清晰的格式。
形成一套pipeline:收集数据、进行质量过滤、评估模型行为,并不断迭代优化数据集,直到 SFT 阶段能够为后续的偏好优化奠定坚实基础。迭代过程中,需要利用多个LLM、外部工具作为裁判。
训练:
1、批处理:
动态批处理:将长度相近的样本分组,减少填充需求
2、序列打包:将多个较短的样本拼接成一个长序列,并用特殊token分割,减少空间浪费
3、填充:注意力掩码,保证损失、梯度只在真实的token上进行,且保证张量的维度
损失函数:本质是一个分类问题,按照交叉熵实现。基于模型最后一层的输出logits,得到预测的词表token的预测概率,采用log-sum-exp技巧实现loss计算不出现数值溢出问题。具体推导如下:
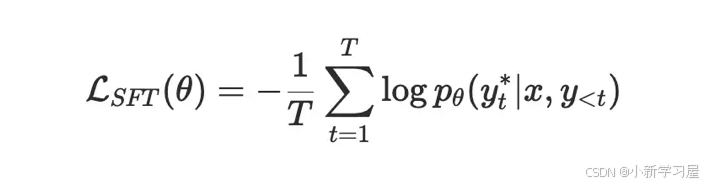
=>
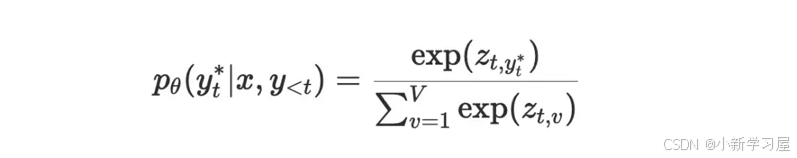
=>
![]()
=>
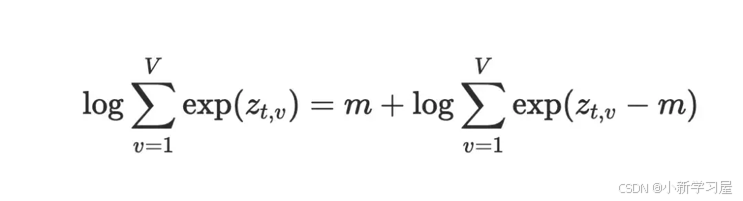
结尾
亲爱的读者朋友:感谢您在繁忙中驻足阅读本期内容!您的到来是对我们最大的支持❤️
正如古语所言:"当局者迷,旁观者清"。您独到的见解与客观评价,恰似一盏明灯💡,能帮助我们照亮内容盲区,让未来的创作更加贴近您的需求。
若此文给您带来启发或收获,不妨通过以下方式为彼此搭建一座桥梁: ✨ 点击右上角【点赞】图标,让好内容被更多人看见 ✨ 滑动屏幕【收藏】本篇,便于随时查阅回味 ✨ 在评论区留下您的真知灼见,让我们共同碰撞思维的火花
我始终秉持匠心精神,以键盘为犁铧深耕知识沃土💻,用每一次敲击传递专业价值,不断优化内容呈现形式,力求为您打造沉浸式的阅读盛宴📚。
有任何疑问或建议?评论区就是我们的连心桥!您的每一条留言我都将认真研读,并在24小时内回复解答📝。
愿我们携手同行,在知识的雨林中茁壮成长🌳,共享思想绽放的甘甜果实。下期相遇时,期待看到您智慧的评论与闪亮的点赞身影✨!
万分感谢🙏🙏您的点赞👍👍、收藏⭐🌟、评论💬🗯️、关注❤️💚~
自我介绍:一线互联网大厂资深算法研发(工作6年+),4年以上招聘面试官经验(一二面面试官,面试候选人400+),深谙岗位专业知识、技能雷达图,已累计辅导15+求职者顺利入职大中型互联网公司。熟练掌握大模型、NLP、搜索、推荐、数据挖掘算法和优化,提供面试辅导、专业知识入门到进阶辅导等定制化需求等服务,助力您顺利完成学习和求职之旅(有需要者可私信联系)
友友们,自己的知乎账号为“快乐星球”,定期更新技术文章,敬请关注!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 38
38 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)