GPT4RoI- Instruction Tuning Large Language Model on Region-of-Interest.论文阅读笔记
基于图文对 (image-text pairs) 的视觉指令微调(visual instruction tuning)已经赋予大语言模型(LLM)通用的视觉-语言能力。然而,由于缺乏 区域-文本对 (region-text pairs),其在 细粒度多模态理解 上的发展受到了限制。在本文中,我们提出了 空间指令微调 (spatial instruction tuning),它在指令中引入了对兴趣区
GPT4RoI- Instruction Tuning Large Language Model on Region-of-Interest.
作者Shilong Zhang, Peize Sun,Shoufa Chen 年份2024
撰写者:麦麦要早起
1 摘要:
基于图文对 (image-text pairs) 的视觉指令微调(visual instruction tuning)已经赋予大语言模型(LLM)通用的视觉-语言能力。然而,由于缺乏 区域-文本对 (region-text pairs),其在 细粒度多模态理解 上的发展受到了限制。在本文中,我们提出了 空间指令微调 (spatial instruction tuning),它在指令中引入了对兴趣区域(RoI)的引用。在送入 LLM 之前,这些区域引用会被对应的 RoI 特征替换,并与语言嵌入交替组成一个输入序列。我们提出的模型 GPT4RoI,在 7 个区域-文本对数据集上进行训练,相较于以往的图像级模型,带来了前所未有的 交互性和对话体验:超越语言的交互:用户既可以通过语言,也可以通过绘制边界框与模型交互,从而灵活调整指令的指向粒度。多样化的多模态能力:GPT4RoI 能够挖掘每个 RoI 的多种属性信息,如颜色、形状、材质、动作等;此外,它还能基于常识对多个 RoI 进行推理。在 Visual Commonsense Reasoning (VCR) 数据集上,GPT4RoI 取得了 81.6% 的准确率,显著超越了所有现有模型(第二名为 75.6%),并几乎达到人类水平 85.0% 的表现。
2 主要贡献
-
提出空间指令微调 (Spatial Instruction Tuning):将用户指令中的 区域引用 (bounding box reference) 转换为 区域特征 (RoI features),并与语言嵌入交替输入到 LLM,实现了对图像的细粒度区域级理解。
-
提出 GPT4RoI 模型:在 7 个区域-文本对数据集上训练,首次支持 语言+边界框混合交互,实现超越语言的灵活对话。
-
多模态能力增强:能够识别并描述区域内的多种属性(颜色、形状、材质、动作等),同时具备基于常识的 多区域推理 能力。
-
实验性能突出:在 Visual Commonsense Reasoning (VCR) 数据集上取得 81.6% 准确率,超过现有最佳模型 75.6%,接近人类水平 85%。
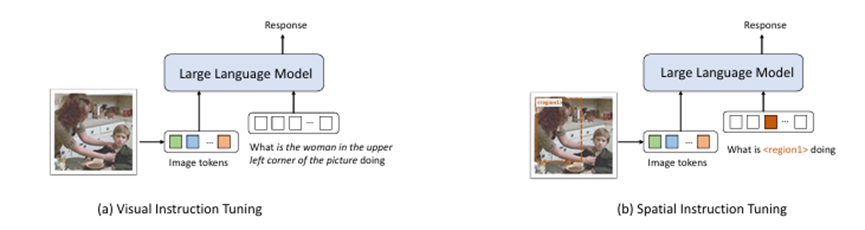
图1 现有视觉指令微调方法对比
如图 a. Visual Instruction Tuning , 在传统的 视觉指令微调 中,用户需要用文字完整地描述图像中的目标,比如 “图片左上角的女人在做什么?”。模型接收整张图像的特征(Image tokens)+ 用户的文本输入。问题在于:对象的描述依赖自然语言,表达可能含糊或复杂;模型需要自己推断“左上角的女人”对应图像的哪个区域,容易出错。如图b. Spatial Instruction Tuning :在 空间指令微调 中,用户不再用文字冗长地描述目标,而是直接在图像上用 边界框 (bounding box) 标注区域。文本输入只需简单指代:“<region1> 在做什么?”。在输入序列中,<region1> token 会被替换成该区域的特征表示(Region features)。相比之下,图b定位精准,避免自然语言描述中的歧义;模型可以直接理解用户指定的区域,提高指令执行的准确性和效率;更符合交互式使用场景(语言 + 框选结合)。
3 方法
本文提出的 GPT4RoI 框架(Instruction Tuning Large Language Model on Region-of-Interest)针对 细粒度区域级图像理解 的问题,设计了一种结合 图像级特征 与 区域级特征的端到端结构。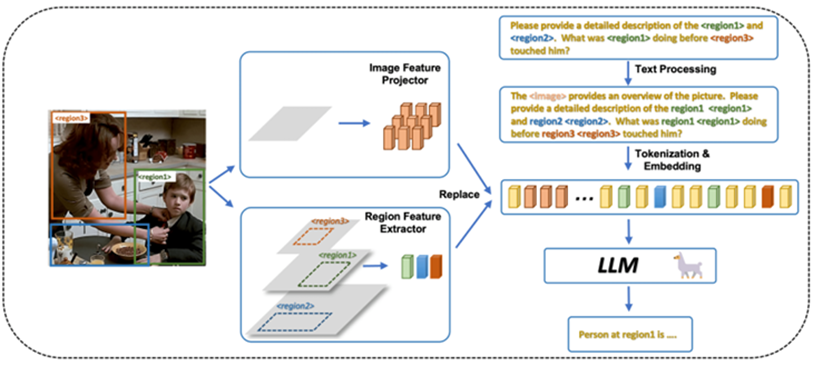
图2 总体架构
如图所示,GPT4RoI 的整体流程包含四个核心组件:图像编码器、区域特征提取器、特征投影器、以及大语言模型 (LLM)。首先,GPT4RoI 使用 CLIP ViT-L/14 作为视觉编码器,从倒数第二层 Transformer 提取整幅图像的全局特征,并通过一个单层线性投影将该特征映射到语言空间。这样,输入序列中的特殊 token <image> 在嵌入阶段会被替换为图像全局语义,从而为语言模型提供整体视觉上下文。与此同时,用户在指令中可以显式引入 <region{i}> token 来指代兴趣区域,模型借助区域特征提取器生成对应的区域特征。该模块基于目标检测常用的设计,首先从 CLIP 的多层特征构建特征金字塔,以保证不同尺度的区域都能获得稳定表征,同时引入绝对坐标信息,使模型能够敏感地捕捉位置信息(例如“左边的人”或“上方的物体”)。之后通过 RoIAlign 操作将指定区域裁剪为固定大小(14×14)的特征块,并融合来自不同层的表示,最终得到紧凑而细致的 RoI embedding。在指令序列构建阶段,原始文本如 “What is <region1> doing?” 会被改写为 “region1 <region1> …”,这样既保留文字层面的语义标记,又将 <region1> 替换为实际区域特征,从而形成一个由语言嵌入与视觉嵌入交错组成的多模态输入序列。最后,这一序列被送入基于 LLaMA 的 Vicuna 大语言模型,通过多头注意力机制实现跨模态交互与推理,从而生成自然语言响应。得益于这一设计,GPT4RoI 能够同时利用图像的整体信息与用户指定的局部区域,在处理涉及物体动作、区域属性、乃至多区域关系推理的任务时展现出更高的准确性和可解释性。相比传统的 Visual Instruction Tuning 仅依赖自然语言模糊描述区域,GPT4RoI 通过显式引入区域 token 并替换为 RoI 特征,大幅降低了歧义和错误推断的风险,实现了更强的交互能力和更细粒度的区域级理解。
3.1. Model Architecture
在 GPT4RoI 的方法设计中,作者将整体逻辑分为图像级特征建模与区域级特征抽取两个部分,并通过统一的嵌入空间将二者融合。首先,采用 CLIP ViT-L/14 作为视觉编码器,利用其在大规模图文对上的预训练优势,使图像特征天然具备跨模态对齐能力。在具体实现中,从倒数第二层 Transformer 获取整幅图像的特征图,并通过单层线性映射投射到语言空间,这样保证 <image> token 在送入 LLM 时能够与文本 embedding 兼容。接下来,区域级理解依赖于专门设计的区域特征提取器。其核心思想借鉴目标检测中的特征金字塔网络(FPN),从 CLIP 编码器的不同深度层(倒数第2、5、8、11层)提取特征,通过五个轻量级的 scale shuffle 模块进行跨层融合,从而实现多尺度建模。这样一方面高层特征能提供语义信息(如类别、动作),另一方面低层特征能保留细粒度的边缘与纹理。为了解决 CNN 和 Transformer 特征固有的平移不变性导致的位置信息缺失问题,作者引入显式的坐标编码,使得每个特征单元都包含绝对位置信息,从而使模型可以对“左边”“右下角”等描述做出准确响应。在区域特征抽取时,作者采用 RoIAlign 算子对兴趣区域进行对齐和裁剪,将不同尺度的区域映射为固定大小的 14×14 特征图。RoIAlign 的优势在于通过双线性插值避免了 RoIPool 的量化误差,从而更好地保留细粒度的结构信息。最终,将来自四个尺度的区域特征进行融合,得到一个单一高维向量作为兴趣区域的最终表示。整体而言,这一设计的底层逻辑是利用 CLIP 的全局语义对齐能力作为背景,结合多尺度特征金字塔保证区域表征的稳健性,引入坐标编码补充空间敏感性,并通过 RoIAlign 保留细节,从而为 LLM 提供既全局一致又局部精确的视觉输入,支撑后续在区域级别的自然语言推理与交互。
下面就本文所引用的RoIAlign方法做一个解读,他沿用了Mask R-CNN这篇文章的方法: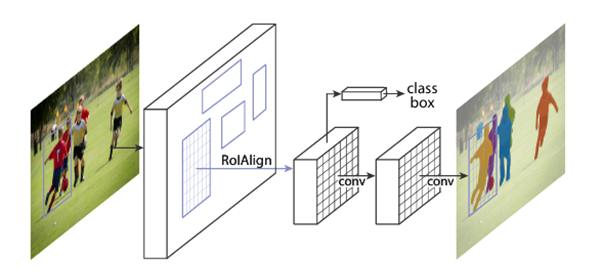
图3 RoIAlign总体架构
在目标检测与实例分割中,常常需要从整幅图像的特征图里“裁剪”出某个候选框(Region of Interest, RoI)的区域特征,用来后续分类、边界框回归,甚至像素级的掩码预测。传统的 RoIPool (Region of Interest Pooling) 会把候选框映射到特征图上,并划分为固定大小的网格(如 7×7),然后在每个网格里取最大值或平均值作为特征。但这种操作会涉及 量化(quantization),即将浮点坐标取整,导致边界信息偏移,丢失精细对齐能力。双线性插值 (Bilinear Interpolation):对于每个采样点,RoIAlign 会根据其浮点坐标,在特征图上用双线性插值计算出精确的特征值,而不是简单地选择最邻近的像素点。固定输出大小:将候选框区域划分为预设的网格(例如 7×7 或 14×14),对每个网格采样若干点(常见是 1 或 4 个),再通过插值计算得到该网格的特征,最终形成固定尺寸的区域特征图。因为避免了取整操作,RoIAlign 保留了更精准的边界信息。图中流程:输入图像首先经过 backbone 网络(如 ResNet 结合 FPN)提取出多层次的特征图,随后候选框(RoI)会被映射到对应的特征层位置,并通过 RoIAlign 操作将候选区域精确裁剪并重新采样为固定大小的特征块(例如 7×7),从而避免量化误差带来的信息丢失。得到的对齐特征被送入不同的分支进行处理,其中一条分支用于分类和边界框回归,另一条分支通过卷积层进行像素级的掩码预测,最终模型同时输出检测框与实例分割结果,实现对目标的精确定位与轮廓刻画。
3.2. Tokenization and Embedding
作者提出了一种特殊的区域指代机制,以便用户在文本输入中能够明确引用感兴趣的区域。他们定义了 <region{i}> 作为占位符,在分词和嵌入阶段会被对应的区域特征替换。例如,当用户给出指令 “What was <region1> doing before <region3> touched him?” 时,<region1> 和 <region3> 这两个 token 的嵌入会被替换为各自的区域特征。但这种替换会丢失文本中对区域的纯语言引用,因此作者将指令改写为 “What was region1 <region1> doing before region3 <region3> touched him?”,这样 LLM 在生成回答时既能利用视觉特征,又能在语言层面保持对不同区域的引用,从而能够生成类似 “The person in region1 was eating breakfast before the person in region3 touched them.” 这样的答案。此外,无论用户输入的具体指令是什么,模型都会预置一个前缀提示 “The <image> provides an overview of the picture.”,其中 <image> 是一个特殊 token,会在嵌入阶段被整幅图像的全局特征替换,以保证 LLM 始终能接收到整体视觉信息,获得更全面的语境理解。
3.3. Spatial Instruction Tuning
在训练方法部分,作者采用了一种基于 next-token prediction loss 的优化策略,即让模型在输入序列中逐步预测下一个词或 token。这种方式与 GPT 系列语言模型的标准训练范式保持一致,从而使 GPT4RoI 能够无缝地处理自然语言与区域特征交织的输入。为了逐步提升模型的能力,作者设计了一个 两阶段的训练流程,分别对应于区域特征与语言空间的初步对齐,以及复杂指令下的推理与多区域理解。
在 第一阶段(预训练阶段) 中,重点是完成 区域特征与语言嵌入的对齐。具体做法是:首先加载经过 LLaVA 初始训练后的权重,这些权重包含一个预训练的视觉编码器(CLIP)、一个图像级特征投影器以及一个大语言模型(Vicuna / LLaMA)。在此基础上,模型仅训练区域特征提取器,使其能够输出与语言 embedding 空间相容的表示。训练数据主要选取 COCO、RefCOCO、RefCOCO+ 等检测与指代表达数据集,这些数据集的标注形式往往是简短的词或短语(通常不超过五个词),描述的是目标的类别、颜色或位置等基础属性。例如,COCO 的标注会直接对应类别名称,如 <region1> person;而 RefCOCO 的指代表达则可能是更细化的描述,如 <region2> red shirt girl。在训练时,这些标注被转换成 instruction-tuning 风格的输入,即指令 + 区域特征 + 回答,且只对目标短语部分计算损失。通过这种方式,GPT4RoI 在阶段一就能够学会识别物体类别、基础颜色以及位置关系等简单语义,为后续的复杂推理打下坚实的基础。从图3中的实验结果可以看到,经过该阶段训练后,模型已经能够稳定地识别出如“大象”“紫色”“左边”等基础区域属性。
在 第二阶段(端到端微调阶段) 中,训练目标扩展到复杂的区域描述与多区域推理。在这一阶段,作者固定视觉编码器的参数,仅对区域特征提取器、图像特征投影器和 LLM 进行训练。此时的重点是提升 GPT4RoI 的综合理解与推理能力。为了实现这一点,作者引入了多种更复杂的数据集和任务形式:例如使用 Visual Genome 的区域描述任务(Region Caption),要求模型能够用自然语言生成某个区域的细粒度描述;在 Flicker30k 数据集中,将标注转化为多区域 caption 任务,即生成的描述必须覆盖所有用边界框标注出的区域;在 RefCOCOg 数据集中,则训练模型理解更复杂的指代表达,这类描述往往涉及对象之间的关系或更复杂的上下文提示。此外,作者还将 Visual Commonsense Reasoning (VCR) 数据集改造为 instruction 格式,使模型能够处理涉及动作、关系和常识推理的问题。这些改造不仅增强了模型的语言理解能力,也让它逐步具备了对多区域交互和逻辑推理的建模能力。
为了进一步提升模型在多轮对话场景下的表现,作者还引入了 LLaVA150k 数据集。具体做法是利用一个预训练的 LVIS 检测器,从图像中自动提取出多达 100 个候选检测框,然后将这些候选区域与指令拼接在一起,例如 “<region{i}> may feature a class_name”。这种方式相当于在指令中显式提供了可能的候选区域提示,使模型在交互过程中能够更灵活地定位目标,并生成更符合人类交互风格的回答。这一改造显著提升了 GPT4RoI 在多轮对话和开放式交互任务中的表现力。
通过这两个阶段的训练,GPT4RoI 逐步形成了由浅入深的能力层次:在第一阶段,它能够稳定地识别基础的类别、颜色和位置等属性,确保区域特征与语言 embedding 对齐;在第二阶段,它学会了更复杂的区域描述与多区域推理任务,能够处理涉及动作、关系甚至常识的复杂指令。此外,LLaVA150k 的加入让它更具对话性和交互性。最终,GPT4RoI 成为一个既能处理区域级别基础识别,又能完成高层推理与复杂交互的多模态大模型。
4.实验
在实验部分,作者系统性地评估了 GPT4RoI 的区域级理解能力。与以往主要依赖图像级对齐的模型不同,GPT4RoI 专注于 区域级别的交互和推理,因此作者选择了一系列具有代表性的基准任务,从综合评测、开放词汇识别、区域描述(Region Caption),到复杂的视觉常识推理(Visual Commonsense Reasoning, VCR),全面展示其性能。
综合区域理解(ViP-Bench):作者首先在 ViP-Bench 上评估了 GPT4RoI 的表现。ViP-Bench 是一个专门面向多模态模型区域理解的综合基准,涵盖了六类任务:识别(Recognition)、OCR、知识问答(Knowledge)、数学(Math)、关系推理(Relationship)和语言生成(Language generation)。对比方法包括使用纯语言引用的 InstructBLIP,使用文本坐标的 Shikra,以及在输入序列中加入额外位置 token 的 Kosmos-2。结果表明,在相同或更少的训练数据条件下,GPT4RoI 在多个子任务上均超越了这些方法,整体性能有显著优势。这说明 GPT4RoI 在区域级别输入建模方面更有效,尤其是在需要明确空间指代的任务上具备更好的泛化能力。
区域识别(Region Recognition): 接下来,作者评估了 GPT4RoI 的区域识别能力。其方法是基于 开放词汇识别(Open-Vocabulary Recognition):模型首先生成一个区域 caption,然后与数据集中提供的词汇表计算语义相似度,选择最高相似度的类别作为最终预测。这种方法避免了固定类别标签的限制,更能体现模型在开放场景下的表达能力。对比方法是 CLIP-Surgery-ViT-L,它输入的是裁剪后的区域(分辨率 512×512);而 GPT4RoI 的输入是 RoIAlign 特征(分辨率 224×224),因此在实例级别(Instance)表现略低于 CLIP-Surgery,但在 Cityscapes 和 ADE20K 数据集上整体指标更优。具体来看,在 Cityscapes 数据集上,GPT4RoI-7B 在 panoptic segmentation (PQ)、instance segmentation (AP)、semantic segmentation (mIoU) 三个指标上分别达到 34.70, 21.93, 36.73,明显优于 Kosmos-2(12.09, 9.81, 13.71)和 Shikra-7B(17.80, 11.53, 17.77),也超过了 CLIP-Surgery 的 PQ 和 mIoU。在 ADE20K-150 数据集上,GPT4RoI-7B 的表现同样领先,三项指标为 36.32, 26.08, 25.82,相比 Kosmos-2(6.53, 4.33, 5.40)和 Shikra-7B(27.52, 20.35, 18.24)优势明显。这说明 GPT4RoI 在不同尺度和复杂场景中都具备强健的区域识别能力。
区域描述(Region Caption): 在 Visual Genome 验证集上,作者进一步评估了模型的区域描述能力,并与 Shikra 和 GRiT 进行了比较。实验表明 GPT4RoI 不仅在零样本条件下表现优越,在微调(fine-tuning)后更是大幅超越了 GRiT 这一专门的区域描述模型。具体数据见表7:在 BLEU@4 指标上,GPT4RoI-7B 从 10.5 提升到微调后的 11.5,13B 模型达到 11.7;在 METEOR 上分别达到 16.5, 17.4, 17.6,均优于 GRiT 的 15.2 和 Shikra 的 17.1;在 ROUGE 上 GPT4RoI 达到 33.4, 35.0, 35.2,也超过 GRiT 的 30.3;在 CIDEr 指标上,GPT4RoI 微调后分别达到 145.2 和 146.8,相比 GRiT 的 142.0 有显著提升。值得注意的是,GPT4RoI-7B 与 GPT4RoI-13B 的表现相差不大,这提示当前瓶颈更多在于视觉模块的设计和区域-文本配对数据的规模,而非单纯依赖语言模型的大小。这一发现为后续研究提供了改进方向。
区域推理(Region Reasoning, VCR): 最后,作者在 Visual Commonsense Reasoning (VCR) 数据集上对 GPT4RoI 的区域推理能力进行了测试。VCR 任务要求模型不仅要选择正确答案,还要选择正确的推理理由,分别包括 Q→A(选择答案)、QA→R(选择理由)、以及 Q→AR(答案和理由同时正确)。这是一个高度依赖视觉理解与常识推理的任务,难度极高。实验结果表明 GPT4RoI 在所有子任务上均取得显著提升,尤其在关键的 Q→AR 上表现突出。GPT4RoI-13B 在 VCR 上达到 Val 89.4%、Test 91.0% 的 Q→A 准确率,以及 81.6% 的 Q→AR 综合准确率,不仅超过了所有现有方法(如 VQA-GNN-L 的 74.0%,HunYuan-VCR 的 75.6%),甚至超过了部分商业化闭源产品的表现,更是逼近人类水平(85.0%)。相比之下,传统方法如 ViLBERT、UNITER-L 等的 Q→AR 准确率在 54–66% 左右,而 GPT4RoI-13B 的提升超过 6 个百分点,说明区域指令调优(Spatial Instruction Tuning)确实显著增强了模型的推理能力。整体来看,GPT4RoI 在四个方面取得了显著突破:在 综合评测 中展现了区域级理解的全面优势;在 开放词汇识别 上表现出较强的泛化能力;在 区域描述任务 中超越了此前的专门模型 GRiT;在 区域推理(VCR) 上接近人类水平,展现了大模型在视觉常识推理方面的潜力。值得强调的是,这些成绩的取得并未依赖过度庞大的训练数据,而更多得益于方法本身对区域特征与语言空间的高效对齐。这不仅验证了 GPT4RoI 框架的有效性,也为后续的多模态研究指出了新的方向,即通过显式的空间指令调优来弥补大模型在细粒度图像理解上的短板。
6 个人评价
从整体实验结果来看,我认为 GPT4RoI 的设计思路非常清晰,它通过在输入序列中引入 <region> token 并替换为 RoI 特征,使模型能够直接对接局部区域信息,从而大幅度增强了细粒度的图像理解能力。实验部分的表现也印证了这一点:在 ViP-Bench 上,GPT4RoI 在多个子任务上超过了 InstructBLIP、Shikra 和 Kosmos-2,说明空间指令调优在区域级别任务中具备天然优势;在开放词汇识别和区域 caption 任务中,它不仅展现出对不同尺度目标的强健建模能力,还能在 CIDEr、ROUGE 等自然语言指标上超越专门为区域描述设计的 GRiT,证明了方法的通用性;而在 VCR 这种复杂的视觉常识推理任务上,GPT4RoI-13B 更是达到了 81.6% 的 Q→AR 准确率,已经逼近人类水平,这表明通过显式地建模区域,LLM 的推理与逻辑能力被进一步释放。我个人觉得,这篇论文的贡献不仅在于性能指标的提升,更在于提供了一条新的思路:大模型不一定需要更多的数据和更大的参数规模,反而可以通过结构设计和指令调优,让模型在空间对齐与细粒度语义上更具可控性。当然,也可以看到一些不足,比如 GPT4RoI-7B 与 13B 的差距不大,说明当前瓶颈并不在语言模型,而在视觉特征与区域文本对数据的丰富性,这也意味着后续的改进方向可能是更好的视觉模块设计和更大规模的区域标注数据。在我看来,这篇工作在“如何让大语言模型真正理解图像细节”这个问题上迈出了非常重要的一步。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)