基于Qwen-Image底模训练二次元LoRA模型:以《鸣潮》卡提希娅为例
本文介绍了基于Qwen-Image底模训练《鸣潮》角色卡提希娅LoRA模型的完整流程。通过收集约100张高质量游戏截图,使用魔搭平台的Florence2模型进行自动标注,并设置合理的训练参数,最终成功训练出能够准确还原角色特征的LoRA模型。文章详细分享了数据准备、自动打标、训练参数配置等关键环节的经验,并提供了模型使用指南和应用场景。该模型具有训练速度快、文件体积小、生成质量高的特点,适合二次元
基于Qwen-Image底模训练二次元LoRA模型:以《鸣潮》卡提希娅为例
1. 引言
近年来,随着人工智能技术的飞速发展,基于扩散模型的图像生成技术取得了显著突破。在众多图像生成模型中,Qwen-Image作为一款优秀的开源底模,在二次元图像生成领域表现出色。本文将详细介绍基于Qwen-Image底模训练《鸣潮》角色卡提希娅的LoRA模型的过程与经验,为二次元爱好者提供实用的模型训练指南。
LoRA(Low-Rank Adaptation)是一种高效的模型微调技术,它通过注入少量的可训练参数,在不改变原始模型权重的情况下,使模型学习到特定风格或角色的特征。这种方法不仅训练速度快,而且生成的模型文件体积小,非常适合个性化角色的定制。
在本项目中,我们使用魔搭平台进行数据打标和训练,通过约100张2K分辨率的游戏截图,成功训练出了高质量的卡提希娅角色LoRA模型。以下是我们的完整训练流程和经验总结。
2. 项目概述
2.1 项目背景
《鸣潮》是一款备受关注的二次元风格游戏,其中的角色卡提希娅以其独特的设计和个性吸引了大量玩家。为了能够生成高质量的卡提希娅同人图像,我们决定训练一个专门的LoRA模型。
2.2 技术选型
我们选择Qwen-Image作为基础模型,主要是因为它在二次元图像生成方面的优秀表现。与Stable Diffusion相比,Qwen-Image生成图像质量更高。
表1:技术选型对比
| 技术选项 | 选择理由 | 优势 |
|---|---|---|
| 底模:Qwen-Image | 优秀的二次元生成能力 | 图像质量高 |
| 微调方法:LoRA | 高效的参数微调 | 训练快,模型小,不破坏原模型 |
| 打标工具:Florence2 | 精准的自动标注 | 减少人工标注成本 |
| 训练平台:魔搭 | 一站式AI开发平台 | 环境配置简单,资源丰富 |
2.3 资源准备
在开始训练前,我们需要准备以下资源:
- 基础模型:Qwen-Image最新版本
- 训练数据:约100张卡提希娅的游戏截图
- 计算资源:使用魔搭平台
- 软件环境(如果本地训练,使用魔搭平台则不需要):Python、PyTorch、训练框架
3. 数据集准备与处理
3.1 数据收集
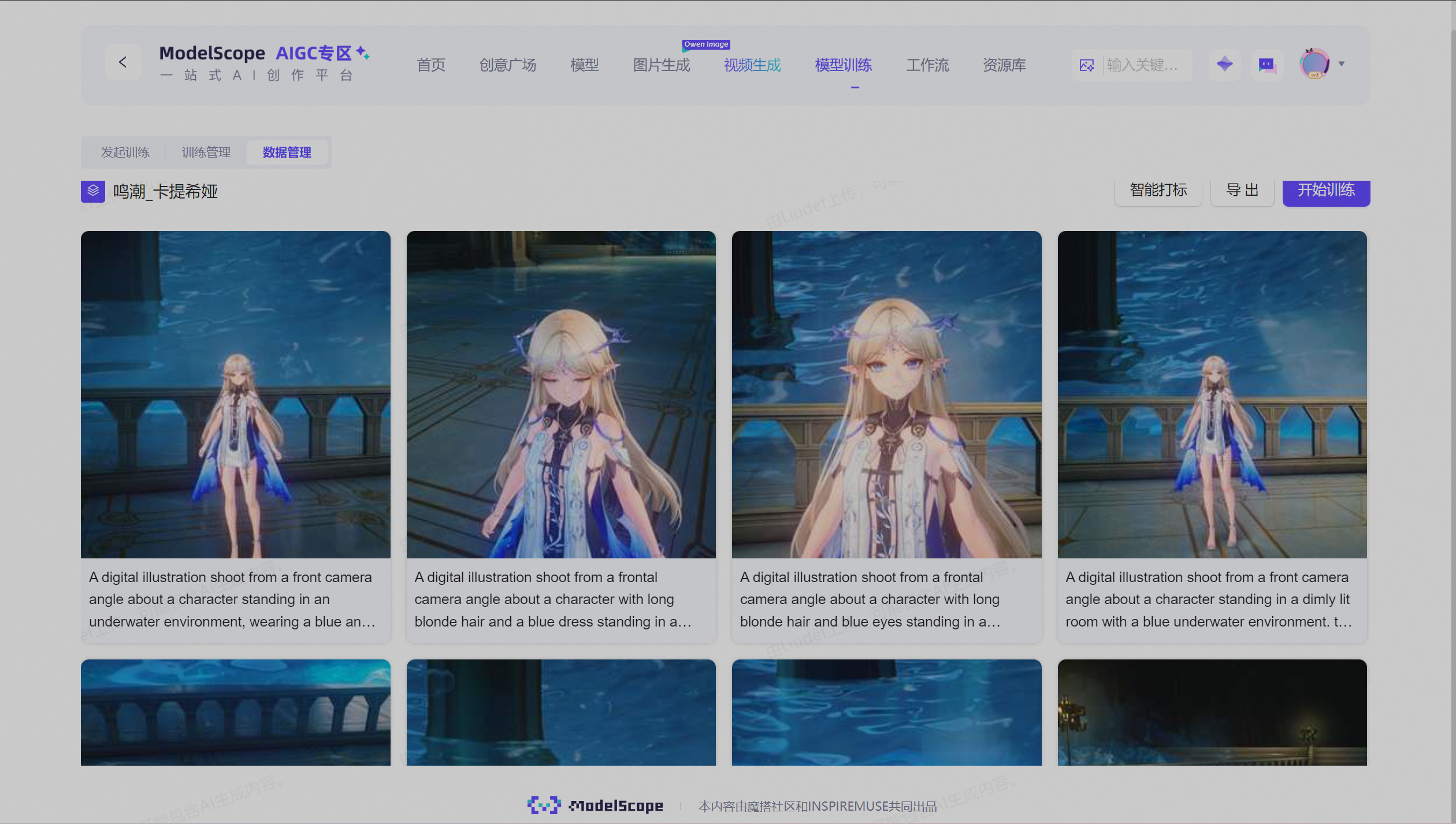
高质量的数据集是训练成功的关键。我们通过两种方式收集卡提希娅的图像数据:
- 游戏剧情截图:捕捉角色在不同剧情中的表情和姿态
- 游戏界面截图:获取角色的立绘和特写画面
收集原则:
- 图像分辨率(越高越好,宁缺毋滥)不低于2K
- 涵盖角色多种表情、姿势和服装
- 避免模糊、遮挡或质量差的图像
- 确保角色在图像中占据主要位置
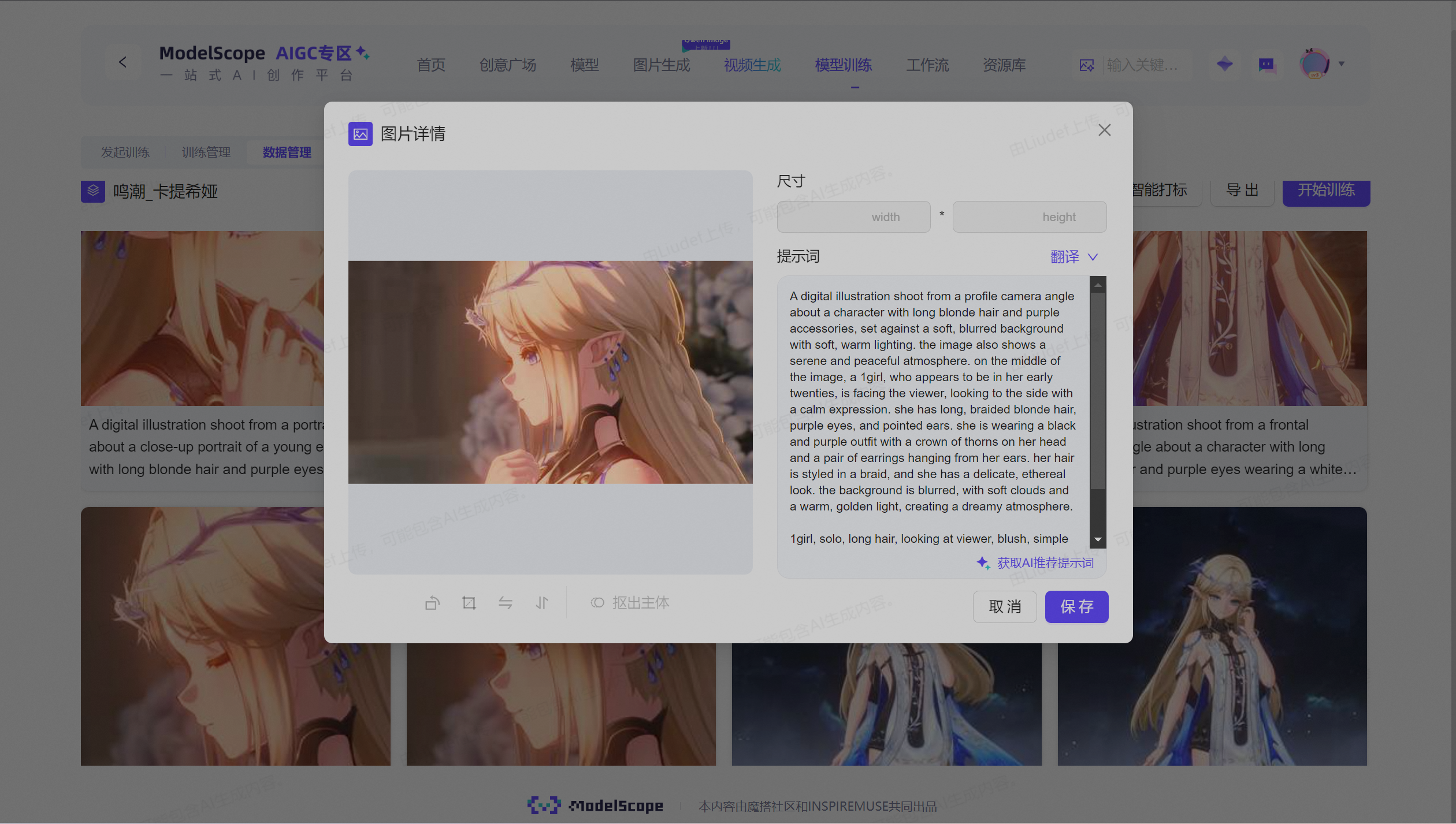
3.2 数据预处理
数据预处理是确保训练效果的重要环节,我们采取了以下步骤:
- 图像筛选:从原始截图中筛选出质量最高的100张图像
- 分辨率统一:将所有图像调整为统一的分辨率(1536×1536)
- 格式转换:将图像转换为训练所需的格式(如JPEG或PNG)
- 数据增强:通过旋转、翻转等操作增加数据多样性
表2:数据集统计信息
| 数据类别 | 数量 | 分辨率 | 来源 |
|---|---|---|---|
| 剧情截图 | 70张 | 2K-4K | 游戏录制 |
| 界面立绘 | 30张 | 2K | 游戏截图 |
| 总计 | 100张 | 平均2K | - |
3.3 自动打标
使用魔搭平台的Florence2模型进行自动打标是本次项目的亮点之一。Florence2是一款强大的视觉-语言模型,能够准确识别图像内容并生成描述性标签。
打标流程:
- 上传图像到魔搭平台
- 调用Florence2模型进行自动标注
- 人工审核和修正标签
- 导出标注结果用于训练
打标提示词示例:
A digital illustration shoot from a profile, character design, anime style, detailed face, beautiful eyes, white hair, blue eyes, cute expression, wearing elegant dress, from the game 'Where Turbulence Flows'
4. 模型训练详解
4.1 训练环境配置
成功的模型训练离不开合适的环境配置。我们使用魔搭平台进行训练,如果本地训练则推荐主要配置如下:
- Python环境:Python 3.8+
- 深度学习框架:PyTorch 1.12+
- 训练框架:基于Diffusers的自定义训练脚本
- GPU资源:NVIDIA RTX 4090(24GB显存)
4.2 训练参数设置
训练参数的合理设置对模型效果至关重要。以下是我们的参数配置详情:
表3:训练参数配置
| 参数类别 | 参数名称 | 设置值 | 说明 |
|---|---|---|---|
| 基础设置 | 模型名称 | XB_CWEN_MC_KTXY | 自定义模型标识 |
| 触发词 | 自定义 | 用于调用LoRA模型的关键词 | |
| 样图设置 | 样图分辨率 | 1104×1472 | 训练过程中生成的样例图像尺寸 |
| 随机种子 | 1155098627 | 确保结果可复现 | |
| 保存设置 | 保存频率 | 每5轮 | 平衡训练进度和存储空间 |
| 保存精度 | bf16 | 兼顾精度和存储效率 | |
| 学习率 | 总学习率 | 0.0001 | 控制参数更新幅度 |
| 优化器 | AdamW | 常用的优化算法 | |
| 数据集 | 图片分辨率 | 1536×1536 | 训练输入图像尺寸 |
| 网络设置 | 网络大小 | 16 | LoRA网络的秩 |
| 高级设置 | 随机数种子 | 1155098627 | 确保训练过程可复现 |
4.3 训练过程监控
训练过程中,我们密切关注以下指标:
- 训练损失:观察损失曲线是否平稳下降
- 生成样本质量:定期检查模型生成的样例图像
- 资源使用:监控GPU显存和利用率
根据训练进度显示(3200/33400步,20/20轮),我们的训练设置能够有效学习角色特征,同时避免过拟合。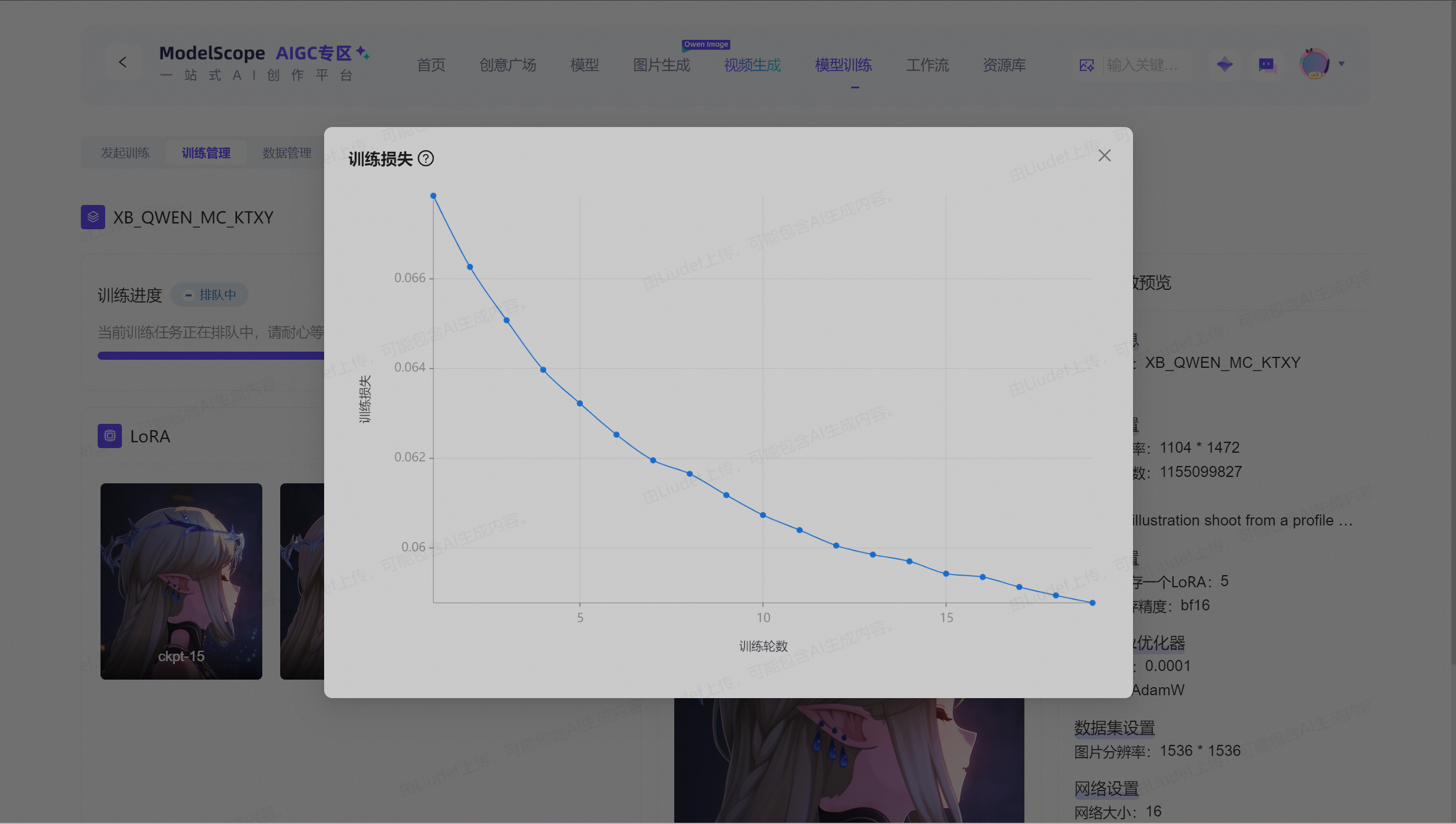
4.4 遇到的技术挑战与解决方案
在训练过程中,我们遇到并解决了以下技术挑战:
- 显存不足:通过调整批次大小和梯度累积解决
- 过拟合:使用早停法和数据增强缓解
- 特征学习不充分:调整学习率和训练步数
- 生成图像多样性不足:优化提示词和增加数据多样性
5. 模型效果与应用
5.1 生成效果评估
训练完成的LoRA模型能够高质量地生成卡提希娅角色的图像,具有以下特点:
- 准确还原角色外貌特征(白发、蓝眼等)
- 保持角色服装和配饰的细节
- 能够生成多种表情和姿势
- 与底模的其他生成能力兼容


5.2 模型使用指南
使用训练好的LoRA模型非常简单:
- 下载模型文件:Liudef/XB_QWEN_MC_KTXY
- 在支持LoRA的推理工具中加载模型
- 在提示词中包含触发词和所需场景描述
- 调整生成参数(如采样器、步数等)
- 生成并评估结果
示例提示词:
A digital illustration shoot from a frontal camera angle about a character with long blonde hair and purple eyes wearing a white and blue outfit with intricate designs, standing confidently in a grand, ornate setting with stone architecture in the background. the image also shows a young woman, who appears to be in her early twenties, standing in the middle of the image, with her upper body facing the viewer and looking directly at them. she has a serious expression and is wearing a sleeveless white dress with a blue and purple cape draped over her shoulders. her hair is long and flowing, and she has pointy ears and a crown of thorns on her head. the lighting is warm and soft, casting gentle shadows on her face and body, highlighting her features and the intricate design of her outfit. the background is a grand stone structure with intricate details, and the overall atmosphere is one of grandeur and elegance.
1girl, solo, long hair, looking at viewer, simple background, blonde hair, hair ornament, dress, closed mouth, jewelry, bare shoulders, standing, purple eyes, collarbone, upper body, yellow hair, short sleeves, sidelocks, cowboy shot, earrings, parted lips, small breasts, horns, short dress, necklace, white dress, glowing, elf, colored skin, glowing eyes, crown, arms at sides, arms behind back, glowing hair ornament
魔搭平台支持生图,或者使用第三方开源webui,如LiuMo Studio
5.3 实际应用场景
训练的角色LoRA模型可以应用于以下场景:
- 同人创作:生成角色在不同场景下的图像
- 故事插图:为粉丝创作的故事配图
- 社交媒体内容:制作个性化的头像和背景
- 角色设计参考:为相关创作提供灵感
6. 经验总结与建议
6.1 成功经验总结
通过本项目,我们总结了以下成功经验:
- 数据质量优于数量:100张(20张也足够)高质量图像足够训练出优秀的LoRA模型
- 精准打标至关重要:Florence2的自动打标大大提升了训练效率
- 参数调优需要耐心:多次实验找到最适合的参数组合
- 监控与调整并重:训练过程中及时调整策略
6.2 对其他二次元模型的训练建议
基于我们的经验,为想要训练其他二次元角色的开发者提供以下建议:
- 角色选择:选择特征鲜明、有足够参考图像的角色
- 数据准备:确保图像质量高、角度多样、特征清晰
- 参数设置:从小学习率开始,根据效果逐步调整
- 迭代优化:不要期望一次训练就完美,需要多次迭代
6.3 未来优化方向
尽管当前模型效果令人满意,但仍有优化空间:
- 增加更多样化的训练数据
- 尝试不同的LoRA配置和训练策略
- 结合ControlNet实现更精确的姿态控制
- 优化提示词工程提升生成质量
7. 结语
本文详细介绍了基于Qwen-Image底模训练《鸣潮》角色卡提希娅LoRA模型的完整流程,从数据准备、自动打标到训练参数设置和效果评估。通过魔搭平台和Florence2打标工具,我们实现了高效、高质量的模型训练。
希望本文能为二次元AI绘画爱好者提供实用的指导和参考,助力更多优秀角色模型的诞生。AI绘画技术正在快速发展,我们期待看到更多创作者利用这些工具,释放想象力,创造出精彩纷呈的二次元作品。
训练完成的Liudef/XB_QWEN_MC_KTXY模型已在魔搭平台分享,欢迎二次元爱好者和AI绘画研究者下载使用,共同探索AI绘画的无限可能。
相关资源链接:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 58
58 0
0- 0



 已为社区贡献113条内容
已为社区贡献113条内容

所有评论(0)