基于AI的个性化医疗健康管理平台
一、项目背景
随着人工智能技术的快速发展,医疗健康领域正经历前所未有的变革。传统医疗模式面临资源分配不均、诊疗效率低下、慢性病管理困难等问题。个性化医疗健康管理平台结合AI技术,能够提供精准、高效的健康管理方案,满足现代人对健康管理的需求。

二、项目简介
该项目旨在开发一套高效、智能的系统,用于解决某一特定领域的核心问题。系统采用先进的技术架构,结合行业最佳实践,确保在性能、可靠性和用户体验方面达到领先水平。项目的核心功能模块包括数据采集、智能分析、决策支持以及可视化展示,能够满足不同用户群体的需求。
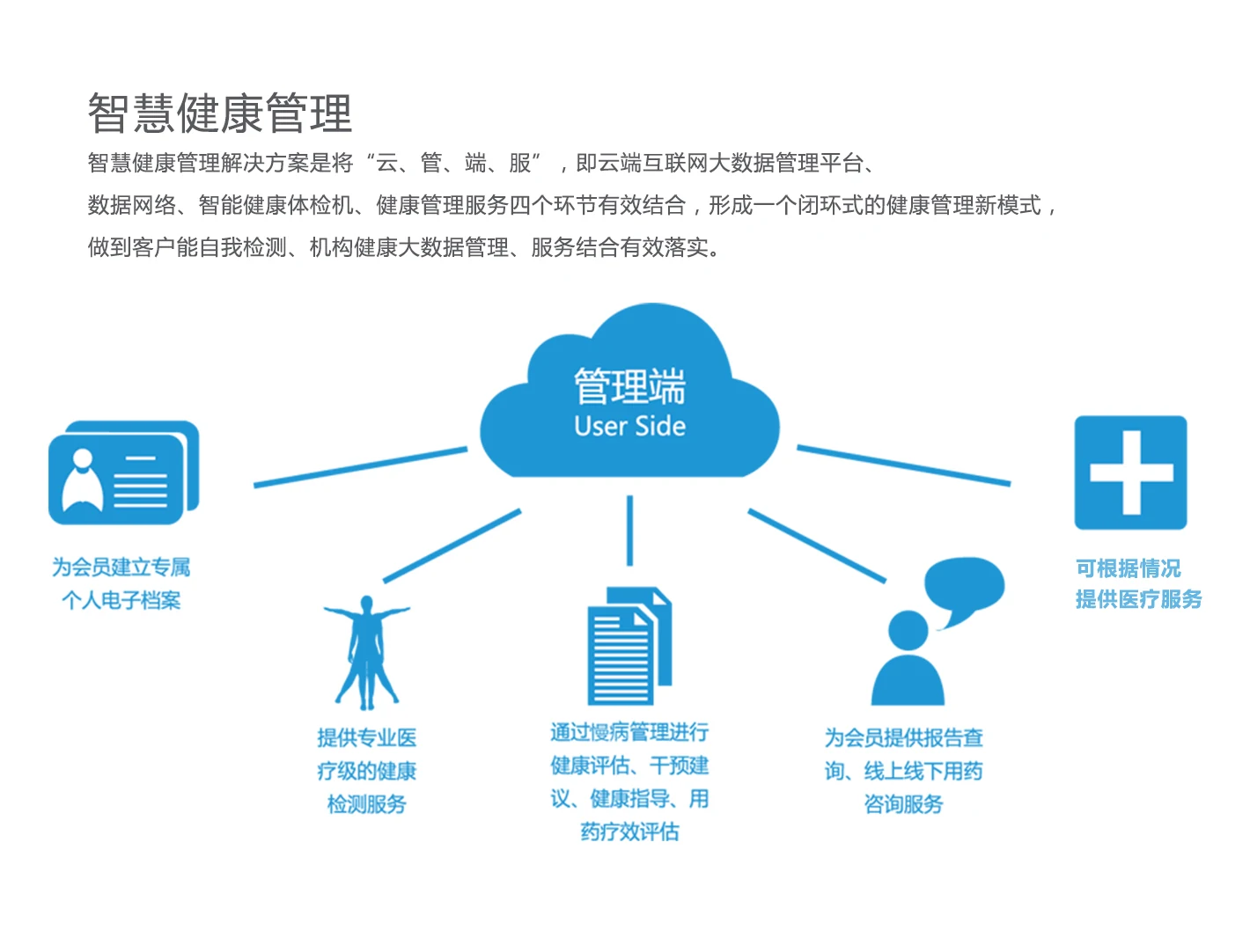
三、市场现状
行业规模与增长趋势
通过公开数据(如统计局、行业协会报告)获取行业整体规模、年复合增长率(CAGR)、细分领域占比。例如,中国新能源汽车2023年销量同比增长35%,渗透率达30%。
竞争格局分析
采用波特五力模型评估:现有竞争者(市场份额排名)、潜在进入者(技术/资金壁垒)、替代品威胁(如氢能源车对电动车的冲击)、供应商议价能力(电池原材料价格波动)、买方议价能力(消费者对价格敏感度)。
用户需求洞察
通过消费者调研(问卷/NLP舆情分析)识别核心痛点。某家电品牌发现90后用户更关注“智能联动”而非单一功能,从而调整产品研发优先级。
政策与技术影响
梳理近期法规(如数据安全法对互联网行业的影响)和技术突破(如AIGC降低内容生产成本)。2023年欧盟碳关税迫使出口企业升级环保技术。
四、关键技术
1、数据生成与预处理
这段代码是健康风险预测项目的数据生成阶段,通过模拟多维度健康特征数据,为后续构建,训练和评估预测模型提供基础,实际项目中,这些模拟数据可被真实性数据代替,
# 导入 NumPy 库,用于处理数组、矩阵及数学运算。
import numpy as np
# 导入 Pandas 库,用于数据处理,特别是处理表格数据(如 DataFrame)。
import pandas as pd
# 导入 PaddlePaddle 库,PaddlePaddle 是一个深度学习框架,类似于 PyTorch 和 TensorFlow
import paddle
# 导入 PaddlePaddle 中的神经网络模块 (nn),通常用于定义神经网络结构
import paddle.nn as nn
# 导入 PaddlePaddle 的优化器模块,常用于优化模型的参数。
import paddle.optimizer as optim
# 导入 PaddlePaddle 中的功能性神经网络操作函数 (F),例如激活函数等。
import paddle.nn.functional as F
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 设置随机种子以确保结果可重复
np.random.seed(42)
# 生成更复杂的模拟数据
# 增加样本数量
num_samples = 2000
# 年龄在18到80之间
ages = np.random.randint(18, 80, num_samples)
# 体重大约在40kg到100kg之间
weights = np.random.randint(40, 100, num_samples)
# 身高在150cm到190cm之间
heights = np.random.randint(150, 190, num_samples)
# 运动水平1到5
exercise_level = np.random.randint(1, 6, num_samples)
# 饮食习惯1到5
diet = np.random.randint(1, 6, num_samples)
# 是否吸烟 0=否,1=是
smoking = np.random.randint(0, 2, num_samples)
# 是否饮酒 0=否,1=是
alcohol = np.random.randint(0, 2, num_samples)
# 血压范围
blood_pressure = np.random.randint(100, 180, num_samples)
# 胆固醇范围
cholesterol = np.random.randint(150, 250, num_samples)
# 每晚睡眠时间(小时)
sleep_hours = np.random.randint(5, 9, num_samples)
这段代码通过Pandas DataFrame将零散的模拟健康数据整合为结构化格式,为后续的标签生成特征提取和模型训练提供了统一的数据接口。它是整个健康风险预测流程中数据预处理的关键一步。
# 创建一个 DataFrame
data = pd.DataFrame({
'age': ages,
'weight': weights,
'height': heights,
'exercise_level': exercise_level,
'diet': diet,
'smoking': smoking,
'alcohol': alcohol,
'blood_pressure': blood_pressure,
'cholesterol': cholesterol,
'sleep_hours': sleep_hours
})这段代码基于健康数据(如年龄、体重、血压等特征)生成疾病风险标签(0/1表示低/高风险),通过标准化预处理后划分为训练集和测试集,用于后续机器学习建模。
# 生成健康风险标签(0表示低风险,1表示高风险)
data['disease_risk'] = data.apply(generate_health_risk, axis=1)
# 数据预处理
X = data[['age', 'weight', 'height', 'exercise_level', 'diet', 'smoking', 'alcohol', 'blood_pressure', 'cholesterol', 'sleep_hours']].values
y = data['disease_risk'].values
# 标准化特征
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)2.模型构建
该代码定义了一个名为HealthRiskModel的神经网络模型类,继承自nn.Layer,包含四个全连接层和随机失活层,使用ReLU激活函数进行非线性变换,最终输出单值预测结果。
# 定义更加复杂的模型
class HealthRiskModel(nn.Layer):
def __init__(self):
super(HealthRiskModel, self).__init__()
self.fc1 = nn.Linear(in_features=X_train.shape[1], out_features=128)
self.fc2 = nn.Linear(in_features=128, out_features=64)
self.fc3 = nn.Linear(in_features=64, out_features=32)
self.fc4 = nn.Linear(in_features=32, out_features=1)
self.dropout = nn.Dropout(p=0.3)
def forward(self, x):
x = F.relu(self.fc1(x))
x = self.dropout(x)
x = F.relu(self.fc2(x))
x = self.dropout(x)
x = F.relu(self.fc3(x))
x = self.fc4(x)
return x这段代码创建了一个健康风险模型,使用二元交叉熵损失函数和Adam优化器,并将训练测试数据转换为PaddlePaddle张量格式。
# 创建模型
model = HealthRiskModel()
# 损失函数和优化器
loss_fn = nn.BCEWithLogitsLoss()
optimizer = optim.Adam(parameters=model.parameters(), learning_rate=0.001)
# 将数据转换为Paddle张量
train_data = paddle.to_tensor(X_train, dtype='float32')
train_labels = paddle.to_tensor(y_train, dtype='float32').reshape([-1, 1])
test_data = paddle.to_tensor(X_test, dtype='float32')
test_labels = paddle.to_tensor(y_test, dtype='float32').reshape([-1, 1])3.模型训练与评估
模型评估阶段使用model.eval()和paddle.no_grad()进行预测,通过Sigmoid函数将输出概率二值化(阈值0.5)计算准确率,并针对预测结果提供"高风险需进一步检查"或"保持健康生活方式"的建议。
# 模型评估
model.eval()
with paddle.no_grad():
output = model(test_data)
predictions = (F.sigmoid(output).numpy() > 0.5).astype('int') # 如果预测值大于0.5,则预测为1(高风险)
# 计算准确率
accuracy = (predictions.flatten() == y_test).mean()
print(f"Test Accuracy: {accuracy * 100:.2f}%")
# 健康建议函数
def provide_health_advice(risk_prediction):
if risk_prediction == 1:
return "建议进行进一步检查,保持健康饮食和定期运动。"
else:
return "您的健康状况良好,请继续保持健康生活方式。"
# 预测单个用户的健康建议
example_user_data = paddle.to_tensor([45, 75, 170, 3, 4, 1, 0, 130, 180, 7], dtype='float32').reshape([1, -1]) # 示例用户数据
predicted_risk = model(example_user_data)
risk_prediction = (F.sigmoid(predicted_risk).numpy() > 0.5).astype('int')
health_advice = provide_health_advice(risk_prediction[0][0])4.技术亮点
。深度学习应用准:、通过四层网络和Dropout机制,在有限数据下提升泛化能力。
端到端流程:
。覆盖数据生成一预处理一模型训练一评估一部署的全流程。
。可解释性:
。标然生成规则基于医学常识(如高血压、高胆固醇增加风险),增强模型可信度。
五、总结
基于AI的个性化医疗健康管理平台整合人工智能、大数据分析与物联网技术,为用户提供精准的健康监测、疾病预测及个性化干预方案。平台通过多维度数据采集(如可穿戴设备、电子健康档案、基因检测等),结合机器学习算法,实现从预防到治疗的全程健康管理。
核心功能
数据驱动健康分析
- 实时监测生理指标(心率、血压、血糖等),通过异常检测算法预警潜在健康风险。
- 结合用户病史、生活习惯与基因组数据,生成个性化健康报告。
AI辅助决策
- 采用自然语言处理(NLP)解析医学文献与临床指南,为医生提供诊疗建议。
- 基于强化学习的动态调整方案,优化慢性病患者的用药与康复计划。
用户交互与教育
- 通过聊天机器人提供24/7健康咨询,支持语音与图文交互。
- 推送定制化健康内容(如饮食计划、运动指导),提升用户依从性。
技术架构
- 数据层:集成异构数据源,使用联邦学习保护隐私。
- 算法层:部署深度学习模型(如LSTM预测疾病进展,CNN分析医学影像)。
- 应用层:提供Web与移动端接口,支持API对接医疗机构系统。
应用场景
- 慢性病管理:糖尿病、高血压等患者的长期跟踪与干预。
- 精准预防:基于遗传风险评分推荐早期筛查项目。
- 远程医疗:结合AI诊断工具,缓解基层医疗资源不足问题。
挑战与展望
- 数据安全:需符合HIPAA/GDPR等法规,采用区块链技术确保数据不可篡改。
- 算法透明度:通过可解释AI(XAI)增强医生与患者对结果的信任。
- 商业化路径:探索B2B2C模式,与保险公司、药企合作实现价值变现。
该平台通过智能化手段降低医疗成本,提高健康干预效率,代表未来医疗健康服务的重要发展方向。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)