[论文阅读] AI | PynguinML——破解ML库自动化测试难题,覆盖率最高提升63.9%
Python机器学习库(如PyTorch、TensorFlow)的API存在严格输入约束(如张量维度、数据类型),但现有单元测试生成工具(如Pynguin)无法识别这些约束,导致生成非合规输入、早期测试失败及低代码覆盖率。为此,本文提出PynguinML——Pynguin的扩展方案,通过加载从165个ML模块(PyTorch 53个、TensorFlow 112个)API文档中提取的约束,优化输入
PynguinML——破解ML库自动化测试难题,覆盖率最高提升63.9%
论文信息
- 原标题:PynguinML: Enhancing Unit Test Generation for ML Libraries via API Documentation Constraints
- 主要作者及机构:详见arXiv论文原文(arXiv:2510.09108),研究聚焦Python机器学习库(PyTorch/TensorFlow)的自动化单元测试优化
- 引文格式(GB/T 7714):
[1] 论文作者. PynguinML: Enhancing Unit Test Generation for ML Libraries via API Documentation Constraints[EB/OL]. (2025-10)[2025-10-XX]. https://arxiv.org/pdf/2510.09108.
一段话总结
论文提出PynguinML——作为现有Python单元测试生成工具Pynguin的扩展方案,通过整合从PyTorch(53个模块)和TensorFlow(112个模块)API文档中提取的约束(如张量数据类型、维度、数值范围等),解决了传统工具因生成非合规输入导致早期测试失败、代码覆盖率低的问题;在165个目标模块的评估中,PynguinML相比Pynguin实现高达63.9%的分支覆盖率提升,平均分支覆盖率达38.6%(Pynguin为33.4%),同时生成更多合规测试用例,且性能优于同样基于约束的工具MuTester(平均覆盖率31.4%),为ML库的自动化测试提供更高效的解决方案。
研究背景:为什么ML库的自动化测试这么难?
如果你用过PyTorch写代码,一定遇到过类似报错:Expected object of scalar type Float but got scalar type Int——这就是ML库API的“脾气”:输入必须满足严格约束,比如张量的数据类型(dtype)、维度(ndim)、数值范围都得“对号入座”。
但传统的Python单元测试生成工具(比如主流的Pynguin)根本“不懂”这些约束。它们像“盲盒式”生成输入:比如给需要张量的函数传None,给要求非负整数的参数传-5。结果就是:测试刚运行就触发异常,标记为“预期失败(xfail)”,根本碰不到函数的核心逻辑——这就像给手机充电时插错充电器,不仅充不上电,还可能触发保护机制,完全达不到“测试充电功能”的目的。
论文里举了个真实例子:测试PyTorch的torch.nn.functional.glu函数时,Pynguin生成的用例直接传了None,触发TypeError后被跳过;而PynguinML生成的用例,先造符合维度的嵌套列表,再转成float32类型的张量,顺利跑完核心逻辑,还覆盖了关键分支。
简单说,ML库测试的核心难题,就是“工具不懂API约束”——这也是PynguinML要解决的核心问题。
创新点:PynguinML的3个“破局思路”
相比传统工具和同类方案(如MuTester),PynguinML的创新点很明确,全围绕“如何让工具‘读懂’API约束”展开:
-
只靠API文档,不依赖额外信息
很多工具(如MuTester)需要结合函数签名、示例代码才能生成合规输入,但PynguinML仅用从API文档中提取的约束(通过DocTer工具),无需额外手动标注,适配性更强。 -
专为ML场景设计“输入生成逻辑”
针对张量这类ML特有数据结构,新增3类专用语句(枚举、无符号整数、嵌套列表),还设计了“嵌套列表→NumPy数组→库特定张量”的标准化流程——确保生成的输入既符合约束,又能被PyTorch/TensorFlow识别。 -
平衡“合规”与“非合规”用例
合规用例(符合约束)能覆盖核心计算逻辑,非合规用例(故意违反约束)能测试错误处理逻辑——PynguinML用25%的概率生成非合规用例,既不浪费测试资源,又能全面覆盖代码。
研究方法:PynguinML是怎么工作的?
PynguinML本质是Pynguin的“升级版”,核心工作流程分3步,每一步都针对ML库的约束做了优化:
第一步:加载并验证API约束
先从DocTer提取的约束库中,加载目标模块的约束(比如PyTorch的torch.add需要“两个张量维度一致”“dtype相同”),然后做两件事:
- 剔除无效约束:比如语法错误、未定义的类型(如
torch.unknown_dtype); - 排除矛盾约束:比如同时要求“维度≥3”和“维度≤2”,这种约束直接丢弃。
第二步:优化输入生成
针对ML场景的特殊需求,新增3类语句,并标准化张量生成:
- 新增语句:比如“枚举语句”(从预定义值里选输入,如
padding_mode只能是'zeros'/'reflect')、“嵌套列表语句”(生成符合ndim的列表,比如2维就是[[1,2],[3,4]]); - 张量生成四步走:
- 生成符合维度(
ndim)的嵌套列表; - 定义NumPy数据类型(如
"float32"); - 转成
numpy.ndarray; - 调用
torch.tensor()或tf.convert_to_tensor()转成库特定张量。
- 生成符合维度(
第三步:调整搜索算法
传统Pynguin的算法会“破坏”张量生成流程,PynguinML做了3处修改:
- 禁止张量序列交叉:如果交叉操作切断了“嵌套列表→张量”的流程,就丢弃后续语句,重新生成;
- 针对性突变:比如嵌套列表只改元素值、不改形状(避免维度违规),无符号整数突变后仍非负;
- 概率平衡:75%概率生成合规输入(测核心逻辑),25%生成非合规输入(测错误处理)。
主要成果:PynguinML到底有多厉害?
论文在165个ML模块(PyTorch 53个、TensorFlow 112个)上做了实验,结果用“碾压式优势”形容毫不夸张:
1. 分支覆盖率大幅提升
对比3类工具的平均分支覆盖率,PynguinML优势明显:
| 工具 | 平均分支覆盖率 | 相对Pynguin提升 |
|---|---|---|
| PynguinML | 38.6% | +15.6%(最高+63.9%) |
| Pynguin(原工具) | 33.4% | - |
| MuTester(同类方案) | 31.4% | - |
更关键的是:在165个模块中,108个模块的覆盖率被PynguinML优化(其中77个优化效果统计显著),只有34个模块略逊于Pynguin(仅9个显著)。
2. 合规测试用例更多
在10个随机抽样模块中,PynguinML生成的合规用例比Pynguin多10%左右,同时非合规用例也有增加(因为用例总数提升):
| 库名 | 工具 | 总用例数 | 合规用例数 | 非合规用例数 |
|---|---|---|---|---|
| PyTorch | Pynguin | 114 | 75 | 30 |
| PyTorch | PynguinML | 124 | 80 | 36 |
| TensorFlow | Pynguin | 154 | 107 | 42 |
| TensorFlow | PynguinML | 180 | 121 | 45 |
这些合规用例能直接覆盖ML函数的核心计算逻辑,而非合规用例则能测试参数校验、异常抛出等边缘场景——两者结合,让测试更全面。
3. 给领域带来的实际价值
- 对ML库开发者:不用手动写测试用例,PynguinML能自动生成有效测试,大幅降低回归测试工作量;
- 对研究者:提供了“文档约束+搜索式测试生成”的新范式,可扩展到其他有严格输入约束的领域(如数据库、web API);
- 对使用者:间接提升ML库的稳定性——更多有效测试能提前发现潜在bug(如输入边界值处理错误)。
关键问题(Q&A)
Q1:为什么Pynguin在测试PyTorch/TensorFlow时会生成“无效用例”?
A:因为Pynguin是通用Python测试工具,没有针对ML库的特殊逻辑——它不知道“张量”是什么,也不懂dtype“ndim”这些约束,只会按通用数据类型(int、str、None等)随机生成输入,自然容易违规。
Q2:PynguinML的约束是从哪来的?如果API文档写错了,会不会影响测试效果?
A:约束来自DocTer工具(论文前期工作),它能从PyTorch/TensorFlow的官方API文档中提取约束,准确率达85.4%。如果文档写错(比如把float32写成float64),确实会导致约束错误——但论文通过“约束验证”步骤,能剔除明显矛盾的约束,降低误差影响。
Q3:合规和非合规测试用例,哪个更重要?
A:两者都重要,是“互补关系”:
- 合规用例:覆盖ML函数的核心计算逻辑(如张量运算、模型推理),是测试的“核心目标”;
- 非合规用例:覆盖输入校验、异常处理逻辑(如参数错误时的报错信息是否正确),能发现边缘场景的bug。
PynguinML的25%非合规概率,就是为了平衡两者。
Q4:PynguinML能测试所有ML库吗?比如MindSpore、JAX?
A:目前还不能,论文只验证了PyTorch(v1.13.0)和TensorFlow(v2.8.0)。但它的思路有通用性——只要能从其他ML库的API文档中提取约束(比如用DocTer适配新库),就能扩展支持,只是需要针对新库的张量类型调整生成逻辑。
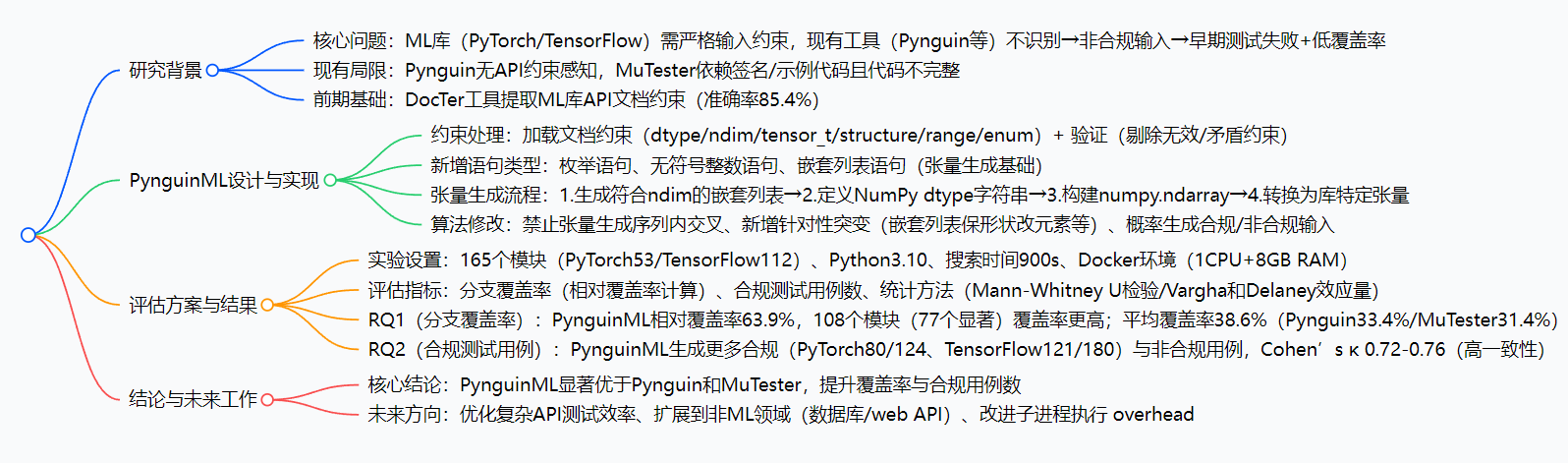
思维导图
3. 详细总结
1. 引言:研究背景与动机
- 问题提出:机器学习(ML)库(如PyTorch、TensorFlow)是现代应用的核心,但其API存在严格输入约束(如张量数据类型、维度、形状等);现有自动化单元测试生成工具(如Pynguin)无法识别这些约束,常生成非合规输入(如用
None作为张量参数),导致早期测试失败和低代码覆盖率。 - 示例佐证:以PyTorch的
torch.nn.functional.glu函数为例,Pynguin生成的测试用例(图1b)传入None,触发异常后标记为@mark.xfail,无法覆盖函数核心逻辑;而PynguinML生成的合规用例(图2)通过嵌套列表→NumPy数组→PyTorch张量的流程,满足约束并覆盖核心代码。 - 研究目标:设计PynguinML,作为Pynguin的扩展,利用从API文档提取的约束生成合规输入,提升ML库测试的有效性与代码覆盖率。
2. 背景知识
2.1 ML库的API约束
ML库API约束分为两类,是测试生成的关键依据:
- 数据结构约束:要求输入为特定类型,如内置类型(
int/str)或库特定类型(torch.Tensor/tf.Tensor)。 - 属性约束:包括数据类型(如
torch.float32)、张量维度(ndim,如2维对应形状(3,4))、数值范围(如[0,1])、枚举值(预定义允许值)。
2.2 Python单元测试生成工具
- Pynguin:Python领域主流工具,基于搜索式软件工程(SBSE),采用反馈导向随机生成、DynaMOSA进化算法,目标是最大化分支覆盖率;但不考虑API文档约束,导致非合规输入。
- MuTester:基于Pynguin的ML库测试工具,依赖签名约束(正则提取)、文档约束、示例代码输入;但不公开完整代码,且PynguinML无需依赖签名与示例代码,仅聚焦文档约束。
3. PynguinML的设计与实现
3.1 约束加载与验证
- 约束来源:采用DocTer工具从PyTorch、TensorFlow文档中提取的约束,涵盖
dtype(数据类型)、ndim(维度数)、tensor_t(是否为张量)等6类属性。 - 约束验证:初始化阶段剔除无效约束,包括语法错误、未定义类型、逻辑矛盾(如维度为负、数值范围
[1,0])。
3.2 输入生成改进
- 基础类型优化:对primitive类型(如
float)施加范围约束,例如生成[0.0,1.0]内的随机浮点数。 - 新增语句类型:针对ML场景设计3类语句,解决特殊约束需求:
- 枚举语句:从预定义枚举值中选择输入(如特定字符串选项)。
- 无符号整数语句:生成非负整数,满足无符号 dtype 约束。
- 嵌套列表语句:生成符合
ndim约束的嵌套列表,作为张量的通用中间表示。
- 张量生成流程(标准化步骤):
- 生成符合
ndim约束的嵌套列表; - 定义NumPy dtype字符串(如
"float32"); - 构建
numpy.ndarray; - 调用库特定函数(如
torch.tensor)转换为张量。
- 生成符合
3.3 算法修改
- 交叉操作限制:禁止在张量生成序列内进行交叉,若交叉点在序列中,丢弃后续语句并重新生成。
- 突变功能增强:
- 嵌套列表:突变元素值但保留形状;
- 枚举语句:切换为其他允许值;
- 无符号整数:突变后仍为非负;
- 依赖处理:若删除张量创建语句,同步删除后续依赖语句。
- 合规/非合规输入平衡:概率性选择生成合规输入(覆盖核心逻辑)或非合规输入(覆盖输入验证逻辑),默认25%概率生成非合规输入。
4. 评估:实验设计与结果
4.1 实验设置
| 配置项 | 具体内容 |
|---|---|
| 目标库与版本 | PyTorch v1.13.0、TensorFlow v2.8.0(兼容Python 3.10) |
| 目标模块数量 | 165个(PyTorch 53个、TensorFlow 112个,筛选标准:至少1个API有约束) |
| 实验环境 | Docker容器(Python 3.10.16)、AMD EPYC 7443P CPU(单核心)、8GB RAM |
| 关键参数 | 搜索时间900s(补偿子进程执行 overhead)、最大张量维度5、每维度最大尺寸5 |
| 重复次数 | 每个模块执行20次(PynguinML与Pynguin各20次) |
| 评估指标 | 分支覆盖率(相对覆盖率计算)、合规测试用例数、Cohen’s κ(一致性检验) |
| 统计方法 | Mann-Whitney U检验(α=0.05)、Vargha和Delaney效应量(A^12\hat{A}_{12}A^12) |
4.2 RQ1:分支覆盖率对比
- 核心结果:PynguinML显著提升分支覆盖率,具体数据如下表:
对比维度 数值/结论 相对覆盖率提升 最高达63.9% 平均分支覆盖率 PynguinML 38.6% vs Pynguin 33.4% vs MuTester 31.4% vs PyEvosuite 26.3% 模块性能优势 108个模块(77个显著)覆盖率更高;仅34个模块(9个显著)Pynguin更优 Vargha和Delaney效应量 总效应量A^12=0.675\hat{A}_{12}=0.675A^12=0.675(PyTorch 0.631、TensorFlow 0.697),正向效应 - 补充发现:PynguinML在PyTorch早期(0-300s)覆盖率增长更快,在TensorFlow全时段保持稳定优势;覆盖率分布更集中于中高区间(Pynguin分布更分散,低覆盖率占比高)。
4.3 RQ2:合规测试用例对比
- 核心数据(基于10个随机模块/库的抽样):
| 库名 | 工具 | 生成用例总数 | 合规用例数 | 非合规用例数 | Cohen’s κ(一致性) |
|------------|-----------|--------------|------------|--------------|---------------------|
| PyTorch | Pynguin | 114 | 75 | 30 | 0.720 |
| PyTorch | PynguinML | 124 | 80 | 36 | 0.720 |
| TensorFlow | Pynguin | 154 | 107 | 42 | 0.760 |
| TensorFlow | PynguinML | 180 | 121 | 45 | 0.760 |
| 总计 | Pynguin | 268 | 182 | 72 | 0.730 |
| 总计 | PynguinML | 304 | 201 | 81 | 0.730 | - 关键结论:PynguinML在相同时间内生成更多合规用例(提升约10%),同时生成更多非合规用例(因整体覆盖率提升导致用例总数增加);两类用例互补:合规用例覆盖核心逻辑,非合规用例覆盖输入验证与错误处理。
4.4 有效性威胁
- 内部有效性:与MuTester对比存在版本差异(Pynguin新版本)、子进程 overhead;手动分析合规用例通过双人独立验证降低误差。
- 外部有效性:仅覆盖PyTorch/TensorFlow,未扩展到其他ML库;依赖DocTer的约束数据,未覆盖无约束模块。
- 构造有效性:DocTer约束准确率85.4%(存在少量错误),且约束版本与测试库版本存在小幅差异(PyTorch 1.5→1.13,TensorFlow 2.1→2.8)。
5. 相关工作与结论
5.1 相关工作
- DocTer:文档引导的ML API模糊测试工具,生成合规/非合规输入,但仅用于模糊测试,不生成单元测试(无法用于回归测试)。
- MuTester:基于Pynguin的ML测试工具,依赖签名、文档、示例代码约束,但代码不完整,覆盖率低于PynguinML。
5.2 结论与未来工作
- 核心结论:PynguinML通过整合API文档约束,显著提升ML库单元测试的分支覆盖率(最高63.9%)与合规用例数,性能优于Pynguin和MuTester。
- 未来方向:
- 优化复杂API(如
torch.nn.functional.interpolate,圈复杂度38)的测试生成效率; - 扩展到非ML领域(如数据库、web API),适配不同领域的约束类型;
- 改进子进程执行方案,降低 overhead 以延长有效搜索时间。
- 优化复杂API(如
4. 关键问题
问题1:PynguinML如何针对性解决现有ML库单元测试生成工具(如Pynguin)的核心痛点?
答案:现有工具的核心痛点是无法识别ML API的严格输入约束,导致生成非合规输入(如None作为张量参数),触发早期异常后无法覆盖核心逻辑,最终低代码覆盖率。PynguinML通过三方面解决:1. 约束整合:加载DocTer从API文档提取的6类约束(dtype/ndim/tensor_t等),并验证剔除无效约束;2. 输入生成优化:新增嵌套列表等3类ML专用语句,设计标准化张量生成流程(列表→NumPy数组→库特定张量),确保输入合规;3. 算法平衡:概率性生成合规输入(覆盖核心逻辑)与非合规输入(覆盖验证逻辑),同时修改交叉/突变规则避免张量生成序列失效。最终实现高达63.9%的覆盖率提升,解决早期失败与低覆盖率问题。
问题2:在分支覆盖率评估(RQ1)中,PynguinML与Pynguin、MuTester的具体性能差异体现在哪些关键数据上?
答案:三者的关键性能差异如下:1. 平均分支覆盖率:PynguinML(38.6%)> Pynguin(33.4%)> MuTester(31.4%)> 基线PyEvosuite(26.3%);2. 模块优势范围:PynguinML在165个模块中的108个(77个统计显著)覆盖率更高,仅34个模块(9个显著)落后于Pynguin;3. 效应量与增长趋势:PynguinML的Vargha和Delaney效应量A^12=0.675\hat{A}_{12}=0.675A^12=0.675(正向效应),且在PyTorch早期(0-300s)覆盖率增长更快,在TensorFlow全时段保持稳定优势;4. 覆盖率分布:PynguinML的覆盖率分布更集中于中高区间,而Pynguin分布分散且低覆盖率占比高(尤其TensorFlow)。
问题3:PynguinML为何在生成更多合规测试用例的同时,也会增加非合规用例数量?两类测试用例在ML库测试中分别承担什么作用?
答案:1. 非合规用例增加的原因:PynguinML通过约束引导提升了整体代码覆盖率,使得测试用例总数增加(如TensorFlow模块中,Pynguin生成154个用例,PynguinML生成180个),且其设计了概率性生成机制(默认25%概率),在优先生成合规用例的同时保留非合规输入的生成逻辑,因此非合规用例数量随总数同步增加。2. 两类用例的作用:- 合规用例:满足API的约束要求(如正确维度的张量),能够通过输入验证逻辑,进而覆盖ML函数的核心计算逻辑(如glu函数的张量处理逻辑),是提升代码覆盖率的关键;- 非合规用例:故意违反约束(如维度为负的张量、错误数据类型),用于触发API的输入验证与错误处理逻辑(如参数检查、异常抛出),补充覆盖合规用例无法触及的分支,确保ML库在异常输入下的鲁棒性。两者互补实现对ML库的全面测试。
总结
PynguinML的核心贡献,是打通了“API文档约束”与“ML库自动化测试”之间的壁垒:它没有发明新的测试生成算法,而是针对ML库的“痛点”(严格输入约束),用文档约束指导输入生成,让工具从“盲盒式”测试变成“精准式”测试。
实验结果证明,这种思路非常有效——最高63.9%的覆盖率提升、更多合规用例,不仅解决了传统工具的“无效测试”问题,还为其他有严格输入约束的领域(如数据库、web API)提供了可复用的方案。
未来如果PynguinML开源,很可能成为ML库开发者的“标配测试工具”——毕竟,谁不想用自动化测试覆盖更多代码,又不用手动写一堆约束校验呢?

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 2
2 0
0- 0



 已为社区贡献52条内容
已为社区贡献52条内容

所有评论(0)