OpenAgent:完全开源的企业级智能体应用框架
在大模型技术落地的浪潮中,企业开发者面临着一个核心困境:是选择功能强大但商业受限的开发引擎,如Dify/n8n等,还是选择简单易用但无法私有部署的SaaS服务,如coze?今天介绍的OpenAgent提供了一个全新的选择——一个完全开源的企业级智能体应用框架:
- 集成智能问答、智能问数、知识库、工作流编排和智能体编排的大模型一站式平台。
- 采用Vue.js + FastAPI + PostgreSQL+Langchain/LangGraph等主流技术栈。
- 专为企业级应用设计,代码完全开源,支持私有化部署,可灵活扩展及二次开发。
- 内置完善用户认证和权限管理(RBAC),用户数据隔离,确保数据安全。
🚀 不仅仅是引擎,更是完整产品
OpenAgent本身就是一个完整的全栈应用,而非单纯的开发引擎或工具包。
企业开发者无需从零开始耗费数月搭建基础架构,OpenAgent 的前后端代码完全开放,无任何绑定或锁定的插件依赖,企业可基于自身需求进行任意程度的定制化开发与扩展,真正实现技术栈的自主可控。通过简单的部署,您即可获得一个功能完备、开箱即用的企业级AI应用,大幅降低研发成本与上线周期。
🏗️ 技术架构
后端技术栈
- Web框架: FastAPI + SQLAlchemy + Alembic
- 数据库: PostgreSQL 16+ (开源关系型数据库)
- 向量数据库: PostgreSQL + pgvector 扩展 (开源向量数据库)
- 智能体编排: LangGraph 状态图 + 条件路由
- 工具调用: Langchain Function Calling
- 数据库MCP: postgresql MCP (Model Context Protocol)
- 倒排索引检索:Postgresql BM25
- 对话记忆: ConversationBufferMemory
- 文档处理: PyPDF2 + python-docx + markdown
- 数据分析: Pandas + NumPy
前端技术栈
- 框架: Vue 3 + TypeScript + Vite
- UI组件: Element Plus (开源UI库)
- HTTP客户端: Axios
- 工作流编辑器: 可视化编辑器
- 工作流引擎: 基于DAG的流程执行引擎
- 图形渲染: Canvas API + SVG
- 拖拽交互: Vue Draggable
- 节点连接: 自定义连线算法
✨ 核心能力
🤖 智能问答
- 多模型支持:支持兼容OpenAI协议的所有大模型,包括DeepSeek、智谱AI、豆包等国内主流AI服务商
- 三种对话模式:
- 自由对话:直接与AI模型交互
- RAG对话:基于知识库的检索增强生成
- 智能体对话:智能体自动规划协作处理复杂任务
- 多轮对话:支持连续对话,上下文理解和记忆
- 对话历史:完整的会话记录和管理
🌟 技术特色
基于LangGraph的智能体对话系统
- 自主规划能力:智能体能够根据任务需求自主调用工具并规划执行流程
- 动态工具调用:根据上下文自动选择最合适的工具并执行
- 多步任务分解:复杂任务自动拆解为多个子任务并顺序执行
- 自动纠错能力:在执行过程中自动检测并修复错误,通过重试机制或替代方案确保任务顺利完成
- 思维链可视化:完整展示智能体的思考过程和决策路径,让每一步推理和工具调用都对用户清晰可见,提升决策透明度
示例场景:
当用户询问"推荐长沙和北京哪个适宜旅游"时:
- 智能体首先调用搜索工具查找相关信息
- 未找到合适结果时,自动规划调用天气查询工具
- 智能拆分为两次执行:先查询长沙天气,再查询北京天气
- 根据气温数据判断北京更适宜旅游
- 自动调用搜索工具查找北京景点信息
- 最终整合所有信息生成总结推荐
第一步:调用搜索引擎工具去查找哪个城市更适合旅游
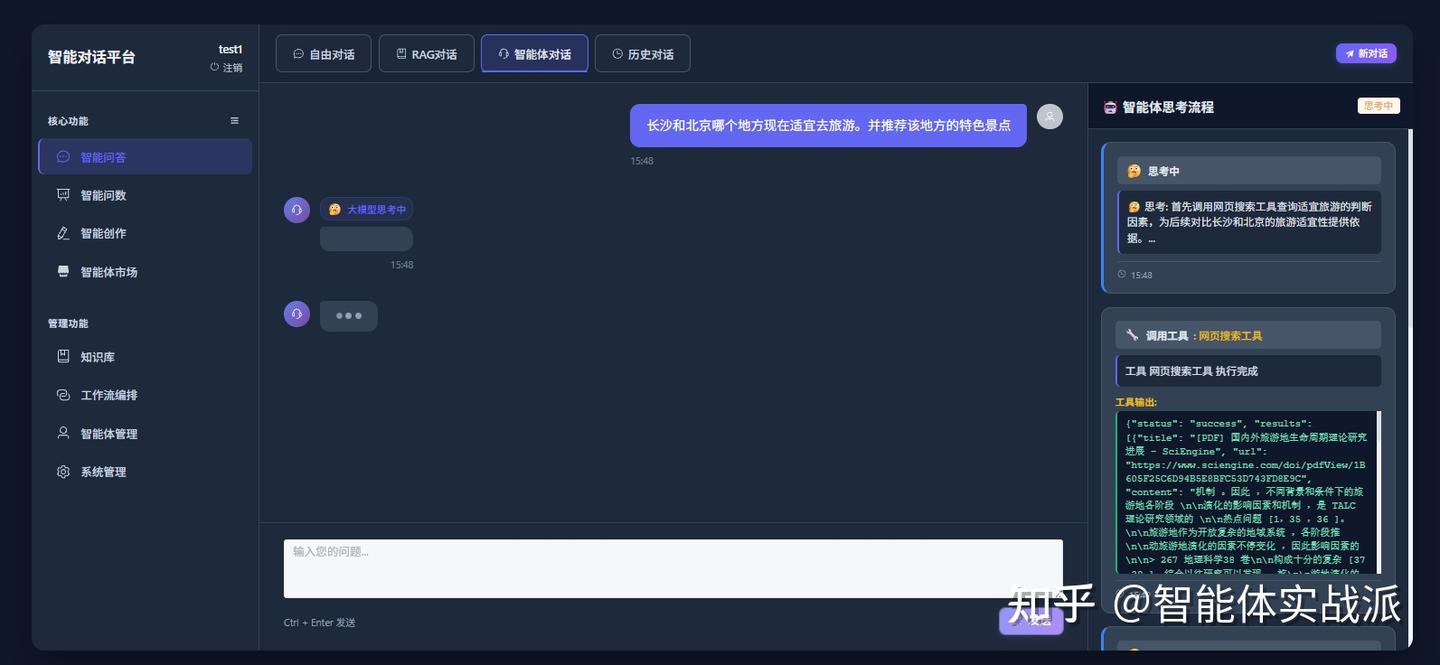
第二步:搜索的内容没有找到合适的答案,意识到错了后,改变策划,重新调用天气工具,从天气的角度判断哪个城市更适合当下旅游 。
并且自动进行任务拆解,对北京、长沙分别调用一次天气工具,获取到两个城市的天气情况。
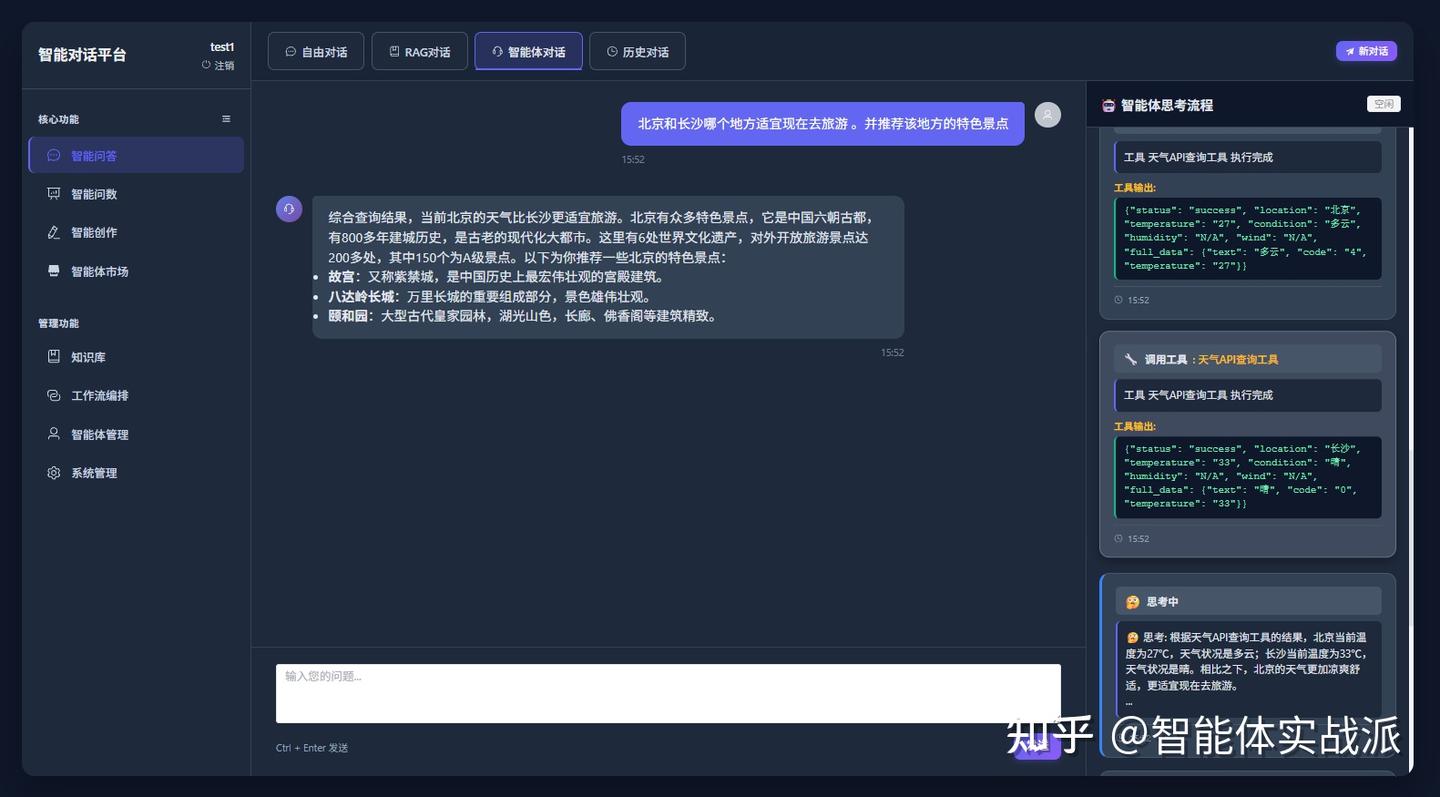
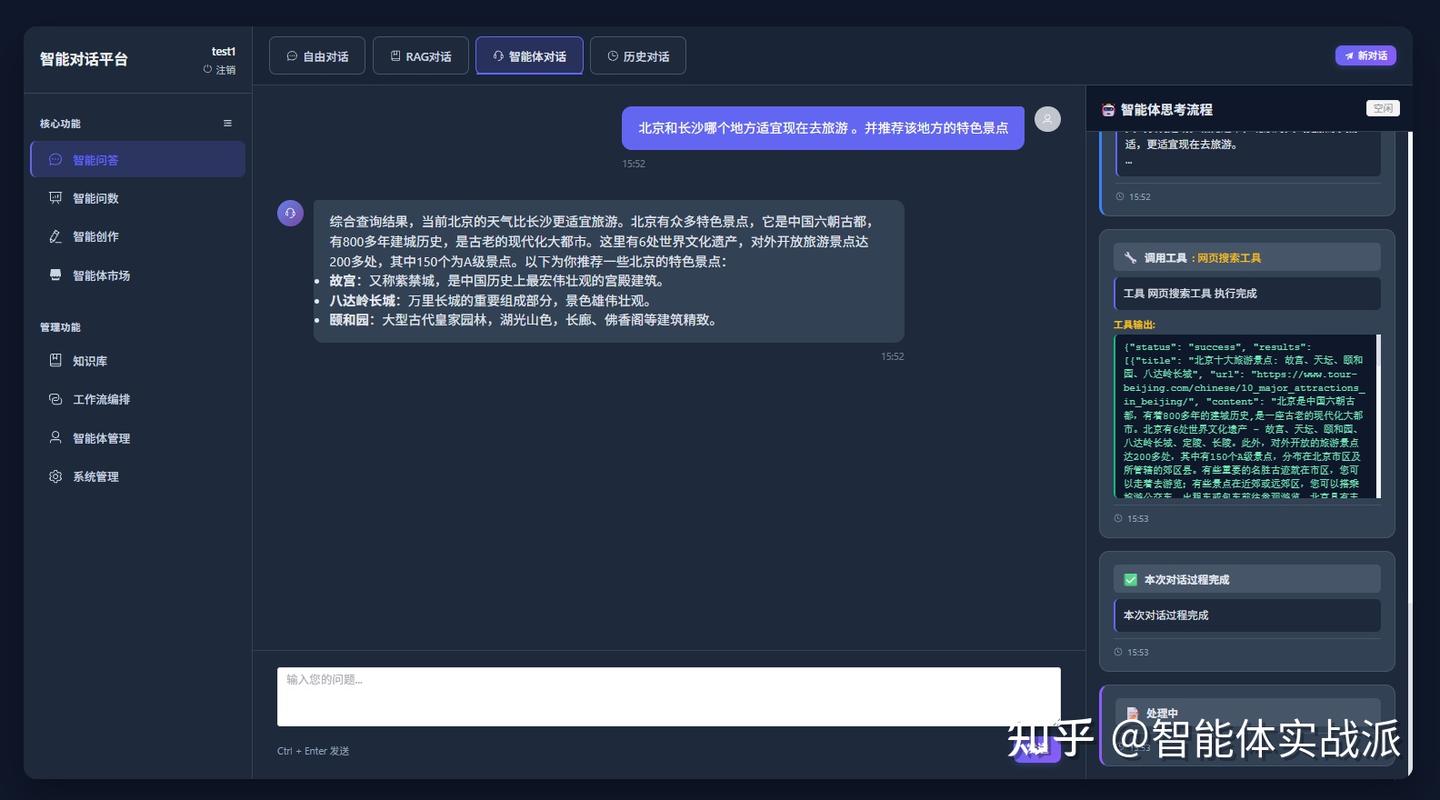
第三步:根据天气判断北京更适合旅游,再调用搜索引擎工具,搜索北京的特色景点。最后将工具调用结果与问题进行总结,完成本次对话过程。
📊 智能问数
智能问数是OpenAgent项目的核心功能模块,致力于解决企业数据查询与分析的核心痛点,让非技术人员也能通过自然语言与数据进行深度对话。
🌟 技术特色
双引擎智能问数系统
基于Excel的智能问数
- 使用LangChain代码解释器插件,将Excel数据读取到Pandas DataFrame
- 大模型将自然语言问题转换为Pandas语法并执行
- 支持多表格文件联合查询和复杂数据分析
- 展示完整的大模型思考工作流
基于数据库的智能问数
- 实现PostgreSQL MCP(Model Context Protocol)接口
- 大模型先提取表元数据,了解表结构和关系
- 根据用户问题自动生成优化SQL查询语句
- 支持多表关联查询和复杂数据检索
- 展示完整的大模型思考工作流
# 基于Excel的智能问数处理流程示例
用户输入:"按项目类型统计2025年的合同总额"
系统自动解析:
1. 语义理解:找到2025年的数据表格,确定合同额,以及项目类型所在的表格列
2. 查询生成:转换为Pandas查询语句
3. 执行优化:调用代码解析器执行python代码
4. 结果呈现:生成可视化图表以及对结果进行总结说明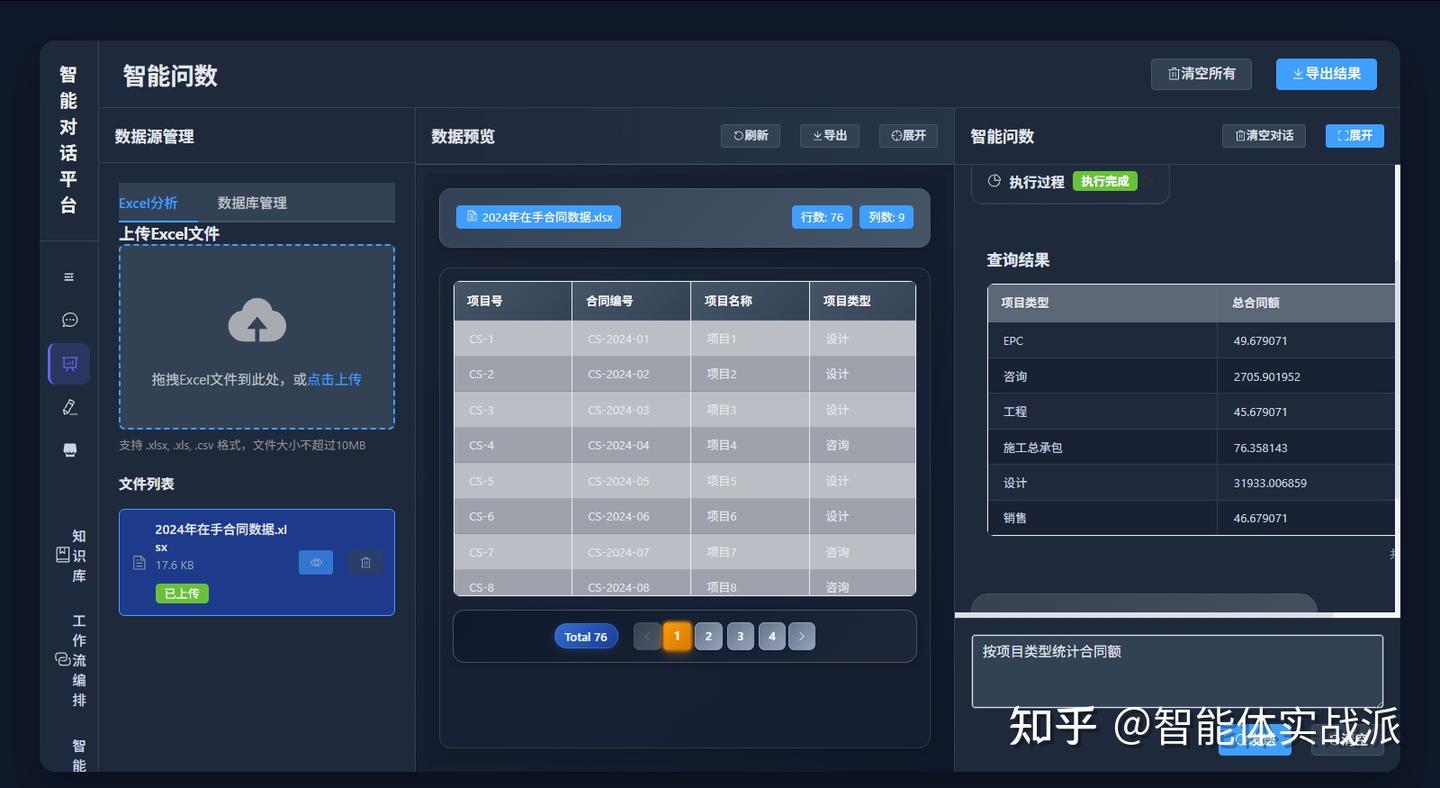
基于Excel表格文件的智能问数
# 基于数据库表的智能问数处理流程示例
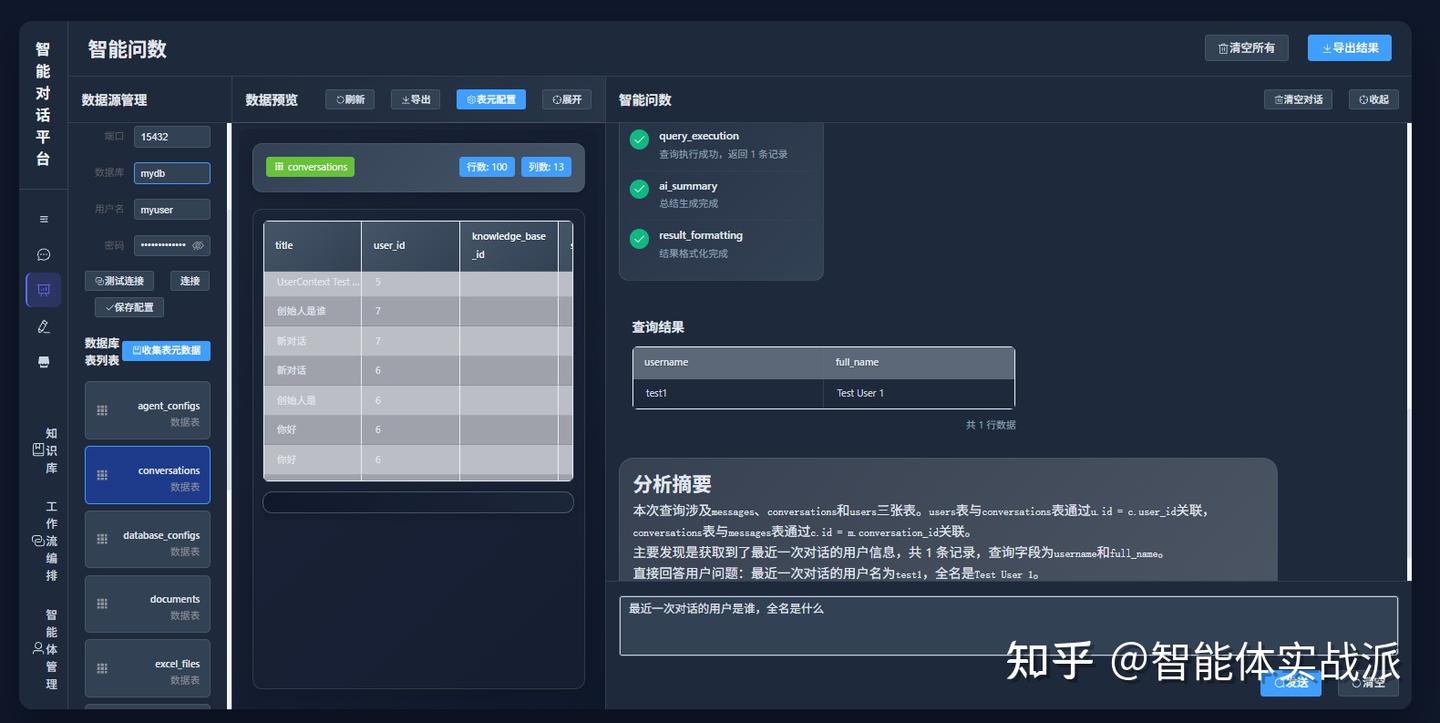
用户输入:"最近一次会话的用户的用户名"
系统自动解析:
1. 语义理解:根据问题找到相关的表:conversation,message,user三张表
2. 根据表元数据找到最终要用到的两张表:message,user两张表
3. 生成关联查询sql:关联message和user表的sql语句,获取最终的username
4. 执行优化:调用代postgresql mcp服务执行sql
5. 结果呈现:生成可视化表格以及对结果进行总结说明
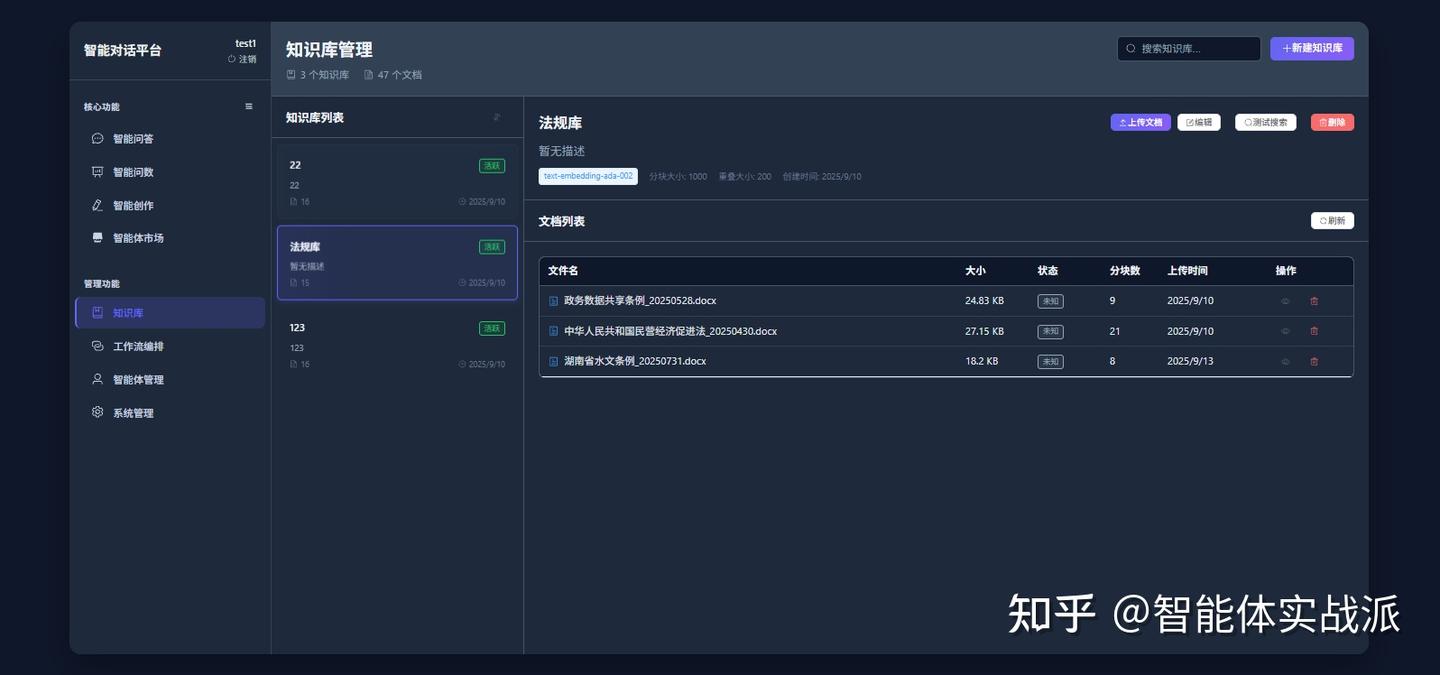
📚 知识库管理
- 文档处理:支持PDF、Word、Markdown、TXT等格式
- 向量存储:基于PostgreSQL + pgvector的向量数据库
- 智能检索:向量相似度搜索和BM25算法关键词检索
- 文档管理:上传、删除、分类和标签管理
- RAG集成:与对话系统无缝集成
🌟 技术特色
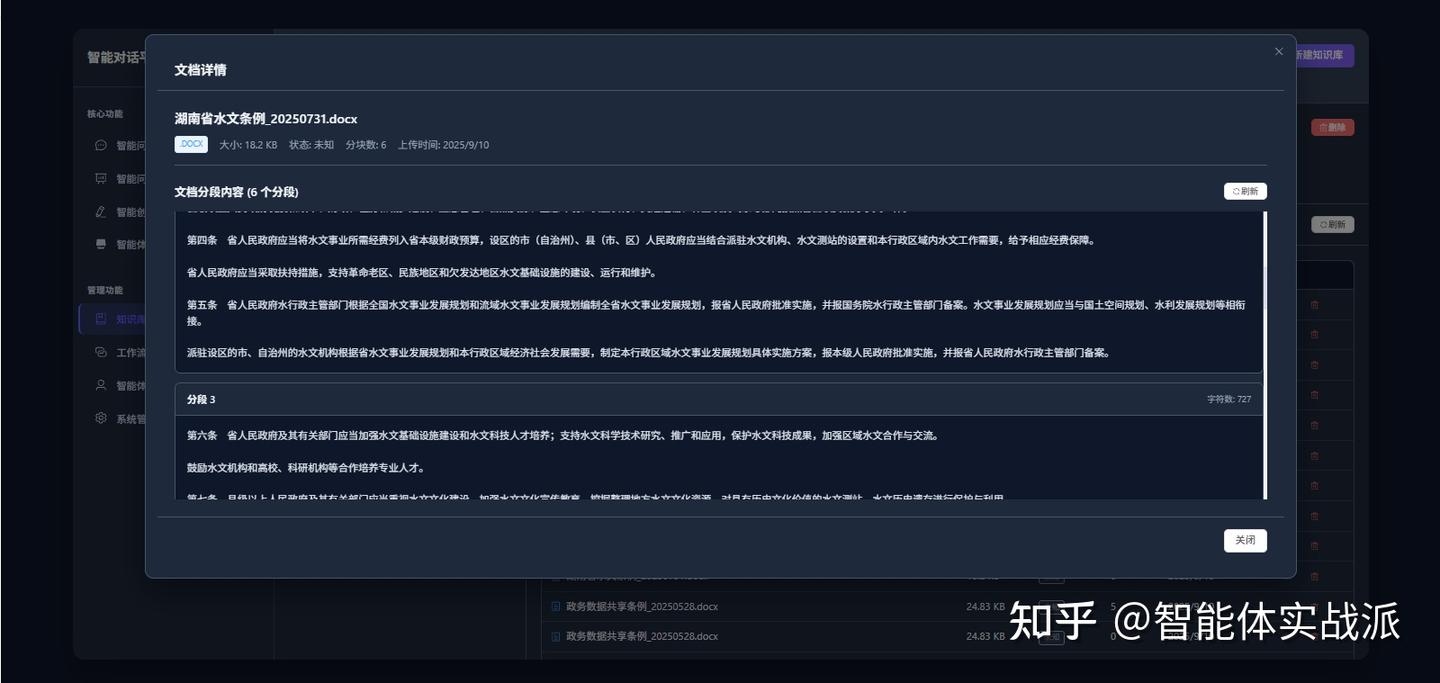
高级语义分割知识库处理
- 智能段落分割:基于大模型的语义理解分割技术,而非传统的文本相似度判断
- 精准切分识别:大模型直接识别最适合的切分位置并输出分割标记字符串
- 高效处理流程:仅输出分割位置字符串,再由代码执行实际分割操作
- 性能优化:避免了传统方法中大量的向量计算和相似度比较,提升处理速度
- 质量保证:大模型的深层语义理解确保分割边界的准确性和合理性
双重召回检索机制
- 多模态检索:结合向量相似度匹配与BM25关键词检索
- 混合排序策略:采用加权融合算法,综合语义相关性和关键词匹配度进行结果排序
- 召回增强:双重召回机制有效解决了单纯向量检索的"词汇不匹配"问题
- 精准度提升:相比单一检索方式,显著提高相关文档的召回率和准确率
知识库文件管理
法律文件智能分割
🔧 工作流编排(待完成)
- 可视化设计:拖拽式工作流设计器
- 节点类型:支持AI对话、数据处理、条件判断等节点
- 流程控制:条件分支、循环、并行执行
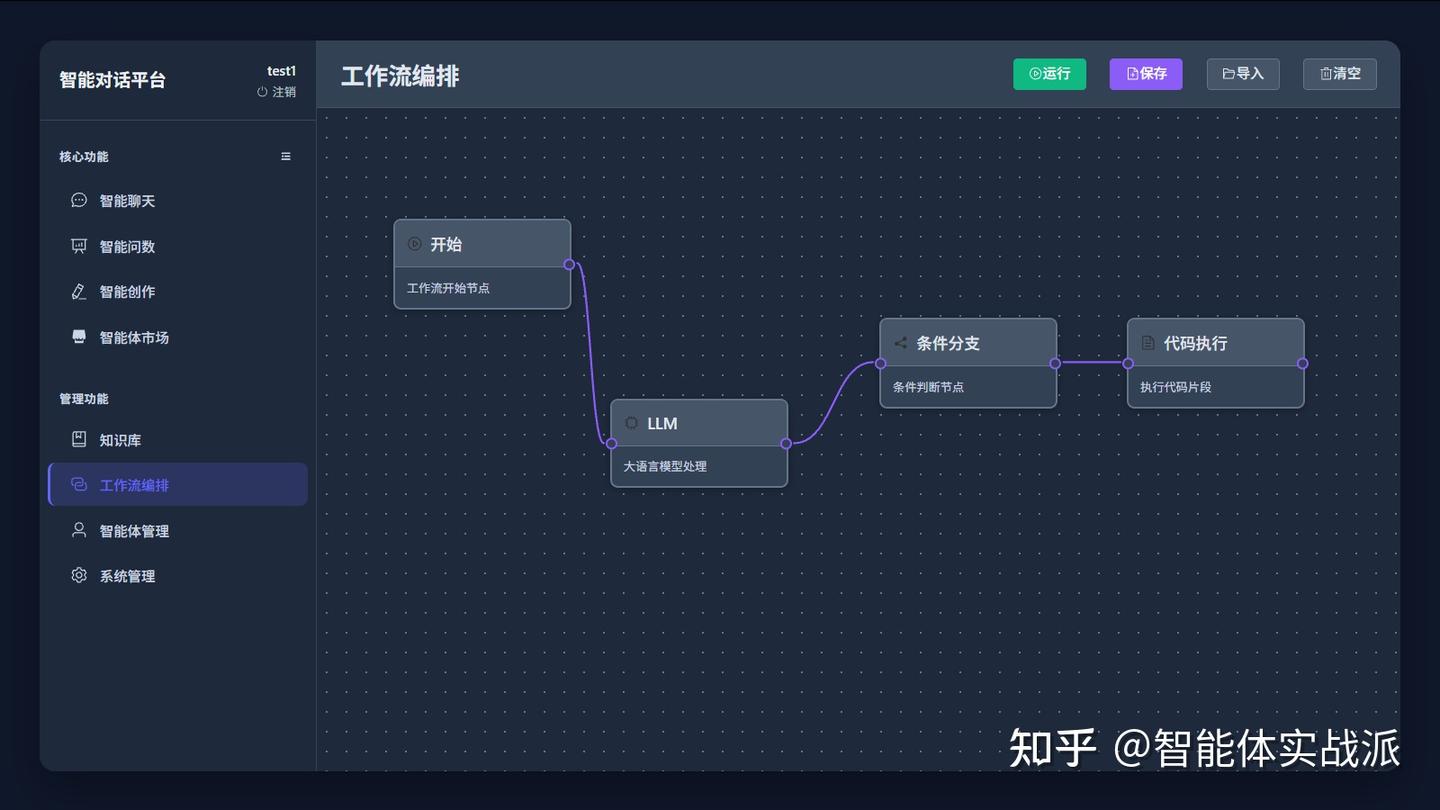
支持对大模型节点、条件分支、代码执行等几种类型节点的自由编排
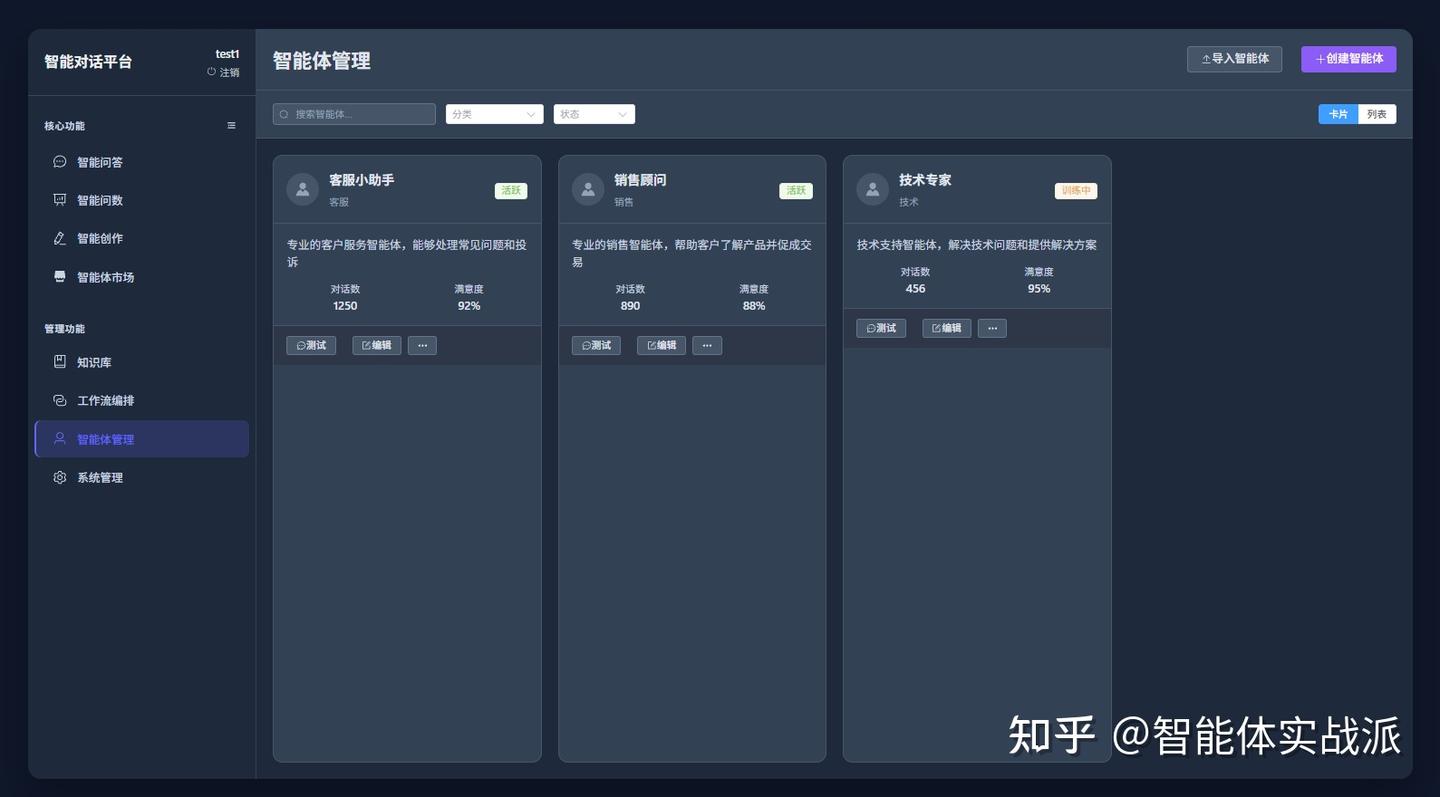
🤖 智能体编排(Todo)
- 多智能体协作:不同专业领域的AI智能体协同工作
- 角色定义:自定义智能体的专业能力和知识领域
- 任务分配:智能分解复杂任务到合适的智能体
- 结果整合:汇总多个智能体的输出生成最终答案
本地源码部署指南
环境要求
- Python 3.10+
- Node.js 18+
- PostgreSQL 16+
1. 安装PostgreSQL和pgvector
方式一:Docker安装(推荐)
使用 Docker + Docker Compose 部署 PostgreSQL 16 + pgvector 插件。
1. 创建docker-compose.yml文件
内容如下:
version: '3.8'
services:
db:
image: pgvector/pgvector:pg16
container_name: pgvector-db
environment:
POSTGRES_USER: myuser
POSTGRES_PASSWORD: your_password
POSTGRES_DB: mydb
ports:
- "5432:5432"
volumes:
- pgdata:/var/lib/postgresql/data
restart: unless-stopped
volumes:
pgdata:说明:
- 使用
pgvector/pgvector:pg16镜像,内置 PostgreSQL 16 + pgvector 插件 - 数据保存在 Docker 卷
pgdata中,重启不会丢失 - 监听宿主机端口 5432,可用本地工具如 pgAdmin, DBeaver, psql 连接
- 默认数据库名称:mydb
- 默认用户名:myuser
- 默认密码:your_password
2. 启动服务
在 docker-compose.yml 所在目录下运行:
docker-compose up -d查看容器状态:
docker ps输出应包含一个名为 pgvector-db 的容器,状态为 Up。
3. 验证 pgvector 安装成功
进入 PostgreSQL 容器:
docker exec -it pgvector-db psql -U myuser -d mydb启用 pgvector 插件:
CREATE EXTENSION IF NOT EXISTS vector;插入并查询向量数据(示例,可以在客户端,如dbeaver等)**
-- 创建表,包含一个向量字段(维度为3)
CREATE TABLE items (
id SERIAL PRIMARY KEY,
embedding vector(3)
);
-- 插入向量数据
INSERT INTO items (embedding) VALUES
('[1,1,1]'),
('[2,2,2]'),
('[1,0,0]');
-- 查询与 [1,1,1] 最接近的向量(基于欧几里得距离)
SELECT id, embedding
FROM items
ORDER BY embedding <-> '[1,1,1]'
LIMIT 3;-- 上述没报错且有结果返回,即安装成功
2. 后端部署
# 克隆项目
git clone https://github.com/lkpAgent/chat-agent.git
cd chat-agent/backend
#创建python虚拟环境,推荐使用conda创建虚拟环境
conda create -n chat-agent python=3.10
conda activate chat-agent
# 安装依赖
pip install -r requirements.txt
# 配置环境变量,windows下直接复制.env.example文件为.env
cp .env.example .env
# 编辑.env文件,配置数据库连接和AI API密钥。相关配置信息见后面的配置说明
# 配置完数据库信息后,初始化数据库表及创建登录账号(用户名: test@example.com, 密码: 123456)
cd backend/tests
python init_db.py
# 启动后端服务,默认8000端口
python -m uvicorn chat_agent.main:app --reload --host 0.0.0.0 --port 8000
# 或者直接运行main.py
# cd backend/chat_agent
# python main.py
3. 前端部署
# 进入前端目录
cd ../frontend
# 安装依赖
npm install
# 配置环境变量
cp .env.example .env
# 编辑.env文件,配置后端API地址
VITE_API_BASE_URL = http://localhost:8000
# 启动前端服务,默认端口3000
npm run dev启动成功后,访问http://localhost:3000,会进入到登录页面,默认账号密码为test@example.com/123456
登录页面
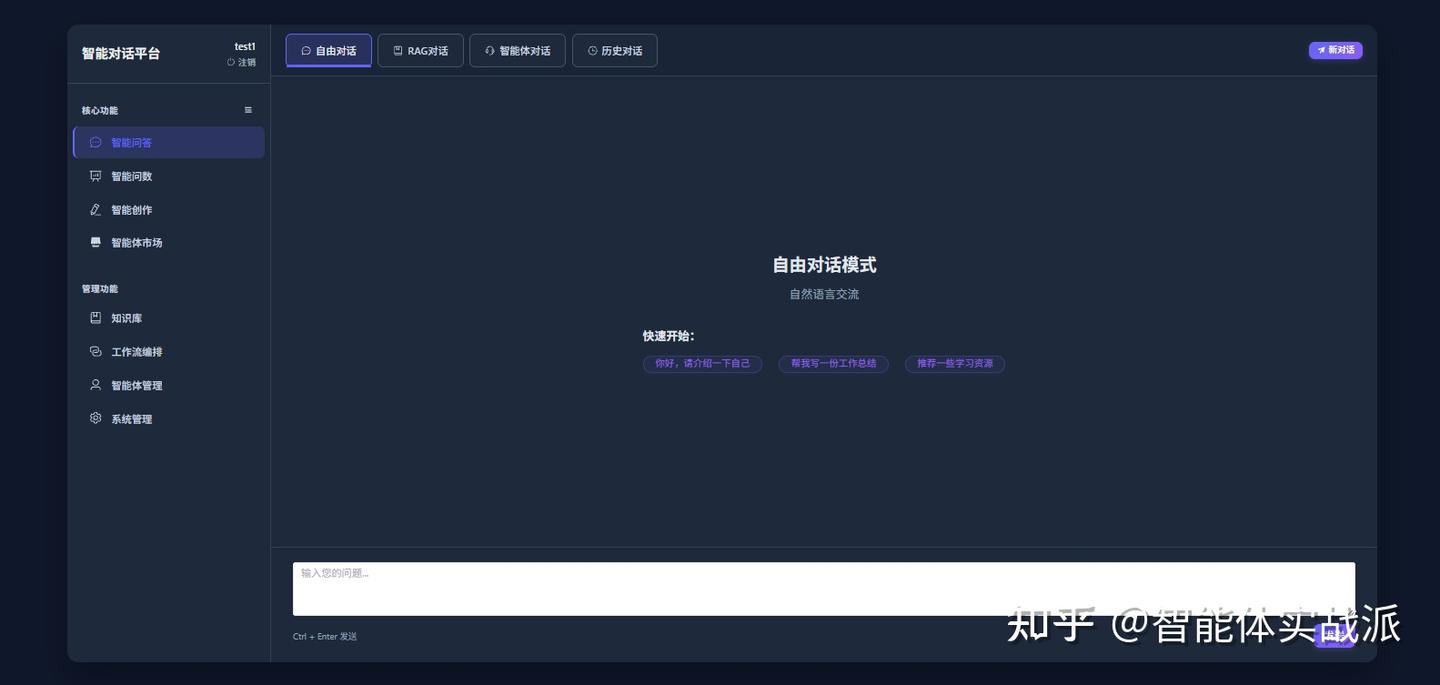
登录后首页
4. 访问应用
- 前端地址: http://localhost:3000
- 后端API: http://localhost:8000
- API文档: http://localhost:8000/docs
5. 后端配置说明
后端环境变量配置 (backend/.env)
# 数据库配置
# ========================================
DATABASE_URL=postgresql://your_username:your_password@your_host:your_port/your_db
# 示例:
# DATABASE_URL=postgresql://myuser:mypassword@127.0.0.1:5432/mydb
# ========================================
# 向量数据库配置
# ========================================
VECTOR_DB_TYPE=pgvector
PGVECTOR_HOST=your_host
PGVECTOR_PORT=your_port
PGVECTOR_DATABASE=mydb
PGVECTOR_USER=myuser
PGVECTOR_PASSWORD=your_password
# 大模型配置 (支持OpenAI协议的第三方服务) 只需要配置一种chat大模型以及embedding大模型
# ========================================
# chat大模型配置
# ========================================
# 可选择的提供商: openai, deepseek, doubao, zhipu, moonshot
LLM_PROVIDER=doubao
# Embedding模型配置
# ========================================
# 可选择的提供商: openai, deepseek, doubao, zhipu, moonshot
EMBEDDING_PROVIDER=zhipu
# OpenAI配置
OPENAI_API_KEY=your-openai-api-key
OPENAI_MODEL=gpt-4
OPENAI_BASE_URL=https://api.openai.com/v1
OPENAI_EMBEDDING_MODEL=text-embedding-ada-002
# 智谱AI配置
ZHIPU_API_KEY=your-zhipu-api-key
ZHIPU_MODEL=glm-4
ZHIPU_EMBEDDING_MODEL=embedding-3
ZHIPU_BASE_URL=https://open.bigmodel.cn/api/paas/v4
# DeepSeek配置
DEEPSEEK_API_KEY=your-deepseek-api-key
DEEPSEEK_BASE_URL=https://api.deepseek.com/v1
DEEPSEEK_MODEL=deepseek-chat
DEEPSEEK_EMBEDDING_MODEL=deepseek-embedding
# 豆包配置
DOUBAO_API_KEY=your-doubao-api-key
DOUBAO_BASE_URL=https://ark.cn-beijing.volces.com/api/v3
DOUBAO_MODEL=doubao-1-5-pro-32k-250115
DOUBAO_EMBEDDING_MODEL=doubao-embedding
# Moonshot配置
MOONSHOT_API_KEY=your-moonshot-api-key
MOONSHOT_BASE_URL=https://api.moonshot.cn/v1
MOONSHOT_MODEL=moonshot-v1-8k
MOONSHOT_EMBEDDING_MODEL=moonshot-embedding
# 工具API配置
## tavilySearch api
TAVILY_API_KEY=your-tavily-api-key
## 心知天气api
WEATHER_API_KEY=your_xinzhi_api_key项目结构
chat-agent/
├── backend/ # 后端代码
│ ├── chat_agent/ # 主应用包
│ │ ├── api/ # API路由
│ │ ├── core/ # 核心配置
│ │ ├── db/ # 数据库相关
│ │ ├── models/ # 数据库模型
│ │ ├── services/ # 业务逻辑
│ │ ├── utils/ # 工具函数
│ │ └── main.py # 应用入口
│ ├── tests/ # 测试文件
│ └── requirements.txt # Python依赖
├── frontend/ # 前端代码
│ ├── src/
│ │ ├── components/ # Vue组件
│ │ ├── views/ # 页面组件
│ │ │ ├── chat/ # 对话页面
│ │ │ ├── knowledge/ # 知识库页面
│ │ │ ├── workflow/ # 工作流页面
│ │ │ └── agent/ # 智能体页面
│ │ ├── stores/ # Pinia状态管理
│ │ ├── api/ # API调用
│ │ ├── types/ # TypeScript类型
│ │ └── router/ # 路由配置
│ └── package.json # Node.js依赖
├── data/ # 数据目录
│ ├── uploads/ # 上传文件
│ └── logs/ # 日志文件
└── docs/ # 文档目录
🌟 与同类平台的差异化优势
对比Dify
- 优势:OpenAgent提供完整的前后端应用,而Dify更偏向后端引擎
- 场景:企业需要快速获得完整解决方案而非开发平台时
对比Coze
- 优势:OpenAgent支持私有化部署和深度定制,Coze为闭源SaaS
- 场景:对数据安全有严格要求的企业环境
对比n8n
- 优势:OpenAgent专注于AI原生应用,n8n更侧重通用自动化
- 场景:需要深度AI能力而非工作流自动化的场景
📄 许可证
本项目采用 MIT License 许可证,这意味着:
- 可以自由使用、修改、分发
- 可以用于商业目的
- 只需保留原始许可证声明
- 作者不承担任何责任
源码地址:
https://github.com/lkpAgent/OpenAgentgithub.com/lkpAgent/openAgent

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)