【论文精读】MotionSight: Boosting Fine-Grained Motion Understanding in Multimodal LLMs
本文是对论文《MotionSight: Boosting Fine-Grained Motion Understanding in Video-LLMs via Motion-Centric Data Curation》的精读解析。该研究针对多模态大模型在视频细粒度运动理解上的局限,提出创新的零样本增强方法MotionSight,并构建首个大规模运动感知数据集MotionVid-QA。本文旨在系统
标题:MotionSight: Boosting Fine-Grained Motion Understanding in Multimodal LLMs
发表会议:**
论文链接:https://arxiv.org/abs/2506.01674v1代码地址与数据集:后继会开源
关键词:细粒度运动理解、运动解耦、视觉聚光灯、运动模糊提示、零样本增强、物体运动聚焦、相机运动感知、MotionVid-QA数据集、多模态大模型(MLLM)、视频理解基准、帧间差异感知、视觉提示工程、SFT与DPO训练、分层标注、开放域视频分析
一、问题提出:从“看到了什么”到“发生了什么”——视频理解的范式跃迁
在多模态大模型时代,图像理解已进入“超人类”阶段。然而,当我们将目光从静态图像转向视频时,一个核心问题浮现:我们是否真的“看懂”了视频?
传统视频理解模型(Video-LLMs)擅长回答“谁、在哪里、有什么”这类静态问题,却在“如何运动、何时变化、为何发生”等动态问题上频频失分。例如:
- “球是被踢飞的,还是被风吹起的?”
- “相机是在后退,还是物体在靠近?”
- “两只手是如何协作完成动作的?”
这些问题的本质是细粒度运动理解(Fine-Grained Motion Understanding),它要求模型具备对物体运动轨迹、速度变化、相互作用、相机运动模式的感知与推理能力。
然而,当前主流Video-LLMs的训练数据多为“视频-标题”配对,标题往往只描述事件类别(如“一个人在踢球”),而缺乏对运动过程的精细描述。这导致模型在训练阶段就“学会了忽略动态细节”。
本文提出了一种数据导向的策略:不是改进模型架构,而是重构训练数据本身。通过构建一个以“运动”为核心的高质量数据集,来提升模型的动态感知能力。
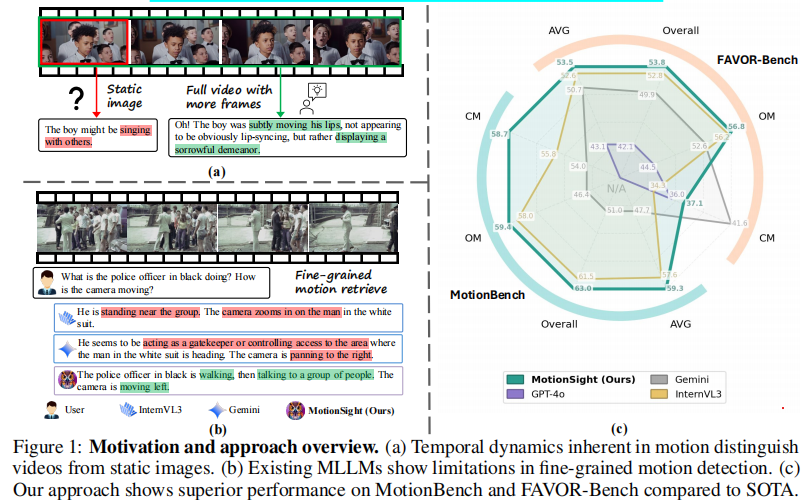
实验表明:
- (a) 运动的动态特性:对比静态图像与视频,强调视频的时间维度是其核心特征。例如,男孩嘴唇的细微移动(如悲伤表情)在单帧中难以察觉,但在视频中可被捕捉。
- (b) 现有模型的局限性:指出当前多标签学习模型在细粒度运动检测上的不足,容易忽略微妙线索。
- (c) 本文方法优势:展示MotionSight在MotionBench和FAVOR-Bench上的优异表现,优于SOTA模型。
二、问题分析:为什么现有模型“看不见”运动?
2.1 视觉编码的“帧间盲区”
大多数Video-LLMs采用“稀疏采样+独立编码”策略:从视频中采样若干关键帧,分别通过图像编码器(如ViT)编码,再送入语言模型。这种架构存在根本性缺陷:
- 缺乏帧间动态建模:模型无法直接感知相邻帧之间的像素变化(即光流);
- 静态特征主导:编码器更关注物体类别、颜色、纹理等静态特征,而非运动;
- 时间信息稀疏:稀疏采样导致运动细节丢失,尤其对高速运动或短时动作。
2.2 训练数据的“语义粗粒度”
现有视频-文本数据集(如WebVid、HowTo100M)的文本描述多为:
“A man is playing basketball.”
这类描述关注事件类别,而非运动过程。模型在训练中从未被要求描述:
“The player dribbles the ball with his right hand, then makes a quick crossover to the left before shooting a three-pointer.”
因此,模型在推理时自然无法生成此类细节。
三、方法设计:Motion-Centric 数据构建范式
MotionSight的核心是Motion-Centric Data Curation,即以“运动”为中心,重构视频-文本配对数据。其方法分为三大模块:
- MotionVid-QA:大规模运动感知数据集
- MotionSight:运动解耦与视觉提示流程
- MotionChat:两阶段微调模型
3.1 MotionVid-QA:首个大规模细粒度运动理解数据集
3.1.1 数据规模与构成
MotionVid-QA包含:
- 约40,000段视频片段(Θ(40K) clips)
- 约87,000组问答对(Θ(87K) Q&A pairs)
这是迄今为止首个专为细粒度运动理解设计的大规模开源数据集。
3.1.2 数据来源
数据融合自多个高质量视频数据集:
- ActivityNet:日常活动视频;
- Kinetics-700:700类人类动作;
- Charades & Charades-Ego:第一人称视角活动;
- Tarsier2-Recap-585K:大规模视频-文本配对;
- OpenVid-1M:百万级开源视频;
- MotionBench-train:专为运动理解设计的训练集。
3.1.3 数据标注流程
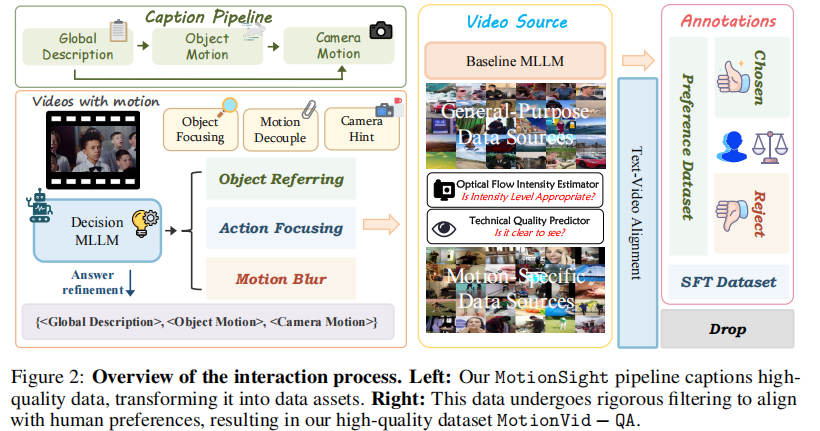
如上图所示,数据处理流程包括分辨率统一、去噪、帧率标准化、运动密度筛选、光照条件过滤等步骤,确保输入数据的高质量。
在数据预处理后,通过VQAScore [19] 和人工阈值对视频片段进行分类(如上图所示):
- 高质量片段 → 进入偏好数据集候选;
- 低质量片段 → 被剔除;
- 剩余部分 → 构成指令数据集(用于SFT)。
最终,通过整合多位受过良好教育且具有指导经验的个体提供的偏好反馈,开发出高质量的偏好数据集(用于DPO)。
3.1.4 数据集对比
为了凸显MotionVid-QA的创新性,论文在 表1 中将其与现有数据集进行了对比:
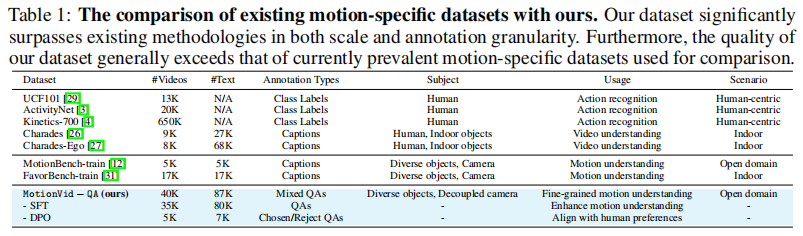
结论:MotionVid-QA在规模、标注粒度、任务复杂度上均显著超越现有数据集,是首个支持结构化动作特征表(SFT)和偏好子集的分层架构数据集。
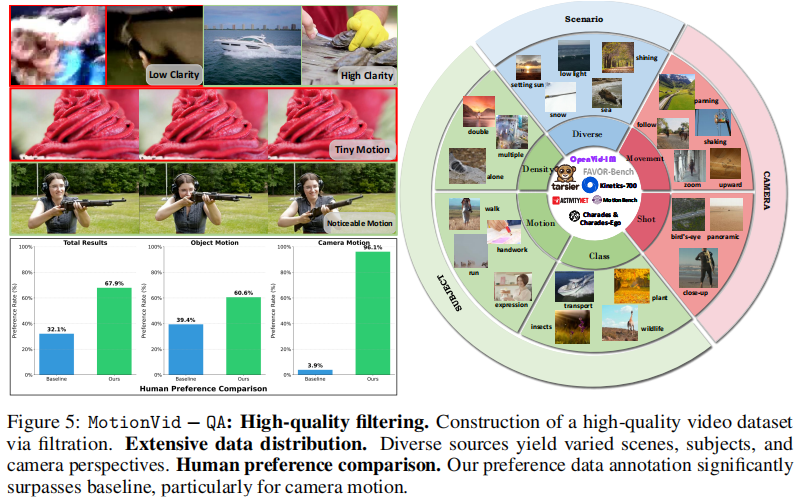
此外,图6进一步展示了MotionVid-QA与现有数据集的对比可视化分析。它指出,传统方法(如依赖类别标签或字幕)无法提供细粒度运动动态注释,而MotionVid-QA即使在缺乏显著主要物体的场景中(如落叶飘落),也能持续生成高质量的物体运动与相机运动描述。

3.2 MotionSight:运动解耦与视觉提示
3.2.1 核心思想:解耦物体运动与相机运动
MotionSight提出一个关键洞察:物体运动与相机运动应被分别建模。
- 若相机在移动,背景的“运动”并非物体自身运动;
- 若物体在移动,固定相机下的运动更易捕捉。
为此,引入运动解耦(Motion Decoupling)机制:
- 物体运动聚焦(Object Motion Focusing):通过视觉提示引导模型关注特定物体;
- 相机运动提示(Camera Motion Hint):显式标注相机运动类型(如“panning left”);
3.2.2 视觉提示(Visual Prompting)技术
MotionSight采用多种视觉提示策略增强运动感知:
| 方法 | 描述 | 作用 |
|---|---|---|
| 视觉聚光灯(Visual Spotlight) | 仅保留运动物体,模糊背景 | 抑制无关干扰,聚焦运动主体 |
| 运动模糊(Motion Blur) | 对整个视频帧施加模糊 | 增强模型对动态模糊的鲁棒性,提升运动感知 |
| 滑动窗口(Sliding Window) | 聚合连续多帧特征 | 捕捉运动轨迹与时间连续性 |
| 边界框标注(Bounding Box) | 在帧上标注物体位置 | 提供精确的时空定位信息 |
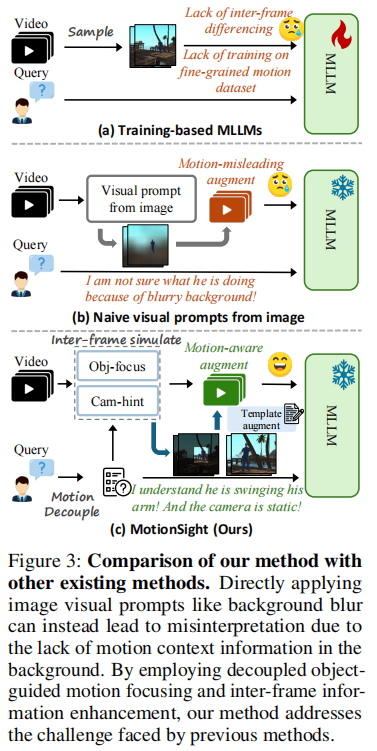
关键发现:论文指出,背景模糊在静态图像中有效,但在视频中可能误导模型,因其模糊了物体边界,增加了模型对鲁棒性的需求。
这一结论在下图中得到验证:将静态图像的视觉提示(如背景模糊)直接迁移到视频任务中,反而降低模型性能。原因是背景模糊破坏了视频的上下文信息,导致模型无法准确感知运动。
3.2.3 完整流程
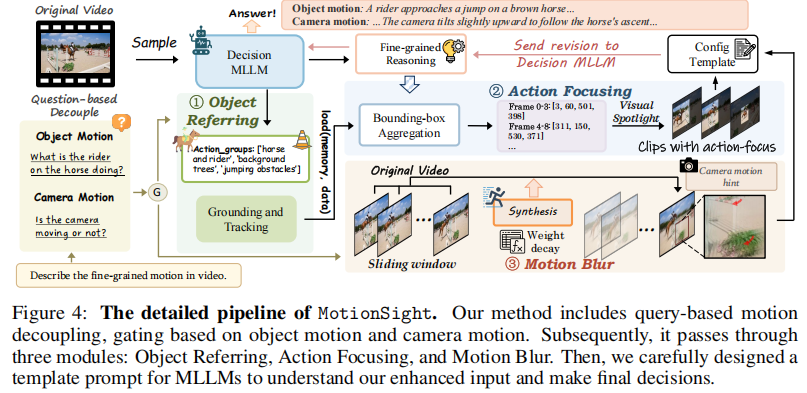
完整流程:
- 运动解耦:根据问题类型区分物体运动与相机运动;
- 物体参考:定位目标物体;
- 动作聚焦:应用视觉聚光灯;
- 运动模糊:增强相机运动感知;
- 模板提示:引导MLLM生成最终回答。
该流程实现了对物体运动与相机运动的精细化建模。
3.3 MotionChat:两阶段微调模型
3.3.1 第一阶段:监督微调(SFT)
- 基座:Qwen2.5VL-7B;
- 训练数据:MotionVid-QA中的指令-回答对;
- 可训练参数:视觉编码器、LLM、连接模块;
- 目标:让模型学会生成运动感知的回答。
3.3.2 第二阶段:直接偏好优化(DPO)
- 训练数据:MotionVid-QA中的偏好对(chosen vs. rejected);
- 可训练参数:仅LLM,视觉编码器冻结;
- 目的:对齐人类偏好,提升回答质量;
- 优势:避免视觉特征退化,专注于语言策略优化。
最终模型命名为 MotionChat,为社区提供一个现成的强基线。
四、实验分析:全面验证有效性
4.1 量化评估
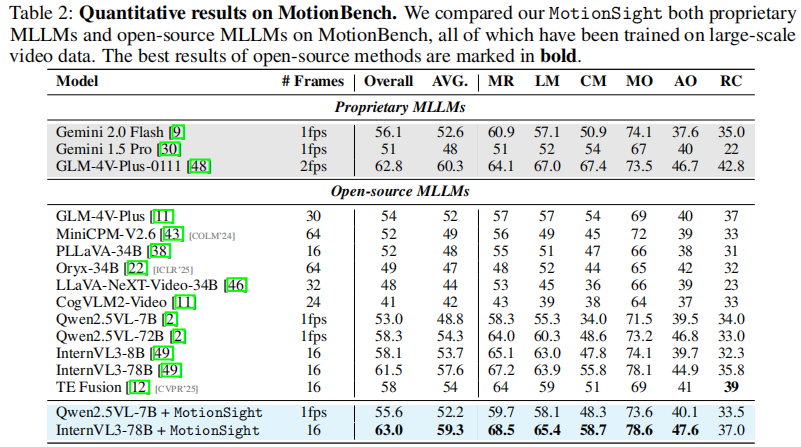
表2 展示了在MotionBench上的量化结果:
- 关键发现:
- Qwen2.5VL + MotionSight 在类别平均精度(AVG)上提升 3.4%;
- 相机运动预测(Camera Motion)准确率提升 14.3%;
- InternVL3-78B + MotionSight 达到业界领先水平,超越GLM-4V-Plus等商用模型。
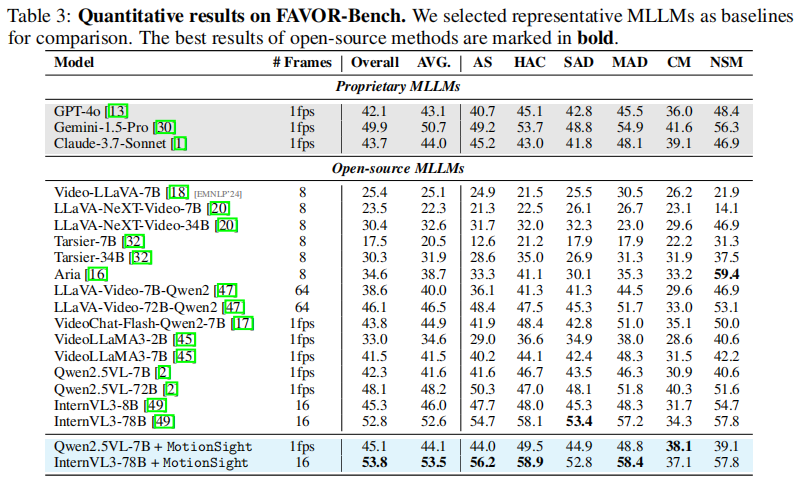
表3 展示了在FAVOR-Bench上的表现:
- Qwen2.5VL-7B + MotionSight:
- 类别平均指标提升 3.0%;
- 整体评估维度提升 2.5%;
- InternVL3-78B + MotionSight:
- 在 AS(Action Segmentation)、HAC(Human Action Classification)、MAD(Motion Anomaly Detection)等子任务上表现突出。
4.2 消融实验
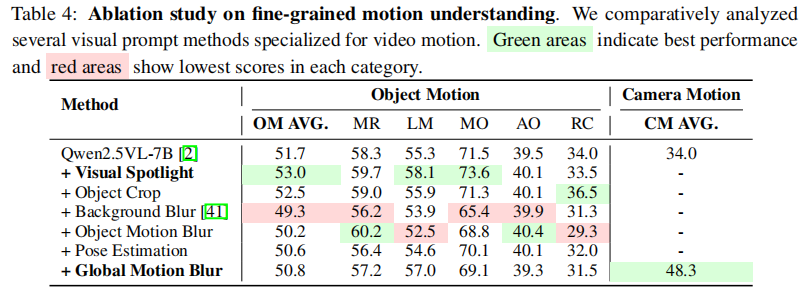
表4 是细粒度动作理解消融实验结果,对比了多种视觉提示方法对物体运动理解(OM AVG)和相机运动理解(CM AVG)的影响。
结论:
- 背景模糊对相机运动理解无益,甚至有害,与其静态在图像提示中的有效性形成鲜明对比;
- 全局运动模糊(Global Motion Blur)是提升相机运动理解的关键;
- 视觉聚焦显著提升物体运动理解。
五、总结与展望
5.1 核心贡献
- 提出 Motion-Centric 范式:将“运动”作为数据构建的核心;
- 发布 MotionVid-QA 数据集:首个大规模细粒度运动理解数据集;
- 设计 MotionSight 流程:通过运动解耦与视觉提示增强感知;
- 训练 MotionChat 模型:为社区提供强基线。
5.2 局限性
- 依赖外部检测模型(SAM 2, Grounding DINO);
- 数据集是否完全开源尚不明确;
- 实时性受限于复杂预处理。
5.3 未来方向
- 端到端运动感知模型;
- 运动预测与生成;
- 具身智能应用;
- 多模态强化学习。
六、结语
本文再次证明:在深度学习时代,数据的质量与范式,往往比模型架构本身更具决定性。它不仅为视频理解领域树立了新标杆,更启发我们:真正的“看懂”视频,始于对“运动”的深刻理解。
参考文献(部分)
[3] ActivityNet: A large-scale video benchmark for human activity understanding.
[4] Kinetics-700: Collection of 700 human action classes.
[12] Wenyi Hong et al. Motionbench: Benchmarking and improving fine-grained video motion understanding. arXiv:2501.02955, 2025.
[21] Grounding DINO: Marrying DINO with grounded pre-training for open-set object detection.
[23] OpenVid-1M: A large-scale open video dataset.
[24] Nikhila Ravi et al. SAM 2: Segment anything in images and videos. arXiv:2408.00714, 2024.
[26] Charades: Dataset of daily indoor activities.
[27] Charades-Ego: First-person view extension of Charades.
[31] Chongjun Tu et al. FAVOR-bench: A comprehensive benchmark for fine-grained video motion understanding. arXiv:2503.14935, 2025.
[44] Tarsier2-Recap-585K: Large-scale video-text dataset.
欢迎在评论区讨论本文的技术细节或分享您的看法!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)