大模型文本分割实战指南:Chonkie、LangChain、LlamaIndex工具详解与代码实现!
文章详细介绍了大模型应用中文本分割的重要性及多种策略(固定大小、自然边界、递归、语义分割等),对比了Chonkie、LangChain和LlamaIndex等工具的实现特点。强调了分割质量直接影响检索准确性和成本,提供了从预处理到索引的完整流程,并针对问答、摘要、搜索等场景给出实践建议,最后提供了评估分割效果的测试框架。
上下文窗口变大了。有些模型一次能处理整章内容。这看似自由,但并未消除权衡。分块依然决定模型读什么,检索返回什么,以及每次调用你得花多少钱。
分块说起来简单,做起来容易出错。你需要把长文本切成模型或嵌入器能处理的片段。听起来像是在调整大小,但实际上是关于相关性。好的分块要小到足够具体,大到能独立存在。做到这一点,检索就像记忆一样自然。做不到,你会得到模糊的匹配、半吊子答案,甚至模型开始瞎猜。
这是一篇实用指南。我们用Chonkie举例,因为它封装了工程师们实际使用的那些不那么光鲜的部分。在合适的地方,我们会提到LangChain和LlamaIndex的分块器,以及像late chunking这样的长上下文策略——先嵌入再切分,以保留每个向量中的全局线索。你会看到这种方法在哪些场景有用,哪些场景没用,还有它会花多少成本。

长窗口改变的是策略,不是原则。即使有百万token的窗口,你也不会想把所有东西都塞进prompt。你想要的是几个精准的片段,因为它们包含答案。分块就是让你先把这些片段创建出来。
一、窗口、检索和成本
分块处于三个核心问题的交汇处。模型只能读取有限的token。你的检索器必须拉到正确的段落。你发送的每个token都要花时间和金钱。分块是平衡这三者的控制旋钮。
上下文窗口设定了硬性上限。你永远不会把整篇文档直接发送。你会发送一个prompt包装、一个问题和几个片段。这些片段只有在你提前分好块的情况下才会存在。这就是分块的作用。它把长文本切成适合的片段,并塑造每个片段,让模型单独读取时也能理解。
检索关注的是焦点。如果一个分块包含三个不相关的想法,向量会把它们混淆。查询可能匹配到错误的部分,带来一堆无关内容。如果分块太小,就像缺了线索的谜语。最好的分块就像教科书里的短段落:一个核心想法,足够细节来支持主题,不带跑题的废话。
成本通过重叠和top-k潜入。重叠保护了边界处的上下文,但会增加token数量。取五个分块而不是三个,模型要读更多内容,你得为这些token付费,还可能稀释相关性。正确的设置不是口号,而是经过权衡的选择。
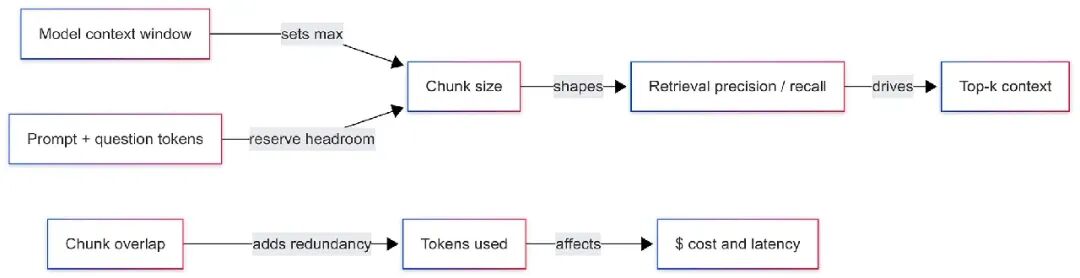
一个简单的分块方法是从窗口倒推。计算你的system prompt、guardrails、指令和安全缓冲区的token数。剩下的就是检索文本的工作预算。将这个预算分配给计划展示的分块数量。如果是一次性流式处理,留出空间给模型的回答。
这里有个小工具帮你老实计算token。它用了tiktoken,匹配很多OpenAI兼容模型的计数方式。如果用其他技术栈,可以换成Hugging Face的tokenizer。
# python 3.11 # pip install tiktoken import tiktoken from math import ceil # 设置tokenizer匹配你的模型。常用选项: # "cl100k_base" (广泛使用) # "o200k_base" (较新的200k token系列) ENCODING_NAME = "cl100k_base"enc = tiktoken.get_encoding(ENCODING_NAME) deftokens(text: str) -> int: returnlen(enc.encode(text)) defchunk_budget(context_max: int, prompt_text: str, buffer_tokens: int = 256) -> int: used = tokens(prompt_text) + buffer_tokens returnmax(0, context_max - used) defchunks_needed(doc_tokens: int, chunk_size: int, overlap: int) -> int: step = max(1, chunk_size - overlap) return ceil(max(0, doc_tokens - overlap) / step) defoverlap_overhead(doc_tokens: int, chunk_size: int, overlap: int) -> float: n = chunks_needed(doc_tokens, chunk_size, overlap) return (n * chunk_size) / max(1, doc_tokens)
如果你的文档有5万token,窗口留给检索文本3千token,想用三个分块,每个分块大约一千token。如果你设置15%的重叠,有效读取量会增加。上面这个工具会告诉你开销比例,帮你看清权衡。
字符和token不是一个单位。字符分割器速度快,适合粗略切割,但会错过精确的token限制。token分割器匹配模型对文本的看法,让你在窗口内榨取最大价值。你可以用字符做原型,到了生产预算时再换成token。Chonkie、LangChain和LlamaIndex都提供这两种方式。实验结束后,用token-aware的路径。
检索质量在分块连贯时提升。你可以用简单测试验证。挑一组有已知答案的问题。建两个不同分块大小和重叠的索引。对每个问题,取出top-3分块,检查答案文本是否出现在检索结果中。跟踪recall@3,记录拉进prompt的额外token数。当recall上升而token下降,你找到了更好的设置。当recall上升但token暴增,判断收益是否值得成本。你不需要大数据集,十几个来自你领域的真实问题就能揭示很多。
窗口大小不尽相同。嵌入器的限制可能比你的聊天模型小。如果嵌入器只能接受短文本,你得先分块再嵌入。如果用late chunking,顺序相反。你先把整个文档通过长上下文编码器,得到token级向量,再聚合成分块向量。每个分块向量现在都带有全文的线索。对于证据跨越局部边界的查询,检索效果会更好。代价是计算和内存。你需要一个能处理全文的模型,还得在回答问题前先跑一遍。
Contextual retrieval是个轻量变种。你还是先分块,但在嵌入或存储元数据时,给每个分块附上小结、标题或线索锚点。比如,一个关于Berlin的分块会带上“Berlin, population context, European cities”的元数据。查询时,这能帮向量空间或重排器区分相似项。它不会修复不连贯的分块,但能让好的分块更常胜出。
窗口变大时,容易想塞更多分块。别冲动。模型按顺序读取,上下文前部会得到更多关注。干净的top-3通常比杂乱的top-8强。如果需要更广的覆盖,用两步计划。先取更宽的集合,用cross-encoder重排,再把top几项传给聊天模型。Chonkie通过生成更好的原始片段融入这个计划。LangChain、LlamaIndex或你自己的代码可以处理重排。
这里有个紧凑的滑动窗口代码,尊重token计数,返回起始偏移量,方便后续映射回源位置。
from typing importList, Tupledefsliding_chunks(text: str, max_tokens: int, overlap_tokens: int) -> List[Tuple[int, int, str]]: ids = enc.encode(text) n = len(ids) step = max(1, max_tokens - overlap_tokens) out = [] i = 0 while i < n: j = min(n, i + max_tokens) piece_ids = ids[i:j] out.append((i, j, enc.decode(piece_ids))) if j == n: break i += step return out
一直在更新,更多的大模型学习和面试资料已经上传带到CSDN的官方了,有需要的朋友可以扫描下方二维码免费领取【保证100%免费】👇👇

二、真正管用的分块策略
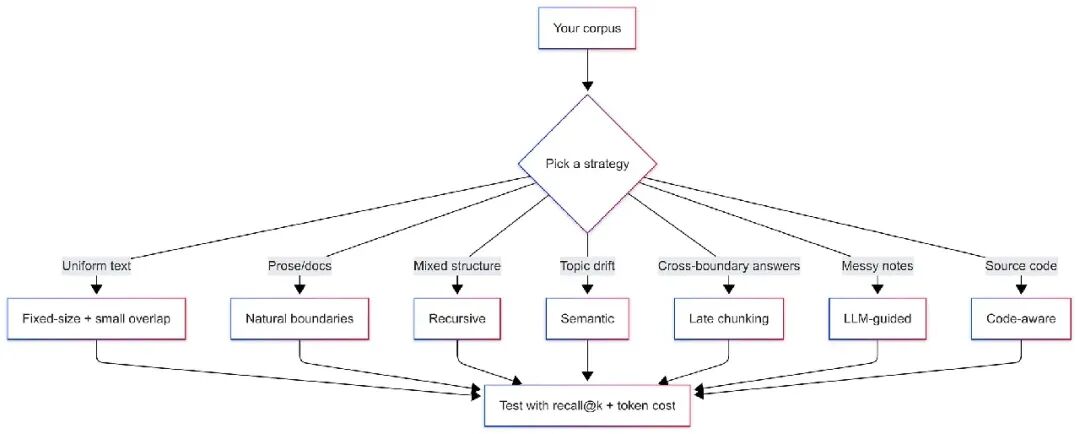
没有一种分割器适合所有语料库。最佳选择取决于你存储什么、查询什么,以及模型怎么计数文本。从最简单可行的开始,只有测试告诉你必须升级时才往上走。
固定大小分块带重叠
这是主力选手。你按token切到目标大小,保留小部分重叠,确保边界事实不被孤立。它快、可靠、易于预算,但也钝。它不知道句子或段落的边界。如果你的文档格式统一或生成式,钝点也没啥。
# python 3.11 # pip install tiktoken import tiktoken enc = tiktoken.get_encoding("cl100k_base") defto_tokens(s: str) -> list[int]: return enc.encode(s) deffrom_tokens(ids: list[int]) -> str: return enc.decode(ids) deffixed_chunks(text: str, max_tokens: int, overlap: int) -> list[str]: ids = to_tokens(text) step = max(1, max_tokens - overlap) out = [] i = 0 while i < len(ids): j = min(len(ids), i + max_tokens) out.append(from_tokens(ids[i:j])) if j == len(ids): break i += step return out
当你需要严格控制token预算时用这个。保持重叠小。如果检索里反复出现相同句子,说明重叠设太高了。
自然边界分块
读者按句子和段落思考。模型在分块包含完整想法时表现更好。自然边界分割器会把完整句子打包,直到下一个句子会超token预算。它保持连贯性,又不失预算控制。
import re sent_re = re.compile(r'(?<!\w\.\w.)(?<![A-Z][a-z]\.)(?<=[.!?])\s+') defsentence_pack(text: str, max_tokens: int) -> list[str]: sentences = sent_re.split(text.strip()) out, cur = [], [] cur_len = 0 for s in sentences: s_tokens = len(to_tokens(s)) if s_tokens > max_tokens: out.extend(fixed_chunks(s, max_tokens, overlap=0)) continue if cur_len + s_tokens <= max_tokens: cur.append(s) cur_len += s_tokens else: out.append(" ".join(cur)) cur, cur_len = [s], s_tokens if cur: out.append(" ".join(cur)) return out
用在散文、文档和报告上。它避免句子被切断,给嵌入器更清晰的信号。如果段落短,就把段落当单位,打包思路不变。
递归分块
真实文档有结构。你可以不用LLM就尊重它。递归分割器先尝试大分界,再回退到小分界,最后才用固定窗口。标题、双换行、句子、token,这个顺序尽量保持相关上下文。
import redefrecursive_chunks(text: str, max_tokens: int, overlap: int = 0) -> list[str]: iflen(to_tokens(text)) <= max_tokens: return [text] if"\n#"in text: parts = re.split(r'\n(?=#)', text) elif"\n\n"in text: parts = text.split("\n\n") else: parts = sentence_pack(text, max_tokens) out, buf = [], "" for p in parts: candidate = buf + ("\n\n"if buf else"") + p iflen(to_tokens(candidate)) <= max_tokens: buf = candidate else: if buf: out.append(buf) iflen(to_tokens(p)) <= max_tokens: buf = p else: out.extend(fixed_chunks(p, max_tokens, overlap)) buf = "" if buf: out.append(buf) return out if out else fixed_chunks(text, max_tokens, overlap)
这和Chonkie的RecursiveChunker或LangChain的递归分割器实际效果一致。适合混合格式文档,是个强默认选择。
语义分块
意义可以引导分割点。你嵌入候选单位(如句子),计算相邻单位的相似度,当相似度下降或token预算超限时开始新分块。结果是一组讨论同一主题的句子,这正是你想要的分块。
# 你提供一个返回numpy数组的embed()函数 import numpy as np defsemantic_chunks(text: str, max_tokens: int, sim_threshold: float = 0.62) -> list[str]: sentences = sent_re.split(text.strip()) vecs = [embed(s) for s in sentences] # shape (n, d) out, cur, cur_len = [], [], 0 defcos(a, b): na = a / (np.linalg.norm(a) + 1e-9) nb = b / (np.linalg.norm(b) + 1e-9) returnfloat((na * nb).sum()) for i, s inenumerate(sentences): v = vecs[i] next_v = vecs[i + 1] if i + 1 < len(vecs) elseNone s_tokens = len(to_tokens(s)) start_new = False if cur and next_v isnotNoneand cos(v, next_v) < sim_threshold: start_new = True elif cur_len + s_tokens > max_tokens: start_new = True if start_new and cur: out.append(" ".join(cur)) cur, cur_len = [], 0 cur.append(s) cur_len += s_tokens if cur: out.append(" ".join(cur)) return out
当长段落内主题切换或标题不可靠时,用语义分块。索引时需要一次嵌入,成本高,但检索通常会以更干净的结果回报。
Late Chunking
有时候你希望每个分块向量记住文档的其余部分。Late chunking反转顺序。你先用长上下文编码器跑一遍全文,拿到token级向量,再聚合成分块向量。每个分块向量都带有全局线索,避免单独嵌入切片时丢失信息。

Late chunking适合答案从分散线索中抽取的场景。它对硬件要求高。你需要一个能吃下整个文件的模型和足够的内存来处理这一轮。很多团队把这个留给高价值语料库,其他地方用经典的先分块后嵌入。
LLM引导的分块
你也可以让小模型标记边界。给它文本和预算,要求返回保持想法完整的偏移量。用你的tokenizer验证后再信任。
{ "instruction": "将文本分成不超过800 token的连贯段落。返回JSON格式的start:end字符偏移量。", "text": "…你的文档在这儿…"}
这种方法对杂乱的散文或会议记录很精确。但它慢且每次调用都有成本,所以大多团队用它处理关键文档或作为一次性预处理器。
代码感知分块
源代码需要不同的刀。函数、类和docstring是自然单位。像Tree-sitter这样的树解析器可以遍历文件,给你符号对应的范围。然后你把这些范围打包到token预算里。尽量别把函数体切开。模型在完整单位存在时回答代码问题更好。
三、Chonkie和朋友们的定位
Chonkie用直白的命名暴露这些概念:TokenChunker用于固定路径,SentenceChunker用于自然边界,RecursiveChunker用于结构化路径,SemanticChunker用于语义分割,LateChunker用于先嵌入后分割,还有实验性的neural chunkers供你想要学习式选择时使用。LangChain和LlamaIndex提供类似的分块器。
这里有个TypeScript版本,方便JavaScript团队复制token-aware模式,不用猜模型怎么计数文本。
// TypeScript: 带重叠的token-aware滑动分块 // npm i tiktoken import { get_encoding } from"tiktoken"; const enc = get_encoding("cl100k_base"); // 或 "o200k_base" 匹配你的模型 typeChunk = { startTok: number; endTok: number; text: string }; exportfunctionslidingChunks(text: string, maxTokens: number, overlapTokens: number): Chunk[] { const ids = enc.encode(text); const step = Math.max(1, maxTokens - overlapTokens); constout: Chunk[] = []; for (let i = 0; i < ids.length; i += step) { const j = Math.min(ids.length, i + maxTokens); out.push({ startTok: i, endTok: j, text: enc.decode(ids.slice(i, j)) }); if (j === ids.length) break; } return out; }
标签可能变,权衡不变。
选一个分块方式,测recall@固定k,记录每次查询拉取的token。如果recall上升而token稳定,你选对了。如果recall上升但token激增,判断收益是否值得延迟和账单。
四、从原始文本到索引分块
好的pipeline把杂乱输入变成干净、可检索的片段。Chonkie的CHOMP理念和大多数团队的做法无缝对接。先规范化文本,再分割,再润色和丰富,最后存储。不同库,节奏相同。
名字听起来好玩,但工作很标准。Document是你源文本。Chef是预处理,修空格、坏OCR或怪Unicode。Chunker是你选的分割器。Refinery是后处理,合并零散片段、标记元数据、附加嵌入。Friends是分块的去处,要么是向量存储,要么是文件导出。如果你喜欢中性标签,换成预处理、分割、精炼、输出,一一对应。

预处理是小胜累积的地方。从爬取的PDF里去掉重复页眉页脚。规范化引号和破折号。压缩重复空格。目标是稳定的分割和嵌入。两个略有不同的相同段落在向量空间里不会很好碰撞。
分割是重头戏。把参数集中一处,每次运行都记录。以后换模型或预算时,你会想知道哪个索引用了哪些设置。在索引旁留个简短清单,记下tokenizer名称、分块大小和重叠。
精炼是质量控制。合并无法独立的小尾巴分块。附上源元数据,如文件名、章节标题、起止字符偏移和token范围。如果打算搜索元数据,再加一行简短摘要。这里也做嵌入,因为你想一次搞定然后继续。
输出故意简单。把向量和元数据推到存储里。或者写JSONL,在别处索引。不管怎样,记录索引版本和生成它的嵌入模型。检索出问题时,没法追溯存储内容会很麻烦。
这里有个紧凑的Python示例,模仿Chonkie风格的pipeline感觉。API形状有代表性,换成你用的真实接口。
# python 3.11 # 模仿典型的chonkie/lc风格流程;适配你的具体库 from dataclasses import dataclass from typing import Iterable, Dict, Any, Listimport hashlib, time import tiktoken # token-aware @dataclass classChunk: text: str doc_id: str chunk_id: str start_char: int end_char: int start_tok: int end_tok: int meta: Dict[str, Any] vector: list[float] | None = Nonedefnormalize_text(raw: str) -> str: cleaned = " ".join(raw.replace("\u00A0", " ").split()) return cleaned defchunk_sliding( text: str, tokenizer, chunk_size: int, overlap: int, doc_id: str = "doc-001") -> List[Chunk]: """带重叠的token窗口分割;返回token/字符范围以映射回源""" ids = tokenizer.encode(text) out: List[Chunk] = [] i = 0 step = max(1, chunk_size - overlap) while i < len(ids): j = min(len(ids), i + chunk_size) piece_ids = ids[i:j] piece = tokenizer.decode(piece_ids) start_char = len(tokenizer.decode(ids[:i])) end_char = start_char + len(piece) cid = hashlib.md5(f"{doc_id}:{i}:{j}".encode()).hexdigest()[:10] out.append(Chunk( text=piece, doc_id=doc_id, chunk_id=f"{doc_id}-{cid}", start_char=start_char, end_char=end_char, start_tok=i, end_tok=j, meta={"ver": 1} )) if j == len(ids): break i += step return out defembed_all(chunks: Iterable[Chunk], embedder) -> List[Chunk]: texts = [c.text for c in chunks] vecs = embedder.embed_documents(texts) # list[list[float]] out: List[Chunk] = [] for c, v inzip(chunks, vecs): c.vector = v out.append(c) return out defupsert(chunks: Iterable[Chunk], vectordb): payload = [{ "id": c.chunk_id, "vector": c.vector, "metadata": { "doc_id": c.doc_id, "start_char": c.start_char, "end_char": c.end_char, "start_tok": c.start_tok, "end_tok": c.end_tok, **c.meta }, "text": c.text } for c in chunks] vectordb.upsert(payload) # 连接起来(token-aware) classTikTokenizer: def__init__(self, name: str = "cl100k_base"): self.enc = tiktoken.get_encoding(name) defencode(self, s: str): returnself.enc.encode(s) defdecode(self, ids): returnself.enc.decode(ids) classDummyEmbedder: defembed_documents(self, texts): return [[hash(t) % 997 / 997.0for _ inrange(8)] for t in texts] classDummyDB: defupsert(self, rows): print(f"已插入 {len(rows)} 个分块") tok = TikTokenizer("cl100k_base") # 如果你的模型用它,换成 "o200k_base" embedder = DummyEmbedder() db = DummyDB() raw = open("document.txt").read() clean = normalize_text(raw) chunks = chunk_sliding(clean, tokenizer=tok, chunk_size=1200, overlap=180, doc_id="doc-001") vectored = embed_all(chunks, embedder) upsert(vectored, db) print(f"在 {time.strftime('%Y-%m-%d %H:%M:%S')} 索引了 {len(vectored)} 个分块")
索引卫生值得注意。重叠有帮助,但会在接缝处制造重复。检索后常看到相邻的两个命中共享一句。构建prompt前按字符范围去重。保留更长的或得分更高的。这里有个跨存储工作的小工具。
def dedupe_overlaps(hits): # 每个hit: {"doc_id","start_char","end_char","text", "score"?} hits = sorted(hits, key=lambda h: (-(h.get("score", 0.0)), h["doc_id"], h["start_char"])) kept = [] seen = {} for h in hits: key = h["doc_id"] cur = seen.get(key, []) overlaps = [k for k in cur ifnot (h["end_char"] <= k["start_char"] or h["start_char"] >= k["end_char"])] if overlaps: best = max([*overlaps, h], key=lambda x: (x["end_char"] - x["start_char"], x.get("score", 0.0))) if best is h: for k in overlaps: cur.remove(k) cur.append(h) else: cur.append(h) seen[key] = cur for v in seen.values(): kept.extend(v) kept.sort(key=lambda h: (h["doc_id"], h["start_char"])) return kept
在索引旁留个简短清单。记录tokenizer、嵌入模型、分块大小、重叠和日期。生产中感觉不对时,你会有个清晰的发货记录。
一直在更新,更多的大模型学习和面试资料已经上传带到CSDN的官方了,有需要的朋友可以扫描下方二维码免费领取【保证100%免费】👇👇
五、付诸实践:问答、摘要和搜索
一个pipeline只有在回答问题、把长报告压成可行动的内容,或比人更快找到段落时才证明自己。以下模式匹配许多团队现在的发货方式。部件相同,旋钮相同,只有预算和库变。
基于事实的问答
问答是戴上耳机的检索。你索引一次,取几个聚焦分块,把这些分块和简单指令、明确请求交给模型。你不会把整本书塞进上下文,你喂一小盘。

这里有个紧凑的Python检索步骤,假设你已有索引。它取top-k,去掉重叠回声,构建基于事实的prompt。LLM调用是个占位符,接入你用的客户端。
from typing importList, Dict, Anydefbuild_prompt(question: str, hits: List[Dict[str, Any]]) -> str: parts = [] for i, h inenumerate(hits, 1): parts.append(f"[{i}] {h['text']}\n(来源: {h['doc_id']}:{h['start_char']}-{h['end_char']})") context = "\n\n".join(parts) return ( "仅用以下片段回答。引用来源如[1]、[2]。如果答案不在其中,说你不知道。\n\n" f"{context}\n\n问题: {question}\n回答:" )defanswer(question: str, vectordb, k: int = 3, budget_tokens: int = 2200) -> str: raw_hits = vectordb.similarity_search(question, top_k=8) # 每个包含text, doc_id, start_char, end_char, score hits = dedupe_overlaps(raw_hits) kept, used = [], 0 for h in hits: t = len(enc.encode(h["text"])) if used + t > budget_tokens: continue kept.append(h) used += t iflen(kept) == k: break prompt = build_prompt(question, kept) # llm_response = llm.complete(prompt, max_tokens=400) # return llm_response.text return prompt # 演示用
保持k小。给检索文本设动态token预算。携带偏移量,答案能引用来源,你也能在阅读器里高亮。如果语料库噪点多,加第二轮用cross-encoder重排前十个命中,再挑最后三个。
可扩展到章节的摘要
长文档先累死人,再累死模型。好的摘要让你扫一眼、做决定、按需深挖。你可以用map-reduce,或边走边精炼。两者都行。精炼适合线性报告,map-reduce适合章节分明的庞大文档。
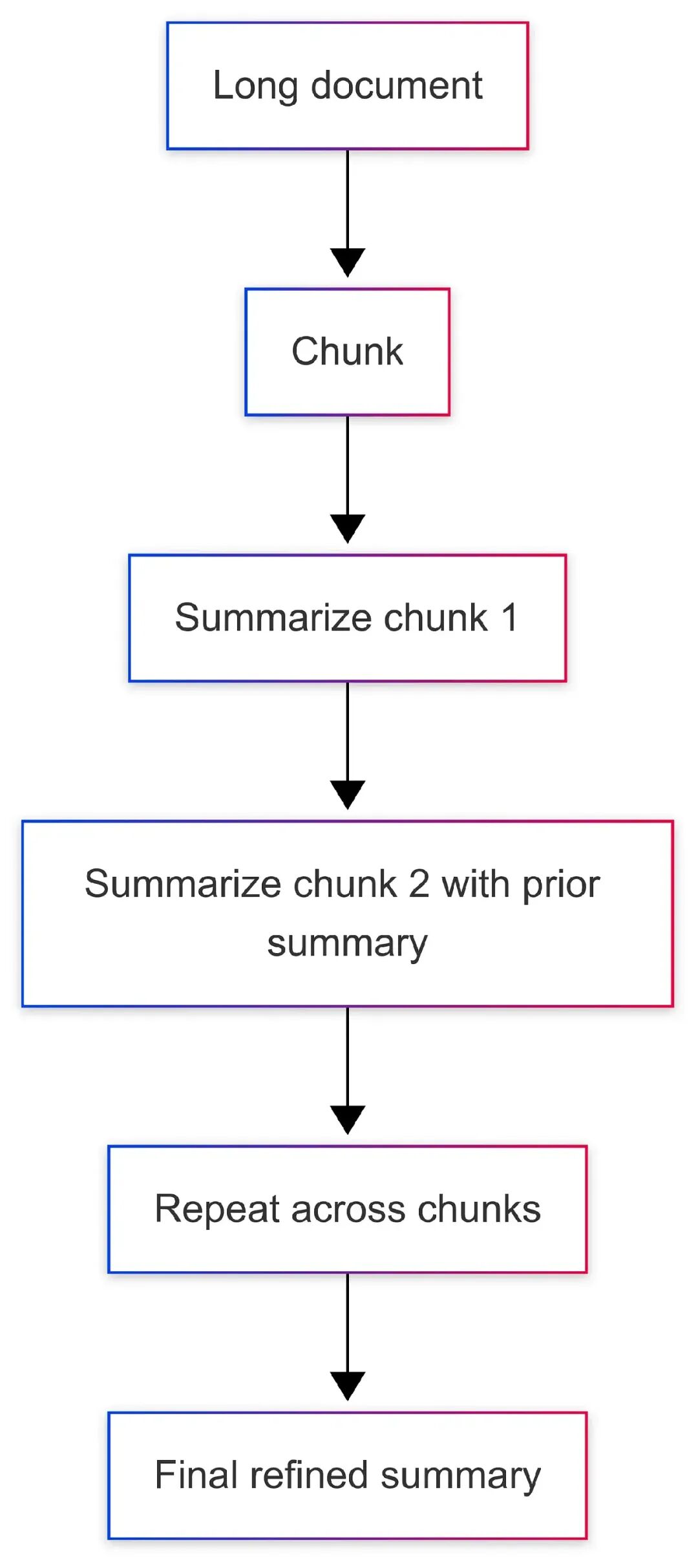
这是一个小精炼循环。它把运行摘要带到下一步,让模型始终看到全局和下一个分块。
def refine_summary(chunks: list[str], llm, part_tokens: int = 800) -> str: summary = "开始简洁的执行摘要。捕捉关键点、数字和决定。" for i, ch inenumerate(chunks, 1): ch_ids = enc.encode(ch)[:part_tokens] ch = enc.decode(ch_ids) prompt = ( f"当前摘要:\n{summary}\n\n" f"新一节 ({i}/{len(chunks)}):\n{ch}\n\n" "更新摘要。保持简洁。保留数字和名字。如新信息修正早期内容,改正它。" ) # resp = llm.complete(prompt, max_tokens=300) # summary = resp.text.strip() summary = f"[占位符更新第{i}节] {summary[:120]}" return summary
你不必追求一次完美覆盖。你需要一个扫一眼可信的摘要。如果文档含大量表格或代码,分块时把这些块当原子单位,模型在重写前能看到完整单位。
像记忆一样的搜索
简单的语义搜索是种安慰。你输入想找的,得到大概想要的段落。好的分块让它感觉干脆,而不是糊成一团。字符适合初建,token在乎预算时更好。
这里有个小型端到端流程,包含常见模块。它分块、嵌入、索引,然后跑查询。换上你的真实tokenizer和嵌入器,换上你的存储。
import tiktoken# 本地tokenizer让代码块自包含enc = tiktoken.get_encoding("cl100k_base")classMiniIndex: def__init__(self, embedder): self.embedder = embedder self.rows = [] # [{"id","vector","text","meta"}] defadd(self, rows): self.rows.extend(rows) defsimilarity_search(self, q: str, top_k: int = 3): import numpy as np qv = np.array(self.embedder.embed_query(q)) scored = [] for r inself.rows: v = np.array(r["vector"]) score = float(qv @ v / (np.linalg.norm(qv) * np.linalg.norm(v) + 1e-9)) scored.append((score, r)) scored.sort(key=lambda x: x[0], reverse=True) return [r for _, r in scored[:top_k]]# 使用文章前面定义的sliding_chunks(text, chunk_size, overlap)defindex_corpus(docs, embedder, chunk_size=800, overlap=100): idx = MiniIndex(embedder) for d in docs: chunks = sliding_chunks(d["text"], chunk_size, overlap) rows = [] for (si, ei, ch_text) in chunks: vec = embedder.embed_documents([ch_text])[0] rows.append({ "id": f"{d['id']}-{si}:{ei}", "vector": vec, "text": ch_text, "meta": {"doc_id": d["id"], "start_tok": si, "end_tok": ei} }) idx.add(rows) return idxclassDummyEmbedder: defembed_documents(self, texts): return [[(hash(t) % 997) / 997.0for _ inrange(384)] for t in texts] defembed_query(self, text): return [(hash(text) % 997) / 997.0for _ inrange(384)]docs = [{"id": "manual", "text": open("manual.txt").read()}]embedder = DummyEmbedder()idx = index_corpus(docs, embedder)hits = idx.similarity_search("factory reset steps", top_k=3)for h in hits: print(h["meta"]["doc_id"], h["text"][:120].replace("\n", " "), "…")
生产中你不会打印。你会展示一个整洁的结果卡,带标题、短摘录和链接,滚动到阅读器里的精确位置。这个紧凑循环让系统感觉活了。分块器默默完成了关键工作。
何时升级到Late Chunking或重排
如果你的问题常从远处线索中抽取,late chunking能帮上忙,因为每个分块向量生来就带有全局视野。如果top-k返回近似命中,cross-encoder重排器能救回正确顺序。两者都加时间和复杂性,所以用在答案必须更准而不是更快的地方。其他情况保留简单路径。
六、闭环:一个你真会用的简单测试计划
空谈无用,测量为王。目标不是排行榜,是确信你的分块设置能带来好recall,不膨胀上下文。
你需要三样东西:一小套有已知答案的真实问题;一个可重复的方式,用特定分块设置建索引;一个循环,逐个提问,取top k,检查正确答案是否出现,记录会发送给模型的token数。

这里有个紧凑的测试框架。它对一组分块大小和重叠网格测试,用小真实集报告recall@3和平均发送的上下文token数。接入真实嵌入器和向量存储时,替换相应部分。
# python 3.11 # pip install tiktoken import tiktoken, time, itertools, numpy as np from typing importList, Dict, Any, Tupleenc = tiktoken.get_encoding("cl100k_base") classDummyEmbedder: defembed_documents(self, texts: List[str]) -> List[List[float]]: return [[(hash(t) % 997) / 997.0for _ inrange(384)] for t in texts] defembed_query(self, text: str) -> List[float]: return [(hash(text) % 997) / 997.0for _ inrange(384)] classMiniIndex: def__init__(self, embedder): self.embedder = embedder self.rows: List[Dict[str, Any]] = [] defadd(self, rows: List[Dict[str, Any]]): self.rows.extend(rows) defsimilarity_search(self, q: str, top_k: int = 10) -> List[Dict[str, Any]]: qv = np.array(self.embedder.embed_query(q)) scored = [] for r inself.rows: v = np.array(r["vector"]) score = float(qv @ v / (np.linalg.norm(qv) * np.linalg.norm(v) + 1e-9)) scored.append((score, r)) scored.sort(key=lambda x: x[0], reverse=True) return [r for _, r in scored[:top_k]] deftokens(s: str) -> int: returnlen(enc.encode(s)) defsliding_chunks(text: str, max_tokens: int, overlap_tokens: int) -> List[Tuple[int, int, str]]: ids = enc.encode(text) n = len(ids) step = max(1, max_tokens - overlap_tokens) out, i = [], 0 while i < n: j = min(n, i + max_tokens) piece_ids = ids[i:j] out.append((i, j, enc.decode(piece_ids))) if j == n: break i += step return out defindex_with_settings(doc_id: str, text: str, embedder, chunk_size: int, overlap: int) -> MiniIndex: idx = MiniIndex(embedder) rows = [] for si, ei, ch_text in sliding_chunks(text, chunk_size, overlap): vec = embedder.embed_documents([ch_text])[0] rows.append({"id": f"{doc_id}-{si}:{ei}", "vector": vec, "text": ch_text, "meta": {"doc_id": doc_id, "start_tok": si, "end_tok": ei, "tok_len": tokens(ch_text)}}) idx.add(rows) return idx defdedupe_overlaps(hits: List[Dict[str, Any]]) -> List[Dict[str, Any]]: hits = sorted(hits, key=lambda h: (h["meta"]["doc_id"], h["meta"]["start_tok"])) kept, last_end = [], -1 for h in hits: if h["meta"]["start_tok"] >= last_end: kept.append(h) last_end = h["meta"]["end_tok"] return kept defevaluate(truth: List[Dict[str, str]], chunk_sizes: List[int], overlaps: List[int]) -> List[Dict[str, Any]]: results = [] embedder = DummyEmbedder() for cs, ov in itertools.product(chunk_sizes, overlaps): start = time.time() recalls, token_budgets = [], [] for item in truth: idx = index_with_settings(item["doc_id"], item["text"], embedder, cs, ov) hits = dedupe_overlaps(idx.similarity_search(item["question"], top_k=8)) topk = hits[:3] recall = any(item["answer"].strip() in h["text"] for h in topk) recalls.append(1if recall else0) token_budgets.append(sum(tokens(h["text"]) for h in topk)) dur_ms = int((time.time() - start) * 1000) results.append({ "chunk_size": cs, "overlap": ov, "recall_at_3": sum(recalls) / max(1, len(recalls)), "avg_tokens_retrieved": sum(token_budgets) / max(1, len(token_budgets)), "build_eval_ms": dur_ms }) returnsorted(results, key=lambda r: (-r["recall_at_3"], r["avg_tokens_retrieved"]))
像看交易一样读输出。如果两个设置recall打平,选token少的。如果一个设置recall大胜但只加了少量token开销,拿下胜利。如果一个设置recall胜但token翻倍,判断你的用户和预算能不能承受。换嵌入器或重排器时,重跑这个网格。保持真实集小而诚实,十到二十个反映真实使用的问题够你不自欺。
你可以用同样习惯做摘要。用生产中的分块方式拆长报告。跑精炼循环。检查重要实体和数字是否在过程中保留。数你用的token。如果关键数字老丢,说明分块错了或预算太紧。先修分块,再调prompt。
最后在索引旁留个简短清单。记录tokenizer、嵌入模型、分块大小、重叠和日期。生产中感觉不对时,你会有个清晰的发货记录。
七、AI大模型从0到精通全套学习大礼包
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
只要你是真心想学AI大模型,我这份资料就可以无偿共享给你学习。大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!
如果你也想通过学大模型技术去帮助就业和转行,可以扫描下方链接👇👇
大模型重磅福利:入门进阶全套104G学习资源包免费分享!

01.从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点
02.AI大模型学习路线图(还有视频解说)
全过程AI大模型学习路线


03.学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的


04.大模型面试题目详解


05.这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
所有的视频由智泊AI老师录制,且资料与智泊AI共享,相互补充。这份学习大礼包应该算是现在最全面的大模型学习资料了。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


智泊AI始终秉持着“让每个人平等享受到优质教育资源”的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起"前沿课程+智能实训+精准就业"的高效培养体系。
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 2
2 0
0- 0



 已为社区贡献290条内容
已为社区贡献290条内容

所有评论(0)