AI原生应用领域多租户:未来技术应用的新方向
本报告系统解析AI原生应用中多租户架构的技术本质与实践路径。通过第一性原理推导,揭示多租户在AI场景下的核心矛盾——共享计算资源与租户专属需求的平衡;构建层次化分析框架,覆盖从理论模型到工程实现的全链路;结合医疗、金融等领域的真实案例,阐明多租户架构如何通过动态资源池化、隐私增强计算(PEC)和模型自适应调优,突破传统SaaS多租户的性能边界。为技术决策者提供从架构选型到伦理合规的全维度指导,助力
AI原生应用的多租户架构:技术原理、设计模式与未来演进
关键词
AI原生应用、多租户架构、租户隔离、动态资源分配、隐私计算、模型即服务(MaaS)、弹性扩展
摘要
本报告系统解析AI原生应用中多租户架构的技术本质与实践路径。通过第一性原理推导,揭示多租户在AI场景下的核心矛盾——共享计算资源与租户专属需求的平衡;构建层次化分析框架,覆盖从理论模型到工程实现的全链路;结合医疗、金融等领域的真实案例,阐明多租户架构如何通过动态资源池化、隐私增强计算(PEC)和模型自适应调优,突破传统SaaS多租户的性能边界。为技术决策者提供从架构选型到伦理合规的全维度指导,助力企业把握AI原生时代的多租户技术红利。
一、概念基础
1.1 领域背景化:AI原生应用的多租户需求起源
AI原生应用(AI-Native Application)是指从架构设计到核心功能均深度依赖AI能力的新一代软件系统,其典型特征包括:
- 模型驱动:业务逻辑由机器学习模型主导(如推荐系统、智能客服);
- 数据动态性:实时摄入多源数据并持续优化模型(如实时风控、个性化医疗);
- 算力敏感:模型推理/训练对计算资源的需求呈指数级增长(如大语言模型LLM服务)。
传统SaaS的多租户架构(如Salesforce的租户隔离方案)以数据隔离为核心,通过数据库分片、租户ID标识等技术实现“逻辑隔离,物理共享”。但AI原生应用的多租户需求更复杂:
- 模型共享 vs 租户专属:租户可能需要共享基础模型(如LLM),但要求输出结果符合自身业务规则(如法律文本生成需适配不同法域);
- 资源动态性:不同租户的模型推理/训练任务对GPU、内存的需求差异极大(如A/B测试时的流量突增);
- 隐私合规:租户数据(如医疗诊断记录、金融交易数据)需满足严格的隐私保护法规(GDPR、HIPAA)。
1.2 历史轨迹:从传统多租户到AI原生多租户
| 阶段 | 时间范围 | 核心技术特征 | 典型场景 | 局限性 |
|---|---|---|---|---|
| 单体应用 | 2000s前 | 单实例服务单租户 | 企业定制软件 | 成本高、扩展性差 |
| 传统SaaS多租户 | 2010s | 逻辑隔离(租户ID+数据库分片) | CRM、OA系统 | 模型/算法无法共享 |
| AI增强多租户 | 2015s-2020s | 模型参数部分共享(如迁移学习) | 基础AI API服务(OCR、NLP) | 租户专属需求满足度低 |
| AI原生多租户 | 2020s至今 | 动态资源池+模型自适应调优 | 大模型API、智能决策系统 | 隔离与共享的平衡难题 |
1.3 问题空间定义
AI原生多租户的核心问题可抽象为三元组:
Problem=(T,R,C) \text{Problem} = (\mathcal{T}, \mathcal{R}, \mathcal{C}) Problem=(T,R,C)
- T\mathcal{T}T:租户集合(Tenants),每个租户有属性向量 t={t隐私等级,t资源需求,t模型偏好}\mathbf{t} = \{t_{\text{隐私等级}}, t_{\text{资源需求}}, t_{\text{模型偏好}}\}t={t隐私等级,t资源需求,t模型偏好};
- R\mathcal{R}R:资源池(Resources),包含计算(GPU/CPU)、存储(模型参数/数据)、网络资源;
- C\mathcal{C}C:约束条件(Constraints),包括隔离性(CisolationC_{\text{isolation}}Cisolation)、性能(ClatencyC_{\text{latency}}Clatency)、成本(CcostC_{\text{cost}}Ccost)、合规(CcomplianceC_{\text{compliance}}Ccompliance)。
目标是找到资源分配策略 π:T→R\pi: \mathcal{T} \rightarrow \mathcal{R}π:T→R,最大化 ∑t∈T(Vt(π(t))−C(π(t)))\sum_{t \in \mathcal{T}} (V_t(\pi(t)) - C(\pi(t)))∑t∈T(Vt(π(t))−C(π(t))),其中 VtV_tVt 是租户价值,CCC 是资源使用成本。
1.4 术语精确性
- 租户隔离:确保租户数据、模型状态、计算资源互不干扰,分为强隔离(物理隔离,如专用GPU)和弱隔离(逻辑隔离,如容器化);
- 租户感知(Tenant Awareness):系统能识别租户身份并动态调整行为(如模型微调、资源配额);
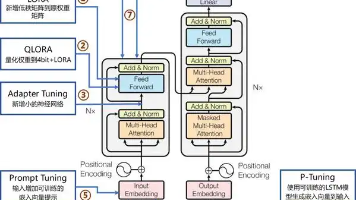
- 共享基模型(Shared Base Model):多租户共享的预训练模型(如GPT-4、Llama),通过适配器(Adapter)实现租户专属适配;
- 动态资源池化(Dynamic Resource Pooling):基于租户需求实时调整资源分配(如Kubernetes的HPA自动扩缩容)。
二、理论框架
2.1 第一性原理推导:从资源共享公理到AI多租户模型
分布式系统的核心公理是资源有限性与需求多样性的矛盾,AI原生多租户的特殊性源于:
- 模型的可组合性:预训练模型的参数可通过Adapter(如LoRA)、提示工程(Prompt Engineering)实现租户定制,而无需全量复制;
- 数据的隐私敏感性:租户数据可能包含受保护信息(PHI、PII),需满足“数据可用不可见”(如联邦学习、安全多方计算);
- 计算的规模经济性:共享基模型的推理/训练可显著降低单租户成本(如OpenAI的API按token计费)。
基于上述公理,AI多租户的最优解需满足:
minπ(α⋅Cisolation+β⋅Ccost+γ⋅Clatency) \min_{\pi} \left( \alpha \cdot C_{\text{isolation}} + \beta \cdot C_{\text{cost}} + \gamma \cdot C_{\text{latency}} \right) πmin(α⋅Cisolation+β⋅Ccost+γ⋅Clatency)
s.t.∀t1≠t2:I(t1,t2)≥ϵ \text{s.t.} \quad \forall t_1 \neq t_2: I(t_1, t_2) \geq \epsilon s.t.∀t1=t2:I(t1,t2)≥ϵ
其中,α,β,γ\alpha,\beta,\gammaα,β,γ 是权重系数,I(t1,t2)I(t_1, t_2)I(t1,t2) 是租户间的隔离度指标(如数据泄露概率、模型参数干扰度),ϵ\epsilonϵ 是最小可接受隔离度。
2.2 数学形式化
(1)租户特征模型
每个租户 ttt 可表示为多维特征向量:
KaTeX parse error: Expected 'EOF', got '_' at position 74: … t_{\text{model_̲type}}, t_{\tex…
- tprivacy∈{0,1}t_{\text{privacy}} \in \{0,1\}tprivacy∈{0,1}:0表示公开数据,1表示敏感数据;
- tconcurrencyt_{\text{concurrency}}tconcurrency:并发请求数;
- KaTeX parse error: Expected 'EOF', got '_' at position 15: t_{\text{model_̲type}}:所需模型类型(如LLM、CV模型);
- tSLAt_{\text{SLA}}tSLA:服务等级协议(如99.9%可用性)。
(2)资源分配函数
资源池 R\mathcal{R}R 包含计算资源 rcomputer_{\text{compute}}rcompute、存储资源 rstorager_{\text{storage}}rstorage、模型参数 rmodelr_{\text{model}}rmodel。分配策略 π(t)\pi(t)π(t) 需满足:
KaTeX parse error: Expected 'EOF', got '_' at position 64: …(t_{\text{model_̲type}}, t_{\tex…
rstorage(t)≥sdata(t)+sadapter(t) r_{\text{storage}}(t) \geq s_{\text{data}}(t) + s_{\text{adapter}}(t) rstorage(t)≥sdata(t)+sadapter(t)
其中,finferencef_{\text{inference}}finference 是推理所需计算资源函数,sdata(t)s_{\text{data}}(t)sdata(t) 是租户数据存储量,sadapter(t)s_{\text{adapter}}(t)sadapter(t) 是租户专属适配器参数存储量(通常远小于基模型参数)。
(3)隔离度计算
租户 t1t_1t1 和 t2t_2t2 的隔离度 I(t1,t2)I(t_1, t_2)I(t1,t2) 可定义为:
I(t1,t2)=1−(λ⋅Shared Computercompute(t1)+rcompute(t2)+(1−λ)⋅Shared Datasdata(t1)+sdata(t2)) I(t_1, t_2) = 1 - \left( \lambda \cdot \frac{\text{Shared Compute}}{r_{\text{compute}}(t_1)+r_{\text{compute}}(t_2)} + (1-\lambda) \cdot \frac{\text{Shared Data}}{s_{\text{data}}(t_1)+s_{\text{data}}(t_2)} \right) I(t1,t2)=1−(λ⋅rcompute(t1)+rcompute(t2)Shared Compute+(1−λ)⋅sdata(t1)+sdata(t2)Shared Data)
λ\lambdaλ 是计算与数据的权重(敏感数据场景下 λ≈0\lambda \approx 0λ≈0)。
2.3 理论局限性
- 隔离-共享权衡:强隔离(如专用GPU)提高安全性但降低资源利用率,弱隔离(如容器共享GPU)可能因资源竞争导致性能波动;
- 模型干扰风险:多租户共享基模型时,租户A的微调可能影响租户B的推理结果(“模型污染”);
- 动态性复杂度:租户需求的实时变化(如突发流量)可能导致资源分配算法失效(如贪心算法陷入局部最优)。
2.4 竞争范式分析
| 范式 | 核心机制 | 适用场景 | 优势 | 劣势 |
|---|---|---|---|---|
| 全复制(Full Copy) | 为每个租户复制完整模型 | 高隔离需求(如军工) | 完全隔离,无干扰 | 成本高(模型参数×N) |
| 基模型+适配器 | 共享基模型,租户使用适配器 | 通用AI服务(如API平台) | 成本低,灵活适配 | 可能存在模型干扰 |
| 联邦学习 | 租户本地训练,共享模型更新 | 敏感数据场景(如医疗) | 数据不出域,隐私性强 | 通信开销大,收敛慢 |
三、架构设计
3.1 系统分解:四层架构模型
AI原生多租户系统可分解为租户接入层→租户管理层→资源池层→基础设施工层(如图1所示):
图1:AI原生多租户系统分层架构
- 租户接入层:处理租户认证(OAuth2/JWT)、请求路由(基于租户ID)、流量整形(限流/熔断);
- 租户管理层:维护租户元数据(如SLA、资源配额)、动态生成适配器(如通过AutoML)、监控租户健康度(如延迟、错误率);
- 资源池层:包括模型仓库(存储基模型、适配器、租户专属模型)、计算集群(GPU/CPU资源池)、存储集群(租户数据、日志);
- 基础设施层:基于云原生技术(Kubernetes、Docker)实现弹性扩缩容,支持混合云/边缘部署。
3.2 组件交互模型:请求处理全流程
租户请求的典型处理流程如下(以LLM推理为例):
- 认证与路由:租户通过API网关发送请求,携带JWT令牌;网关验证令牌并提取租户ID(tidt_idtid)。
- 租户上下文加载:租户管理层根据tidt_idtid查询元数据,获取租户的资源配额、适配器路径、SLA要求。
- 模型组装:从模型仓库加载基模型(如Llama-70B)和租户适配器(如LoRA参数),组装为租户专属模型。
- 资源分配:计算集群调度器根据租户的并发请求数和资源配额,分配GPU实例(如通过Kubernetes的Pod调度)。
- 推理执行:租户专属模型在分配的GPU上执行推理,结果返回前进行脱敏处理(如屏蔽其他租户信息)。
- 监控与反馈:记录推理延迟、错误率等指标,反馈至租户管理层调整资源配额或适配器参数。
3.3 设计模式应用
- 共享基模型+轻量级适配器(Shared Base + Lightweight Adapter):如Hugging Face的PEFT(Parameter-Efficient Fine-Tuning)框架,通过添加小参数适配器(占基模型0.1%-1%参数)实现租户定制,显著降低存储/计算成本;
- 动态容器化(Dynamic Containerization):使用Kubernetes的StatefulSet管理租户专属容器,结合HPA(Horizontal Pod Autoscaler)根据流量自动扩缩容;
- 隐私增强计算集成(PEC Integration):在数据预处理阶段集成同态加密(HE)或安全多方计算(MPC),确保租户数据在共享计算时“可用不可见”(如医疗影像分析场景)。
四、实现机制
4.1 算法复杂度分析
以资源分配算法为例,假设租户集合大小为NNN,资源维度为DDD(如GPU、内存、网络),常用算法的时间复杂度如下:
| 算法 | 时间复杂度 | 适用场景 | 优势 | 劣势 |
|---|---|---|---|---|
| 贪心算法 | O(N⋅D)O(N \cdot D)O(N⋅D) | 实时性要求高(如在线调度) | 计算快,实现简单 | 可能陷入局部最优 |
| 线性规划 | O(N3)O(N^3)O(N3) | 离线资源规划 | 全局最优解 | 计算成本高,难实时 |
| 强化学习(PPO) | O(T⋅N⋅D)O(T \cdot N \cdot D)O(T⋅N⋅D) | 动态环境(流量波动大) | 自适应优化 | 训练时间长,调参复杂 |
4.2 优化代码实现:基于Kubernetes的租户容器管理
以下是通过Kubernetes API动态创建租户专属Pod的Python示例(使用Kubernetes Client库):
from kubernetes import client, config
def create_tenant_pod(tenant_id: str, model_type: str, gpu_request: int):
# 加载Kubernetes配置(本地或集群)
config.load_incluster_config()
v1 = client.CoreV1Api()
# 定义Pod模板(租户隔离通过命名空间+标签实现)
pod = client.V1Pod(
metadata=client.V1ObjectMeta(
name=f"tenant-{tenant_id}-{model_type}",
namespace=f"tenant-{tenant_id}",
labels={"tenant": tenant_id, "model": model_type}
),
spec=client.V1PodSpec(
containers=[client.V1Container(
name=f"{model_type}-container",
image="ai-native/llm:v2",
resources=client.V1ResourceRequirements(
requests={"nvidia.com/gpu": str(gpu_request)},
limits={"nvidia.com/gpu": str(gpu_request)}
),
env=[client.V1EnvVar(
name="TENANT_ID",
value=tenant_id
)]
)],
restart_policy="Always"
)
)
# 创建Pod
try:
response = v1.create_namespaced_pod(
namespace=f"tenant-{tenant_id}",
body=pod
)
return f"Pod {response.metadata.name} created successfully"
except client.ApiException as e:
return f"Error creating pod: {e}"
4.3 边缘情况处理
- 租户流量突增:通过Kubernetes的HPA结合Prometheus监控,设置基于GPU利用率的自动扩缩容策略(如利用率>80%时增加Pod);
- 模型漂移(Model Drift):租户管理层定期触发模型再训练(使用租户近期数据),并通过A/B测试验证新模型性能;
- 数据泄露风险:租户数据存储时加密(AES-256),传输时使用TLS 1.3,访问日志记录完整操作轨迹(满足GDPR的可追溯性要求)。
4.4 性能考量
- 延迟优化:通过模型量化(如FP16→INT8)减少推理时间,或使用模型蒸馏(Distillation)生成轻量级租户专属模型;
- 吞吐量提升:采用批处理(Batching)技术,将多个租户的小请求合并为大批次(需保证租户数据隔离);
- 成本控制:利用云厂商的抢占式实例(Spot Instances)处理非实时任务(如模型训练),降低GPU使用成本。
五、实际应用
5.1 实施策略:分阶段部署路径
- 单租户验证(Phase 1):选择1-2个高价值租户,部署专用AI应用,验证模型效果与业务价值;
- 多租户试点(Phase 2):基于试点租户需求设计多租户架构(如选择基模型+适配器模式),重点解决隔离性与资源共享的基础问题;
- 全量推广(Phase 3):扩展至更多租户,引入自动化工具(如租户自服务控制台、智能资源调度系统),优化运营效率;
- 持续优化(Phase 4):通过租户反馈迭代模型与架构(如引入联邦学习支持敏感数据租户)。
5.2 集成方法论:与现有系统的API对接
AI原生多租户系统通常通过REST/gRPC API与企业现有系统(如CRM、ERP)集成。关键集成点包括:
- 身份同步:通过SAML/OAuth2与企业IDP(如Okta、Azure AD)对接,实现租户身份的统一管理;
- 数据同步:使用Kafka等消息队列同步租户业务数据(如订单、用户行为),作为模型训练/推理的输入;
- 结果回写:将AI输出(如推荐结果、风险评分)通过Webhook或API写入企业数据库(需验证租户权限)。
5.3 部署考虑因素
- 云原生优先:基于Kubernetes构建,支持公有云(AWS/GCP/Azure)、私有云(OpenStack)、混合云部署;
- 边缘计算集成:对延迟敏感的租户(如实时风控),在边缘节点部署轻量级模型(如TensorFlow Lite),核心模型在中心云训练;
- 多区域容灾:在全球多个区域部署副本(如AWS的多可用区),通过Anycast DNS实现租户请求路由至最近节点。
5.4 运营管理
- 监控体系:通过Prometheus+Grafana监控租户级指标(请求量、延迟、错误率)和系统级指标(GPU利用率、内存占用);
- 计费模型:按资源使用量(如GPU小时数、token数)或业务结果(如推荐点击量)计费,支持灵活定价策略;
- 租户生命周期管理:提供自服务控制台,支持租户自助注册、升级/降级套餐、停用账户(需清理租户数据与模型)。
六、高级考量
6.1 扩展动态:租户规模增长的架构演进
当租户数量从100增长至10万时,系统需经历三次关键演进:
- 水平扩展(100→1万):增加资源池规模(如GPU集群从100张扩展至1000张),优化调度算法(从贪心到强化学习);
- 架构分层(1万→10万):引入多级资源池(热池:实时推理,冷池:离线训练),租户根据SLA等级分配至不同层级;
- 自治化(10万+):通过AIOps自动优化资源分配(如使用AutoML调优调度策略)、预测租户需求(如基于历史数据预测流量高峰)。
6.2 安全影响:隐私计算与模型安全
- 隐私保护:对敏感数据租户(如医疗、金融),采用联邦学习(FL)+ 差分隐私(DP)技术:
- 联邦学习:租户在本地训练模型,仅上传梯度更新(而非原始数据);
- 差分隐私:在梯度更新中添加噪声(Laplace机制),防止模型反演攻击(Model Inversion Attack)。
- 模型安全:通过模型水印(Watermarking)防止租户窃取基模型(如在模型参数中嵌入唯一标识),或使用模型混淆(Obfuscation)增加逆向工程难度。
6.3 伦理维度:算法公平性与租户歧视
- 公平性风险:共享基模型可能隐含训练数据中的偏见(如性别、种族偏见),导致不同租户的输出结果不公平(如招聘推荐系统对女性候选人的歧视);
- 缓解策略:在模型训练阶段引入公平性约束(如Equalized Odds),在推理阶段对租户输出结果进行偏见检测(如使用Fairlearn工具包),并提供租户申诉渠道。
6.4 未来演化向量
- 自治多租户(Autonomous Multi-Tenancy):租户AI代理(如AutoGPT)自动协商资源分配、模型适配策略,减少人工干预;
- 神经架构搜索(NAS)优化:通过NAS为不同租户自动生成最优模型架构(如小租户使用轻量级模型,大租户使用大模型);
- 跨租户知识迁移(Cross-Tenant Knowledge Transfer):在确保隐私的前提下,允许租户共享非敏感知识(如行业通用特征)以提升模型性能。
七、综合与拓展
7.1 跨领域应用
- 医疗AI:多租户电子病历分析系统,不同医院共享基模型但保留各自患者数据隐私(通过联邦学习);
- 金融科技:多租户智能风控系统,银行共享反欺诈模型但根据自身业务规则调整风险阈值(通过适配器);
- 智能制造:多租户设备预测性维护系统,制造商共享设备故障检测模型但适配不同产线的传感器数据(通过动态特征工程)。
7.2 研究前沿
- 动态多租户模型(Dynamic Multi-Tenant Models):MIT CSAIL提出的“Tenant-Aware Layers”,在模型训练阶段显式编码租户信息,提升适配效率(论文:Dynamic Parameter Allocation for Multi-Tenant Neural Networks);
- 隐私增强多租户系统(PE-MT):UC Berkeley的“PrivateMaaS”框架,结合同态加密与模型分片,实现“计算在云端,数据在本地”(论文:PrivateMaaS: Privacy-Preserving Model-as-a-Service);
- 多租户模型的可解释性:斯坦福HAI实验室开发的“TenantX”工具,可视化租户专属适配器对模型决策的影响(如哪些特征被租户A重点关注)。
7.3 开放问题
- 跨租户知识迁移的平衡:如何在不泄露隐私的前提下,让租户从其他租户的知识中受益(如“隐私安全的知识蒸馏”);
- 实时多租户资源调度:如何在毫秒级响应租户需求变化(如大模型API的突发流量),同时保证全局最优;
- 多租户模型的长期维护:基模型过时后(如LLM的知识截止日期),如何高效更新所有租户的适配器(“模型版本升级的级联影响”)。
7.4 战略建议
- 优先构建可扩展的基础架构:选择云原生、模块化的技术栈(如Kubernetes+TensorFlow Serving),预留模型/资源扩展接口;
- 强化隐私保护能力:针对敏感行业租户(医疗、金融),提前集成联邦学习、同态加密等隐私计算技术;
- 设计租户价值导向的定价模型:根据租户对资源的需求弹性(如实时性要求)制定差异化定价(如“按需付费”+“预留容量折扣”);
- 建立伦理合规体系:成立算法公平性委员会,定期审计模型输出,确保符合《人工智能伦理准则》(如欧盟AI法案)。
教学元素附录
概念桥接:多租户与共享办公空间
- 共享基模型 ≈ 共享办公区的公共设施(如会议室、打印机);
- 租户适配器 ≈ 租户的专属办公隔间(定制化但共享基础结构);
- 租户隔离 ≈ 办公空间的门禁系统(确保只有授权人员进入专属区域);
- 动态资源分配 ≈ 智能办公系统根据租户预约自动调整会议室大小(小团队用小会议室,大团队用大会议室)。
思维模型:“共享-隔离”二维决策图
graph LR
A[高共享/低隔离] --> B[通用AI API(如OCR)]
A --> C[成本优先场景]
D[低共享/高隔离] --> E[军工AI系统]
D --> F[安全优先场景]
G[高共享/高隔离] --> H[医疗AI(联邦学习)]
G --> I[隐私+成本双优先]
J[低共享/低隔离] --> K[传统定制软件]
J --> L[早期市场]
style A fill:#ff9,stroke:#333
style D fill:#f9f,stroke:#333
style G fill:#9f9,stroke:#333
style J fill:#99f,stroke:#333
图2:多租户决策的“共享-隔离”二维模型
案例研究:OpenAI的多租户API服务
OpenAI的GPT-4 API是典型的AI原生多租户系统,其关键设计包括:
- 基模型共享:所有租户共享GPT-4大模型,通过提示工程(Prompt)实现租户专属输出(如法律文本生成、代码编写);
- 动态资源池:基于Azure的GPU集群,通过自动扩缩容应对流量波动(如ChatGPT发布时的百万级并发请求);
- 隐私保护:租户输入的prompt默认不用于模型训练(可选开启数据共享以提升模型),符合GDPR要求;
- 计费模型:按token数计费(输入+输出),对高并发租户提供预留容量折扣。
参考资料
- OpenAI. (2023). GPT-4 Technical Report.
- Cloud Native Computing Foundation. (2022). Multi-Tenancy in Cloud Native Applications.
- MIT CSAIL. (2023). Dynamic Parameter Allocation for Multi-Tenant Neural Networks.
- UC Berkeley. (2024). PrivateMaaS: Privacy-Preserving Model-as-a-Service.
- NIST. (2023). Framework for AI Risk Management (AI RMF).

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 4
4 0
0- 0



 已为社区贡献153条内容
已为社区贡献153条内容

所有评论(0)