RAG核心特性:文档过滤和检索
文档过滤和检索,也是RAG的核心特性之一,在进行向量转换和存储之后,需要通过文档过滤和检索,优化大模型回复的准确性。整个文档过滤和检索的过程,可以划分为检索前检索时检索后。
本文为个人学习笔记整理,仅供交流参考,非专业教学资料,内容请自行甄别。
文章目录
概述
文档过滤和检索,也是RAG的核心特性之一,在进行向量转换和存储之后,需要通过文档过滤和检索,优化大模型回复的准确性。整个文档过滤和检索的过程,可以划分为检索前,检索时,检索后
一、预检索阶段
预检索阶段,是在将用户提问发送给大模型之前,进行优化。让用户的原始查询更加清晰和详细。其主要的手段有:
- 查询转换-查询翻译:将一种查询语言翻译成另一种语言,用于国际化(直接用AI进行翻译,但是调用的成本比调用第三方翻译的API要高)
- 查询转换-查询压缩:将对话历史和后续查询压缩成一个独立的查询,进行概括总结,适用于历史对话较长,并且后续查询和历史上下文相关的场景
- 查询扩展- 多查询扩展:将用户查询的语句,扩展为多个不同的关键词,从不同的角度进行搜索
- 查询转换-查询重写:将用户的提问进行优化,转化为大模型更能理解的语言。
1.1、查询转换-查询翻译
查询翻译主要利用了TranslationQueryTransformer类,它的作用是实现国际化,将用户发送给大模型的语言,翻译成目标的语言: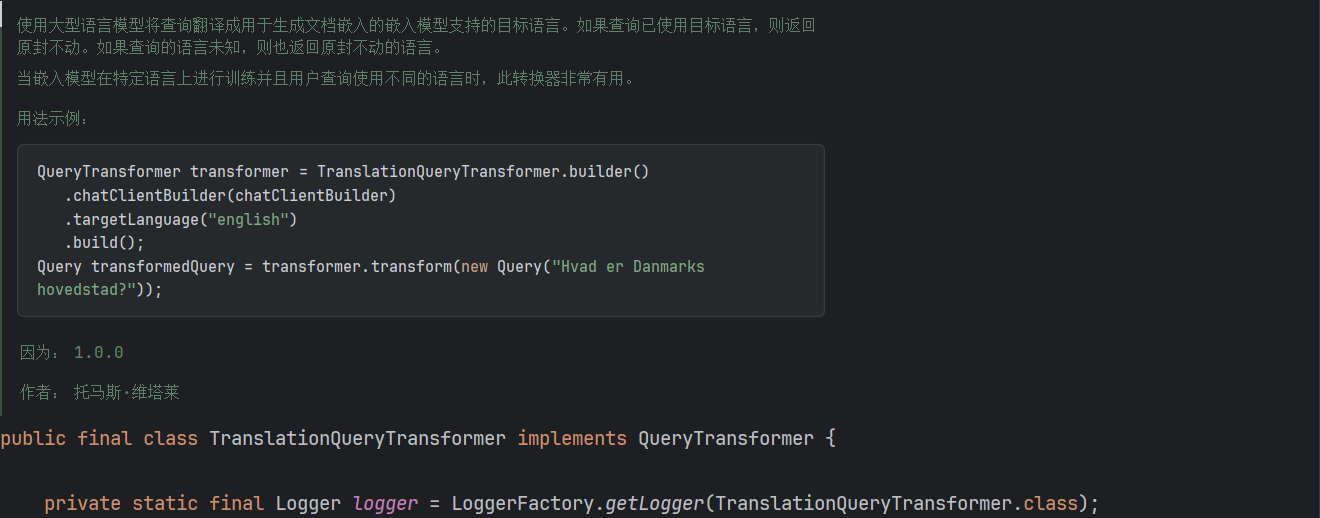
它的底层同样是通过预设提示词 + 调用大模型的方式,实现翻译。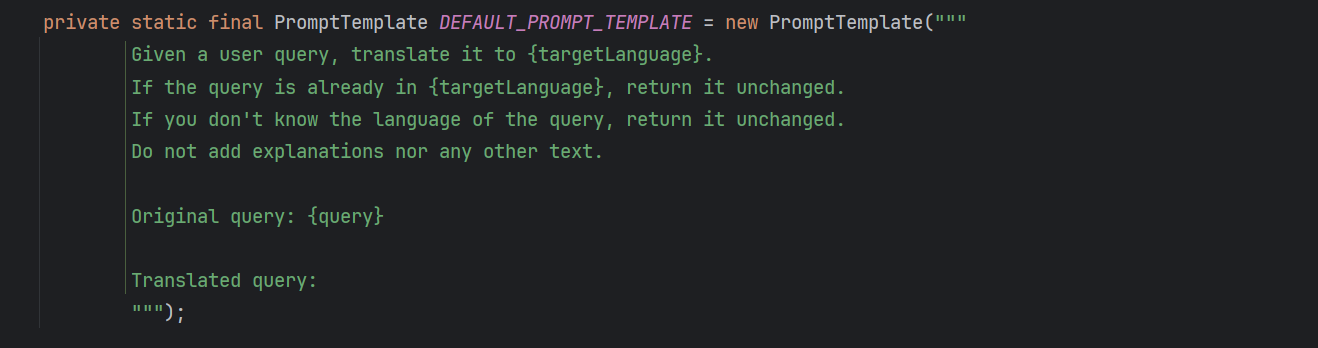
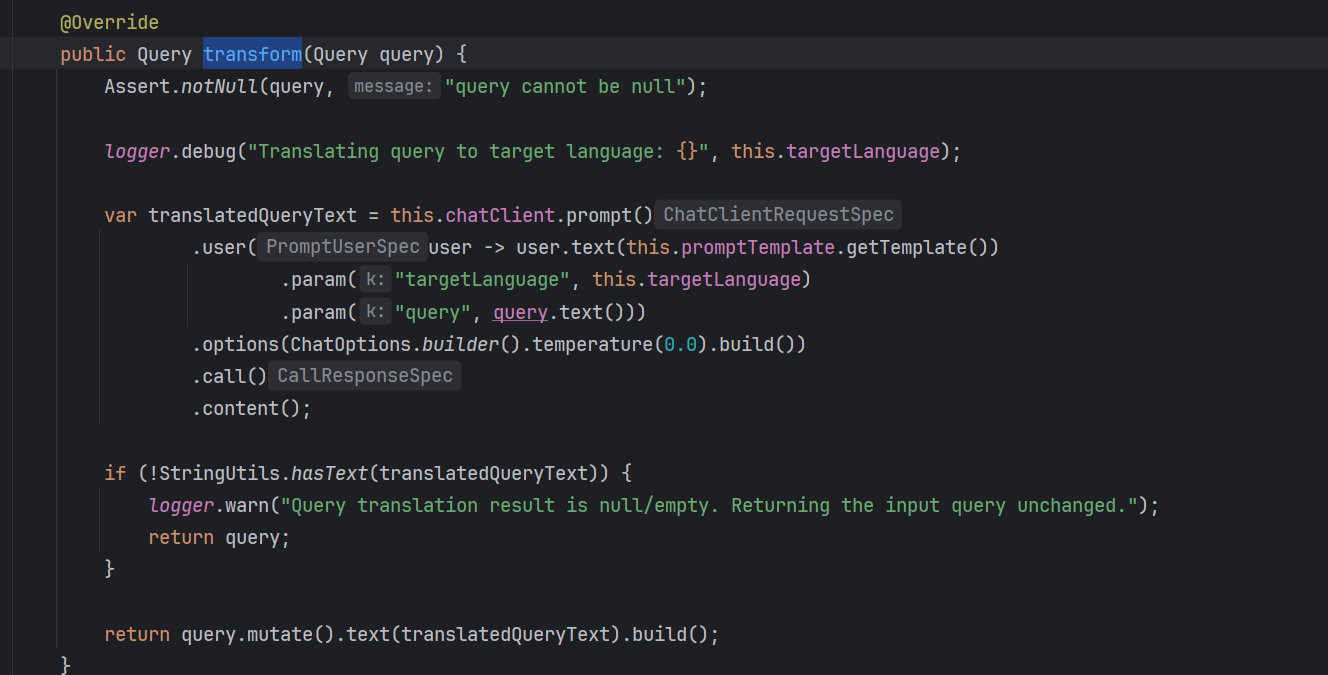
运用场景:编写一个方法,构造QueryTransformer,并且通过transform转换结果。
@Component
public class QueryTransformerFacotry {
private final QueryTransformer queryTransformer;
public QueryTransformerFacotry(ChatModel dashscopeChatModel){
ChatClient.Builder builder = ChatClient.builder(dashscopeChatModel);
queryTransformer = TranslationQueryTransformer.builder()
.chatClientBuilder(builder)
.targetLanguage("chinese")
.build();
}
public Query getQueryTransformer(String text){
Query query = new Query(text);
return queryTransformer.transform(query);
}
}
在调用大模型时,进行转换:
@Resource
private QueryTransformerFacotry queryTransformerFacotry;
/**
* 测试RAG知识库
* @param message
* @param chatId
* @return
*/
public String doChatWithRAGTransfer(String message, String chatId){
ChatResponse response = chatClient
.prompt()
.user(queryTransformerFacotry.getQueryTransformer(message).text())
.advisors(spec -> spec.param(CHAT_MEMORY_CONVERSATION_ID_KEY, chatId)
.param(CHAT_MEMORY_RETRIEVE_SIZE_KEY, 10))
.advisors(new MyLogAdvisor())
.advisors(new QuestionAnswerAdvisor(vectorStore))
.call()
.chatResponse();
return response.getResult().getOutput().getText();
}
编写单元测试类:
@Test
void doChatWithRAGTransfer() {
String chatId = UUID.randomUUID().toString();
String message = "who is dog";
String answer = loveApp.doChatWithRAGTransfer(message, chatId);
Assertions.assertNotNull(answer);
}
翻译前:
翻译后: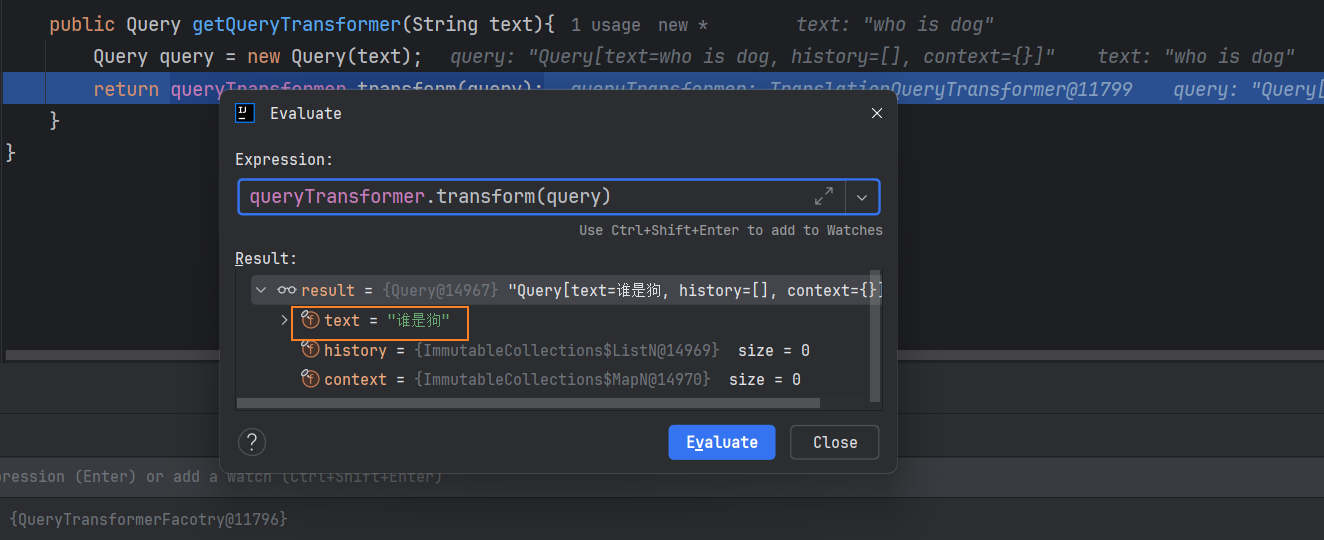
1.2、查询转换-查询压缩
CompressionQueryTransformer将使用大型语言模型将对话历史记录和后续查询压缩成独立查询。当对话历史记录很长且后续查询与对话上下文相关时,此转换器非常有用。
案例代码:
@Component
public class CompressionQueryTransformerFactory {
private final QueryTransformer queryTransformer;
public CompressionQueryTransformerFactory(ChatModel dashscopeChatModel){
ChatClient.Builder builder = ChatClient.builder(dashscopeChatModel);
queryTransformer = CompressionQueryTransformer.builder()
.chatClientBuilder(builder)
.build();
}
/**
Query query = Query.builder()
.text("编程导航有啥内容?")
.history(new UserMessage("谁是程序员鱼皮?"),
new AssistantMessage("编程导航的创始人 codefather.cn"))
.build();
**/
public Query getCompressionQuery(String text,Query query){
return queryTransformer.transform(query);
}
}
这里的运用方式和1.1、查询转换-查询翻译的一致。
1.3、查询转换-查询重写
查询重写,对应的是RewriteQueryTransformer,当用户查询冗长、模棱两可或包含可能影响搜索结果质量的不相关信息时,此转换器非常有用。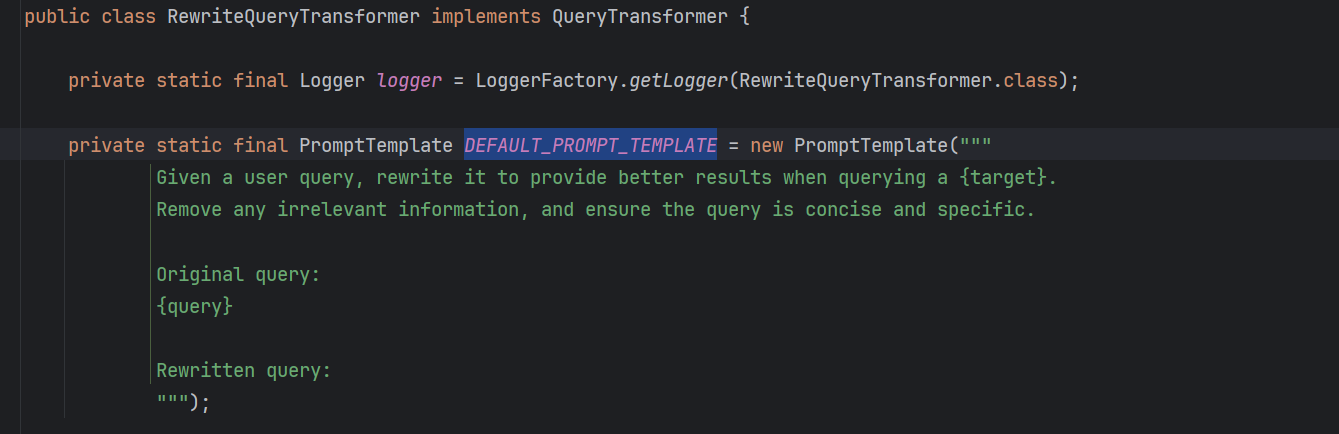
案例代码:
@Component
public class RewriteQueryTransformerFactory {
private final QueryTransformer queryTransformer;
public RewriteQueryTransformerFactory(ChatModel dashscopeChatModel){
ChatClient.Builder builder = ChatClient.builder(dashscopeChatModel);
queryTransformer = RewriteQueryTransformer.builder()
.chatClientBuilder(builder)
.build();
}
public Query getRewriteQuery(String text){
return queryTransformer.transform(new Query(text));
}
}
1.4、查询转换-多查询扩展
多查询扩展利用的是MultiQueryExpander,它使用大模型将查询扩展为多个语义上不同的变体,有利于检索额外的上下文信息,获取更精确的结果。即将用户查询的语句,扩展为多个不同的关键词,从不同的角度进行搜索。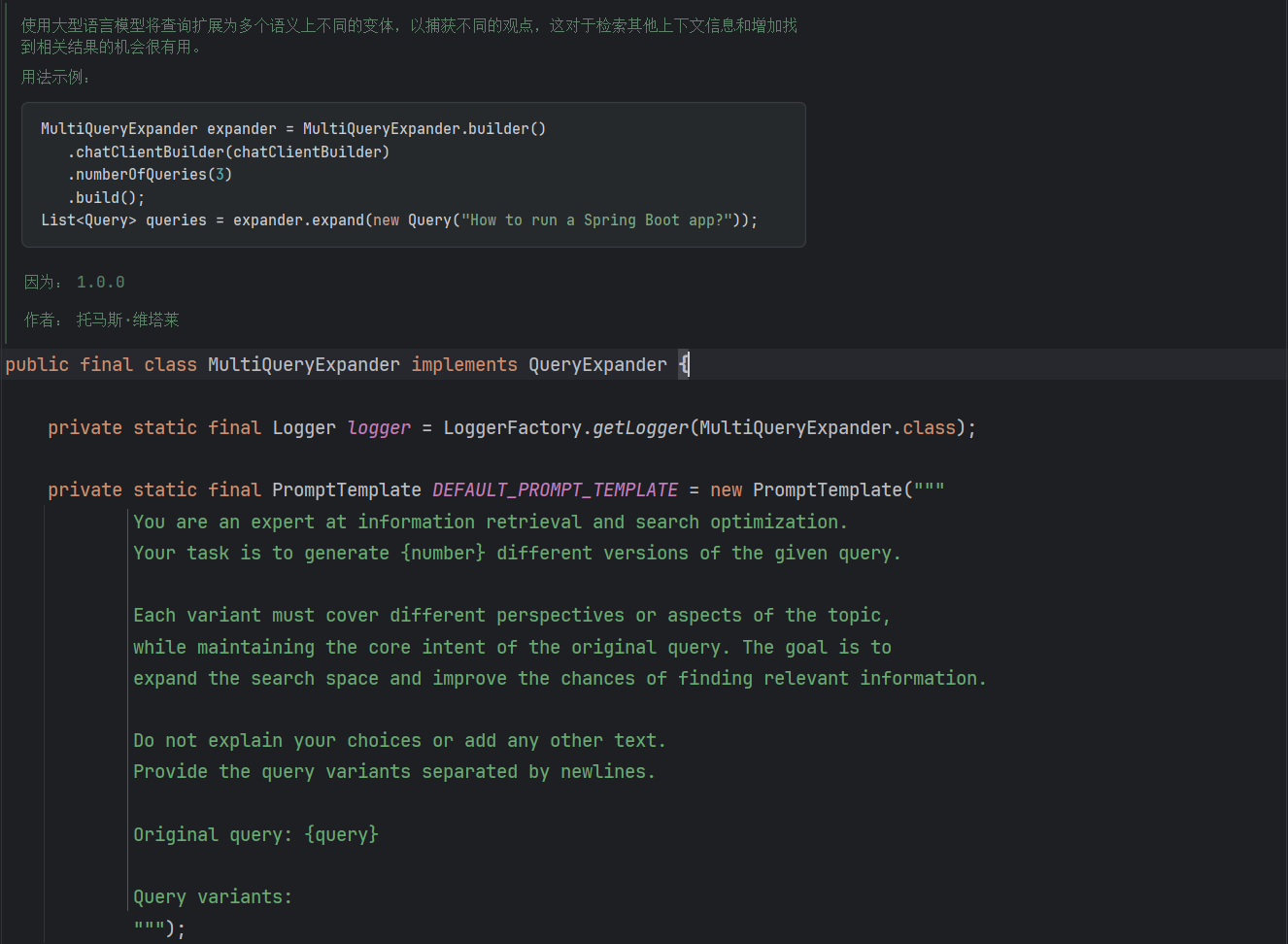
使用案例:
@Component
public class MultiQueryExpanderFactory {
private final ChatClient.Builder builder;
public MultiQueryExpanderFactory(ChatModel dashscopeChatModel) {
builder = ChatClient.builder(dashscopeChatModel);
}
public List<Query> getMultiQueryExpander(int numberOfQueries, String text) {
MultiQueryExpander expander = MultiQueryExpander.
builder().
chatClientBuilder(builder).
numberOfQueries(numberOfQueries).
build();
return expander.expand(new Query(text));
}
}
二、检索阶段
检索阶段的主要目的是,提高查询的相关性,DocumentRetriever是Document从底层数据源(例如搜索引擎、矢量存储、数据库或知识图谱)检索的组件。它有一个VectorStoreDocumentRetriever的实现,是从向量数据库中进行检索: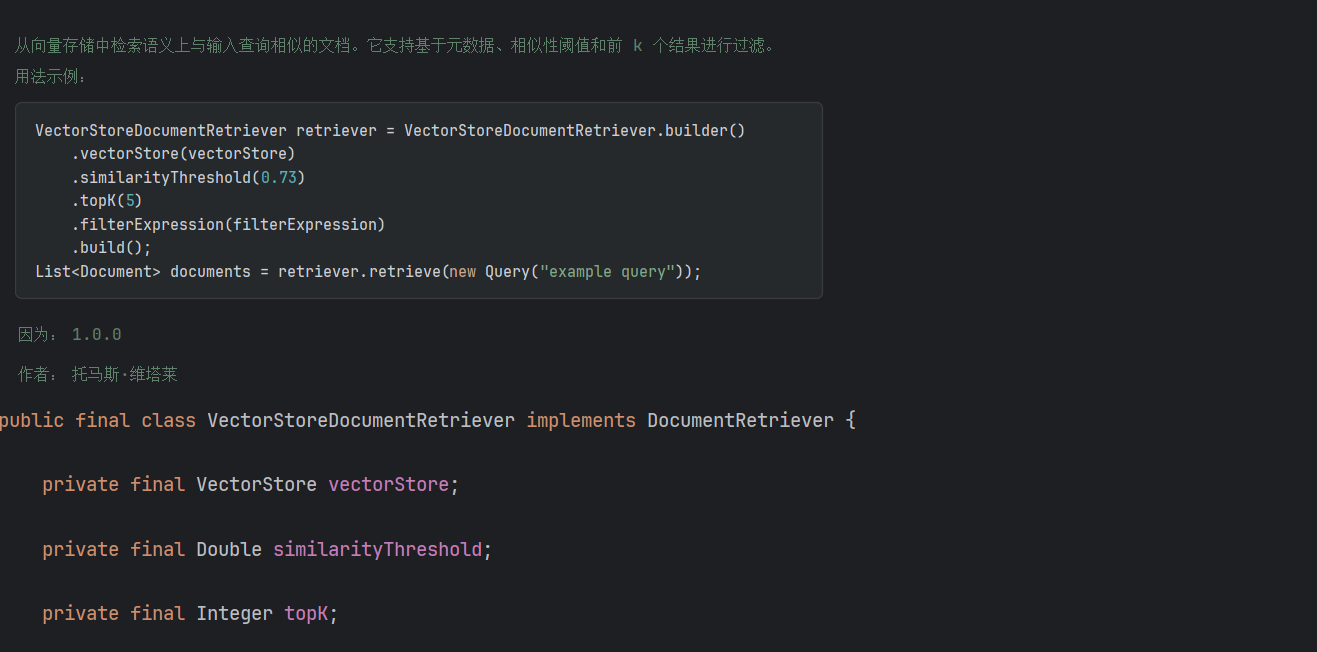
使用案例:
VectorStoreDocumentRetriever retriever = VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore)
.similarityThreshold(0.73)
.topK(5)
.filterExpression(filterExpression)
.build();
List<Document> documents = retriever.retrieve(new Query("example query"));
在Spring AI的内部,还提供了ConcatenationDocumentJoiner文档合并器组件,通过将基于多个查询和从多个数据源检索到的文档合并为单个文档集合来合并它们。如果文档重复,则保留第一次出现(去重)。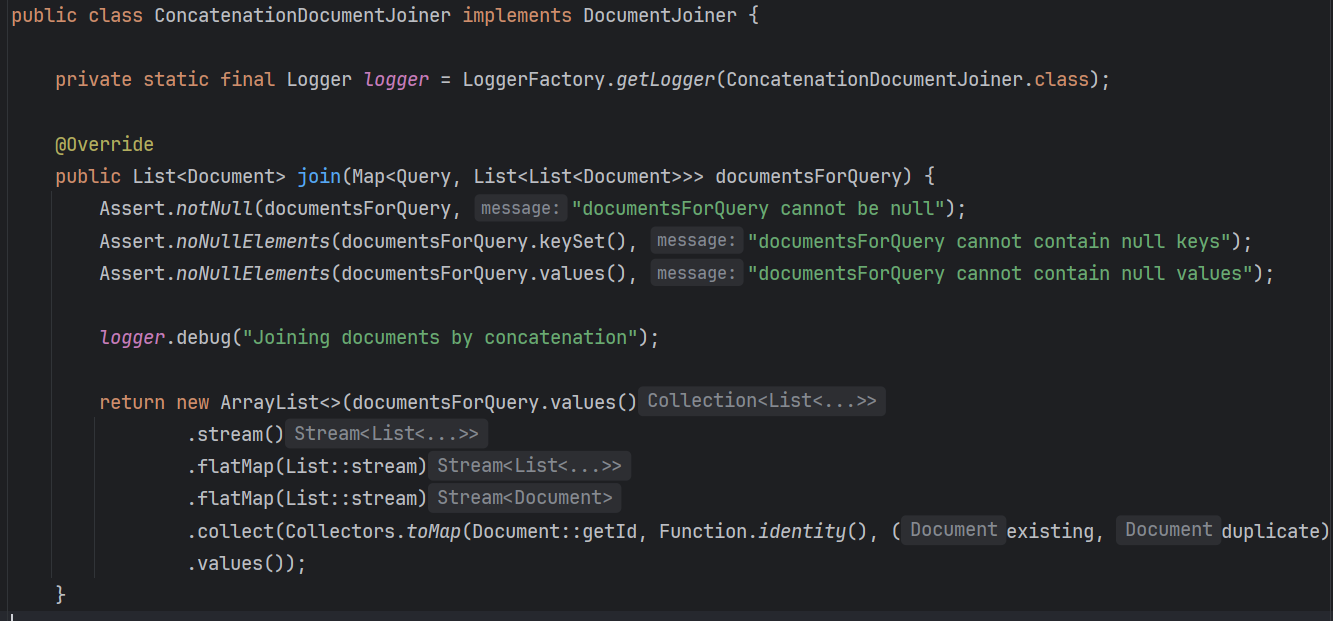
上述的检索组件,虽然Spring AI框架已经帮我们集成了,但有些时候还是需要用户去根据具体业务场景进行配置、扩展和整合的,例如:
@Configuration
public class RagConfig {
// 配置文档检索器(含过滤功能)
@Bean
public VectorStoreRetriever documentRetriever(MilvusVectorStore vectorStore) {
// 1. 构建过滤条件:只检索"技术文档"类别且发布时间在2023年之后的文档
Filter filter = Filter.and(
Filter.eq("category", "技术文档"),
Filter.gt("publishYear", 2023)
);
// 2. 配置检索器
return VectorStoreRetriever.builder()
.vectorStore(vectorStore)
.filter(filter) // 应用过滤条件
.topK(5) // 返回最相似的5个文档
.similarityThreshold(0.7) // 相似度阈值,低于此值的文档不返回
.build();
}
}
三、检索后阶段
检索后阶段的主要目的是对于文档的处理进行优化,可能包括:
- 根据查询到结果的相关性进行排序。
- 去除掉冗余的结果。
- 对文档的内容进行压缩。
四、文档过滤和检索优化
文档过滤和检索优化,主要的优化手段有:
- 利用多查询扩展
- 利用查询重写和翻译
- 检索器配置
4.1、多查询扩展提示词优化
多查询扩展,主要包含以下步骤:
- 根据原有的text,获取扩展后的text
- 使用retrieve进行检索
- 使用ConcatenationDocumentJoiner进行合并处理
- 改写prompt
它的优化点体现在,如果是未改写版本,仅将用户原始问题(text)传递给模型,模型只能依赖自身训练的通用知识回答,无法获取业务 / 领域相关的特定信息。改写后的版本,将用户问题与检索到的documentList文档内容结合,模型可以基于这些外部文档(如企业内部资料、专业知识库等)生成回答,信息来源更具体、更可控。
加入documentList的改写本质是实现了 “检索增强生成(RAG)” 的核心逻辑 —— 让模型从 “仅凭记忆回答” 升级为 “参考指定资料回答”,从而在准确性、相关性、时效性上更符合实际业务需求,尤其适合需要结合特定文档或动态信息的场景。
public String testMultiQueryExpander(String text, String chatId) {
Map<Query, List<List<Document>>> documentsForQuery = new HashMap<>();
//根据原有的text,获取扩展后的
List<Query> queryList = multiQueryExpanderFactory.getMultiQueryExpander(3, text);
//进行检索
for (Query query : queryList) {
DocumentRetriever retriever = VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore)
.similarityThreshold(0.73)
.topK(5)
.build();
// 直接用扩展后的查询来获取文档
List<Document> retrievedDocuments = retriever.retrieve(query);
documentsForQuery.put(query, Collections.singletonList(retrievedDocuments));
}
//进行合并
ConcatenationDocumentJoiner concatenationDocumentJoiner = new ConcatenationDocumentJoiner();
List<Document> documentList = concatenationDocumentJoiner.join(documentsForQuery);
// //改写prompt
// 构建带上下文的提示词
StringBuilder promptBuilder = new StringBuilder();
promptBuilder.append("基于以下信息回答问题:\n\n");
// 添加文档内容作为上下文
for (Document doc : documentList) {
promptBuilder.append("文档内容:").append(doc.getText()).append("\n\n");
}
// 添加原始问题
promptBuilder.append("问题:").append(text);
String enhancedPrompt = promptBuilder.toString();
ChatResponse response = chatClient
.prompt()
.user(enhancedPrompt)
.advisors(spec -> spec.param(CHAT_MEMORY_CONVERSATION_ID_KEY, chatId)
.param(CHAT_MEMORY_RETRIEVE_SIZE_KEY, 10))
.advisors(new MyLogAdvisor())
.advisors(new QuestionAnswerAdvisor(vectorStore))
.call()
.chatResponse();
return response.getResult().getOutput().getText();
}
4.2、检索器配置的优化
检索器配置的优化,主要包含了设置合理的相似度阈值,控制文档返回的数量,配置文档过滤规则。
- 相似度阈值,需要根据文档检索召回的实际结果进行调整。如果发现召回的结果不完整,可以适当的降低阈值,反之则提高阈值。
- 文档返回的数量,也可以根据实际情况在
retriever检索器或者第三方云平台的控制界面进行调整。 - 文档过滤规则,如果是知识库中包含多个
类别的文档,希望限定出检索的范围,可以为文档添加标签。如果是知识库中有多篇结构相似的文档,希望精确定位,可以提取元数据。同样是通过retriever检索器的filterExpression进行设置。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 26
26 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)