大数据工程师转行AI大模型,只需6个月!超详细学习路线助你成为算法工程师!
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
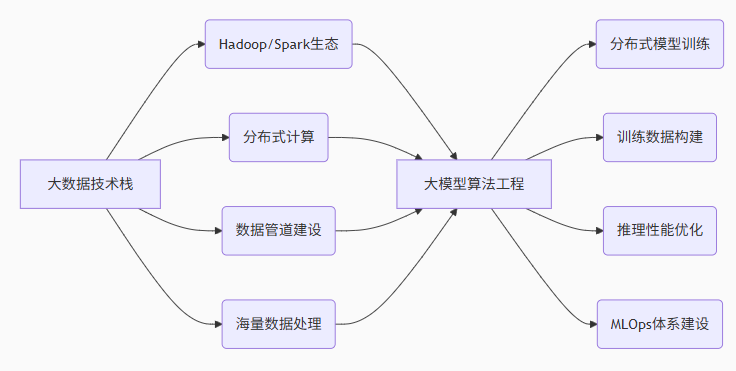
分布式计算+数据工程+大模型=年薪百万!大数据背景是你转型AI算法工程师的超级优势!
前言:大数据工程师是大模型时代最受欢迎的转型者
2025年是大模型落地元年,而拥有大数据处理经验的工程师正在成为AI算法岗位最抢手的人才!为什么?
-
优势1:你已掌握海量数据处理能力——这是大模型训练的基石
-
优势2:分布式系统经验可直接迁移到大模型训练框架
-
优势3:数据管道建设能力是大模型落地的重要环节
以下是为你量身定制的转型路径!
大数据工程师 vs AI算法工程师:你的独特优势
6个月转型计划表(每周投入15-20小时)
| 阶段 | 时间 | 学习重点 | 实战产出 |
|---|---|---|---|
| 基础夯实期 | 第1-2个月 | 深度学习基础+Python进阶 | 图像分类模型 |
| 核心突破期 | 第3-4个月 | 大模型原理+分布式训练 | 文本生成模型 |
| 专项深入期 | 第5个月 | 行业应用+性能优化 | 行业解决方案 |
| 求职准备期 | 第6个月 | 项目复盘+面试准备 | 技术作品集 |
第一阶段:基础夯实(1-2个月)
第1-4周:深度学习基础与Python进阶
python
# 大数据工程师的Python深度学习快速上手
import torch
import torch.nn as nn
import torch.optim as optim
# 从Spark到PyTorch的思维转换
# Spark RDD → PyTorch Tensor
# 分布式数据处理 → 批量训练
# 构建第一个深度学习模型
class SimpleNN(nn.Module):
def __init__(self, input_size, hidden_size, num_classes):
super(SimpleNN, self).__init__()
self.layer1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.layer2 = nn.Linear(hidden_size, num_classes)
def forward(self, x):
out = self.layer1(x)
out = self.relu(out)
out = self.layer2(out)
return out
# 模型训练
model = SimpleNN(784, 500, 10)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 类比大数据批处理
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
# 前向传播
outputs = model(images)
loss = criterion(outputs, labels)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
第5-8周:深度学习框架深度掌握
重点学习:
-
PyTorch/TensorFlow框架核心机制
-
自动微分与计算图原理
-
模型训练与评估流程
实战项目: 基于CIFAR-10的图像分类模型
第二阶段:核心突破(3-4个月)
第9-12周:大模型理论基础
python
# Transformer架构核心实现
import torch
import torch.nn as nn
import math
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
def forward(self, query, key, value, mask=None):
# 线性变换
Q = self.W_q(query)
K = self.W_k(key)
V = self.W_v(value)
# 头部分裂
Q = Q.view(-1, self.num_heads, self.d_k)
K = K.view(-1, self.num_heads, self.d_k)
V = V.view(-1, self.num_heads, self.d_k)
# 注意力计算
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
attention = torch.softmax(scores, dim=-1)
# 输出计算
output = torch.matmul(attention, V)
output = output.view(-1, self.d_model)
return self.W_o(output)
第13-16周:分布式训练与优化
重点学习:
-
数据并行与模型并行原理
-
DeepSpeed/FSDP分布式训练框架
-
混合精度训练与梯度优化
第三阶段:专项深入(第5个月)
第17-20周:大模型应用与优化
python
# 使用你的大数据经验优化模型推理
import torch
from transformers import AutoModel, AutoTokenizer
class OptimizedInference:
def __init__(self, model_name):
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
# 模型加载优化 - 类比大数据缓存策略
self.model = AutoModel.from_pretrained(
model_name,
torch_dtype=torch.float16, # 半精度优化
device_map="auto", # 自动设备分配
low_cpu_mem_usage=True # 低内存占用
)
# 推理批处理 - 类比Spark批处理
self.batch_size = 16
def preprocess_data(self, texts):
# 大数据处理经验的应用
encodings = self.tokenizer(
texts,
padding=True,
truncation=True,
max_length=512,
return_tensors="pt"
)
return encodings
def batch_inference(self, texts):
# 批量推理优化
results = []
for i in range(0, len(texts), self.batch_size):
batch_texts = texts[i:i+self.batch_size]
encodings = self.preprocess_data(batch_texts)
with torch.no_grad():
outputs = self.model(**encodings)
results.extend(outputs.last_hidden_state.mean(dim=1))
return results
第四阶段:求职准备(第6个月)
第21-24周:项目实战与面试准备
打造差异化竞争优势:
-
分布式训练优化项目:展示你的大数据集群管理经验
-
数据处理管道建设:体现数据工程能力
-
模型推理性能优化:展示系统优化能力
面试准备重点:
-
算法基础:深度学习、机器学习基础算法
-
系统设计:分布式训练架构、推理服务设计
-
项目经验:突出大数据背景的独特价值
为什么大数据背景是巨大优势?
直接可迁移的技能:
-
分布式系统经验:直接应用于大模型分布式训练
-
数据管道能力:模型训练数据处理的核心技能
-
性能优化思维:模型推理优化的关键能力
-
集群管理经验:GPU集群管理的天然优势
学习资源与支持
CSDN专属大数据转型套餐:
-
分布式训练专项课:深入讲解多机多卡训练
-
大模型数据处理实战:千亿token数据处理实践
-
推理性能优化大师班: latency优化、吞吐优化
-
企业内推通道:直推需要大数据背景的AI岗位
AI大模型学习路线
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 21
21 0
0- 0



 已为社区贡献287条内容
已为社区贡献287条内容

所有评论(0)