presenton:告别PPT熬夜!这个开源神器让AI帮你做演示文稿,本地部署不泄露数据
【PPT制作神器Presenton开源上线】这款本地部署的AI工具能自动生成专业演示文稿,支持多种模型自由组合(如GPT-4、Llama等),完美适配企业品牌模板。3分钟即可通过Docker部署,数据完全私有,还能用API批量生成。相比付费工具,它更安全灵活,支持PPTX/PDF导出,彻底告别排版熬夜。项目正在快速迭代,现已开放GitHub下载,是职场人士和学术工作者的效率利器。
🔥 告别PPT熬夜!这个开源神器让AI帮你做演示文稿,本地部署不泄露数据
你是不是也有过这样的经历?为了赶一个会议PPT,对着空白幻灯片发呆两小时;好不容易凑完内容,又卡在配色和排版上反复修改;更头疼的是,用在线工具做的演示文稿,总担心数据隐私泄露。
现在,一个叫Presenton的开源项目彻底解决了这些痛点。作为Gamma、Beautiful AI等付费工具的平替,它不仅能让AI自动生成专业级演示文稿,还支持本地部署——所有数据都留在你的设备上,安全感拉满。
项目地址:github.com/presenton/presenton
欢迎大家关注我的公众号:大模型论文研习社
往期回顾:大模型也会 “脑补” 了!Mirage 框架解锁多模态推理新范式,无需生成像素图性能还暴涨
🚀 它凭什么替代付费PPT工具?
打开Presenton的瞬间,你就会发现它和传统PPT工具的本质区别:AI全程参与,却把控制权完全交给你。
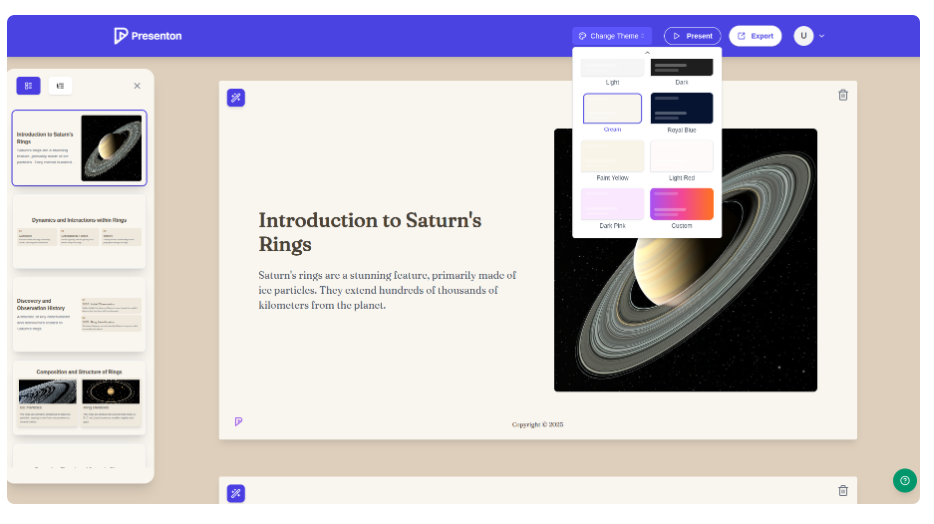
比如你想做一份"土星环科普"的演示文稿,只需输入主题,AI会自动生成8页大纲——从"土星环的组成结构"到"卡西尼号探测器的发现",逻辑脉络清晰;还能根据你的需求调整语气,是选"学术严谨"还是"轻松有趣",一键切换。
更贴心的是模板复用功能。上传你公司的PPT模板,Presenton会自动提取设计风格,下次生成新文稿时,字体、配色、版式都能完美匹配品牌形象,再也不用手动调整每一页。
它的灵活性更是让人惊艳:
- 模型自由:想用OpenAI的GPT-4做文本生成,搭配DALL-E 3出图?没问题。偏爱本地部署,用Ollama跑Llama 3.2?也支持。甚至能混搭 Anthropic Claude 和 Pexels 图片库,组合出专属工作流。
- 格式全能:生成的文稿可直接导出为PPTX或PDF,字体和图表不会出现错乱,拿去打印或分享都不用二次修改。
- 细节可控:从是否包含目录页,到每页文字的详细程度,都能通过参数精确调整。生成后还能在网页端直接编辑,添加图标、修改图表样式。
⚙️ 3分钟部署,小白也能上手
Presenton最良心的地方在于,它把复杂的配置都封装成了简单命令,无论是Linux、macOS还是Windows,跟着步骤走就能跑起来。
方法一:Docker一键启动(推荐新手)
这是最省心的方式,不需要安装额外依赖:
-
拉取镜像并启动
- Linux/macOS(打开终端输入):
docker run -it --name presenton -p 5000:80 -v "./app_data:/app_data" ghcr.io/presenton/presenton:latest- Windows(打开PowerShell输入):
docker run -it --name presenton -p 5000:80 -v "${PWD}\app_data:/app_data" ghcr.io/presenton/presenton:latest这里的
5000是端口号,如果你电脑的5000端口被占用,换成8080或其他数字即可。 -
访问应用
打开浏览器,输入http://localhost:5000,就能看到Presenton的操作界面,不需要注册登录,直接使用。 -
配置AI模型(可选)
如果想指定用OpenAI或Google模型,启动时加上环境变量即可。比如用GPT-4生成文本,DALL-E 3出图:docker run -it --name presenton -p 5000:80 \ -e LLM="openai" -e OPENAI_API_KEY="你的API密钥" \ -e IMAGE_PROVIDER="dall-e-3" -e CAN_CHANGE_KEYS="false" \ -v "./app_data:/app_data" ghcr.io/presenton/presenton:latest用Ollama本地模型也很简单,只需指定模型名称:
docker run -it --name presenton -p 5000:80 \ -e LLM="ollama" -e OLLAMA_MODEL="llama3.2:3b" \ -e IMAGE_PROVIDER="pexels" -e PEXELS_API_KEY="你的API密钥" \ -v "./app_data:/app_data" ghcr.io/presenton/presenton:latest
方法二:GPU加速部署(适合大模型)
如果用Ollama跑7B或更大的模型,建议开启GPU加速,需要先安装NVIDIA容器工具包,然后启动时加上--gpus=all参数:
docker run -it --name presenton --gpus=all -p 5000:80 \
-e LLM="ollama" -e OLLAMA_MODEL="llama3.2:7b" \
-e IMAGE_PROVIDER="pexels" -e PEXELS_API_KEY="你的API密钥" \
-v "./app_data:/app_data" ghcr.io/presenton/presenton:latest
这样生成速度会快3-5倍,尤其是处理带图片的演示文稿时,差距更明显。
🛠️ 进阶玩法:用API批量生成文稿
对于需要批量做报告的职场人,Presenton的API功能简直是效率神器。只需发送一个POST请求,就能自动生成文稿并导出为PPTX。
比如生成一份"机器学习入门"的5页演示文稿,用curl命令就能实现:
curl -X POST http://localhost:5000/api/v1/ppt/presentation/generate \
-H "Content-Type: application/json" \
-d '{
"content": "Introduction to Machine Learning",
"n_slides": 5,
"language": "English",
"template": "general",
"export_as": "pptx"
}'
响应会返回文稿的ID和保存路径,打开edit_path链接还能在线修改内容:
{
"presentation_id": "d3000f96-096c-4768-b67b-e99aed029b57",
"path": "/app_data/.../Introduction_to_Machine_Learning.pptx",
"edit_path": "/presentation?id=d3000f96-096c-4768-b67b-e99aed029b57"
}
还能结合CSV数据生成数据报告,或上传PDF文档让AI提炼内容做演示文稿,具体教程在官方文档里都有详细说明。
💡 为什么说它比在线工具更值得用?
作为开源项目,Presenton的优势在数据隐私和自定义能力上体现得淋漓尽致:
- 数据完全私有:本地部署时,所有文稿内容和API密钥都存在你的设备里,不用担心第三方平台泄露。
- 零成本使用:不需要订阅付费套餐,用自己的API密钥只付实际调用费用,比按月付费的工具便宜不少。
- 灵活扩展:开发者可以用HTML和Tailwind CSS自定义模板,甚至对接自己的模型服务,满足特殊需求。
目前项目还在快速迭代,接下来会支持外部SQL数据库、自定义系统提示等功能,社区也在Discord上活跃讨论,遇到问题能很快找到解决方案。
🎁 现在就试试吧!
如果你也受够了做PPT的繁琐,不妨花3分钟部署试试这个开源神器。无论是日常工作汇报、学术演讲,还是产品介绍,它都能帮你节省大量时间。
来留言区聊聊:你最想用它生成哪种类型的演示文稿? 又期待它增加什么功能?

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)