让大模型拥有眼睛:为LLM添加视觉能力的两种技术路径与代码实现
本文系统分析了大语言模型(LLM)视觉化的两种技术路线:原生多模态模型(NMMs)和预训练LLM+视觉模块。重点对比了LLaVA和VoRA两种创新方案,前者通过视觉编码器将图像映射到词嵌入空间,存在分辨率限制和串行处理缺陷;后者采用LoRA适配器微调技术,仅需调整少量参数即可实现视觉能力整合,既保留LLM原有知识又提升训练效率。文章指出VoRA通过知识蒸馏和双向注意力机制,为构建轻量级多模态模型提
本文探讨了为现有大语言模型(LLM)添加视觉能力的两种主流技术路径:一是构建原生多模态模型(NMMs)如Chameleon,从头训练统一架构;二是为预训练LLM添加视觉模块,如LLaVA和创新的VoRA方法。LLaVA方法虽高效但存在分辨率限制,而VoRA通过LoRA适配器仅微调少量参数,既保留LLM原有知识又加速视觉知识整合,为构建高效轻量级多模态模型提供了新思路。
01
引言
当大语言模型(LLMs)进入消费市场时,人人都想分一杯羹。然而随着时间的推移,我们开始渴望超越单纯的语言建模能力。视觉是首个被攻克的模态领域之一,这使得大量视觉语言模型(Vision Language Models,VLMs)涌向市场。
若我问你:"我已经学会了从零构建LLM模型,现在想为其融入视觉能力。你认为我应该如何入手?这里给出两大类方向:
- 从头训练同时支持语言和视觉的模型(原生多模态模型 - NMMs)
- 利用预训练LLM并为其添加视觉模块(预训练LLM+视觉模块)
由于NMMs的复杂性,多模态领域早期研究主要采用第二种路径。
在探讨该领域最新进展之前,让我们先简要分析这两种方法。
02
原生多模态大模型
本文将聚焦讨论"早期融合(Early Fusion)"模型,并将NMMs定义为对所有模态共享统一离散标记空间的模型。
基于上述定义,我们可以排除VisualBERT(2019)、Flamingo(2022)、PaLI(2022)等早期多模态模型(因其架构设计不符合严格的原生多模态标准)。
根据我们的标准,Meta发布的Chameleon(2024)被认为是首个真正的原生多模态模型,其设计理念直接推动了Llama 4、Gemini 2.5等后续模型的涌现。
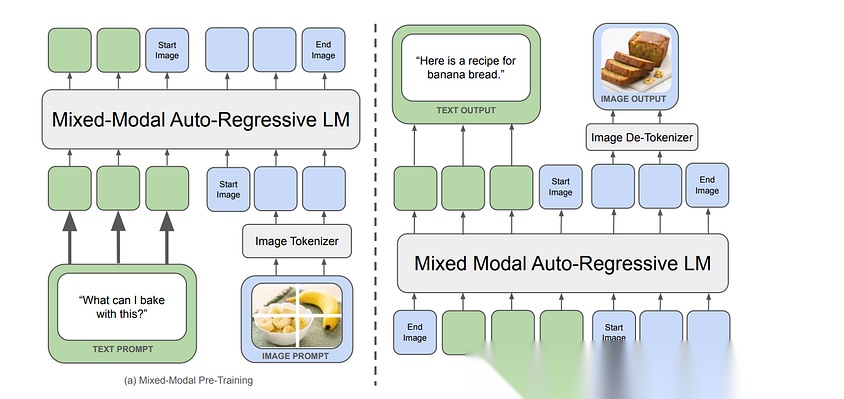
Chameleon大体沿用了Llama-2的架构,但进行了关键性优化:
- 激活函数改用SwiGLU
- 位置编码采用RoPE技术
然而,由于softmax函数的平移不变性特征,Llama架构也导致Chameleon出现了逻辑偏移(logit drift)问题。虽然本文不深入探讨其完整优化流程(如多模态对齐、动态批处理策略等),但对模型实验细节感兴趣的读者可研读Chameleon论文,了解Meta团队如何在训练稳定性与性能间取得精妙平衡。
既然我们的目标是基于现有LLM构建多模态模型,接下来将重点解析第二种实现路径。
03
预训练大语言模型+视觉模块
有多种方法可以将 LLM 与视觉模块融合,但最常见的方法是 LLaVA 论文中展示的那种。让我们看看它是如何工作的。
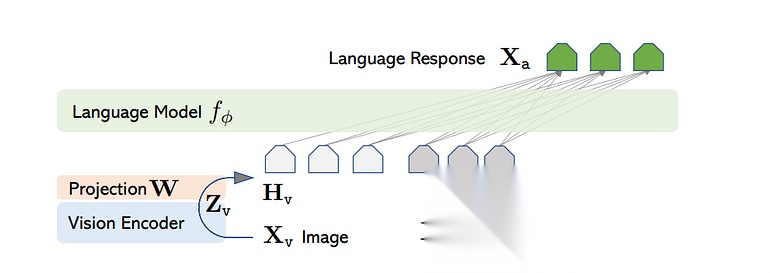
图像通过视觉编码器进行处理,然后投影到词嵌入空间。请注意,这个投影矩阵是一个可训练的张量。这个编码器模型可以是任何东西——就像 LLaVA 论文中的 CLIP,或者 ViT(因为大多数近期论文都使用它)。
视觉编码器的权重始终是冻结的,而投影矩阵和语言模型的参数在训练期间会被更新。
在不涉及任何技术细节的情况下,让我们看看训练是如何进行的。
假设你和你的助手一起在艺术画廊里,你们看到了一幅20世纪初的作品,你想了解更多关于这幅作品的信息。幸运的是,你的助手对这幅作品了如指掌,于是你们开始以多轮对话的形式交流(你提问,助手回答)。你的助手会观察这幅作品,并将信息存储在他们的记忆中。之后,整个对话会保持连贯性,每一个问题都能得到恰当的回答。在LLaVA架构中,生成答案的工作由最终的语言模型完成。
这可以重新想象为以最大似然估计的方式进行训练,如下所示:
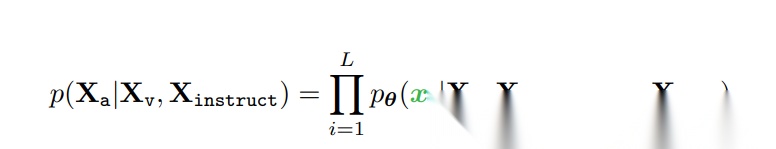
这种方法的局限性
虽然这种训练方式效率很高,但依赖外部视觉模型也存在一些缺点。
- 图像分辨率限制:大多数视觉编码器在训练时采用固定分辨率,这限制了模型能处理的图像灵活性。
- 串行工作流程:由于数据是线性传递的,语言模型必须等待视觉编码器完成处理才能开始执行,导致效率受限。
04
Vision as LoRA
VoRA提出了一种创新方案——不再依赖外部视觉模型,也不干扰预训练大语言模型(LLM)的原有知识,而是仅微调LoRA适配器(用于视觉上下文)和一个图像嵌入层。换句话说,LoRA适配器就是模型的"视觉参数"。
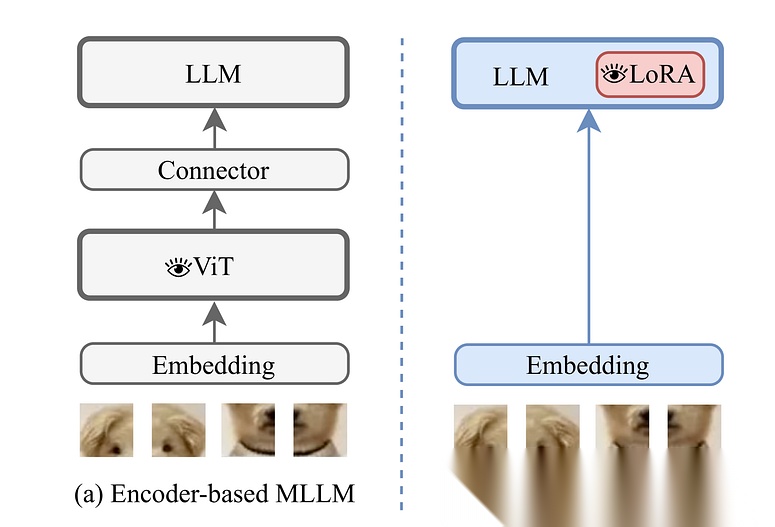
在预训练阶段,VoRA允许前N(vit)层内的所有线性层(包括QKV投影和FFN)都配备LoRA层。
预训练完成后,LoRA参数可以无缝集成到LLM块中,从而消除任何推理时的额外开销。
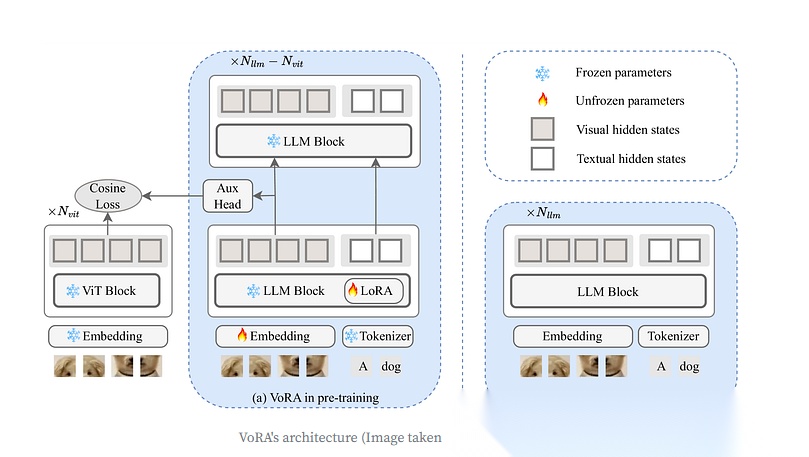
该论文中最有趣的一点是从预训练的 ViT 模型中进行知识蒸馏。因此,对于 LLM 的前 N(vit) 层,视觉隐藏状态与相应 ViT 模型中的隐藏状态对齐。这有两大好处:
- 加速训练,因为视觉知识不是从头开始整合的。
- 只更新 LoRA 参数,而不是一个完整的投影层。
模型的训练目标可以分解为两个部分:蒸馏损失和语言建模损失。
- 蒸馏损失函数——计算投影后的LLM特征与ViT嵌入的余弦相似度。
- 语言建模损失函数——采用交叉熵损失函数。
这两种损失结合在一起,形成最终的训练目标。
注意:这篇论文也是最早讨论视觉模态中双向注意力机制的研究之一,它对最终模型产生了积极的影响。
虽然仍处于早期阶段,VoRA在构建不仅仅是VLM,还可能包括各种多模态大模型(如音频、视频、3D图像等)方面展现出巨大的潜力。通过解耦不同模态的参数,避免了对特定模态参数的依赖,我们可以节省大量训练时间,并有望未来出现更小的VLMs 。
读者福利大放送:如果你对大模型感兴趣,想更加深入的学习大模型**,那么这份精心整理的大模型学习资料,绝对能帮你少走弯路、快速入门**
如果你是零基础小白,别担心——大模型入门真的没那么难,你完全可以学得会!
👉 不用你懂任何算法和数学知识,公式推导、复杂原理这些都不用操心;
👉 也不挑电脑配置,普通家用电脑完全能 hold 住,不用额外花钱升级设备;
👉 更不用你提前学 Python 之类的编程语言,零基础照样能上手。
你要做的特别简单:跟着我的讲解走,照着教程里的步骤一步步操作就行。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
现在这份资料免费分享给大家,有需要的小伙伴,直接VX扫描下方二维码就能领取啦😝↓↓↓
为什么要学习大模型?
数据显示,2023 年我国大模型相关人才缺口已突破百万,这一数字直接暴露了人才培养体系的严重滞后与供给不足。而随着人工智能技术的飞速迭代,产业对专业人才的需求将呈爆发式增长,据预测,到 2025 年这一缺口将急剧扩大至 400 万!!
大模型学习路线汇总
整体的学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战,跟着学习路线一步步打卡,小白也能轻松学会!
大模型实战项目&配套源码
光学理论可不够,这套学习资料还包含了丰富的实战案例,让你在实战中检验成果巩固所学知识
大模型学习必看书籍PDF
我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。
大模型超全面试题汇总
在面试过程中可能遇到的问题,我都给大家汇总好了,能让你们在面试中游刃有余
这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。
👉获取方式:
😝有需要的小伙伴,可以保存图片到VX扫描下方二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最适合零基础的!!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献193条内容
已为社区贡献193条内容

所有评论(0)