十行代码实现会议纪要智能整理(录音-纪要)
·
一、音频转文本
任务一、创建文件夹,上传音频
1、在根目录下创建文件夹“audio”
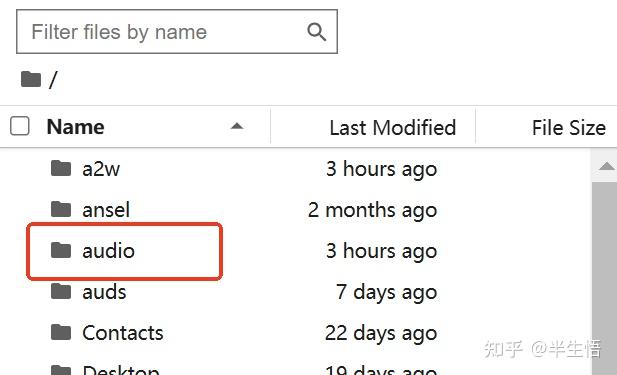
2、上传会议录音音频
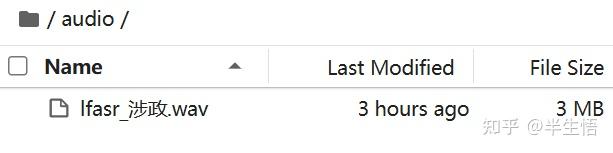
任务二、安装必要的库
1、SpeechRecognition
中文名称:语音识别库
主要功能:
- 提供简单易用的接口,支持语音文件或麦克风输入的语音识别。
- 支持多种语音识别引擎(如 Google Web Speech API、Sphinx 等)。
- 识别语音中的内容并将其转换为文本。
使用方法: 安装库:
pip install SpeechRecognition代码示例:
import speech_recognition as sr
# 初始化识别器
recognizer = sr.Recognizer()
# 从音频文件中识别语音
with sr.AudioFile('example.wav') as source:
audio_data = recognizer.record(source)
text = recognizer.recognize_google(audio_data, language='zh-CN')
print("识别结果:", text)
# 从麦克风中识别语音
with sr.Microphone() as source:
print("请开始说话:")
audio_data = recognizer.listen(source)
text = recognizer.recognize_google(audio_data, language='zh-CN')
print("识别结果:", text)2、pyaudio
中文名称:音频处理库
主要功能:
- 提供对音频输入和输出的接口,可以录制和播放音频。
- 支持 WAV 文件录制、流式音频处理。
使用方法: 安装库:
pip install pyaudio代码示例:
import pyaudio
import wave
# 设置音频参数
FORMAT = pyaudio.paInt16
CHANNELS = 1
RATE = 44100
CHUNK = 1024
RECORD_SECONDS = 5
WAVE_OUTPUT_FILENAME = "output.wav"
audio = pyaudio.PyAudio()
# 开启音频流
stream = audio.open(format=FORMAT, channels=CHANNELS,
rate=RATE, input=True,
frames_per_buffer=CHUNK)
print("正在录音...")
frames = []
for _ in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
frames.append(data)
print("录音结束!")
# 停止音频流并保存文件
stream.stop_stream()
stream.close()
audio.terminate()
with wave.open(WAVE_OUTPUT_FILENAME, 'wb') as wf:
wf.setnchannels(CHANNELS)
wf.setsampwidth(audio.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))3、requests
中文名称:HTTP请求库
主要功能:
- 提供简单易用的接口,用于发送 HTTP 请求(GET、POST、PUT、DELETE 等)。
- 支持处理参数、文件上传、认证、会话和 Cookie。
使用方法: 安装库:
pip install requests代码示例:
import requests
# 发送 GET 请求
response = requests.get('https://api.example.com/data')
print("GET 请求响应:", response.json())
# 发送 POST 请求
payload = {'key1': 'value1', 'key2': 'value2'}
response = requests.post('https://api.example.com/submit', data=payload)
print("POST 请求响应:", response.text)
# 下载文件
file_url = 'https://example.com/file.zip'
response = requests.get(file_url)
with open('file.zip', 'wb') as file:
file.write(response.content)
print("文件下载完成!")任务三、加载音频文件并进行语音识别
import speech_recognition as sr
# 初始化识别器
recognizer = sr.Recognizer()
# 加载音频文件并进行语音识别
audio_file_path = r"audio/lfasr_涉政.wav"
with sr.AudioFile(audio_file_path) as source:
audio_data = recognizer.record(source)
text = recognizer.recognize_google(audio_data, language="zh-CN")
print(text)
二、创建文本整理智能体
任务一、在coze平台上创建文本整理智能体
1、登录coze平台(http://coze.cn)创建智能体
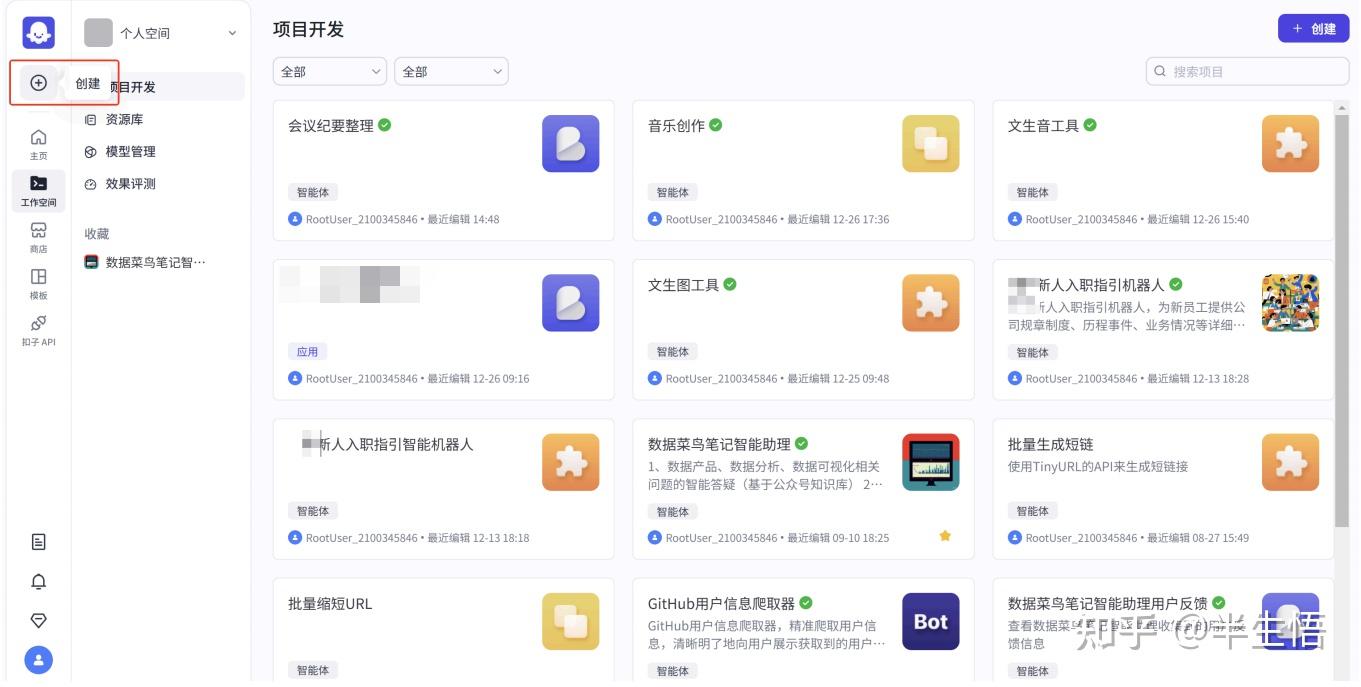
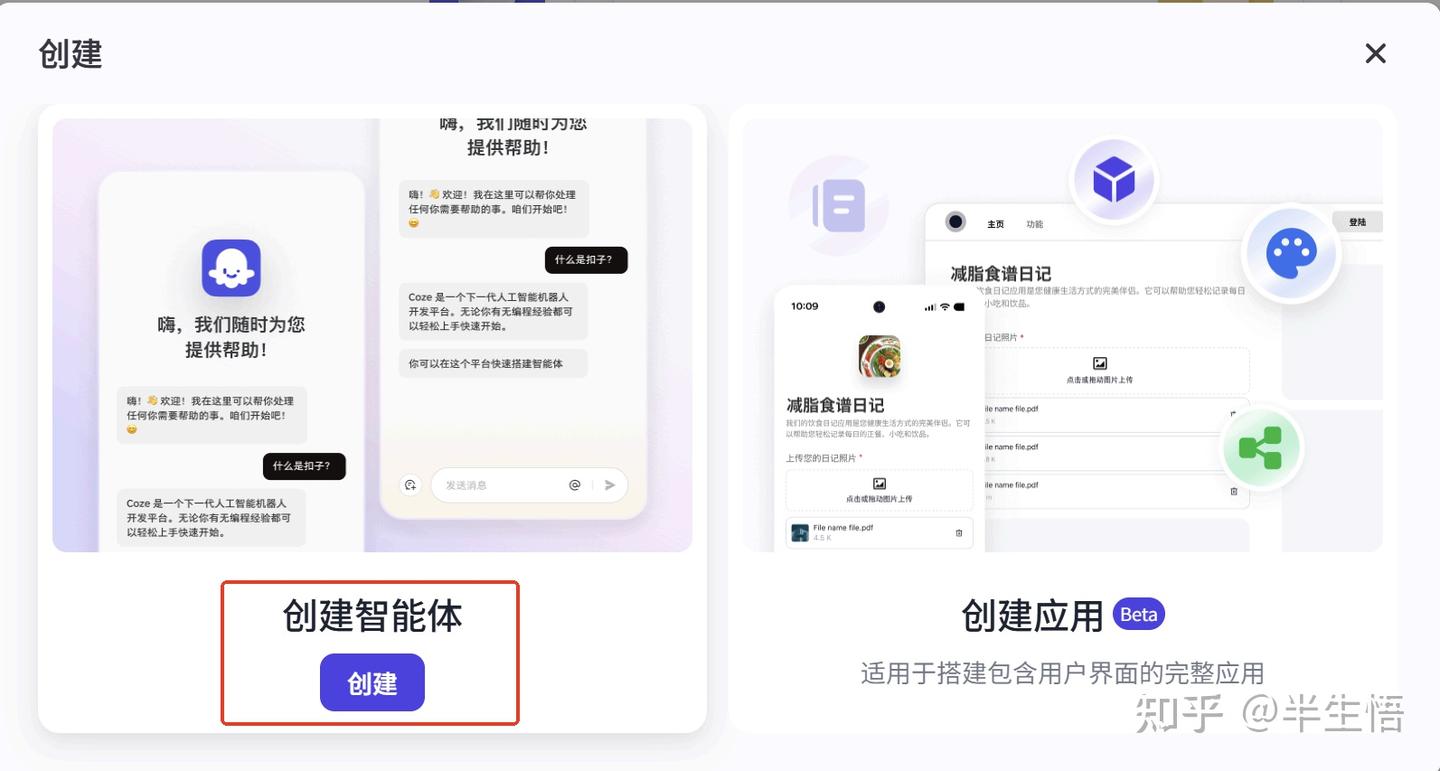
2、编写提示词

请按照以下要求,将输入的文本内容整理为会议纪要。格式严格按照以下结构:
整理后的会议纪要:
a. 会议主题:
[请明确会议的标题和主要目的]
b. 会议日期和时间:
[请提取并注明会议的具体日期和时间]
c. 参会人员:
[列出参加会议的所有人员的姓名或职位]
d. 会议记录者:
[请注明记录这些内容的人员的姓名或职位]
e. 会议议程:
[列出会议的所有主题和讨论点]
f. 主要讨论:
[根据议程逐一详细说明每个议题的讨论内容]
g. 决定和行动计划:
[列出会议中做出的所有决定,以及具体的行动计划、负责人和完成时间]
h. 下一步打算:
[列出需要在下一次会议中进一步讨论的问题或计划]
请确保输出格式与上述框架完全一致,并提供清晰、具体的内容。3、调试后,发布智能体

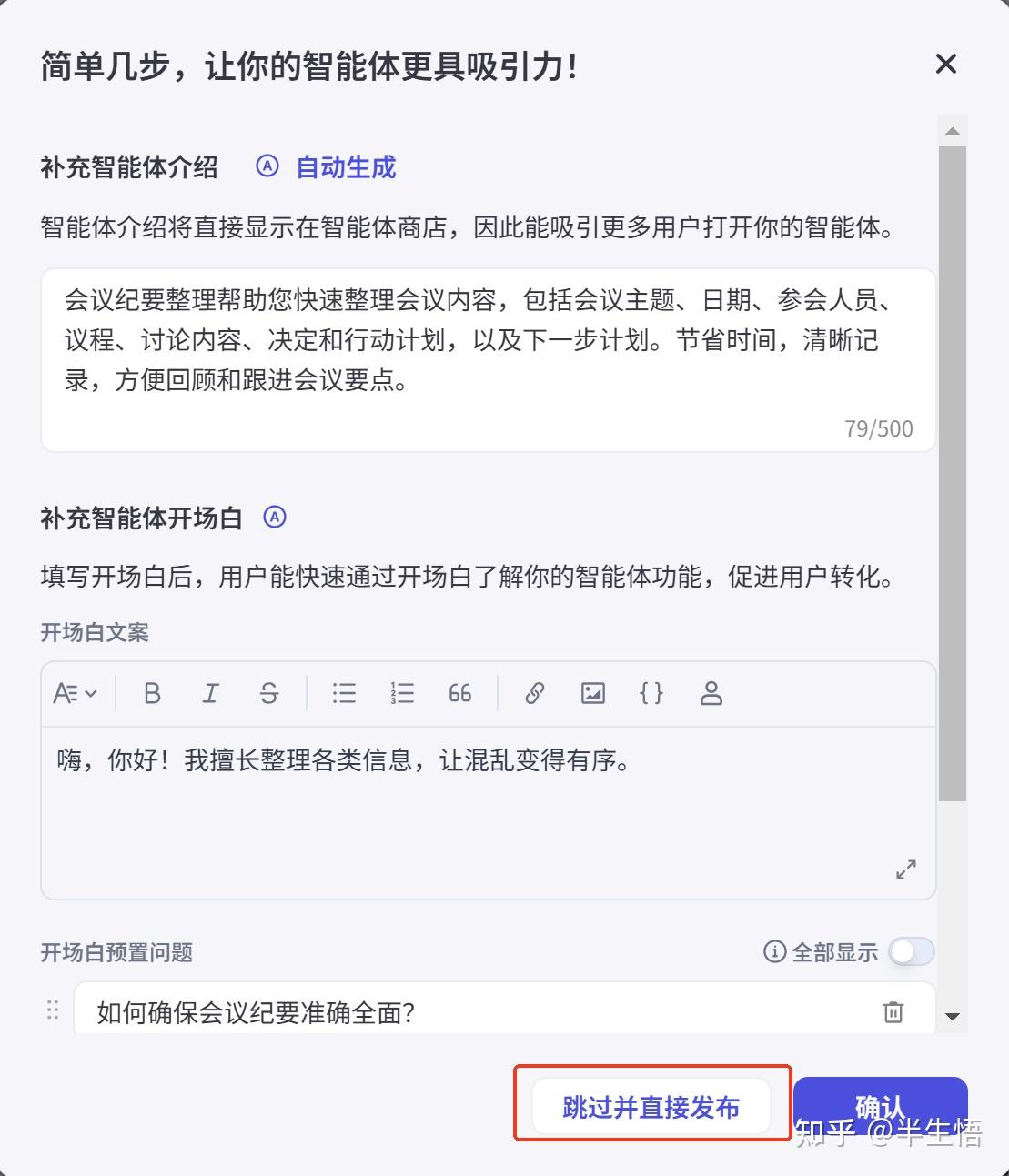
任务二、获得授权密钥和智能体ID
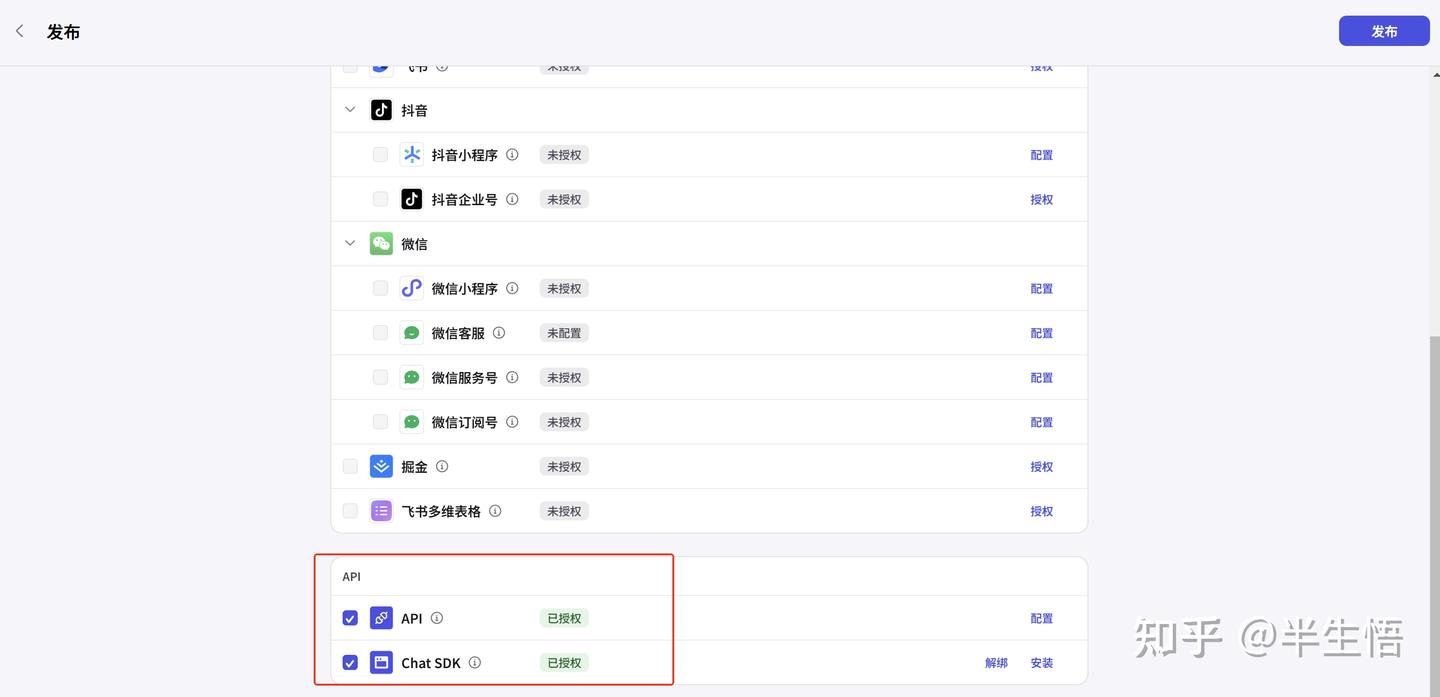
1、获取授权密钥
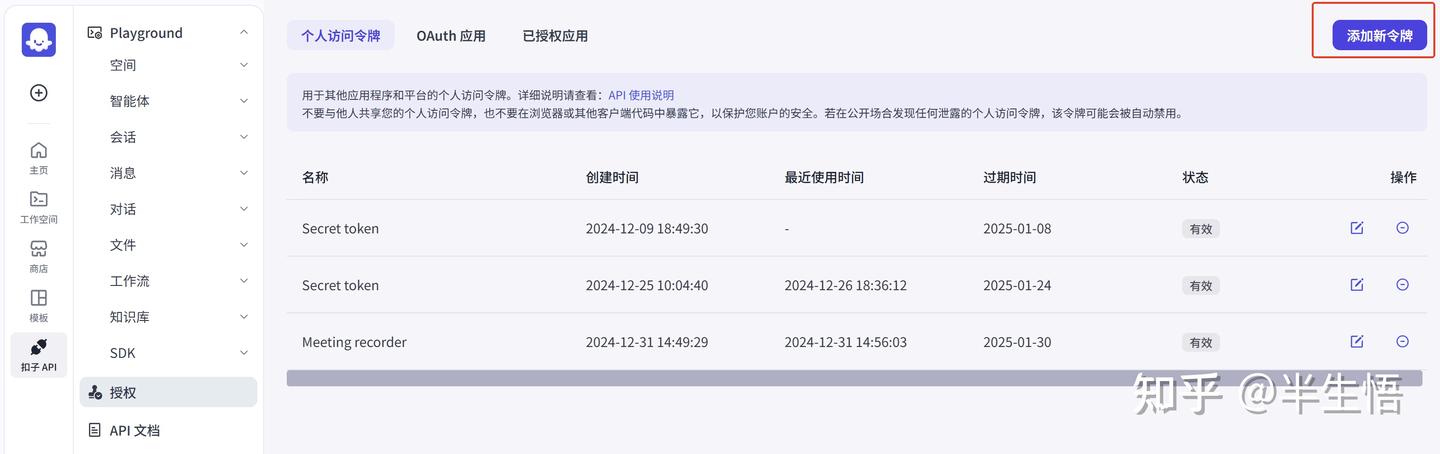
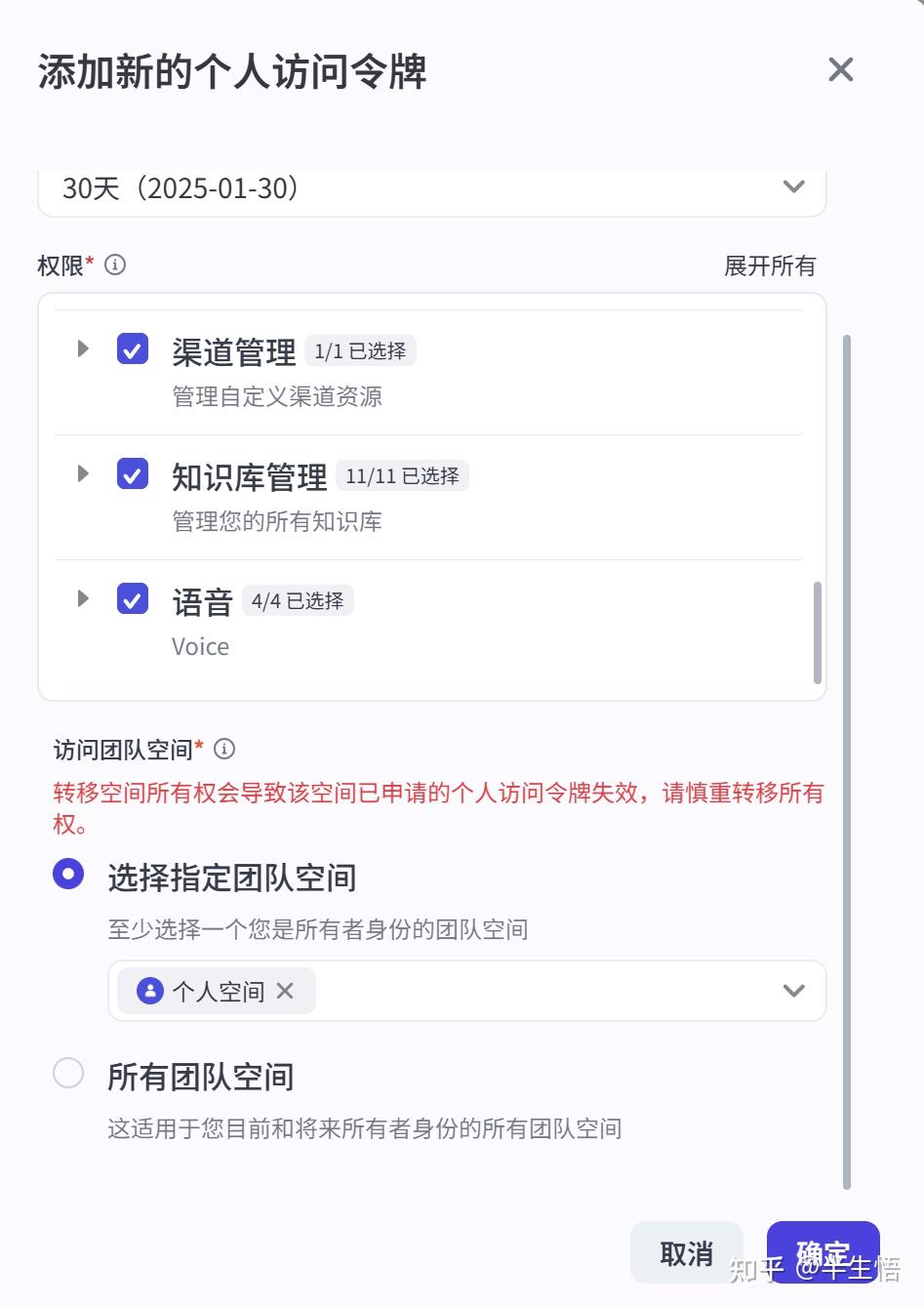
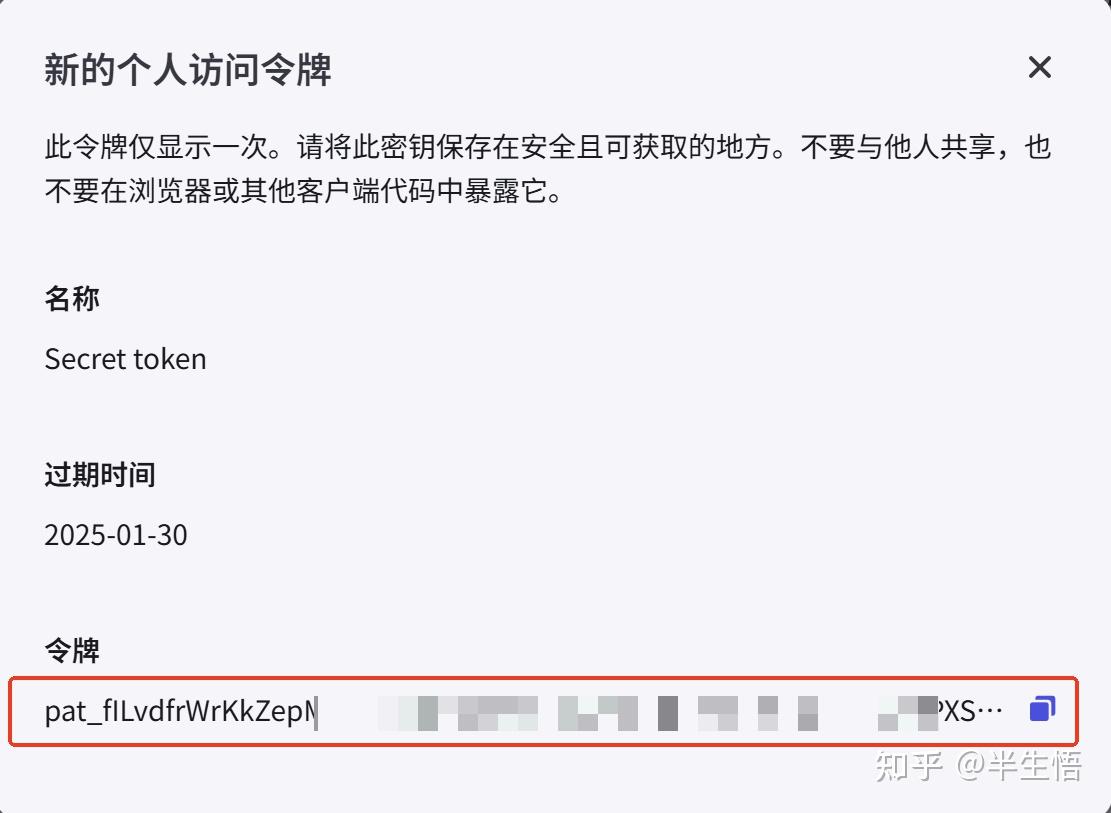
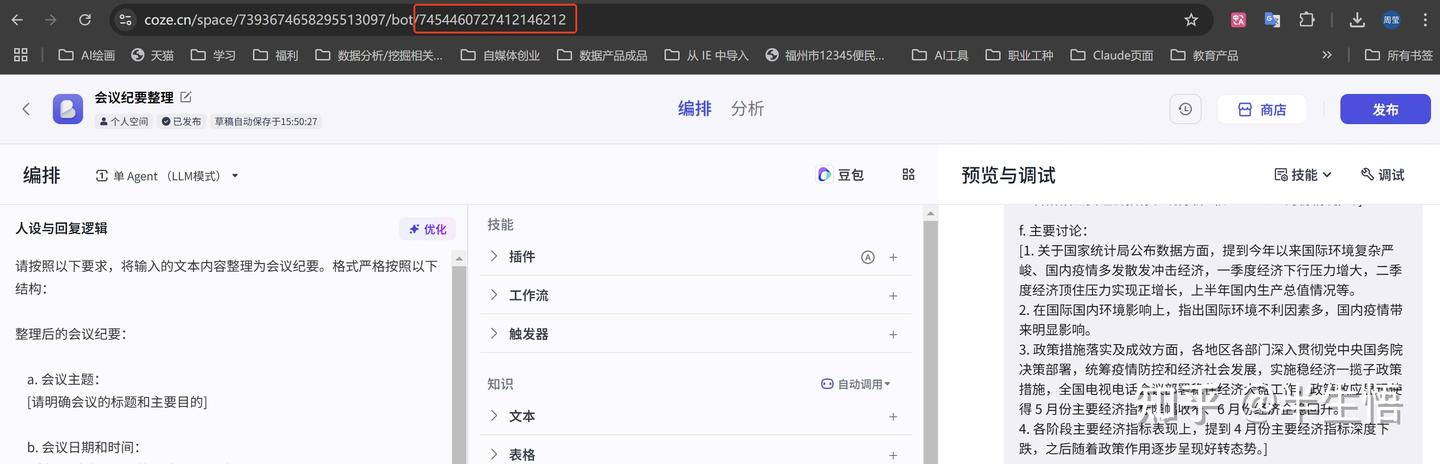
2、获取智能体ID
打开智能体,复制url上的最后一串数字
三、调用智能体实现会议纪要工具
任务一、编写coze接口调用模块
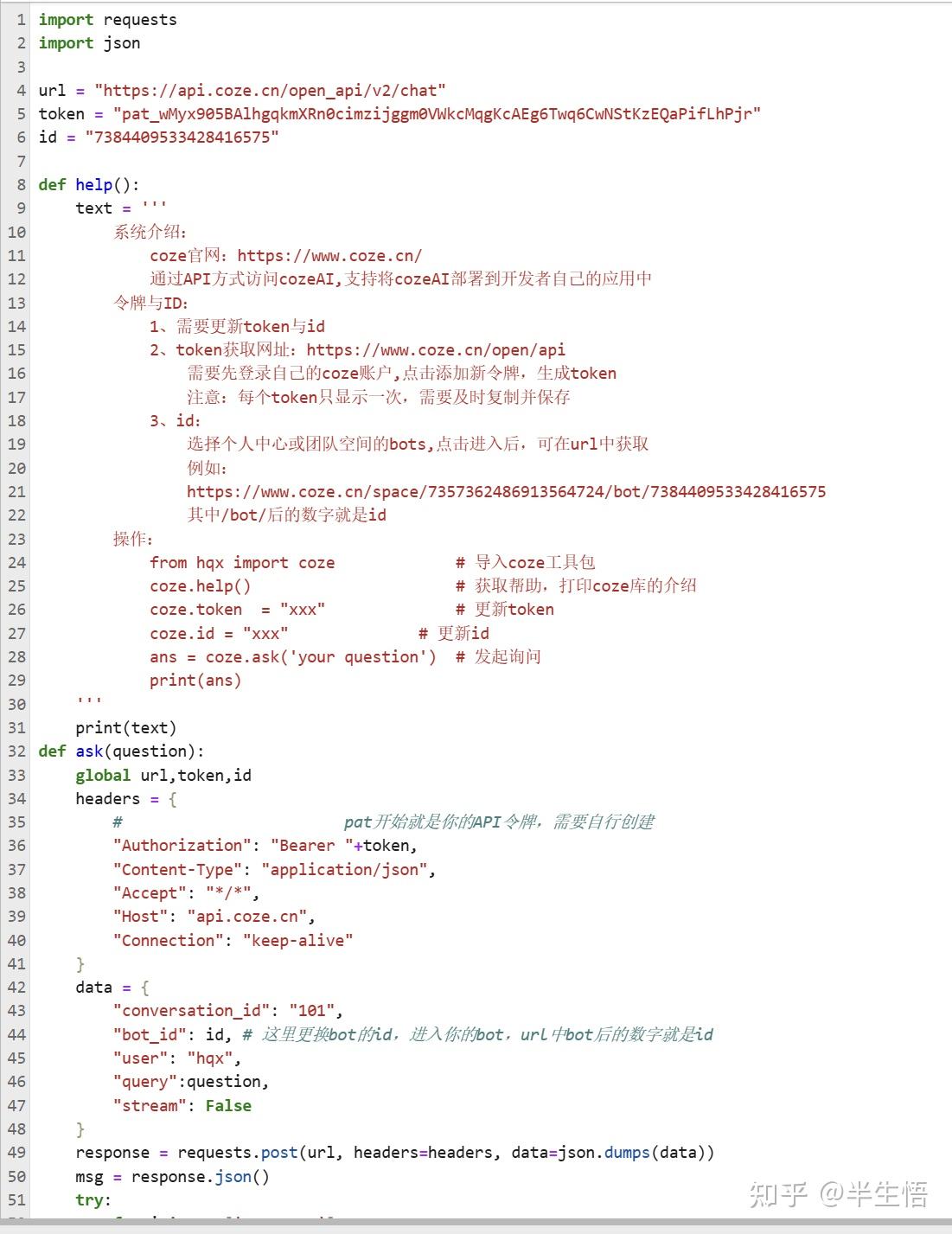
任务二、调用API并传参
# 设置 API token 和 ID
coze.token = 'pat_wDjqtaPaXC7Dy7jgOjpsYE6iYyooyQF6Yn3p2RFrTJTm5JuE2y9ffLHGa5lyMhGw'
coze.id = '7454460727412146212'
# 确保传递的字符串格式正确
meeting = coze.ask(f"{text}")任务三、运行程序,获得会议纪要
from LMAPI import coze
import speech_recognition as sr
# 初始化识别器
recognizer = sr.Recognizer()
# 加载音频文件并进行语音识别
audio_file_path = r"audio/lfasr_涉政.wav"
with sr.AudioFile(audio_file_path) as source:
audio_data = recognizer.record(source)
text = recognizer.recognize_google(audio_data, language="zh-CN")
# 设置 API token 和 ID
coze.token = 'pat_wDjqtaPaXC7Dy7jgOjpsYE6iYyooyQF6Yn3p2RFrTJTm5JuE2y9ffLHGa5lyMhGw'
coze.id = '7454460727412146212'
# 确保传递的字符串格式正确
meeting = coze.ask(f"{text}")
# 打印输出
print(meeting)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)