FALCON:学习力-自适应的人形机器人操控
《FALCON:力自适应人形机器人操控学习框架》提出了一种基于双智体强化学习的新方法,通过分解控制任务实现精确的全身操控。该框架将下半身(稳定运动)和上半身(力补偿操控)作为独立智能体进行联合训练,采用渐进式力课程和扭矩感知机制提升适应性。实验表明,FALCON在模拟中实现2倍精度提升,并能迁移到真实机器人执行负重运输(20N)、拉车(100N)等任务。相比传统IK控制或整体式RL,该框架在训练效
25年5月来自 CMU 、创业公司 Field AI 和 Nissan USA 的论文“FALCON: Learning Force-Adaptive Humanoid Loco-Manipulation”。
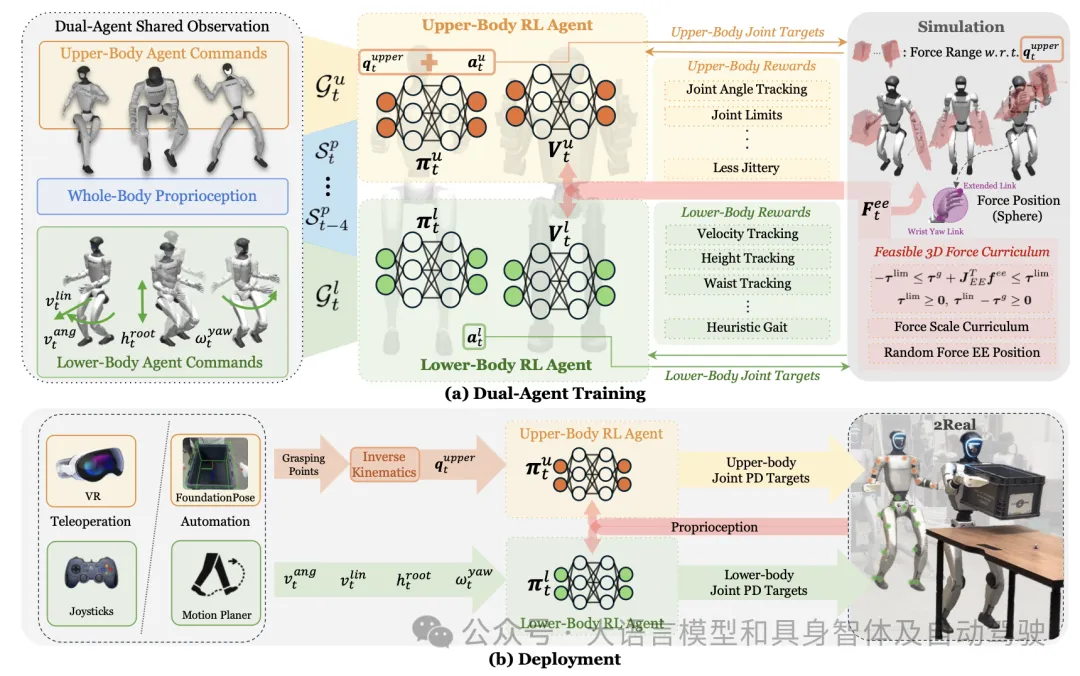
人形机器人在日常服务和工业任务中具有变革性的潜力,但实现具有 3D 末端执行器力相互作用的精确、鲁棒的全身控制仍然是一项重大挑战。先前的方法通常仅限于轻量级任务或四足/轮式平台。为了克服这些限制,提出 FALCON,这是一个基于双智体强化学习的鲁棒力-自适应人形机器人操作框架。FALCON 将全身控制分解为两个专门的智体:(1)下半身智体,确保在外力干扰下保持稳定运动;(2)上半身智体,通过隐式自适应力补偿精确跟踪末端执行器的位置。这两个智体在模拟中接受联合训练,使用力课程,在遵守扭矩限制的同时,逐步增加施加在末端执行器上的外力。实验表明,与基线相比,FALCON 实现 2 倍更高精度的上肢关节追踪,同时在力干扰下保持稳健的运动,并实现更快的训练收敛。此外,FALCON 无需针对具体实例的奖励或课程调整即可进行策略训练。使用相同的训练设置,获得可部署在多个类人机器人上的策略,从而能够在现实世界中执行诸如运输有效载荷(0-20N force)、拉车(0-100 N force)和开门(0-40N force)等强力操控任务,如图所示。
在外部动力驱动下进行人形机器人的定位操作需要对下半身和上半身进行协调控制。首先将该问题表述为一个统一的双目标条件策略学习问题。将人形机器人的自由度 (DoF) 划分为下半身关节和上半身关节,其中 nl 表示下半身 DoF 的数量,nu 表示上半身 DoF 的数量,n = nl + nu 表示驱动关节的总数。
机器人本体感觉 sp_t 定义为 sp_t ≜ [q_t−4:t, q ̇_t−4:t ,ωroot_t−4:t ,g_t−4:t ,a_t−5:t-1],其中包含关节位置 q_t、关节速度 q ̇_t、根角速度 ωroot_t、投影重力 g_t 和先前动作 a_t-1 的五步历史。目标空间 G 由运动目标 Gl_t ≜ [vlin,ang_t, φstance_t, hroot_t, wyaw_t] 组成,指定所需的根线速度和角速度、姿势指标、根高度和腰部偏航角,以及操纵目标 Gu_t ≜ [qupper*_t ],指定上身 qupper*_t 的目标关节配置。
在这种统一的形式体系下,传统方法的主要区别在于它们如何生成控制机器人关节的动作 a_t:
• Lower-RL-Upper-IK:下肢动作 al_t 由基于全身本体感觉和目标的策略 πl: sp_t × ⟨Gl_l, Gu_t⟩ → Al_t 生成,而上肢动作 au_t 则通过基于 Gu_t 的逆运动学 (IK) 求解器计算得出。
• Monolithic-Whole-body-RL:单一策略 π : sp_t × G_t → a_t 直接预测全身动作 a_t,试图同时满足运动和操控目标。
虽然 Lower-RL-Upper-IK 方法具有样本效率高的特点,但它们忽略上肢力补偿和 末端执行器(EE) 力扰动下的全身耦合。相比之下,整体式全身强化学习方法虽然提升了表达能力,但由于动作空间过大,且涵盖了粗略关联的运动和操作目标,因此存在探索效率低下的问题。为了克服这些挑战,引入 FALCON,这是一个双智体强化学习框架,它通过共享全身观察的分解学习来提高训练效率和协调性。
双智体学习框架
如图所示,FALCON 联合训练两个智体,每个智体负责不同的子任务。下肢运动智体学习策略 πl : sp_t × Gl_t → Al_t,其值函数为 Vl(·);上肢操控智体学习策略 πu : sp_t × Gu_t → Au_t,其值函数为 Vu(·)。
两个智体观测相同的本体感受输入 sp_t,但各自优化独立的目标条件目标。
这两个策略参数 θ_l 和 θ_u 通过近端策略优化 (PPO [42]) 进行更新:
上肢目标关节角度 qupper_t(肩部、肘部、腕部的目标关节)在训练期间从 AMASS 数据集 [43] 中随机采样,并在部署期间通过反向运动 (IK) 计算得出。两个智能体的组合动作 a_t = [al_t ; au_t ] 被发送到关节级 PD 控制器。由于现实世界中的类人机器人控制本质上是部分可观测的,采用非对称的 actor- critics 训练方法,其中 critics 在训练期间额外访问特权信息,包括根线速度和 EE 力 Fee_t,但在部署期间则无法访问。
扭矩-限制-觉察的 3D 力课程学习
对于人形机器人,尤其是关节扭矩限制相对较弱的机器人,例如 Unitree Humanoid G1 上的腕关节,当对末端执行器 (EE) 施加较大的外部干扰时,明确考虑这些扭矩限制至关重要。在上肢策略训练期间忽略这些限制可能会导致实际机器人部署中出现扭矩饱和或关节限制违规,从而导致意外或不安全的行为。此外,在训练过程中逐渐增加外力也很重要,这样可以使策略逐步学习有效的力适应策略。为了实现这些目标,力应用框架遵循三个原则:
1)扭矩-觉察力计算:在施加力之前,首先需要估算可以施加在左或右末端执行器上的最大力。给定左或右末端执行器在其质心(CoM)处的雅可比矩阵 J_EE、它们的关节扭矩极限 τlim(EE τlim ≥ 0)以及满足 −τlim ≤ τg ≤ τlim lim 的重力补偿扭矩 τg 以确保可行性,通过分析在每个方向上施加单位力引起的最坏情况关节扭矩来估计沿每个笛卡尔轴 i 的最大和最小允许力 fmax 和 fmin。逐元力边界可以并行计算如下:

之后,通过狄利克雷分布 [44] 采样 x、y 和 z 轴之间相对比 γ = [γ_x, γ_y, γ_z],满足 sum_i∈{x,y,z} (γ_i) = 1。可行的作用力将在估计范围内均匀采样,并表示为:
这种方法在尊重扭矩限制的同时最大限度地提高力的自适应性,从而比随机采样更有效地进行训练。需要注意的是,由于上肢结构不对称,左右 EE 之间的作用力可能有所不同,如上图所示。
2)渐进式力课程:为了促进渐进式力的适应性,估计的 EE 力通过全局因子 α_g ∈ (0, 1) 进行缩放,该因子在训练过程中不断增加,因此作用力变为 Fee_t = α_g · fee_t。在行走过程中,平面力的投射方向与速度方向相反。采用低通滤波器来减少力的抖动。
3)施加力的位置随机化:基于学习的力自适应利用本体感受历史来隐式补偿外力,无需显式估计[40]或感知[45]力。为了提高对末端执行器 (EE) 接触点变化(通过 EE 雅可比矩阵改变扭矩映射)的鲁棒性,沿 EE 杆随机施加力,从腕部偏航到远端节段,如上图所示。
自主流程
开发一个用于手提箱物流的分层自主流程,利用运动捕捉 (MoCap) 系统来定位机器人和办公桌的位置。机器人由一个状态机框架控制,该框架包含四种状态:(1) 不带手提箱行走,(2) 拾起手提箱,(3) 携带手提箱行走,以及 (4) 放下手提箱,如图所示。为了估计手提箱相对于摄像机的姿态,用 FoundationPose [41],这是一种最先进的方法,可以进行精确可靠的 6 自由度姿态估计。
感知 - 姿态估计
为了设置 FoundationPose 流程 [41],首先通过执行原始 3D 扫描获取工业手提箱的高保真 3D 模型,然后在 3D 建模工具中进行手动后处理。生成的纹理和 .obj 文件将作为 FoundationPose 的输入,从而能够根据 G1 机器人的图像流对手提箱进行 6 自由度姿态估计。此外,在手提箱表面纵向预定义抓取点,并利用摄像头和机器人之间已标定的外参将这些抓取点转换为机器人基座坐标系,如图所示。
运动捕捉系统
运动捕捉系统在全局参考系中为机器人基座、拾取台和放下台提供精确的 6 自由度姿态估计——位置 (x, y, z) 和方向 (偏航、俯仰、滚转),从而实现整个系统的一致空间定位。
当状态机由动作捕捉反馈触发转换到“(2) 拾取手提箱”状态时,FoundationPose 将实时执行以估计手提箱姿态。然后将预定义的抓取点传递给逆运动学 (IK) 求解器,该求解器被设计为上肢操控的“定位姿势”问题。
实际部署中的硬件限制
在使用 FALCON 训练的策略进行模拟到实际部署的过程中,人形机器人难以长时间维持高关节扭矩,这常常导致电机快速过热,尤其是在腕部。这严重限制了在默认关节位置下执行每臂超过 2 公斤有效载荷运输的能力。相比之下,在 MuJoCo [47] 中评估的相同策略,通过扭矩限制来限制关节限制,但没有对热约束进行建模,成功地在每个末端执行器上运输超过 3 公斤的有效载荷,同时精确跟踪沿 x 轴的指令线速度 -1 米/秒。这凸显模拟和实际执行器耐久性之间的关键差距。
然而,对于诸如拉车之类的重型任务(只需要短时间的高扭矩爆发),电机不太容易过热,因为不需要持续的高扭矩输出。这使得机器人能够在现实世界中成功执行此类任务。
实验细节
选择 Unitree Humanoid G1 和 Booster T1 作为人形机器人平台。
考虑两种用于力自适应的基线方法,它们均在相同目标空间(例如,命令)和力课程学习下进行训练,并且每种方法都进一步包含相关的消融实验变型。
解耦下半身 RL 与上半身 IK 控制器。对于所有变型,RL 用于下半身运动,IK 根据末端执行器姿势提供目标上半身关节角度。主要区别在于力课程学习的使用和上肢关节追踪策略:
(a) Upper-PD-w/o-Force-Curr.:遵循[8, 9]的基线,使用PD控制进行上肢关节追踪,无需力随机化。
(b) Upper-PD:在(a)的基础上扩展,加入力课程,使下肢能够适应外力;上肢仍由PD控制。
© Upper-PID:在(b)的基础上扩展,在上肢控制器中添加积分项,以减少稳态追踪误差。
(d) Upper-PD-ID:在(a)的基础上扩展,加入学习力估计器[38],并在准静态假设下进行基于逆动力学的扭矩补偿。
整体式全身强化学习
(e) 整体式全身强化学习(无力指令):基于先前的设计 [11, 15],单个智体使用与 FALCON 相同的目标命令进行训练,但在训练过程中不施加任何力。
(f) 整体式全身强化学习(带力指令):基于 (e),在训练过程中采用力随机化来实现力的自适应,同时保持其他训练设置不变。
仿真环境采用 Nvidia IsaacGym 工具实现。真实环境在 Unitree G1 上评估 FALCON,在实际任务中,每只手负载 1.2 千克,该任务以 (0.5, 0.0) 米/秒的速度行走,角速度为零,身高和腰部固定,上半身保持默认姿势。与两个基准模型进行比较:(i) 带力指令的 Upper-PD 模型,以及 (ii) 带力指令的整体式全身强化学习 (Monolithic-WB-RL)。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 6
6 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)