每日AI学习笔记----Qwen3-Omni 、HuatuoGPT-o1医学复杂推理
没有什么比静下心来学习能让你更踏实。浮躁了就去学习,想谈恋爱了就去学习,烦了就去学习吧,孩子。
只要工作不加班到很晚,每天都要坚持至少一小时的AI新知识和技术的学习。
9.24
1.Qwen3-Omni
🚀本地部署+全面测评!阿里最强全模态大模型Qwen3-Omni史诗级更新!OCR能力、音频识别、视频理解无所不能!它真的什么都懂!_哔哩哔哩_bilibili
Instruct版本支持多模态输入输出、Thinking版本支持思维链推理、Captioner版本专注字幕识别。无论是语音翻译、音乐分析还是视频理解,Qwen3-Omni都展现了卓越性能。
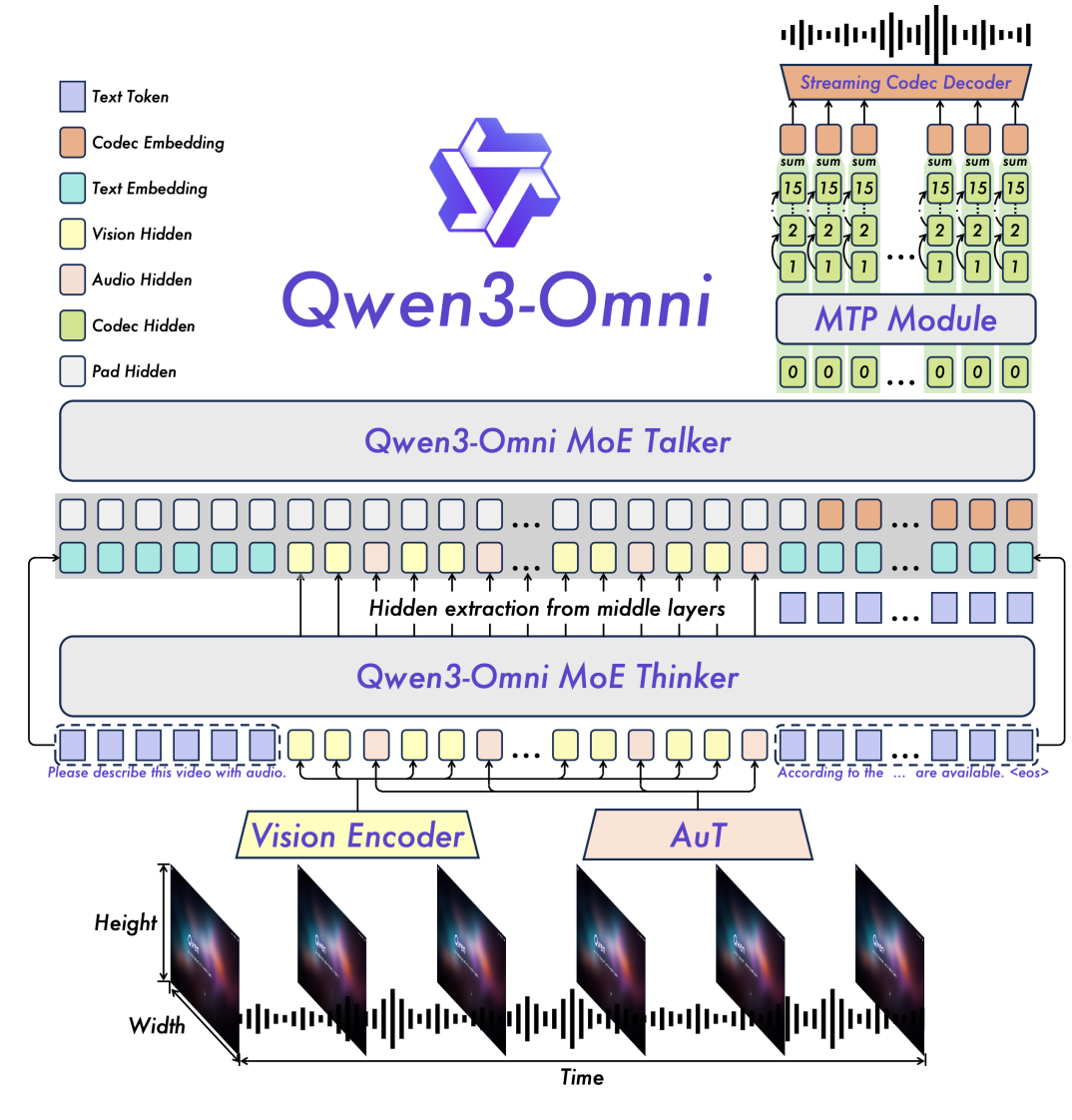
架构设计:Thinker–Talker 怎么配合
- 一个端到端的多模态骨架:同一套模型里完成文本、图像、音频、视频的“看懂 + 说出来”,不搞多段管线那套。
- Thinker(思考):主打跨模态理解与推理,遇到复杂任务可以切到“思考模式”,简单问题就走“非思考模式”。
- Talker(说话):主打实时输出文本/语音,和 Thinker 松耦合,目的是把交互延迟压下来、控制力更强。
- MoE + 多码本:兼顾表示力和吞吐,难活不掉链子,量大时也能跑得动。
- AuT 音频编码器:AuT 音频编码器是阿里云为 Qwen3-Omni 模型开发的全新音频编码器。采用动态注意力窗口技术,处理实时音频时,可以专注于当前的短时间窗口,确保快速响应;处理长音频时,又可以扩大注意力范围,理解更完整的上下文信息,让 AuT 在各种音频任务中都能保持优秀表现。
码本:
- 码本的本质:可以理解为 “字典” 或 “符号表”,里面存储着一系列预定义的基础 “单元”(如音频片段、图像特征、语义向量等)。模型会将原始数据拆解成这些基础单元的组合,用 “索引”(而非原始数据)来表示信息,类似用 “字典查字” 的方式压缩数据。
- 多码本的作用:单一码本难以覆盖复杂数据的全部特征(比如音频中的人声、背景音、不同频率成分),而多码本通过分工协作 —— 不同码本专注于捕捉数据的不同维度特征(如音色、节奏、语义等),既能保留更丰富的细节(保证表示力),又能通过并行处理多个码本的索引,大幅降低单个码本的规模和计算压力(提升吞吐效率)。
型号怎么选、开源情况
模型都是30B
- Instruct:Thinker + Talker,全能型,音/视频/文本都能进,音频/文本都能出。
- Thinking:只有 Thinker,主打链式推理,入参同上,输出是文本。
- Captioner:从 Instruct 微调的音频精细字幕模型,细节足、幻觉低,适合标注和理解任务。
- 许可:三款都是 Apache 2.0,研发和商用都友好。
部署怎么配更稳(性能/稳定性)
- 后端:优先 vLLM(低延迟/高吞吐);Transformers 适合做研究与定制,MoE 下注意速度和显存。
- FlashAttention 2:在 Transformers 环境建议开启(需要硬件支持,且用 fp16/bf16 加载)。
- 工具链:安装好
ffmpeg;用qwen-omni-utils处理 Base64/URL/交错多模态,预处理更省心。 - 实时场景:关注音视频 I/O 和编码参数,结合“因果卷积 + 多码本”的路径,保证流式稳定。
关于qwen3
Qwen3首次将认知科学中的"双系统理论"引入AI模型设计,构建了混合推理架构。这种架构通过动态门控机制实时评估任务复杂度,自动在"快思考"与"慢思考"模式间切换:
-
快思考模式(非推理模式):处理日常对话、信息提取等简单任务时,模型采用轻量化路径,仅激活20%参数实现毫秒级响应,算力消耗降低40%。
-
慢思考模式(推理模式):面对数学证明、代码生成等复杂逻辑时,模型启动深度推理模块,通过多步骤分析输出结果,支持38K token的动态思考预算控制。
技术实现亮点:
-
混合专家架构(MoE)的精细化迭代:
-
分层稀疏调度:Qwen3 的配置文件中,mlp_only_layers参数可指定仅使用传统 MLP 的层序号,decoder_sparse_step参数控制 MoE 层的插入间隔。例如 mlp_only_layers = [0,6]时,第 0、3、6 层启用 MoE,其余层保持密集计算,使模型在不同层之间灵活切换计算方式。
-
动态专家激活:默认每个 token 处理时激活的专家数 num_experts_per_tok为 8,总专家池规模 num_experts扩展至 128 个。这样,模型处理复杂任务可调用更多专家资源,简单任务则降低计算开销。
-
负载均衡优化:采用改进的 load_balancing_loss_func,参考 Switch Transformer 设计并引入动态衰减因子,惩罚专家负载不均现象,确保各专家模块均衡利用,提升训练稳定性。
-
-
Transformer 架构的优化:Qwen3 延续并优化了解码器-only结构,精心调整网络层数、注意力机制等关键组件。其注意力机制有三大亮点,一是 QK 标准化,缓解深层网络梯度消失问题;二是动态 RoPE 扩展,支持多种模式且能自适应处理超长序列;三是多后端优化,集成 FlashAttention-2 等内核,大幅提升了对长序列文本的处理能力与效率。
-
注意力机制升级:集成FlashAttention-2内核,RTX 4090显卡推理速度提升37%;支持256K超长上下文,可解析20万字学术论文并生成摘要。
QK标准化:

动态 RoPE 扩展


FlashAttention-2
-
训练策略优化:采用四阶段训练策略,包括长思维链冷启动、强化学习探索、模式融合以及通用校准,强化了模型的学习能力和适应性,提升了准确性并减少了计算资源消耗。整个训练过程分为多个阶段,先构建基础语言能力,再优化知识密集型领域,最后扩展长上下文能力,使模型能力逐步提升。
Qwen3-Omni 全面解析:端到端多模态·实时语音视频·119语言(含技术细节与实操) • Tech Explorer 🚀
2.HuatuoGPT-o1, 采用 LLM 的医学复杂推理
(7 封私信) HuatuoGPT-o1, 采用 LLM 的医学复杂推理 - 知乎
(1)使用验证器指导搜索复杂的推理轨迹以微调 LLM,(2)应用基于验证器的奖励强化学习 (RL) 来进一步增强复杂推理。最后,推出 HuatuoGPT-o1,一种能够进行复杂推理的医学 LLM,它仅使用 40K 个可验证问题就超越一般和医学特定的基线。实验表明,复杂推理可提高医学问题解决能力,并且可从强化学习中获益更多。
相关工作
增强 LLM 中的推理能力。思维链 (CoT) 提示增强 LLM 的推理能力 [60, 61],但扩展专家标记的推理路径仍然成本高昂,尤其是对于复杂问题 [62, 63]。为了缓解这种情况,通过外部监督过滤的模型生成的推理路径(用模型自动生成初稿,再用外部监督筛选优质内容),提供了部分解决方案 [64, 65],但可扩展性挑战仍然存在 [66, 67]。利用奖励模型或 oracle 函数的强化学习方法显示出潜力,但往往存在处理速度慢、成本高和监督瓶颈等问题 [68, 69]。
复杂推理。开发具有批判和自我纠正等反思能力的模型已在推理、规划和编码任务中取得成功 [23, 70–74],但在医学等专业领域尚未得到充分探索。虽然提示技术可以产生自我批判推理 [75, 70],但它们在没有可靠的奖励函数或验证器的情况下会举步维艰,尤其是在复杂领域 [76, 77]。微调和强化学习方法提供了解决方案,但需要大量的人工注释或复杂的奖励设计 [78–81]。此外,自我训练方法为开发自我纠正能力提供了一个有希望的方向 [72, 82, 83]。
工作流程:
数据集构造:将选择题改写成开放型的问题,避免模型不能进行复杂的推理,同时要选择有挑战性的问题(用几个模型一起选择,都对的即为简单问题)。
开发医学验证器。针对这些可验证问题,提出一个验证器来评估模型输出的正确性。给定一个医学可验证问题 x,该模型会生成一个思维链 (CoT) e 和一个结果 y。验证器会根据真实答案 y∗ 检查 y,用 GPT-4o 作为验证器,基于医学领域知识,分析 “模型输出结果 y” 与 “真实答案 y∗” 的核心医学信息是否完全一致 **,而非纠结文字是否相同。
训练 LLM。进行医学复杂推理以识别错误,并使用深度思考来完善答案。如图所示,该方法分为两个阶段:第一阶段:掌握复杂推理;第二阶段,使用强化学习 (RL) 增强复杂推理。
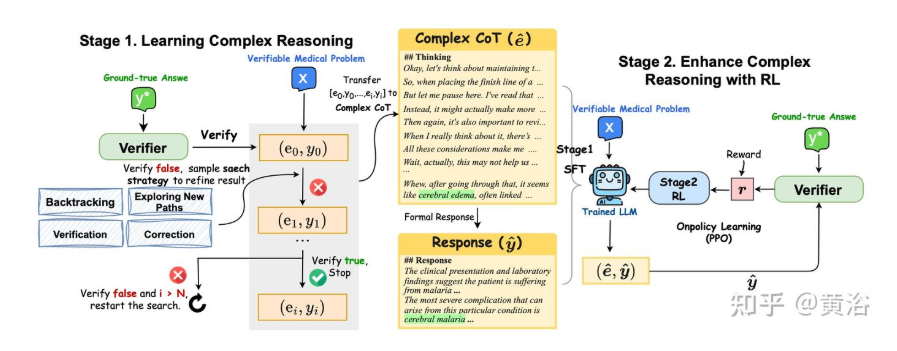
第一阶段:掌握复杂推理
通过 “迭代搜索正确推理轨迹 + 监督微调(SFT)”,让 LLM 学会医学领域复杂推理的完整流程,核心是先 “让强模型(GPT-4o)试错找到正确思考路径”,再用这些路径训练其他 LLM。下面按 “第一阶段:找正确推理轨迹” 和 “第二阶段:用轨迹做 SFT 训练” 两步拆解,结合具体例子让逻辑更清晰:
这一步的目标是:对每个医学问题(x),让 GPT-4o 通过 “试错 + 调整策略”,找到从 “问题” 到 “正确答案(y∗)” 的完整推理过程(即 “推理轨迹”)。本质是模拟人类 “做错题后修正思路” 的过程,只不过用 4 种固定策略指导修正方向。
1. 基础设定:每个问题的 “初始状态”
对每一个 “可验证医学问题二元组 (x, y∗)”(比如 x 是 “患者胸痛 + 心电图异常,诊断是什么?”,y∗是 “急性下壁心梗”):
- 先用 GPT-4o 生成第一次推理:初始思维链 e₀(比如 “患者胸痛,可能是心梗;心电图没说具体导联,所以猜是前壁心梗”)+ 初始答案 y₀(比如 “急性前壁心肌梗死”);
- 用之前提到的 “医学验证器”(还是 GPT-4o)检查 y₀:发现 y₀(前壁心梗)和 y∗(下壁心梗)不一致→判定 “第一次推理错误”,需要进入迭代修正。
2. 核心:4 种搜索策略指导迭代修正
迭代修正的逻辑是:每次错误后,从 4 种策略中随机选 1 种,让 GPT-4o 基于 “之前所有的推理记录(e₀,y₀; e₁,y₁; ...)” 调整思路,生成新的推理 eᵢ和新答案 yᵢ,直到 yᵢ正确,或达到限制次数。
4 种策略的具体作用和例子(接上面的 “心梗诊断错误” 案例):
| 策略名称 | 核心逻辑 | 对应案例中的修正过程 |
|---|---|---|
| 探索新路径 | 完全放弃之前的推理思路,换一种全新的方法分析问题 | 之前 e₀没关注 “心电图具体导联”,这次换思路:“先看题干里的心电图细节 —— 题干提了‘Ⅱ、Ⅲ、aVF 导联 ST 段抬高’,这是下壁心梗的典型表现,再结合胸痛,所以诊断应该是急性下壁心梗”→新 e₁(关注导联细节)+ 新 y₁(急性下壁心梗)。 |
| 回溯 | 不从头再来,而是回到 “前几次推理中某一步”,从那步开始继续往下推(限制 i≤2,即最多回溯到第一次推理) | 假设第一次 e₀只说了 “胸痛→可能心梗”,没分析心电图;第二次推理时选 “回溯”,回到 e₀的 “可能心梗” 这一步,补充分析:“之前只想到心梗,没看心电图 —— 题干里 Ⅱ、Ⅲ、aVF 导联 ST 段抬高,说明是下壁,所以是急性下壁心梗”→新 e₁(从 “可能心梗” 继续推)+ 新 y₁(正确答案)。 |
| 验证 | 不直接改答案,而是先 “评估上一次推理错在哪”,再基于评估结果生成新推理 | 上一次 e₀错在 “没看心电图导联”,选 “验证” 策略后,GPT-4o 先评估:“e₀的问题是遗漏了题干中‘Ⅱ、Ⅲ、aVF 导联 ST 段抬高’的关键信息,这个导联异常对应下壁心梗,而非前壁”→评估过程作为新 e₁,再基于评估得出 y₁(急性下壁心梗)。 |
| 更正 | 直接指出上一次推理的错误,然后 “修正错误步骤” 生成新推理 | 选 “更正” 策略后,GPT-4o 直接批评 e₀:“e₀错误在于未分析心电图具体导联,题干中 Ⅱ、Ⅲ、aVF 导联 ST 段抬高是下壁心梗的特征,而非前壁”→修正后的推理作为 e₁,答案 y₁(正确)。 |
3. 迭代终止条件:找到正确轨迹或放弃
- 成功终止:如果某次迭代生成的 yᵢ被验证器判定为 “正确”,则停止迭代,此时 “e₀,y₀; e₁,y₁; ...; eᵢ,yᵢ” 就是这条问题的 “成功推理轨迹”;
- 失败重试:如果迭代到最大次数 N=3(即试了 3 次还没对),则 “重新开始”(换策略再试一轮),最多重试 T=3 次;
- 彻底放弃:3 次重试都失败,就丢弃这个问题(不把它纳入后续训练数据)。
基于格式化后的 ê,生成一个 “简洁、规范的医学答案”(ŷ),作为最终给用户的回复。比如上面的 ê 对应的ŷ是:“该患者最可能的诊断为急性下壁心肌梗死。”
4. 构建 SFT 数据集 + 微调 LLM
- 构建数据集:成功找到轨迹的医学问题(x,y∗)”,每个都生成(x, ê, ŷ)三元组,组成 SFT 数据集 D_SFT;
- 监督微调(SFT):用 D_SFT 去训练目标 LLM(比如之前提到的 Gemma2-9B、LLaMA-3.1-8B 等中小型医学 LLM)。训练目标是:让模型看到问题 x 后,先生成像 ê 一样的 “复杂、连贯的推理过程”,再输出像ŷ一样的 “规范答案”。
- 训练目的:教会模型 “先思考、再回答”—— 模仿 GPT-4o 的 “搜索流(SoS)” 方式,遇到复杂医学问题时,先深入探索推理路径(而非直接蒙答案),最终输出正确结果。
第二阶段:使用强化学习 (RL) 增强复杂推理
-
为啥要 RL:第一阶段 SFT 让模型学会 “正确推理”,但路径可能不优、泛化差;RL 要进一步让模型推理更高效、稳定,还不偷懒。
-
怎么给奖励(引导方向):
- 答案对 + 有完整推理:奖励 1(最优);
- 答案错但有推理:奖励 0.1(鼓励思考,不鼓励瞎蒙);
- 没推理直接给答案:奖励 0(严罚偷懒);
- 加 “KL 散度约束”:防止模型推理跑偏(比如为了简洁跳过关键医学步骤),保证优化不脱离正确基础。
- 用 PPO 算法执行 RL:
- 用第一阶段 SFT 后的模型当初始模型,在新的医学题(D_RL)上练;
- 模型生成推理和答案→算奖励→根据奖励调整模型参数;
- 循环多次,直到模型稳定拿高奖励(推理又对又优)。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)