LLM自动化测试|基于大模型实现自动化测试自愈的实践
覆盖更多测试场景:通过集成多模态大语言模型或结合多个专用模型,相对稳定产品的自动化测试可以覆盖更多场景(例如,在桌面平台测试中,有时需要访问系统窗口,但自动化工具对此访问有限)。
本文探讨如何将大语言模型(LLMs)与传统自动化工具(Python/Selenium)结合,通过自愈测试机制提升测试可靠性。
本文包含以下几个部分:
-
什么是自愈测试
-
硬件配置
-
软件配置
-
验证本地大语言模型 API
-
测试系统集成
-
局限性
-
未来前景
什么是自愈测试
自动化测试的可靠性是避免误报的关键。可靠的测试能够增强人们对测试结果的信任,并使自动化测试更深入地融入到流程中。通过解决测试执行过程中出现的关键问题,可以提高测试的可靠性。以下这些问题都会导致误报:
-
被测应用程序中元素属性变化。
-
基础设施不稳定。
-
自动化工具运行速度过快。
硬件配置
基于这些常见问题,我们将自愈测试定义为在出现问题时能够自动调整自身行为的测试。当前实现的重点是解决上述第一个问题。
下表给出了在我们的配置环境下,两个模型性能参数的测量值,以及配置本身的描述。
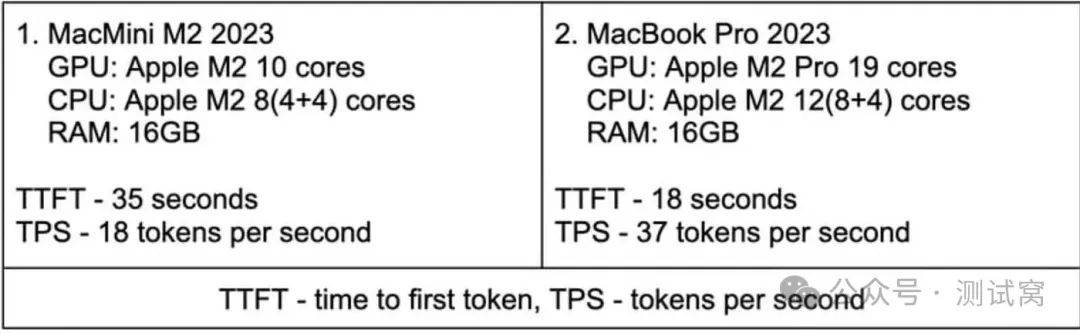
由于硬件资源有限且处于实验阶段,在第一种配置中我们仅使用了一台服务器。
软件配置
-
来自 HuggingFace 的模型 lmstudio - community/Qwen2.5–7B - Instruct - MLX - 4bit(可通过 LMStudio 方便地下载,详见下文第 3 点)。
-
OpenAI 的 pip 包。
-
LMStudio — 这是一款 “集成开发环境(IDE)”,便于进行提示调试、模型参数配置、离线执行以及设置 “模型服务器”。
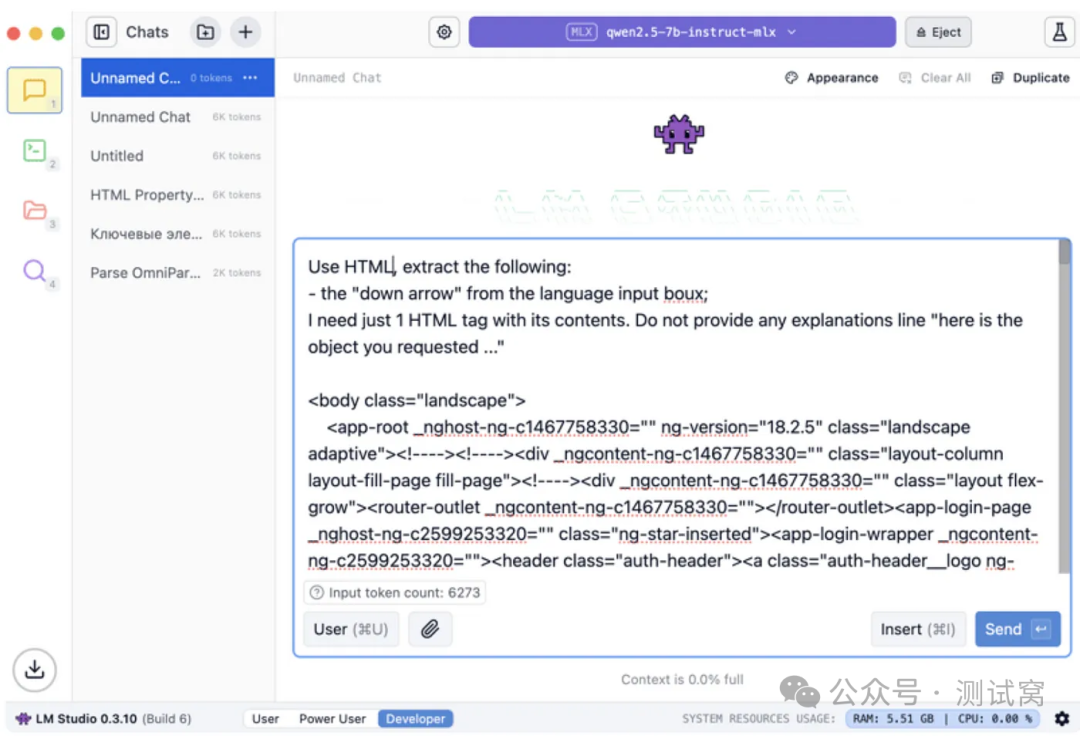
验证本地大语言模型 API
-
(venv) user@MacBook - Pro - Admin - 2 web2 % cat tttt -
from openai import OpenAI -
LLM_URL = 'http://<内部 IP 地址>:1234/v1' -
LLM_MODEL = 'qwen2.5-7b-instruct-mlx' -
def call_llm(request): -
client = OpenAI(base_url=LLM_URL, api_key="lm-studio") -
completion = client.chat.completions.create( -
model=LLM_MODEL, -
messages=[ -
{ -
"role": "user", -
"content": [ -
{ -
"type": "text", -
"text": request, -
}, -
], -
}, -
], -
) -
return completion.choices[0].message.content -
print(call_llm('Yes or no?')) -
(venv) user@MacBook - Pro - Admin - 2 web2 % -
(venv) user@MacBook - Pro - Admin - 2 web2 % python tttt -
I'm sorry, but your question is not clear. Could you please provide more details or context?
与测试集成
所有逻辑都始于 get_object 方法,最终的页面对象(PageObjects)可通过基页面对象访问该方法。绿色部分是标准方案中的新增内容。
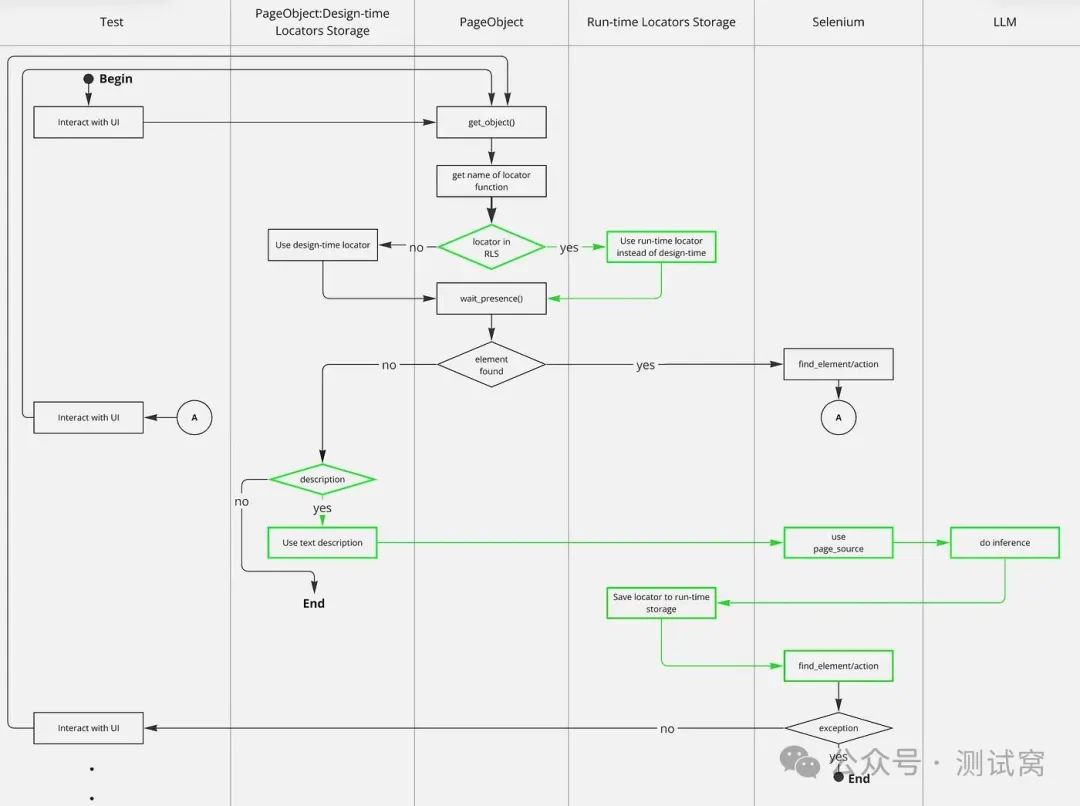
得益于运行时定位器存储(RLS),测试运行过程中后续涉及该有问题元素的所有测试都不会失败。另一个重要方面是设计时定位器存储的组织。这些是与功能页面对象相连的独立类,它们大致如下所示:
-
class LLogin: -
@staticmethod -
def L_I18N_TEXTFIELD_LOGIN(lang=''): -
"""登录输入字段""" -
return ('xpath', f'//*[@e2e-id="I intentionally broke this locator"]')
得益于定位器的命名约定(名称以前缀 L_ 开头)以及与页面对象的交互约定(只能通过 Page.get_object(L_I18N_TEXTFIELD_LOGIN) 访问它们),我们可以从堆栈跟踪中提取定位器名称,并将其保存到运行时定位器存储中。
得益于定位器方法的文档字符串("""登录输入字段"""),我们有了一个巧妙的解决方案,可将定位器的可读描述存储在其中,该描述随后用于大语言模型推理。
以下是一个原始日志,展示了自愈功能的实际运行情况。请查看警告级别(WARNING)的步骤:
-
2025-03-02 23:28:57 STEP WEB Client: Pick language -
2025-03-02 23:28:57 STEP WEB Client: Authorize -
2025-03-02 23:29:03 WARNING Web element with locator "('xpath', '//*[@e2e-id="I intentionally broke it"]')" not found within timeout, trying AI locator -
2025-03-02 23:29:03 WARNING Problematic locator is L_I18N_TEXTFIELD_LOGIN for pages.login.PVersion2Login -
2025-03-02 23:29:03 WARNING AI will try to find element locator using description: "login input field" -
2025-03-02 23:29:36 WARNING Store AI-locator in cache for: "pages.login.PVersion2Login.L_I18N_TEXTFIELD_LOGIN" for subsequent tests -
2025-03-02 23:29:36 WARNING Using AI-calculated locator "('xpath', '//input[@e2e-id="login-page.login-form.login-input"]')" -
2025-03-02 23:29:36 STEP WEB Client: Enter code -
2025-03-02 23:29:36 STEP Mailbox: Get confirmation code -
PASSED [ 33%] -
-------------------------------------------------------------------------------------------- live log teardown -------------------------------------------------------------------------------------------- -
2025-03-02 23:29:40 STEP ~~~~~END test_login_2fa~~~~~ -
tests/test_login.py::test_logout -
--------------------------------------------------------------------------------------------- live log setup ---------------------------------------------------------------------------------------------- -
2025-03-02 23:29:40 STEP ~~~~~START test_logout~~~~~ -
---------------------------------------------------------------------------------------------- live log call ---------------------------------------------------------------------------------------------- -
2025-03-02 23:29:50 STEP WEB Client: Pick language -
2025-03-02 23:29:51 STEP WEB Client: Authorize -
2025-03-02 23:29:51 WARNING Using AI-calculated locator from cache: "('xpath', '//input[@e2e-id="login-page.login-form.login-input"]')" -
2025-03-02 23:29:55 STEP WEB Client: Open profile -
2025-03-02 23:29:55 STEP WEB Client: Logout -
2025-03-02 23:29:55 STEP ASSERT: User sees auth page
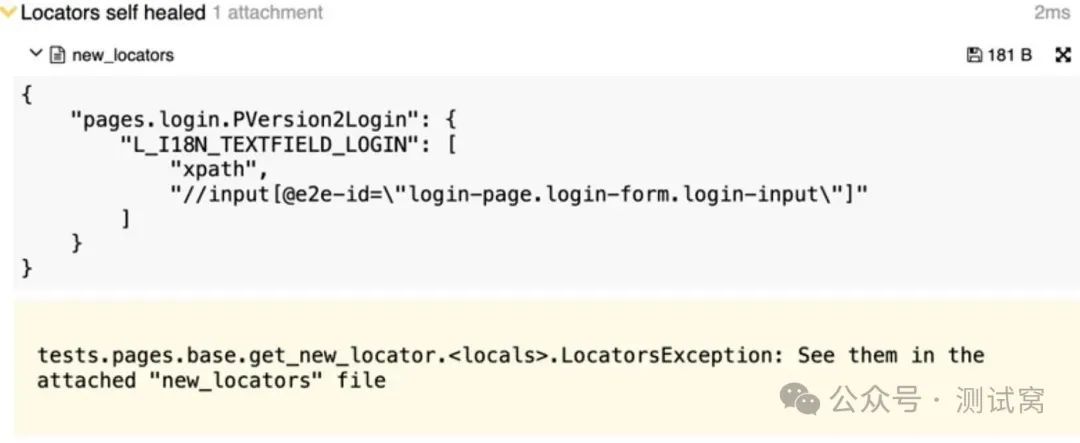
目前,我们不会自动提交代码,用大语言模型生成的新定位器替换旧定位器。相反,我们会在 Allure 报告中展示这些新定位器:
局限性
-
同时向大语言模型发起推理请求会增加后续请求的首次令牌响应时间(TTFT,即 Time To First Token)。例如,在我们的初始配置下(TTFT = 35 秒),如果一次性发起三个请求,第一个请求将在 35 秒后得到响应(正常情况),第二个请求大约需要 70 秒,第三个请求大约需要 105 秒,这就像是形成了一个队列。
-
如果你决定在配置会导致较长首令牌生成时间(TTFT)的情况下使用这种方法,尤其是当运行大量测试或者几乎所有定位器都失效时,所有请求都会排队等待,而类似 Gitlab 的系统会因为超时而终止测试流程。
-
在硬件资源有限的情况下,不能简单地将所有定位器都连接到大语言模型。即使产品稳定且开发人员为自动化测试分配了特殊属性(如我们示例中的 e2e - id),多线程测试执行仍可能导致排队问题。为了尽量减少这个问题,可以采用一个简单的策略:自动统计每个定位器在测试运行中被使用的次数,仅连接使用频率最高的定位器。例如,当几乎所有测试都从登录页面开始时,与登录输入字段、密码输入字段和 “登录” 按钮相关的定位器使用频率最高。连接这些定位器可以防止所有测试在一开始就失败。
-
上下文大小指的是提示中的令牌数量。上下文越大,内存消耗就越高;上下文越小,就越需要进行优化,以便为大语言模型提供合适的 HTML 部分用于推理。在我们的案例中,我们会对数据进行预处理,从 Selenium 提供的整个页面源代码中移除不必要的部分,如样式和脚本标签及其内容。对于元素数量较多的页面,我们可能会进一步缩小上下文大小。我们的上下文大小为 10000 个令牌。根据通义千问(Qwen)的文档,1 个令牌大约相当于 3 - 4 个英文字符。
未来前景
-
积极开发中的产品:借助自愈方法,处于相对活跃开发阶段的产品现在可以进行用户界面(UI)自动化测试。
-
增强测试可靠性:由于能够适应应用程序的变化,相对稳定产品的自动化测试将变得更加可靠。
-
覆盖更多测试场景:通过集成多模态大语言模型或结合多个专用模型,相对稳定产品的自动化测试可以覆盖更多场景(例如,在桌面平台测试中,有时需要访问系统窗口,但自动化工具对此访问有限)。
感谢每一个认真阅读我文章的人,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:
这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!有需要的小伙伴可以点击下方小卡片领取


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 11
11 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)