大模型开发中的浮点数精度选择:FP32、FP16、BF16详解!
文章详细介绍了深度学习和高性能计算中常用的浮点数精度格式,包括FP32、FP16、BF16、TF32、FP64及INT8/INT4等。分析了它们的位数构成、数值表示能力和适用场景,并提供了选择建议:模型训练优先考虑BF16或混合精度训练,推理阶段可根据显存情况选择FP16或INT8/INT4量化,边缘设备适合INT4。强调了选择精度时需考虑任务需求、硬件支持和资源限制,并指出指数位决定动态范围,尾
简介
文章详细介绍了深度学习和高性能计算中常用的浮点数精度格式,包括FP32、FP16、BF16、TF32、FP64及INT8/INT4等。分析了它们的位数构成、数值表示能力和适用场景,并提供了选择建议:模型训练优先考虑BF16或混合精度训练,推理阶段可根据显存情况选择FP16或INT8/INT4量化,边缘设备适合INT4。强调了选择精度时需考虑任务需求、硬件支持和资源限制,并指出指数位决定动态范围,尾数位决定精度。
BF16、FP16和FP32是深度学习和高性能计算中常用的几种浮点数精度格式,它们在位数构成、数值表示能力和适用场景上各有特点。除此之外,还有TF32、FP64以及INT8/INT4等精度格式。
🔍 精度格式详解

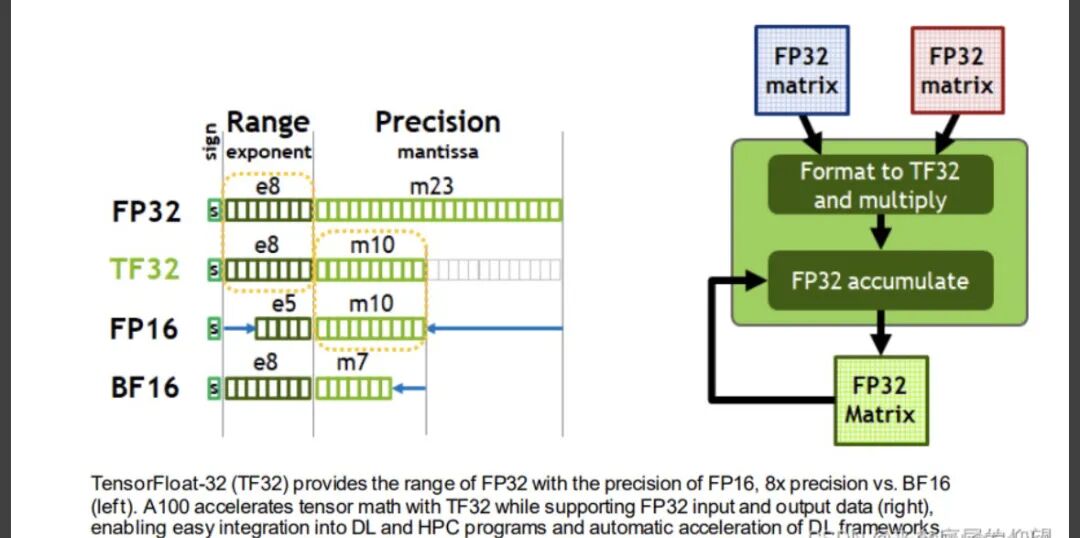
FP32 (单精度浮点数) 使用32位表示:1位符号位、8位指数位和23位尾数位。其动态范围约为 ±1.4×10⁻⁴⁵ 到 ±3.4×10³⁸,提供约6-9位十进制有效数字的高精度,但每个参数需占用4字节内存。FP32数值精度高、稳定性好,常用于科学计算、金融模拟等对精度要求极高的领域,缺点是计算速度相对较慢,内存占用大。

FP16 (半精度浮点数) 使用16位表示:1位符号位、5位指数位和10位尾数位。其动态范围约为 ±5.96×10⁻⁸ 到 ±6.55×10⁴,提供约3-4位十进制有效数字。每个参数占用2字节内存,内存占用仅为FP32的一半,计算速度快,并能利用现代GPU的Tensor Core进行加速。主要缺点是数值范围窄,在深度学习训练中容易发生梯度上溢出(变成NaN)或下溢出(变为0),通常需要配合梯度缩放技术(如NVIDIA的AMP)使用。多用于深度学习推理和移动端部署。

BF16 (脑浮点16) 同样使用16位表示:1位符号位、8位指数位和7位尾数位。它的关键优势在于其指数位与FP32相同,因此动态范围与FP32基本一致(约 ±1.2×10⁻³⁸ 到 ±3.4×10³⁸),但尾数位较少,精度较低,仅提供约2位十进制有效数字。每个参数占用2字节内存。BF16在保持16位计算效率和低内存占用优势的同时,因其宽广的动态范围,能有效避免训练过程中的梯度溢出问题,大大提升了训练稳定性,尤其适合大型模型(如LLM)的训练。
🧠 其他常见的数值精度
除了上述三种,深度学习中还常见其他精度格式:
-
TF32 (Tensor Float 32):NVIDIA为其Ampere架构GPU设计的格式。指数位同FP32/BF16(8位),尾数位同FP16(10位)。它在保持FP32动态范围的同时,提供优于BF16的精度,并能利用Tensor Core实现高速计算,在Ampere及后续架构的GPU上训练时性能优异。
-
FP64 (双精度浮点数):64位(1符号位 + 11指数位 + 52尾数位)。提供极高精度(约15-17位有效数字)和极大动态范围,但内存占用和计算开销也最大(8字节/参数)。主要用于传统科学计算、精密仿真等对数值精度有极致要求的领域,在深度学习中较少使用。
-
INT8 / INT4 (8位 / 4位整数):通过量化技术将浮点数转换为低比特整数,并配合一个缩放因子(scale)来表示数值。可以极大约束模型体积和提升推理速度,但对精度有一定影响。常用于边缘设备部署、移动端推理等对存储和功耗敏感的场景。通常需要在量化后进行微调(如使用GPTQ、AWQ算法)来尽可能恢复精度。
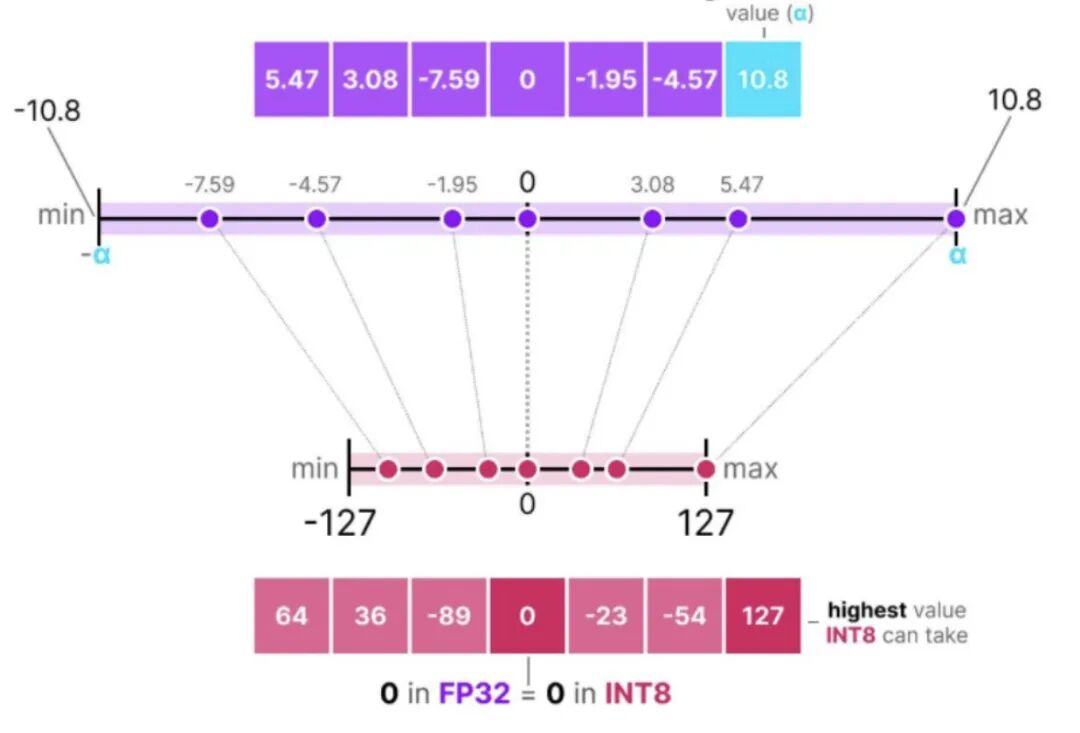
上图是对称量化的示例,原本浮点数的值域会被映射到量化空间(quantized space)中一个以零为中心的对称区间,**量化前后的值域都是围绕零点对称的。**除了对称量化,还有非对称量化,而且量化有一个最大的问题是存在量化误差,比如上图的5.47量化成64,5.45可能也会量化成64,就无法区分这两个原始数值了,这块比较复杂,以后介绍。
⚡️ 如何选择精度格式
选择时需权衡任务需求、硬件支持和资源限制:
-
模型训练:
- 优先考虑 BF16:因其动态范围与FP32相同,能有效避免梯度溢出,训练更稳定,同时节省显存。
- 混合精度训练:常见做法是权重使用FP32(主权重),前向和反向计算使用FP16或BF16,最后用FP32精度更新权重。这既能加速计算、节省显存,又能保持数值稳定性。PyTorch等框架提供自动混合精度(AMP)工具。
-
模型推理:
- 显存充足(≥16GB):可优先使用 FP16,在支持Tensor Core的硬件上能获得很好的加速比。
- 显存紧张或追求极致吞吐:考虑 INT8 或 INT4 量化,但需注意精度损失,并可能需要进行量化后微调。
- 边缘/移动设备:INT4 是常见选择,需使用特定优化库。
-
高精度计算:
- 科学计算、金融建模等领域,对误差敏感,FP32 或 FP64 仍是首选。
🧭 硬件支持注意事项
选择精度时务必考虑硬件兼容性:
- BF16:需要较新的GPU架构支持(如NVIDIA的Ampere架构及以上:A100, H100, RTX 30/40系列)。
- FP16:支持广泛(NVIDIA GPU从Pascal架构开始普遍支持)。
- TF32:NVIDIA Ampere架构及以上GPU专属。
- INT4/INT8:需要硬件支持对应的整数计算指令集。
💎 记住核心原则
- 指数位决定动态范围(能表示的数有多大/多小)。
- 尾数位决定精度(表示的数有多精确)。
- 位宽决定内存占用和理论计算速度。
- “BF16保范围舍精度,FP16保精度舍范围”。
希望这些信息能帮助你更好地理解这些精度格式的区别和应用场景。
AI大模型学习路线
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 3
3 0
0- 0



 已为社区贡献365条内容
已为社区贡献365条内容

所有评论(0)