智能体框架和工具系列:2-LangChain-LangGraph生态深度剖析
摘要: 本文深度剖析LangChain和LangGraph两大智能体开发框架。LangChain作为模块化LLM应用框架,提供链式调用和组件化开发能力,支持多步推理流程构建。LangGraph基于图结构编排复杂智能体系统,实现状态管理和条件执行。两者形成互补生态,覆盖从简单链式调用到复杂智能体系统的全场景需求。文章详细解析了技术架构、核心原理(如链式调用/图遍历机制)和实战案例(如法律咨询系统),
智能体框架和工具系列:2-LangChain-LangGraph生态深度剖析
智能体框架和工具系列总目录:
- 一、智能体框架和工具系列:1-低代码智能体平台深度解析Dify、Coze、n8n
- 二、智能体框架和工具系列:2-LangChain-LangGraph生态深度剖析
- 三、智能体框架和工具系列:3-多智能体协作框架深度解析AutoGen、CrewAI、GraphRAG
- 四、智能体框架和工具系列:4-企业级知识管理平台深度解析MaxKB、FastGPT、DB-GPT
- 五、智能体框架和工具系列:5-框架全景对比分析、实战案例集、框架选择建议
本文深度解析LangChain和LangGraph两大核心框架,从模块化链式架构到图结构编排,为开发者提供全面的技术指南。
目录
概述
LangChain生态系统是当前最成熟的LLM应用开发框架之一,包含两个核心组件:
- LangChain:模块化LLM应用框架,提供链式调用和组件化开发能力
- LangGraph:基于图结构的智能体编排框架,支持复杂状态管理和条件执行
两者相辅相成,共同构成了从简单链式调用到复杂智能体系统的完整解决方案。
一、LangChain:模块化LLM应用框架
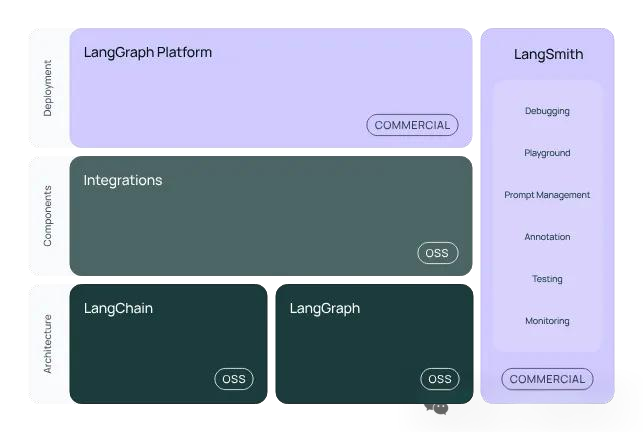
LangChain是智能体框架领域的早期布道者,由LangChain团队开发,提供链式调用和模块化组合的架构设计。
项目地址:https://github.com/langchain-ai/langchain
技术架构深度解析
LangChain采用模块化链式架构,核心组件包括:
1. 核心抽象层
- BaseModel:统一的模型接口抽象
- BasePromptTemplate:Prompt模板管理
- BaseMemory:记忆管理抽象
- BaseTool:工具调用接口
2. 链式组合层
- Sequential Chain:顺序执行链
- Router Chain:条件路由链
- MapReduce Chain:并行处理链
- Transform Chain:数据转换链
核心技术原理
链式调用机制
from langchain.chains import LLMChain, SequentialChain
from langchain.prompts import PromptTemplate
class MultiStepReasoning:
def __init__(self, llm):
self.llm = llm
# 第一步:问题分析
analysis_prompt = PromptTemplate(
input_variables=["question"],
template="""
分析以下问题的关键要素:
问题:{question}
请识别:
1. 主要问题类型
2. 需要的信息类型
3. 解决步骤
"""
)
self.analysis_chain = LLMChain(llm=llm, prompt=analysis_prompt)
# 第二步:信息检索
retrieval_prompt = PromptTemplate(
input_variables=["analysis", "question"],
template="""
基于分析结果:{analysis}
针对问题:{question}
请生成具体的检索查询策略
"""
)
self.retrieval_chain = LLMChain(llm=llm, prompt=retrieval_prompt)
# 第三步:答案生成
generation_prompt = PromptTemplate(
input_variables=["question", "analysis", "retrieval_info"],
template="""
原始问题:{question}
分析结果:{analysis}
检索信息:{retrieval_info}
请生成准确、完整的答案
"""
)
self.generation_chain = LLMChain(llm=llm, prompt=generation_prompt)
# 组合成序列链
self.overall_chain = SequentialChain(
chains=[self.analysis_chain, self.retrieval_chain, self.generation_chain],
input_variables=["question"],
output_variables=["text"]
)
def run(self, question: str) -> str:
return self.overall_chain.run(question=question)
核心能力
- 链式调用逻辑:适合构建多步推理的问答系统
- 模块化工具集成:支持多种外部API和数据库
- 开源模型兼容:与开源语言模型兼容性良好
- 调试监控工具:提供完整的调试和监控工具链
- 丰富的RAG支持:向量数据库集成和检索增强生成
实战案例:智能法律咨询系统
from langchain.chains import RetrievalQA
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.document_loaders import DirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
class LegalConsultationSystem:
def __init__(self, law_documents_path: str):
# 加载法律文档
loader = DirectoryLoader(law_documents_path, glob="**/*.txt")
documents = loader.load()
# 文档分块
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200
)
splits = text_splitter.split_documents(documents)
# 构建向量数据库
embeddings = OpenAIEmbeddings()
self.vectorstore = Chroma.from_documents(splits, embeddings)
# 创建检索问答链
self.qa_chain = RetrievalQA.from_chain_type(
llm=ChatOpenAI(temperature=0),
chain_type="stuff",
retriever=self.vectorstore.as_retriever(search_kwargs={"k": 3}),
return_source_documents=True
)
def consult(self, legal_question: str) -> dict:
"""处理法律咨询问题"""
result = self.qa_chain({"query": legal_question})
return {
"answer": result["result"],
"sources": [doc.metadata for doc in result["source_documents"]],
"confidence": self._calculate_confidence(result)
}
def _calculate_confidence(self, result) -> float:
# 基于检索文档相似度计算置信度
scores = [doc.metadata.get("score", 0) for doc in result["source_documents"]]
return sum(scores) / len(scores) if scores else 0
# 使用示例
legal_system = LegalConsultationSystem("./legal_documents")
result = legal_system.consult("合同违约的法律后果是什么?")
print(f"答案:{result['answer']}")
print(f"依据:{result['sources']}")
适用场景
LangChain特别适合需要多步推理和工具调用的场景:
- 文档问答系统:基于知识库的智能问答
- 代码辅助生成:多步骤的代码分析和生成
- RAG应用:检索增强生成应用
- 内容创作:多步骤的内容生成流程
局限性
- 学习曲线陡峭:链式结构相对复杂
- 状态管理有限:对任务流程控制支持不够强
- 图形界面缺失:主要依赖代码开发,开发效率较低
- 语言限制:主要面向Python开发者
二、LangGraph:基于图结构的智能体编排框架

LangGraph是LangChain生态系统的最新成员,专门用于构建状态化、多智能体应用的框架。它通过图结构来表示智能体的工作流,支持复杂的条件逻辑和循环控制。
项目地址:https://github.com/langchain-ai/langgraph
技术架构深度解析
LangGraph基于有向图(DAG)架构设计:
1. 图结构核心组件
- Nodes(节点):代表智能体或函数
- Edges(边):定义执行流程和条件路由
- State(状态):在节点间传递的数据结构
- Checkpoints(检查点):支持暂停和恢复执行
2. 状态管理机制
- Reducer Functions:处理状态更新冲突
- State Schema:定义状态数据结构
- Persistence Layer:持久化状态存储
核心技术原理
图结构工作流引擎
from langgraph.graph import StateGraph, END
from typing import TypedDict, Annotated
import operator
class AgentState(TypedDict):
messages: Annotated[list, operator.add]
current_task: str
completed_steps: list
error_count: int
def research_node(state: AgentState):
"""研究节点"""
messages = state["messages"]
task = state["current_task"]
# 执行研究逻辑
research_result = conduct_research(task)
return {
"messages": messages + [{"role": "researcher", "content": research_result}],
"completed_steps": state["completed_steps"] + ["research"],
"current_task": task
}
def analysis_node(state: AgentState):
"""分析节点"""
messages = state["messages"]
research_data = messages[-1]["content"]
# 执行分析逻辑
analysis_result = analyze_data(research_data)
return {
"messages": messages + [{"role": "analyst", "content": analysis_result}],
"completed_steps": state["completed_steps"] + ["analysis"],
}
def should_continue(state: AgentState):
"""条件判断函数"""
messages = state.get("messages", [])
if len(messages) > 10:
return "end"
elif state.get("error_count", 0) > 3:
return "error_handler"
else:
return "continue"
# 构建图结构工作流
workflow = StateGraph(AgentState)
# 添加节点
workflow.add_node("research", research_node)
workflow.add_node("analysis", analysis_node)
workflow.add_node("synthesis", synthesis_node)
# 设置入口点
workflow.set_entry_point("research")
# 添加条件边
workflow.add_conditional_edges(
"research",
should_continue,
{
"continue": "analysis",
"error_handler": "error_node",
"end": END
}
)
workflow.add_edge("analysis", "synthesis")
workflow.add_edge("synthesis", END)
# 编译图
app = workflow.compile()
核心能力
- 状态化执行:支持复杂的状态管理和数据流转
- 条件路由:基于执行结果动态选择下一步执行路径
- 并行执行:支持多个节点同时执行,提高效率
- 检查点机制:支持工作流暂停、恢复和回滚
- 人机协作:支持人工介入和审批流程
实战案例:智能客户服务系统
from langgraph.graph import StateGraph, END
from langgraph.prebuilt import ToolExecutor
from langchain.tools import Tool
from typing import TypedDict, Annotated, List
import operator
class CustomerServiceState(TypedDict):
messages: Annotated[List[dict], operator.add]
customer_info: dict
intent: str
confidence: float
escalation_needed: bool
resolution_steps: List[str]
def intent_detection_node(state: CustomerServiceState):
"""意图识别节点"""
last_message = state["messages"][-1]["content"]
# 调用意图识别模型
intent_result = intent_classifier.predict(last_message)
return {
"intent": intent_result["intent"],
"confidence": intent_result["confidence"],
"messages": state["messages"]
}
def knowledge_retrieval_node(state: CustomerServiceState):
"""知识库检索节点"""
intent = state["intent"]
customer_query = state["messages"][-1]["content"]
# 从知识库检索相关信息
relevant_docs = knowledge_base.search(
query=customer_query,
filters={"category": intent},
top_k=3
)
knowledge_context = "\n".join([doc.content for doc in relevant_docs])
return {
"messages": state["messages"] + [{
"role": "system",
"content": f"相关知识:{knowledge_context}"
}],
"resolution_steps": state.get("resolution_steps", []) + ["knowledge_retrieved"]
}
def response_generation_node(state: CustomerServiceState):
"""回答生成节点"""
conversation_history = state["messages"]
intent = state["intent"]
# 生成个性化回答
response = chatbot.generate_response(
messages=conversation_history,
intent=intent,
customer_info=state.get("customer_info", {})
)
return {
"messages": state["messages"] + [{
"role": "assistant",
"content": response
}],
"resolution_steps": state.get("resolution_steps", []) + ["response_generated"]
}
def escalation_check(state: CustomerServiceState):
"""升级判断函数"""
confidence = state.get("confidence", 0)
intent = state.get("intent", "")
# 低置信度或复杂问题需要人工处理
if confidence < 0.7 or intent in ["complaint", "refund", "technical_issue"]:
return "human_agent"
elif state.get("escalation_needed", False):
return "supervisor"
else:
return "automated_response"
# 构建客户服务图结构
customer_service_workflow = StateGraph(CustomerServiceState)
# 添加处理节点
customer_service_workflow.add_node("intent_detection", intent_detection_node)
customer_service_workflow.add_node("knowledge_retrieval", knowledge_retrieval_node)
customer_service_workflow.add_node("response_generation", response_generation_node)
customer_service_workflow.add_node("human_handoff", human_handoff_node)
# 设置流程路径
customer_service_workflow.set_entry_point("intent_detection")
customer_service_workflow.add_conditional_edges(
"intent_detection",
escalation_check,
{
"automated_response": "knowledge_retrieval",
"human_agent": "human_handoff",
"supervisor": "human_handoff"
}
)
customer_service_workflow.add_edge("knowledge_retrieval", "response_generation")
customer_service_workflow.add_edge("response_generation", END)
customer_service_workflow.add_edge("human_handoff", END)
# 编译并部署
customer_service_app = customer_service_workflow.compile()
# 使用示例
initial_state = {
"messages": [{"role": "user", "content": "我的订单还没收到,怎么办?"}],
"customer_info": {"user_id": "12345", "vip_level": "gold"},
"resolution_steps": []
}
result = customer_service_app.invoke(initial_state)
print(f"最终回答:{result['messages'][-1]['content']}")
适用场景
LangGraph特别适合需要复杂状态管理和条件执行的场景:
- 多轮对话系统:需要维护对话历史和上下文
- 复杂业务流程自动化:包含多个决策点和分支逻辑
- 人机协作系统:需要在特定条件下转交给人工处理
- 有状态的游戏AI:需要记住游戏状态和历史行为
局限性
- 学习曲线陡峭:图结构设计需要仔细规划
- 调试复杂:复杂工作流的调试相对困难
- Python限制:主要支持Python语言
- 资源消耗:状态管理可能带来额外的计算和存储开销
LangChain vs LangGraph对比分析
1、架构设计对比
| 维度 | LangChain | LangGraph |
|---|---|---|
| 设计模式 | 链式调用 | 图结构 |
| 状态管理 | 有限 | 强大 |
| 条件执行 | 基础 | 原生支持 |
| 并行处理 | 有限 | 原生支持 |
| 复杂度 | 中等 | 高 |
2、功能能力对比
| 功能 | LangChain | LangGraph | 说明 |
|---|---|---|---|
| 简单链式调用 | ★★★★★ | ★★★☆☆ | LangChain更简单直接 |
| 复杂工作流 | ★★★☆☆ | ★★★★★ | LangGraph支持复杂逻辑 |
| 状态持久化 | ★★☆☆☆ | ★★★★★ | LangGraph原生支持 |
| 人机协作 | ★★☆☆☆ | ★★★★☆ | LangGraph更适合 |
| 调试工具 | ★★★★☆ | ★★★☆☆ | LangChain工具更成熟 |
| 学习成本 | ★★★☆☆ | ★★★★☆ | LangGraph学习曲线更陡 |
3、性能对比
| 指标 | LangChain | LangGraph | 备注 |
|---|---|---|---|
| 执行效率 | 高 | 中等 | 图结构有额外开销 |
| 内存使用 | 低 | 中等 | 状态管理需要更多内存 |
| 扩展性 | 良好 | 优秀 | 图结构更易扩展 |
| 维护性 | 中等 | 良好 | 图结构更清晰 |
4、使用场景对比
| 场景 | 推荐框架 | 理由 |
|---|---|---|
| 简单RAG应用 | LangChain | 链式调用足够,开发更简单 |
| 文档问答 | LangChain | 成熟的RAG组件 |
| 多轮对话 | LangGraph | 需要状态管理 |
| 复杂工作流 | LangGraph | 条件分支和并行处理 |
| 人机协作 | LangGraph | 支持人工介入点 |
| 快速原型 | LangChain | 开发速度快 |
| 生产系统 | LangGraph | 更好的可维护性 |
生态系统集成
1、组件共享
LangChain和LangGraph共享大部分底层组件:
# 共享的组件
from langchain.llms import OpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.tools import Tool
# LangChain中使用
llm = OpenAI()
chain = LLMChain(llm=llm, prompt=prompt)
# LangGraph中使用
def llm_node(state):
llm = OpenAI()
response = llm.invoke(state["messages"][-1])
return {"messages": state["messages"] + [response]}
2、渐进式迁移
可以从LangChain逐步迁移到LangGraph:
# 阶段1:LangChain链式调用
def simple_chain():
return SequentialChain(
chains=[analysis_chain, retrieval_chain, generation_chain]
)
# 阶段2:LangGraph简单图
def simple_graph():
workflow = StateGraph(State)
workflow.add_node("analysis", analysis_node)
workflow.add_node("retrieval", retrieval_node)
workflow.add_node("generation", generation_node)
workflow.add_edge("analysis", "retrieval")
workflow.add_edge("retrieval", "generation")
return workflow.compile()
# 阶段3:LangGraph复杂图
def complex_graph():
workflow = StateGraph(State)
# 添加条件路由、并行处理等
workflow.add_conditional_edges(...)
return workflow.compile()
3、混合使用模式
在同一个项目中可以混合使用两个框架:
class HybridSystem:
def __init__(self):
# 使用LangChain处理简单链式调用
self.simple_qa = RetrievalQA.from_chain_type(...)
# 使用LangGraph处理复杂工作流
self.complex_workflow = self.build_complex_graph()
def handle_simple_query(self, query):
return self.simple_qa.run(query)
def handle_complex_task(self, task):
return self.complex_workflow.invoke(task)
选择建议
1、技术选型决策树
2、按团队情况选择
新团队/学习阶段
- 从LangChain开始学习基本概念
- 掌握链式调用和组件使用
- 积累RAG应用开发经验
有经验团队/复杂需求
- 直接使用LangGraph构建复杂系统
- 利用状态管理和条件路由
- 实现高级功能如人机协作
3、按应用类型选择
内容类应用
- 文档问答:LangChain
- 内容生成:LangChain
- 知识检索:LangChain
交互类应用
- 智能客服:LangGraph
- 虚拟助手:LangGraph
- 游戏AI:LangGraph
流程类应用
- 业务自动化:LangGraph
- 审批工作流:LangGraph
- 数据处理管道:LangGraph
4、迁移策略
对于现有LangChain项目,建议的迁移路径:
- 评估现状:分析当前系统的复杂度和痛点
- 局部试点:选择一个模块用LangGraph重构
- 渐进替换:逐步将复杂部分迁移到LangGraph
- 系统整合:最终形成混合架构或完全迁移
总结
LangChain生态系统为开发者提供了从简单到复杂的完整解决方案:
- LangChain:成熟稳定,适合快速开发和学习
- LangGraph:功能强大,适合复杂系统和高级需求
选择时应根据项目需求、团队能力和维护成本综合考虑。对于大多数项目,建议从LangChain开始,在需要时逐步引入LangGraph的高级功能。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 20
20 0
0- 0



 已为社区贡献62条内容
已为社区贡献62条内容

所有评论(0)