LazyLLM 第二讲:构建轻松构建基于本地知识库的RAG应用
LazyLLM构建轻松构建基于本地知识库的RAG应用
商汤科技大装置事业群 算法工程师 陈嘉豪
直播预约:https://live.csdn.net/room/csdnnews/8MJt5x2v
活动介绍
看到最后有福利,点击立即报名

1. RAG 介绍
基本概念
Retrieval‑Augmented Generation(检索增强生成),简称 RAG,是一种将大型语言模型(LLM)与外部检索系统相结合的生成式 AI 架构。其主要流程是:在生成回答之前,先从外部知识库(如文档库、数据库或互联网)检索相关信息,再将这些检索到的内容与用户提示共同输入给 LLM,进而生成更加准确、上下文相关的答案。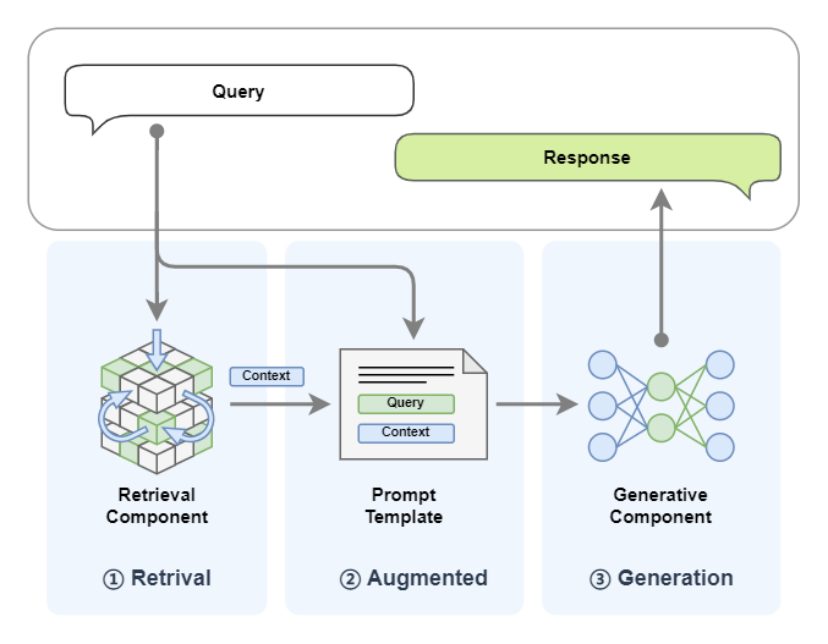
- 不重新训练模型
- LLM 与外部检索系统相结合
- 实时的、领域相关的信息源,生成更可靠
必要性
- 幻觉(Hallucination)
- 看似合理但实际上没有根据 – 不真实
- 其出现原因包括参数猜测机制、策略瑕疵、上下文缺失等
- RAG: 将检索到的真实信息作为生成基础,补充可信源,从而显著减少幻觉。
注意:幻觉只能减少,不可避免
- 无足够算力
- 训练或微调模型通常需要大量计算资源
- RAG 架构中核心 LLM 不需频繁更新,仅靠更新知识库即可保持信息时效性,极大降低计算负担
大规模微调所需数据成本高且知识比例难以调配。 RAG 则通过动态调用外部信息,无需大规模微调即可获得领域知识,具有显著的资源优势。
利用外部知识库替代再训练,使系统的知识持续可更新并具针对性,也更经济灵活。
技术原理
通过前面的学习,我们了解到RAG技术主要可以分为两个阶段——知识入库与在线问答
- 知识入库:通过上传文档、处理文档的方式将文档转化为“知识”,并存储。也称作“离线阶段”。
- 在线问答:通过检索有效知识、组装输入的方式形成最终的模型输入,让模型回答有理有据。也称作“在线阶段”
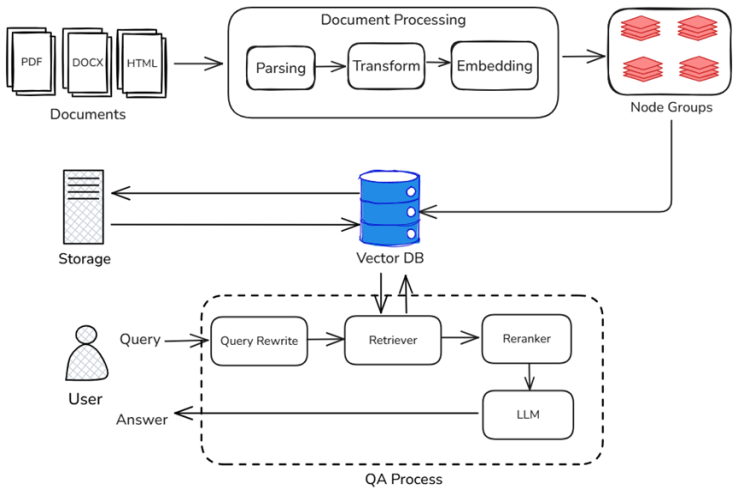
离线解析阶段
为了让 RAG 在线阶段能够顺利运作,前期需要对各种数据进行处理,这其中文档的读取与解析至关重要。在收集数据时,会从各类来源(如文档、数据库、API、网页等)收集大量数据,以此构建丰富的知识库。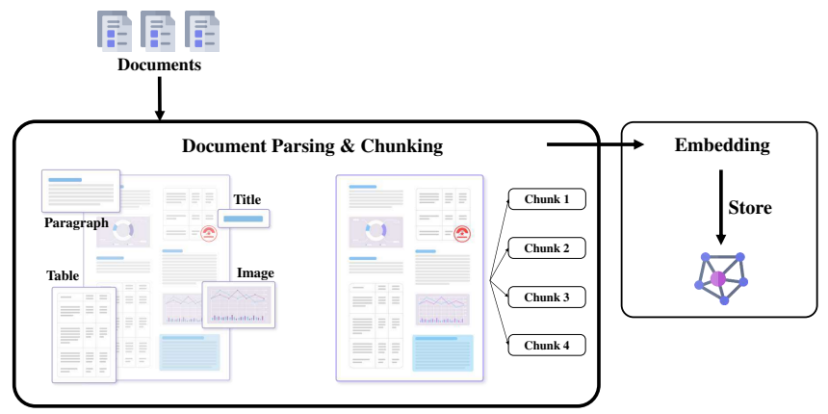
- 文本切片
- 文档过长时系统处理的效率也会降低
- 将文档切分为多个子段落
- 易于在特定查询中返回准确的结果
- 常用策略:固定大小分块、递归分块、语义分块、基于文档结构分块


- 向量化
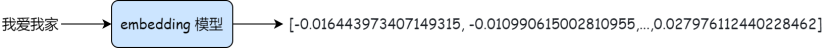
- 简单来说就是使用Embedding模型将切片转换为在一定程度上保留文本的上下文信息的固定维度的**多维向量**
- 本质是将信息映射到高维语义空间,向量之间的距离或角度可以反映文本之间的**语义相似度**
- 即使两个句子使用不同的词汇,但如果它们表达相似的意思,它们在嵌入空间中的距离会很近
使用Embedding进行向量检索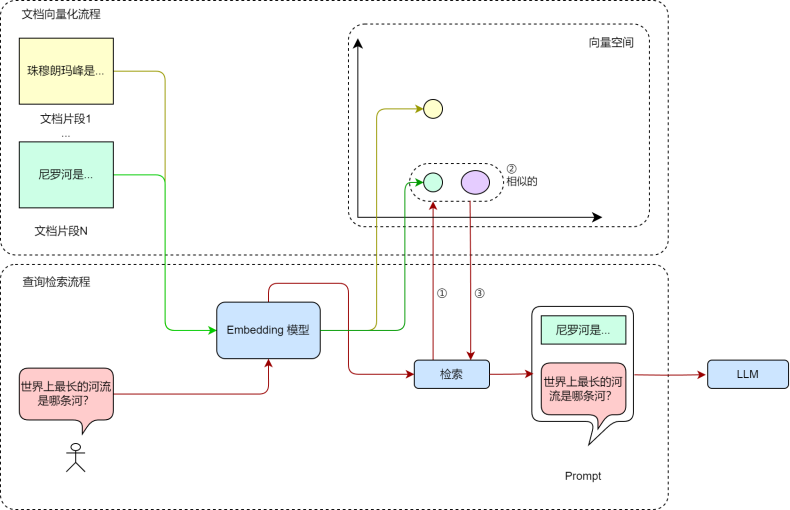
距离度量函数
常见相似度计算有:余弦相似度(cosine similarity),点积(dot product),以及欧氏距离等。
索引构建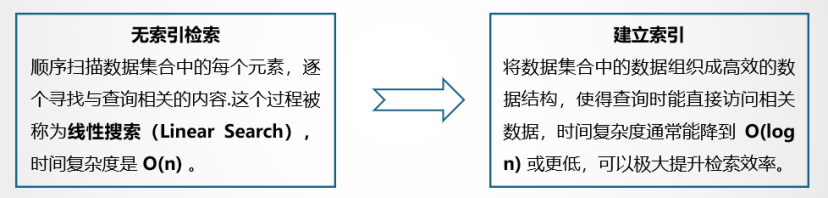
- 通过预先组织数据的结构,使检索器能够高效定位和检索相关信息
- 索引就像是书籍中的目录,它帮助快速定位特定信息,避免逐页查找
- 对向量数据构建的是向量索引,通常使用ANN算法
- 常用的向量索引(如IVF、HNSW)在大多数向量数据库中支持
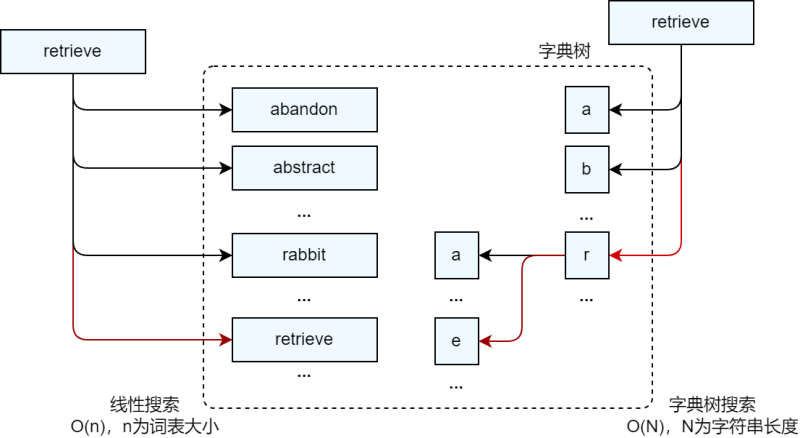
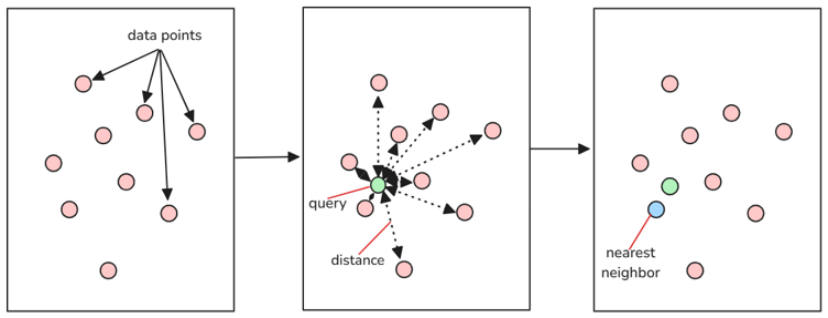
在线问答阶段
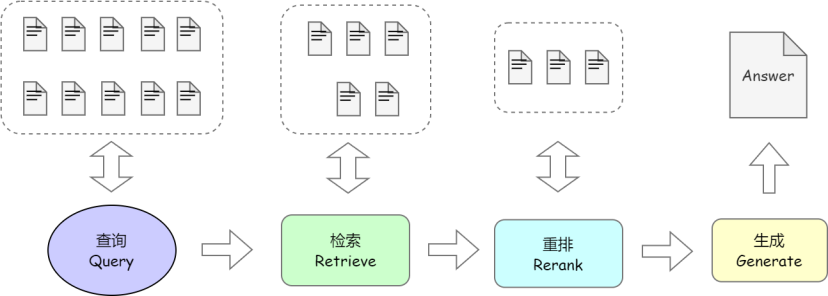
Query检索(Retrival)
用户输入问题后,系统会基于该输入在外部知识库中检索相关内容。
- 常用检索算法:
- 关键词检索(BM25)
- 语义向量检索(向量相似度)
增强(Augmented)
- 检索内容作为额外上下文,与用户输入一起提供给大模型
- 这一阶段涉及 Prompt 设计
- 指令遵循
- 消除歧义
- 引用段落
生成(Generatation)
大模型结合检索到的信息和自身的预训练知识,生成最终的回答。
相比单纯依赖大模型,RAG
结合“检索+生成”,利用向量数据库高效召回知识,并通过大模型生成答案,从而降低幻觉风险,增强知识时效性,并减少微调需求,提升模型的适应能力。
2.组件介绍
Document
RAG的核心是从文档集合进行文档检索,集合内的文档格式各异,针对这些不同格式的文档,我们需要特定的解析器来提取其中有用的文本、图片、表格、音频和视频等内容。
在 LazyLLM 中,文档集合被抽象为Document类,其支持传入不同的文件/文件路径集合、选择多种向量模型及存储类型,并提供高效的方法注册不同格式的解析器(Reader)、创建不同类型的“节点组”,以生成我们想要的切片种类。
目前 LazyLLM 内置的 Document可以支持 DOCX,PDF,PPT,EXCEL 等常见格式的解析与提取,您也可以自定义 Reader 读取特定格式的文档(在后续的教程中我们会进行详细介绍)。
Document的主要参数如下:
-
dataset_path (str) – 数据集目录的路径。此目录应包含要由文档模块管理的文档(注意:暂不支持指定单个文件)。
-
embed (Optional[Union[Callable, Dict[str, Callable]]], default: None ) – 用于生成文档 embedding 的对象。如果需要对文本生成多个 embedding,此处需要通过字典的方式指定多个 embedding 模型,key 标识 embedding 对应的名字, value 为对应的 embedding 模型。
-
manager (bool, default: False ) – 指示是否为文档模块创建用户界面的标志。默认为 False。
-
launcher (optional, default: None ) – 负责启动服务器模块的对象或函数。如果未提供,则使用 lazyllm.launchers 中的默认异步启动器 (sync=False)。
-
store_conf (optional, default: None ) – 配置使用哪种存储后端
-
doc_fields (optional, default: None ) – 配置需要存储和检索的字段及对应的类型
Document基础使用方法:只需要传入数据集目录的路径即可:
Python
# RAG 文档读取
from lazyllm import Document
# 传入绝对路径
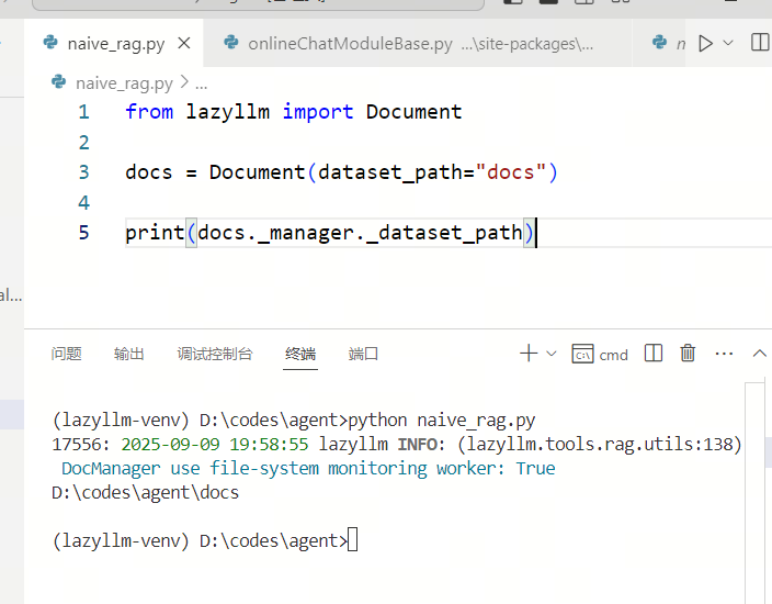
doc = Document("path/to/content/docs/")
print(f"实际传入路径为:{doc._manager._dataset_path}")
# 传入相对路径
doc = Document("/content/docs/")
print(f"实际传入路径为:{doc._manager._dataset_path}")
注意,在此处传入绝对路径,或者是以当前目录为基础的相对路径
Embedding
Embedding介绍:
LazyLLM 支持调用线上和线下 Embedding 模型,其中线上模型通过 OnlineEmbeddingModule调用,线下模型通过 TrainableModule调用。
Embedding的主要参数如下:
OnlineEmbeddingModule 用来管理创建市面主流的在线Embedding服务模块,可配置参数有:
source (str)– 指定要创建的模块类型,可选为 openai / sensenova / glm / qwen / doubaoembed_url (str)– 指定要访问的平台的基础链接,默认是官方链接embed_model_name (str)– 指定要访问的模型,默认值为 text-embedding-ada-002(openai) / nova-embedding-stable(sensenova) / embedding-2(glm) / text-embedding-v1(qwen) / doubao-embedding-text-240715(doubao)
在线 embedding 模型提供的 embedding 模型需要在指定厂商的模型列表进行查找,如果没有特定需求,可以直接使用LazyLLM OnlineEmbeddingModule
提供的默认模型。
Embedding基础使用方法:
下面是使用LazyLLM调用在线Embedding模型和启动本地服务并调用的示例代码:
这里我们使用sensenova的Embedding模型
运行前需要先导入api_key:export LAZYLLM_SENSENOVA_API_KEY="sk-<你自己的api_key>"
from lazyllm import OnlineEmbeddingModule
online_embed = OnlineEmbeddingModule("sensenova")
print("online embed: ", online_embed("hello world"))
上述代码输出应当为:
online embed: [-3.85302734375, 4.352343559265137, 1.0450439453125…0.842041015625]
注:不同模型生成的 Embedding 有所差异是正常的。
为 Document 指定 Embedding 的方法如下所示:
import lazyllm
# 定义嵌入模型
online_embed = lazyllm.OnlineEmbeddingModule()
# 加载文档
documents = lazyllm.Document('/path/to/your/document', embed=online_embed)
Retriever
Retriever介绍:
LazyLLM 中执行检索功能的是 Retriever 组件, Retriever 组件可以创建一个用于文档查询和检索的检索模块。此构造函数将会初始化一个检索模块,该模块根据指定的向量模型/相似度度量配置文档检索功能。
Retriever的主要参数如下:
doc (object)– 文档模块实例,可以是单个实例,也可以是一个实例的列表。如果是单个实例,表示对单个Document进行检索,如果是实例的列表,则表示对多个Document进行检索。group_name (str)– 在哪个 node group 上进行检索。(lazyllm_root,
group_name 有三种内置切分策略,都是用 SentenceSplitter 切分,区别在于块大小不同:- CoarseChunk: 块大小为 1024,重合长度为 100
- MediumChunk: 块大小为 256,重合长度为 25
- FineChunk: 块大小为 128,重合长度为 12
similarity (Optional[str], default: None )– 用于设置文档检索的相似度函数。候选集包括 [“bm25”, “bm25_chinese”, “cosine”]similarity_cut_off (Union[float, Dict[str, float]], default: float('-inf') )– 当相似度低于指定值时丢弃该召回节点。在多 embedding 场景下,如果需要对不同的 embedding 指定不同的值,则需要使用字典的方式指定,key 表示指定的是哪个 embedding,value 表示相应的阈值。如果所有的 embedding 使用同一个阈值,则只指定一个数值即可。index (str, default: 'default' )– 用于文档检索的索引类型。目前仅支持 ‘default’。
-topk (int, default: 6 )– 表示取相似度最高的多少篇文档。embed_keys (Optional[List[str]], default: None )– 表示通过哪些 embedding 做检索,不指定表示用全部 embedding 进行检索。similarity_kw– 传递给 similarity 计算函数的其它参数。
Retriever的基础使用方法:
下面这行代码声明检索组件需要在 doc 这个文档中的 Coarse chunk 节点组利用 bm25相似度进行检索,最终返回相似度最高的 3 个节点。
from lazyllm import Retriever, Document
# 传入绝对路径
doc = Document("/path/to/content/docs/")
# 使用Retriever组件,传入文档doc,节点组名称这里采用内置切分策略"CoarseChunk",相似度计算函数bm25_Chinese
retriever = Retriever(doc, group_name='CoarseChunk', similarity="bm25", topk=3)
# 调用retriever组件,传入query
retriever_result = retriever("your query")
# 打印结果,用get_content()方法打印具体的内容
print(retriever_result[0].get_content())
效果演示
同时,你也可以准备一些自己的文档集(docx、pdf为主),尝试建立属于自己的知识库问答系统。
现在我们已经介绍了LazyLLM中最常用的三个RAG 组件,以及准备好了知识库,接下来就让我们实现最简单的RAG吧!
将这三个组件的使用串联在一起,我们就得到了最简单的RAG,代码如下:
使用第一次开通的DeepSeek-V3-1作为chat模型,使用qwen的text-embedding-v4作为embedding模型
Ps:运行下面代码前需要导入api_key
import lazyllm
from lazyllm import Retriever, Document, OnlineEmbeddingModule
embed_model = OnlineEmbeddingModule(source="sensenova")
doc = Document(dataset_path="docs", embed=embed_model)
retriever = Retriever(doc, group_name='CoarseChunk', similarity="cosine", topk=3)
llm = lazyllm.OnlineChatModule(source="sensenova",model="SenseChat-5")
# prompt 设计
prompt = 'You will act as an AI question-answering assistant and complete a dialogue task. In this task, you need to provide your answers based on the given context and questions.'
llm.prompt(lazyllm.ChatPrompter(instruction=prompt, extra_keys=['context_str']))
query = "介绍一下LightRAG"
# 将Retriever组件召回的节点全部存储到列表doc_node_list中
doc_node_list = retriever(query=query)
# 将query和召回节点中的内容组成dict,作为大模型的输入
res = llm({"query": query, "context_str": "".join([node.get_content() for node in doc_node_list])})
print(f'With RAG Answer: {res}')
没有配备RAG系统时的LLM回答:
配备了RAG系统后的回答:
Ps:如果出现如下的问题,是因为 embedding API请求频率限制的问题,可以尝试减少文件的数量和大小(这里只使用了LightRAG一篇论文进行功能演示)。{"code":"Throttling.RateQuota","message":"Requests rate limit exceeded, please try again later.","request_id":"484cccf3-f240-4adc-a3e9-f855be204c46"}
3. agentic rag实现
在我们第一天实现的ReactAgent的基础上,将它的工具替换为 RAG 中的 Retriever ,让它可以调用检索器。那么我们就会得到一个最基础的agentic rag实现。
import lazyllm
from lazyllm import (
fc_register, Document, Retriever,
OnlineEmbeddingModule, OnlineChatModule, WebModule,
ReactAgent
)
embed_model = OnlineEmbeddingModule(source="sensenova")
doc = Document(dataset_path="docs", embed=embed_model)
retriever = Retriever(doc, group_name='CoarseChunk', similarity="cosine", topk=3)
# 注册RAG工具
@fc_register("tool")
def search_knowledge_base(query: str):
"""
搜索知识库并返回相关文档内容
Args:
query (str): 搜索查询字符串
"""
# 将Retriever组件召回的节点全部存储到列表doc_node_list中
doc_node_list = retriever(query=query)
# 将召回节点中的内容组合成字符串
context_str = "".join([node.get_content() for node in doc_node_list])
return context_str
# prompt 设计
prompt = 'You will act as an AI question-answering assistant and complete a dialogue task. In this task, you need to provide your answers based on the given context and questions. You can use the search_knowledge_base tool to find relevant information from the knowledge base.'
# 创建ReactAgent
agent = ReactAgent(
llm=OnlineChatModule(source='sensenova', model="SenseChat-5", stream=False),
tools=['search_knowledge_base'],
prompt=prompt,
stream=False
)
# 创建Web模块并启动
w = WebModule(agent, stream=False)
w.start().wait()
我们还是进行相同的提问"讲解一下LightRAG",通过结果可以看到,结合上React Agent的RAG,可以给予更加智能和丰富的回答和交互体验。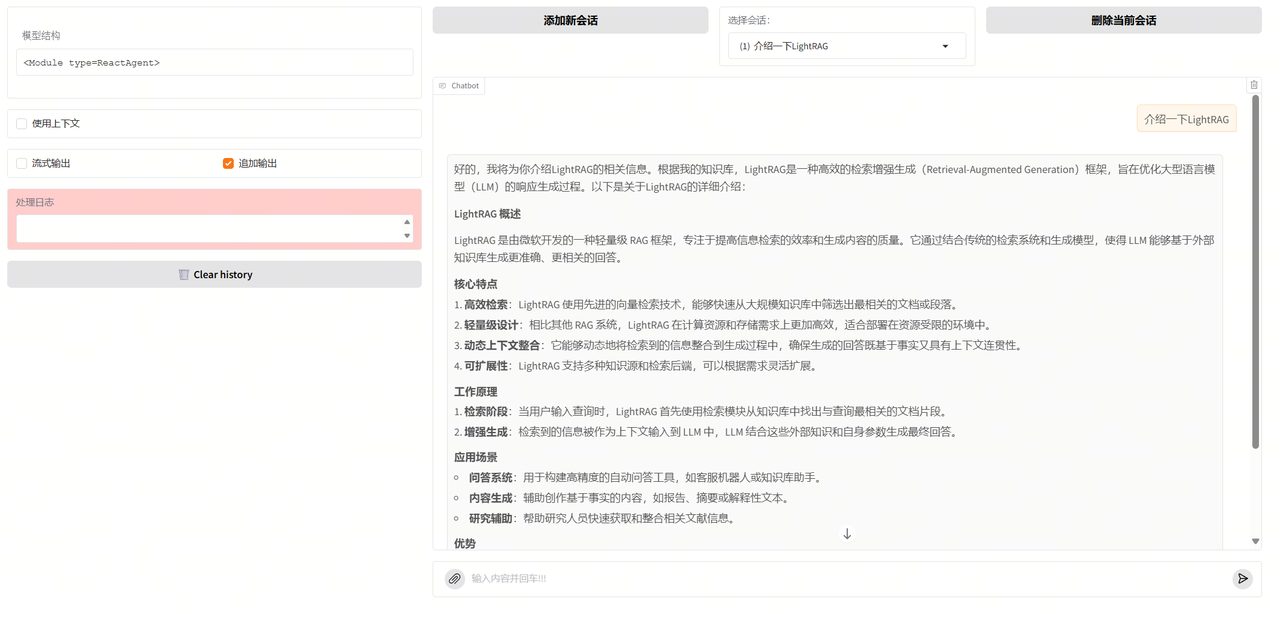
使用更开放一些的query,例如"总结提炼一下LightRAG的创新点,以及可能得到的启发",可以看到回答结果有着不错的效果。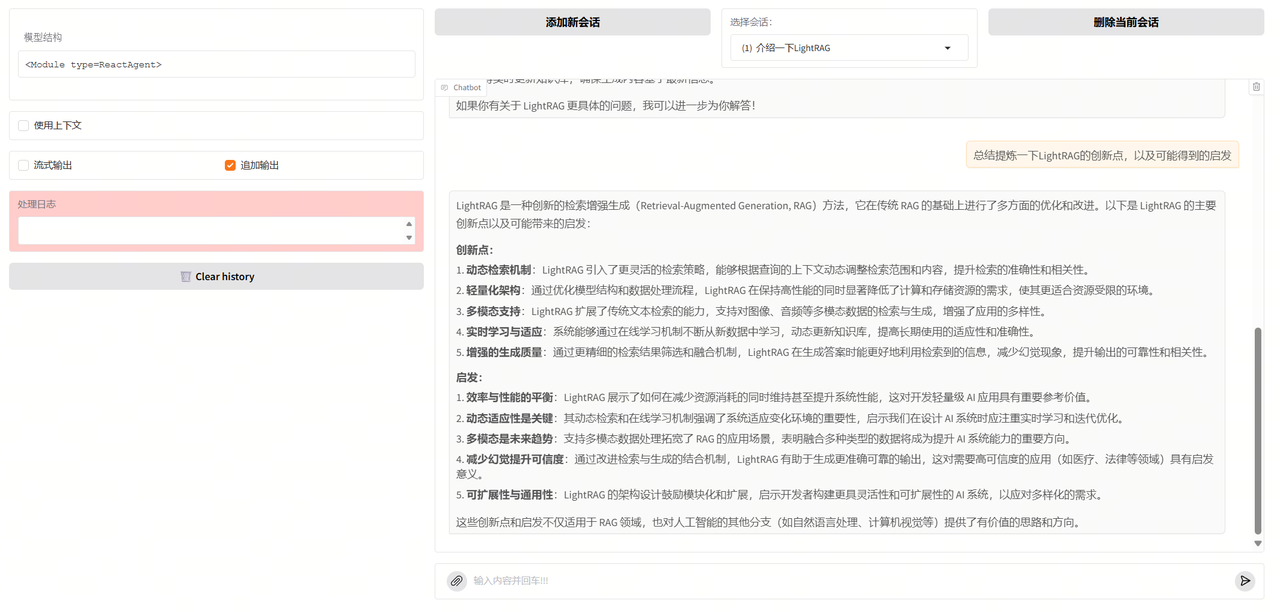
4. RAG优化策略
优化策略介绍
- 优化切片策略
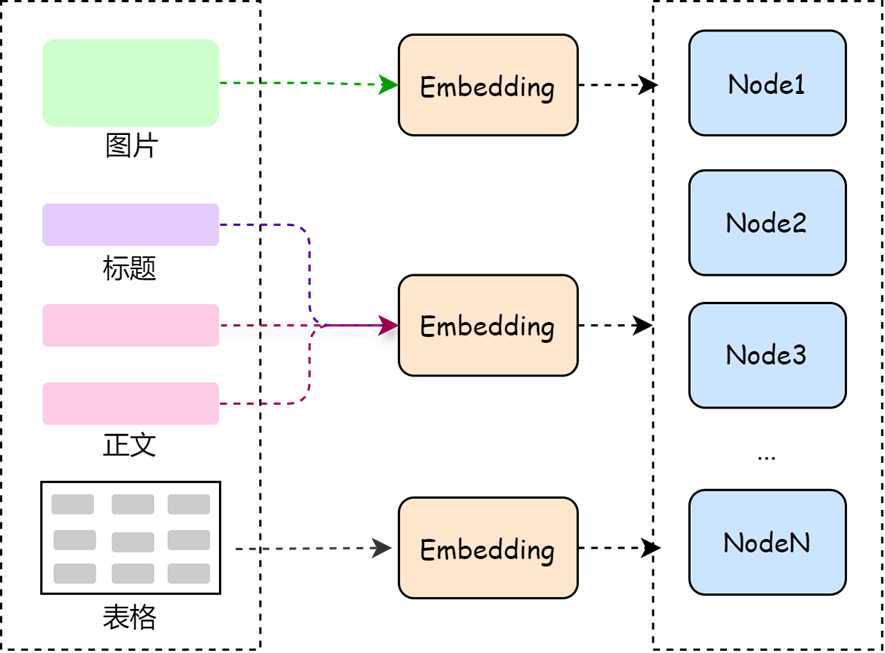
- 含义:合理的分块/信息提取等策略,将长文本拆解为更具针对性的片段
- 作用:更精准地匹配查询内容,从而提高相关信息的召回率和检索质量
“小块召回、大块生成” 是一种常见且高效的策略。其核心思想是:
- 小块召回:小块用于高精度召回文档先按较小粒度进行切分(如按段落、句子),每个小块携带更精细的语义信息,便于精准计算与用户查询的相似度。检索阶段只对小块向量进行相似度比对,从而更容易找到与用户查询语义接近的内容。
- 大块召回:大块用于上下文生成一旦某个小块被成功召回,系统会找到该小块所属的大块(如一整节内容或完整子话题),将其作为上下文提供给大模型,用于生成更完整、更连贯的回答。这样做的好处是:避免小块信息太碎,大模型理解困难;同时减少将所有大块入库所带来的计算和存储成本。
query重写
- 为什么需要query重写?
- 用户查询常常信息不足或存在歧义,影响检索效果。
- 查询扩写通过同义词补充、上下文补全、模板转换等方式,使查询更清晰具体,从而提升准确率和召回率。
- 如何进行query重写?
- 使用pipeline,在接收到query后,调用一个定义好prompt的llm进行改写
- 其中ChatPrompter 是一个专门用于聊天场景的提示器,能够将用户输入、系统指令、历史对话等元素组织成符合特定格式的提示模板,便于与大型语言模型进行交互。
多路召回重排
召回重排:
- 召回:经初步检索得到一组文档切片(从海量切片中找,范围较广,精度略低)
- 重排:通过一个额外模型对召回结果进行再次排序以提高最终的效果(更大的模型,小范围精排过滤)
已经召回了,为什么还要进行重排序呢?
- 基于向量相似度计算,信息压缩大量的信息丢失
- 其次基于词频等简单特征的 BM25 等传统方法在捕捉深层语义和上下文方面的能力有限
- 重排序模型往往是一个体量比嵌入模型更大的模型,通过一个完整的Transformer推理步骤,针对查询和文档生成一个相似度分数,相比于计算cosine等相似度具有更高的准确度。
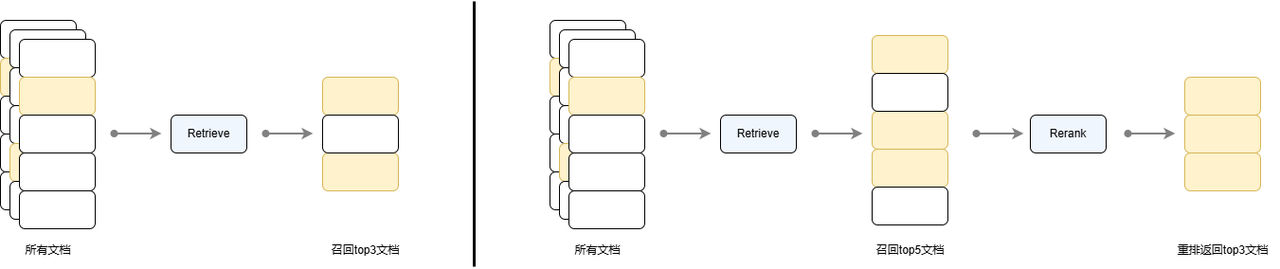
- Retriever 主要负责高效筛选,从海量文档中快速提取与查询相关的候选文档,常见的方法包括语义检索和例如 BM25 的稀疏向量检索。
- Reranker 对初步召回的文档进行更精准的筛选,对召回的文档集合进行更细粒度的语义分析,并重新计算相似度得分。常用基于 Transformer 的排序模型(如 bge-reranker-large、bge-reranker-base)进行重排序步骤,针对查询和文档生成一个相似度分数,能够捕捉更复杂的语义信息,提高最终检索效果,但计算成本较高。
- 两者结合形成“广撒网 + 精筛选”的漏斗式结构,以平衡效率与效果。
多路召回RAG:
传统的单一检索策略可能会遗漏部分关键信息,而多路召回 RAG 通过整合多种检索方式,可以提升检索召回率,从而优化最终的生成效果。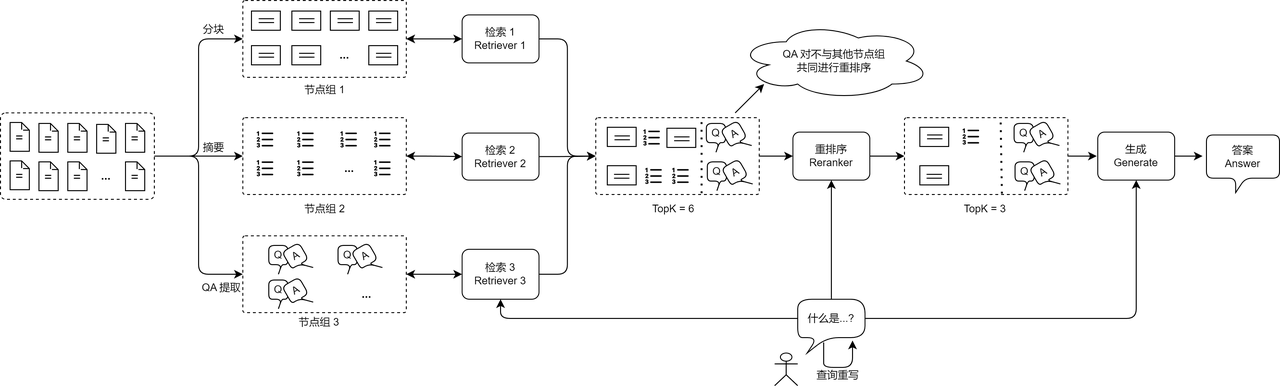
不同维度实现多路召回:
- 重写用户查询:针对用户查询,进行同义词替换、历史内容补充、或生成多个子查询,使检索器可以针对不同维度的内容进行检索。
例如当用户查询:“2023 年 AI 生成内容的主要挑战是什么?”可能的子查询有“2023 年 AI 生成内容的技术限制有哪些?”、“2023 年 AI 生成内容在法规和伦理方面的挑战?”、“2023 年 AI 生成内容的商业应用困难?” - 检索多个节点组:使用多个检索器查询不同数据来源或不同的知识粒度可以有效召回相关文档。这种方式允许 RAG 查询不同粒度的信息,多维度搜索与用户查询强相关的文档片段。
- 使用多种检索策略:使用不同的相似度函数或多种向量嵌入方法可以最大化现有检索技术的优势。如稠密向量与稀疏向量混合使用。
多路召回和重排实现
Parallel:Parallel支持我们并行调用多个pipeline,其数据流示意如下:
/> module11 -> ... -> module1N -> out1 \
input -> module21 -> ... -> module2N -> out2 -> (out1, out2, out3)
\> module31 -> ... -> module3N -> out3 /
Parallel支持对输出格式进行格式化处理,方便下游组件进行针对性使用,目前Parallel支持输出字典、元组、列表和字符串形式的输出,具体效果可见下方例子:
函数式
import lazyllm
test1 = lambda a: a + 1
test2 = lambda a: a * 4
test3 = lambda a: a / 2
prl1 = lazyllm.parallel(test1, test2, test3)
prl2 = lazyllm.parallel(path1=test1, path2=test2, path3=test3).asdict
prl3 = lazyllm.parallel(test1, test2, test3).astuple
prl4 = lazyllm.parallel(test1, test2, test3).aslist
prl5 = lazyllm.parallel(test1, test2, test3).join(',')
print("默认输出:prl1(1) -> ", prl1(1), type(prl1(1)))
print("输出字典:prl2(1) -> ", prl2(1), type(prl2(1)))
print("输出元组:prl3(1) -> ", prl3(1), type(prl3(1)))
print("输出列表:prl4(1) -> ", prl4(1), type(prl4(1)))
print("输出字符串:prl5(1) -> ", prl5(1), type(prl5(1)))
输出
输出字典:prl2(1) -> {'path1': 2, 'path2': 4, 'path3': 0.5} <class 'dict'>
输出元组:prl3(1) -> (2, 4, 0.5) <class 'tuple'>
输出列表:prl4(1) -> [2, 4, 0.5] <class 'list'>
输出字符串:prl5(1) -> 2,4,0.5 <class 'str'>
with 式
import lazyllm
test1 = lambda a: a + 1
test2 = lambda a: a * 4
test3 = lambda a: a / 2
with lazyllm.parallel() as prl1:
prl1.func1 = test1
prl1.func2 = test2
prl1.func3 = test3
with lazyllm.parallel().asdict as prl2:
prl2.path1 = test1
prl2.path2 = test2
prl2.path3 = test3
with lazyllm.parallel().astuple as prl3:
prl3.func1 = test1
prl3.func2 = test2
prl3.func3 = test3
with lazyllm.parallel().aslist as prl4:
prl4.func1 = test1
prl4.func2 = test2
prl4.func3 = test3
with lazyllm.parallel().join(',') as prl5:
prl5.func1 = test1
prl5.func2 = test2
prl5.func3 = test3
print("默认输出:prl1(1) -> ", prl1(1), type(prl1(1)))
print("输出字典:prl2(1) -> ", prl2(1), type(prl2(1)))
print("输出元组:prl3(1) -> ", prl3(1), type(prl3(1)))
print("输出列表:prl4(1) -> ", prl4(1), type(prl4(1)))
print("输出字符串:prl5(1) -> ", prl5(1), type(prl5(1)))
输出
默认输出:prl1(1) -> (2, 4, 0.5) <class 'lazyllm.common.common.package'>
输出字典:prl2(1) -> {'path1': 2, 'path2': 4, 'path3': 0.5} <class 'dict'>
输出元组:prl3(1) -> (2, 4, 0.5) <class 'tuple'>
输出列表:prl4(1) -> [2, 4, 0.5] <class 'list'>
输出字符串:prl5(1) -> 2,4,0.5 <class 'str'>
当我们进行知识的分片与检索时,如果长度过大,向量模型往往比较有压力(将密集知识的映射至同一维度),长度过小,检索到的知识不足以让大模型理解完整的上下文。怎么办呢?
不妨这样做:
- 先粗粒度切分文档,随后细粒度再切一份(同时建立父子关系)
- 召回时先召回细粒度切片
- 随后向上寻找父节点
- 把父节点传入大模型,让其大模型获取更多知识
从而实现“精准检索,全面回答”
- 创建多粒度节点组:
doc.create_node_group(name="block", transform=SentenceSplitter, chunk_size=1024, chunk_overlap=100)
doc.create_node_group(name="line", transform=SentenceSplitter, chunk_size=128, chunk_overlap=20, parent="block")
- 检索时,对应的修改retriever的参数:
ppl.retriever = Retriever(doc, group_name='line', similarity="cosine", topk=6, output_format='content', target='block')
这样就可以实现:检索小块,实际返回的是父级的大块。
多路召回与精排器 - Reranker前面我们了解到,通过使用多路召回与重排器,可以在更广的搜索后实现更精准的知识筛选。
LazyLLM 提供了 Reranker 组件进行重排序,分别提供了在线和离线两种重排序模型的调用途径,其中在线模型通过OnlineEmbeddingModule(type=“rerank”) 进行调用。使用 Reranker 时的可调整参数有:
name(str, default: ‘ModuleReranker’ ) : 实现重排序时必须为 ModuleRerankermodel(Union[Callable, str]) : 实现重排序的具体模型名称或可调用对象- Callable 情形:
- OnlineEmbeddingModule (type=“rerank”):目前支持qwen和glm的在线重排序模型,使用前需要指定 apikey
- TrainableModule(model=“str”):需要传入本地模型名称,常用的开源重排序模型为bge-reranker系列
- str 情形:模型名称,与上 Callable 情形 TrainableModule 对应的 model 参数要求相同
- Callable 情形:
topk(int): 最终需要返回的 k 个节点数- output_format(str, default: None):输出格式,默认为None,可选值有 ‘content’ 和 ‘dict’,其中 content 对应输出格式为字符串,dict 对应字典
- join(boolean, default: False):是否联合输出的 k 个节点,当输出格式为 content 时,如果设置该值为 True,则输出一个长字符串,如果设置为 False 则输出一个字符串列表,其中每个字符串对应每个节点的文本内容。
下面我们通过OnlineEmbeddingModule(type=“rerank”)进行调用:
下面我们通过OnlineEmbeddingModule(type=“rerank”)进行调用:
from lazyllm import OnlineEmbeddingModule,Reranker
# 目前 LazyLLM 支持 qwen和glm 在线重排模型,使用前请指定相应的 API key。
online_rerank = OnlineEmbeddingModule(source='qwen', stream=False, model='text-embedding-v4',type="rerank")
reranker = Reranker('ModuleReranker', model=online_rerank, topk=3)
下面我们实现一个例子,对上述block和line节点组检索的 10 条结果取精排后的 top 6 文档。
with pipeline() as ppl:
with lazyllm.parallel().sum as ppl.prl:
prl.r1 = Retriever(doc, group_name='line', similarity="cosine", topk=6, target='block')
prl.r2 = Retriever(doc, group_name='block', similarity="cosine", topk=6)
ppl.reranker = Reranker('ModuleReranker', model=rerank_model, output_format='content',
join=True) | bind(query=ppl.input)
ppl.formatter = (lambda context, query: dict(context_str=str(context), query=query)) | bind(query=ppl.input)
ppl.llm = OnlineChatModule(source='sensenova', stream=False,model="DeepSeek-V3-1").prompt(lazyllm.ChatPrompter(prompt, extra_keys=["context_str"]))
ppl.start()
领取奖励
看到这里的同学相信已经完成了 LazyLLM 的 RAG 体验
福利时间到!
领取快速部署奖 点击提交使用 LazyLLM 的使用截图,10 月 25 日前,前 500 名完成的同学获得 B 站大会员月卡一张(2 周内小助手通过邮箱发放)
领取应用实践奖
点击 提交基于 LazyLLM 的创意作品(例如:日志分析、运维助手、科研助手 etc.),前 35 名可以获得200 元京东 E 卡。
应用实践奖 提交需要包含以下两项内容:
1.开源代码仓库
要求:作品必须是基于 LazyLLM 框架的原创应用或项目案例。
平台:将项目完整代码上传至任一公开的代码托管平台(如 GitHub、GitCode 等)。
2.CSDN 博客文章
要求:在 CSDN 博客平台发布一篇图文并茂的技术文章,详细介绍您的作品。
内容应包含:
项目简介:清晰说明项目的背景、目标和核心功能。
实现步骤:分步讲解应用的构建过程和技术细节。
核心代码:展示关键代码片段并附上必要解释。
效果展示:通过截图、GIF 或视频等形式直观展示项目成果。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 17
17 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)