arXiv 2025 | 性能SOTA!苹果发布统一多模态大模型Manzano,实现理解与生成双优!
本文的研究目标是解决统一多模态模型中图像理解与生成能力之间的性能冲突。具体问题是,现有的视觉分词策略(连续嵌入用于理解,离散令牌用于生成)导致LLM内部产生任务冲突,影响模型整体性能。为解决此问题,论文提出了 Manzano 模型,其核心技术贡献是设计了一个混合图像分词器。该分词器使用一个共享的视觉编码器,派生出两个适配器:一个连续适配器为理解任务生成连续嵌入,一个离散适配器为生成任务提供离散令牌
本文提出了一种名为 Manzano 的简单且可扩展的统一多模态大语言模型 (Multimodal Large Language Models, MLLMs) 框架,旨在解决现有模型在集成图像理解与生成能力时普遍存在的性能冲突问题。
当前模型的挑战在于,图像理解任务偏好连续的视觉嵌入,而自回归生成任务则需要离散的视觉令牌,这种不一致性导致了任务冲突。Manzano 通过引入一个创新的混合图像分词器 (hybrid image tokenizer) 来应对这一挑战。该分词器基于一个共享的视觉编码器,通过两个轻量级适配器分别产出用于理解的连续嵌入和用于生成的离散令牌,两者源于同一语义空间,从而显著缓解了任务间的紧张关系。整个框架由一个统一的自回归LLM负责预测高层语义(文本和图像令牌),并由一个辅助的扩散解码器 (diffusion decoder) 将图像令牌渲染为像素。结合精心设计的三阶段统一训练流程,Manzano 在不牺牲理解能力的前提下,实现了强大的图像生成,并在多个基准测试中取得了统一模型中的最佳性能,尤其在富文本理解任务上表现突出,验证了该架构在平衡两种能力上的有效性。
另外,我整理了CV入门必读资料包+CVPR 2020-2025论文合集,感兴趣的可以dd,希望能帮到你!
一、论文基本信息

基本信息
- 论文标题:MANZANO: A Simple and Scalable Unified Multimodal Model with a Hybrid Vision Tokenizer
- 作者:Yanghao Li, Rui Qian, Bowen Pan, 等
- 作者单位:Apple
- 论文链接:https://arxiv.org/abs/2509.16197
摘要精炼

本文的研究目标是解决统一多模态模型中图像理解与生成能力之间的性能冲突。具体问题是,现有的视觉分词策略(连续嵌入用于理解,离散令牌用于生成)导致LLM内部产生任务冲突,影响模型整体性能。
为解决此问题,论文提出了 Manzano 模型,其核心技术贡献是设计了一个混合图像分词器。该分词器使用一个共享的视觉编码器,派生出两个适配器:一个连续适配器为理解任务生成连续嵌入,一个离散适配器为生成任务提供离散令牌。由于两者源于同一语义空间,极大地缓解了LLM在处理视觉信息时的冲突。模型采用统一的自回归LLM预测文本和图像令牌,再由一个辅助的扩散解码器完成图像渲染。
关键结论是,Manzano 框架不仅在统一模型中达到了SOTA性能,在富文本理解等任务上可与专业模型媲美,并且展现出良好的模型尺寸扩展性,证明了其架构设计的有效性。
二、研究背景与相关工作
研究背景
统一多模态模型,即同时具备理解和生成视觉内容能力的模型,是当前人工智能领域的研究热点。这类模型被认为可以解锁更高级的涌现能力,如复杂推理、多模态指令遵循和迭代式视觉编辑。然而,现有技术普遍面临一个核心痛点:在模型中加入图像生成能力往往会显著降低其图像理解的性能,特别是在需要精确感知的富文本(如文档、图表)基准测试上,统一模型与纯理解模型的性能差距尤为明显。这种性能权衡的瓶颈主要源于视觉表征的冲突,成为了阻碍统一多模态模型发展的关键挑战。
相关工作
针对统一多模态模型中理解与生成的冲突,现有工作主要分为两类。
第一类是双分词器策略,即为理解任务使用一个语义编码器(如CLIP)生成连续特征,同时为生成任务使用另一个独立的量化分词器(如VQ-VAE)产生离散令牌。这种方法的局限性在于,LLM被迫处理两种来源和性质迥异的视觉令牌(高层语义 vs. 底层空间),加剧了内部的任务冲突。
第二类是解耦LLM-扩散方法,即冻结一个预训练的MLLM用于理解,并将其输出连接到一个独立的扩散解码器用于生成。这种方法的局限性在于,生成过程与LLM解耦,无法从LLM的规模扩展中充分受益,也失去了两种能力相互促进的可能性。Manzano 正是为解决这些局限而提出的。
三、主要贡献与创新
-
提出创新的混合图像分词器:设计了一个共享视觉编码器驱动的双适配器结构,能够同时为理解任务生成连续嵌入,为生成任务提供离散令牌。由于两者共享同一语义空间,从根本上缓解了现有统一模型中的任务冲突。
-
构建简单且可扩展的统一模型架构:将高层语义预测(由LLM完成)与底层像素渲染(由扩散解码器完成)清晰解耦。这种简洁的设计不仅易于训练,还使得LLM和图像解码器可以独立扩展,展示了优越的扩展性。
-
设计高效的统一训练流程:提出了一个包含预训练、持续预训练和监督微调的三阶段训练方案,能够在一个统一的自回归目标下同时优化图像理解和生成能力,无需复杂的辅助损失或任务特定模块。
-
实现SOTA性能并验证有效性:实验证明,Manzano 在统一模型中取得了理解和生成任务的SOTA性能,尤其在富文本理解任务上超越了同类模型。消融实验和扩展性研究也证实,该框架有效解决了性能权衡问题,且模型性能随规模增大而稳定提升。
四、研究方法与原理
总体框架与核心思想
Manzano的核心设计哲学是“语义与渲染解耦” (Decoupling Semantics from Rendering)。它将复杂的视觉任务分解为两个层面:高层语义的理解与预测,以及底层像素细节的生成。
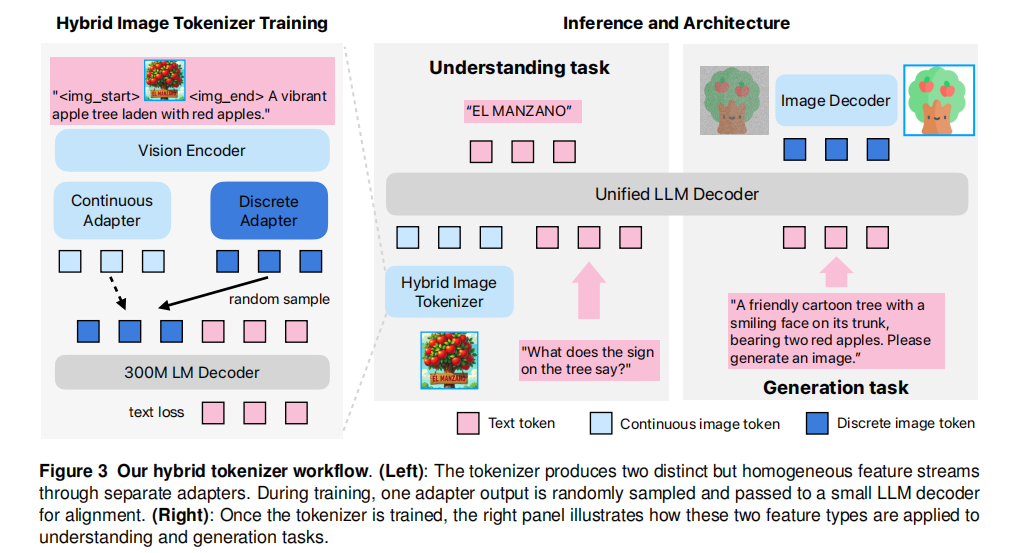
其总体框架由三个核心组件构成(如图3):
- 混合图像分词器:这是模型的核心创新。它包含一个共享的 ViT (Vision Transformer) 编码器,以及两个并行的轻量级适配器(连续适配器和离散适配器)。它负责将输入图像转化为LLM能够处理的、在统一语义空间中的连续或离散表示。
- 统一LLM解码器:这是一个标准的自回归语言模型。它接收文本令牌和/或来自连续适配器的图像嵌入,并以自回归的方式预测下一个文本令牌或离散图像令牌。它专注于学习高层面的语义逻辑。
- 图像解码器:这是一个基于扩散的模型(DiT-Air架构)。它接收由LLM生成的离散图像令牌序列作为条件,负责将这些高层语义表征渲染成高保真的图像像素。
通过这种方式,LLM得以摆脱繁重的像素级生成任务,专注于其擅长的语义推理,而专业的图像解码器则保证了生成质量。
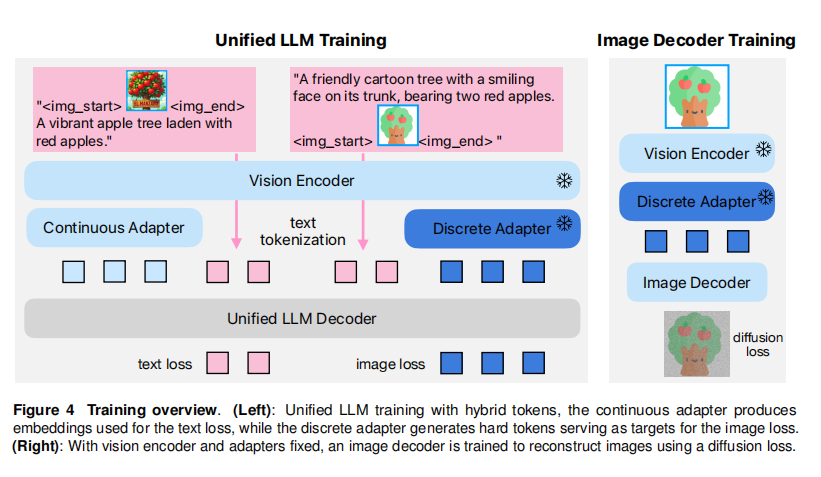
关键实现与评估原理
关键实现细节:
- 分词器细节:适配器使用了空间到通道 (Spatial-to-Channel, STC) 层来压缩空间令牌数量。离散适配器采用有限标量量化 (Finite Scalar Quantization, FSQ) 技术,其码本大小为64K,因其简单且易于扩展而备受青睐。
- 训练流程:分词器首先通过一个小型(300M)LLM进行预对齐训练。在统一LLM训练阶段,文本损失和图像损失的权重比被设置为 1:0.5,以平衡不同任务的学习。
- 图像解码器训练:采用了渐进式分辨率增长 (progressive resolution growing) 的策略,从256x256分辨率逐步微调至2048x2048,以高效生成高分辨率图像。
- 模型架构:图像解码器采用了 DiT-Air 架构,该架构通过层级参数共享,在保持性能的同时显著减小了模型大小。
核心评估原理与指标:
- 评估维度:评估分为图像理解和图像生成两大维度。
- 理解任务指标:
- 通用VQA:SEEDBench, RealWorldQA, MMBench
- 知识与推理:AI2D, ScienceQA, MMMU, MathVista
- 富文本理解:ChartQA, TextVQA, DocVQA, InfoVQA, OCRBench
- 生成任务指标:
- 自动化评估:GenEval(指令遵循), DPG(指令遵循), WISE(世界知识)
- 人工评估:在800个挑战性提示上,从结构完整性、指令遵循和审美质量三个维度进行打分。
五、实验结果与分析
实验设置
- 数据集: 训练数据混合了文本、图像理解和生成数据。其中,理解数据包括23亿图文对(如CC12M)和17亿交错图文文档;生成数据包含10亿内部图文对。
- 评估指标: 采用上文所述的图像理解(如MMMU, DocVQA)和生成(如GenEval, WISE, 人工评估)基准。
- 对比基线: 为验证核心贡献,论文设置了两种关键基线:
- 纯离散 (Pure-discrete): 理解和生成任务都使用离散令牌。
- 双编码器 (Dual-encoder): 理解使用语义编码器,生成使用独立的VAE风格编码器。
- 关键超参: FSQ量化码本大小为64K;训练中图像损失权重为0.5。
核心实验与结论
【指令】: 仅选择一项最能体现本文贡献的核心实验进行阐述。
- 实验目的:
该实验旨在验证本文提出的混合分词器策略相较于其他主流分词器范式(纯离散、双编码器)的优越性,并证明其能有效缓解理解与生成之间的任务冲突。
-
关键结果:
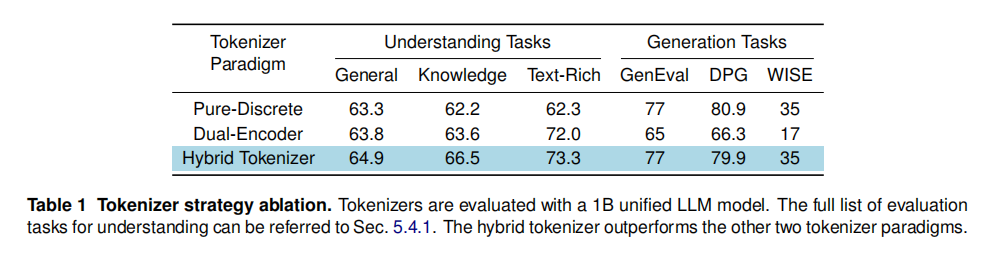
实验结果如表1所示。- 混合分词器 vs. 纯离散:与纯离散基线相比,混合分词器在所有理解任务上均取得显著优势,尤其在富文本(Text-Rich)类别上提升了4.3分。这表明离散化会损失关键视觉细节,影响理解性能。
- 混合分词器 vs. 双编码器:混合分词器在所有理解和生成基准上全面优于双编码器基线。特别是在知识型(Knowledge)理解任务上提升了2.9分,证明了统一语义空间能减少LLM内部的表示冲突,从而提升其推理能力。
- 在生成任务上,混合分词器也取得了最佳或并列最佳的成绩。
-
作者结论:
作者得出结论,混合分词器是解决统一模型中任务冲突的有效方案。它通过同源的、语义对齐的连续与离散表示,成功地在不牺牲理解性能的前提下集成了强大的生成能力,其综合性能优于纯离散和双编码器这两种常用方法。
六、论文结论与启示
总结
本文成功地提出并验证了一种简单、可扩展的统一多模态模型——Manzano,其核心在于创新的混合图像分词器。该分词器通过共享编码器和双适配器的设计,为理解和生成任务提供了源于同一语义空间的视觉表示,从而有效解决了长期困扰统一模型的性能冲突问题。通过将LLM聚焦于高层语义预测,并将像素渲染交由独立的扩散解码器,Manzano的架构清晰且易于扩展。
实验结果有力地证明,该模型不仅在各项理解(尤其是富文本)和生成基准上达到了SOTA水平,而且随着模型规模的扩大,各项能力均能得到持续提升,展示了其设计的优越性和实用性。
展望
基于论文的讨论,未来的研究方向可以包括:
- 扩展至更复杂的交互任务:利用Manzano强大的统一建模能力,探索更具挑战性的应用,如对话式图像编辑和多轮次视觉推理。
- 融合更多模态:将“混合分词器 + 统一自回归骨干 + 领域解码器”的设计范式推广到视频、音频等更多模态,构建更全面的多模态统一模型。
- 优化评估基准:现有生成基准(如GenEval)在模型变大后出现饱和现象,这启发社区需要开发新的评估方法,以更准确地衡量统一模型涌现出的高级能力,特别是结合世界知识的生成任务。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 6
6 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)