Coggle数据科学 | Coggle 竞赛学习活动:7天入门时序预测建模(数境杯大模型赛题)
数境杯工业互联网数据创新应用大赛聚焦通用大模型在跨领域时序预测中的潜力,设置风电预测、水电流量预测、物料需求预测三个子赛题。参赛需完成四项打卡任务:1)报名与数据分析;2)提交均值/线性回归模型;3)构建ARIMA模型;4)开发基于Transformer的大模型方案。比赛强调模型通用性,鼓励单一模型解决多领域问题,并提供200元京东卡和技术书籍作为打卡奖励。文章详细介绍了各赛题特性、时序预测基础方
本文来源公众号“Coggle数据科学”,仅用于学术分享,侵权删,干货满满。
原文链接:https://mp.weixin.qq.com/s/BeFr3U9CuhG5942CCOicOA
Part1 内容介绍
本次“数境杯”数据智能创新应用大赛·工业互联网数据创新应用专业赛(第八届),旨在探索通用大模型在解决多样化、跨领域时间序列预测问题上的潜力。本赛题鼓励选手构建一个统一的、具有强大泛化能力的通用模型,以应对来自三个不同领域的挑战:
-
子赛题1: 机组数据驱动的风电场短期风况预测
-
子赛题2: 水电站入库流量预测
-
子赛题3: 离散制造行业产品物料需求智能预测
Part2 活动安排
-
这是一项免费的学习活动,旨在帮助大家更好地理解和参与本次比赛。
Part3 学习打卡
|
任务名称 |
难度/分值 |
任务说明 |
|---|---|---|
| 打卡1:
报名参赛和数据分析 |
低 |
报名参加全部三道子赛题,确保拥有参赛资格。 |
| 打卡2:
均值和线性回归模型提交 |
低 |
尝试使用最基础的均值模型和线性回归对三个子赛题进行预测并提交结果,熟悉比赛流程。 |
| 打卡3:
ARIMA模型提交 |
中 |
学习和使用 ARIMA (自回归移动平均) 等经典统计时序模型,对三个子赛题进行预测并提交结果。 |
| 打卡4:
大模型时序预测 |
高 |
学习并实践基于通用大模型的时序预测方法,参考赛题推荐的 Autoformer 或其他基于 Transformer 的模型。 |
打卡奖励
-
Top 1-3: 在9月27日前完成所有打卡任务的同学中,排名前3的优秀学习者将获得 200元京东卡!
-
Top 4-5: 表现出色的第4名和第5名学习者将获得精美技术书籍一本。
历史活动打卡链接,可以参考如下格式:
-
https://blog.csdn.net/weixin_42551154/article/details/125474519
-
https://blog.csdn.net/weixin_42551154/article/details/125481695
任务1:报名参赛和数据分析
📌 任务目标
-
报名参赛:确保成功报名全部三个子赛题,获得参赛资格。
-
数据下载与分析:下载各赛题数据,进行初步探索性分析(EDA),理解数据结构和预测目标。
赛题旨在探索通用大模型在解决多样化、跨领域的时间序列预测问题上的潜力。我们期望选手能够突破传统“一个任务,一个模型”的范式,构建一个统一的、具有强大泛化能力的通用模型,以应对来自不同场景的挑战。参赛选手将同时接触到三个领域的时序预测任务,鼓励选手通过通用模型完成所有任务的预测结果,全面考验模型的综合能力与适应性。
-
赛题官网:https://www.industrial-bigdata.com/Competition
-
参赛宣讲:https://mp.weixin.qq.com/s/4ElfpZ1lIZ4VScuCC8p_Kg
本赛题要求选手采用一个模型解决三个子赛题的比赛任务,三道赛题均要报名参赛,且保证三道赛题都有有效成绩。选手在每道子赛题进行数据下载及答案提交,由每道子赛题给出评分及子赛题分别的排名;复赛结束会根据所有选手复赛结果,按照三道子赛题得分等权重综合排名,进行决赛答辩资格筛选。推荐并鼓励选手采用通用模型的思路进行模型构建,对三道子赛题进行推理预测。在决赛答辩环节,模型的通用性、泛化能力和创新性将作为一个独立的、重要的评价维度。
|
特性维度 |
子赛题1:机组数据驱动的风电场短期风况预测 |
子赛题2:水电站入库流量预测 |
子赛题3:离散制造行业产品物料需求智能预测 |
|---|---|---|---|
| 预测目标 |
每台机组未来10分钟内的风速、风向 |
电站未来7日的入库流量 |
每个工厂的每个产品物料未来几个月的需求量 |
| 预测对象 |
风电场中的单台机组 |
整个电站
的入库流量 |
工厂-产品物料
组合 |
| 数据输入 |
1. 风电场最近12小时及未来1小时的气象数据 |
历史数据
和当前观测信息 |
1. 产品物料的需求历史数据 |
| 预测范围 | 超短期
:未来10分钟 |
短期至中期
:未来7天 |
中长期
:未来几个月 |
| 时间分辨率 | 极高
:30秒一个预测点 |
高
:3小时一个预测点(共56个点) |
低
:月度(通常以月为单位) |
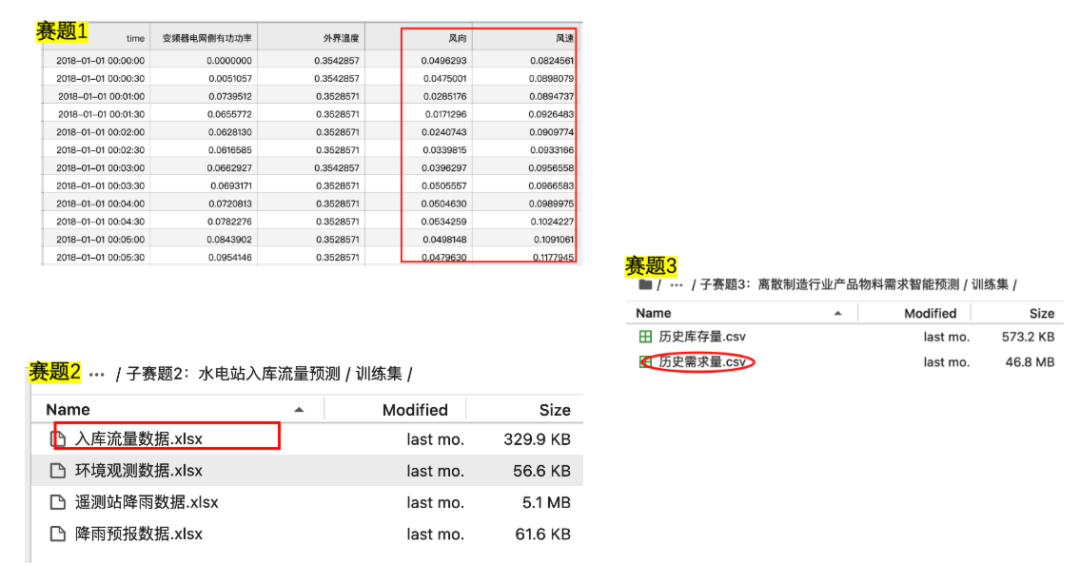
自回归 (AutoRegressive, AR)
-
核心思想: 用变量自身的历史值来预测其未来值。其基本假设是“过去会影响未来”。
-
模型表示(以线性为例):
Y(t) = β₀ + β₁*Y(t-1) + β₂*Y(t-2) + ... + βₚ*Y(t-p) + ε(t)-
Y(t)是当前时刻的值。 -
Y(t-1),Y(t-2), ...,Y(t-p)是前p个时刻的历史值(称为 滞后项 -lag features)。 -
β是模型需要学习的系数。 -
ε(t)是误差项。
-
多元回归 (Multiple Regression)
-
核心思想: 用多个其他变量(特征) 来预测目标变量。这些特征与目标变量可以是同一时刻的。
-
模型表示:
Y(t) = β₀ + β₁*X₁(t) + β₂*X₂(t) + ... + βₙ*Xₙ(t) + ε(t)-
X₁(t),X₂(t), ...,Xₙ(t)是n个在t时刻的特征。
-
-
简单理解: 就像用“学习时间”、“请教学长次数”、“睡眠时间”等多个因素来预测考试成绩。
外部特征和目标变量的时间分辨率可能不同。例如,赛题2中降雨数据可能是小时级,而流量是3小时级。为此必须将所有特征处理并聚合到同一时间粒度上。对于未来预报,需要确保预报的时间点与预测 horizon 对齐。因此对于外部特征,不仅可以只用当前值,还可以创建滚动窗口统计量作为新特征,如过去24小时的平均降雨量、过去1小时的风速最大值等,这能提供更丰富的上下文信息。
-
ARIMAX 和 SARIMAX 是专门为这种带外部变量的自回归问题设计的,但通常处理线性关系较好。
-
LightGBM、XGBoost 等树模型能自动处理非线性关系和平稳性,非常适合此类问题。
-
LSTM、Transformer 等模型是终极武器。它们能够自动学习历史序列中的长期依赖关系和模式,无需手动创建大量滞后特征。
任务2: 均值和线性回归模型提交
📌 任务目标
-
理解均值模型和线性回归的思路:两者有什么区别?。
-
**参考开源的均值提交代码**:提交到比赛平台,看看效果。
均值模型是一种简单但有效的时间序列预测方法,它基于历史数据的平均值来预测未来值。这种方法虽然简单,但在许多实际应用中可以作为基准模型,为后续更复杂的模型提供比较基准。不需要复杂的数学模型和参数调优,处理大规模数据时速度快。
-
子赛题1:使用每个风机最新观测值作为预测值
-
子赛题2:使用历史流量的移动平均值作为未来预测
-
子赛题3:使用历史需求量的整体平均值作为未来预测
线性回归模型则可以看作是均值模型的升级版,它不仅可以利用目标变量的历史值(自回归),还可以结合其他外部特征进行预测。其核心思想是通过一条直线或超平面来拟合特征和目标变量之间的关系。自回归线性回归(Autoregressive Linear Regression)将这两种思想结合起来,利用目标变量自身的历史值和其他相关特征来预测未来的值。例如,你可以使用过去几个小时的风速、风向、温度以及未来的气象预报数据,来预测未来的风速。这个方法非常灵活,可以通过手动创建滞后项和滚动窗口统计特征来捕捉时间序列中的模式,并用简单的线性模型进行拟合。
线性回归中要预测未来 t 时刻的值,你可以使用 t-1, t-2, t-3 等时刻的历史值作为特征。
-
构建特征矩阵(
X)和目标向量(y):X是你的输入特征,y是你想要预测的目标变量。 -
滞后特征 (Lag Features): 在时间序列预测中,将历史值作为特征是核心。
df['sales'].shift(i)函数可以方便地创建这些滞后项。 -
训练与预测数据: 在实际比赛中,你需要将数据分为训练集和测试集。使用训练集来拟合模型,然后用测试集来进行预测并提交结果。
-
多变量线性回归: 如果你有外部特征(例如,天气数据、价格),只需将它们添加到特征矩阵
X中,线性回归模型就能自动处理。
任务3: ARIMA模型提交
📌 任务目标
-
理解ARIMA模型:其是非常经典的时序模型,可以很好的预测趋势和周期。
-
**参考开源的ARIMA提交代码**:提交到比赛平台,看看效果。
ARIMA 模型全称为 差分自回归移动平均模型(AutoRegressive Integrated Moving Average),它由三个部分组成:
-
AR(AutoRegressive,自回归):利用历史观测值来预测当前值。其核心思想是,当前值与过去值之间存在某种线性关系。这个部分由参数
p控制,表示使用过去p个时间步的观测值。 -
I(Integrated,差分):用于将非平稳时间序列转换为平稳序列。平稳性是 ARIMA 模型的一个重要假设,指的是序列的统计特性(如均值、方差)不随时间变化。如果你的数据有明显的趋势或季节性,通常需要通过差分来消除这些影响。这个部分由参数
d控制,表示差分的阶数。 -
MA(Moving Average,移动平均):利用历史预测误差来预测当前值。它认为,当前值与过去一段时间的预测误差之间存在某种线性关系。这个部分由参数
q控制,表示使用过去q个时间步的预测误差。
ARIMA 模型通常表示为 **ARIMA(p,d,q)**,其中 p,d,q 是模型的超参数。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pmdarima import auto_arima
from pmdarima.datasets import load_airpassengers
# 加载示例数据(航空乘客数据集)
# 这是一个经典的时间序列数据集,展示了1949-1960年每月航空乘客数量的增长趋势
data = load_airpassengers(as_series=True)
# 划分训练集和测试集
train_size = int(len(data) * 0.8)
train, test = data[:train_size], data[train_size:]
# 使用auto_arima自动寻找最佳ARIMA参数
# 它会自动尝试不同的(p,d,q)组合,并选择AIC值最小的模型
model = auto_arima(train.values,
seasonal=True, # 启用季节性组件
trace=False, # 显示训练过程
m=24,
error_action='ignore',
suppress_warnings=True)
# 进行预测
forecast_steps = len(test)
forecast, conf_int = model.predict(n_periods=forecast_steps, return_conf_int=True)
# 将预测结果转换为Series,方便绘图
forecast_series = pd.Series(forecast, index=test.index)
# 绘制预测结果
plt.figure(figsize=(12, 6))
plt.plot(train, label='Train')
plt.plot(test, label='Test')
plt.plot(forecast_series, label='pred')
plt.legend()
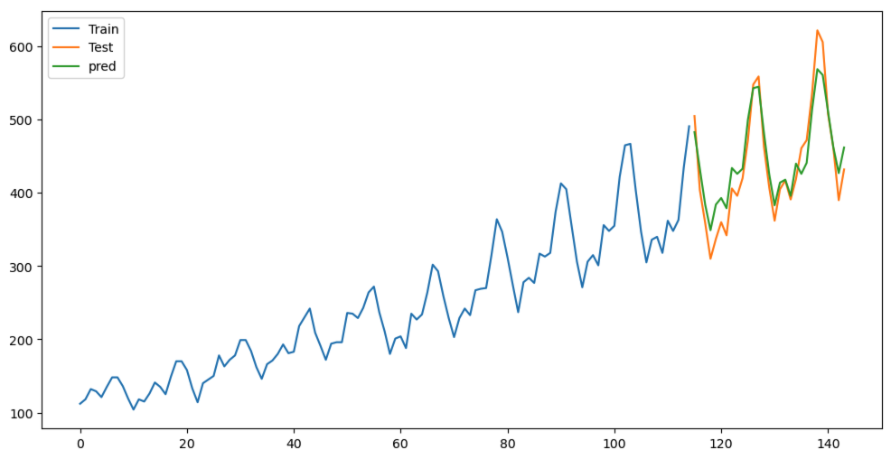
为每个子赛题单独构建 ARIMA 模型 是一种安全且高效的策略,可以帮助你在初赛中快速获得一个不错的排名。ARIMA 模型主要捕捉数据中的线性关系。也可以使用 pmdarima 库中的 auto_arima 函数,为每个子赛题的每个预测目标自动寻找最佳的 ARIMA 模型参数,并进行预测。
打卡4: 大模型时序预测
-
理解大模型进行时图预测的原理。
-
参考开源的Qwen提交代码 :提交到比赛平台,看看效果。
通用大模型,如基于 Transformer 的模型,可以在大量不同领域的时间序列上进行训练。它能从风电数据的波动性、水电数据的季节性、物料需求数据的稀疏性等多种模式中学习到共性的规律。这些模型通过注意力机制(Attention Mechanism)能够理解时间序列中的长距离依赖关系,而不仅仅是局限于最近的历史数据。
通用模型可以被设计成一个多头(Multi-head)模型,其中一个模型的主体部分共享所有任务的知识,而每个任务有一个独立的输出层。这种机制使得模型在预测某个时间点的值时,能够动态地衡量历史数据中每一个时间点的重要性。
-
需要为每个数据点添加额外的元数据,例如
任务ID(风电、水电、物料)、序列ID(风机编号、水电站编号、物料编码),甚至可能包括文本描述。 -
处理好不同时间分辨率的问题。例如,将所有数据降采样或上采样到统一的频率,或者使用时间嵌入(Positional Embeddings)来处理不规则的时间间隔。
现在也存在流行的时间序列预测方法:
-
OneFitsAll:这个方法也被称为GPT4TS,它通过实例归一化和“块”化处理输入的时间序列,然后将其传递到线性层以获得语言模型的输入表示。
-
Time-LLM:这个方法通过“块”化将输入的时间序列进行标记化,并使用多头注意力将其与低维词嵌入对齐。然后,将这些对齐后的输出与描述性统计特征的嵌入结合,传递给预训练的冻结语言模型。
-
CALF:这个方法将输入的时间序列的每个通道视为一个“词”,并通过交叉注意力将其与语言模型的低维词嵌入对齐。这种表示被传递给预训练的冻结语言模型以获得“文本预测”。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 7
7 0
0- 0



 已为社区贡献151条内容
已为社区贡献151条内容

所有评论(0)