通义团队提出环境Scaling:自动构建环境,并自主学习和成长,可让30B比肩1T效果
这就好比教一个孩子不仅要知道“什么是开关”,还要学会“走过去按下开关”来开灯——后者需要的是在具体环境中通过反复尝试和反馈才能掌握的能力。论文:Towards General Agentic Intelligence via Environment Scaling链接:https://arxiv.org/pdf/2509.13311以往训练这类“代理智能”的主要瓶颈在于缺乏高质量、大规模、多样化的
近年来,大型语言模型(LLM)在理解与生成自然语言方面取得了惊人进展,但要让它们真正成为能处理现实任务的“智能代理”,还面临一个核心挑战:如何让模型学会调用外部工具(如API、函数)来与环境交互。这就好比教一个孩子不仅要知道“什么是开关”,还要学会“走过去按下开关”来开灯——后者需要的是在具体环境中通过反复尝试和反馈才能掌握的能力。

-
论文:Towards General Agentic Intelligence via Environment Scaling
-
链接:https://arxiv.org/pdf/2509.13311
以往训练这类“代理智能”的主要瓶颈在于缺乏高质量、大规模、多样化的交互数据。人工标注成本极高,而单纯用模型生成的数据又往往不够真实或难以验证。这篇由阿里巴巴通义实验室团队发表的论文(通过环境扩展迈向通用代理智能)提出了一条全新的路径:通过程序化、自动化地构建海量、异构、可验证的模拟环境,让语言模型能在其中自主交互、收集经验、学习成长。基于该方法训练的AgentScaler模型系列,仅用数十亿参数就在多项权威测试中达到了与万亿级模型或闭源商业系统媲美的性能,为高效、轻量级代理智能的发展打开了新的可能性。
接下来,我们将深入解读这项研究是如何实现这一目标的。
研究背景与动机:为何需要环境扩展?
要让语言模型成为能处理现实任务的智能代理,核心是赋予其“函数调用”(Function Calling)或“工具使用”(Tool Use)的能力。例如,用户问“帮我把明天北京的天气设为手机壁纸”,模型需要依次调用“天气查询API”和“壁纸设置API”才能完成。
然而,训练这种能力面临两大难题:
-
数据稀缺:高质量的代理交互数据(即模型调用工具成功完成任务的轨迹)非常稀少,且人工标注成本极高。
-
环境限制:以往的方法要么在真实环境中调用工具(成本高、速度慢、不稳定),要么用另一个LLM模拟工具响应(容易“幻觉”、不一致)。
这篇论文的核心观点是:代理智能的泛化能力与训练环境的多样性直接相关。因此,他们提出了一个根本性解决方案:系统地、自动化地“扩展”(Scale)环境,从而大规模生成高质量、可验证的代理交互数据。
方法总览:环境扩展与代理经验学习的双轮驱动
整个研究遵循一个清晰的两阶段框架:
-
环境构建与扩展(Environment Build & Scaling):自动化地构建大量模拟环境,每个环境对应一个特定的工具使用领域(如购物、航班、通讯),并确保工具调用能真实地改变环境状态。
-
代理经验学习(Agent Experience Learning):让模型在这些模拟环境中与虚拟用户交互,收集成功和失败的轨迹,并通过严格过滤后用于训练模型。
最终目标是训练出能熟练、稳定调用工具的模型——AgentScaler。
环境构建与扩展:如何自动化生成多样化工具使用场景?
设计原则:将工具视为对数据库的读写操作
论文提出了一个简洁而强大的抽象:任何工具调用都可以看作是对某个底层环境数据库(𝒟)的“读”或“写”操作。
-
读操作(Read):查询信息,如搜索商品、查询航班。不改变数据库状态。
-
写操作(Write):执行动作,如下单购票、修改设置。会改变数据库状态。
一个工具调用 API(func, α) 等价于执行 op(func)(α; 𝒟),其中 α 是调用参数。这一定义使得所有工具执行结果变得可计算、可验证。
环境自动构建的三步流程
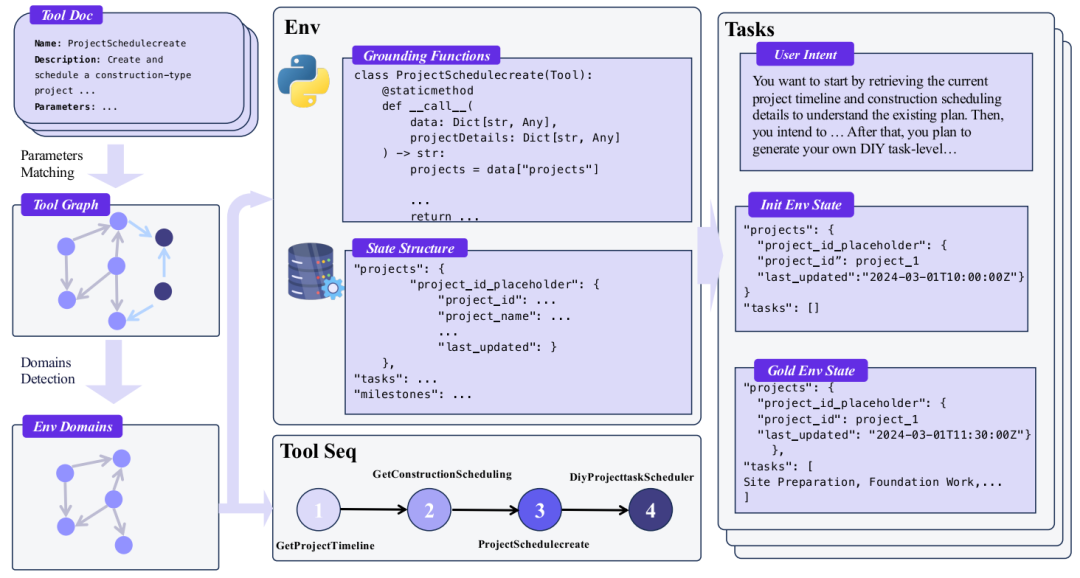
环境自动构建的整体流程
-
场景收集(Scenario Collection):从多个来源(如ToolBench、API-Gen)收集了超过3万个真实世界的API,经过清洗和格式化,构成了庞大的工具池。
-
工具依赖图建模(Tool Dependency Graph Modeling):将工具视为图中的节点,如果两个工具的参数相似(通过向量相似度计算),就在它们之间建立边。然后使用社区检测算法(Louvain方法)将工具聚类成不同的“领域”(Domain),如零售、航空、电信等。最终得到了超过1000个领域。
-
功能模式程序化实现(Function Schema Programmatic Materialization):这是最关键的一步。为每个领域生成一个数据库结构(Schema),然后将该领域内的每个工具都实现为可执行的Python代码。这些代码能真实地对数据库进行读写操作。例如,“购买商品”工具会真的从库存中减少数量并生成订单。
代理任务构建与轨迹生成
环境建好后,就可以生成训练数据了:
-
从某个领域的工具图中采样一个逻辑连贯的工具序列(如:搜索商品 -> 查看详情 -> 加入购物车 -> 下单)。
-
为每个工具调用生成参数,并实际执行它,从而改变数据库状态。
-
最终,每一步的执行结果和最终数据库状态都是已知的,这为后续的数据验证提供了“标准答案”。
这种方法确保了生成的数据在两个层面可验证:
-
环境状态一致性:最终数据库状态是否与预期一致。
-
工具序列精确匹配:模型调用的工具和参数是否与预设序列完全一致。
代理经验学习:如何从交互中高效学习?
人机交互模拟与经验收集
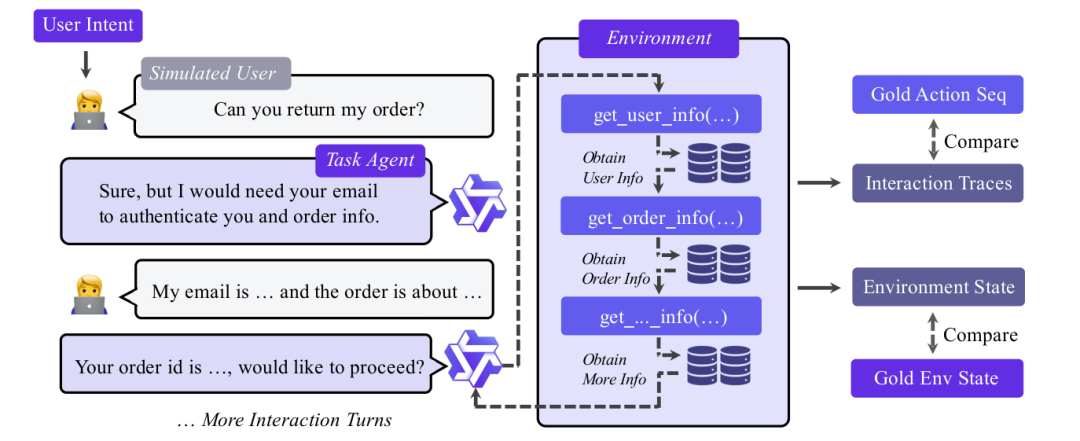
代理与模拟用户交互,并通过工具调用改变环境状态的过程
在一个构建好的任务中,一个模拟用户会提出一个高级目标(如“计划一次出差”)。代理模型需要调用各种工具来逐步满足用户需求,直到任务完成。这个过程完全由代码模拟,实现了用户、代理、环境三端的端到端模拟,极具可扩展性。
三层过滤机制确保数据质量
收集到的交互轨迹并非全部可用,论文设计了一个“漏斗型”三层过滤框架:
-
有效性控制(Validity Control):过滤掉无效的对话格式和严重重复的推理内容。
-
环境状态对齐(Environment State Alignment):只保留那些最终数据库状态与预期完全一致的轨迹。这确保了“写操作”真正起到了效果。
-
函数调用精确匹配(Function Calling Exact Match):最严格的过滤。只保留工具调用序列和参数与预设的“标准答案”完全一致的轨迹。这保证了学习信号的高保真度。
特别注意:不过滤那些中间步骤出错的轨迹。因为即使某些调用失败了,最终任务仍可能成功。保留这些数据有助于提升模型的鲁棒性。
两阶段训练策略:从通用基础到领域专精
训练目标函数如下:
-
符号解释:
-
: 一段交互轨迹。
-
: 轨迹中的第k个token。
-
: 指示函数,判断token是否属于需要模型学习的部分。
-
: 需要模型学习的部分,即工具调用()和助理的自然语言回复()。
-
-
核心思想:在计算损失时,只对模型需要生成的部分(工具调用和回复)求损失。用户指令()和工具返回结果()作为上下文输入给模型,但不参与损失计算。这确保了模型在学习时能看到全部信息,但只专注于学习如何决策和回应。
两阶段经验学习:
-
第一阶段(通用基础):让模型在广泛的通用领域(多个工具域)进行训练,学习“何时调用工具”、“如何调用”以及“如何将工具结果整合进回复”的基础能力。
-
第二阶段(领域专精):在特定的垂直领域(如零售、航空)进行精细化训练,使模型适应该领域的特定工具、任务和用户意图,生成更精准、更符合语境的回应。
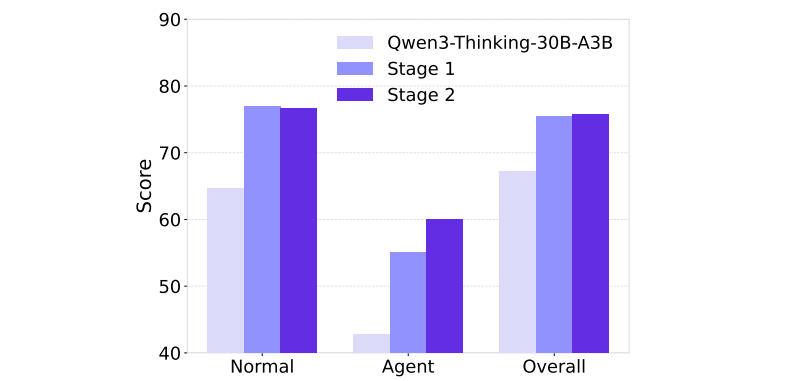
在ACEBench-en基准上,两阶段训练对模型性能的提升效果
实验验证:AgentScaler模型表现如何?
基准测试与对比模型
论文在三个公认的代理基准上进行了全面评估:
-
τ-bench:关注零售和航空领域。
-
τ²-Bench:扩展了零售、航空和电信领域。
-
ACEBench-en:综合性评测,包含常规任务(Normal)、特殊任务(Special)和代理任务(Agent)。
对比模型包括顶尖的闭源模型(如GPT-5, Gemini-2.5-pro, Claude-Sonnet-4)和开源模型(如Deepseek-V3, Kimi-K2, Qwen3系列)。
主要结果:轻量模型实现领先性能
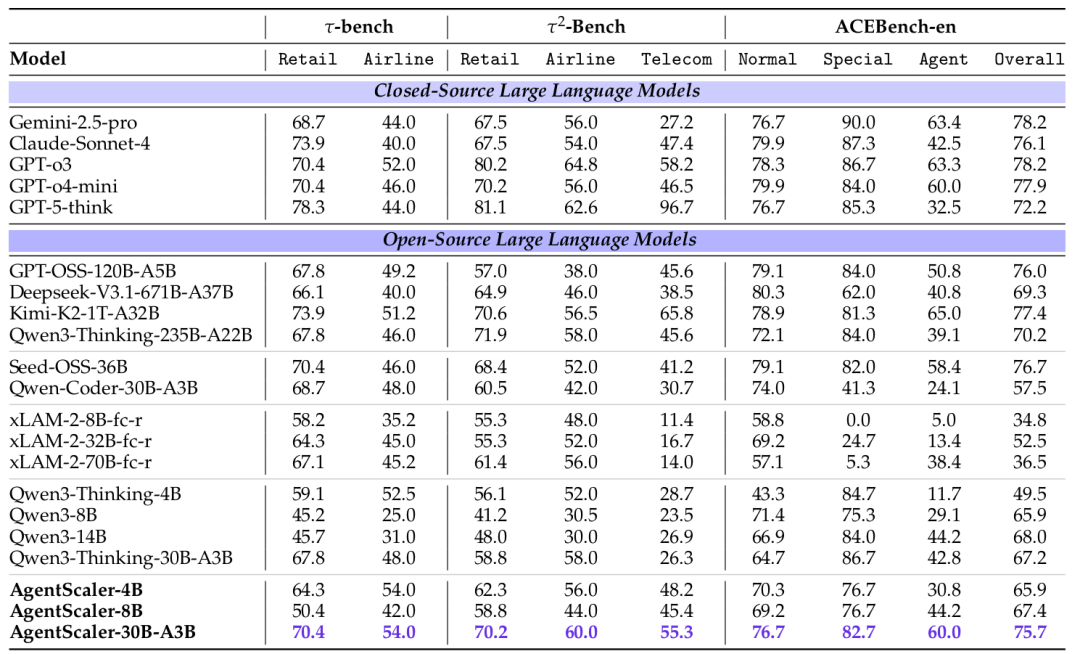
所有模型在三大基准上的性能对比
实验结果非常震撼:
-
AgentScaler-4B(40亿参数)的性能与许多300亿参数的开源模型相当,证明了小模型在代理任务上的巨大潜力。
-
AgentScaler-30B-A3B(300亿参数激活,30亿参数)实现了最佳的开源模型性能,在多项测试中媲美甚至超越了参数量达万亿级的开源模型(如Kimi-K2-1T),并且在某些领域接近了顶级闭源模型(如GPT-o3)的水平。
这充分证明了本文方法的高效性:无需依赖巨大的模型参数,通过高质量的环境扩展和经验学习,也能培育出强大的代理智能。
深入分析:泛化性、稳定性与长序列挑战
论文还进行了深入分析,揭示了AgentScaler的更多特性:
-
强大的泛化能力:在训练未涉及的中文ACEBench(ACEBench-zh) 上,AgentScaler模型同样显著超越了其原始Qwen基线。
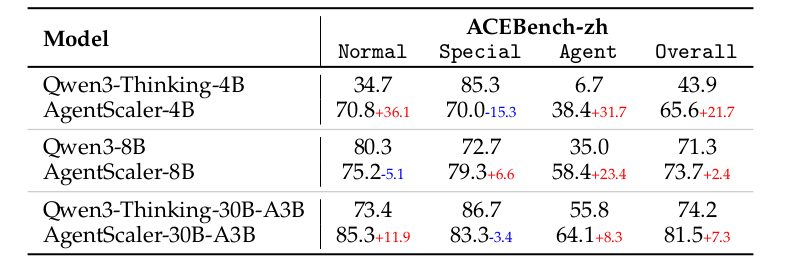
-
稳定性分析:使用 pass^k 指标(模型k次独立尝试均答对的准确率)评估稳定性。
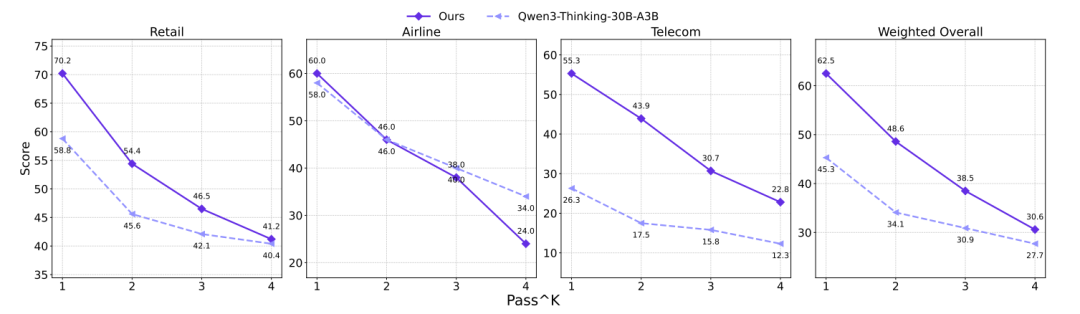
(上图显示了在τ²-Bench上,随着k增大(要求更稳定),所有模型的得分都下降,但AgentScaler-30B-A3B的稳定性始终优于基线模型。) 结果表明,虽然AgentScaler更稳定,但处理长序列工具调用时的稳定性仍然是整个领域的开放挑战。
-
长序列挑战:分析表明,随着任务要求调用的工具数量增加,所有模型的性能都会下降。
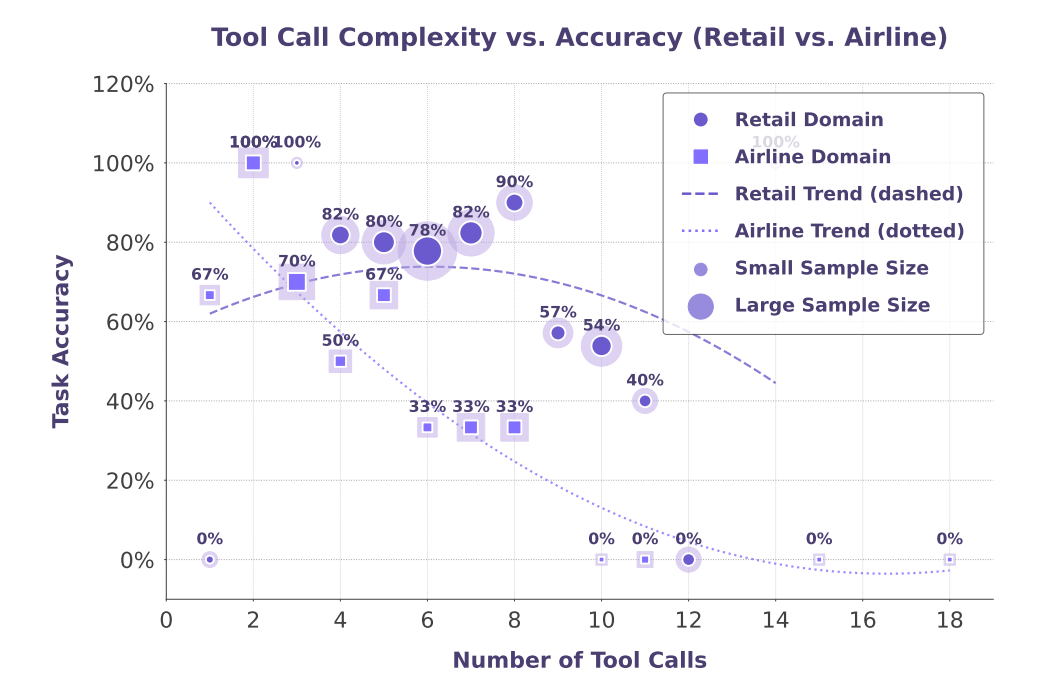
(上图展示了在τ-bench上,模型准确率随所需工具调用次数增加而下降的趋势。) 这指明了未来需要重点改进的方向。
创新与贡献
-
环境扩展新范式:提出了一个系统性的、可扩展的自动化环境构建框架,将工具抽象为对数据库的读写操作,并通过程序化实现确保其可验证性。
-
高质量数据生成与过滤:通过端到端模拟和三层漏斗过滤,大规模生成高保真、可验证的代理交互数据。
-
高效的两阶段训练法:先通用后专精的训练策略,高效地赋予了模型扎实的代理基础能力和领域适应能力。
-
轻量而强大的AgentScaler模型:用相对极小的参数量,达到了与超大模型和闭源系统媲美的性能,为代理智能的实际部署提供了高效方案。
局限性
论文坦诚地指出了当前工作的两个主要局限:
-
尚未集成强化学习(RL):目前仅使用了监督微调(SFT)。而构建的模拟环境能提供稳定、低延迟的反馈,是理想的RL训练环境。未来结合RL有望进一步优化代理行为。
-
模型规模上限:目前最大只验证到300亿参数级别。虽然作者认同“小模型是代理智能的未来”(便于部署),但将方法扩展到更大规模(200B+)模型仍是值得探索的方向。
未来工作将围绕集成RL、扩展模态(如图像、音频)、以及面向真实部署场景展开。
结论
这篇论文为迈向通用代理智能提供了一条清晰而坚实的路径:通过环境扩展来创造经验,通过经验学习来培育智能。其提出的自动化环境构建框架和两阶段训练策略,不仅显著提升了模型的工具调用能力,更证明了“小而精”的模型同样可以拥有强大的代理智能。这项工作不仅推动了学术前沿,更对开发低成本、高效率、易于部署的现实世界AI代理具有重要的实践价值。我们有望在不久的将来,看到更多能真正帮我们处理复杂任务的智能助手,走进日常生活。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献62条内容
已为社区贡献62条内容

所有评论(0)