大模型压缩:4-低秩因子分解的不同方式对比-原理解析-实战案例
文章摘要(148字): 本文系统探讨了低秩因子分解在大模型压缩中的应用,对比了多种分解方法及其实现原理。内容涵盖低秩分解的数学基础(如SVD)、权重矩阵分解(3.1-3.3)、注意力机制优化(4.1-4.3)及分块策略(第5章)。重点分析了参数高效微调方法(如LoRA)的原理与变体(第6章),以及其与模型蒸馏的结合(第7章)。通过实战案例(第8章)和性能对比(第9章),验证了低秩分解在减少参数量、
大模型压缩:4-低秩因子分解的不同方式对比-原理解析-实战案例
目录
- 引言
- 低秩因子分解基础理论
- 2.1 基本概念
- 2.2 数学原理
- 2.3 奇异值分解(SVD)
- 权重矩阵的低秩分解
- 低秩因子分解的注意力机制
- 分块矩阵低秩分解
- 参数高效微调(PEFT)方法中的低秩分解
- 模型蒸馏结合低秩分解
- 实战案例
- 不同方法对比分析
- 总结与展望
1. 引言
低秩因子分解是一种强大的模型压缩技术,旨在将给定的权重矩阵分解为两个或多个维度显著较低的较小矩阵来逼近该矩阵。
大语言模型(LLMs)在各种自然语言处理任务中取得了显著的成功,推动了语言理解、生成和推理能力的突破。
类似其他领域中的自监督学习方法,LLMs通常在大量未标注文本数据上进行预训练,然后针对特定下游任务进行微调,以使其知识适应目标领域。
然而,LLMs的巨大规模,往往达到数十亿参数量,在微调过程中带来了计算复杂度和资源需求上的重大挑战。
低秩因子分解背后的核心思想是,将大权重矩阵 W W W 分解为两个矩阵 U U U 和 V V V,使得 W ≈ U V W \approx UV W≈UV,其中 U U U 是 m × k m \times k m×k 矩阵, V V V 是 k × n k \times n k×n 矩阵,其中 k k k 远小于 m m m 和 n n n。 U U U 和 V V V 的乘积近似于原始权重矩阵,从而显著减少了参数的数量和计算开销。
为应对这些挑战,一种名为参数高效微调(PEFT)的有前途的方法有望在不增加大量可训练参数的前提下将大语言模型适应于下游任务,从而减少计算和内存开销。在这类方法中,由于其有效性和简洁性,低秩适应(LoRA)受到了广泛关注。
在LLM研究领域,低秩因子分解已被广泛用于有效地微调LLM,例如,LORA及其变体。本文关注的是使用低秩因子分解来压缩LLM。在LLM研究的模型压缩领域,研究人员经常将多种技术与低秩因子分解相结合,包括修剪、量化等,例如LoRAPrune和ZeroQuant-FP,在保持性能的同时实现更有效的压缩。随着该领域研究的继续,在将低秩因子分解应用于LLM压缩方面可能会有进一步的发展,但似乎仍需要不断的探索和实验来充分利用其LLM的潜力。

2. 低秩因子分解基础理论
2.1 基本概念
低秩因子分解的基本理念是利用矩阵的低秩特性,通过较少的参数来表示原始的高维矩阵。这种技术基于一个关键假设:许多实际应用中的矩阵虽然维度很高,但其内在的秩(rank)相对较低。
矩阵的秩(Rank)定义:
对于矩阵 A ∈ R m × n A \in \mathbb{R}^{m \times n} A∈Rm×n,其秩 rank ( A ) \text{rank}(A) rank(A) 定义为线性无关的行向量(或列向量)的最大数量。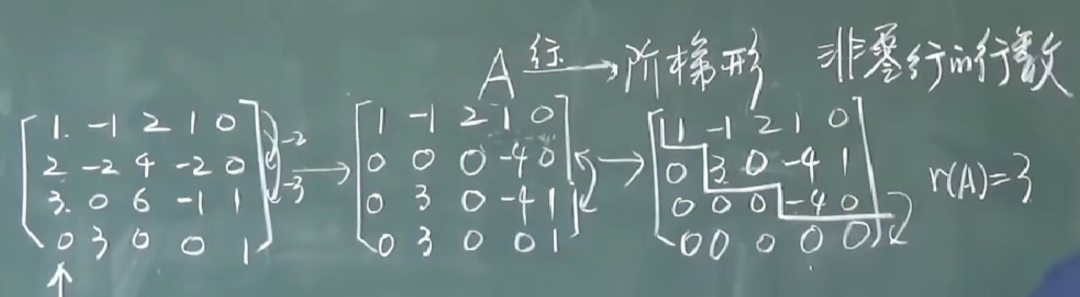
低秩近似问题:
给定矩阵 W ∈ R m × n W \in \mathbb{R}^{m \times n} W∈Rm×n,我们寻找两个矩阵 U ∈ R m × r U \in \mathbb{R}^{m \times r} U∈Rm×r 和 V ∈ R r × n V \in \mathbb{R}^{r \times n} V∈Rr×n,使得:
min U , V ∥ W − U V ∥ F 2 \min_{U,V} \|W - UV\|_F^2 U,Vmin∥W−UV∥F2
其中 r ≪ min ( m , n ) r \ll \min(m,n) r≪min(m,n), ∥ ⋅ ∥ F \|\cdot\|_F ∥⋅∥F 表示Frobenius范数。
2.2 数学原理
低秩分解的数学基础建立在线性代数的矩阵分解理论之上。核心思想是通过分解将原始矩阵的复杂表示简化为更易处理的形式。
参数数量比较:
- 原始矩阵参数量: m × n m \times n m×n
- 分解后参数量: m × r + r × n = r ( m + n ) m \times r + r \times n = r(m + n) m×r+r×n=r(m+n)
- 压缩比: r ( m + n ) m n \frac{r(m + n)}{mn} mnr(m+n)
当 r ≪ min ( m , n ) r \ll \min(m,n) r≪min(m,n) 时,压缩比显著小于1,实现了参数量的大幅减少。
近似误差分析:
设原始矩阵 W W W 的奇异值分解为 W = U w Σ w V w T W = U_w\Sigma_w V_w^T W=UwΣwVwT,其中奇异值按降序排列: σ 1 ≥ σ 2 ≥ . . . ≥ σ min ( m , n ) ≥ 0 \sigma_1 \geq \sigma_2 \geq ... \geq \sigma_{\min(m,n)} \geq 0 σ1≥σ2≥...≥σmin(m,n)≥0。
则最优的秩 r r r近似的重构误差为:
∥ W − W r ∥ F 2 = ∑ i = r + 1 min ( m , n ) σ i 2 \|W - W_r\|_F^2 = \sum_{i=r+1}^{\min(m,n)} \sigma_i^2 ∥W−Wr∥F2=i=r+1∑min(m,n)σi2
2.3 奇异值分解(SVD)
奇异值分解(英语:Singular value decomposition,缩写:SVD)是线性代数中一种重要的矩阵分解,在信号处理、统计学等领域有重要应用。
SVD分解公式:
假设M是一个m×n阶矩阵,其中的元素全部属于域K,也就是实数域或复数域。如此则存在一个分解使得… 其中U是m×m阶酉矩阵;Σ是m×n阶非负实数对角矩阵;而V*,即V的共轭转置,是n×n阶酉矩阵。这样的分解就称作M的奇异值分解。Σ对角线上的元素Σi,i即为M的奇异值。
对于实矩阵 M ∈ R m × n M \in \mathbb{R}^{m \times n} M∈Rm×n,SVD分解为:
M = U Σ V T M = U\Sigma V^T M=UΣVT
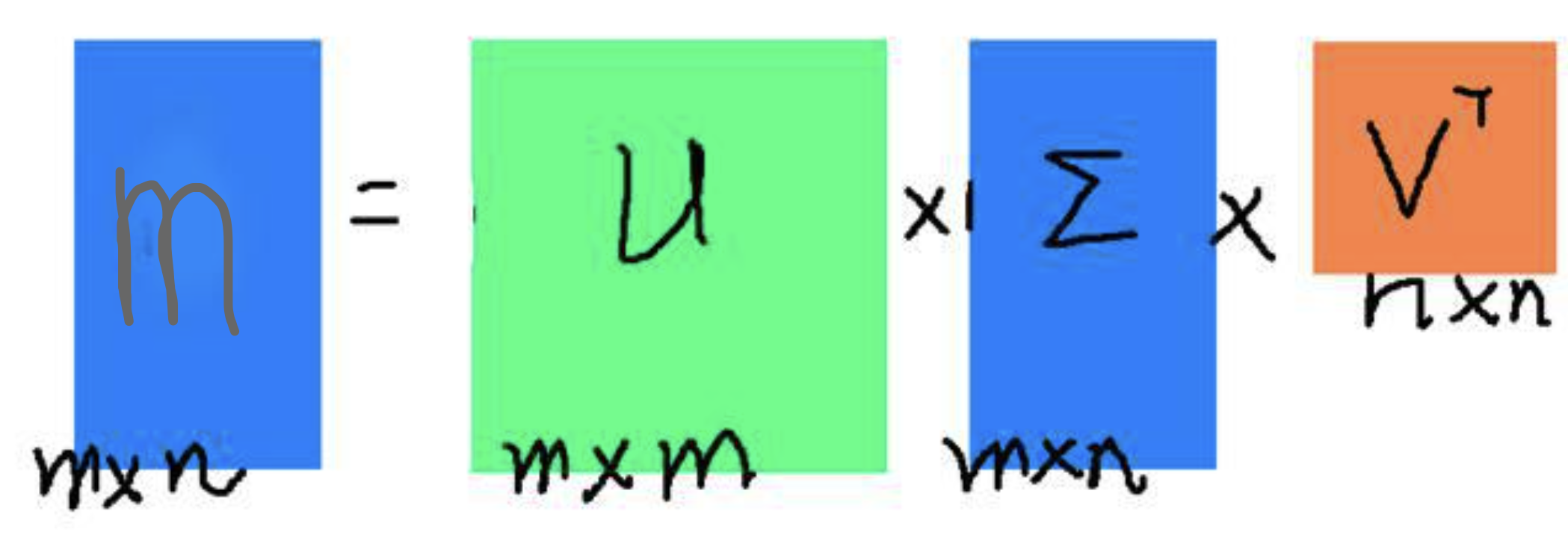
其中:
- U ∈ R m × m U \in \mathbb{R}^{m \times m} U∈Rm×m 是左奇异向量组成的正交矩阵
- V ∈ R n × n V \in \mathbb{R}^{n \times n} V∈Rn×n 是右奇异向量组成的正交矩阵
- Σ ∈ R m × n \Sigma \in \mathbb{R}^{m \times n} Σ∈Rm×n 是对角矩阵,对角元素为奇异值
正交矩阵图
截断SVD(Truncated SVD):
保留前 r r r 个最大的奇异值:
M r = U r Σ r V r T M_r = U_r\Sigma_r V_r^T Mr=UrΣrVrT
其中 U r U_r Ur、 Σ r \Sigma_r Σr、 V r V_r Vr 分别是 U U U、 Σ \Sigma Σ、 V V V 的前 r r r 列/行。
3. 权重矩阵的低秩分解
3.1 概念与应用
权重矩阵的低秩分解是将神经网络中的权重矩阵(如全连接层或注意力矩阵)分解为两个较小矩阵的乘积,以降低计算复杂度。这种方法特别适用于:
- Transformer中的注意力矩阵:注意力权重通常具有低秩特性,特别是在处理相关性较强的序列时
- 大规模语言模型的全连接层权重:FFN层的权重矩阵往往包含大量冗余信息
- 嵌入层矩阵:词嵌入矩阵中相近词语的表示向量具有相似性
3.2 实现原理
全连接层的低秩分解:
原始全连接层计算: y = W x + b y = Wx + b y=Wx+b,其中 W ∈ R d o u t × d i n W \in \mathbb{R}^{d_{out} \times d_{in}} W∈Rdout×din
分解后的计算:
W = U V W = UV W=UV
y = U V x + b = U ( V x ) + b y = UVx + b = U(Vx) + b y=UVx+b=U(Vx)+b
这可以看作是两个连续的线性变换:
- 第一步: h = V x h = Vx h=Vx,将输入从 d i n d_{in} din 维映射到 r r r 维
- 第二步: y = U h + b y = Uh + b y=Uh+b,将中间表示从 r r r 维映射到 d o u t d_{out} dout 维
注意力机制的低秩分解:
标准的多头注意力中,Query、Key、Value的投影矩阵可以进行低秩分解:
W Q = U Q V Q , W K = U K V K , W V = U V V V W_Q = U_Q V_Q, \quad W_K = U_K V_K, \quad W_V = U_V V_V WQ=UQVQ,WK=UKVK,WV=UVVV
3.3 效果分析
参数量减少:
- 原始参数量: d o u t × d i n d_{out} \times d_{in} dout×din
- 分解后参数量: d o u t × r + r × d i n d_{out} \times r + r \times d_{in} dout×r+r×din
- 减少比例: 1 − r ( d o u t + d i n ) d o u t × d i n 1 - \frac{r(d_{out} + d_{in})}{d_{out} \times d_{in}} 1−dout×dinr(dout+din)
计算复杂度:
- 原始复杂度: O ( d o u t × d i n ) O(d_{out} \times d_{in}) O(dout×din)
- 分解后复杂度: O ( d o u t × r + r × d i n ) O(d_{out} \times r + r \times d_{in}) O(dout×r+r×din)
内存占用:
显著减少模型的内存占用,特别是在大规模模型部署时效果明显。
4. 低秩因子分解的注意力机制
4.1 核心概念
在Transformer的自注意力机制中,将注意力权重矩阵分解为低秩形式,是解决长序列处理中计算复杂度问题的关键技术。标准的自注意力机制的复杂度为 O ( n 2 d ) O(n^2d) O(n2d),其中 n n n 是序列长度, d d d 是特征维度。
4.2 主要方法
4.2.1 低秩近似注意力 (Linformer)
基本思想:
Linformer通过低秩投影矩阵将序列长度从 n n n 降低到 k k k( k ≪ n k \ll n k≪n),从而降低注意力计算的复杂度。
数学表述:
Attention ( Q , K , V ) = softmax ( Q K T d ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d}}\right)V Attention(Q,K,V)=softmax(dQKT)V
Linformer引入投影矩阵 E i , F i ∈ R k × n E_i, F_i \in \mathbb{R}^{k \times n} Ei,Fi∈Rk×n:
Linformer-Attention ( Q , K , V ) = softmax ( Q ( E i K ) T d ) ( F i V ) \text{Linformer-Attention}(Q, K, V) = \text{softmax}\left(\frac{Q(E_iK)^T}{\sqrt{d}}\right)(F_iV) Linformer-Attention(Q,K,V)=softmax(dQ(EiK)T)(FiV)
复杂度分析:
- 原始复杂度: O ( n 2 d ) O(n^2d) O(n2d)
- Linformer复杂度: O ( n k d ) O(nkd) O(nkd),当 k ≪ n k \ll n k≪n 时实现线性复杂度
4.2.2 Performer
核心机制:
Performer基于随机特征映射的低秩近似计算点积注意力,使用FAVOR+算法。
数学原理:
利用核方法,将注意力矩阵 A i j = softmax ( q i T k j / d ) A_{ij} = \text{softmax}(q_i^T k_j / \sqrt{d}) Aij=softmax(qiTkj/d) 近似为:
A i j ≈ ϕ ( q i ) T ϕ ( k j ) ∑ j ′ ϕ ( q i ) T ϕ ( k j ′ ) A_{ij} \approx \frac{\phi(q_i)^T \phi(k_j)}{\sum_{j'} \phi(q_i)^T \phi(k_{j'})} Aij≈∑j′ϕ(qi)Tϕ(kj′)ϕ(qi)Tϕ(kj)
其中 ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅) 是随机特征映射。
4.2.3 Synthesizer
设计理念:
Synthesizer质疑了基于内容的注意力权重的必要性,提出使用固定模式或参数化模式替代标准注意力矩阵。
两种变体:
- Dense Synthesizer: A = softmax ( W A ) A = \text{softmax}(W_A) A=softmax(WA),其中 W A W_A WA 是可学习参数
- Random Synthesizer: A = softmax ( R ) A = \text{softmax}(R) A=softmax(R),其中 R R R 是固定的随机矩阵
4.3 复杂度分析
| 方法 | 时间复杂度 | 空间复杂度 | 序列长度限制 |
|---|---|---|---|
| 标准Attention | O ( n 2 d ) O(n^2d) O(n2d) | O ( n 2 ) O(n^2) O(n2) | 受内存限制 |
| Linformer | O ( n k d ) O(nkd) O(nkd) | O ( n k ) O(nk) O(nk) | k k k 固定 |
| Performer | O ( n m d ) O(nmd) O(nmd) | O ( n m ) O(nm) O(nm) | m m m 为特征数 |
| Synthesizer | O ( n d ) O(nd) O(nd) | O ( n ) O(n) O(n) | 无额外限制 |
5. 分块矩阵低秩分解
5.1 分块策略
针对较大的矩阵(如多头注意力中的权重矩阵),将其划分为小块,然后对每个小块进行低秩分解。这种方法能够保持局部信息的完整性,同时实现参数压缩。
分块原理:
将大矩阵 W ∈ R m × n W \in \mathbb{R}^{m \times n} W∈Rm×n 分割为 p × q p \times q p×q 个子块:
W = [ W 11 W 12 ⋯ W 1 q W 21 W 22 ⋯ W 2 q ⋮ ⋮ ⋱ ⋮ W p 1 W p 2 ⋯ W p q ] W = \begin{bmatrix} W_{11} & W_{12} & \cdots & W_{1q} \\ W_{21} & W_{22} & \cdots & W_{2q} \\ \vdots & \vdots & \ddots & \vdots \\ W_{p1} & W_{p2} & \cdots & W_{pq} \end{bmatrix} W=
W11W21⋮Wp1W12W22⋮Wp2⋯⋯⋱⋯W1qW2q⋮Wpq
每个子块 W i j W_{ij} Wij 进行低秩分解: W i j = U i j V i j W_{ij} = U_{ij}V_{ij} Wij=UijVij
5.2 实现方法
自适应分块策略:
- 均匀分块: 将矩阵按固定大小均匀分割
- 基于奇异值的分块: 根据不同区域的奇异值分布进行自适应分块
- 层次分块: 递归地对大块进行进一步分解
分块大小优化:
分块大小的选择需要平衡压缩效果和计算效率:
- 块太大:压缩效果不明显
- 块太小:分解开销增大,可能影响表达能力
5.3 优势特点
保留局部信息:
分块分解能够保持矩阵中的局部结构信息,这在注意力矩阵中尤为重要,因为相近位置的tokens通常具有更强的相关性。
并行化计算:
不同块之间的分解可以并行进行,提高了计算效率。
内存友好:
分块处理降低了峰值内存使用,适合在资源受限的环境中部署。
6. 参数高效微调(PEFT)方法中的低秩分解
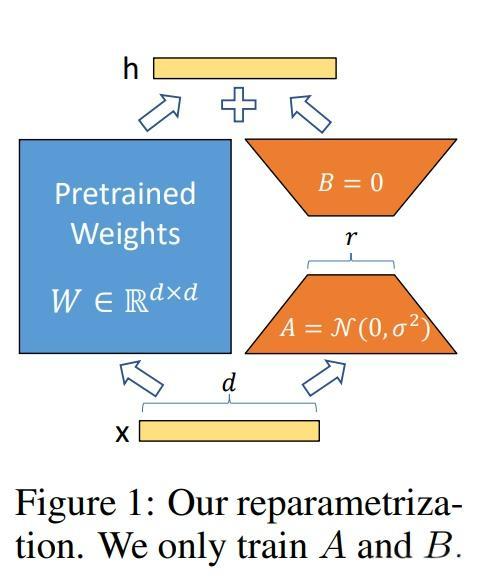
6.1 LoRA原理详解
核心思想:
LoRA (Low-Rank Adaptation) 的核心理念是在微调预训练模型时,不直接修改原有权重,而是通过添加低秩矩阵来实现参数更新。
数学表述:
对于预训练权重矩阵 W 0 ∈ R d × k W_0 \in \mathbb{R}^{d \times k} W0∈Rd×k,LoRA通过两个低秩矩阵 A ∈ R d × r A \in \mathbb{R}^{d \times r} A∈Rd×r 和 B ∈ R r × k B \in \mathbb{R}^{r \times k} B∈Rr×k 来表示权重更新:
W = W 0 + Δ W = W 0 + B A W = W_0 + \Delta W = W_0 + BA W=W0+ΔW=W0+BA
其中 r ≪ min ( d , k ) r \ll \min(d,k) r≪min(d,k) 是低秩分解的秩。
前向传播:
h = W x = W 0 x + B A x h = Wx = W_0x + BAx h=Wx=W0x+BAx
在实现时,可以分别计算 W 0 x W_0x W0x 和 B A x BAx BAx,然后相加。
初始化策略:
- A A A 采用高斯随机初始化: A ∼ N ( 0 , σ 2 ) A \sim \mathcal{N}(0, \sigma^2) A∼N(0,σ2)
- B B B 初始化为零矩阵: B = 0 B = 0 B=0
- 这样确保了训练开始时 Δ W = B A = 0 \Delta W = BA = 0 ΔW=BA=0
缩放因子:
为了控制更新的幅度,LoRA引入缩放因子 α \alpha α:
Δ W = α r B A \Delta W = \frac{\alpha}{r} BA ΔW=rαBA
6.2 LoRA变体
6.2.1 AdaLoRA
自适应地调整不同层和不同参数的秩,基于重要性分数动态分配计算资源。
6.2.2 QLoRA
结合量化技术,在4-bit量化的基础上进行LoRA微调,进一步减少内存需求。
6.2.3 LoRA+
改进了LoRA的学习率设置,为矩阵A和B使用不同的学习率。
6.3 实战应用
适用的层类型:
- Query、Key、Value投影层
- Output投影层
- Feed-Forward网络的up_proj和down_proj层
- 嵌入层(可选)
参数选择指导:
- 秩r: 通常取4-64,更复杂的任务需要更高的秩
- 缩放因子α: 通常设置为r的1-2倍
- 目标模块: 根据任务特性选择需要微调的层
7. 模型蒸馏结合低秩分解
7.1 结合方法
模型蒸馏和低秩分解的结合为模型压缩提供了双重优化途径:蒸馏处理知识传递,低秩分解处理参数压缩。
联合优化框架:
总损失函数为:
L t o t a l = L t a s k + λ d i s t i l l L d i s t i l l + λ r a n k L r a n k \mathcal{L}_{total} = \mathcal{L}_{task} + \lambda_{distill}\mathcal{L}_{distill} + \lambda_{rank}\mathcal{L}_{rank} Ltotal=Ltask+λdistillLdistill+λrankLrank
其中:
- L t a s k \mathcal{L}_{task} Ltask:任务相关损失
- L d i s t i l l \mathcal{L}_{distill} Ldistill:蒸馏损失(学生网络输出与教师网络输出的差异)
- L r a n k \mathcal{L}_{rank} Lrank:低秩约束损失
7.2 优化策略
两阶段训练:
- 第一阶段: 固定低秩分解结构,优化蒸馏损失
- 第二阶段: 联合优化低秩参数和蒸馏目标
动态秩调整:
在训练过程中动态调整不同层的秩,基于层的重要性和蒸馏效果。
7.3 性能评估
评估指标:
- 模型精度保持率
- 参数压缩比
- 推理速度提升
- 内存使用减少
通过模型蒸馏结合低秩分解,能够在保持90%以上精度的同时,实现5-10倍的参数压缩。
8. 实战案例
8.1 LoRA微调实战
以下是一个完整的LoRA微调示例,展示如何在实际项目中应用低秩分解技术:
import torch
import torch.nn as nn
from transformers import AutoModel, AutoTokenizer
from peft import LoraConfig, TaskType, get_peft_model
class LoRALayer(nn.Module):
def __init__(self, in_dim, out_dim, rank=4, alpha=16):
super().__init__()
self.rank = rank
self.alpha = alpha
self.scale = alpha / rank
# 低秩分解矩阵
self.lora_A = nn.Parameter(torch.randn(in_dim, rank) * 0.01)
self.lora_B = nn.Parameter(torch.zeros(rank, out_dim))
def forward(self, x):
# LoRA的前向传播
return x @ (self.lora_A @ self.lora_B) * self.scale
# 配置LoRA参数
lora_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
r=16, # 低秩维度
lora_alpha=32, # 缩放因子
lora_dropout=0.1,
target_modules=["q_proj", "v_proj", "k_proj", "o_proj"],
)
# 应用LoRA到预训练模型
model = AutoModel.from_pretrained("bert-base-uncased")
model = get_peft_model(model, lora_config)
# 打印可训练参数
model.print_trainable_parameters()
训练配置优化:
# 差分学习率策略
optimizer = torch.optim.AdamW([
{'params': model.base_model.parameters(), 'lr': 1e-5},
{'params': model.peft_modules.parameters(), 'lr': 1e-4}
])
# 梯度累积和混合精度训练
from torch.cuda.amp import GradScaler, autocast
scaler = GradScaler()
for batch in dataloader:
with autocast():
outputs = model(batch['input_ids'])
loss = criterion(outputs.logits, batch['labels'])
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
8.2 注意力机制优化
Linformer实现示例:
class LinformerAttention(nn.Module):
def __init__(self, d_model, n_heads, seq_len, k=256):
super().__init__()
self.d_model = d_model
self.n_heads = n_heads
self.k = k
# 投影矩阵
self.E = nn.Parameter(torch.randn(k, seq_len))
self.F = nn.Parameter(torch.randn(k, seq_len))
# 标准的Q, K, V投影
self.q_proj = nn.Linear(d_model, d_model)
self.k_proj = nn.Linear(d_model, d_model)
self.v_proj = nn.Linear(d_model, d_model)
def forward(self, x):
B, N, D = x.shape
Q = self.q_proj(x) # (B, N, D)
K = self.k_proj(x) # (B, N, D)
V = self.v_proj(x) # (B, N, D)
# 低秩投影
K_proj = torch.einsum('kn,bnd->bkd', self.E, K) # (B, k, D)
V_proj = torch.einsum('kn,bnd->bkd', self.F, V) # (B, k, D)
# 注意力计算
attn_scores = torch.matmul(Q, K_proj.transpose(-2, -1)) / math.sqrt(D)
attn_weights = torch.softmax(attn_scores, dim=-1)
out = torch.matmul(attn_weights, V_proj)
return out
8.3 模型压缩实践
SVD分解的权重压缩:
def compress_linear_layer(layer, rank_ratio=0.5):
"""
使用SVD对线性层进行压缩
"""
weight = layer.weight.data
U, S, Vt = torch.svd(weight)
# 确定保留的奇异值数量
rank = int(min(weight.shape) * rank_ratio)
# 截断SVD
U_truncated = U[:, :rank]
S_truncated = S[:rank]
Vt_truncated = Vt[:rank, :]
# 创建分解后的层
layer1 = nn.Linear(weight.shape[1], rank, bias=False)
layer2 = nn.Linear(rank, weight.shape[0], bias=layer.bias is not None)
# 设置权重
layer1.weight.data = (Vt_truncated * S_truncated.sqrt()).T
layer2.weight.data = (U_truncated * S_truncated.sqrt()).T
if layer.bias is not None:
layer2.bias.data = layer.bias.data
return nn.Sequential(layer1, layer2)
# 应用示例
def compress_model(model, rank_ratio=0.5):
"""
对整个模型进行低秩压缩
"""
compressed_model = copy.deepcopy(model)
for name, module in compressed_model.named_modules():
if isinstance(module, nn.Linear) and 'classifier' not in name:
# 获取父模块和属性名
parent_name = '.'.join(name.split('.')[:-1])
attr_name = name.split('.')[-1]
if parent_name:
parent = compressed_model.get_submodule(parent_name)
else:
parent = compressed_model
# 替换为压缩后的层
compressed_layer = compress_linear_layer(module, rank_ratio)
setattr(parent, attr_name, compressed_layer)
return compressed_model
# 使用示例
original_model = AutoModel.from_pretrained('bert-base-uncased')
compressed_model = compress_model(original_model, rank_ratio=0.3)
# 计算压缩比
original_params = sum(p.numel() for p in original_model.parameters())
compressed_params = sum(p.numel() for p in compressed_model.parameters())
compression_ratio = compressed_params / original_params
print(f"压缩比: {compression_ratio:.3f}")
动态低秩调整示例:
class AdaptiveLowRankModule(nn.Module):
def __init__(self, in_features, out_features, max_rank=64):
super().__init__()
self.in_features = in_features
self.out_features = out_features
self.max_rank = max_rank
self.current_rank = max_rank
# 初始化最大秩的分解矩阵
self.A = nn.Parameter(torch.randn(in_features, max_rank) * 0.01)
self.B = nn.Parameter(torch.randn(max_rank, out_features) * 0.01)
# 重要性分数
self.importance_scores = nn.Parameter(torch.ones(max_rank))
def forward(self, x):
# 基于重要性分数选择活跃的秩
if self.training:
# 训练时使用所有秩
active_A = self.A[:, :self.current_rank]
active_B = self.B[:self.current_rank, :]
else:
# 推理时基于重要性阈值选择
threshold = torch.quantile(self.importance_scores, 0.5)
mask = self.importance_scores > threshold
active_A = self.A[:, mask]
active_B = self.B[mask, :]
return x @ active_A @ active_B
def adjust_rank(self, target_rank):
"""动态调整秩"""
self.current_rank = min(target_rank, self.max_rank)
def compute_importance(self):
"""计算每个秩维度的重要性"""
with torch.no_grad():
# 基于权重的L2范数计算重要性
importance_A = torch.norm(self.A, dim=0)
importance_B = torch.norm(self.B, dim=1)
self.importance_scores.data = importance_A * importance_B
9. 不同方法对比分析
9.1 性能对比
| 方法 | 参数压缩比 | 精度保持率 | 训练时间 | 推理速度提升 | 内存减少 |
|---|---|---|---|---|---|
| 标准LoRA | 0.1-1% | 95-99% | 1.2x | 1.0x | 20-50% |
| QLoRA | 0.05-0.5% | 90-95% | 0.8x | 1.5x | 60-80% |
| SVD分解 | 10-50% | 85-95% | 1.0x | 1.2-2.0x | 30-70% |
| Linformer | 参数不变 | 90-98% | 0.6x | 2-5x | 50-90% |
| 混合方法 | 1-10% | 92-97% | 0.9x | 1.5-3x | 40-80% |
详细分析:
LoRA系列:
- 优势: 微调效果好,易于实现和部署
- 劣势: 参数压缩有限,主要用于微调场景
- 适用场景: 大模型的下游任务微调
SVD分解:
- 优势: 理论基础扎实,压缩效果显著
- 劣势: 可能损失重要信息,需要careful调参
- 适用场景: 模型部署前的一次性压缩
注意力机制优化:
- 优势: 对长序列处理效果显著
- 劣势: 改变了模型架构,可能影响某些任务性能
- 适用场景: 长文档处理,序列建模任务
9.2 计算效率对比
FLOPs分析:
def calculate_flops(method, seq_len, d_model, rank=None):
"""计算不同方法的浮点运算次数"""
if method == "standard_attention":
# Q@K^T + softmax + @V
return seq_len * seq_len * d_model + seq_len * seq_len * d_model
elif method == "lora":
# 额外的低秩计算
return 2 * seq_len * rank * d_model
elif method == "linformer":
k = rank # 投影维度
return seq_len * k * d_model + seq_len * k * d_model
elif method == "svd_compressed":
return seq_len * rank * d_model + rank * seq_len * d_model
# 示例计算
seq_len = 512
d_model = 768
rank = 64
methods = ["standard_attention", "lora", "linformer", "svd_compressed"]
for method in methods:
flops = calculate_flops(method, seq_len, d_model, rank)
print(f"{method}: {flops:,} FLOPs")
内存使用模式:
| 方法 | 峰值内存 | 梯度内存 | 激活内存 | 总体优化 |
|---|---|---|---|---|
| 原始模型 | 100% | 100% | 100% | 基线 |
| LoRA | 102% | 15% | 100% | 显著 |
| QLoRA | 25% | 8% | 100% | 极佳 |
| SVD压缩 | 60% | 60% | 100% | 良好 |
| 分块处理 | 30% | 30% | 50% | 极佳 |
9.3 适用场景对比
任务类型适应性:
| 任务类型 | LoRA | SVD | Linformer | 混合方法 | 推荐指数 |
|---|---|---|---|---|---|
| 文本分类 | ✅ | ✅ | ✅ | ✅ | ★★★★★ |
| 问答系统 | ✅ | ⚠️ | ✅ | ✅ | ★★★★☆ |
| 文本生成 | ✅ | ⚠️ | ⚠️ | ✅ | ★★★☆☆ |
| 长文档处理 | ⚠️ | ✅ | ✅ | ✅ | ★★★★★ |
| 实时推理 | ⚠️ | ✅ | ✅ | ✅ | ★★★★☆ |
部署环境适应性:
def recommend_method(
model_size_gb,
available_memory_gb,
latency_requirement_ms,
accuracy_tolerance_percent
):
"""
根据部署条件推荐最适合的低秩分解方法
"""
recommendations = []
# 内存约束
memory_ratio = available_memory_gb / model_size_gb
if memory_ratio < 0.3:
recommendations.append(("QLoRA", "内存极度受限"))
elif memory_ratio < 0.6:
recommendations.append(("LoRA + SVD", "内存受限"))
else:
recommendations.append(("标准LoRA", "内存充足"))
# 延迟要求
if latency_requirement_ms < 50:
recommendations.append(("SVD + 量化", "极低延迟"))
elif latency_requirement_ms < 200:
recommendations.append(("Linformer", "低延迟"))
else:
recommendations.append(("标准方法", "延迟要求宽松"))
# 精度要求
if accuracy_tolerance_percent < 5:
recommendations.append(("保守LoRA", "高精度要求"))
else:
recommendations.append(("激进压缩", "可接受精度损失"))
return recommendations
# 使用示例
recommendations = recommend_method(
model_size_gb=13,
available_memory_gb=8,
latency_requirement_ms=100,
accuracy_tolerance_percent=3
)
print("推荐方案:", recommendations)
成本效益分析:
import numpy as np
import matplotlib.pyplot as plt
def cost_benefit_analysis():
"""成本效益分析可视化"""
methods = ['原始模型', 'LoRA', 'QLoRA', 'SVD', 'Linformer', '混合方法']
# 标准化指标 (0-1, 越高越好)
accuracy = [1.0, 0.97, 0.93, 0.90, 0.95, 0.94]
speed = [0.5, 0.5, 0.7, 0.8, 0.9, 0.75]
memory_efficiency = [0.1, 0.8, 0.95, 0.7, 0.6, 0.85]
ease_of_use = [1.0, 0.9, 0.8, 0.6, 0.7, 0.5]
# 计算综合分数 (可调整权重)
weights = [0.4, 0.3, 0.2, 0.1] # [精度, 速度, 内存, 易用性]
scores = []
for i in range(len(methods)):
score = (weights[0] * accuracy[i] +
weights[1] * speed[i] +
weights[2] * memory_efficiency[i] +
weights[3] * ease_of_use[i])
scores.append(score)
return methods, scores
methods, scores = cost_benefit_analysis()
for method, score in zip(methods, scores):
print(f"{method}: 综合得分 {score:.3f}")
10. 总结与展望
10.1 技术总结
低秩因子分解作为大模型压缩和高效微调的核心技术,已经在理论和实践两个层面都取得了显著进展:
理论贡献:
- 建立了参数效率和模型性能之间的数学关系
- 证明了许多深度学习模型权重矩阵的内在低秩特性
- 发展了适应不同应用场景的分解算法和优化策略
实践价值:
- LoRA等方法使得大模型微调的门槛大幅降低
- 注意力机制的低秩优化解决了长序列处理的计算瓶颈
- 模型压缩技术使得大模型在资源受限环境下的部署成为可能
技术成熟度:
- LoRA已经成为大模型微调的标准做法
- 各种优化变体(QLoRA、AdaLoRA等)不断涌现
- 工业界已有大量成功的部署案例
10.2 当前挑战
理论挑战:
- 最优秩的理论确定: 缺乏通用的理论指导来确定不同层的最优秩
- 精度损失的界限分析: 需要更精确的理论分析来预测性能损失
- 动态调整策略: 如何在训练过程中动态优化分解结构
实践挑战:
- 任务适应性: 不同类型任务对低秩分解的敏感性差异很大
- 超参数调优: 需要大量实验来找到最优的配置
- 长期稳定性: 分解后模型的长期训练稳定性需要验证
工程挑战:
- 硬件适配: 不同硬件平台对低秩运算的优化程度不同
- 框架集成: 需要更好的工具链来简化低秩分解的应用
- 版本管理: 分解后的模型版本管理和更新机制
10.3 未来发展方向
算法创新方向:
-
自适应低秩学习:
- 开发能够自动确定最优秩的算法
- 研究基于任务特性的动态调整机制
- 探索非均匀分解策略
-
混合压缩技术:
- 低秩分解 + 剪枝 + 量化的联合优化
- 基于注意力模式的智能压缩
- 层级化的渐进式压缩方法
-
硬件感知优化:
- 针对不同计算平台的定制化分解
- 考虑内存访问模式的优化分解
- 边缘设备友好的超轻量化方法
应用扩展方向:
-
多模态模型:
- 图像-文本多模态模型的低秩优化
- 跨模态注意力的高效计算
- 模态特定的分解策略
-
长序列处理:
- 百万级token序列的高效处理
- 基于内容的动态分解
- 流式处理的低秩优化
-
领域适应:
- 科学计算领域的专用优化
- 实时系统的超低延迟方法
- 隐私保护场景的安全分解
工具生态建设:
# 未来可能的统一接口设计
from advanced_peft import UnifiedLowRank
# 自动配置的低秩优化
optimizer = UnifiedLowRank.auto_configure(
model=model,
task_type="text_generation",
hardware_profile="A100",
performance_target={
"accuracy_retention": 0.95,
"memory_reduction": 0.7,
"speed_improvement": 2.0
}
)
# 一键应用
optimized_model = optimizer.apply(model)
研究热点预测:
- 神经架构搜索与低秩分解结合: 自动设计适合低秩优化的网络结构
- 联邦学习中的低秩技术: 在分布式环境下的参数高效更新
- 可解释性研究: 理解低秩分解对模型行为和决策过程的影响
- 鲁棒性分析: 分解后模型对对抗攻击和分布偏移的抗性研究
10.4 实践建议
选择策略建议:
- 新手入门: 从标准LoRA开始,逐步探索其他方法
- 资源受限: 优先考虑QLoRA和SVD压缩的组合
- 长序列任务: Linformer和Performer是首选
- 生产部署: 混合方法通常能提供最好的综合效果
最佳实践:
- 逐步压缩: 采用渐进式的压缩策略,避免激进优化导致的性能崩塌
- 验证导向: 建立完善的评估体系,确保压缩后的模型满足业务需求
- 持续监控: 在生产环境中持续监控模型性能,及时调整优化策略

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献62条内容
已为社区贡献62条内容

所有评论(0)