大模型压缩:3-大模型量化剖析-不同方式对比-原理解析-实战案例,RTN、LLM.int8、SmoothQuant、AWQ、AutoAWQ、GPTQ、FP8
大模型量化技术概述与实战 本文系统介绍了大语言模型(LLM)量化技术,涵盖从基础概念到前沿算法的全面解析。主要内容包括: 核心概念: 量化目标:降低显存占用和计算成本,同时保持模型性能 量化方式:训练感知量化(QAT)与训练后量化(PTQ) 量化粒度:逐层、逐通道、逐组等不同粒度选择 量化对象:权重、激活值和KV缓存的量化策略差异 经典算法剖析: RTN:最基础的量化方法,适合小模型 LLM.in
大模型压缩:3-大模型量化剖析-不同方式对比-原理解析-实战案例,RTN、LLM.int8、SmoothQuant、AWQ、AutoAWQ、GPTQ、FP8
目录
概述
随着大语言模型(LLM)参数规模的不断增长,模型部署面临着巨大的内存和计算挑战。量化技术通过降低模型参数和激活值的数值精度,在保持模型性能的同时显著减少内存占用和加速推理过程,已成为大模型实用化部署的关键技术。
量化的核心观察:
- 权重易量化,激活难量化
- 激活中,不同Tokens的数据分布表现出一致的趋势,异常值出现在固定的一些通道,不同Tokens的相同通道值方差较小
- 4bit及以下权重量化,权重中有0.1%~1%的权重对量化误差影响很大,对应激活中的异常通道
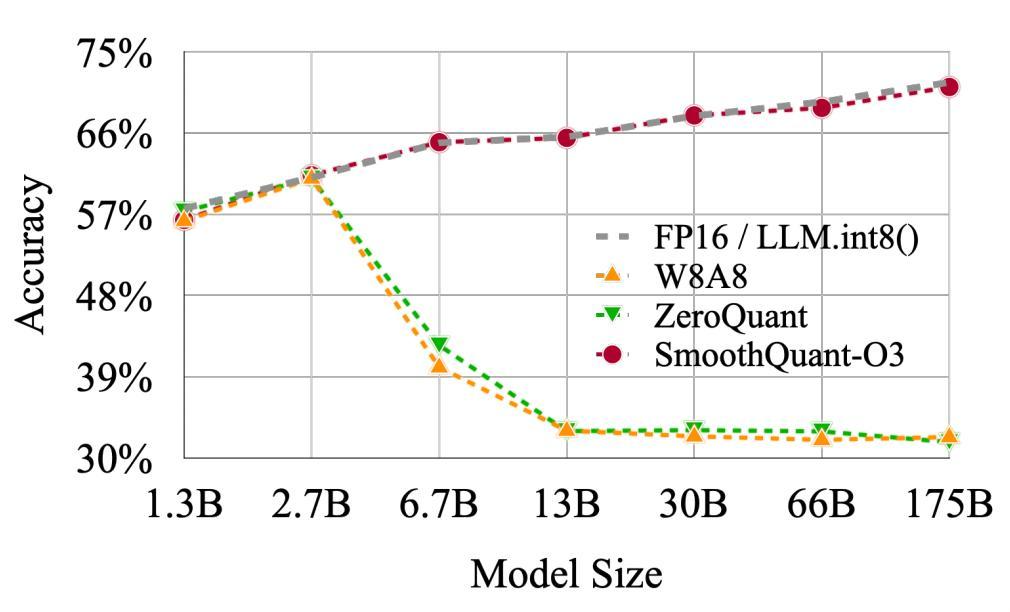
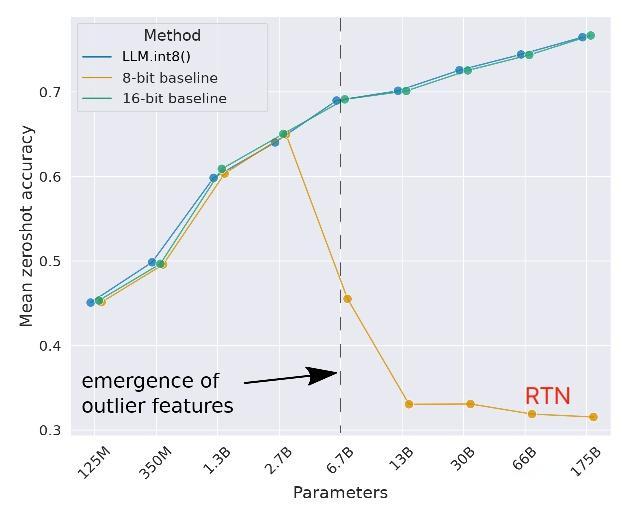
- 模型超过6.7B,RTN w8a8精度下降明显
- FP8由于数据点的分布不同于Int的均匀分布,量化效果较好,但需要结合实际的数据分布来看
基本概念
数值表示格式
FP32 (32位单精度浮点数)
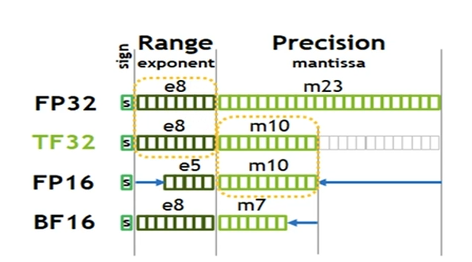
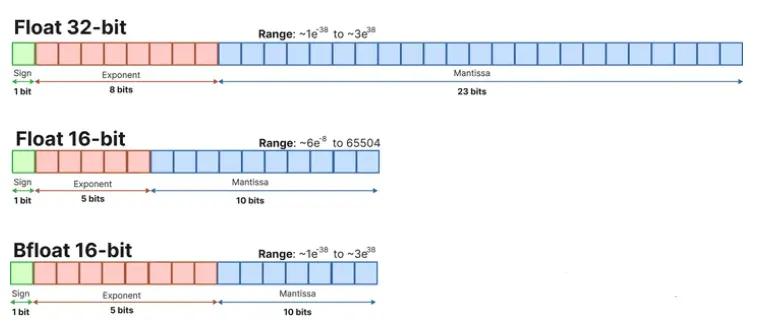
- 表示方式: 1位符号位 + 8位指数位 + 23位尾数位
- 范围(Range): 大约 1 0 − 38 10^{-38} 10−38 到 1 0 38 10^{38} 1038
- 精度(Precision): 大约 2 − 23 2^{-23} 2−23 ≈ 1 0 − 7 10^{-7} 10−7
- 应用: 常用于需要高精度的训练和推理任务
其中,指数位的范围计算:8位指数位可以表示0-255,减去偏置127,实际范围是-126到127,因此范围约为 2 127 ≈ 1 0 38 2^{127} ≈ 10^{38} 2127≈1038。
其他精度格式对比
- TF32: 1位符号位 + 8位指数位 + 10位尾数位
- FP16: 1位符号位 + 5位指数位 + 10位尾数位
- BF16: 1位符号位 + 8位指数位 + 7位尾数位
- INT8: 1位符号位 + 7位数值位
- INT4: 1位符号位 + 3位数值位
量化定义与目标
量化是以较低的推理精度损失,将高精度(通常为float32或者大量可能的离散值)的浮点型参数近似为有限个离散值(通常为int8)的过程。
量化公式:
Q = Clip ( Round ( X − zero_point scale ) + zero_point , Q min , Q max ) Q = \text{Clip}(\text{Round}(\frac{X - \text{zero\_point}}{\text{scale}}) + \text{zero\_point}, Q_{\min}, Q_{\max}) Q=Clip(Round(scaleX−zero_point)+zero_point,Qmin,Qmax)
其中:
- X X X:原始浮点数值
- scale \text{scale} scale:量化缩放因子
- zero_point \text{zero\_point} zero_point:零点偏移
- Q min , Q max Q_{\min}, Q_{\max} Qmin,Qmax:量化数值类型的最小值和最大值
反量化公式:
X = scale × ( Q − zero_point ) X = \text{scale} \times (Q - \text{zero\_point}) X=scale×(Q−zero_point)
量化目标:
- 在不明显损失效果的前提下,降低显存占用
- 提高推理速度
- 减少模型存储空间
量化方式
QAT (Quantization-Aware Training)
- 特点: 训练时引入量化感知
- 方法: 通过近似微分rounding operation操作,进行retrain或finetune
- 缺点: 资源消耗大,LLM很少采用
- 适用性: 适合从头训练或有充足计算资源的场景
PTQ (Post-Training Quantization)
- 特点: 训练后量化
- 方法: 直接量化pre-trained model,需要少量数据校正
- 优点: 资源消耗小,实施简便
- 现状: LLM的主流量化方法
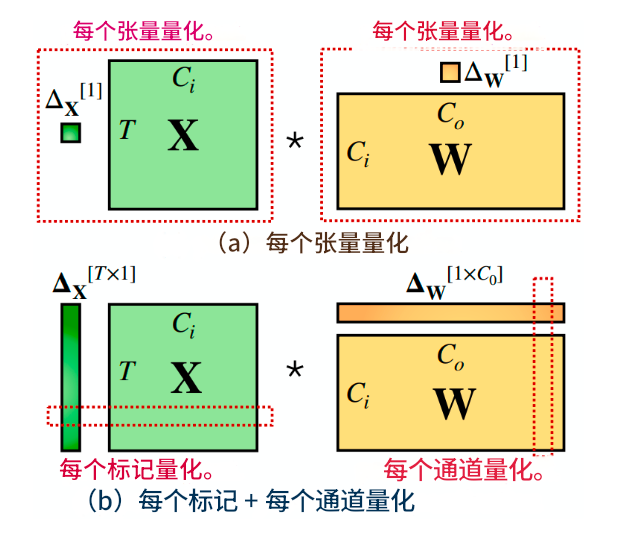
量化粒度
根据量化参数 s s s(缩放因子)和 z z z(零点偏移)的共享范围,量化方法可以分为:
逐层量化 (Per-tensor)
- 整个张量共享同一组量化参数
- 实现简单,硬件友好
- 量化精度相对较低
逐通道量化 (Per-token & Per-channel)
- 按通道或token维度设置量化参数
- 能更好适应数据分布差异
- 硬件实现复杂度增加
逐组量化 (Per-group/Group-wise)
- 将通道分组,每组共享量化参数
- 平衡了精度和实现复杂度
- 是当前主流的量化粒度选择
量化对象
Weights (权重)
- 特点: 分布相对稳定,易于量化
- 方法: 可采用更激进的量化策略(如4bit甚至更低)
Activations (激活值)
- 特点: 存在离群值,量化难度大
- 挑战: 离群值会显著影响量化精度
KV Cache (键值缓存)
- 重要性: 在长序列推理中占用大量内存
- 策略: 通常采用较保守的量化方法
其他常见概念
- 静态量化: 通过校准数据离线获取量化参数
- 动态量化: 在线推理时动态计算量化参数
- 对称量化: zero-point=0的量化方式
- 非对称量化: zero-point≠0的量化方式
- 仅权重量化: 如AWQ & GPTQ
- 权重激活同时量化: 如SmoothQuant
经典量化算法
1. RTN (Round-to-Nearest)
核心思想
直接通过量化公式对模型参数进行四舍五入量化,是最简单直接的量化方法。
算法原理
量化公式:
q = Clip ( Round ( r s ) + z , q min , q max ) q = \text{Clip}(\text{Round}(\frac{r}{s}) + z, q_{\min}, q_{\max}) q=Clip(Round(sr)+z,qmin,qmax)
其中:
- r r r: 原始浮点值
- s s s: 缩放因子 s = r max − r min q max − q min s = \frac{r_{\max} - r_{\min}}{q_{\max} - q_{\min}} s=qmax−qminrmax−rmin
- z z z: 零点 z = q max − r max s z = q_{\max} - \frac{r_{\max}}{s} z=qmax−srmax
特点分析
- 优点: 实现简单,计算开销小
- 缺点: 对于大模型(一般超过6.7B),精度损失较大
- 适用性: 通常作为baseline使用
性能表现
从实验结果可以看出,RTN方法在模型规模超过6.7B后,精度急剧下降,特别是在8bit量化时表现不佳。
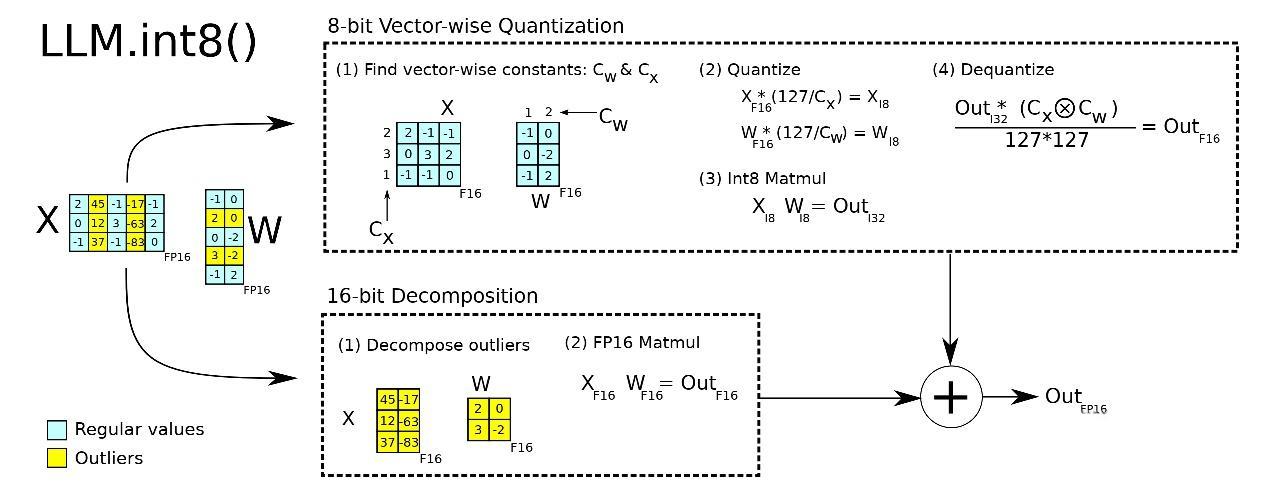
2. LLM.int8()
核心思想
基于对激活值分布的深入观察,发现激活中存在离群值(Emergent Features),这些离群值对量化精度起决定性作用。通过矩阵分解,对绝大部分权重和激活用8bit量化,对离群特征的几个维度保留16bit精度。
算法原理
离群值检测:
对于激活矩阵 X ∈ R T × d X \in \mathbb{R}^{T \times d} X∈RT×d,计算每个特征维度的最大绝对值:
outlier_threshold = α × max ( mean ( ∣ X ∣ ) ) \text{outlier\_threshold} = \alpha \times \max(\text{mean}(|X|)) outlier_threshold=α×max(mean(∣X∣))
混合精度矩阵乘法:
Y = X ⋅ W = ( X fp16 ⋅ W fp16 ) + ( X int8 ⋅ W int8 ) Y = X \cdot W = (X_{\text{fp16}} \cdot W_{\text{fp16}}) + (X_{\text{int8}} \cdot W_{\text{int8}}) Y=X⋅W=(Xfp16⋅Wfp16)+(Xint8⋅Wint8)
其中离群值维度使用FP16精度,其余使用INT8精度。
主要操作流程
- 矩阵分解: 将权重和激活矩阵按离群值分解
- 混合精度计算: 离群值部分用FP16,其余用INT8
- 结果合并: 将两部分计算结果相加
性能特点
- 优点: 能保持与FP16相当的精度,有效降低显存占用
- 缺点: 由于需要额外的FP16计算和数据移动,推理速度比FP16还慢
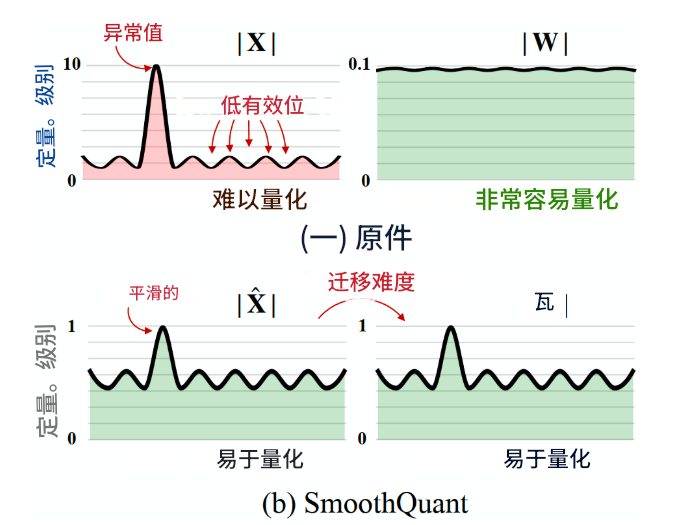
3. SmoothQuant (平滑量化)
核心思想
基于"weights容易量化,activations不易量化"的观察,通过数学等价变换,将激活的难量化特性转移到权重上,使得weights和activations都相对容易量化。
数学原理
对于线性层计算 Y = X ⋅ W Y = X \cdot W Y=X⋅W,引入平滑因子 S S S:
Y = X ⋅ W = ( X ⋅ S − 1 ) ⋅ ( S ⋅ W ) = X ~ ⋅ W ~ Y = X \cdot W = (X \cdot S^{-1}) \cdot (S \cdot W) = \tilde{X} \cdot \tilde{W} Y=X⋅W=(X⋅S−1)⋅(S⋅W)=X~⋅W~
其中:
- S = diag ( s 1 , s 2 , . . . , s d ) S = \text{diag}(s_1, s_2, ..., s_d) S=diag(s1,s2,...,sd) 为对角矩阵
- 平滑因子: s j = max ( X j ) α / max ( W j ) 1 − α s_j = \max(X_j)^{\alpha} / \max(W_j)^{1-\alpha} sj=max(Xj)α/max(Wj)1−α
- α \alpha α 是平衡参数,通常取0.5
关键观察
- 权重易量化: INT8甚至INT4量化权重不会显著降低准确性
- 激活异常值问题: 激活异常值比普通值大约100倍,导致量化困难
- 异常值固定性: 异常值持续出现在固定通道中
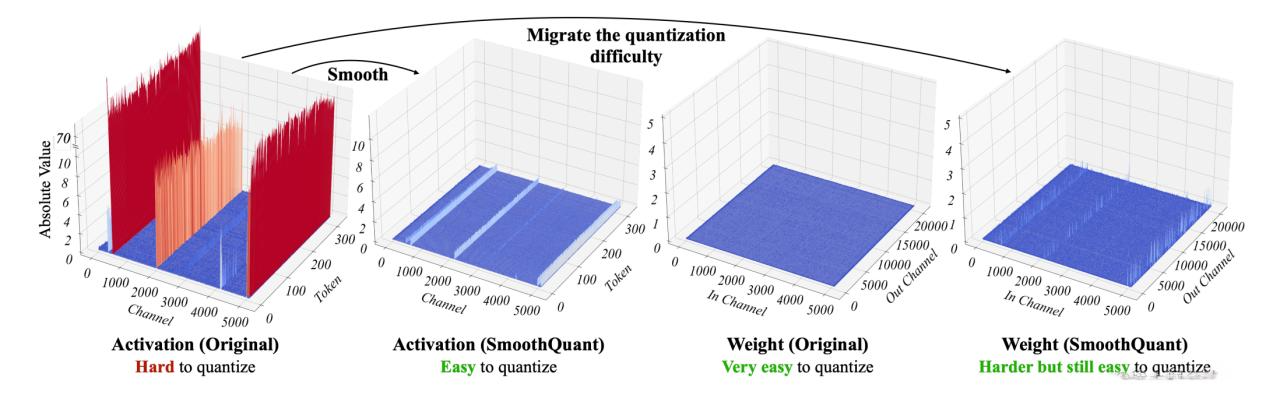
算法流程
- 离线阶段: 使用校准数据计算平滑因子 S S S
- 权重预处理: W ~ = S ⋅ W \tilde{W} = S \cdot W W~=S⋅W
- 推理阶段: X ~ = X ⋅ S − 1 \tilde{X} = X \cdot S^{-1} X~=X⋅S−1,然后进行W8A8量化计算
性能表现
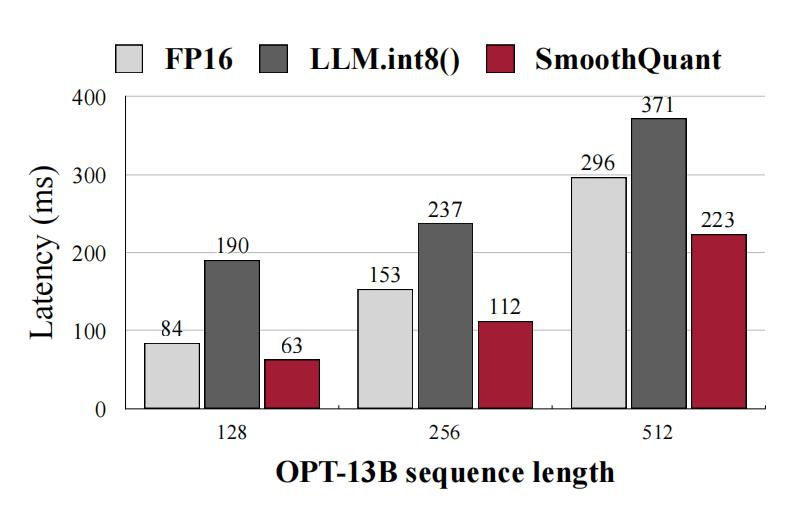
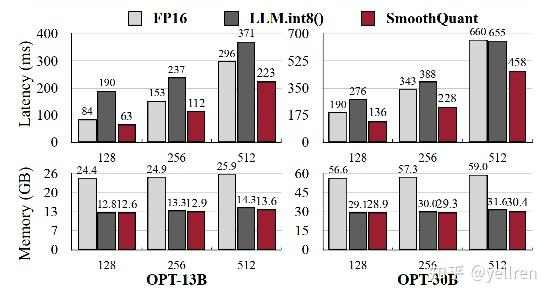
- 优点: W8A8量化,相比FP16量化损失较小,加速约1.4倍,显存减少一半
- 缺点: 不适合更低bit的量化(如4bit)
4. AWQ (激活感知权重量化)
核心思想
并非所有权重都同等重要,只有0.1%~1%的权重显著重要。通过保护这些重要权重,可以有效降低量化误差。重要权重对应于大激活值,它们关联着更重要的特征。
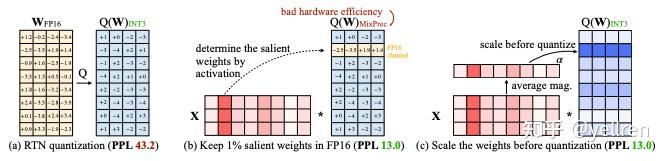
数学原理
权重重要性评估:
I c = 1 N ∑ i = 1 N ∣ X i , c ∣ I_c = \frac{1}{N} \sum_{i=1}^{N} |X_{i,c}| Ic=N1i=1∑N∣Xi,c∣
其中 I c I_c Ic表示第 c c c个通道的重要性, X i , c X_{i,c} Xi,c表示第 i i i个样本在第 c c c个通道的激活值。
缩放因子计算:
s c = ( I c median ( I ) ) α s_c = (\frac{I_c}{\text{median}(I)})^{\alpha} sc=(median(I)Ic)α
权重缩放:
W ~ : , c = s c ⋅ W : , c \tilde{W}_{:,c} = s_c \cdot W_{:,c} W~:,c=sc⋅W:,c
算法步骤
- 重要性计算: 基于校准数据计算每个通道的激活值重要性
- 缩放因子优化: 使用网格搜索找到最优的 α \alpha α参数
- 权重预缩放: 按重要性对权重进行预缩放
- 量化: 对缩放后的权重进行4bit量化
优势特点
- 避免过拟合: 相比GPTQ,不会过拟合校准数据
- 数据效率: 使用更少的校准数据
- 精度保持: 4bit量化下仍能保持较好精度
5. AutoAWQ
产品定位
AutoAWQ是基于AWQ算法的易于使用的4bit量化模型包,是MIT LLM-AWQ的改进版本。
性能优势
- 相比FP16,速度提升3倍,内存需求降低3倍
- 在不同batch size下表现稳定
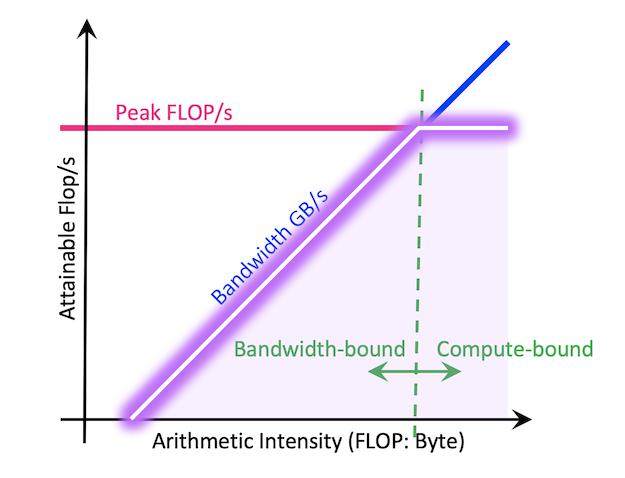
Memory-bound vs Compute-bound分析
基于Roofline模型,LLM推理可分为两种情况:
Memory-bound场景:
- 发生在小batch size情况下
- 性能受内存带宽限制
- 量化模型由于权重更小,可以更快地在内存中移动,获得加速
Compute-bound场景:
- 发生在大batch size情况下
- 性能受浮点计算峰值限制
- W4A16量化可能不会获得加速,因为反量化开销会减慢整体速度
Roofline模型公式:
Attainable FLOP/s = min ( Peak FLOP/s , Arithmetic Intensity × Peak GB/s ) \text{Attainable FLOP/s} = \min(\text{Peak FLOP/s}, \text{Arithmetic Intensity} \times \text{Peak GB/s}) Attainable FLOP/s=min(Peak FLOP/s,Arithmetic Intensity×Peak GB/s)
6. GPTQ (梯度训练后量化)
理论基础
GPTQ基于Optimal Brain Quantization(OBQ)理论,而OBQ源于Optimal Brain Surgeon(OBS)剪枝方法。
核心思想
按行迭代进行权重量化,部分权重量化后,利用近似二阶导数信息更新未量化的权重,从而弥补已量化权重带来的精度损失。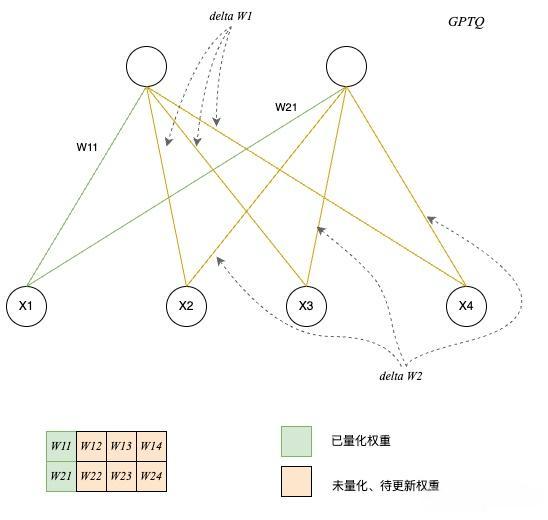
数学原理
目标函数:
arg min w ^ ∥ W X − W ^ X ∥ 2 2 \underset{\hat{\mathbf{w}}}{\arg\min} \|\mathbf{W}\mathbf{X} - \hat{\mathbf{W}}\mathbf{X}\|_2^2 w^argmin∥WX−W^X∥22
其中 W ^ \hat{\mathbf{W}} W^是量化后的权重矩阵。
Hessian矩阵近似:
H = 2 X X T \mathbf{H} = 2\mathbf{X}\mathbf{X}^T H=2XXT
权重更新公式:
当量化第 q q q个权重时,其他权重的更新为:
w i = w i − h i q h q q ⋅ ( w q − w ^ q ) , ∀ i > q w_i = w_i - \frac{h_{iq}}{h_{qq}} \cdot (w_q - \hat{w}_q), \quad \forall i > q wi=wi−hqqhiq⋅(wq−w^q),∀i>q
算法流程
- Hessian计算: 计算 H = 2 X X T \mathbf{H} = 2\mathbf{X}\mathbf{X}^T H=2XXT
- Cholesky分解: H = L L T \mathbf{H} = \mathbf{L}\mathbf{L}^T H=LLT
- 逐行量化:
- 量化当前权重
- 根据二阶信息更新其他权重
- 更新Hessian矩阵
性能特点
- 优点: 4bit量化精度损失可忽略,可扩展至2bit甚至三元量化,小批量推理加速明显
- 缺点: 可能过拟合校准数据,计算开销相对较大
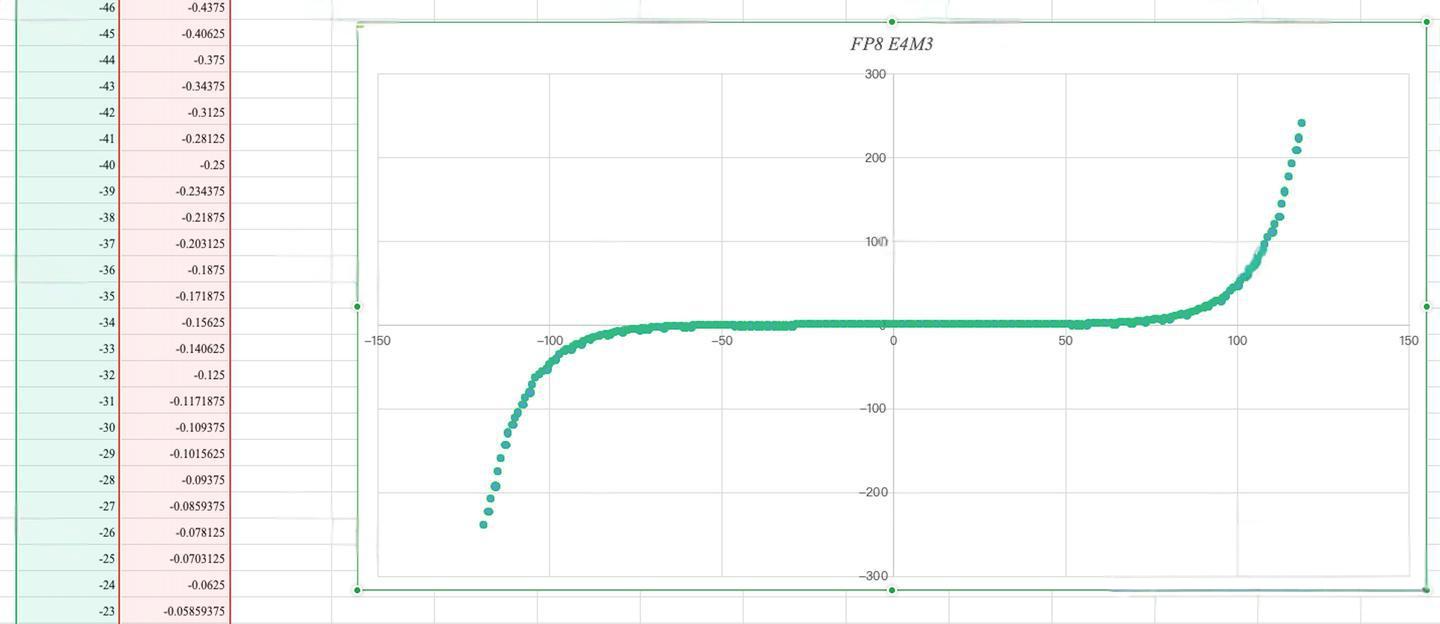
7. FP8量化
基本原理
FP8采用浮点数表示,相比INT8的均匀分布,更适合神经网络中常见的正态分布数据。
计算公式
Q = Clip ( Round ( X X max × Q max ) , Q min , Q max ) Q = \text{Clip}(\text{Round}(\frac{X}{X_{\max}} \times Q_{\max}), Q_{\min}, Q_{\max}) Q=Clip(Round(XmaxX×Qmax),Qmin,Qmax)
数据格式
FP8 E4M3 (4位指数,3位尾数):
- 范围: 约 6 × 1 0 − 8 6 \times 10^{-8} 6×10−8到 4.4 × 1 0 5 4.4 \times 10^{5} 4.4×105
- 适合权重量化
FP8 E5M2 (5位指数,2位尾数):
- 范围更大,精度稍低
- 适合激活量化
与INT8对比
- INT8优势: 更适合权重,适合均匀分布数据,硬件支持更好
- FP8优势: 更适合激活,适合正态分布数据,"中间密两头稀"的分布特性
FP8的数据点分布呈现"中间密两头稀"的特点,更符合神经网络激活值的统计特性,因此在激活量化上通常优于INT8。
量化算法对比分析
| 算法 | 量化位宽 | 量化对象 | 精度保持 | 推理速度 | 内存占用 | 实现复杂度 | 适用模型规模 |
|---|---|---|---|---|---|---|---|
| RTN | 8/4bit | W | 低 | 快 | 低 | 简单 | <6.7B |
| LLM.int8() | 8bit | W+A | 高 | 慢 | 中等 | 中等 | 所有规模 |
| SmoothQuant | 8bit | W+A | 中等 | 中等 | 低 | 中等 | >6.7B |
| AWQ | 4bit | W | 高 | 快 | 很低 | 中等 | 所有规模 |
| GPTQ | 4/3/2bit | W | 高 | 快 | 很低 | 复杂 | 所有规模 |
| FP8 | 8bit | W+A | 高 | 快 | 低 | 中等 | 所有规模 |
详细性能对比
精度保持能力
- LLM.int8(): 通过混合精度保持与FP16相当的精度
- AWQ/GPTQ: 4bit量化下精度损失最小
- SmoothQuant: 8bit下精度较好,但不适合更低位宽
- FP8: 在激活量化上优于INT8
- RTN: 大模型下精度损失明显
推理速度
- AWQ/GPTQ: Memory-bound场景下加速最明显
- FP8: 硬件支持好时速度快
- SmoothQuant: 中等加速比
- RTN: 理论上最快,但精度限制
- LLM.int8(): 由于混合精度计算,速度反而较慢
内存效率
- 4bit量化(AWQ/GPTQ): 内存减少约75%
- 8bit量化: 内存减少约50%
- 混合精度方法: 内存减少30-50%
实战案例
环境配置
# 安装必要的库
pip install torch transformers accelerate
pip install auto-gptq autoawq
pip install bitsandbytes # for LLM.int8()
# 安装量化工具
pip install optimum
RTN量化实战
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers import BitsAndBytesConfig
# RTN 8bit量化配置
quantization_config = BitsAndBytesConfig(
load_in_8bit=True,
llm_int8_enable_fp32_cpu_offload=True
)
# 加载模型
model_name = "meta-llama/Llama-2-7b-hf"
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 加载量化模型
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=quantization_config,
device_map="auto",
torch_dtype=torch.float16
)
# 推理测试
def test_inference(model, tokenizer, prompt):
inputs = tokenizer(prompt, return_tensors="pt")
with torch.no_grad():
outputs = model.generate(
inputs.input_ids,
max_length=100,
do_sample=True,
temperature=0.7
)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
# 性能评估
import time
prompt = "The future of artificial intelligence is"
start_time = time.time()
result = test_inference(model, tokenizer, prompt)
inference_time = time.time() - start_time
print(f"Inference time: {inference_time:.2f}s")
print(f"Generated text: {result}")
AWQ量化实战
from awq import AutoAWQForCausalLM
from transformers import AutoTokenizer
import torch
# AWQ量化配置
def quantize_model_awq(model_path, quant_path):
# 加载模型
model = AutoAWQForCausalLM.from_pretrained(model_path)
tokenizer = AutoTokenizer.from_pretrained(model_path)
# 准备校准数据
def prepare_calibration_data():
data = []
# 可以使用WikiText-2或其他数据集
sample_texts = [
"The quick brown fox jumps over the lazy dog.",
"Machine learning is a subset of artificial intelligence.",
# 添加更多样本...
]
for text in sample_texts:
tokens = tokenizer(text, return_tensors='pt')
data.append(tokens.input_ids)
return data
# 执行量化
model.quantize(
tokenizer,
quant_config={
"zero_point": True,
"q_group_size": 128,
"w_bit": 4,
"version": "GEMM"
},
calib_data=prepare_calibration_data()
)
# 保存量化模型
model.save_quantized(quant_path)
tokenizer.save_pretrained(quant_path)
return model, tokenizer
# 使用量化模型
def load_and_test_awq(quant_path):
model = AutoAWQForCausalLM.from_quantized(quant_path)
tokenizer = AutoTokenizer.from_pretrained(quant_path)
# 推理测试
prompt = "Explain quantum computing in simple terms:"
inputs = tokenizer(prompt, return_tensors="pt")
with torch.no_grad():
outputs = model.generate(
inputs.input_ids,
max_length=200,
do_sample=True,
temperature=0.7,
top_p=0.9
)
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
return result
# 执行量化
model_path = "meta-llama/Llama-2-7b-hf"
quant_path = "./llama2-7b-awq"
print("Starting AWQ quantization...")
quantized_model, tokenizer = quantize_model_awq(model_path, quant_path)
# 测试量化模型
print("Testing quantized model...")
result = load_and_test_awq(quant_path)
print(f"Generated text: {result}")
GPTQ量化实战
from auto_gptq import AutoGPTQForCausalLM, BaseQuantizeConfig
from transformers import AutoTokenizer
import torch
def quantize_with_gptq(model_name, quantized_model_dir):
# 量化配置
quantize_config = BaseQuantizeConfig(
bits=4, # 4bit量化
group_size=128, # 组大小
desc_act=False, # 是否使用激活值排序
)
# 加载模型
model = AutoGPTQForCausalLM.from_pretrained(
model_name,
quantize_config
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 准备校准数据集
import datasets
def prepare_calibration_dataset():
dataset = datasets.load_dataset('wikitext', 'wikitext-2-raw-v1', split='train')
examples = []
for i in range(min(128, len(dataset))): # 使用128个样本
line = dataset[i]['text']
if len(line) > 50: # 过滤短文本
tokens = tokenizer(
line,
truncation=True,
max_length=512,
return_tensors='pt'
)
examples.append(tokens.input_ids)
return examples
# 执行量化
print("Preparing calibration data...")
examples = prepare_calibration_dataset()
print("Starting GPTQ quantization...")
model.quantize(examples)
# 保存量化模型
print("Saving quantized model...")
model.save_quantized(quantized_model_dir)
tokenizer.save_pretrained(quantized_model_dir)
return model, tokenizer
def evaluate_gptq_model(quantized_model_dir):
# 加载量化模型
model = AutoGPTQForCausalLM.from_quantized(
quantized_model_dir,
device="cuda:0"
)
tokenizer = AutoTokenizer.from_pretrained(quantized_model_dir)
# 性能测试
test_prompts = [
"The benefits of renewable energy include",
"In the field of machine learning,",
"Climate change is caused by"
]
results = []
for prompt in test_prompts:
inputs = tokenizer(prompt, return_tensors="pt").to("cuda:0")
with torch.no_grad():
outputs = model.generate(
inputs.input_ids,
max_length=150,
num_return_sequences=1,
temperature=0.8,
do_sample=True
)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
results.append(generated_text)
return results
# 执行GPTQ量化流程
model_name = "meta-llama/Llama-2-7b-hf"
quantized_dir = "./llama2-7b-gptq"
# 量化模型
model, tokenizer = quantize_with_gptq(model_name, quantized_dir)
# 评估结果
print("Evaluating quantized model...")
results = evaluate_gptq_model(quantized_dir)
for i, result in enumerate(results):
print(f"Result {i+1}: {result}\n")
性能对比测试
import torch
import time
import psutil
import numpy as np
from transformers import AutoModelForCausalLM, AutoTokenizer
class QuantizationBenchmark:
def __init__(self):
self.results = {}
self.test_prompts = [
"The future of artificial intelligence is",
"Explain the theory of relativity in simple terms:",
"What are the main challenges in climate change?"
]
def measure_memory_usage(self):
"""测量当前内存使用情况"""
process = psutil.Process()
memory_info = process.memory_info()
return memory_info.rss / 1024 / 1024 / 1024 # 转换为GB
def measure_inference_time(self, model, tokenizer, prompt, num_runs=5):
"""测量推理时间"""
times = []
for _ in range(num_runs):
inputs = tokenizer(prompt, return_tensors="pt")
if torch.cuda.is_available():
inputs = {k: v.cuda() for k, v in inputs.items()}
torch.cuda.synchronize() if torch.cuda.is_available() else None
start_time = time.time()
with torch.no_grad():
outputs = model.generate(
inputs['input_ids'],
max_length=150,
do_sample=True,
temperature=0.7,
pad_token_id=tokenizer.eos_token_id
)
torch.cuda.synchronize() if torch.cuda.is_available() else None
end_time = time.time()
times.append(end_time - start_time)
return {
'mean_time': np.mean(times),
'std_time': np.std(times),
'min_time': np.min(times),
'max_time': np.max(times)
}
def evaluate_model_quality(self, model, tokenizer, prompt):
"""评估模型生成质量"""
inputs = tokenizer(prompt, return_tensors="pt")
if torch.cuda.is_available():
inputs = {k: v.cuda() for k, v in inputs.items()}
with torch.no_grad():
outputs = model.generate(
inputs['input_ids'],
max_length=200,
do_sample=True,
temperature=0.7,
top_p=0.9,
pad_token_id=tokenizer.eos_token_id
)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
return generated_text
def benchmark_quantization_methods(self):
"""对比不同量化方法"""
model_name = "microsoft/DialoGPT-small" # 使用较小模型进行演示
# 1. FP16基线
print("Testing FP16 baseline...")
model_fp16 = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token
if torch.cuda.is_available():
model_fp16 = model_fp16.cuda()
# 测量FP16性能
fp16_memory = self.measure_memory_usage()
fp16_times = self.measure_inference_time(model_fp16, tokenizer, self.test_prompts[0])
fp16_quality = self.evaluate_model_quality(model_fp16, tokenizer, self.test_prompts[0])
self.results['FP16'] = {
'memory_gb': fp16_memory,
'inference_time': fp16_times,
'sample_output': fp16_quality
}
# 2. INT8量化 (使用bitsandbytes)
print("Testing INT8 quantization...")
from transformers import BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(
load_in_8bit=True,
llm_int8_enable_fp32_cpu_offload=False
)
model_int8 = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=quantization_config,
device_map="auto" if torch.cuda.is_available() else None
)
int8_memory = self.measure_memory_usage()
int8_times = self.measure_inference_time(model_int8, tokenizer, self.test_prompts[0])
int8_quality = self.evaluate_model_quality(model_int8, tokenizer, self.test_prompts[0])
self.results['INT8'] = {
'memory_gb': int8_memory,
'inference_time': int8_times,
'sample_output': int8_quality
}
# 3. INT4量化 (模拟,实际项目中使用AWQ/GPTQ)
print("Testing INT4 quantization...")
quantization_config_4bit = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4"
)
model_int4 = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=quantization_config_4bit,
device_map="auto" if torch.cuda.is_available() else None
)
int4_memory = self.measure_memory_usage()
int4_times = self.measure_inference_time(model_int4, tokenizer, self.test_prompts[0])
int4_quality = self.evaluate_model_quality(model_int4, tokenizer, self.test_prompts[0])
self.results['INT4'] = {
'memory_gb': int4_memory,
'inference_time': int4_times,
'sample_output': int4_quality
}
return self.results
def print_comparison_report(self):
"""打印对比报告"""
if not self.results:
print("No benchmark results available. Run benchmark_quantization_methods() first.")
return
print("\n" + "="*80)
print("QUANTIZATION PERFORMANCE COMPARISON REPORT")
print("="*80)
print(f"{'Method':<10} {'Memory(GB)':<12} {'Avg Time(s)':<12} {'Speedup':<10} {'Memory Saved':<12}")
print("-"*80)
baseline_time = self.results['FP16']['inference_time']['mean_time']
baseline_memory = self.results['FP16']['memory_gb']
for method, result in self.results.items():
memory_gb = result['memory_gb']
avg_time = result['inference_time']['mean_time']
speedup = baseline_time / avg_time if avg_time > 0 else 0
memory_saved = (baseline_memory - memory_gb) / baseline_memory * 100
print(f"{method:<10} {memory_gb:<12.2f} {avg_time:<12.3f} {speedup:<10.2f}x {memory_saved:<12.1f}%")
print("\nSample Outputs:")
print("-"*80)
for method, result in self.results.items():
print(f"\n{method}:")
print(f"Output: {result['sample_output'][:100]}...")
# 运行基准测试
benchmark = QuantizationBenchmark()
results = benchmark.benchmark_quantization_methods()
benchmark.print_comparison_report()
高级量化技术实现
class AdvancedQuantization:
def __init__(self):
pass
def smooth_quant_implementation(self, model, calibration_data, alpha=0.5):
"""SmoothQuant算法实现"""
print("Implementing SmoothQuant...")
# 收集激活统计信息
activation_scales = {}
weight_scales = {}
model.eval()
with torch.no_grad():
for batch in calibration_data:
# 前向传播收集激活值
def hook_fn(name):
def hook(module, input, output):
if name not in activation_scales:
activation_scales[name] = []
# 计算输入激活的最大值
activation_scales[name].append(input[0].abs().max(dim=0)[0])
return hook
# 注册钩子
hooks = []
for name, module in model.named_modules():
if isinstance(module, torch.nn.Linear):
hook = module.register_forward_hook(hook_fn(name))
hooks.append(hook)
# 前向传播
_ = model(**batch)
# 移除钩子
for hook in hooks:
hook.remove()
# 计算平滑因子
smooth_scales = {}
for name, module in model.named_modules():
if isinstance(module, torch.nn.Linear) and name in activation_scales:
# 计算激活和权重的最大值
act_max = torch.stack(activation_scales[name]).max(dim=0)[0]
weight_max = module.weight.abs().max(dim=0)[0]
# 计算平滑因子
smooth_scale = (act_max.pow(alpha) / weight_max.pow(1-alpha)).clamp(min=1e-5)
smooth_scales[name] = smooth_scale
# 应用平滑
with torch.no_grad():
# 缩放权重
module.weight.data = module.weight.data * smooth_scale.unsqueeze(0)
return model, smooth_scales
def mixed_precision_quantization(self, model, sensitive_layers=None):
"""混合精度量化实现"""
print("Implementing mixed precision quantization...")
if sensitive_layers is None:
sensitive_layers = []
for name, module in model.named_modules():
if isinstance(module, torch.nn.Linear):
if name in sensitive_layers:
# 敏感层保持FP16
module.weight.data = module.weight.data.half()
else:
# 其他层量化到INT8
weight = module.weight.data
# 简单的对称量化
scale = weight.abs().max() / 127
quantized_weight = torch.round(weight / scale).clamp(-128, 127)
# 存储量化参数
module.register_buffer('weight_scale', scale)
module.register_buffer('quantized_weight', quantized_weight.byte())
return model
# 使用示例
advanced_quant = AdvancedQuantization()
# 准备校准数据
def prepare_calibration_data(tokenizer, model_name="wikitext"):
# 这里应该加载实际的校准数据集
sample_texts = [
"The quick brown fox jumps over the lazy dog.",
"Machine learning is transforming the world.",
"Quantum computing represents the future of computation."
]
calibration_data = []
for text in sample_texts:
tokens = tokenizer(text, return_tensors='pt', padding=True, truncation=True)
calibration_data.append(tokens)
return calibration_data
量化选择建议
基于应用场景的选择
1. 生产环境部署
推荐: AWQ或GPTQ 4bit量化
- 原因: 最佳的精度-效率平衡
- 适用: 需要高性能推理的生产系统
# 生产环境配置示例
production_config = {
"quantization_method": "AWQ",
"bits": 4,
"group_size": 128,
"calibration_samples": 512,
"hardware_optimization": True
}
2. 资源受限环境
推荐: GPTQ 3bit或2bit量化
- 原因: 极致的内存压缩
- 适用: 移动设备、边缘计算
# 资源受限配置
resource_limited_config = {
"quantization_method": "GPTQ",
"bits": 3,
"group_size": 64,
"aggressive_optimization": True
}
3. 快速原型开发
推荐: BitsAndBytesConfig 8bit量化
- 原因: 实现简单,精度损失小
- 适用: 研究、实验、快速验证
# 快速开发配置
from transformers import BitsAndBytesConfig
quick_config = BitsAndBytesConfig(
load_in_8bit=True,
llm_int8_enable_fp32_cpu_offload=True
)
模型规模选择指南
| 模型规模 | 推荐方法 | 位宽 | 预期精度损失 | 内存减少 |
|---|---|---|---|---|
| <1B | RTN/INT8 | 8bit | <5% | ~50% |
| 1B-7B | AWQ | 4bit | <2% | ~75% |
| 7B-13B | AWQ/GPTQ | 4bit | ❤️% | ~75% |
| 13B-30B | GPTQ | 4bit | <5% | ~75% |
| >30B | SmoothQuant+GPTQ | 8+4bit | <8% | ~60% |
硬件平台考虑
NVIDIA GPU
- 推荐: AWQ, GPTQ (CUDA优化好)
- 避免: FP8 (需要H100+)
AMD GPU
- 推荐: 标准INT8量化
- 注意: 部分高级量化方法支持有限
CPU推理
- 推荐: ONNX Runtime + INT8
- 考虑: 动态量化减少内存压力
移动端
- 推荐: TensorRT-LLM + INT4
- 关注: 延迟优化vs精度平衡
总结
量化技术是大模型部署的核心技术之一,通过合理选择量化算法和配置,可以在保持模型性能的同时显著降低部署成本。
关键要点:
- 算法选择: AWQ和GPTQ是目前最成熟的4bit量化方案
- 精度平衡: 4bit通常是精度和效率的最佳平衡点
- 硬件适配: 根据部署硬件选择合适的量化方法
- 校准数据: 高质量的校准数据对量化效果至关重要
- 验证测试: 量化后必须进行充分的精度和性能验证
发展趋势:
- 混合精度: 更精细的层级量化策略
- 硬件协同: 与专用AI芯片深度优化
- 动态量化: 运行时自适应量化
- 新数值格式: FP8、INT4等新格式的标准化

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献62条内容
已为社区贡献62条内容

所有评论(0)