HealthGPT: A Medical Large Vision-Language Model for Unifying Comprehension and Generation via Heter
这项工作的意义在于为医学AI提供了一个统一的多模态解决方案,既保持了专门化的优势,又避免了多任务学习中的常见冲突问题。异构知识适配:提出Heterogeneous Low-Rank Adaptation (H-LoRA),将理解和生成任务的知识存储在独立的"插件"中。自回归设计:使用离散token表示统一文本和视觉输出,将理解和生成任务都建模为自回归生成。差异化处理:针对理解任务使用抽象层特征,生
HealthGPT: A Medical Large Vision-Language Model for Unifying Comprehension and Generation via Heterogeneous Knowledge Adaptation

这篇论文介绍了HealthGPT,一个医学大视觉语言模型,我来总结其核心贡献和发现:
主要贡献
- 统一医学多模态框架
首创性:据作者声称,这是首个同时支持医学视觉理解和生成的统一框架
自回归设计:使用离散token表示统一文本和视觉输出,将理解和生成任务都建模为自回归生成
- H-LoRA技术创新
异构知识适配:提出Heterogeneous Low-Rank Adaptation (H-LoRA),将理解和生成任务的知识存储在独立的"插件"中
效率优势:相比MoELoRA,使用4个专家时仅需67%的训练时间,避免了多任务冲突
- 分层视觉感知
差异化处理:针对理解任务使用抽象层特征,生成任务使用具体层特征
动态选择:根据任务类型自动选择合适的视觉特征层级
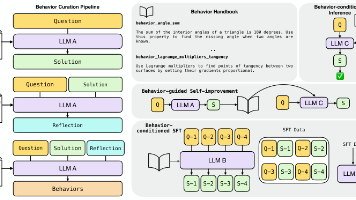
- 三阶段学习策略
阶段1:多模态对齐
阶段2:异构H-LoRA插件适配
阶段3:视觉指令微调
关键发现
- 任务冲突问题
实验证据:混合训练会导致理解和生成性能互相损害(图2显示性能随另一类型数据比例增加而下降)
解决方案:H-LoRA通过任务解耦有效缓解了这一问题
- 性能优势
理解任务:在7个医学视觉理解任务上超越现有医学专用和通用模型
生成任务:在CT/MRI转换、超分辨率等5个生成任务上表现优异
统一优势:HealthGPT-M3(3.8B参数)在医学统一任务上得分61.3,显著超越其他统一模型
- 数据效率
在数据受限的医学场景下仍能实现良好性能
VL-Health数据集包含76.5万理解样本和78.3万生成样本
技术特点
架构设计
基于CLIP-L/14视觉编码器
使用Phi-3-mini和Phi-4作为基础语言模型
VQGAN用于视觉token化
创新机制
硬路由选择:根据任务类型选择相应的H-LoRA模块
矩阵合并:通过可逆矩阵块乘法减少计算开销
专家混合:在单任务内使用多专家机制处理子任务多样性
这项工作的意义在于为医学AI提供了一个统一的多模态解决方案,既保持了专门化的优势,又避免了多任务学习中的常见冲突问题。不过需要注意的是,该工作仍需要在更大规模的临床环境中验证其实用性和安全性。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 2
2 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)