Lanchain读取文件内容并做分割
Lanchain读取文件内容并做分割,将分割后的内容交给向量数据库,用作RAG检索
LangChain 设计了一个 Embeddings 类。该类是一个专为与文本嵌入模型进行交互而设计的类。有许多嵌入模型提供商(如OpenAI、BaiChuan、QianFan、Hugging Face等)这个类旨在为它们提供一个标准接口。
Embeddings类会为文本创建一个向量表示。这很有用,因为这意味着我们可以在向量空间中思考文本,并做一些类似语义搜索的事情,比如在向量空间中寻找最相似的文本片段。
对于Embedding Models我们只需要学会如何去使用就可以,是因为有非常多的模型供应商,如OpenAI、Hugging Face国内的有百川、千帆都提供了标准接口并集成在LangChian框架中,这意味着:Embedding Models已经有人帮我们训练好了,我们只要按照其提供的接口规范,将自然语言文本传入进去,就能得到其对应的向量表示。这显然是非常简单的。
那么在如此多的Embedding Models都可以使用的情况下,应该如何选择呢? 首先,我们在使用形式上把 Embedding Models分为两类:
-
在线Embedding Models,仅提供API服务,需要按照Token付费;
-
开源Embedding Models可以下载到本地免费使用,但在运行过程中会消耗GPU资源。
在线Embedding Models
LangChain接入了国内的Baidu Qianfan,Baichuan Text Embeddings等向量模型,具体支持的平台可以在如下位置进行查看:https://python.langchain.com/docs/integrations/text_embedding/

接下来我们以Baichuan Text Embeddings为例展开讲解。注意:Baichuan Text Embeddings目前仅支持中文文本嵌入。
-
如何使用Baichuan Text Embeddings
-
要使用Baichuan Text Embeddings,首先需要获取API密钥。您可以通过以下步骤获取:
-
访问百川智能官方网站
-
注册并创建一个账户
-
在控制台中申请并获取API密钥
-
获取API Key
-
安装必要的库
pip install langchain_community
-
-
代码示例
from langchain_community.embeddings import BaichuanTextEmbeddings import os # 设置API密钥 key = open('./key_files/baichuan_API-Key.md').read().strip() embeddings = BaichuanTextEmbeddings(api_key=key) # 示例文本 text_1 = "今天天气不错" text_2 = "今天阳光很好" # 获取单个文本的嵌入 query_result = embeddings.embed_query(text_1) print("单个文本嵌入结果:", query_result[:5]) # 只打印前5个元素 # 获取多个文本的嵌入 doc_result = embeddings.embed_documents([text_1, text_2]) print("多个文本嵌入结果:", [vec[:5] for vec in doc_result]) # 每个向量只打印前5个元素 -
BaichuanTextEmbeddings主要参数介绍
-
api_key:这是调用Baichuan Text Embeddings服务的身份验证凭证。只有拥有有效API Key的用户才能访问和使用该模型进行文本嵌入操作。
-
-
BaichuanTextEmbeddings对象主要操作介绍
-
单向量查询(embed_query):法用于将单个文本嵌入为向量表示。它接受一个字符串类型的文本作为输入,并返回该文本对应的向量表示。这个向量是一个高维向量(1024维),包含了文本的语义信息,可以用于后续的各种自然语言处理任务。
-
多向量查询(embed_documents):法用于将多个文本同时嵌入为向量表示。
-
这里模拟一个QA场景,我们定义一个问题,然后定义10条文本作为回答。然后分别对问题和回答各自进行词向量转换:
query = "早睡早起到底是不是保持身体健康的标准?"
sentences = ["早睡早起确实是保持身体健康的重要因素之一。它有助于同步我们的生物钟,并提高睡眠质量。",
"早睡早起可以帮助人们更好地适应自然光周期,从而优化褪黑激素的产生,这种激素是调节睡眠和觉醒的关键。",
"关于提高工作效率,确保在日常饮食中包含充足的蛋白质、复合碳水化合物和健康脂肪非常关键。",
"投资可再生能源项目和推广电动汽车可以显著减少温室气体排放,从而缓解气候变化带来的负面影响。",
"多发性硬化症是一种影响中枢神经系统的自身免疫疾病,导致神经传导受损。虽然与阿尔茨海默症类似,多发性硬化症的主要症状包括疲劳、视觉障碍和肌肉控制问题。",
"今天的天气太好了,可以早点起床去爬山",
"如果下班特别晚的话,我建议你还是打车回家吧",
"提升学术研究质量需侧重于多学科融合和国际合作。研究机构应该鼓励学者之间的交流,通过共享数据和研究方法,来推动科学发现和技术创新。",
"如果你认为我说的没用,那你大可以不必理会。",
"衡量一个人是否成功的标准在于他到底能不能让身边的人都变的优秀"
]使用embed_documents方法,传入sentences列表,得到每条文本的向量表示
sentence_embeddings=embeddings_model.embed_documents(sentences)
通过embed_query方法生成问题的向量表示
embedded_query=embeddings_model.embed_query(query)
开源EMbedding Models
ollama官网进行开源模型下载:https://ollama.com/search?q=embedding
我们以nomic-embed-text向量模型为例:
def ollama_embedding_by_api(text):
res = requests.post(
url = 'http://127.0.0.1:11434/api/embeddings',
json = {
"model":'nomic-embed-text:latest',
'prompt':text
}
)
embedding_list = res.json()['embedding']
return embedding_list代码构建简易RAG
pip install chromadb
pip install requests
import uuid
import chromadb
import requests
import os
from openai import OpenAI
#创建数据库,类似创建一个文件夹
client = chromadb.PersistentClient(path="./db/chroma_demo")
#创建数据集合(库表)
collection = client.get_or_create_collection(name="collection_v2")
#数据集切分-分块处理
def file_chunk_list():
#1.读取文件内容
with open('中医问诊.txt','r',encoding='utf-8') as fp:
data = fp.read()
#2.根据换行切割:将一个病症作为一个列表元素数据
chunk_list = data.split('\n\n')
chunk_list = [chunk for chunk in chunk_list if chunk]
return chunk_list
#数据集向量化封装
def ollama_embedding_by_api(text):
#使用nomic向量模型
# res = requests.post(
# url = 'http://127.0.0.1:11434/api/embeddings',
# json = {
# "model":'nomic-embed-text:latest',
# 'prompt':text
# }
# )
# embedding_list = res.json()['embedding']
# return embedding_list
#使用阿里百炼向量模型(效果超级好)
client = OpenAI(
api_key="sk-52xxxd1e203c6712", # 如果您没有配置环境变量,请在此处用您的API Key进行替换
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" # 百炼服务的base_url
)
completion = client.embeddings.create(
model="text-embedding-v3",
input=text,
dimensions=1024,
encoding_format="float"
)
return completion.data[0].embedding
#deepseek模型调用
def ollama_generate_by_api(prompt):
res = requests.post(
url = 'http://127.0.0.1:11434/api/generate',
json = {
"model":'deepseek-r1:7b',
'prompt':prompt,
'stream':False
}
)
res = res.json()['response']
return res
#整体集成
def initial():
#构造数据
documents = file_chunk_list()
#给每一个数据创建唯一的id标识
ids = [str(uuid.uuid4()) for _ in documents]
embeddings = [ollama_embedding_by_api(text) for text in documents]
#插入数据
collection.add(
ids = ids,
documents=documents,
embeddings=embeddings
)
def run():
qs = '我好像是感冒了,症状是头痛、轻微发烧、肢节酸痛、打喷嚏和流鼻涕。'
qs_embedding = ollama_embedding_by_api(qs)
#n_results表示匹配几个最高相似度的结果
res = collection.query(query_embeddings=[qs_embedding,],query_texts=qs,n_results=2)
result = res['documents'][0]
context = '\n'.join(result)
prompt = f'''你是一个中医问答机器人,任务是根据参考信息回答用户问题,如果你参考信息不足以回答用户问题,请回复不知道,切记不要去杜撰和自由发挥任何内容和信息,请用中文回答,参考信息:{context},来回答问题:{qs},'''
result = ollama_generate_by_api(prompt)
print(result)调用测试:
initial() #执行一次即可
run() #可多次测试1.1 Source 与 data loaders
Source概念指的是RAG架构中所外挂的知识库。正如我们之前所讨论的,因为大模型的原生能力很强,所以它可以识别多种不同的类型的原始数据而不用做额外的处理,而且在实际场景中,私有数据通常也并不是单一的,可以来自多种不同的形式,可以是上百个.csv文件,可以是上千个.json文件,也可以是上万个.pdf文件,同时如果对接到具体的业务,可以是某一个业务流程外放的API,可以是某个网站的实时数据等多种情况。
所以LangChain首先做的就是:将常见的数据格式和数据来源使用LangChain的规范,抽象出一个一个的单独的集成模块,称为文档加载器(Document loaders),用于快速加载某种形式下的文本数据。如下图所示:
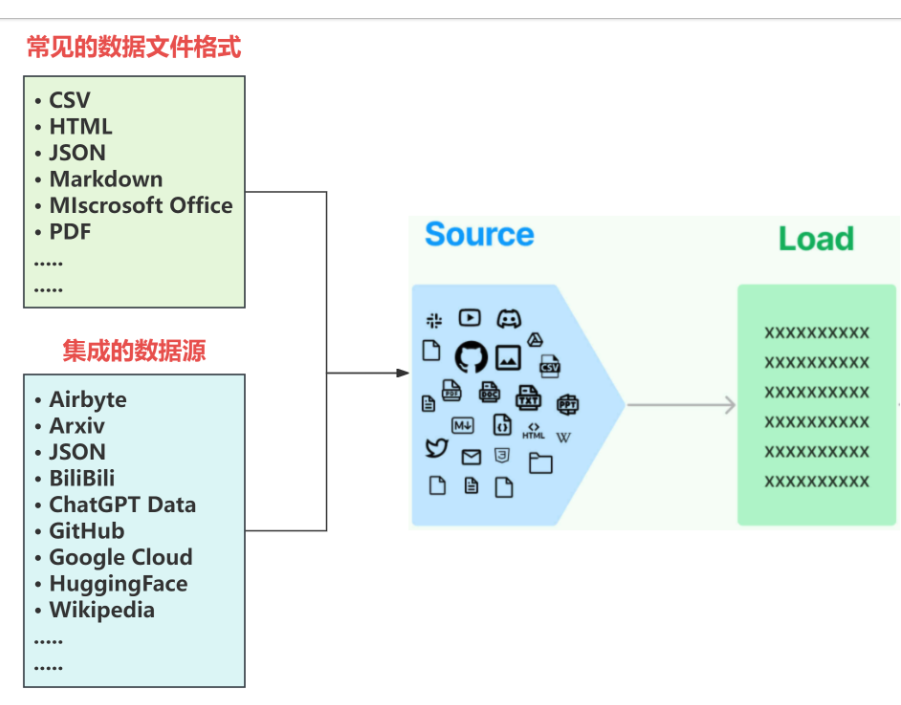
这意味着,我们可以通过调用LangChain抽象好的方法直接处理私有数据,无需手动编写中间的处理流程,并且每一种文档的加载器,在LangChain官方文档中都有基本的调用示例供我们快速上手使用,具体位置如下:https://python.langchain.com/docs/integrations/document_loaders/
我们以加载txt文件为示例:
将文件作为文本读入,并将其全部放入一个文档中,这是最简单的一个文档加载程序,使用方式如下:
from langchain.document_loaders import TextLoader
docs = TextLoader('./data/reason.txt', encoding="utf-8").load() 对于TextLoader,使用.page_content和.metadata去访问数据。
加载csv文件为示例:
逗号分隔值(CSV)文件是⼀种使用逗号分隔值的定界文本文件。文件的每一行是⼀个数据记录。每个记录由⼀个或多个字段组成,字段之间用逗号分隔。LangChain 实现了⼀个 CSV 加载器,可以将 CSV 文件加载为⼀系列 Document 对象。CSV 文件的每⼀行都会被翻译为⼀个文档。
from langchain_community.document_loaders.csv_loader import CSVLoader
file_path = (
"csv_loader.py"
)
loader = CSVLoader(file_path=file_path,encoding="UTF-8")
data = loader.load()
for record in data[:2]:
print(record)加载pdf文件为示例:
这⾥我们使用pypdf 将PDF加载为文档数组,其中每个文档包含页面内容和带有 page 编号的元数据。
pip install pypdf
from langchain_community.document_loaders import PyPDFLoader
file_path = ("pytorch.pdf")
loader = PyPDFLoader(file_path)
#加载并分割 PDF 文件。将其按页分割成多个部分。返回的结果是一个包含每一页内容的列表 pages。
pages = loader.load_and_split()
print(pages[0])1.2 Text Splitters 详解
1.2.1 如何将文本切分成Chunks
分块(Chunking),其实现形式上是将长文档拆分为较小的块的过程,目的是在检索时能够准确地找到最直接和最相关的段落。由于文章通常包含大量不相关信息,在进行分块之前,也常常需要进行一些预处理工作,如文本清洗、停用词处理等。
转回到核心内容来看,一个有效的分块策略,可以确保搜索结果精确地反映用户查询的实际需求。如果分块过小或过大,都可能导致搜索结果不准确或提取不到最相关的内容。理想的文本块应尽可能语义独立,即不过度依赖上下文,这样的文本是语言模型最易于理解的。因此,为文档确定最佳的块大小是确保搜索结果准确性和相关性的关键。这涉及多个决策因素,如块的大小;如果句子太短,模型可能难以理解其意义,且句子越短,包含的有效信息就越少。比较常用的有如下4种不同的方法来优化分块策略:
-
根据句子切分:这种方法按照自然句子边界进行切分,以保持语义完整性。
-
按照固定字符数来切分:这种策略根据特定的字符数量来划分文本,但可能会在不适当的位置切断句子。
-
按固定字符数来切分,结合重叠窗口(overlapping windows):此方法与按字符数切分相似,但通过重叠窗口技术避免切分关键内容,确保信息连贯性。
-
递归方法:通过递归方式动态确定切分点,这种方法可以根据文档的复杂性和内容密度来调整块的大小。
第二种方法(按照字符数切分)和第三种方法(按固定字符数切分结合重叠窗口)主要基于字符进行文本的切分,而不考虑文章的实际内容和语义。这种方式虽简单,但可能会导致主题或语义上的断裂。相对而言,递归方法更加灵活和高效,它结合了固定长度切分和语义分析。通常是首选策略,因为它能够更好地确保每个段落包含一个完整的主题。
这些方法各有优势和局限,选择适当的分块策略取决于具体的应用需求和预期的检索效果。接下来我们依次尝试用常规手段应该如何实现上述几种方法的文本切分。
接下来就具体来上上述4中切分方式的具体实现~
1.2.2 按照句子切分
按照句子切分,其实就是通过标点符号来进行文本切分(分割),这可以直接使用Python的标准库来完成这个任务。一种简单的方法是使用re模块,它提供了正则表达式的支持,可以方便地根据标点符号来分割文本。如下示例中,展示了如何使用re.split()函数来根据中文和英文的标点符号进行文本切分。代码如下:
import re
def split_text_by_punctuation(text):
# 定义一个正则表达式,包括常见的中英文标点
# pattern = r"[。!?。"#$%&'()*+,-/:;<=>@[\]^_`{|}~\s、]+"
pattern = r"[。!?。]+"
# 使用正则表达式进行分割
segments = re.split(pattern, text)
# 过滤掉空字符串
return [segment for segment in segments if segment]这个函数会根据中文和英文的标点符号来分割文本,并移除空字符串。定义好分割函数后,我们可以尝试进行功能测试:
# 文本
text = "春节的脚步越来越近,大街小巷都布满了节日的气氛。商店门口挂满了红灯笼和春联,家家户户都在忙着打扫卫生,准备迎接新的一年。\
小明回到家乡,感受到了浓浓的过年氛围。他在街上走着,看到小朋友们手持烟花棒,欢笑声此起彼伏。\
夜幕降临,整个城市亮起了五彩缤纷的灯光,映照着人们脸上的喜悦与期待。老人们聚在一起,回忆过去,展望未来。\
而年轻人则在夜市享受美食,放松心情。这是一个充满希望和喜悦的时刻,每个人都在以自己的方式庆祝这个特殊的节日。"
# 调用函数进行分割
segments = split_text_by_punctuation(text)
# 使用循环来打印每个chunk
for i, segment in enumerate(segments):
print("Chunk {}: {}".format(i + 1, segment))1.2.3 按照固定字符数切分
如果想按照固定字符数来切分文本,这种方法就不再依赖于标点符号,而是简单地按照给定的字符数来切分文本。我们可以编写一个函数,用来将文本分割成指定长度的片段。代码如下:
def split_text_by_fixed_length(text, length):
# 使用列表推导式按固定长度切分文本
return [text[i:i + length] for i in range(0, len(text), length)]这个函数的作用是根据指定的长度(在这个例子中为100个字符)来切分文本。我们可以根据具体需要调整这个长度。
# 文本
text = "春节的脚步越来越近,大街小巷都布满了节日的气氛。商店门口挂满了红灯笼和春联,家家户户都在忙着打扫卫生,准备迎接新的一年。\
小明回到家乡,感受到了浓浓的过年氛围。他在街上走着,看到小朋友们手持烟花棒,欢笑声此起彼伏。\
夜幕降临,整个城市亮起了五彩缤纷的灯光,映照着人们脸上的喜悦与期待。老人们聚在一起,回忆过去,展望未来。\
而年轻人则在夜市享受美食,放松心情。这是一个充满希望和喜悦的时刻,每个人都在以自己的方式庆祝这个特殊的节日。"
# 定义每个片段的长度
chunk_length = 100
# 调用函数进行分割
result = split_text_by_fixed_length(text, chunk_length)
# 打印结果
for i, segment in enumerate(result):
print(f"Chunk {i+1}: {segment}")然而,这种方法的一个明显缺点是由于仅依据长度进行切分,切分后的片段可能无法保持完整的语义。但并不意味着它不适用于文本切分任务。例如,这种方法非常适合于处理日志文件或代码块,其中文本通常以固定长度或格式出现,或者在处理来自传感器或其他实时数据源的流数据时,固定长度切分可以确保数据被均匀地处理和分析。这些应用场景中,数据的结构和形式通常是预定和规范的,因此即便是按固定长度进行切分,反而会更有利于对数据的理解和使用。
1.2.4 结合重叠窗口的固定字符数切分
重复窗口的意义是:块之间保持一些重叠,以确保语义上下文不会在块之间丢失。在文本处理和其他数据分析领域,"重叠"(overlap)指的是连续数据块之间共享的部分。这种方法特别常见于信号处理、语音分析、自然语言处理等领域,其中数据的连续性和上下文信息非常重要。比如下述代码所示:
def split_text_by_fixed_length_with_overlap(text, length, overlap):
# 使用列表推导式按固定长度及重叠长度切分文本
return [text[i:i + length] for i in range(0, len(text) - overlap, length - overlap)]
# 文本
text = "春节的脚步越来越近,大街小巷都布满了节日的气氛。商店门口挂满了红灯笼和春联,家家户户都在忙着打扫卫生,准备迎接新的一年。\
小明回到家乡,感受到了浓浓的过年氛围。他在街上走着,看到小朋友们手持烟花棒,欢笑声此起彼伏。\
夜幕降临,整个城市亮起了五彩缤纷的灯光,映照着人们脸上的喜悦与期待。老人们聚在一起,回忆过去,展望未来。\
而年轻人则在夜市享受美食,放松心情。这是一个充满希望和喜悦的时刻,每个人都在以自己的方式庆祝这个特殊的节日。"
# 定义每个片段的长度和重叠长度
chunk_length = 100
overlap_length = 30
# 调用函数进行分割
result = split_text_by_fixed_length_with_overlap(text, chunk_length, overlap_length)
# 打印结果
for i, segment in enumerate(result):
print(f"Chunk {i+1}: {segment}")如上所示,每个文本片段长度为100个字符,并且每个片段与下一个片段有30个字符的重叠。这样,每个窗口实际上是在上一个窗口向前移动30个字符的基础上开始的。这种方法特别适用于需要数据重叠以保持上下文连续性的情况,能够较好的在某一个chunk中保存某个完整的语义信息,比如在第一个Chunk中的:'他在街上走着,看到小朋友们手持烟花棒,欢笑'被截断,但是完整的语义能够在Chunk2中被存储:'他在街上走着,看到小朋友们手持烟花棒,欢笑声此起彼伏。' 那么当这条语义信息是有关于Query的上下文,就可以在chunk2中被检索出来。
1.2.5 递归字符文本切分
在前面讲的三种切分方法,虽然简单且更容易理解,但其存在的核心问题是:完全忽视了文档的结构,只是单纯按固定字符数量进行切分。所以难免要更进一步地去做优化,那么一个更进阶的文本分割器应该具备的是:
-
能够将文本分成小的、具有语义意义的块(通常是句子)。
-
可以通过某些测量方法,将这些小块组合成一个更大的块,直到达到一定的大小。
-
一旦达到该大小,请将该块设为自己的文本片段,然后创建具有一些重叠的新文本块,以保持块之间的上下文。
根据上述需求,衍生出来的就是递归字符文本切分器,在langChain中的抽象类为:RecursiveCharacterTextSplitter,同时它也是Langchain的默认文本分割器。
文档切分的可视化工具
我们可以用LangChain提供的文本切分可视化小工具进行直观的理解:https://langchain-text-splitter.streamlit.app/
如上代码所展示的就是RecursiveCharacterTextSplitter类的核心逻辑。所谓的按字符递归分割,就是使用一组分隔符以分层和迭代的方式将输入文本分成更小的块。默认使用[“\n\n” ,"\n" ," ",""] 这四个特殊符号作为分割文本的标记,如果分割文本开始的时候没有产生所需大小或结构的块,那么这个方法会使用不同的分隔符或标准对生成的块递归调用,直到获得所需的块大小或结构。这意味着虽然这些块的大小并不完全相同,但它们仍然会逼近差不多的大小。其中的关键参数:
-
separators:指定分割文本的分隔符
-
chunk_size:被切割字符的最大长度
-
chunk_overlap:如果仅仅使用chunk_size来切割时,前后两段字符串重叠的字符数量。
-
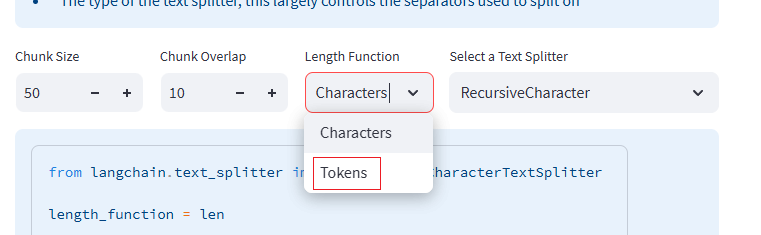
length_function:如何计算块的长度。默认情况下,只计算字符数,也可以选择按照Token。
这里我们可以使用同样的文本进行文本切分测试。示例文本如下所示:
春节的脚步越来越近,大街小巷都布满了节日的气氛。商店门口挂满了红灯笼和春联,家家户户都在忙着打扫卫生,准备迎接新的一年。小明回到家乡,感受到了浓浓的过年氛围。他在街上走着,看到小朋友们手持烟花棒,欢笑声此起彼伏。夜幕降临,整个城市亮起了五彩缤纷的灯光,映照着人们脸上的喜悦与期待。老人们聚在一起,回忆过去,展望未来。而年轻人则在夜市享受美食,放松心情。这是一个充满希望和喜悦的时刻,每个人都在以自己的方式庆祝这个特殊的节日。
同时调整Chunk Size,因为默认的是1000,很明显我们的测试文本长度低于1000,这里我们降低为100,同时将overlap设置为20:
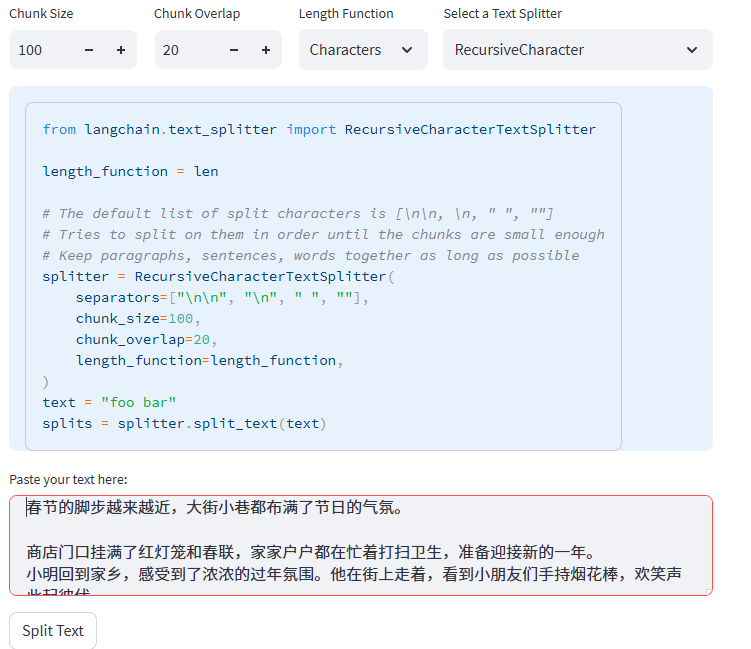
切分结果如下所示,会正常的切分为四个较为完整的chunks。
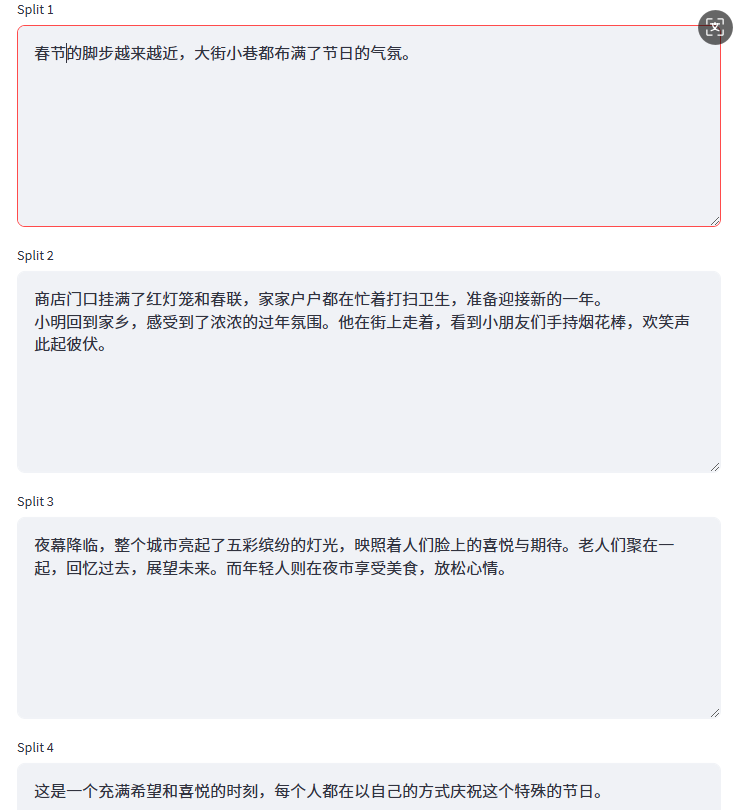
这里我们需要强调的两个关键点是:
-
切分的结果是由
length_function = len决定的,按照设置的切分规则,依次对文本进行分割; -
能不能进行分割,并不是由Chunk Size决定,超出Chunk Size只是触发条件,而真正会不会实际执行分割操作,取决于separator设置的切分符。
比如我们调低Chunk Size为50,再次执行。它会由原来的4个Chunk增加到8个Chunk,这里我们以chunk 4 和 chunk 5 举例说明:
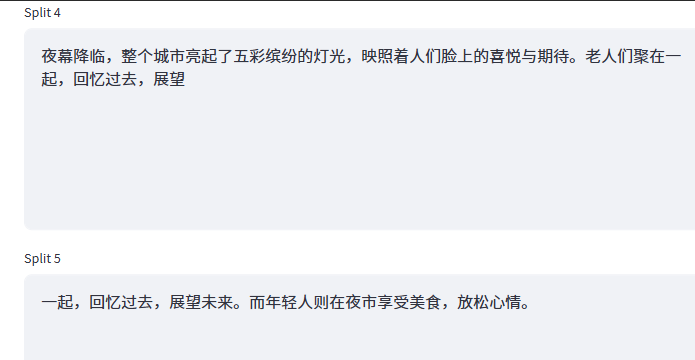
当Chunk Size设置为50时,夜幕降临,整个城市亮起了五彩缤纷的灯光,映照着人们脸上的喜悦与期待。老人们聚在一起,回忆过去,展望展望未来。是超出50个字符,此时就会触发Chunk Overlap。也就说:当某一个片段溢出了Chunk Size设定的值,才会在下一个分片段中触发 Chunk Overlap,没有触发时,就不需要补充上下文,但当触发了以后,补充的上下文不能超过设定的Chunk Overlap,这是一个非常重要的点,一定要理解。
在这种情况下虽然超出了 Chunk Size,但是按照separators=["\n\n", "\n", " ", ""]的规则,没有任何一条命中,所以不能分割。因此我们才说:超出Chunk Size只是触发条件,而能不能分割,取决于separator设置的关键词。
当然,除了按照 length_function = len(即字符长度)来进行切分,也可以按照Token切分,Token和字符大概是1 :4 这样一个比例,原理是一致的,大家可以自行尝试。
1.3 langchain中的Text Splitters设计
我们首先需要明确的是:在RAG流程中,我们不仅仅处理原始字符串,更常见的是处理文档。文档不仅包含我们关注的文本,还包括额外的元数据(文档标题、发布日期、摘要或者作者信息等),而这两点,均在LangChain的Document Loader的设计中通过 Document对象的Page_content和metadata设定中进行了定义。所以TextSplitter的核心不仅仅是为了划分数据块,而是要以一种便于日后检索和提取价值的格式来整理我们的数据。那么这里我们首先要进行探索的就是:如何去接收不同的数据形式,并能够按照预定的切分方式进行切分。
下面我们就具体来看在langchain中对于Text Splitters是如何进行设计和实现的。
CharacterTextSplitter
这是最简单的方法。其基于字符(默认为“”)进行分割,并通过字符数来测量块长度。要使用该方法,需要先进行导入:
# 如果未安装过该模块,需要先进行安装pip install -qU langchain-text-splitters
这里先导入一个测试文本:
from langchain.text_splitter import CharacterTextSplitter
# This is a long document we can split up.
with open("./data/reason.txt", encoding="utf-8") as f:
reason_desc = f.read()split_text进行文本切分:
-
chunk_size: 每个块的最大字符数为 100。
-
chunk_overlap: 相邻两个块之间会有 20 个字符的重叠部分。这是为了确保在处理或分析时,相邻块之间有足够的上下文信息。
#定义的文本分割器实例
text_splitter = CharacterTextSplitter(separator='',
chunk_size = 100,
chunk_overlap=20,)
text_res = text_splitter.split_text(reason_desc)
len(text_res) #查看切分块的个数
text_res[0],text_res[1],text_res[2] #查看每一块的内容split_documents进行切分
要使用split_documents方法,需要的是我们使用文档加载器,将str形式的文本数据先转换为Document对象,如下代码所示:
from langchain.document_loaders import TextLoader
docs = TextLoader('./data/reason.txt', encoding="utf-8").load()
#定义的文本分割器实例
text_splitter = CharacterTextSplitter(separator='',
chunk_size = 100,
chunk_overlap=20,)
text_res = text_splitter.split_documents(docs)
len(text_res) #查看切分块的个数
text_res[0],text_res[1],text_res[2] #查看每一块的内容split_documents与split_text定义的文本分割器实例text_splitter参数是一致的。但不同的是,split_documents其接收的是Document对象,返回的chunks也是Docement对象。
通过上述操作过程不难发现,LangChain通过巧妙的设计通过CharacterTextSplitter这一文档分割器就可以通过separator、chunk_size、chunk_overlap参数的灵活组合,实现了我们在前面。
1.4 综合应用
把向量化流程、数据加载和分块策略应用在LangChain的数据处理流中。
首先,我们通过Document Loaders读取到一个外部的.txt文件。
from langchain.document_loaders import TextLoader
docs = TextLoader('./data/Chinese.txt', encoding="utf-8").load()这份文档中的文本内容覆盖了多个主题,用来增强测试的复杂性。接下来,使用Text Splitters中的RecursiveCharacterTextSplitter进行文本分块:
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(chunk_size=300, chunk_overlap=0)
docs = text_splitter.split_documents(docs)
#查看每一个chunk的内容
for index, doc in enumerate(docs):
print(f"Chunk {index + 1}: {doc.page_content}\n")接下来,通过BaiChuan获取每个Chunk的向量表示:
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(chunk_size=300, chunk_overlap=0)
docs = text_splitter.split_documents(docs)
#查看每一个chunk的内容
for index, doc in enumerate(docs):
print(f"Chunk {index + 1}: {doc.page_content}\n")然后,通过如下代码获取到query的向量表示:
query_embedding = baichuan_embedding_by_api("现在科技创新方面有什么进展?")在有了原始文档和query的向量表示后,我们通过余弦相似度去匹配哪一个Chunk中的内容,与输入的query是最相近的。
import numpy as np
def cosine_similarity(A, B):
# 使用numpy的dot函数计算两个数组的点积
# 点积是向量A和向量B在相同维度上对应元素乘积的和
dot_product = np.dot(A, B)
# 计算向量A的欧几里得范数(长度)
# linalg.norm默认计算2-范数,即向量的长度
norm_A = np.linalg.norm(A)
# 计算向量B的欧几里得范数(长度)
norm_B = np.linalg.norm(B)
# 计算余弦相似度
# 余弦相似度定义为向量点积与向量范数乘积的比值
# 这个比值表示了两个向量在n维空间中的夹角的余弦值
return dot_product / (norm_A * norm_B)# 计算与查询最相近的文档块
similarities = [cosine_similarity(query_embedding, emb) for emb in embeddings]
max_index = np.argmax(similarities) # 找到最高相似性的索引
# 打印最相似的文档块
print(f"The most similar chunk is Chunk {max_index + 1} with similarity {similarities[max_index]}:")
print(docs[max_index].page_content)从输出上看,当query为现在科技创新方面有什么进展?,涉及到原始文档科技创新这一主题时,检索出来的最匹配内容就是存储着科技创新内容的这一个chunk。同样,我们可以继续进行测试,此次提问的query涉及经济问题:
query_embedding = baichuan_embedding_by_api("现在的经济趋势怎么样?")
# 计算与查询最相近的文档块
similarities = [cosine_similarity(query_embedding, emb) for emb in embeddings]
max_index = np.argmax(similarities) # 找到最高相似性的索引
# 打印最相似的文档块
print(f"The most similar chunk is Chunk {max_index + 1} with similarity {similarities[max_index]}:")
print(docs[max_index].page_content)对于经济问题,也能够很好的检索出原始文档中存储经济相关内容的chunk,这样的流程从本质上就是RAG检索的过程,只不过,一个应用级的RAG系统仅通过这样的简单设计肯定是不行的,首先,知识库存储的内容不可能这么少,chunks也不可能只有我们示例中的6个,那么当一个用户的query进入到这个RAG系统,query作为一个向量,要去偌大的知识库中(可能有几万、上千万个chunks)中找到与其最接近、内容最相关的问题,这就变成了一个搜索问题。
如果每个都去一一进行比较,这肯定是不现实的,它的时间复杂度会非常高,那有效的解决办法就是向量数据库,所以向量数据库,解决的核心问题是:如何以一种高效的搜索策略快速的返回检索结果。
以下是使用阿里百炼的向量大模型的操作步骤:
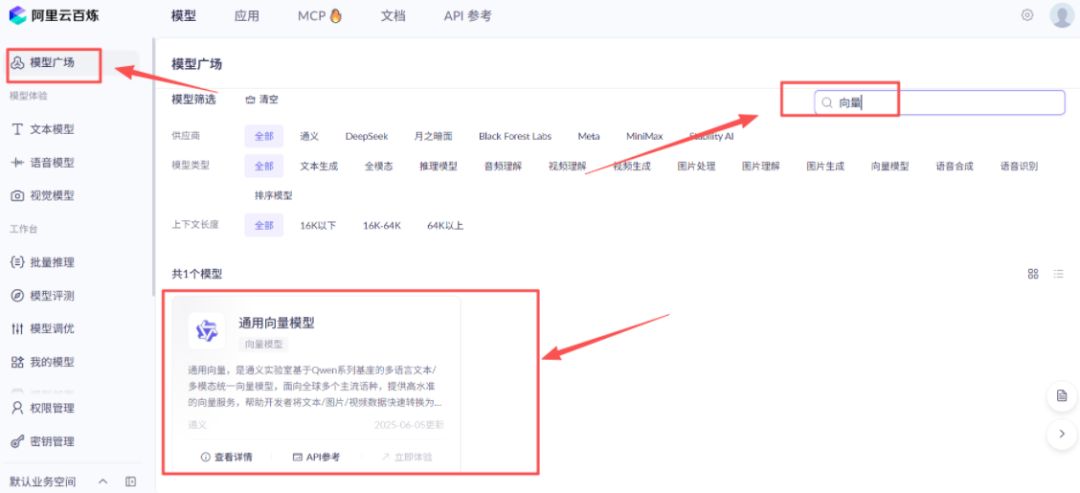
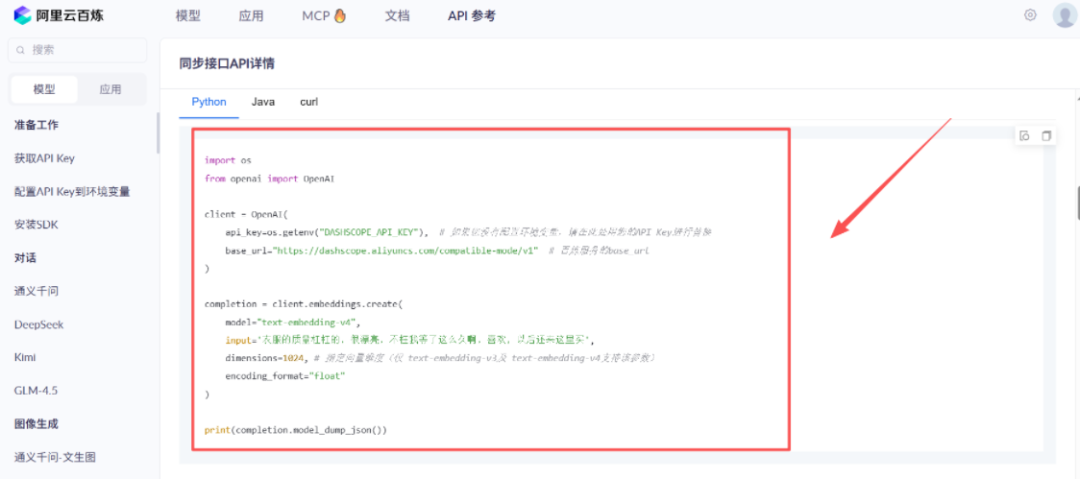
from langchain.document_loaders import TextLoader
import os
from openai import OpenAI
docs = TextLoader('./key_files/Chinese.txt', encoding="utf-8").load()
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(chunk_size=300, chunk_overlap=0)
docs = text_splitter.split_documents(docs)
#查看每一个chunk的内容
for index, doc in enumerate(docs):
print(f"Chunk {index + 1}: {doc.page_content}\n")
def alibailian_embedding_by_api(text):
client = OpenAI(
api_key="xxxx", # 自己的的API Key
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" # 百炼服务的base_url
)
completion = client.embeddings.create(
model="text-embedding-v4",
input=text,
dimensions=1024, # 指定向量维度(仅 text-embedding-v3及 text-embedding-v4支持该参数)
encoding_format="float"
)
return completion.data[0].embedding #这里返回的是一个向量列表,原API中是json,这里要修改一下
embeddings = [alibailian_embedding_by_api(doc.page_content) for doc in docs]

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 11
11 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)