flash attention计算过程的探索和学习
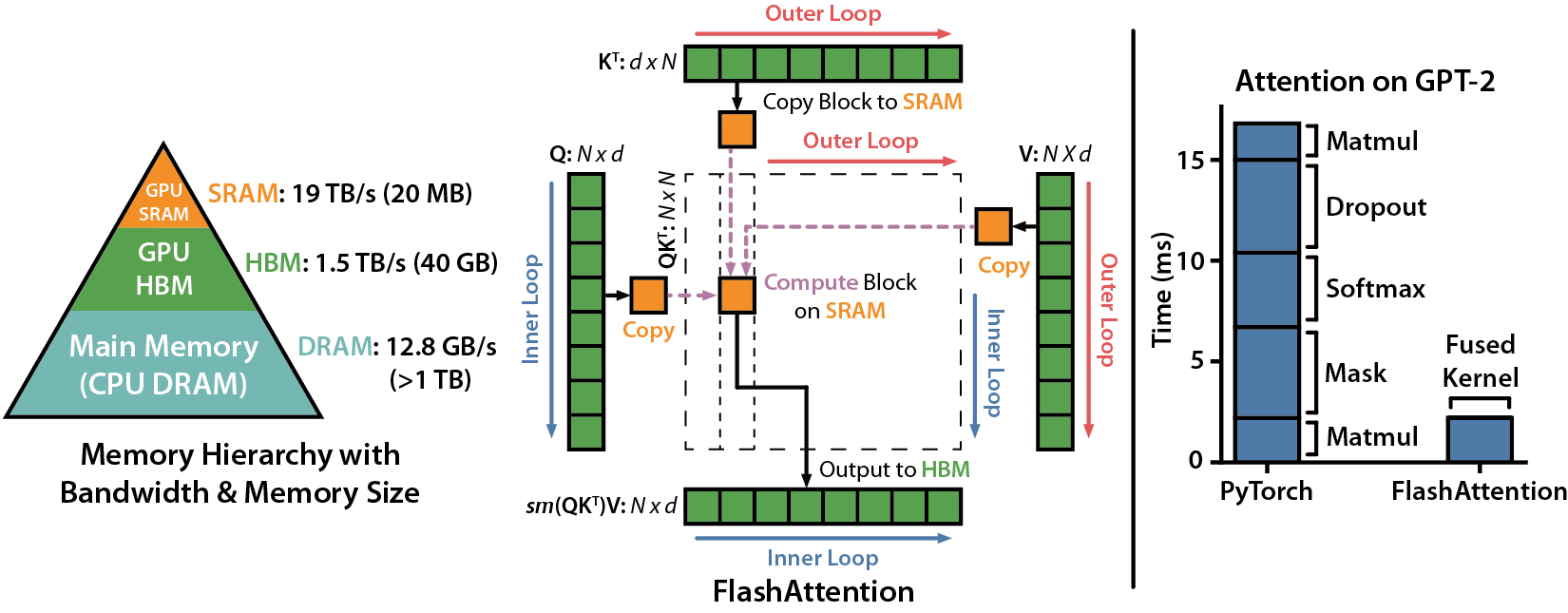
目前(25.9.22)HBM依然是AI热点之一,如下图所示,在GPU存储体系中HBM还不是最快的,最快的SRAM仅20MB左右,其次才是HBM有40GB~90GB,然后是系统内存,可轻松扩展到TB级。对于attention类模型,由于处理的序列很长,20M SRAM不能容纳一个完整的v=qk运算,所以需要引入中间变量暂存当前分块计算过程,在整个计算过程中,分块可能需要多次换入SRAM和从SRAM换
目前(25.9.22)HBM依然是AI热点之一,然而如下图所示,在GPU存储体系中HBM还不是最快的,最快的SRAM仅20MB左右,其次才是HBM有40GB~90GB,然后是系统内存,可轻松扩展到TB级。
对于attention类模型,由于处理的序列很长,20M SRAM不能容纳一个完整的v=qk运算,所以需要引入中间变量暂存当前分块计算过程,在整个计算过程中,分块可能需要多次换入SRAM和从SRAM换出道HBM,在换入和换出过程中,计算可能就处于等待状态。
flash attention通过修改attention计算过程中的softmax分块算法,在完成每个分块后,不再需要从SRAM写回HBM缓存,而是可以一次性跑完,省去了中间变量缓存的过程,虽然引入了部分修正计算,但整体提升了attention的计算效率,缩短了运行时间。
这里尝试分析flash attention的分块算法,探索flash attention提升运行速度的原因。
1 经典attention
假设处理序列长度seq_len = 2,针对查询Q、键K=[K1, K2]和值V,attention计算示例如下。
这里分解计算过程,Q分别与V1和V2相乘后获得S1和S2。
针对S=[S1, S2],分别进行exp处理,获得A1和A2。
依据softmax的公式,需要针对A进行归一化,然后与V对应部分相乘,计算过程如下。
也就是说,需要先计算所有A后,将所有A块求和,再计算O。
实际输入序列max_seq会很长,比如128k,所以不可能在SRAM一次性容纳这么多数据。
所以,经典attention计算引入中间数据S和A,确保softmax计算的正确性。
经典attention算法示例如下

2 flash attention
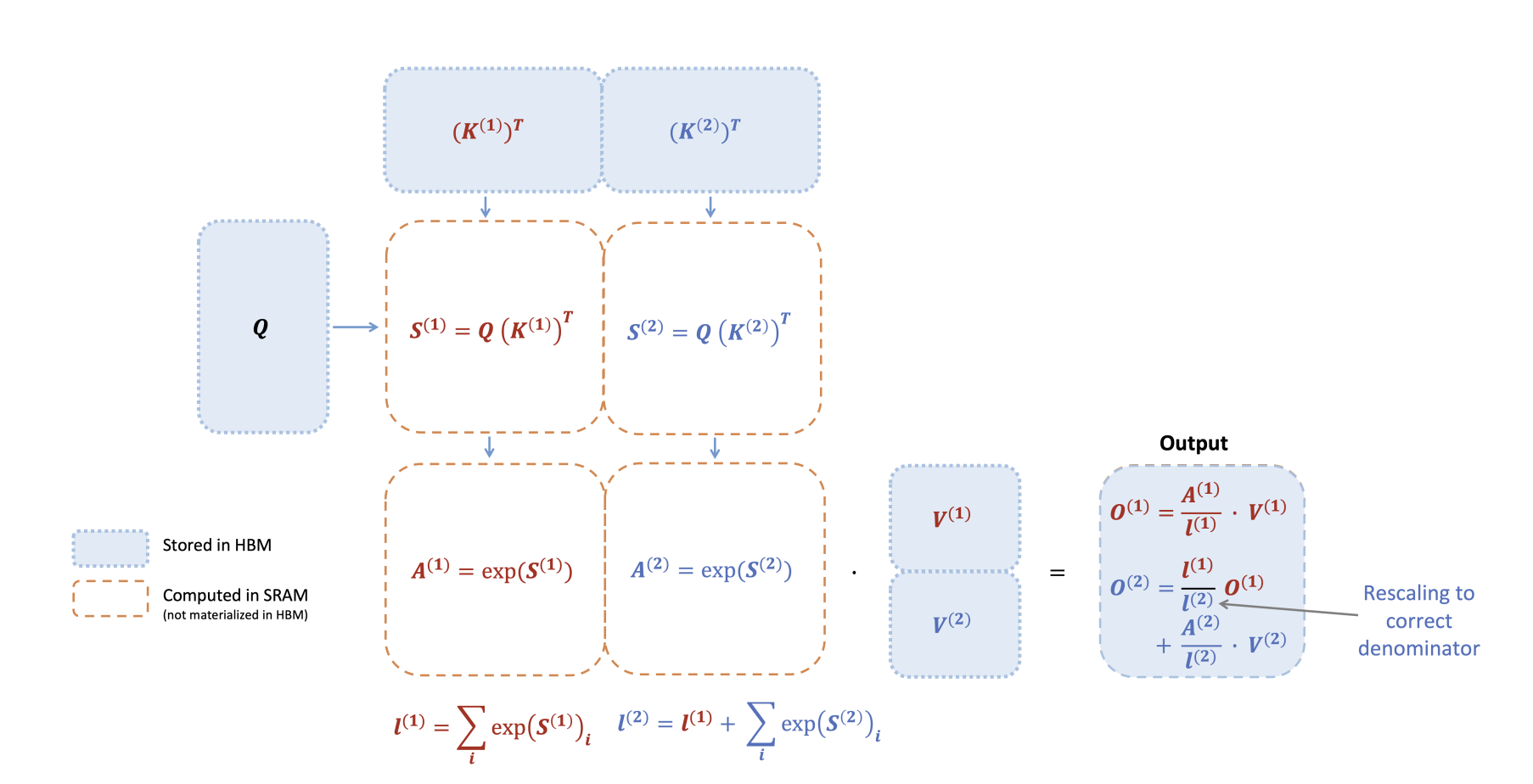
为减少中间数据带来的消耗,flash attention将attention的计算过程做了如下所示的优化。
假设序列长度为3,最终输出O,即如下公式中的O3,计算过程过程如下。
可见,最终计算O3之前,没必要一次性计算出所有的权重l,而是在计算过程中,使用当前最新的权重l_i修正上次l_(i-1)的结果。
所以,这意味着不需要中间变量S和A缓存,因为相邻2次分块计算的数据在SRAM中可以容纳。
flash attention的整体计算过程示意图如下所示。
flash attention算法示例如下

reference
---
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
https://arxiv.org/abs/2205.14135
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
https://arxiv.org/pdf/2307.08691
flash-attention

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 4
4 0
0- 0



 已为社区贡献37条内容
已为社区贡献37条内容

所有评论(0)