(论文速读)SPAI - AI图像检测瓶颈的频谱学习新方法
SPAI,通过光谱学习检测任意分辨率的AI生成图像。不同于传统方法追踪特定模型的伪影,SPAI创新性地建模真实图像的频谱分布作为判别标准。系统采用掩膜频谱学习进行自监督训练,通过频谱重建相似性捕捉生成图像的分布差异,并引入频谱上下文关注机制处理不同分辨率。实验表明,SPAI在13种最新生成模型上平均AUC达91.0%,较现有最佳方法提升5.5%,且对常见图像处理具有鲁棒性。该方法仅需真实图像训练,
论文题目:Any-Resolution AI-Generated Image Detection by Spectral Learning(基于光谱学习的任意分辨率人工智能生成图像检测)
会议:CVPR2025
摘要:最近的研究表明,人工智能模型将光谱伪影引入生成的图像中,并提出了使用标记数据学习捕获它们的方法。然而,这些工件在不同生成模型之间的显著差异阻碍了这些方法推广到训练期间未见的生成器。在这项工作中,我们建立在一个关键思想的基础上,即真实图像的光谱分布构成了人工智能生成的图像检测的不变和高度判别模式。为了在自监督设置下对其进行建模,我们使用频率重建的借口任务使用掩膜频谱学习。由于生成的图像构成了该模型的分布外样本,我们提出了光谱重建相似性来捕获这种差异。此外,我们引入了光谱上下文关注,这使得我们的方法能够有效地捕获任何分辨率图像中的细微光谱不一致。我们的光谱人工智能生成图像检测方法(SPAI)在13种最近的生成方法中实现了比以前最先进的AUC绝对提高5.5%,同时对常见的在线扰动表现出鲁棒性。
源码链接:https://mever-team.github.io/spai
引言
随着DALL-E、Midjourney、Stable Diffusion等AI图像生成工具的普及,区分真实图像和AI生成图像变得越来越困难,也越来越重要。一篇来自CVPR 2025的最新研究提出了一种革命性的检测方法——SPAI(Spectral AI-generated Image Detection),为这一挑战提供了全新的解决思路。
当前AI图像检测面临的困境
传统的AI图像检测方法主要依赖于学习特定生成模型留下的"指纹"或伪影。然而,这种方法存在致命缺陷:
泛化性不足:每个AI生成模型都有其独特的伪影模式。即使是同一类型但版本略有不同的模型,其生成图像的伪影特征也可能截然不同。这意味着在Stable Diffusion上训练的检测器可能完全无法识别DALL-E生成的图像。
维护成本高:随着新生成模型的不断涌现,检测系统需要持续更新训练数据,这在实际应用中几乎不可行。
SPAI的核心洞察:从"追踪伪影"到"建模真实"
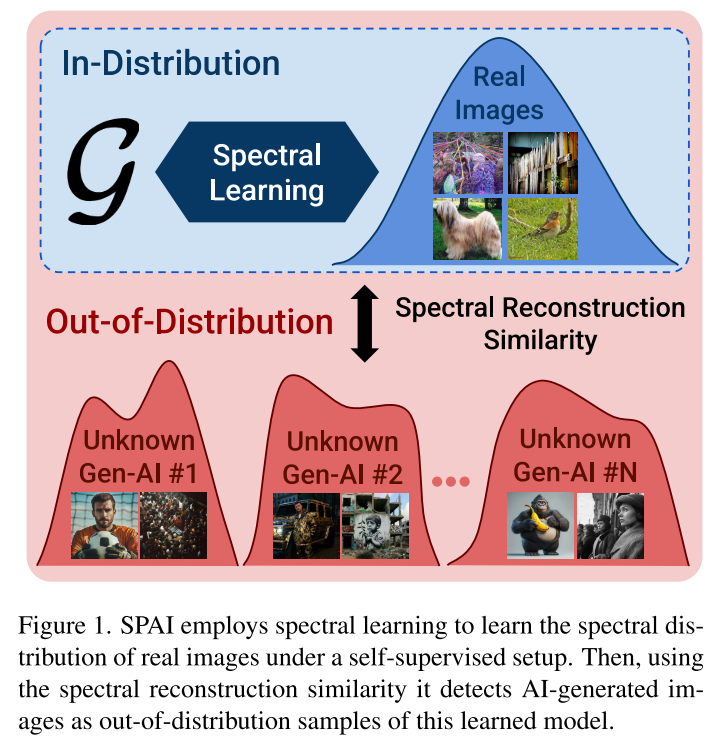
SPAI提出了一个根本性的思路转变:与其试图学习千变万化的AI伪影,不如专注于理解真实图像的本质特征。
研究团队的关键洞察是:真实图像的频谱分布构成了一个稳定且高度判别性的模式。这个分布不会因为新的AI生成模型的出现而改变,因此可以作为检测的"黄金标准"。
基于这一思路,AI生成的图像可以被视为相对于真实图像频谱分布的"异常样本"。
技术创新:四大核心组件
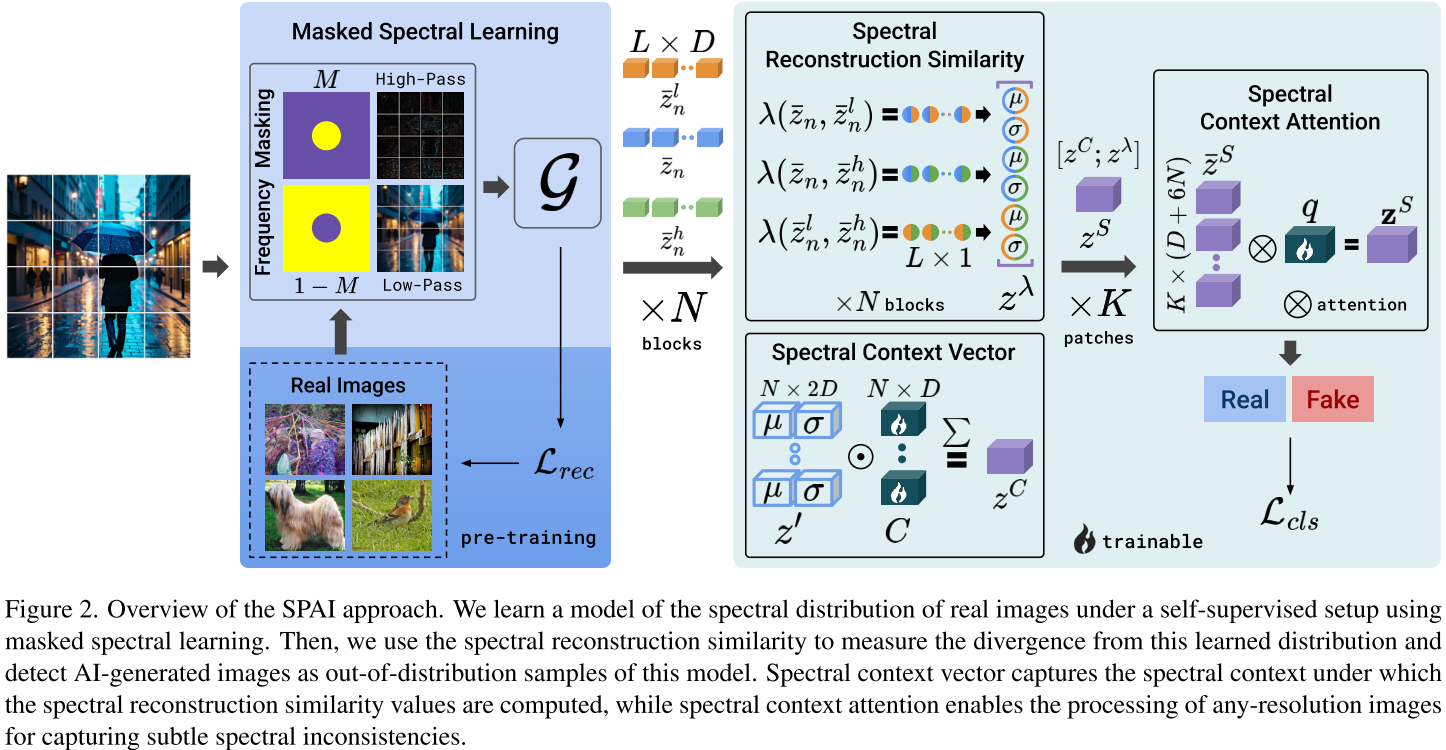
1. Masked Spectral Learning(掩码频谱学习)
SPAI首先通过自监督学习建立真实图像的频谱模型:
- 频率掩码:随机遮蔽输入图像的低频或高频分量
- 重建任务:训练模型预测被遮蔽的频率信息
- 纯真实数据:整个过程只使用真实图像,无需任何AI生成样本
这个过程让模型深度学习了真实图像在频域中的内在规律。
2. Spectral Reconstruction Similarity(频谱重建相似性)
核心检测机制基于一个简单但有效的观察:训练好的频谱模型对真实图像的重建效果比对AI生成图像更好。
SPAI通过计算以下三组相似性来量化这种差异:
- 原始图像与低频分量的相似性
- 原始图像与高频分量的相似性
- 低频与高频分量之间的相似性
3. Spectral Context Vector(频谱上下文向量)
不同图像的频谱特征重要性不同。例如,对于缺乏高频细节的图像,高频重建的准确性就不那么重要。
频谱上下文向量通过注意力机制捕获这种上下文信息,确保检测系统能够根据图像内容自适应地权衡不同频率成分的重要性。
4. Spectral Context Attention(频谱上下文注意力)
现有视觉模型通常无法高效处理高分辨率图像(数百万像素),而在图像检测任务中,细节信息至关重要。
SCA通过注意力机制智能融合图像不同区域的频谱信息,实现了:
- 任意分辨率处理:无需预先缩放图像
- 细节保留:保持对微妙伪影的敏感性
- 计算高效:复杂度仅为O(K),其中K是图像块数量
实验结果:全面领先的性能表现
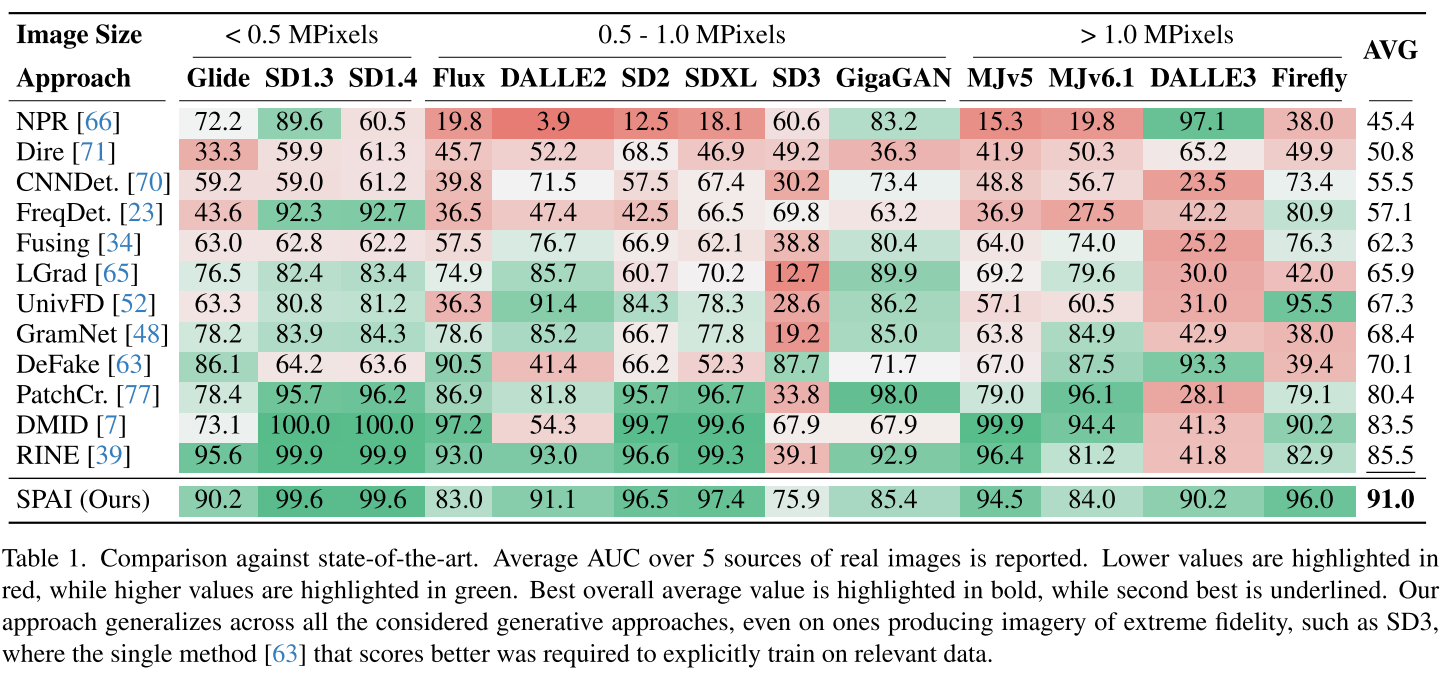
SPAI在多个维度都展现出了卓越的性能:
检测准确性
- 13个最新生成模型:包括Stable Diffusion系列、DALL-E系列、Midjourney、Flux等
- 平均AUC达91.0%:比现有最佳方法提升5.5%
- 一致性优秀:在所有测试模型上都保持稳定的高性能
鲁棒性测试
针对真实网络环境中常见的图像处理操作,SPAI展现出了显著的鲁棒性:
- 压缩处理:JPEG和WebP压缩(质量因子50-85)
- 噪声干扰:高斯模糊和高斯噪声
- 尺寸变化:图像缩放(50%-85%)
计算效率
相比需要大规模预训练的竞争方法(如基于CLIP的方法使用4亿张图像),SPAI仅使用120万张图像就达到了更好的效果。
技术优势分析
1. 泛化能力强
通过建模真实图像的不变特征而非学习特定的AI伪影,SPAI天然具备对未见生成模型的泛化能力。
2. 训练数据需求低
无需收集各种AI生成样本,仅使用真实图像即可训练,大大降低了数据收集和标注成本。
3. 分辨率无关
SCA机制使得方法能够处理任意分辨率的图像,无需损失细节信息。
4. 理论基础扎实
基于频域分析的方法有着深厚的信号处理理论基础,相比纯经验性方法更可靠。
局限性与未来方向
尽管SPAI表现出色,但仍存在一些局限:
衍生图像检测困难
当AI生成图像经过截图、打印扫描等"二次处理"后,原始的频谱特征会被破坏,检测难度大幅增加。
压缩算法的影响
虽然具有一定鲁棒性,但极端的压缩或特殊的图像处理仍可能影响检测效果。
技术实现细节
对于感兴趣的开发者,论文提供了详细的实现参数:
- 骨干网络:ViT-B/16,在ImageNet上预训练
- 训练配置:35轮训练,学习率5e-4,余弦衰减
- 数据增强:随机缩放、裁剪、旋转、高斯模糊、JPEG压缩等
- 硬件要求:单块Nvidia L40S 48GB GPU
结论:AI图像检测的新范式
SPAI代表了AI图像检测领域的一个重要里程碑。通过从根本上改变检测策略——从"学习AI特征"转向"理解真实本质",这项工作为构建更加鲁棒和通用的检测系统提供了新的思路。
随着AI生成技术的不断发展,我们需要更多像SPAI这样具有前瞻性和理论基础的检测方法。这不仅有助于维护数字内容的真实性,也为负责任的AI发展提供了重要的技术保障。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 27
27 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)