【GitHub项目推荐--Sentient:AI驱动的自然语言编程语言完全指南】
Sentient 是一个革命性的实验性编程语言,它允许开发者使用自然语言编写程序,通过AI模型(如大型语言模型)将自然语言描述转换为可执行代码。这个创新项目代表了编程范式的重大转变,旨在降低编程门槛并提高开发效率。🔗 GitHub地址🚀 核心价值:自然语言编程 · AI代码生成 · 实验性创新 · 开源探索项目背景:编程革命:探索自然语言作为编程接口的可能性AI融合:利用

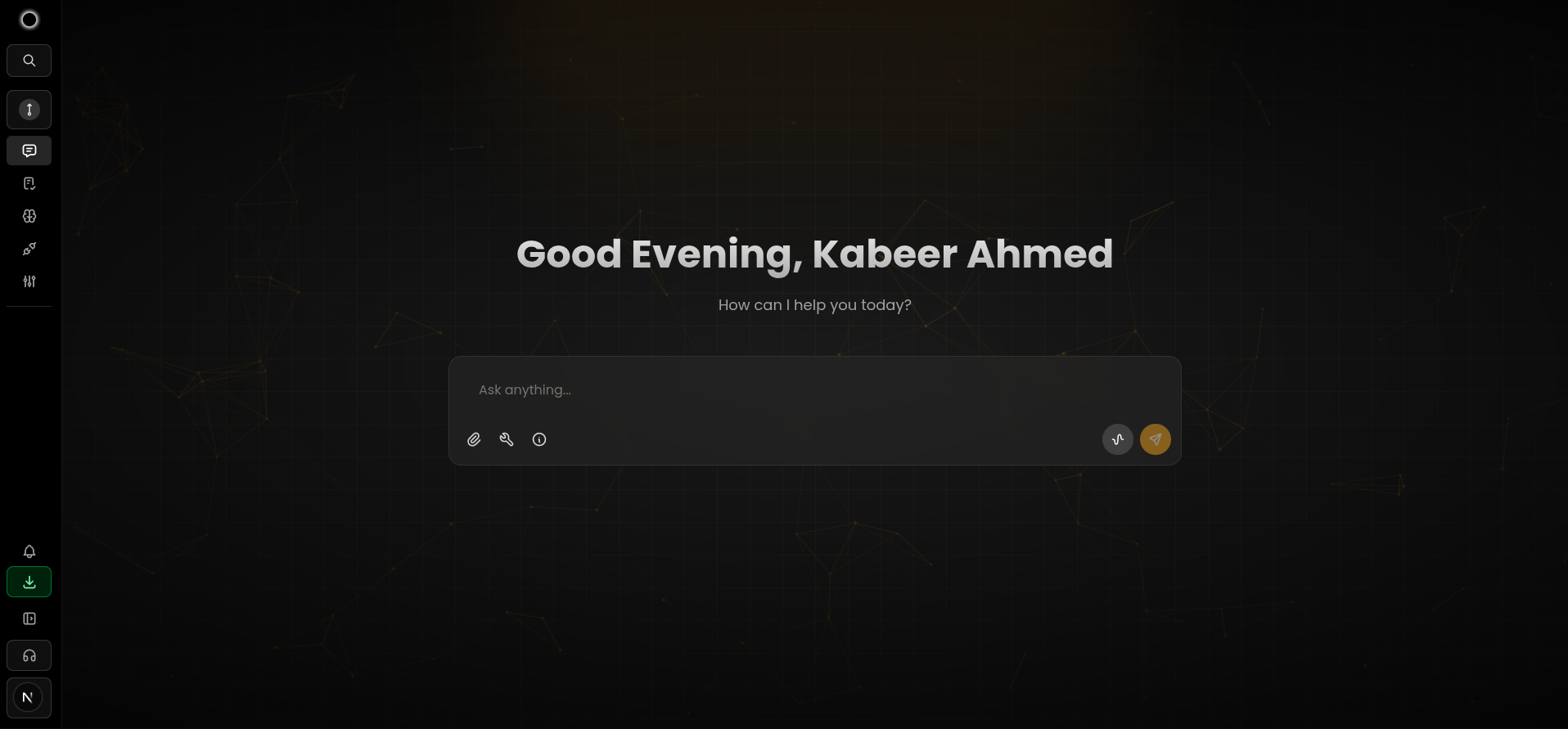
文字聊天
语音聊天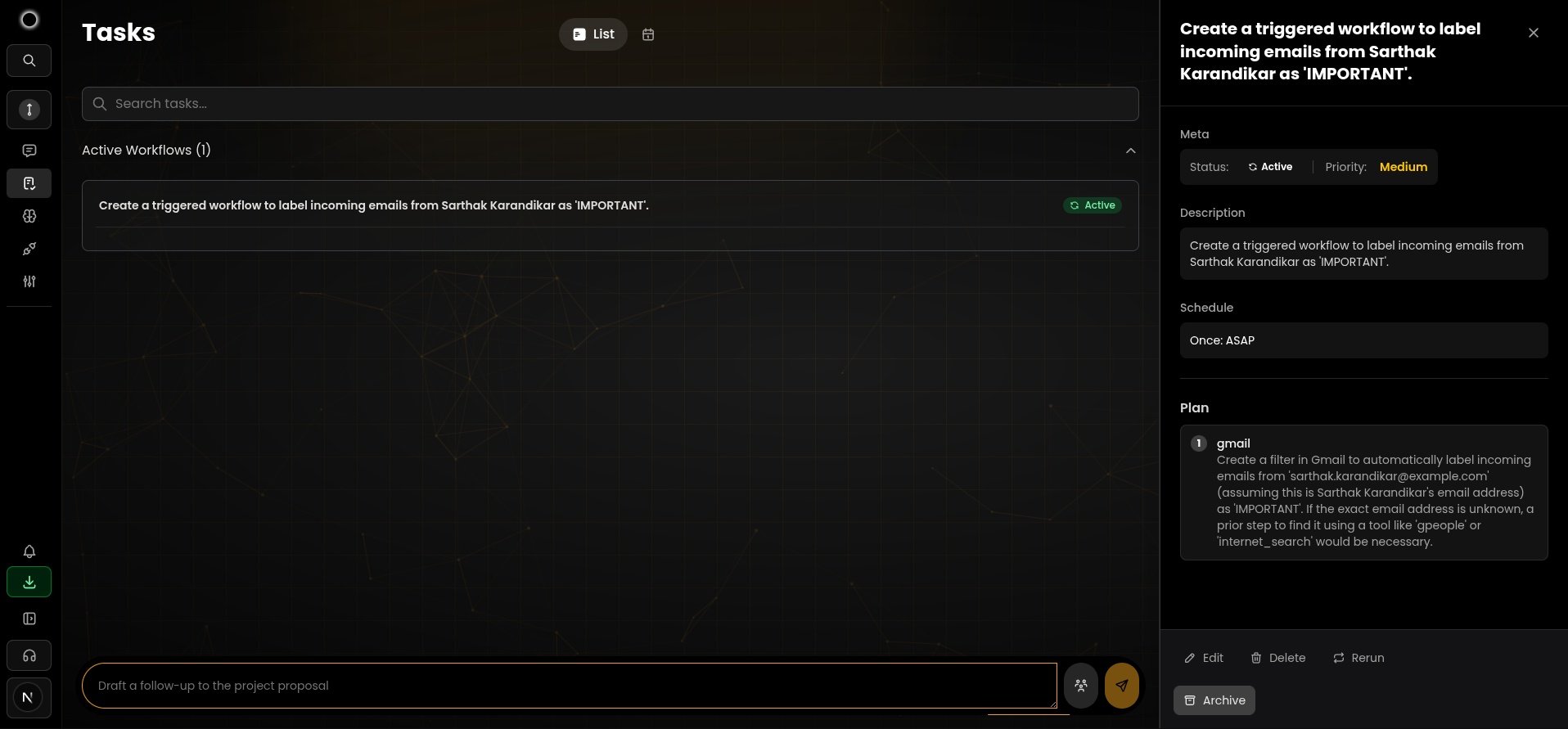
从“任务”页面管理后台任务 - 创建重复、触发、计划或 Swarm 任务。
Sentient 会学习关于您的记忆 - 它用来个性化行动和反应。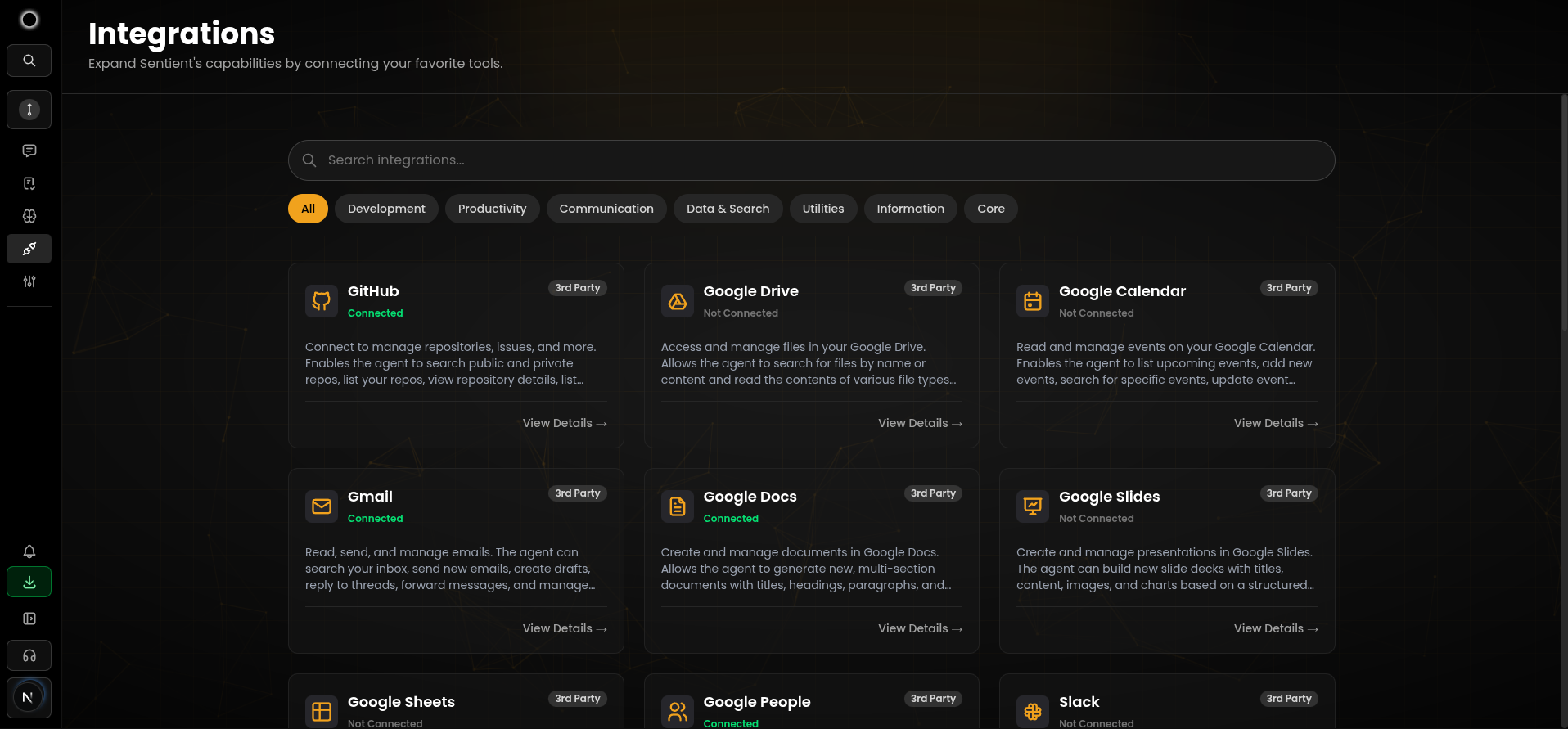
连接您的所有工具。(已支持 20+ 应用程序)
简介
Sentient 是一个革命性的实验性编程语言,它允许开发者使用自然语言编写程序,通过AI模型(如大型语言模型)将自然语言描述转换为可执行代码。这个创新项目代表了编程范式的重大转变,旨在降低编程门槛并提高开发效率。
🔗 GitHub地址:
https://github.com/existence-master/Sentient
🚀 核心价值:
自然语言编程 · AI代码生成 · 实验性创新 · 开源探索
项目背景:
-
编程革命:探索自然语言作为编程接口的可能性
-
AI融合:利用大型语言模型弥合人类语言与机器代码之间的鸿沟
-
开源实验:作为研究项目推动编程语言设计的边界
-
教育使命:使编程更易于接触和学习
技术特色:
-
🗣️ 自然语言接口:使用英语等自然语言描述程序逻辑
-
🤖 AI集成:集成LLM进行意图理解和代码生成
-
⚡ 即时执行:实时将描述转换为可执行代码
-
🔧 多语言支持:生成Python、JavaScript等多种语言代码
-
🌐 交互环境:提供REPL(交互式解释环境)体验
设计理念:
-
可访问性:使编程对非技术人员更易接触
-
表达自由:摆脱传统语法限制
-
实验精神:探索编程的未来可能性
-
教育导向:作为学习编程概念的工具
-
开放探索:鼓励社区参与和扩展
主要功能
1. 核心架构体系

2. 功能详情
自然语言编程:
-
意图表达:用自然语言描述程序逻辑和功能
-
模糊处理:处理不精确或模糊的描述
-
上下文理解:维护对话上下文理解复杂需求
-
多语言支持:支持多种人类语言描述
-
逐步细化:通过对话逐步完善程序描述
AI代码生成:
-
即时转换:实时将描述转换为可执行代码
-
多语言输出:生成Python、JavaScript、Java等代码
-
代码解释:解释生成的代码逻辑和结构
-
优化建议:提供代码优化和改进建议
-
错误处理:自动修正描述中的逻辑错误
执行环境:
-
交互式REPL:实时输入描述并查看执行结果
-
脚本执行:运行保存的Sentient程序文件
-
编译输出:导出为传统编程语言文件
-
调试支持:提供自然语言调试界面
-
执行可视化:可视化程序执行流程和数据流
高级特性:
-
状态管理:自动维护程序执行状态
-
外部集成:调用外部API和库函数
-
数据操作:自然语言描述数据处理
-
控制结构:用自然语言表达条件、循环等
-
函数定义:创建可重用的自然语言函数
3. 技术规格
AI模型集成:
# 支持的AI模型
OpenAI GPT系列
Anthropic Claude
Google Gemini
本地LLM(Llama、Mistral等)
自定义模型集成
# 模型功能
自然语言理解
代码生成能力
上下文维护
错误检测和修正
优化建议执行环境:
# 支持的语言输出
Python: 3.8+
JavaScript: ES6+
Java: 11+
C#: .NET Core 3.1+
Go: 1.18+
其他: 通过插件扩展
# 执行模式
解释模式: 直接执行Sentient描述
编译模式: 生成目标语言源代码
混合模式: 部分解释部分编译系统要求:
# 基础要求
Python: 3.8+
Node.js: 16.x+ (可选)
Java: 11+ (可选)
.NET Core: 3.1+ (可选)
# 硬件要求
CPU: 现代多核处理器
内存: 8GB+ RAM (推荐16GB)
存储: 1GB+ 可用空间
# AI模型要求
云模型: 需要API密钥和网络连接
本地模型: 需要GPU支持和大内存性能指标:
# 响应时间
简单程序: < 2秒
中等程序: 5-10秒
复杂程序: 10-30秒
# 处理能力
最大描述长度: 4096 tokens
最大上下文: 8192 tokens
最大嵌套: 10层安装与配置
1. 环境准备
基础要求:
# Python环境
python --version # 需要Python 3.8+
pip --version # 需要pip包管理器
# 可选环境
node --version # 如需JavaScript输出
java --version # 如需Java输出
dotnet --version # 如需C#输出2. 安装步骤
从源码安装:
# 克隆仓库
git clone https://github.com/existence-master/Sentient.git
cd Sentient
# 创建虚拟环境
python -m venv .venv
source .venv/bin/activate # Linux/macOS
# .venv\Scripts\activate # Windows
# 安装依赖
pip install -r requirements.txt
# 安装Sentient
pip install -e .使用Docker:
# 构建Docker镜像
docker build -t sentient .
# 运行容器
docker run -it --rm sentient
# 带GPU支持运行
docker run -it --rm --gpus all sentient配置API密钥:
# 设置环境变量
export OPENAI_API_KEY="your_openai_api_key"
export ANTHROPIC_API_KEY="your_anthropic_api_key"
export GOOGLE_API_KEY="your_google_api_key"
# 或使用配置文件
# 创建config.ini
[api_keys]
openai = "your_openai_api_key"
anthropic = "your_anthropic_api_key"
google = "your_google_api_key"3. 配置说明
配置文件示例:
# sentient_config.ini
[general]
default_model = "gpt-4-turbo"
language_output = "python"
interactive_mode = true
log_level = "info"
[local_models]
llama_model_path = "/path/to/llama/model"
mistral_model_path = "/path/to/mistral/model"
[execution]
timeout = 30
max_iterations = 100
safe_mode = true
[ui]
theme = "dark"
font_size = 14环境变量配置:
# 模型选择
export SENTIENT_MODEL="claude-3-opus"
# 输出语言
export SENTIENT_OUTPUT_LANG="javascript"
# 交互模式
export SENTIENT_INTERACTIVE="true"
# 调试选项
export SENTIENT_DEBUG="false"本地模型配置:
# 使用Ollama集成本地模型
ollama pull llama3
export SENTIENT_LOCAL_MODEL="llama3"
# 或使用Hugging Face模型
export SENTIENT_LOCAL_MODEL="mistralai/Mistral-7B-Instruct-v0.2"使用指南
1. 基本工作流
使用Sentient的基本流程包括:描述需求 → AI生成代码 → 执行验证 → 迭代优化。整个过程设计为直观自然,无需传统编程知识。
2. 基本使用
交互式REPL:
# 启动Sentient REPL
sentient-repl
# 示例会话
> 创建一个函数计算两个数的和
定义函数 add(a, b):
返回 a + b
> 调用这个函数计算5和7的和
结果 = add(5, 7)
> 打印结果
打印(结果)
执行结果: 12脚本执行:
# 创建Sentient脚本文件 (example.snt)
描述: 计算斐波那契数列前n项
输入: n=10
步骤:
如果 n <= 0: 返回空列表
如果 n == 1: 返回 [0]
序列 = [0, 1]
当 序列长度 < n:
下一个数 = 序列[-1] + 序列[-2]
添加 下一个数 到 序列
返回 序列
# 执行脚本
sentient run example.snt
# 输出
[0, 1, 1, 2, 3, 5, 8, 13, 21, 34]编译输出:
# 将Sentient描述编译为Python代码
sentient compile example.snt -o python -f fib.py
# 生成的Python代码
def fibonacci(n):
if n <= 0:
return []
if n == 1:
return [0]
sequence = [0, 1]
while len(sequence) < n:
next_num = sequence[-1] + sequence[-2]
sequence.append(next_num)
return sequence
print(fibonacci(10))API集成:
from sentient import generate_code, execute
# 自然语言描述
description = """
获取用户输入的数字列表
计算这些数字的平均值
如果平均值大于10,打印"高于阈值"
否则打印"低于阈值"
"""
# 生成并执行代码
code = generate_code(description, lang="python")
result = execute(code, inputs={"numbers": [8, 12, 15, 7, 10]})
print(result) # 输出: 低于阈值3. 高级功能
复杂程序开发:
# 多步骤程序开发
> 定义一个用户管理系统
系统包含:
- 用户列表
- 添加用户功能: 接受姓名和邮箱
- 查找用户功能: 通过邮箱查找
- 删除用户功能: 通过邮箱删除
> 实现添加用户功能
函数 add_user(name, email):
如果 邮箱已存在: 抛出错误"邮箱已存在"
新用户 = {"name": name, "email": email}
添加 新用户 到 用户列表
> 实现查找用户功能
函数 find_user(email):
对于 用户 在 用户列表:
如果 用户.email == email: 返回 用户
返回 空
> 实现删除用户功能
函数 delete_user(email):
用户 = find_user(email)
如果 用户 不为空: 从用户列表移除用户
否则: 抛出错误"用户不存在"外部库调用:
> 使用requests库获取API数据
导入 requests
url = "https://api.example.com/data"
响应 = requests.get(url)
数据 = 响应.json()
> 处理数据
对于 项 在 数据:
打印(项["名称"], 项["值"])错误处理:
> 尝试执行可能失败的操作
尝试:
结果 = 除法(10, 0)
捕获 异常 作为 e:
打印("发生错误:", e)调试支持:
> 调试一个函数
调试 函数 计算平均值(列表):
总和 = 0
对于 数 在 列表:
总和 += 数
返回 总和 / 列表长度
# 设置断点
在 "总和 += 数" 设置断点
# 执行调试
调试执行 计算平均值([5, 10, 15])应用场景实例
案例1:教育编程入门
场景:编程初学者学习基础概念
解决方案:使用Sentient作为无门槛编程学习工具。
学习路径:
# 基础概念学习
> 什么是变量?
变量是存储数据的容器,如 age = 25
> 如何创建函数?
函数是可重用的代码块,如:
函数 问候(名字):
返回 "你好," + 名字
> 解释循环
循环用于重复执行代码,如:
对于 i 在 范围(5):
打印(i)
# 实践练习
> 创建一个计算阶乘的函数
函数 阶乘(n):
如果 n == 0: 返回 1
否则: 返回 n * 阶乘(n-1)
> 计算5的阶乘
结果 = 阶乘(5)
打印(结果) # 输出: 120
# 概念验证
> 什么是递归?
递归是函数调用自身的过程,如上面的阶乘函数教育价值:
-
零门槛入门:无需学习语法即可开始编程
-
概念理解:通过自然语言强化编程概念
-
即时反馈:实时查看代码执行结果
-
错误容忍:AI辅助修正描述错误
-
学习动力:快速成就感增强学习动力
案例2:快速原型开发
场景:开发者需要快速验证想法
解决方案:使用Sentient加速原型开发。
原型开发流程:
# 数据获取和处理
> 从CSV文件读取销售数据
导入 pandas
数据 = pandas.read_csv("sales.csv")
> 计算每月总销售额
数据['日期'] = pandas.to_datetime(数据['日期'])
数据['月份'] = 数据['日期'].dt.month
月销售额 = 数据.groupby('月份')['销售额'].sum()
> 可视化结果
导入 matplotlib.pyplot 作为 plt
plt.plot(月销售额.index, 月销售额.values)
plt.title('月销售额趋势')
plt.xlabel('月份')
plt.ylabel('销售额')
plt.show()原型优化:
> 添加预测功能
导入 sklearn.linear_model
模型 = LinearRegression()
模型.fit(月销售额.index.values.reshape(-1,1), 月销售额.values)
预测 = 模型.predict([[13]]) # 预测下个月销售额实施效果:
-
开发速度:分钟级完成原型开发
-
概念验证:快速验证想法的可行性
-
跨语言能力:无需掌握特定语言语法
-
文档生成:自然语言描述即文档
-
协作简化:非技术人员可理解程序逻辑
案例3:自动化脚本编写
场景:非技术用户需要自动化重复任务
解决方案:使用Sentient创建自动化脚本。
自动化任务:
# 文件管理自动化
> 整理下载文件夹
对于 文件 在 目录"~/Downloads":
如果 文件是图片: 移动到"~/Pictures"
如果 文件是文档: 移动到"~/Documents"
如果 文件是压缩包: 解压到"~/Downloads/Extracted"
如果 文件超过30天未访问: 移动到"~/Downloads/Archive"
# 数据处理自动化
> 处理每日销售报告
读取 CSV文件"daily_sales.csv"
计算 总销售额 = 所有行销售额之和
计算 平均订单值 = 总销售额 / 订单数量
如果 总销售额 > 10000: 发送邮件通知团队
生成 PDF报告 包含关键指标
保存报告到"reports/YYYY-MM-DD.pdf"任务调度:
> 设置每天上午9点自动运行
使用 cron 调度任务
每天 9:00 运行 sales_report.snt实施价值:
-
非技术友好:无需编程知识创建自动化
-
效率提升:自动化重复性手动任务
-
错误减少:减少人为操作错误
-
灵活适应:快速修改和调整脚本
-
资源优化:释放人力资源用于更高价值工作
案例4:AI辅助代码生成
场景:开发者需要加速编码过程
解决方案:使用Sentient作为AI编程助手。
开发辅助:
# 复杂算法实现
> 实现快速排序算法
函数 快速排序(列表):
如果 列表长度 <= 1: 返回 列表
基准 = 列表[0]
小于 = [x for x in 列表[1:] if x < 基准]
大于等于 = [x for x in 列表[1:] if x >= 基准]
返回 快速排序(小于) + [基准] + 快速排序(大于等于)
# API集成
> 创建Twitter API客户端
类 TwitterClient:
初始化(api_key, api_secret):
设置认证凭据
方法 发推(内容):
使用API发送推文
方法 获取时间线(用户, 数量=10):
返回用户的最新推文
# 测试代码生成
> 为TwitterClient编写测试
测试类 TestTwitterClient:
设置:
创建客户端实例
测试 发推:
调用 发推("测试推文")
验证 推文已发送
测试 获取时间线:
时间线 = 获取时间线("test_user")
验证 时间线不为空代码审查:
> 审查以下Python代码的安全性
代码:
user_input = input("输入用户名: ")
query = f"SELECT * FROM users WHERE username = '{user_input}'"
result = db.execute(query)
问题: SQL注入漏洞
建议: 使用参数化查询
修复:
query = "SELECT * FROM users WHERE username = ?"
result = db.execute(query, (user_input,))实施效益:
-
编码加速:减少样板代码编写时间
-
知识扩展:学习新的API和库使用
-
代码质量:AI辅助生成最佳实践代码
-
问题解决:快速解决复杂编程问题
-
文档生成:自动生成代码注释和文档
生态系统与社区
1. 社区资源
获取帮助:
-
📚 官方文档:GitHub README和Wiki文档
-
💬 社区讨论:GitHub Discussions和问题区
-
🐛 问题报告:通过GitHub Issues报告问题
-
💡 功能建议:提交新功能请求和改进建议
支持渠道:
-
GitHub Issues:主要的问题跟踪和功能请求
-
Discord社区:实时讨论和开发者交流
-
示例库:丰富的使用示例和模板
-
更新通知:关注仓库获取最新更新
贡献指南:
-
Fork项目仓库
-
创建特性分支 (
git checkout -b feature/AmazingFeature) -
提交更改 (
git commit -m 'Add some AmazingFeature') -
推送到分支 (
git push origin feature/AmazingFeature) -
发起Pull Request
2. 相关项目集成
AI生态系统:
-
LangChain:语言模型应用开发框架
-
LlamaIndex:数据连接和检索增强
-
Hugging Face:模型和数据集集成
-
Ollama:本地大模型运行环境
-
OpenAI API:云AI服务集成
开发工具:
-
VS Code扩展:Sentient语言支持
-
Jupyter集成:在Notebook中使用Sentient
-
CLI工具:命令行界面和脚本集成
-
Web IDE:基于浏览器的开发环境
-
调试工具:集成调试和性能分析
应用场景:
-
教育平台:编程学习工具集成
-
自动化工具:RPA和工作流自动化
-
低代码平台:增强自然语言能力
-
数据科学:简化数据分析和处理
-
物联网:自然语言控制设备编程
总结
Sentient作为实验性的自然语言编程语言,代表了编程范式的重大创新。通过将自然语言描述转换为可执行代码,它挑战了传统编程的边界,使编程更易接触和理解。
核心优势:
-
🚀 革命性接口:自然语言作为编程语言
-
🤖 AI驱动:大型语言模型提供智能支持
-
🌐 可访问性:降低编程学习门槛
-
⚡ 开发效率:加速原型开发和脚本编写
-
🔧 教育价值:直观理解编程概念
适用场景:
-
编程教育和学习
-
快速原型开发和验证
-
自动化脚本创建
-
AI辅助编程
-
跨领域协作工具
技术特色:
-
自然语言核心:人类语言作为主要接口
-
多语言输出:生成多种编程语言代码
-
交互环境:REPL即时反馈体验
-
上下文感知:维护对话上下文理解复杂需求
-
错误容忍:AI辅助修正和优化
🌟 GitHub地址:
https://github.com/existence-master/Sentient
🚀 快速开始:
pip install git+https://github.com/existence-master/Sentient.git💬 社区支持:
通过GitHub Issues获取帮助和支持
立即体验Sentient,探索编程的未来!
最佳实践建议:
-
🏁 初学者:从简单描述开始逐步学习
-
🔧 开发者:作为AI编程助手提高效率
-
👩🏫 教育者:用于编程概念教学
-
🤖 AI爱好者:探索语言模型在编程中的应用
-
🔍 研究者:研究自然语言编程的潜力
注意事项:
-
⚠️ 实验性质:项目处于早期开发阶段
-
🔒 隐私考虑:注意API调用中的数据隐私
-
💡 描述清晰:清晰描述提高代码质量
-
🔍 结果验证:始终验证生成代码的正确性
-
📚 学习基础:作为补充而非替代传统编程学习
Sentient持续演进和发展,欢迎加入社区共同塑造编程的未来!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 10
10 0
0- 0



 已为社区贡献167条内容
已为社区贡献167条内容

所有评论(0)