LangGraph 入门全解(六):实战 DeepResearch--打造强大的 AI 调研助手,大模型入门到精通,收藏这篇就足够了!
本文完整介绍了 DeepResearch 的原理与实现,并结合 LangGraph 展示了如何构建一个具备“搜索—反思—迭代”能力的研究型 Agent。

DeepResearch
我们在使用AI问答的过程中,AI的答案往往只依赖模型已有的训练数据,或者仅仅做一次搜索。这种方式虽然快速,但结果往往不够全面,还可能被单一上下文影响,导致结论片面。
回想我们在写毕业论文时的流程: 确定研究问题 → 查阅多篇文献 → 做笔记 → 比对分析 → 形成观点 → 引用参考文献。
而 DeepResearch 的核心思想,正是模仿人类这种系统化的调研方式。它利用 链式思维(Chain-of-Thought)和反思性推理(Reflective Reasoning),一步步推进研究过程,直到得到足够可靠的答案。
DeepResearch流程图
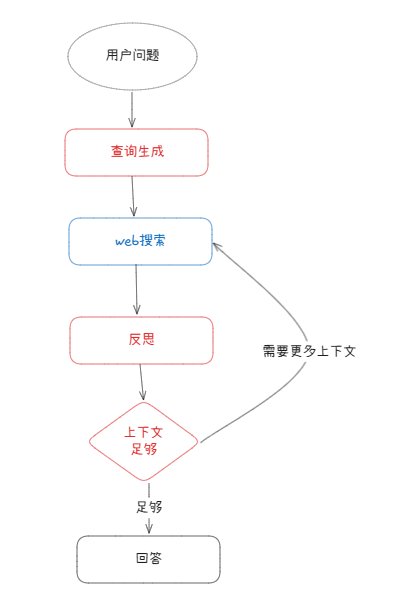
-
- 生成初始查询:根据用户输入,模型会生成一组搜索查询。
-
- 网络研究:针对每个查询,通过模型和搜索工具查找相关网页。
-
- 反思与差距分析:代理对搜索结果进行分析,判断信息是否足够,是否存在知识盲点。
-
- 迭代细化:如果发现不足,自动生成后续查询,重复“搜索—反思”的循环(直到达到设定的最大次数)。
-
- 生成最终答案:当研究内容足够时,模型整合信息,生成一个逻辑清晰、带引用的最终答案。
代码示例
在实现过程中,我将整个 Agent 拆分为三个文件:
- prompts.py:定义所有提示词(Prompt)
- state_schema.py:定义状态与结构化输出的 Schema
- graph.py:定义 Agent 的执行逻辑
配置必要的环境变量
export TAVILY_API_KEY=""
export OPENAI_API_KEY=""
export OPENAI_BASE_URL=""
prompt.py
from datetime import datetime
def get_current_date():
# 获取当前日期函数
return datetime.now().strftime("%B %d, %Y")
query_writer_instructions = """您的目标是生成复杂且多样化的网络搜索查询。这些查询适用于能够分析复杂结果、跟踪链接和综合信息的高级自动化网络研究工具。
指示:
- 始终首选单个搜索查询,仅当原始问题要求多个方面或元素并且一个查询不够时才添加另一个查询。
- 每个查询都应关注原始问题的一个特定方面。
- 不要生成超过5个查询。
- 查询应该是多样化的,如果主题很广泛,则生成 1 个以上的查询。
- 不要生成多个类似的查询,1 个就足够了。
- 查询应确保收集最新信息。当前日期为 {current_date}。
格式:
- 使用以下两个确切键将响应格式化为 JSON 对象:
- “rationale”:简要解释为什么这些查询是相关的
- “query”:搜索查询列表
示例:
主题:去年哪些收入增长更多 苹果股票或购买 iPhone 的人数
'''json
{{
“rationale”: “为了准确回答这个比较增长问题,我们需要有关苹果股票表现和 iPhone 销售指标的具体数据点。这些查询针对所需的精确财务信息:公司收入趋势、特定产品的单位销售数据以及同一财政期间的股价变动,以便直接比较。
“query”: [“苹果2024财年总收入增长”、“2024财年iPhone销量增长”、“2024财年苹果股价增长”],
}}
上下文:{research_topic}“”"
web_searcher_prompt = “”"进行有针对性的搜索,收集有关“{research_topic}”的最新、可信的信息,并将其合成为可验证的文本。
指示:
- 查询应确保收集最新信息。当前日期为 {current_date}。
- 进行多种不同的搜索以收集全面的信息。
- 整合关键发现,同时仔细跟踪每个特定信息的来源。
- 输出应该是根据您的搜索结果编写良好的摘要或报告。
- 只包含搜索结果中发现的信息,不要编造任何信息。
研究课题:
{research_topic}
“”"
reflection_instructions = “”"您是一名专家研究助理,分析有关“{research_topic}”的摘要。
指示:
- 识别知识差距或需要深入探索的领域并生成后续查询。(1 或多个)。
- 如果提供的摘要足以回答用户的问题,请不要生成后续查询。
- 如果存在知识差距,请生成有助于扩展您的理解的后续查询。
- 关注未完全涵盖的技术细节、实施细节或新兴趋势。
要求:
- 确保后续查询是独立的,并包含网络搜索的必要上下文。
输出格式:
- 使用以下确切键将响应格式化为 JSON 对象:
- “is_sufficient”:true or false
- “knowledge_gap”:描述哪些信息缺失或需要澄清
- “follow_up_queries”:写一个具体的问题来解决这一差距
示例:
‘’'json
{{
“is_sufficient”: true, // 或 false
“knowledge_gap”: “摘要缺少有关性能指标和基准的信息”, // “如果is_sufficient为 true,
“follow_up_queries”: [“用于评估 [特定技术] 的典型性能基准和指标是什么?”] // [](如果is_sufficient为 true)
}}
仔细反思摘要,以确定知识差距并生成后续查询。然后,按照以下 JSON 格式生成输出:
摘要:
{summaries}
"""
answer_instructions = """根据提供的摘要为用户的问题生成高质量的答案。
指示:
- 当前日期是 {current_date}。
- 你是多步骤研究过程的最后一步,不要说你是最后一步。
- 您可以访问从前面的步骤中收集的所有信息。
- 您可以访问用户的问题。
- 根据提供的摘要和用户的问题,为用户的问题生成高质量的答案。
- 使用MarkDown编写答案。这是必须的。
用户上下文:
- {research_topic}
摘要:
{summaries}
"""
state_schema.py
from __future__ import annotations
from dataclasses import dataclass, field
from typing import TypedDict, List
from typing_extensions import Annotated
import operator
from pydantic import BaseModel, Field
class SearchQueryList(BaseModel):
query: List[str] = Field(
description="用于 Web 研究的搜索查询列表。"
)
rationale: str = Field(
description="简要解释为什么这些查询与研究主题相关。"
)
class Reflection(BaseModel):
is_sufficient: bool = Field(
description="提供的摘要是否足以回答用户的问题。"
)
knowledge_gap: str = Field(
description="对缺少或需要澄清的信息的描述。"
)
follow_up_queries: List[str] = Field(
description="解决知识差距的后续查询列表。"
)
class OverallState(TypedDict):
topic: str# 研究主题
search_query: Annotated[list, operator.add] # 搜索列表
web_research_result: Annotated[list, operator.add] # 搜索摘要结果
research_loop_count: int# 当前循环次数
max_research_loops: int# 最大循环次数
is_sufficient: bool# 是否足够研究
knowledge_gap: str# 当前搜索后,还缺少的信息
follow_up_queries: List[str] # 接下来需要搜索的问题
final_answer: str
class ReflectionState(TypedDict):
is_sufficient: bool
knowledge_gap: str
follow_up_queries: List[str]
research_loop_count: int
number_of_ran_queries: int
class Query(TypedDict):
query: str
rationale: str
class QueryGenerationState(TypedDict):
search_query: list[Query]
class WebSearchState(TypedDict):
search_query: str
graph.py
from langchain_openai import ChatOpenAI
from langchain_tavily import TavilySearch
from langgraph.types import Send
from langgraph.graph import StateGraph
from langgraph.prebuilt import create_react_agent
from langgraph.graph import START, END
from state_schema import SearchQueryList, Reflection, OverallState,QueryGenerationState,ReflectionState,WebSearchState
from prompts import get_current_date,query_writer_instructions,reflection_instructions,answer_instructions,web_searcher_prompt
# 此处定义你自己的模型
llm = ChatOpenAI(model="qwen3_32")
# 此处定义搜索工具
tool = TavilySearch(max_results=2)
# Nodes
def generate_query(state: OverallState) -> QueryGenerationState:
"""分解用户问题"""
structured_llm = llm.with_structured_output(SearchQueryList)
current_date = get_current_date()
formatted_prompt = query_writer_instructions.format(
current_date=current_date,
research_topic=state["topic"]
)
result = structured_llm.invoke(formatted_prompt)
return {"search_query": result.query}
def continue_to_web_research(state: OverallState):
""" """
return [
Send("web_research", {"search_query": search_query})
for idx, search_query inenumerate(state["search_query"])
]
def web_research(state: WebSearchState) -> OverallState:
"""创建一个搜索Agent"""
formatted_prompt = web_searcher_prompt.format(
current_date=get_current_date(),
research_topic=state["search_query"],
)
agent = create_react_agent(model=llm,tools=[tool],)
response = agent.invoke({"messages": [{"role": "user", "content": formatted_prompt}]})
return {"web_research_result": [response["messages"][-1].content]}
def reflection(state: OverallState) -> ReflectionState:
"""反思节点,分析摘要内容,并确定是否需要进一步搜索"""
state["research_loop_count"] = state.get("research_loop_count", 0) + 1
current_date = get_current_date()
formatted_prompt = reflection_instructions.format(
current_date=current_date,
research_topic=state["topic"],
summaries="\n\n---\n\n".join(state["web_research_result"]),
)
result = llm.with_structured_output(Reflection).invoke(formatted_prompt)
return {
"is_sufficient": result.is_sufficient,
"knowledge_gap": result.knowledge_gap,
"follow_up_queries": result.follow_up_queries,
"research_loop_count": state["research_loop_count"],
"number_of_ran_queries": len(state["search_query"]),
}
def evaluate_research(
state: OverallState,
) -> OverallState:
"""路由函数"""
max_research_loops = state.get("max_research_loops")
if state["is_sufficient"] or state["research_loop_count"] >= max_research_loops:
return"finalize_answer"
else:
return [
Send("web_research",{"search_query": follow_up_query,},)
for idx, follow_up_query inenumerate(state["follow_up_queries"])
]
def finalize_answer(state: OverallState):
"""生成最终回答"""
current_date = get_current_date()
formatted_prompt = answer_instructions.format(
current_date=current_date,
research_topic=state["topic"],
summaries="\n---\n\n".join(state["web_research_result"]),
)
result = llm.invoke(formatted_prompt)
return {"final_answer": result.content,}
grpah = StateGraph(OverallState)
grpah.add_node("generate_query", generate_query)
grpah.add_node("web_research", web_research)
grpah.add_node("reflection", reflection)
grpah.add_node("finalize_answer", finalize_answer)
grpah.add_edge(START, "generate_query")
grpah.add_conditional_edges(
"generate_query", continue_to_web_research, ["web_research"]
)
grpah.add_edge("web_research", "reflection")
grpah.add_conditional_edges(
"reflection", evaluate_research, ["web_research", "finalize_answer"]
)
grpah.add_edge("finalize_answer", END)
app = grpah.compile()
监控与调试
官方的LangSmith用于监控Agent的执行非常的方便。
但是数据会上传到Langchain服务器,不建议在敏感项目中使用。
-
- 申请API Key,登录LangSmith https://smith.langchain.com,免费获取Key
-
- 安装LangGraph-cli pip install --upgrade “langgraph-cli[inmem]”
-
- 创建配置文件langgraph.json,内容如下。按照实际情况修改配置,如有问题,评论区联系
{ "dependencies":["."], "graphs":{ "agent":"graph:app" }, "env":".env", "image_distro":"wolfi" } -
- 创建环境变量文件.env,写入第一步申请的Key
LANGSMITH_API_KEY=lsv2_pt_xxxxxxx -
- 使用命令langgraph dev启动,复制图中链接到浏览器中打开
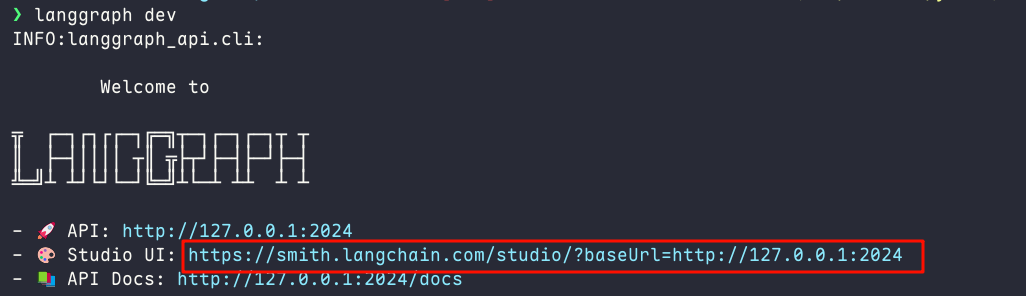
-
- 查看Graph并执行,写入研究主题,最大循环次数,提交
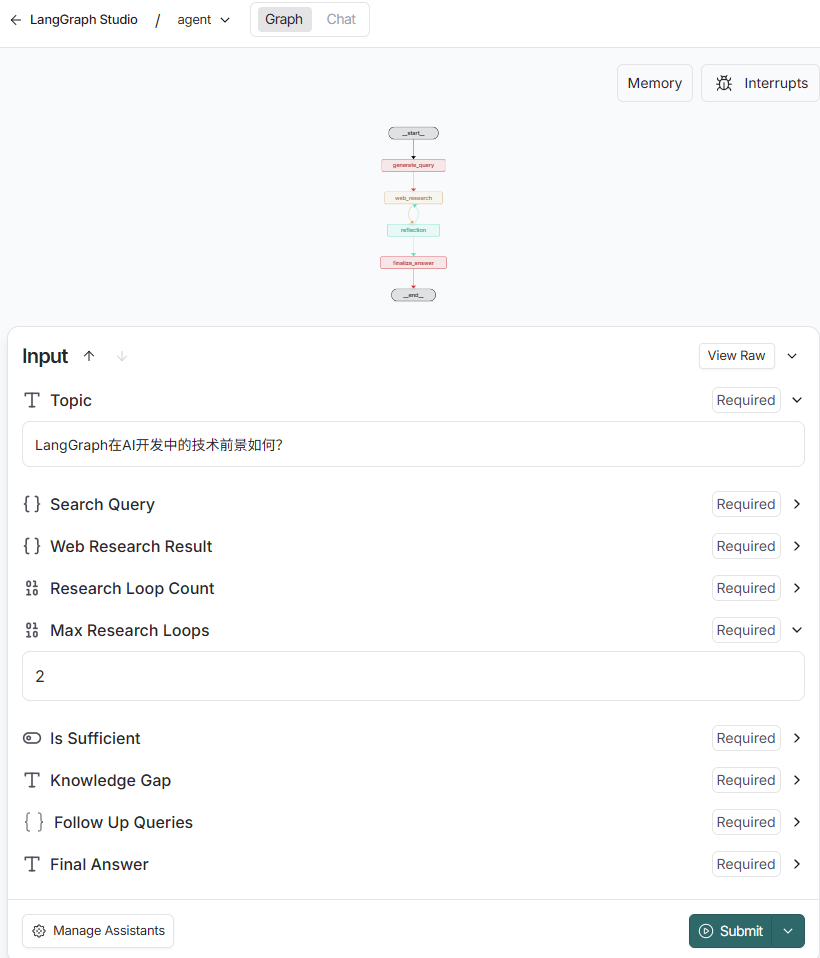
-
- Agent开始运行,可以在右侧的界面上看到每一步执行的情况,整个流程运行了约5分钟。

最后
本文完整介绍了 DeepResearch 的原理与实现,并结合 LangGraph 展示了如何构建一个具备“搜索—反思—迭代”能力的研究型 Agent。
这一系列文章被我命名为 《LangGraph 入门全解》,到这里已全部写完。如果你对 LangGraph 或 AI Agent 有更多兴趣,欢迎在评论区留言或私信我交流。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 2
2 0
0- 0



 已为社区贡献332条内容
已为社区贡献332条内容

所有评论(0)