Graph ⋈ Agent:Chat2Graph 如何重构 GraphRAG 范式?
构建通用 RAG 框架仅仅是第一步,增强 RAG 问答效果才是核心。微软的 GraphRAG 方案爆火,引爆了「LLM + KG」热潮。同时其「社区摘要」的理念也为 GraphRAG 链路中知识图谱的处理带来了新思路 —— 借助于图算法,可以从更高的维度丰富知识图谱语义。图算法的引入,为知识图谱引入了新的图特征信息,相当于在原始知识图谱层之上新增了知识层次。比如引入社区发现算法构建社区摘要知识,引
1. 思想之源:符号 ⋈ 连接 ⋈ 行为
在人工智能研究领域,「符号主义」、「连接主义」、「行为主义」各有所长。「符号主义」工于数理逻辑,基于显式的人工规则,获得高度可解释性的推理效果。「连接主义」长于自主学习,通过大规模神经网络并行计算,以模型权重的形式固化隐式的知识。「行为主义」强调环境反馈,旨在以感知进化的方式让行为智能化。
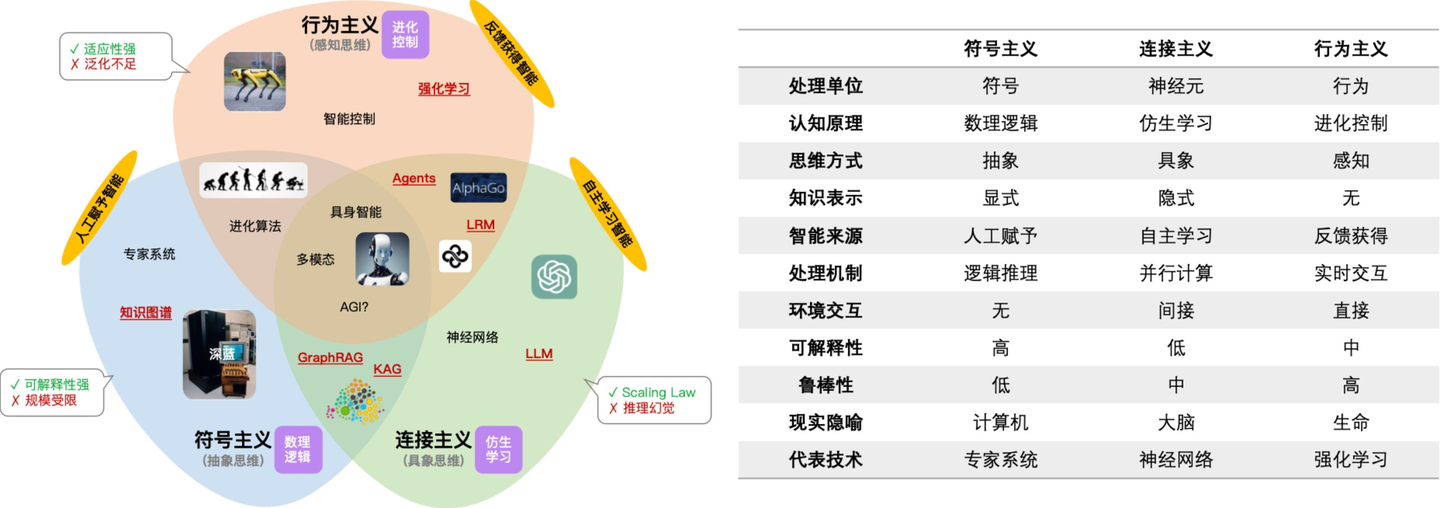
然而,基于人工规则的「符号主义」的智能水平受限于规则的规模,而以概率统计为基础的「连接主义」在推理时的幻觉总是不可避免,同时「行为主义」从环境中学习的能力很难有效地迁移泛化。单项能力的不足反而为优势互补提供了空间,比如大模型与强化学习结合的推理模型(LRM)、环境反馈赋能的大模型智能体(Agent)等。
我们都知道 GraphRAG 其实是对 RAG 链路中「知识库」的改进技术,它以知识图谱而非向量的形式组织模型外的知识信息结构,属于典型的知识图谱与大模型的技术结合案例,回归到思想本源,也就是「符号主义」与「连接主义」的融合。
同时,基于论文《A Theory of Formalisms for Representing Knowledge》的关键结论:“在知识表示上,符号主义与连接主义具有等价性,并且可以相互借鉴”,这进一步地提升了我们对「符号主义」与「连接主义」融合的价值认知和技术决策信心。
For the debate between symbolic AI and connectionist AI, the existence of recursive isomorphisms between KRFs implies that for any knowledge operator in a KRF we can effectively find an operator in another KRF to perform the same transformation. From a theoretical perspective, all these representation methodologies either pave the way to AGI or none, with core challenges being universal and advancements in one methodology benefiting others.
更进一步地,如果将 GraphRAG 看做“符号 ⋈ 连接”的产物(Graph ⋈ LLM),将 Agent 看做“连接 ⋈ 行为”的产物(LLM ⋈ 环境反馈),那么继续推导“符号 ⋈ 连接 ⋈ 行为”这三方结合的产物:「Graph ⋈ LLM ⋈ 环境反馈」,简而化之,即 Graph ⋈ Agent 。没错,这正是我们这次要探讨的主题!
2. 范式重演:GraphRAG 演化史
要弄清 Graph ⋈ Agent 的核心内涵和价值归宿,仍要从 Graph ⋈ LLM 开始,我们需要从「历史唯物主义」的角度重新审视 GraphRAG 技术的演进过程,弄清每一次技术「变革」的背后,要解决的核心的「矛盾」是什么。
2.1 知识问答:Q&A
从 2022 年底 ChatGPT 正式发布,提供给用户的最初界面便是「自然语言问答」,后续我们统一简称为 Q&A。由于相信 Scaling Law,因此我们相信 LLM 中的大规模参数「压缩」了「世界知识」,既而期望通过「提示工程」优化表达,逐步打开信息的「潘多拉魔盒」。至于如何优化表达,成为合格的「提示工程师」,可以参考之前这篇文章《访谈李继刚:从哲学层面与大模型对话》。
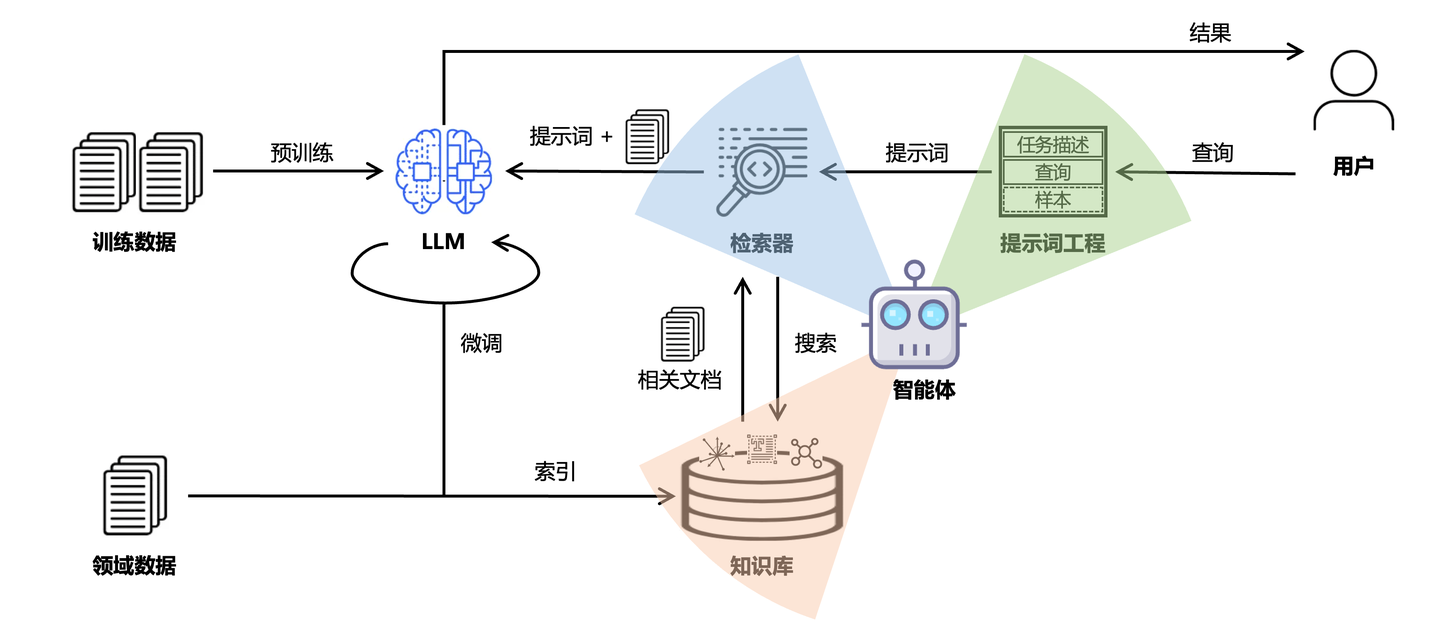
然而事实往往不尽如人意,大家都意识到了 LLM 至今都无法回避的问题 —— 幻觉。为了缓解 LLM 幻觉,各路“诸侯”是「十八般武艺」全往上招呼:模型微调、查询重写、检索增强、向量嵌入、重排序、知识图谱、智能体技术,一股脑得全往上怼,只为让评测效果提升几个百分点,逐步形成了如今面向「知识问答」的 AI 工程链路形态。从某种意义的说,LLM 幻觉问题为这两年 AI 工程链路的持续改进提供了原始动力,真可谓「成也萧何,败也萧何」。
2.2 模型微调:Text2GQL
2023 年,也就是 ChatGPT 发布后的第二年,私域知识的问答诉求与日俱增,借助于 SFT 对 LLM 进行后训练的方式,可以快速为 LLM 补充私域知识,扩展其知识边界。在这个历史时期,用户的知识图谱数据还是通过传统的数据工程手段采集、清洗、加工,存储在图数据库系统内。如果希望借助 LLM 通过自然语言的方式访问这些图数据,最直接的手段就是将自然语言通过 LLM 直接翻译为图查询语言(GQL),既而访问图数据库获取数据。为此,我们还专门训练了 Text2GQL 模型,同时解决了 GQL 语料不足的自动合成问题。具体可以参考文章《Awesome-Text2GQL:从语料生成到TuGraph-DB ChatBot》。
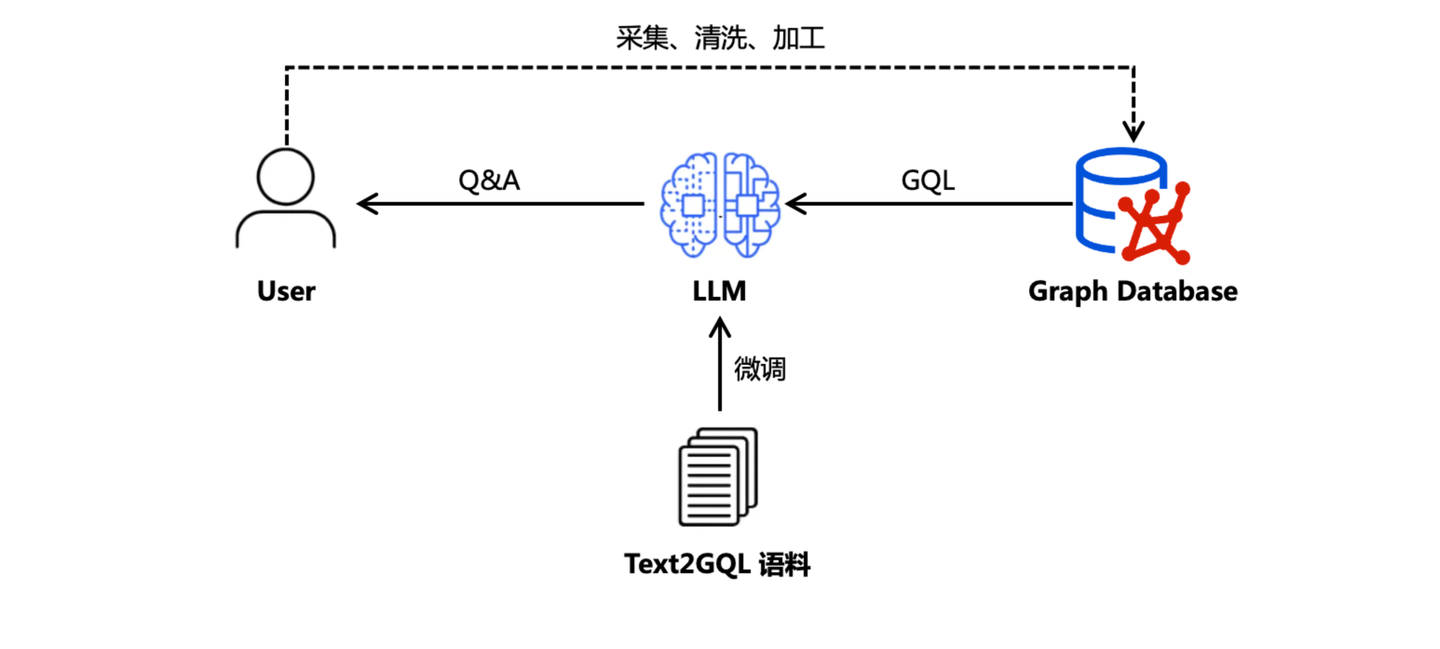
本质上说,Text2GQL 可以看作 GraphRAG 的初级形态。然而,以 LLM 微调后训练为基础的技术方案,仍然无法逃脱私域知识语料无法实时更新的羁绊。
2.3 向量嵌入:RAG
2024 年,以向量知识库为数据底座,结合 ICL(In Context Learning)的 RAG 技术全面爆发,通过外挂知识库组件避免了私域知识更新困难的问题,相比于微调在工程实现上具备了更高的灵活度,行业繁荣程度可参考我去年底整理的《RAG七十二式:2024年度RAG清单》。
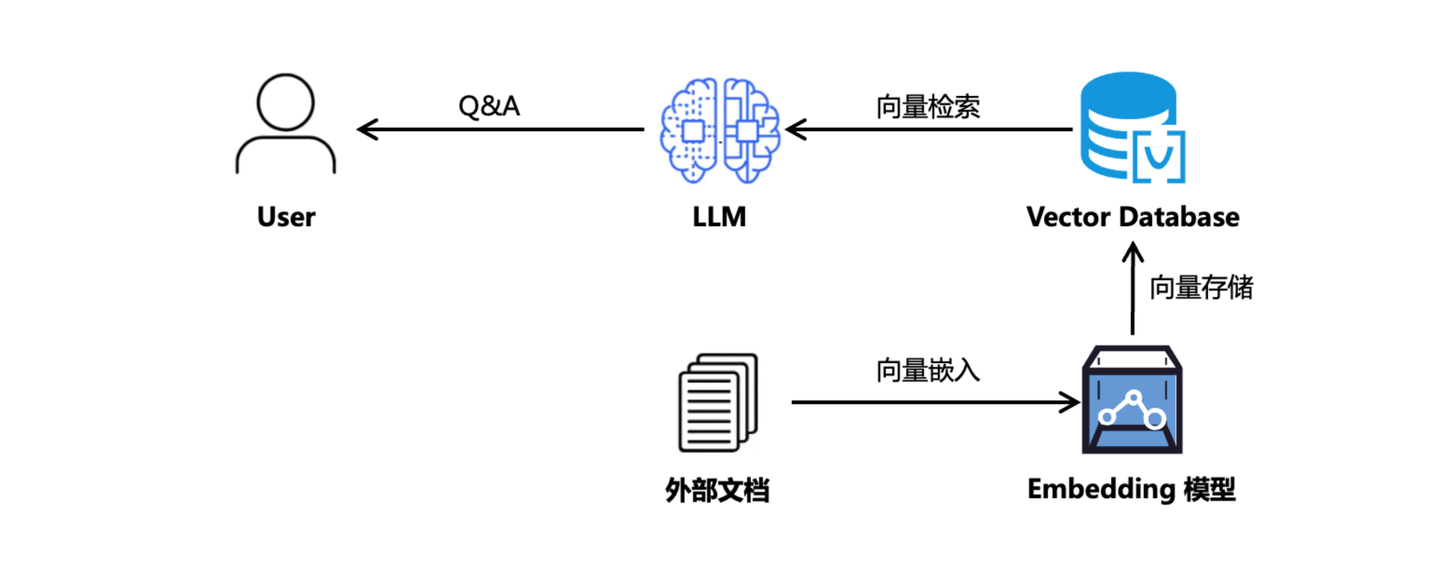
然而,基于向量表征的知识管理方案,忽视了文本之间的事实关联信息,导致文档召回出现遗漏、噪声、错误、矛盾等一系列问题。
2.4 知识图谱:GraphRAG
相比而言,图数据结构就更适合描述事物间的复杂关联信息,因此集成图数据库作为知识库底座,已成必然趋势。同时为了让图数据库能与 RAG 框架无缝集成,必须引入知识图谱语义层支持「文档载入」、「文档召回」等能力,形成与向量数据库底座兼容的通用 RAG 框架。
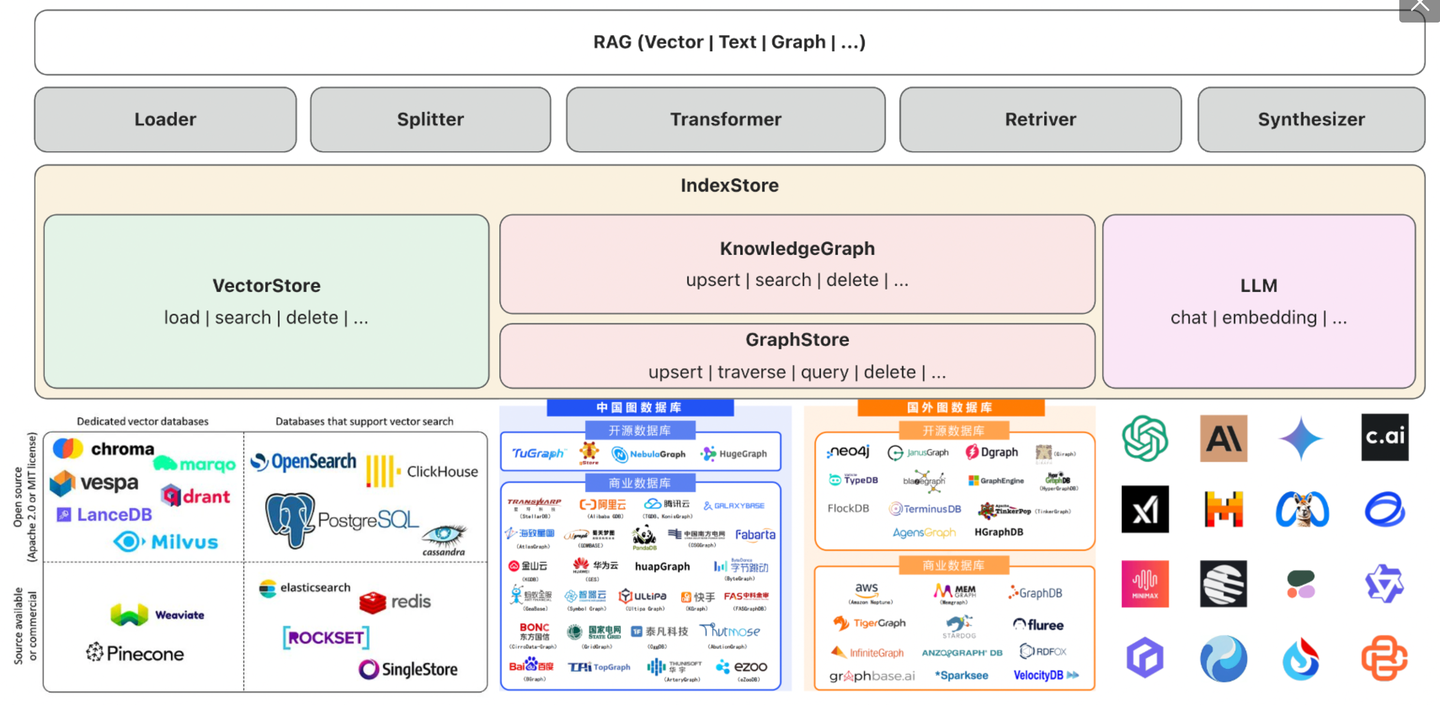
2.5 知识分层:社区摘要
构建通用 RAG 框架仅仅是第一步,增强 RAG 问答效果才是核心。微软的 GraphRAG 方案爆火,引爆了「LLM + KG」热潮。同时其「社区摘要」的理念也为 GraphRAG 链路中知识图谱的处理带来了新思路 —— 借助于图算法,可以从更高的维度丰富知识图谱语义。
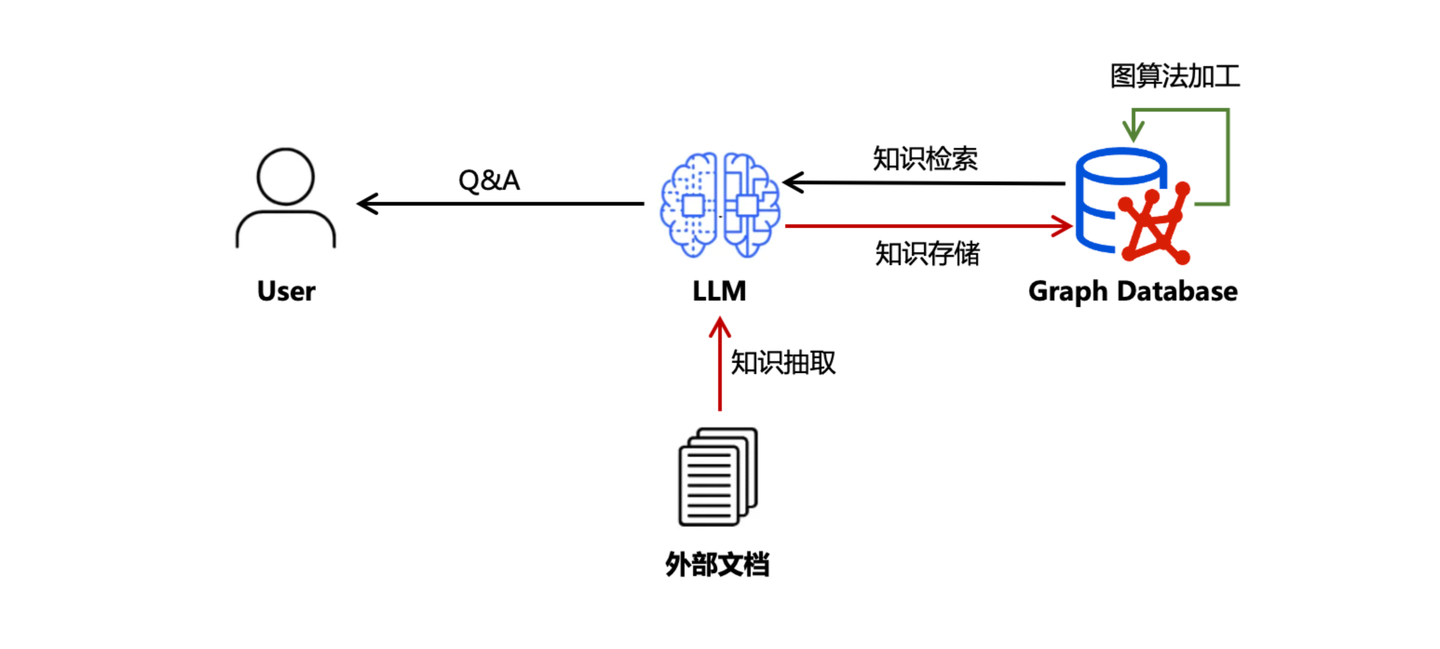
图算法的引入,为知识图谱引入了新的图特征信息,相当于在原始知识图谱层之上新增了知识层次。比如引入社区发现算法构建社区摘要知识,引入 PPR 算法挖掘重要节点信息等。这相当于构建了知识分层的架构,属于对知识图谱的「垂直扩展」。
2.6 图谱扩充:文档结构
相对应的,便是对知识图谱的「水平扩展」,最直接的莫过于引入新的知识图谱数据,比如文档结构图谱。
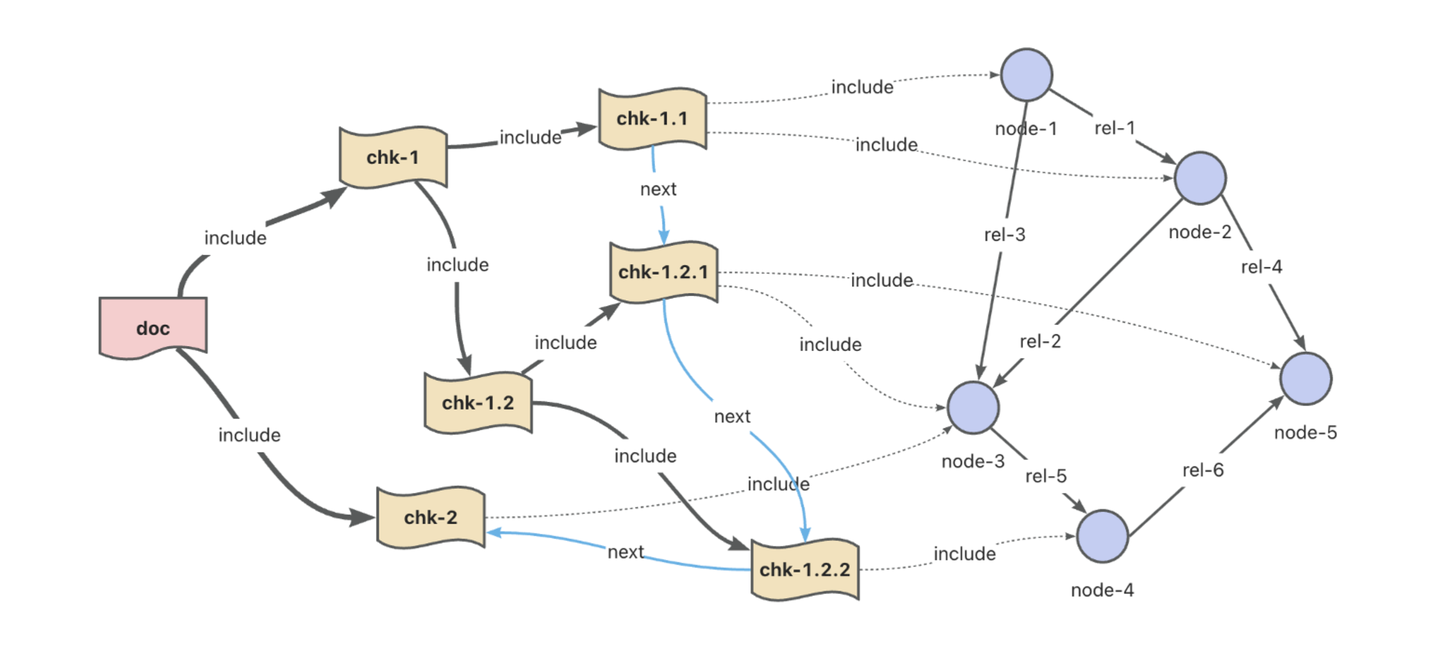
文档结构的引入提升了知识图谱中的文档溯源能力,以提供更完备的 GraphRAG 上下文。当然,除此之外仍有诸多更灵活的知识扩充方法,比如知识图谱增强技术中常用的的消歧、链指、融合等方法也可以看做广义上的知识扩充手段。
2.7 知识召回:混合检索
知识图谱的分层与扩展在强化了知识库能力的同时,也对知识召回的能力提出了更进一步的要求。我们可以清晰地看到,GraphRAG 的知识召回链路也从单一的「关键词检索」,到「向量检索」,再到「混合检索」的逐步演进路径。
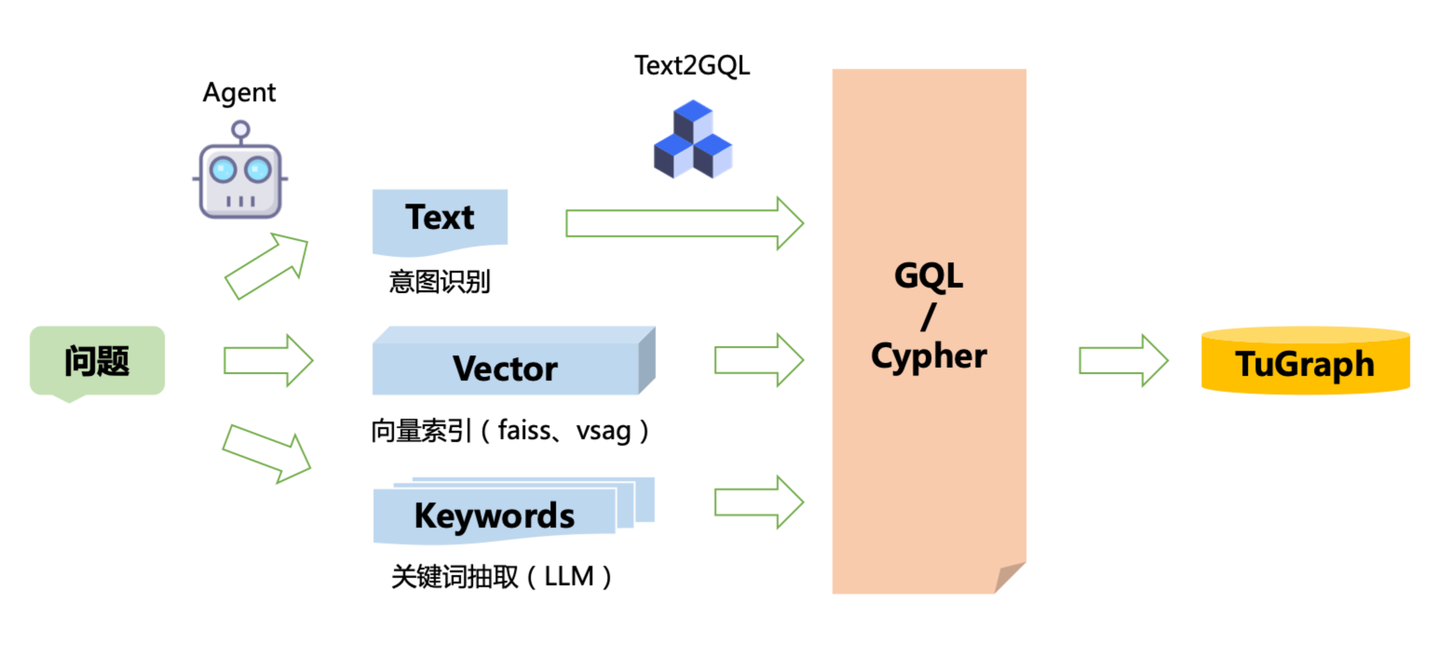
尤其是在引入了「意图识别 + Text2GQL」的「文本驱动」检索链路后,GraphRAG 不光整合了 Text2GQL 技术,还对智能体技术提出了新的要求。因为我们发现一个事实:依赖简单的「意图识别」、「查询重写」手段已不足以解决复杂的Q&A问题,通过智能体对用户问题拆分、规划已开始提上日程。
2.8 工具使用:AgenticRAG
在另一个维度上,单一的外挂知识库方法也开始不能满足用户日益增长的查询诉求了。用户不再满足于异步的知识库文档加载延迟,而是需要调用工具实时地感知开放的外部世界知识,AgenticRAG 自然也就应运而生。
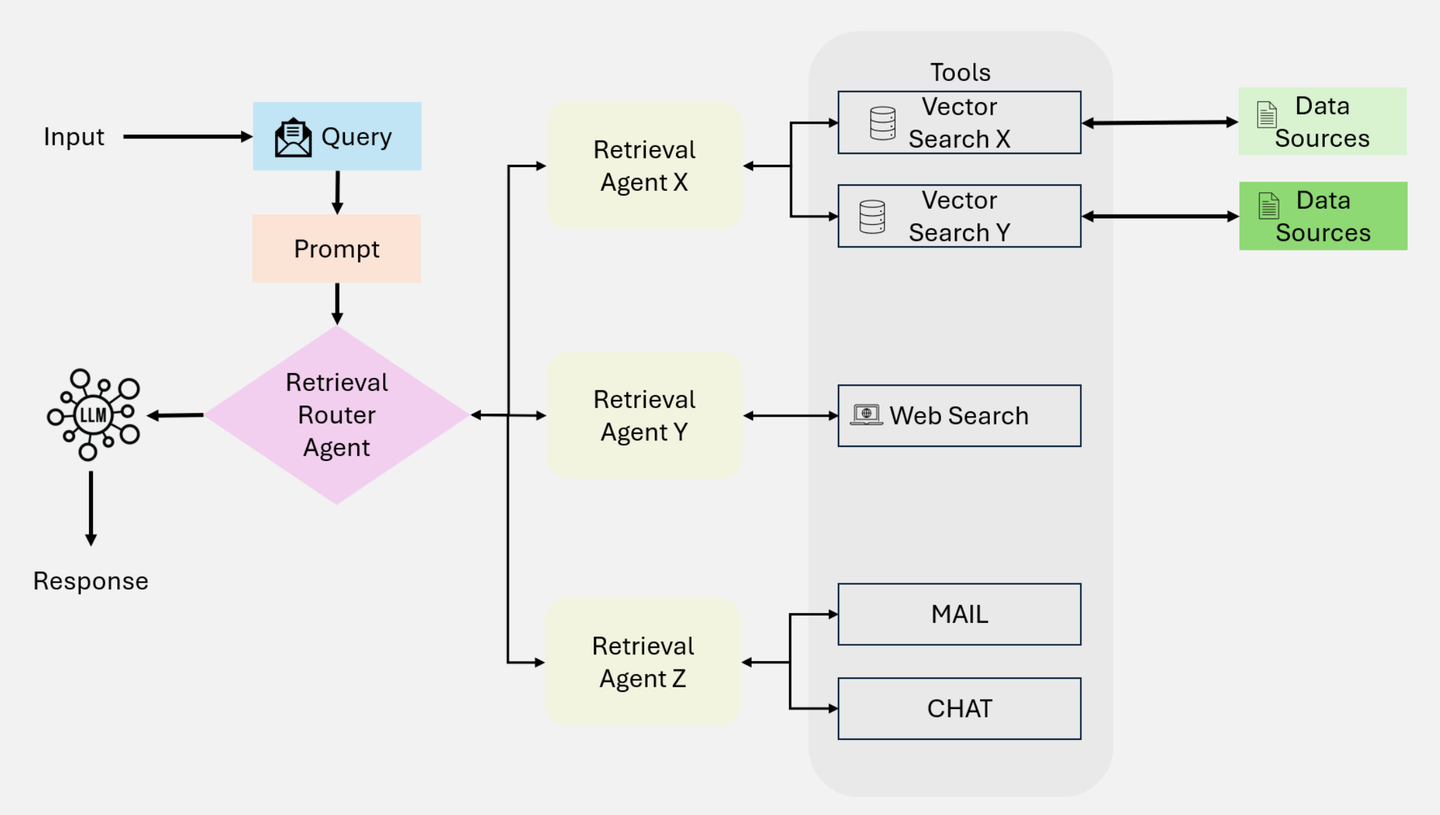
AgenticRAG 引入了工具调用,将 RAG 从原本的「检索增强」,逐步过渡到「工具增强」形态,RAG 的原生含义开始被默默「变革」。
2.9 图智能体:GraphAgent
再次回到 Jerry Liu(LlamaIndex CEO)去年在技术报告《Beyond RAG: Building Advanced Context-Augmented LLM Applications》中提出的「RAG的未来是Agent」的观点。
结合混合检索中对用户问题「规划拆分」,以及 AgenticRAG 中「工具使用」对智能体关键能力的诉求,我们可以果断地得出一个清晰的结论:
GraphRAG 的未来是 GraphAgent。
有了这个结论之后,紧接着一个新问题就是:“什么是 GraphAgent?”。如果只是单纯地把 「GraphRAG + 任务规划 + 工具使用」进行硬性地组合,是我们期望的 GraphAgent 真正形态吗?
比如 GraphRAG 在 GraphAgent 中的定位是什么?访问图数据库的工具和 GraphAgent 的工具是什么关系?需不需要多个 GraphAgent 进行协作?在回答这些问题之前,我们需要对智能体有一个更清晰的认知,以指导我们更好完成 GraphAgent 的设计。
3. 群智之问:个体 vs. 群体
在《人类简史》这本书中,描述了人类历史发展过程中最重要的三种力量:
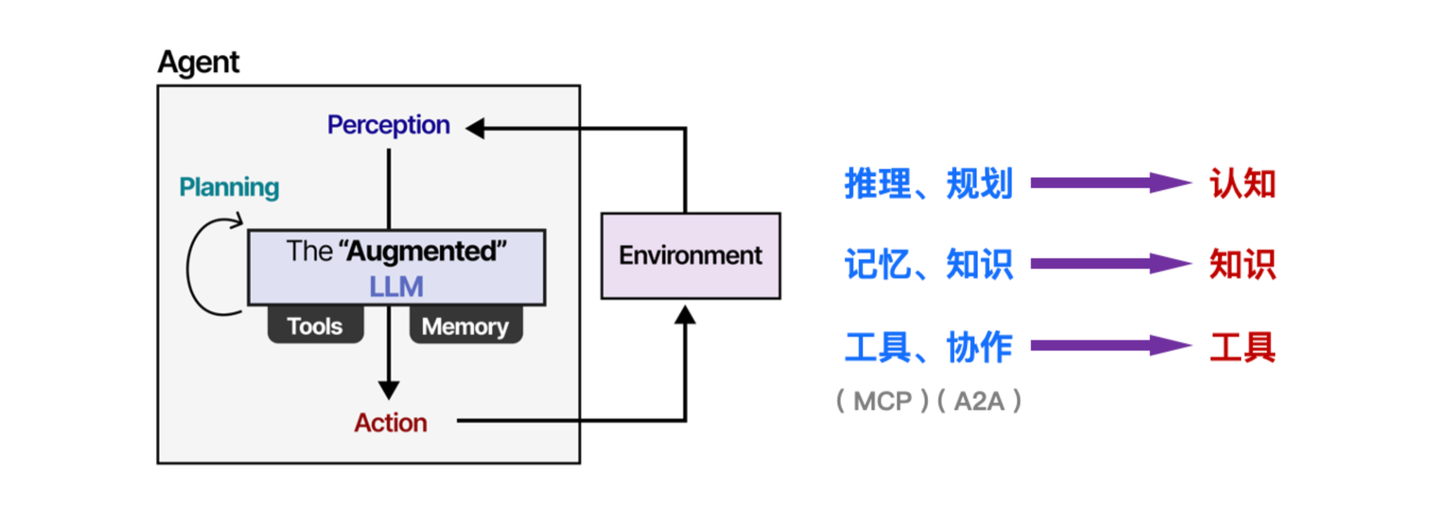
一个是知识,一个是工具,还有一个就是认知。
而在《A Visual Guide to LLM Agents》一文中,对智能体的结构有个比较清晰的可视化描绘,与《人类简史》中的观点相互呼应。在智能体结构中,通过增强式 LLM 提供「推理」与「规划」能力,比如 CoT、LRM等,这部分对应智能体的「认知」。而「记忆」组件和环境中的外部「知识」对应智能体的「知识」,以及「工具」集和智能体之间的「协作」对应「工具」这一范畴。
比较神奇的是,如今热门的 MCP、A2A “恰好”都在工具这个类别下,当然这不是巧合,大厂积极地推广这样的交互协议,本质是期望通过定义智能体与世界的交互标准,达到构建生态的目的。细心的读者可能会发现,大家目前都在“卷”工具的标准,那么知识有没有标准呢?我相信这件事正在发生。
说完智能体的结构,还需要再探索另一个问题:“我们应该选择单智能体,还是多智能体?”。
这个问题近来讨论热度非常高,早先 UC Berkeley 的论文《Why Do Multi-Agent LLM Systems Fail?》就曾揭示,虽然我们都期望多智能体系统能做到「1 + 1 > 2」的效果,但是实测下来却不尽如人意。构建 Devin 的 Cognition AI 最近在《Don’t Build Multi-Agents》一文中,也对多智能体系统「上下文共享」的困难,以及面临的「过度工程化」表达了担忧,转而更关注提升单智能体的可靠性。
虽然反对声音不绝于耳,但也不乏有力的支持者。Anthropic 在文章《How we built our multi-agent research system》中认为多智能体系统在处理复杂问题时,就应该用更多的 Token 换取更好的效果这样的「力大砖飞」策略,同时也提出了诸多优化方法,比如并行优化、工具选型、智能体自我改进等。
当下这个问题并未尘埃落定,单从架构灵活性考虑,支持多智能体能力不失为一种稳健的选择。这样既保留了面向生态和未来的扩展性,也不妨碍我们专注于优化单智能体的能力。
4. 广义仿生:神经元 → 世界
连接主义的代表性技术「神经网络」,是通过模拟大脑神经元的组织和行为而逐步发展的技术体系,属于仿生学习的典型案例。另外,论文《Advances and Challenges in Foundation Agents》中对仿生的理念做了延伸,将大脑的不同功能区与 AI 研究领域进行了映射。
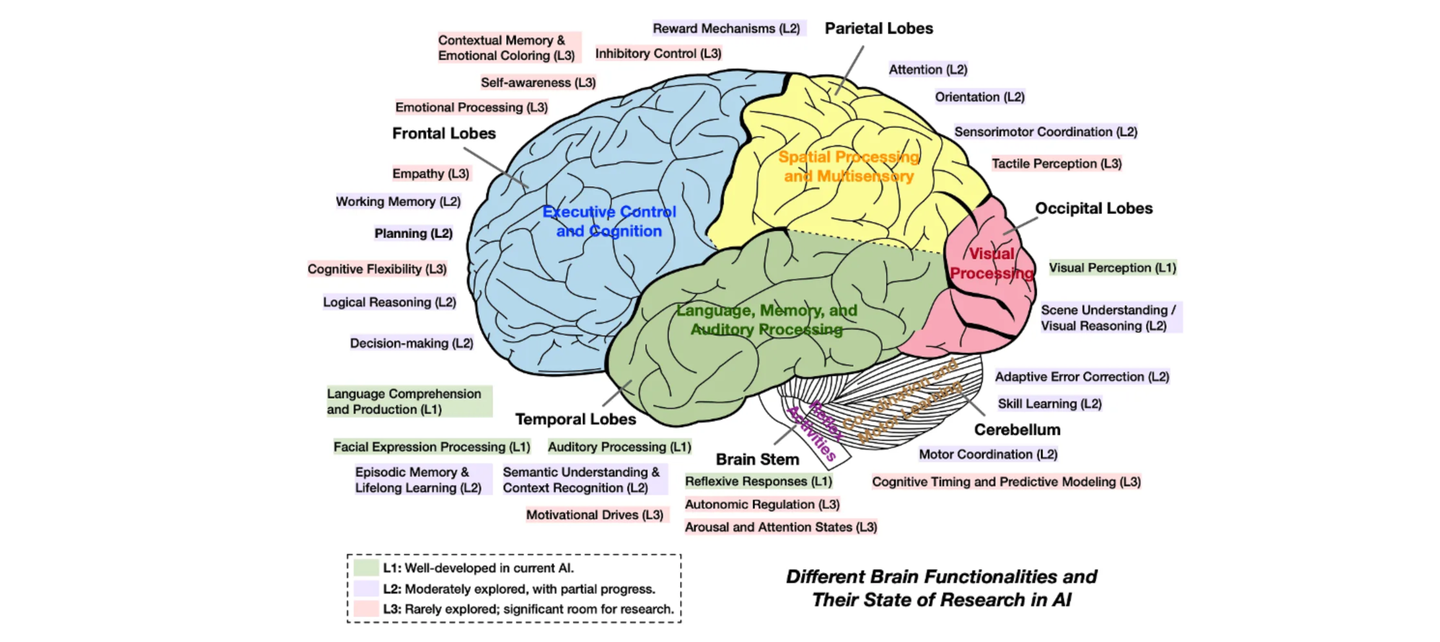
仿生学习理念在智能体时代可以有更广阔的发挥,可以将脑神经科学、认知心理学、社会学、哲学等跨学科知识与计算机科学进行深度的结合。更进一步地,我们扩展出「广义仿生」的理念:从神经元、大脑、四肢、个体、群体乃至到世界的全面仿生。
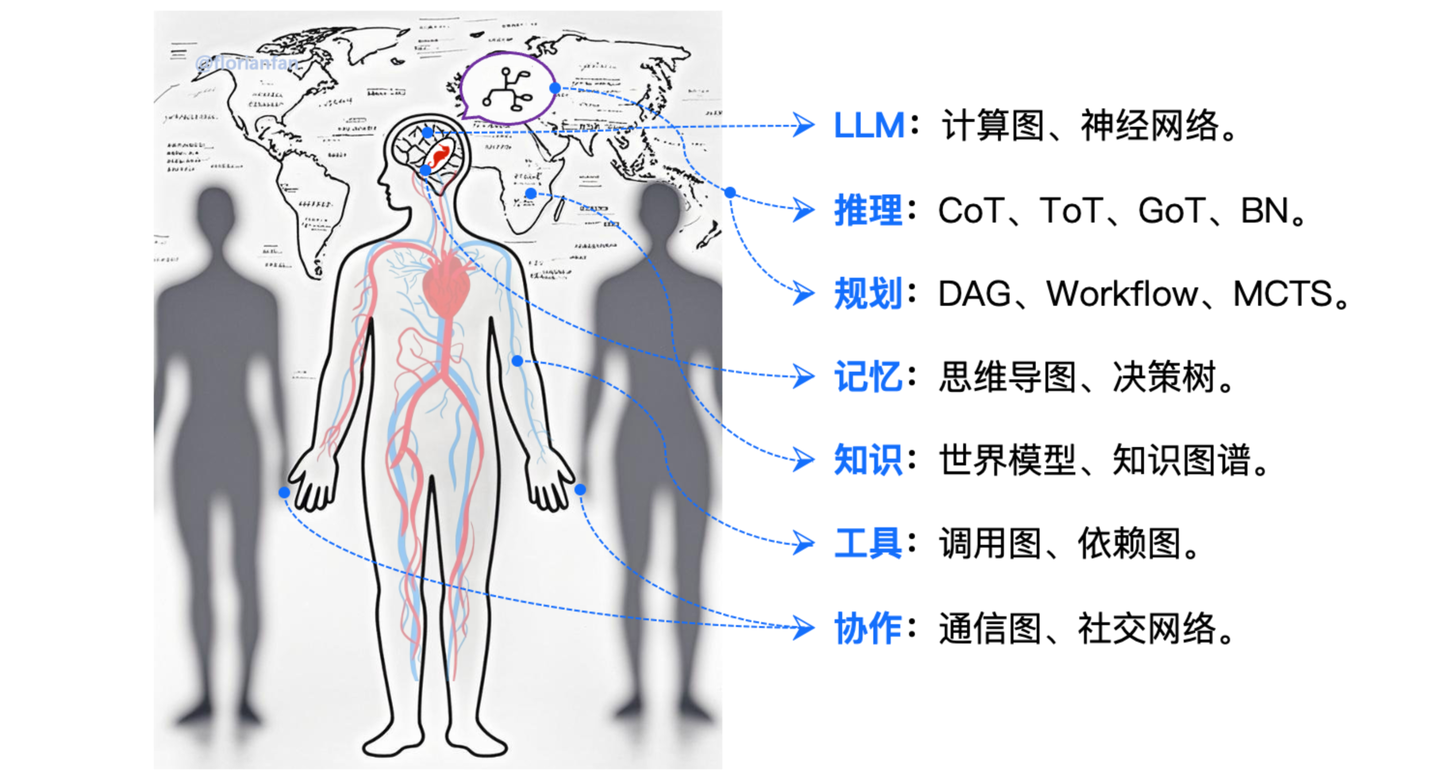
并且,我们发现这种广义的仿生理念,和 Graph 有着深度的内在联系,这得益于 Graph 在描述「事物客观联系」上的天然优势。从而可以使用多样化的 Graph 结构和技术描述智能体中 LLM(大脑)、推理 & 规划(思考)、记忆(海马体)、知识(世界知识)、工具(四肢 & 外部工具)、协作(群体)的内在组织结构,实现 Graph 对智能体能力的全面增强。
5. 图智互融:Graph + AI
结合 GraphRAG 的演进历史,以及 Graph 对「广义仿生」驱动的智能体的设计思考,我们基本梳理清楚了 「Graph + AI」技术的关联逻辑,也就是「图智互融」。
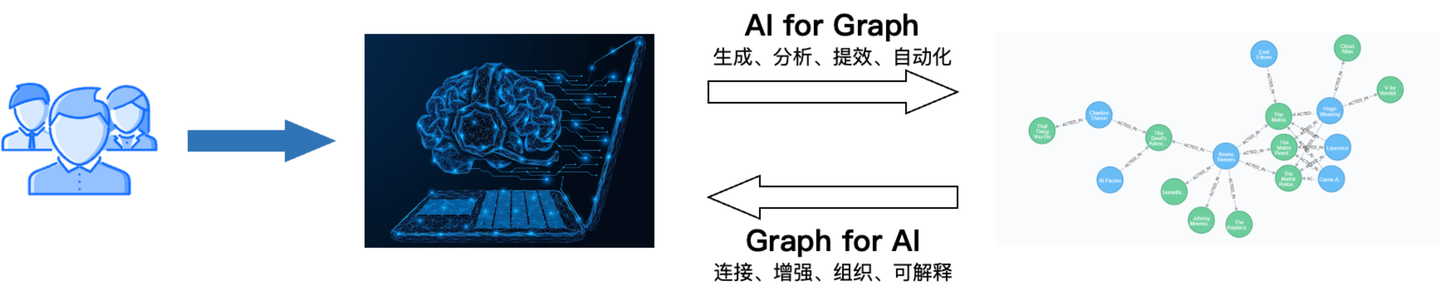
一方面借助 AI 加速 Graph 的构建、分析,提升产品的使用效率和自动化,即「AI for Graph」。另一方面,利用Graph 在连接上的优势,重构 AI 组件的组织,增强推理能力和可解释性,即「Graph for AI」。
5.1 定义图原生
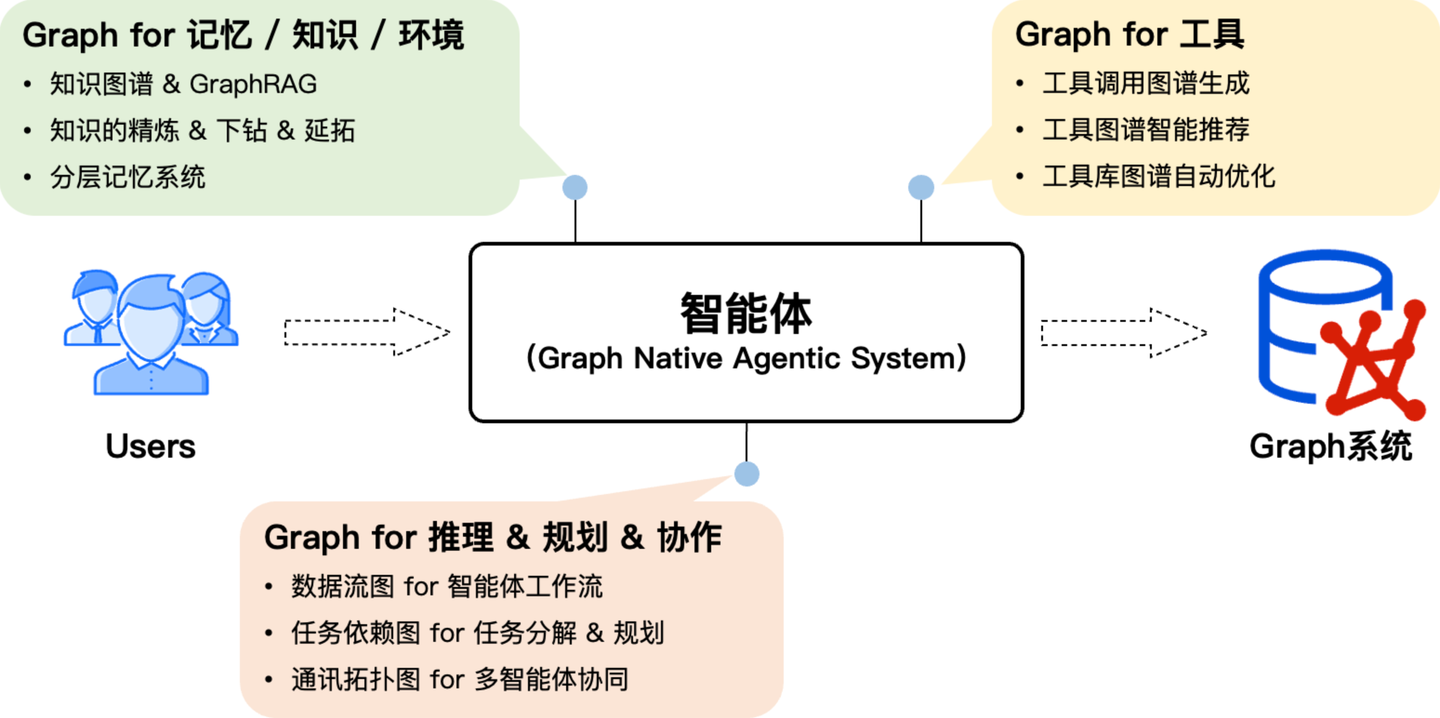
结合「图智互融」的理念,我们定义了 Graph 与 AI 的双向增强逻辑。作为智能体不仅可以解决智能用图的问题,还可以受益于图在智能体系统设计的增强优势,让图的能力在智能体内置化,这就是我们定义的「图原生」。
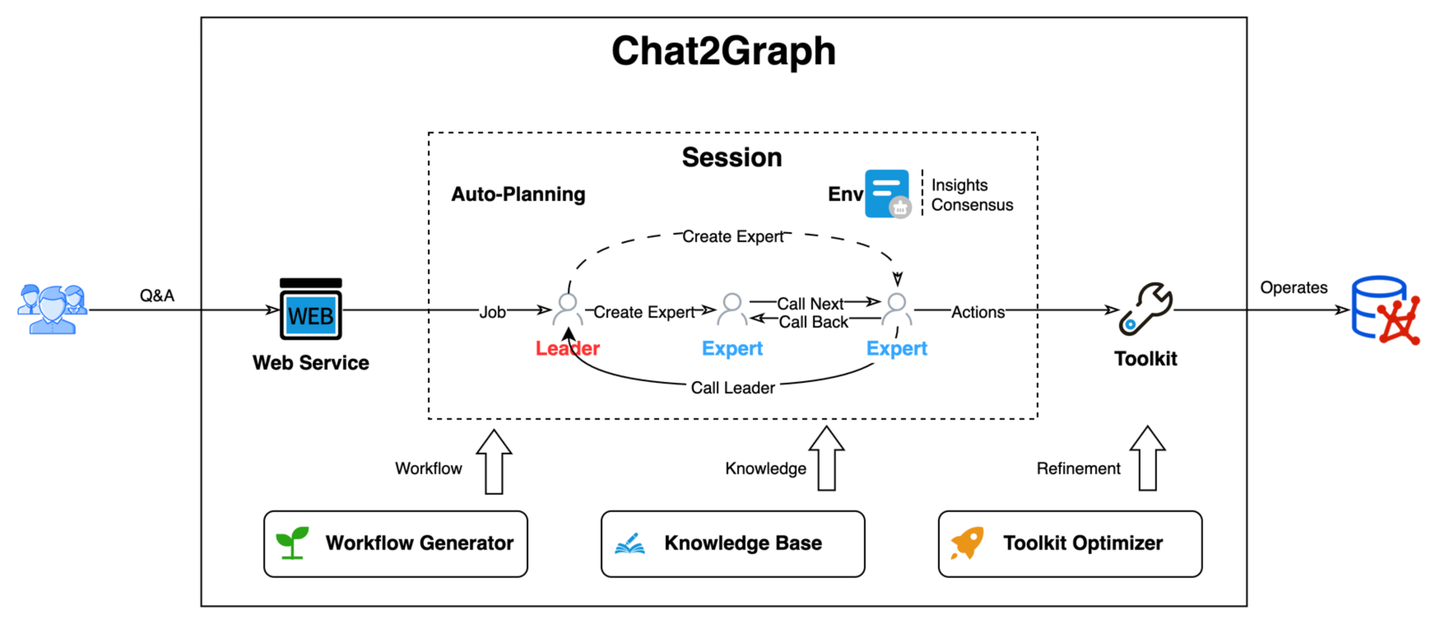
5.2 Chat2Graph 架构
Chat2Graph 是行业首个全面践行「图原生智能体」理念的系统:以智能体为蓝图,探索「图智互融」技术创新。系统采用了「单主动-多被动」的混合智能体架构,构建了以单个 Leader 智能体驱动,多个 Expert 智能体协作的任务执行体系。
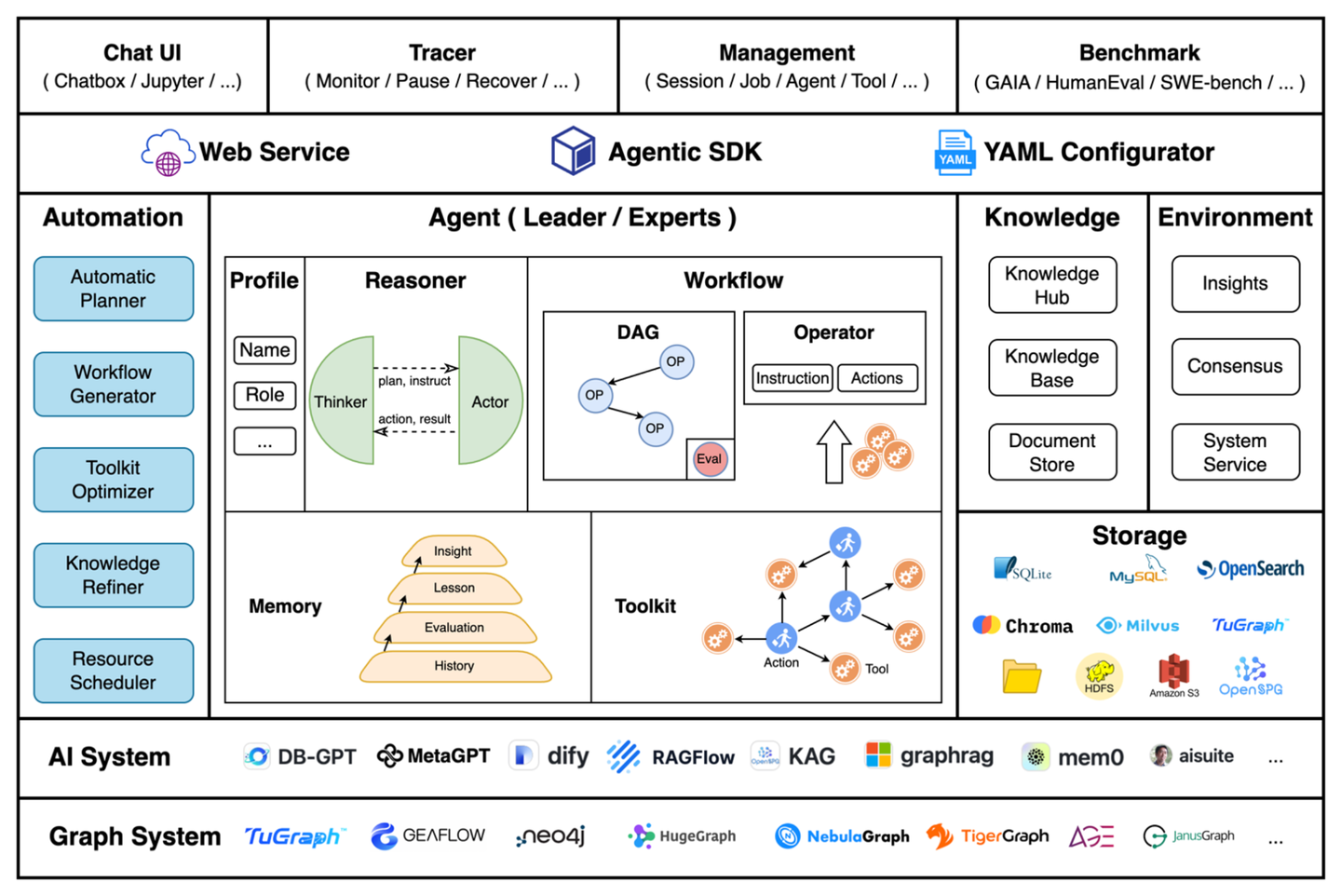
系统的核心组件有:
- 图系统层:构建了面向图系统的统一抽象,使用图数据库服务统一管理,并支持未来更多图计算系统的扩展。
- AI 系统层:构建 AI 基础设施抽象,如智能体框架、RAG、记忆工具、模型服务工具等,提供智能体能力基建和生态扩展。
- 存储服务层:存储智能体的持久化数据,包括元数据、记忆、知识、文件等。
- 推理机:提供 LLM 服务封装、推理增强、工具调用等基础能力。
- 工作流:负责智能体内部的算子(Operator)编排与SOP抽象,定义智能体工作流程。
- 记忆系统:构建分层的知识精练体系,负责智能体系统的信息存储、检索,包括记忆管理、知识库、环境等。
- 工具库:基于图谱的方式描述工具和智能体行动的关联关系,实现工具的自动化管理和推荐。
- 智能体:智能体系统执行单元的统一抽象,使用角色定义(Profile)描述工作职责,使用工作流描述工作流程。主要包括 Leader 智能体和 Expert 智能体两大类型。
- 自动化:系统智能体化能力的抽象,「Less Structure」理念的实践手段。包括自动的任务规划、工作流生成、工具库优化、知识精练、资源调度等能力。
- 系统集成:提供 Web UI、Restful API、SDK 的集成方式,通过 YAML 一键配置智能体系统,方便开发者快速接入 Chat2Graph 的能力。
系统运行时,Chat2Graph 能够将用户的自然语言指令智能地转化为一系列精确、自动化的图数据构建、数据处理、算法应用和迭代优化的步骤。这极大地降低了用户进行复杂图分析的技术门槛,使得非技术背景的用户也能利用图的强大表达能力进行深度探索和知识发现。
关于智能体的标准定义,行业并未形成统一标准,但智能体的关键组件概念基本上已经深入人心:如推理、规划、记忆、知识、行动、工具、协作、环境等等。早在 2023 年 OpenAI 安全 VP 翁荔在文章《LLM Powered Autonomous Agents》中就提出 「Agent = 规划 + 记忆 + 工具 + 行动」的基本结构。后续随着智能体技术的行业演进,出现了诸多「改进型」范式,如 「Agent = 规划 + 记忆 + 工具」,甚至更极端的「Agent = LLM + 工具」的定义。
在设计 Chat2Graph 的过程中,我们经过长期的深度思考,总结了 Chat2Graph 对 Agent 结构的理解。即「Agent = 推理 + 记忆 + 工具」,规划 & 协作属于高维的推理,知识 & 环境属于高维的记忆,行动 & 战略属于高维的工具。接下来我们先按照这个总体理念,介绍 Chat2Graph 的关键组件设计和实现原理,并在「开放架构」章节解释这个观点的自洽性。
5.3 推理系统
推理系统整合了 LLM 的交互能力,从提示工程激发 LLM 的「推理」能力,到任务拆分「规划」复杂任务,再通过多智能体「协作」完成总体目标,是智能体系统「智能」的统一抽象。
5.3.1 推理增强
常规 LLM 推理能力增强有两种主流路线,一种是借助 RL(强化学习)增强隐式推理能力的 LRM 模型路线,另一种是通过提示工程(CoT 等)增强 LLM 显式推理能力的工程路线。
当前 Chat2Graph 的推理机选择了工程路线的实现方式,结合了「快慢思考」的认知模型,构建了「双模推理机」能力(DualModelReasoner)。快慢思考的实践理念在智能体领域有不少的应用案例,比如来自 Google DeepMind 的研究工作《Agents Thinking Fast and Slow: A Talker-Reasoner Architecture》就很具代表性。
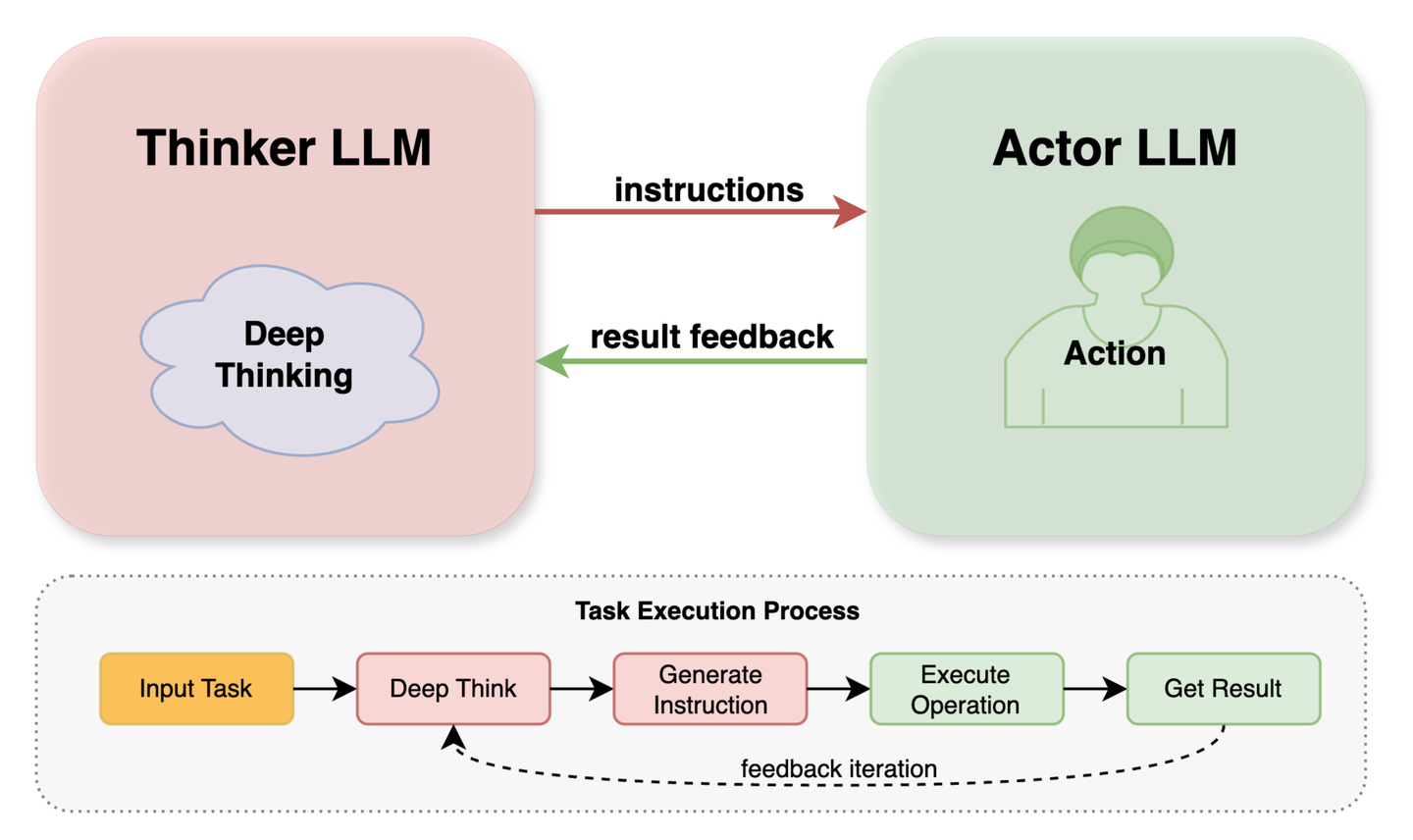
DualModelReasoner 采用一个“思考者”(Thinker)LLM 和一个“执行者”(Actor)LLM 协同工作的模式,类似于两个 LLM 在“一言一语”地交叉式地对话。Thinker 通常是能力更强、理解和规划能力更出色的 LLM,负责理解复杂的用户意图、分解任务、制定计划,并在需要时决定调用哪个工具或子任务,可以将具体的、定义清晰的、步骤性的任务或工具调用请求传递 Actor 模型执行。Actor 模型则是在遵循指令进行格式化输出、执行特定类型的工具调用、快速思考回答更高效的 LLM,可以专注于处理工具调用的请求和响应格式化,使得 Thinker 模型能更集中于核心的推理和规划。
关于 LLM 推理能力增强是走模型路线,还是工程路线,我们认为不是一个选择题。我们期待 LLM 未来推理能力的持续改进与提升,也不排斥在 LLM 推理能力不足时期,引入必要的工程手段加以补充。
5.3.2 任务规划
任务规划是一个相对模糊的概念,至少在智能体系统内,有两类规划场景。一类是面向不确定的用户原始问题,如何拆分为具体的子任务,并安排好子任务的执行和依赖关系,即任务拆分,产出为 JobGraph。另一类则是针对特定领域的子问题,如何设计合理的流程对任务分阶段处理,即 SOP,产出为 Workflow。
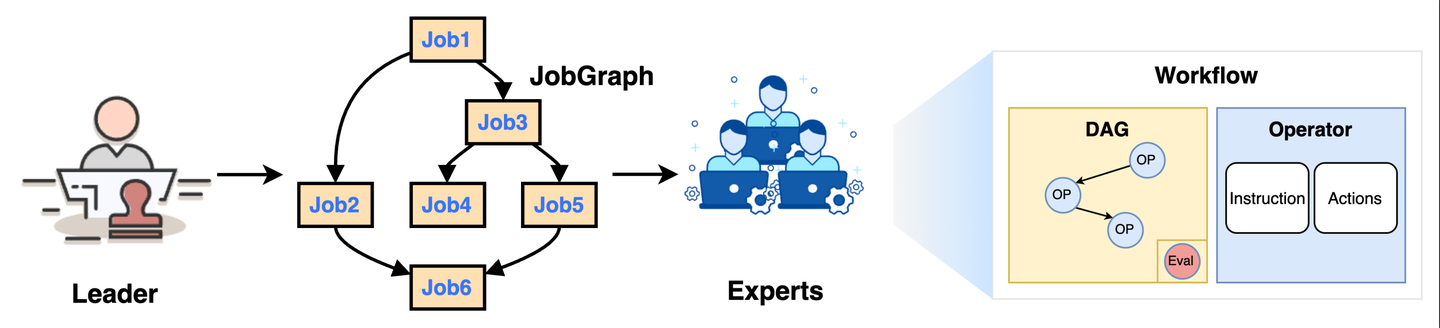
其实这两类场景其实本质是相同的,在 Chat2Graph 中,JobGraph 更侧重于描述智能体间的职责分配,Workflow 则更侧重描述单智能体内部的职责,仅仅是对用户目标的拆分粒度在不同的层面而已。当前 Chat2Graph 的 JobGraph 由 Leader 统一完成,而 Workflow 还是「硬编码」在智能体内部,同时我们也在 OSPP 中和社区一起共建「自动工作流生成」能力。未来,这两部分规划能力,即 JobGraph 和 Workflow 可以做到统一整合。
5.3.3 协作执行
协作当前更多的还是强调多个智能体之间的互动,处理任务、资源的动态分配和调度。不论是采用「单主动-多被动」的统一 Leader 协调方式,还是多个 Expert 自由通信的自主方式。亦或采用单进程的串行处理,还是使用远程通信的并发处理。多智能体系统的协作机制都要处理以下几个关键问题:
- 任务分配:将拆分好的子任务合理地分配到对应的智能体执行。
- 执行容错:任务执行结果的评估与反思,并能通过重试自动恢复。
- 重新规划:对不合理的任务拆分的容错能力,能适时的请求重新规划流程。
- 结果交付:能通过合理的协作,对任务产出物生成、加工、优化,交付预期结果。
- 资源调度:通过调度优化资源的使用,降低时间、空间、Token 开销,提升质量。
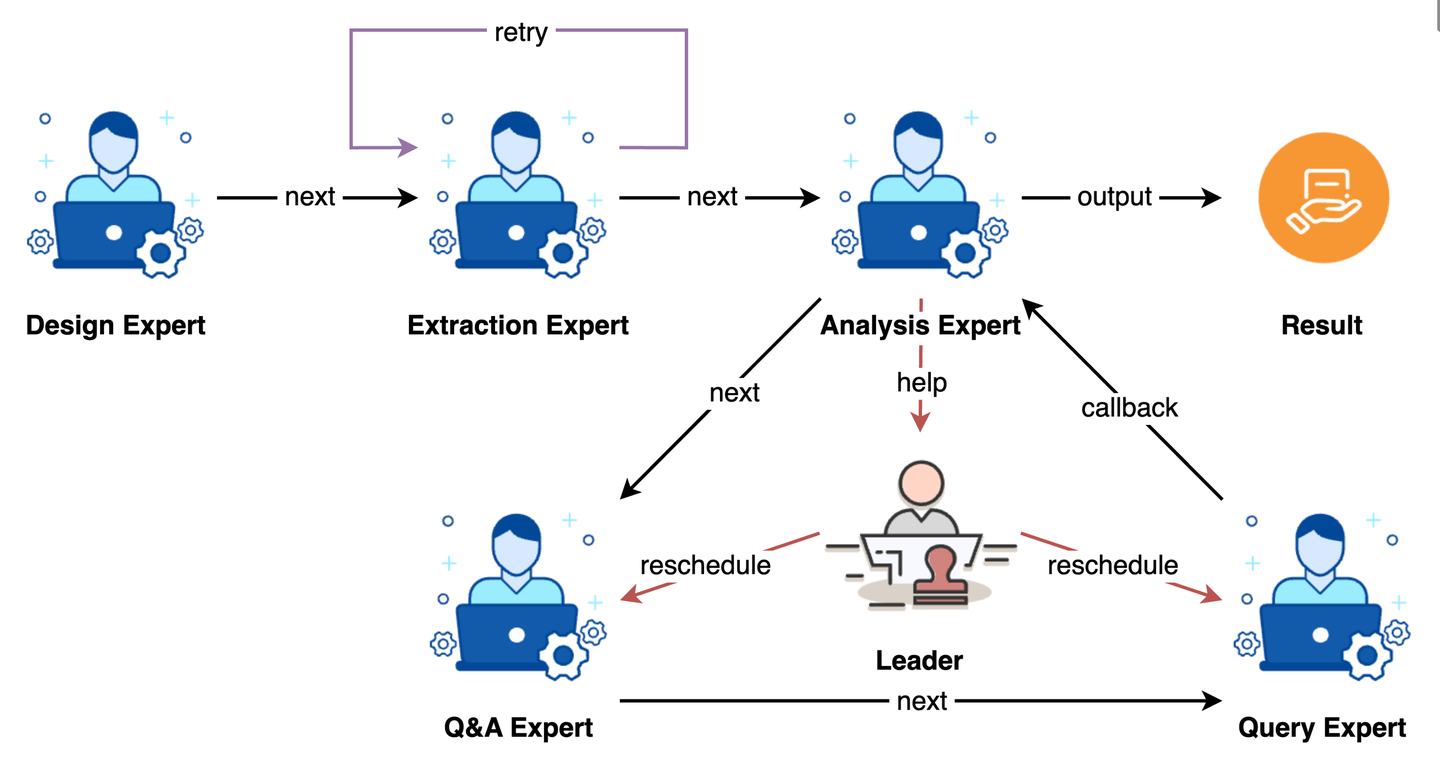
相比 Workflow 的「静态」属性多一些,更侧重规范化流程,JobGraph 的「动态」属性则多一些,更侧重任务的灵活性以及能力扩展。尤其是类似 A2A 协议定义了智能体交互的规范,更需要良好的协作机制,通过引入更开放的生态,扩展系统边界,提升解题能力。
5.4 记忆系统
记忆系统负责智能体系统中信息的存储、检索和管理,可以与推理机配合构建长上下文、跨会话机制,为整个系统提供持久化的学习和适应能力,提升系统的整体智能水平。Chat2Graph 引入了分层「记忆」设计,定义了从原始数据逐步提炼到高层次的智慧洞察的过程,希望使用统一架构兼容「知识」库、外部「环境」信息。
5.4.1 分层记忆
与传统的基于仿生理念将记忆划分为感知记忆、短期记忆、长期记忆的划分手段不同,Chat2Graph 借鉴了 DIKW 金字塔模型,从信息的内容角度出发将记忆划分为四层结构。

这是一次新颖的尝试,我们更相信在记忆系统的设计中引入数据工程、知识图谱等传统数据处理方法,而非单纯地走「仿生」的路线。
5.4.2 知识管理
一般的,知识库被看作外部知识的「封闭式」存储仓库。为了提升知识召回的质量,RAG 框架多数情况在对知识库的外围技术做改进,比如查询重写、文档切分、重排序等等,反而忽略了知识内容自身的改进。当然,GraphRAG 可以看做一种相对早期的尝试。分层记忆系统的引入,为精细化的知识管理的提供了「开放式」的解决思路。
分层记忆系统引入的多级信息抽象,允许我们能从更精细的粒度对知识进行管理。
- 知识精练(Knowledge Refinement):原始知识经过逐级的处理、分析、抽象、压缩,形成更高层次的知识,扩展知识生产的能力。
- 知识下钻(Knowledge Drilling):在使用高维知识的同时,还可以按需下钻低维知识,让推理上下文粗中有细,强化知识消费的能力。
- 知识延拓(Knowledge Expansion):表示同层级知识关联的构建和召回,通过特定方法丰富知识上下文。典型代表是 RAG(检索增强生成)。
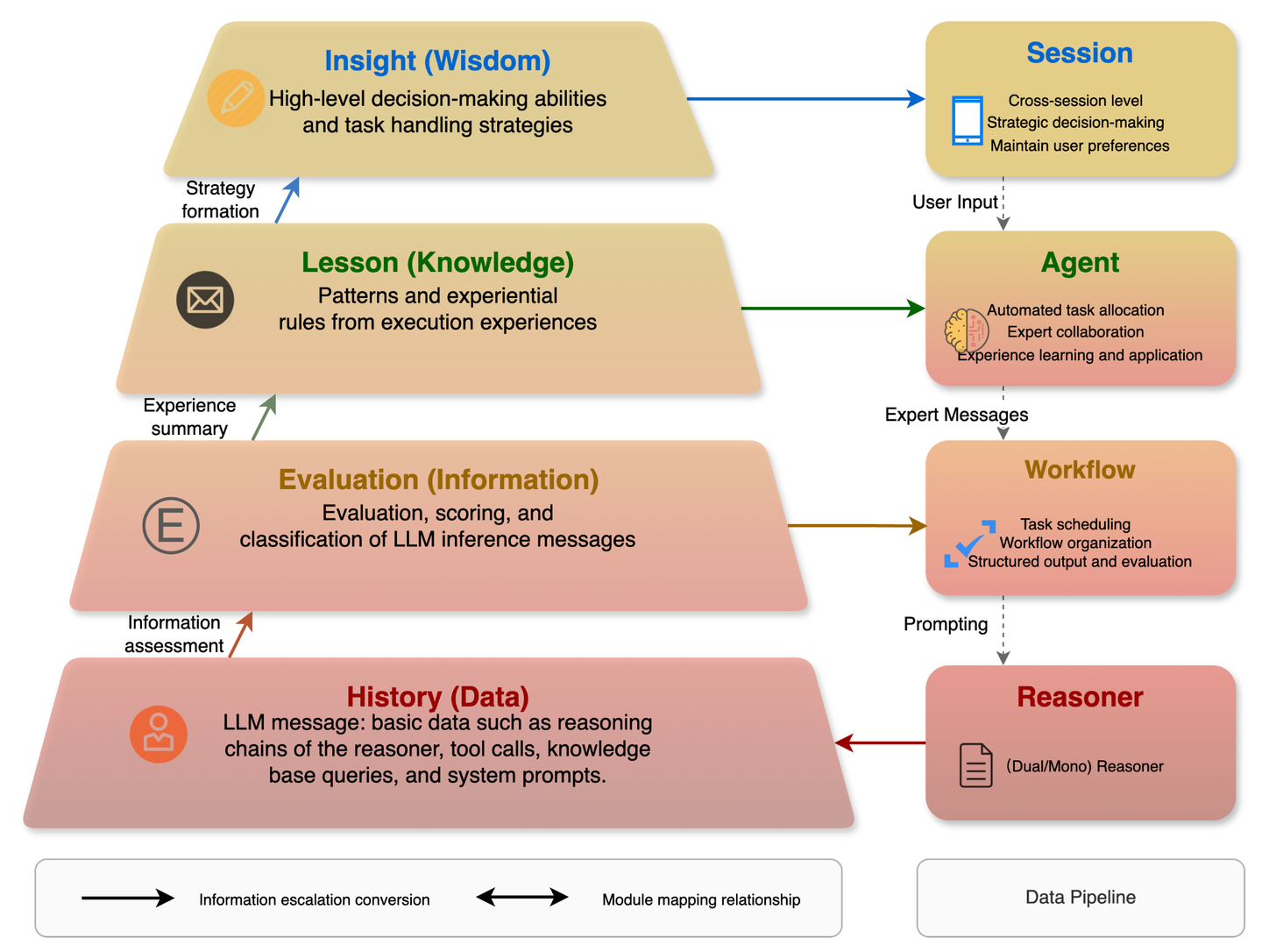
从某种意义上讲,「知识库其实是记忆系统在垂类领域知识上的特化表达」。当前 Chat2Graph 初步地将 RAG 作为知识库的实现底座,并正在与 MemFuse 在社区上通力合作,构建分层、动态、关联的记忆系统架构,最终实现知识库能力整合。
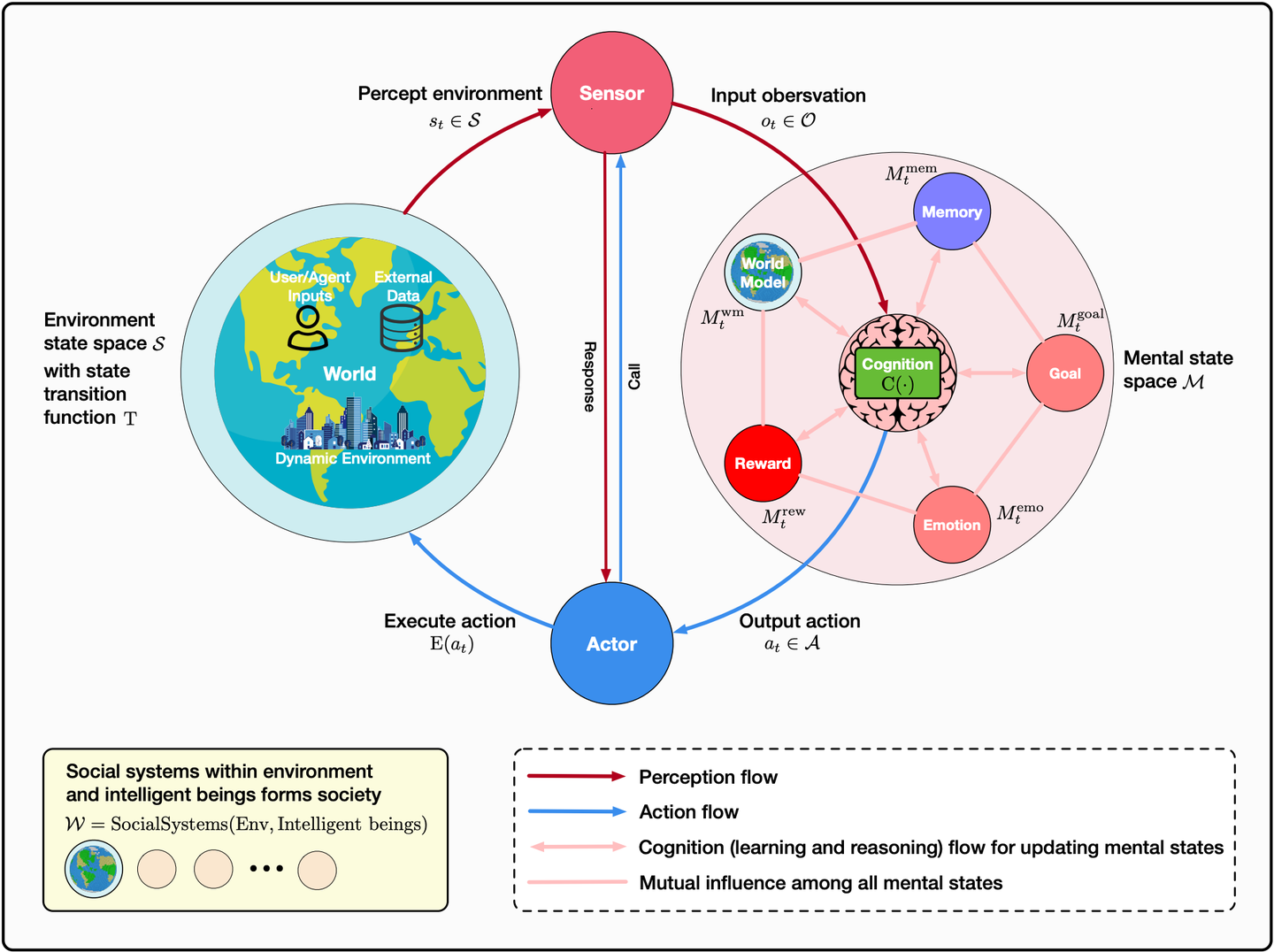
5.4.3 外部环境
环境指的是智能体执行过程中可交互的外部空间,智能体可以通过工具操作感知环境变化,影响环境状态。本质上,「环境可以被视为"当前时刻的外部记忆",而记忆则是"历史时刻的环境快照"」,这种同质性使得环境可以无缝地融入分层记忆模型中。Agent 通过工具感知的环境信息其实是 L0 层的原始数据,并可以进一步的提炼形成更高层次洞察(L1 ~ L3)。反过来,记忆系统中经验积累会直接影响环境中的全局共识和高维洞察。
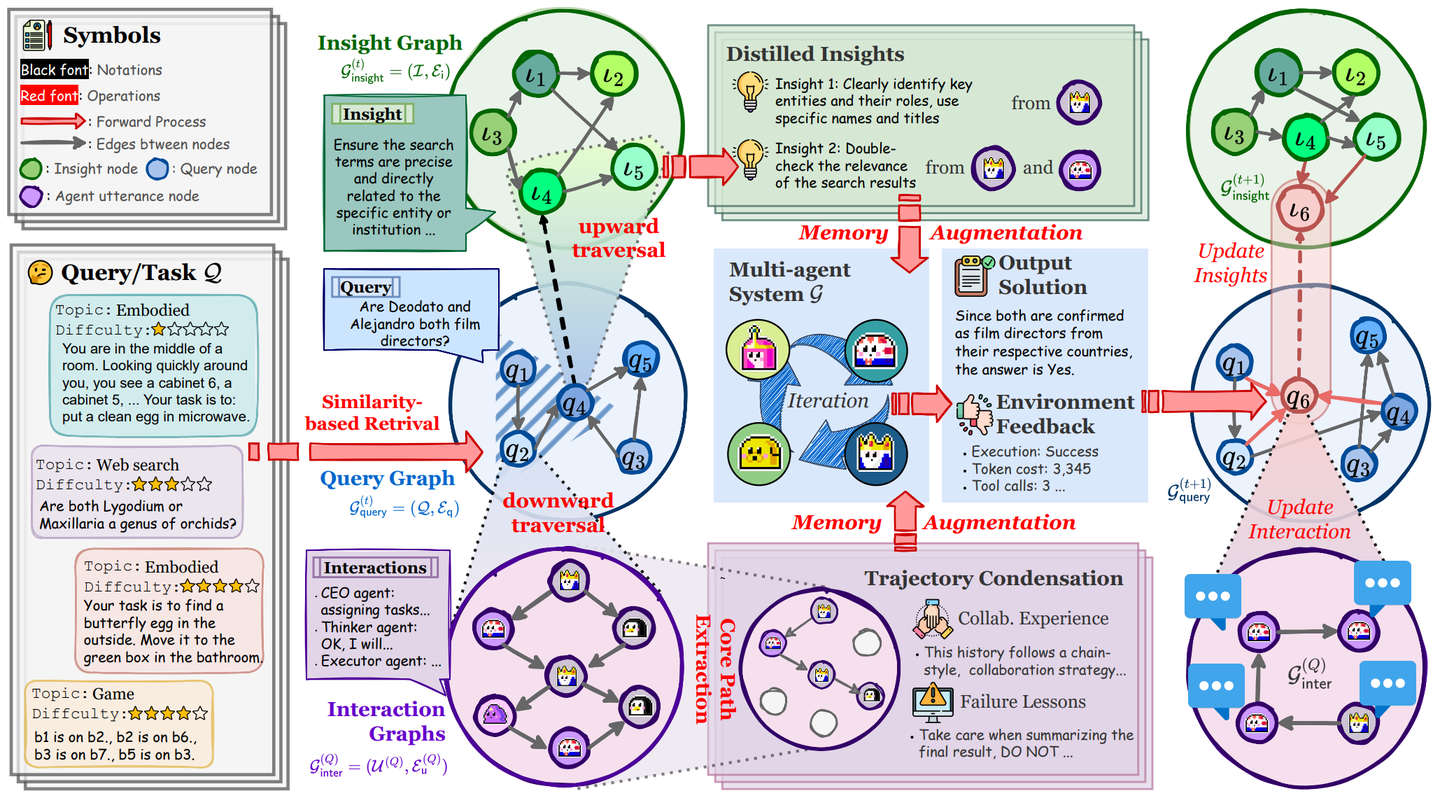
最新的 G-Memory 的研究与我们的分层记忆系统的理念不谋而合,它设计了三层图结构来管理记忆:
- 交互图(Interaction Graph):存储细粒度的智能体间的通信日志,提供事实依据。
- 查询图(Query Graph):记录任务节点(含状态)以及语义相似或关联的任务关系,并与交互图链接。
- 洞见图(Insight Graph):存储从多次成功或失败的交互中提炼出的、具有普适性的经验和教训。
另外,从智能体与外部环境的关系来看,通过「工具」这座桥梁,可以深层次地打通记忆系统与环境状态,构建智能体的「精神世界」与外部环境的「物理世界」的映射关系,即世界知识模型。
5.5 工具系统
工具系统负责智能体系统中「工具」的调用与管理,通过与「行动」关联构建工具库图谱,并能提供「战略」性的指导建议为推理机推荐合适的工具集,扩展智能体行为能力的边界。
5.5.1 工具调用
工具调用早期的形态来源于 LLM 的 Function Calling 机制,随着 LLM 能力不断提升,通过提示工程构建通用的工具调用能力已经相当普遍。
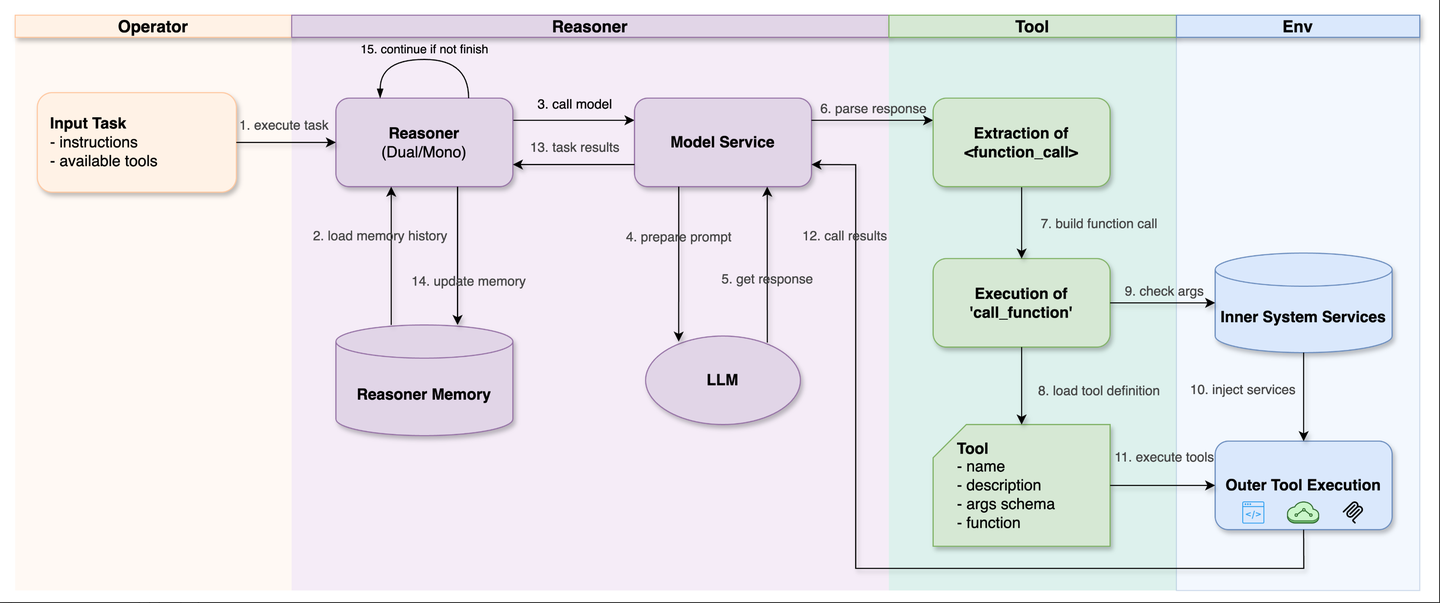
在 Chat2Graph 中,推理机可以结合任务目标,从候选工具集中确定所需的工具并触发调用动作。除了对常规意义的外部工具(如脚本、API、MCP)的支持,Chat2Graph 还允许将系统的内置服务(文件服务、知识库服务等)注入到工具,以便和系统资源无缝打通。从整个智能体角度来看,这么做提升了工具调用的扩展性和灵活性。
5.5.2 行动关联
随着智能体接入的行业领域不断增长以及工具控制粒度的不断细化,智能体面临的工具规模管理成本和合理工具选型的难度将不断提升。面向大规模工具集的合理工具选型是一个典型的「推荐问题」,而「二分图」是解决推荐问题时常用的图数据抽象,因此构建「行动 - 工具」的关联图谱就十分合理。
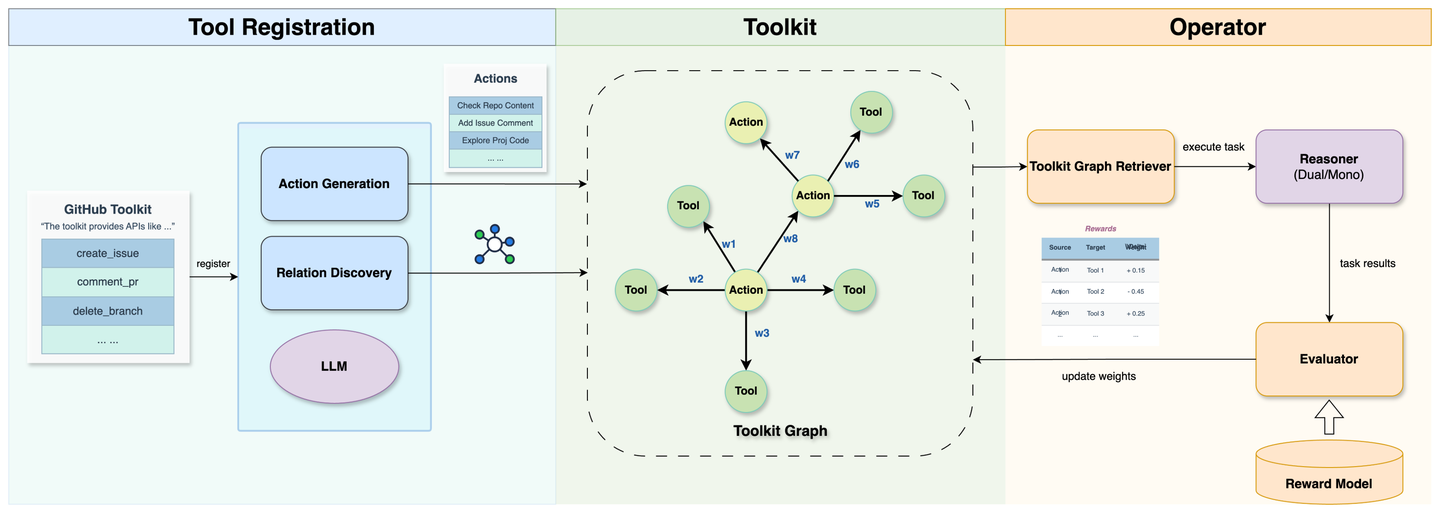
在 Chat2Graph 中,正在建设自动化的工具图谱构建、优化、推荐的能力。比如一键注册工具包、MCP Server 到工具图谱,并结合强化学习的思路优化工具的元信息、关联关系和权重等。
5.5.3 战略指导
如果说行动是对工具的初级抽象,那么战略则是对行动的进一步抽象。通过建立行动的高维抽象,描述行动间的顺序依赖和关联关系,为智能体的行为序列推荐提供战略性的指导建议,进一步提升工具图谱的丰富度和推荐能力。这一部分的工作我们还在逐步探索。
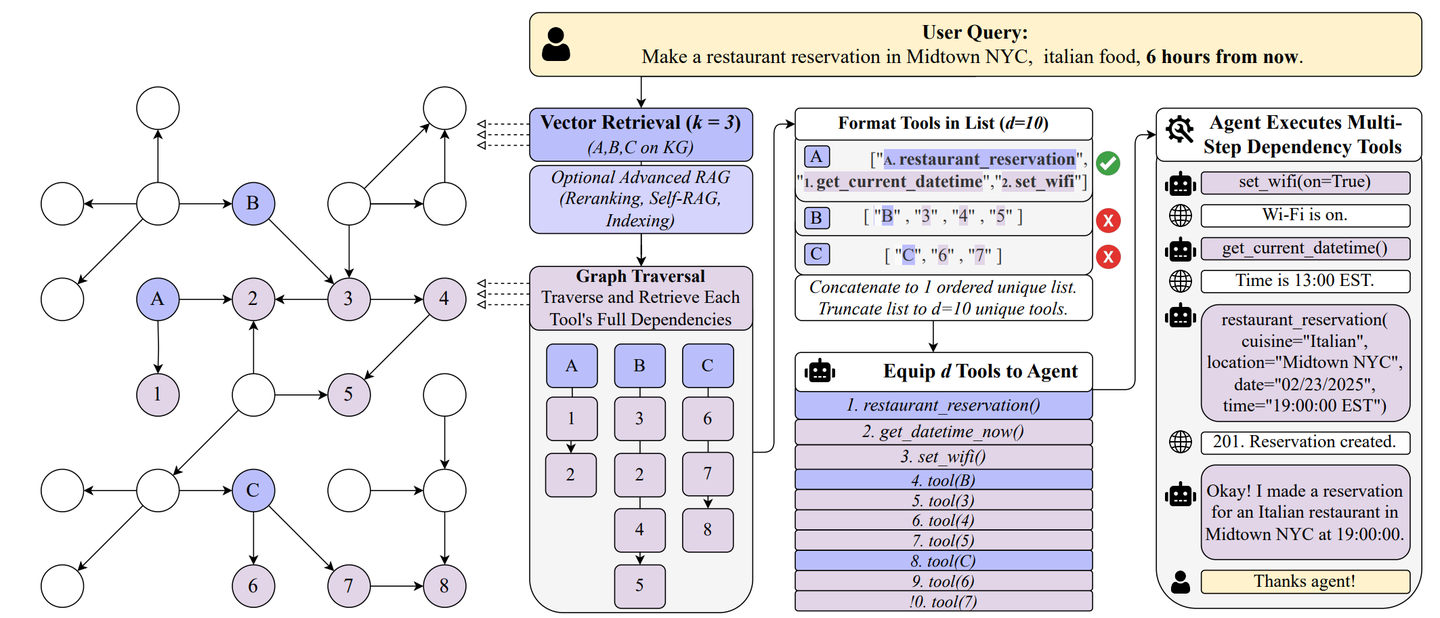
使用工具图谱组织工具库内在结构,在学术界也有一些前置的研究工作可以参考,如论文 《ToolNet: Connecting Large Language Models with Massive Tools via Tool Graph》使用有向图组织工具关系并使用自适应权重兼容新工具集成,以及《Graph RAG-Tool Fusion》通过结合 GraphRAG 与工具库建模,研究提升工具推荐效果的方法。工具图谱的研究和热度明显还处于行业早期,我们非常期待在 Chat2Graph 社区能找到志同道合的朋友共建这块能力。
5.6 开放设计
随着智能体行业技术的不断迭代和演进,智能体产品「百花齐放」,但智能体产品之间缺乏有效的连接。前不久微软在论文《Interaction, Process, Infrastructure: A Unified Architecture for Human-Agent Collaboration》里提出了人机协作的分层框架,在承认智能体专业化的前提下,专注于智能体协作。期望建立一个让所有智能体都能协作的架构,这就对智能体架构的开放性提出了更高的要求。Chat2Graph 在设计之初,就非常关注架构的开放性和扩展能力。我们甚至可以通过一个 YAML 文件完整的描述多智能体系统的能力,而不需要复杂的硬编码。
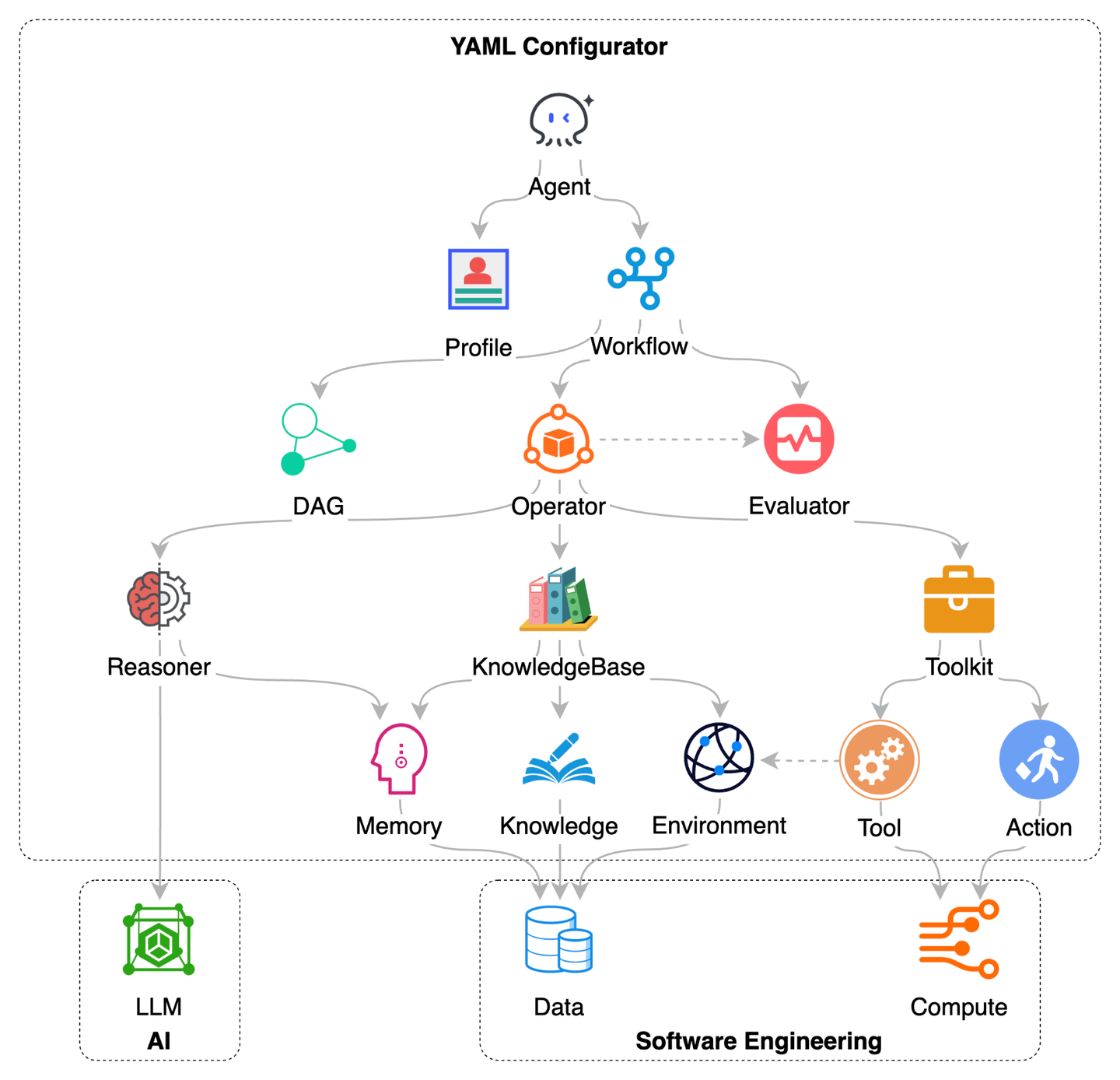
传统的软件工程核心本质在于解决数据和计算的问题,通过设计良好的编程语言高效地操纵 CPU 和存储,通过合理的数据结构和算法描绘软件的功能逻辑,通过优雅的架构定义软件的数据模型和计算抽象,因此可以说「数据」和「计算」是传统软件工程的基石。基于 LLM 的 AI 行业爆发以后,引入了第三块基石 —— 「模型」,将传统软件工程升级为 AI 软件工程,Agent 便是最典型的代表。
结合前面对 Chat2Graph 架构原理的解读,可以进一步得到如下抽象能力矩阵。
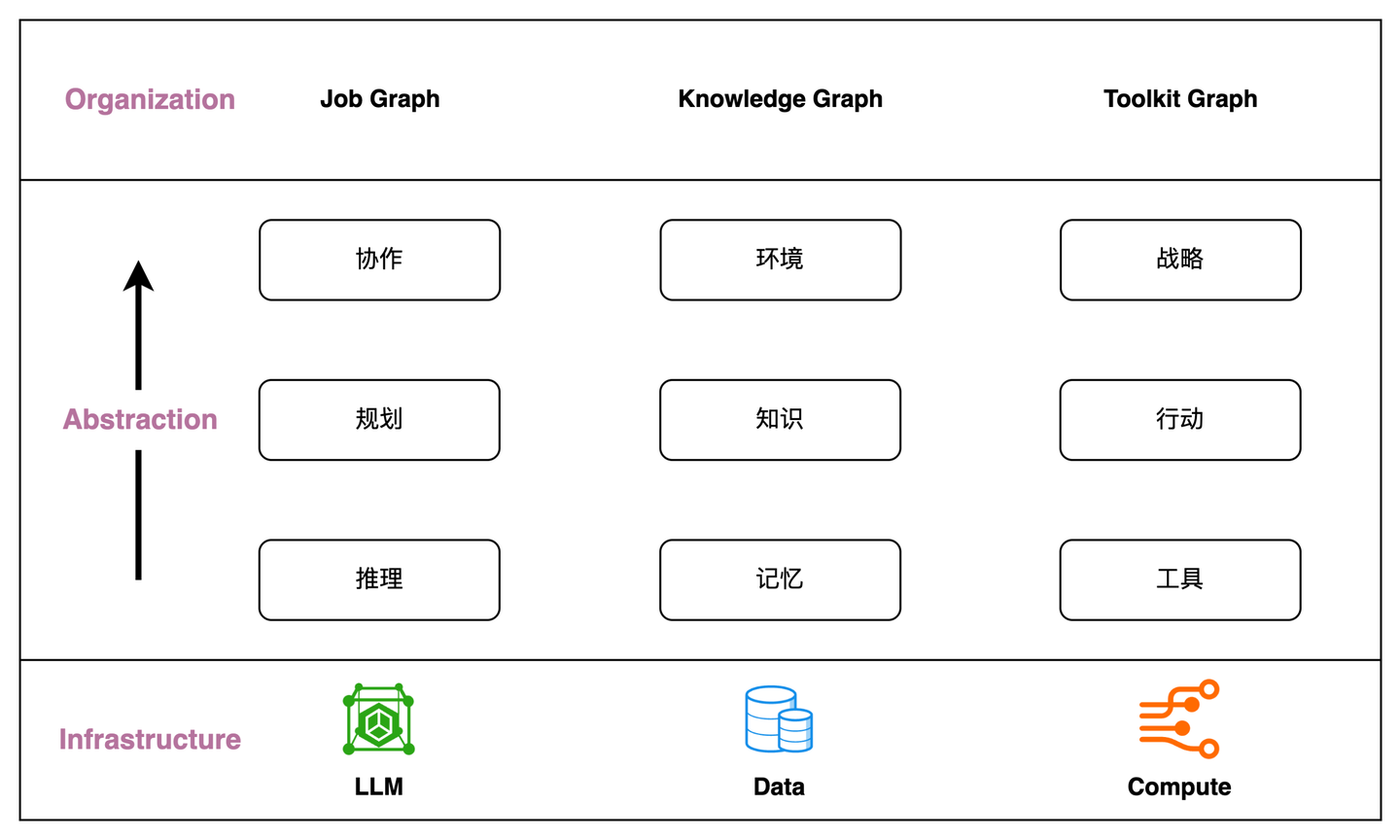
我们认为,「推理」、「记忆」、「工具」是对 AI 工程三大基石「模型」、「数据」、「计算」的工程化表达,同时「规划 & 协作」、「知识 & 环境」、「行动 & 战略」是对「推理」、「记忆」、「工具」的进一步抽象,而它们都可以使用 Graph 统一表达,分别对应「任务图谱」、「知识图谱」、「工具图谱」,甚至在未来这三张 Graph 还可以进一步融合,这便是我们对「Graph for AI 软件工程」的整体理解。
基于这样的第一性思考,再结合 MCP、A2A 这样的标准化协议,可以指导 Chat2Graph 面向未来的开放设计。甚至可以让 Chat2Graph 形成自主迭代能力,引导 Chat2Graph 从 AI Agent 走向 Agentic AI。
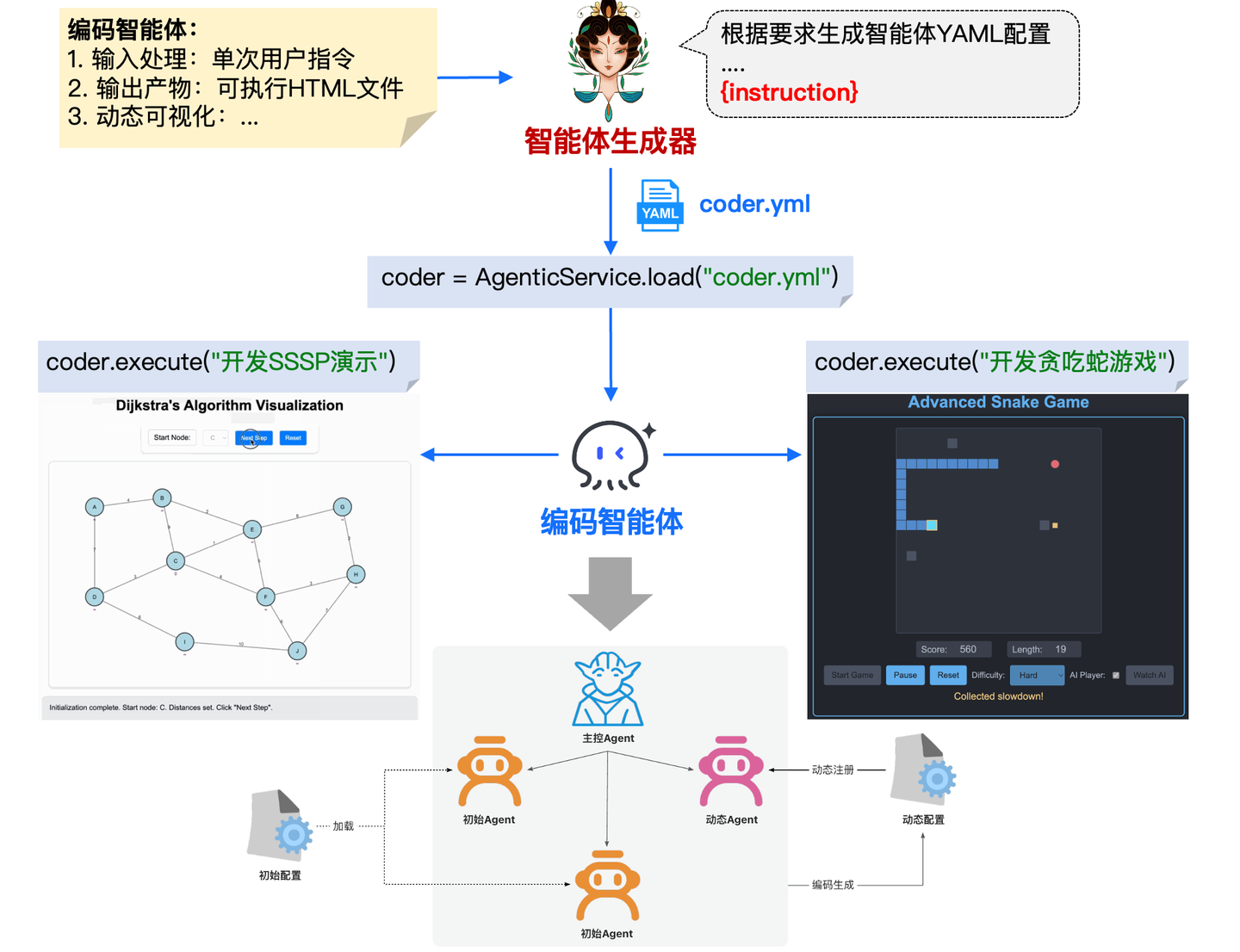
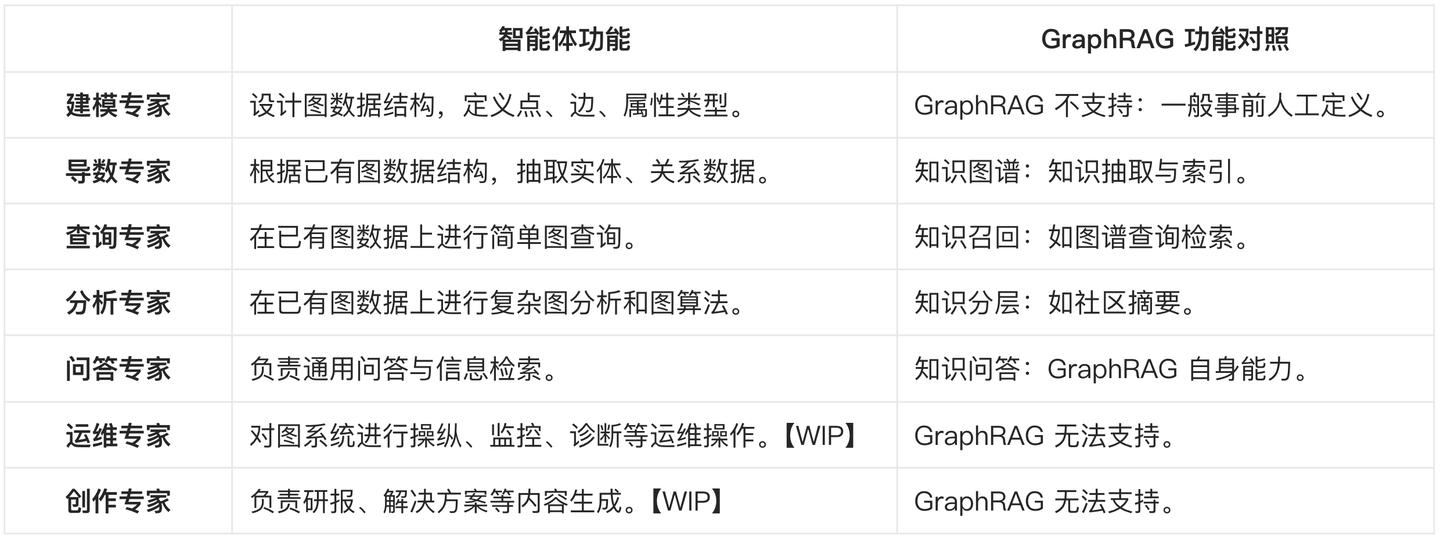
5.7 与图对话
Chat2Graph 当前内置了多个图领域专家,可以通过多智能体协作的方式传统 GraphRAG 的链路工作。
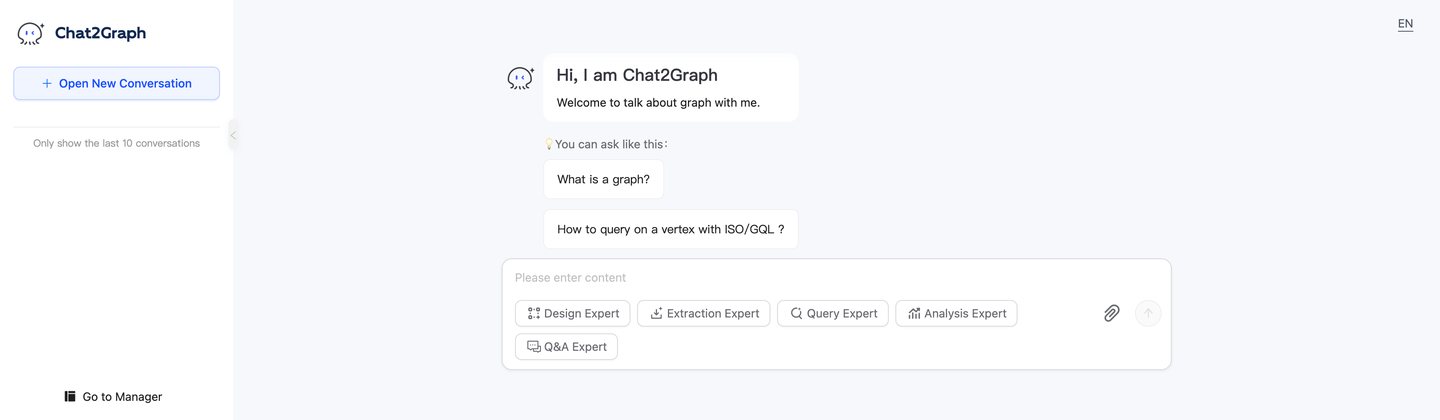
通过 Chat2Graph 服务可以体验白屏产品流程,具体参考快速开始文档。
另外,基于 Chat2Graph SDK 也可以实现轻松集成到你的 Python 应用。
# init
chat2graph = AgenticService.load("app/core/sdk/chat2graph.yml")
# sync execution
answer = chat2graph.execute("What is TuGraph ?").get_payload()
# async execution
job = chat2graph.session().submit("What is TuGraph ?")
answer = job.wait().get_payload()
6. 未来形态:Graph ⋈ Agent
以上我们全面解读了 Chat2Graph 践行「Graph + AI」理念的细节,即 GraphAgent。关于 Graph ⋈ Agent 的未来形态,还有一些关键的点需要持续保持关注。
6.1 Less Structure
由 Manus 团队提出的智能体产品设计理念,「Less Structure, More Intelligence」是 AI Native 思想的直观表达,正在深刻影响着智能体的演进路径。过度结构化将扼杀智能体的涌现潜力,但「Less Structure」并非简单的「去结构化」,而是就智能体设计这个问题上,人与 LLM 之间的「信任转移」,即你更相信自己多一些,还是更相信 LLM 多一些?
这个思路的转变,最直接的影响就是让智能体设计从「被动响应式」转向「自动行动式」,这为智能体的「智能涌现」提供了机会,即「人类定义意义,智能体扩展可能」,也就是最近经常讨论的 Agentic AI。论文《AI Agents vs. Agentic AI: A Conceptual Taxonomy, Applications and Challenges》清晰地定义了 AI Agent 与 Agentic AI 的能力差异。
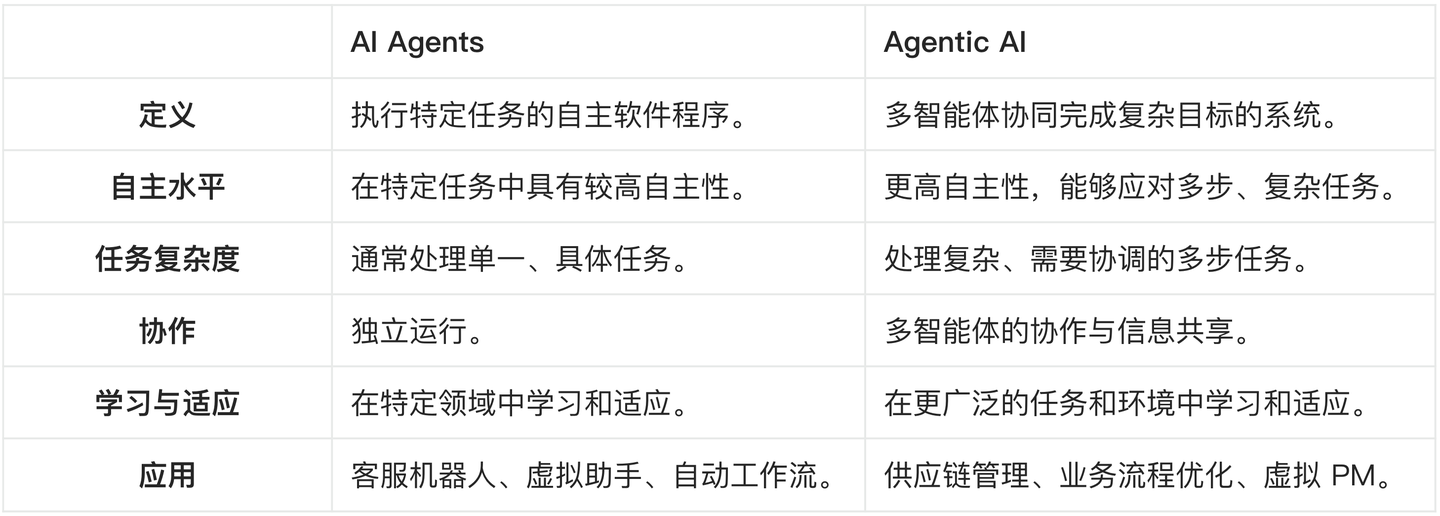
Chat2Graph 的架构设计中,「自动化」能力的设计就是对「Less Structure」理念的落实,也是未来走向 Agentic AI 的关键基础。
6.2 More Connection
相对应的,Chat2Graph 提出了「More Connection, Less Hallucination」的理念,这是 Graph Native 思想的具象化,也是符号主义的在 AI 时代的价值主张,更是 GraphAgent 的精神内核。「More Connection」并非单纯意义上的增加连接的规模,而是在智能体系统的关键设计中引入「连接」设计,比如任务图谱、知识图谱、工具图谱,为智能体赋予更确定的语义结构,增强推理的可解释性。
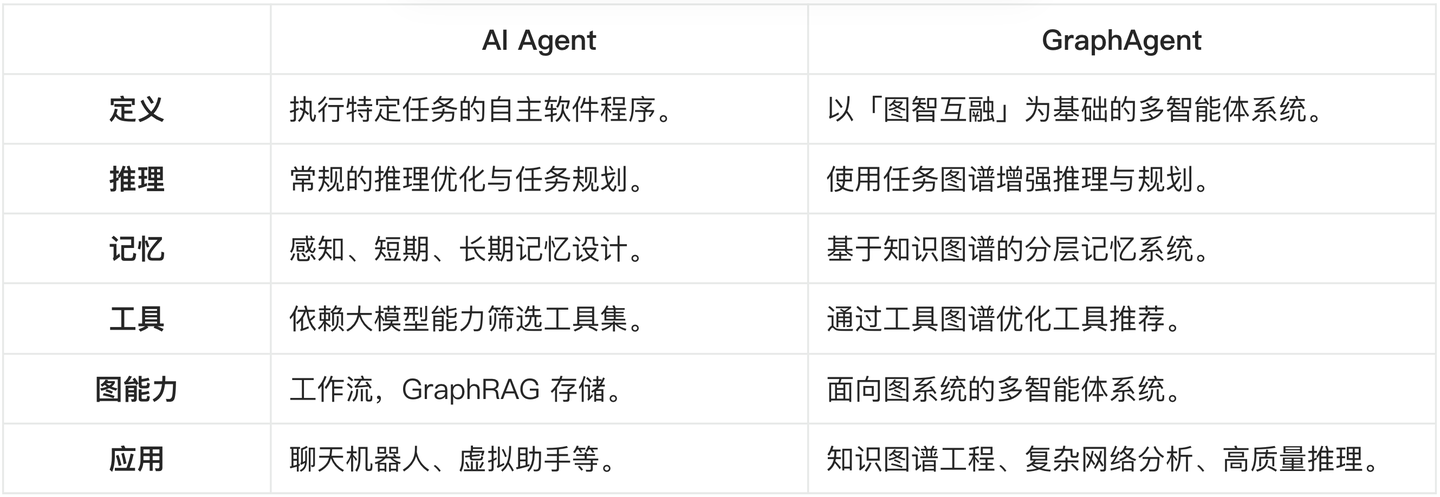
结合前面的讨论,这里简单对比一下 AI Agent 与 GraphAgent 能力差异。
这里多做一步讨论,过往多年,人工智能的研究者们一直不懈地探索表达人类「世界知识」的方法。以「知识图谱」为代表「符号主义」研究鏖战多年,而以「神经网络」为代表的「连接主义」也是到 LLM 的「Scaling Law」的出现才迎来转机。不幸的是人们很快就遇到了 LLM 的「算力 & 数据」瓶颈,导致 LLM 只能用有限层级的「深度神经网络」去压缩「世界知识」,带来的直接后果就是「幻觉」。
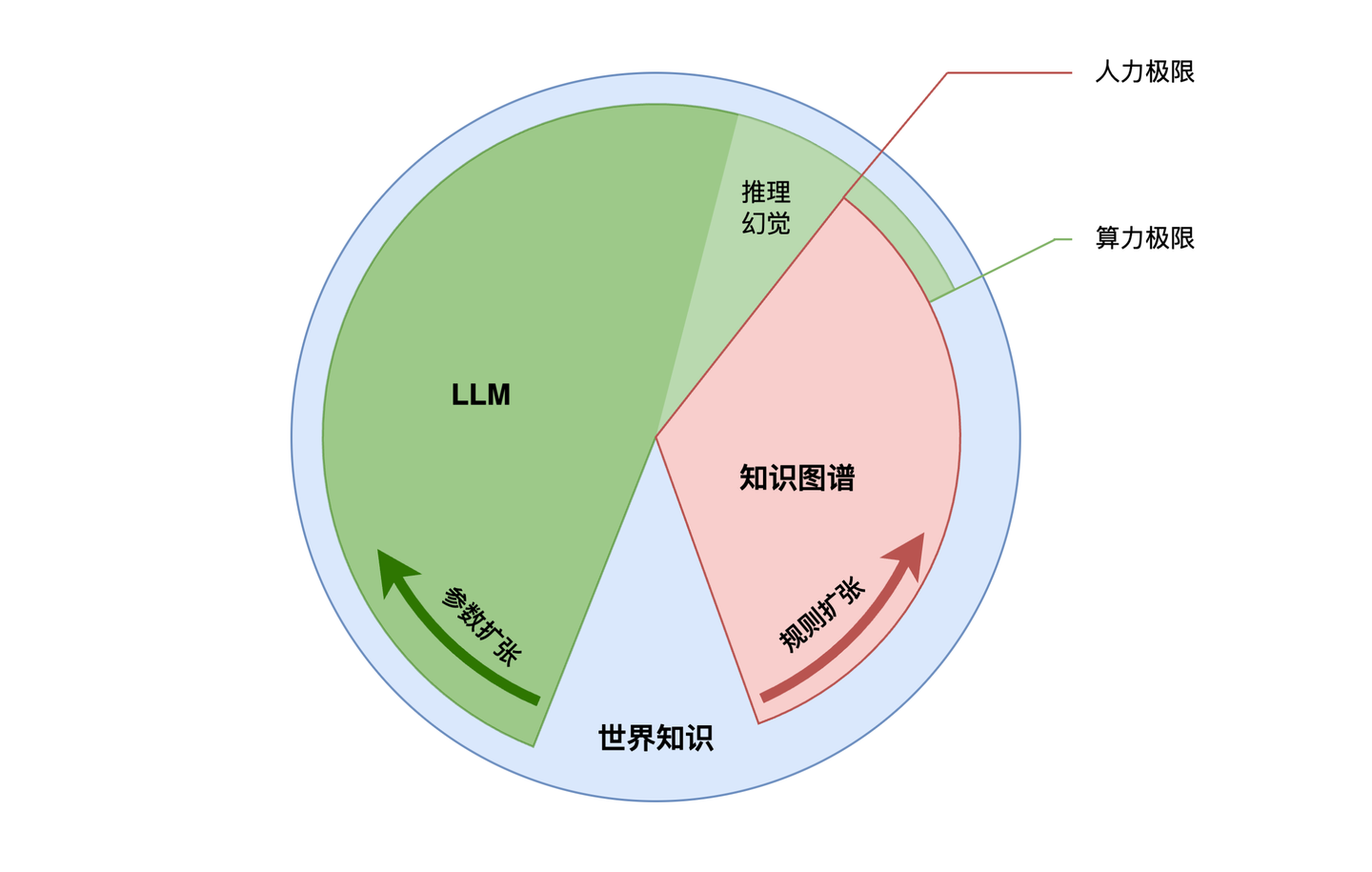
这个时候大家自然想到,「知识图谱」这位“难兄难弟”能不能在关键时刻捞自己一把,弥补掉那部分因为「深度缺失」而遗漏的知识。在和 DeepSeek 就这个话题沟通时,TA 说的一句话倒是让我眼前一亮:“知识图谱不是 AI 的插件,而是机器认知世界的骨架。”,倒是和我对「图智互融」本质的粗浅理解达成共识了。
6.3 Agent - LLM = ?
最后,对去年底年终总结时留下的“小作业”做个回顾:「Agent - LLM = ?」,意思是去掉 LLM,Agent 真正剩下的价值是什么?当时写下这个问题的本意是帮助大家去深思“在 LLM 能力不断增强的情况下,「AI 工程」的不变价值是什么?”,不知道你是否还记得当时的答案吗?
经过这篇万字文章的「自问自答」,我结合 Chat2Graph 给出了我们一直坚信的答案:
Agent - LLM = Memory + Tool
或许会有人挑战:“其实 Memory 的读写也应该看做 Tool 的一部分”。这里我使用一句话对此释义:
记忆是白盒化的工具,而工具是黑盒化的知识。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)