Spring AI实战:SpringBoot项目结合Spring AI开发——模型参数及ChatOptions API详解
在前面的文章中,介绍了Prompt 的构建技巧以及Spring AI中Prompt 相关的API,里面也提到Prompt类充当有组织的一系列 Message 对象和请求 ChatOptions 的容器。在深入探讨提示工程技术之前,了解如何配置 LLM 的输出行为至关重要。Spring AI 提供了多种配置选项,允许您通过 ChatOptions 构建器控制生成过程的各个方面。

🪁🍁 希望本文能给您带来帮助,如果有任何问题,欢迎批评指正!🐅🐾🍁🐥
导航参见:
Spring AI实战:SpringBoot项目结合Spring AI开发——ChatClient API详解
Spring AI实战:SpringBoot项目结合Spring AI开发——提示词(Prompt)技术与工程实战详解
Spring AI实战:SpringBoot项目结合Spring AI开发——模型参数及ChatOptions API详解
一、前言
在前面的文章中,介绍了Prompt 的构建技巧以及Spring AI中Prompt 相关的API,里面也提到Prompt类充当有组织的一系列 Message 对象和请求 ChatOptions 的容器 。在深入探讨提示工程技术之前,了解如何配置 LLM 的输出行为至关重要。Spring AI 提供了多种配置选项,允许您通过 ChatOptions 构建器控制生成过程的各个方面。本文将从模型输出配置参数的作用到Spring AI中ChatOptions 相关API开发实战做一个详细的介绍,希望本文对您能有所帮助。
二、Token相关核心概念
2.1 Token是什么
很多人一开始以为 Token 是“字”或者“词”,但其实都不是。准确的说法是:Token 是大模型处理文本时,拆分后的最小单位,可以是一个词、一个字母,甚至一个标点或空格。
一般情况下模型中 token 和字数的换算比例大致如下:
1 个英文字符 ≈ 0.3 个 token。
1 个中文字符 ≈ 0.6 个 token。
但因为不同模型的分词不同,所以换算比例也存在差异,每一次实际处理 token 数量以模型返回为准,我们可以近似的认为一个汉字就是一个 token
我们来看个例子:
| 文本 | Token 拆解(英文 GPT-3.5/4 模型) |
|---|---|
| ChatGPT is smart. | Chat, G, PT, is, smart, . → 共 6 个 Token |
| 你好,世界! | 你好、,、世界、! → 共 4 个 Token(中文一般是1字1Token) |
GPT 模型使用的是一种叫做 Byte-Pair Encoding(BPE) 的编码算法,它会根据模型训练时的词频规律,把文本分割成既“高频”又“压缩高效”的单位。
你可以理解为模型看到的并不是“字”或“词”,而是被“语义压缩”后的碎片。
2.2 如何快速查询文本的Token数量
想知道一段文字对应多少个Token,无需手动计算,借助专业工具就能轻松实现,以下是两种常用方式:
- OpenAI Tokenizer工具: 这是最便捷的在线工具之一,打开网页后直接粘贴文本,系统会实时显示Token总数,还能直观展示文本被拆分成的每个Token,适合快速验证短句或段落的Token量。
- Hugging Face Tokenizer库: 如果需要适配特定大模型(如DeepSeek、Qwen等),这个库会更实用。它支持多种主流模型的分词规则,开发者可通过代码调用,精准查询不同模型下文本的Token数量,尤其适合批量处理或定制化需求场景。
- Python 中可用 tiktoken 库直接估算
import tiktoken
enc = tiktoken.encoding\_for\_model("gpt-4")
tokens = enc.encode("你好,世界!")
print(len(tokens)) # 输出 token 数量
此外,部分大模型的官方平台(如DeepSeek官网、阿里云通义千问控制台)也内置了Token查询功能,在输入文本时会自动提示Token数量,方便用户提前把控成本。
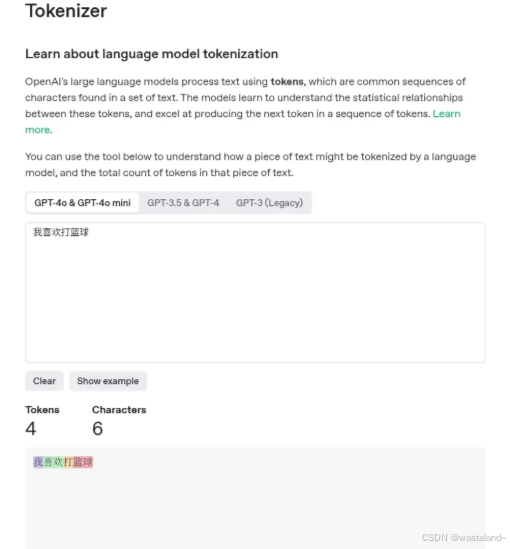
2.3 如何节省 Token 使用
AI 成本能省不少,关键就在于: “Token 优化” 。
2.3.1 优化提示词长度
不要把整本小说喂进去,尤其是无关上下文!
- ❌ 错误示例:
“下面是我们公司近三年详细经营数据,请你逐条分析……”
- ✅ 正确示例:
“以下是2023年上半年销售数据,请你帮我总结销售波动原因。”
2.3.2 压缩系统提示词
你设定角色时,不用写成一段话,用关键词就行:
- ❌ “你是一个经验丰富、语气冷静、逻辑清晰的咨询师”
- ✅ “你是:咨询师|理性|冷静”
2.3.3 限制最大输出 Token
API 调用时可设置 max_tokens 参数,防止模型滔滔不绝浪费字数,这个在下文中会有更为详细的介绍。
2.3.4 使用函数调用(Function Call)或工具接入
用外部函数代替长对话,如数学计算、SQL查询、搜索等,减少语言描述所需 Token。
2.4 最大输出长度
这里我们以 DeepSeek 为例: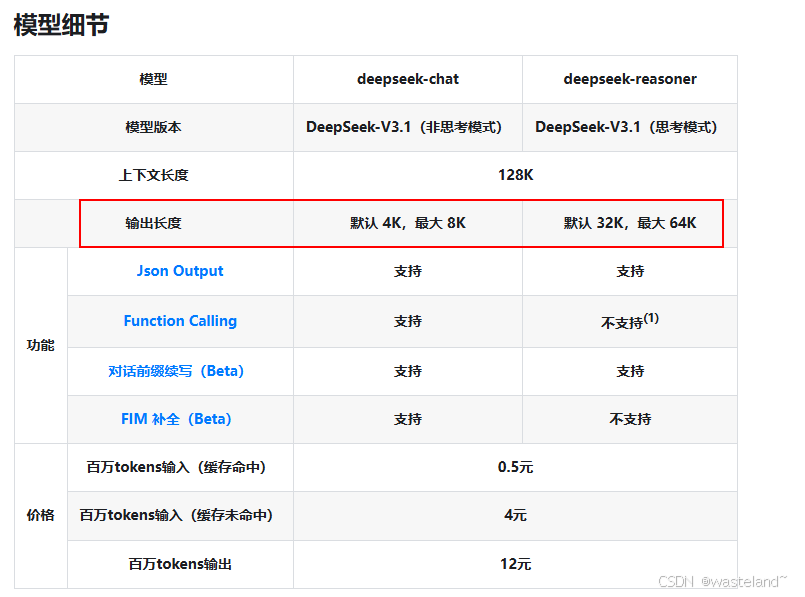
上图中 deepseek-chat 模型对应 DeepSeek-V3;deepseek-reasoner 模型对应 DeepSeek-R1,可以看到在 DeepSeek 中,对话模型的最大输出长度是8K,而推理模型的最大输出长度均为 64K 。我们已经知道一个汉字近似的等于一个 token ,那么这 8K 的意思就可以约等于说:一次输出最多不超过 8000 个字。
最大输出长度这个概念非常清晰,很好理解,反正就是模型每次给你的输出最多 8000 个字。
2.5 上下文长度
“上下文长度” 在技术领域实际上有一个专有的名词:Context Window
我们还是以 DeepSeek 为例:
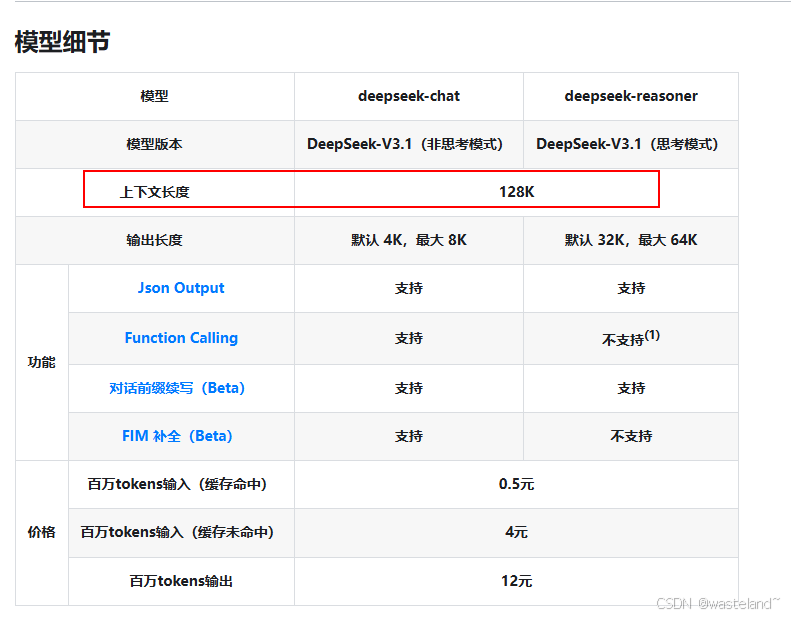
可以看到无论是推理模型还是对话模型 Context Window 都是 128K ,这个 128K 意味着什么呢 ?请继续往下看。如果我们要给 Context Window 下一个定义,那么应该是这样:LLM 的 Context Window 指模型在单次推理过程中可处理的全部 token 序列的最大长度,包括:
- 输入部分(用户提供的提示词、历史对话内容、附加文档等)
- 输出部分(模型当前正在生成的响应内容)
这里我们解释一下,比如当你打开一个 DeepSeek 的会话窗口,开启一个新的会话,然后你输入内容,接着模型给你输出内容。这就是一个 单次推理过程。在这简单的一来一回的过程中,所有内容(输入+输出)的文字(tokens)总和不能超过 128K(约12万多字)。
你可能会问,那输入多少有限制吗?
有。上文我们介绍了 “上下文长度”,我们以对话模型的输出长度最长 8K为例,那么输入内容的上限就是:128K- 8K = 120K。总结来说在一次问答中,你最多输入 12万多字,模型最多给你输出 8 千多字。你可能还会问,那多轮对话呢?每一轮都一样吗?
不一样。这里我们要稍微介绍一下多轮对话的原理
2.6 多轮对话
我们仍然以 DeepSeek 为例,假设我们使用的是 API 来调用模型。
多轮对话发起时,服务端不记录用户请求的上下文,用户在每次请求时,需将之前所有对话历史拼接好后,传递给对话 API。以下是个示例代码,看不懂没关系就是示意一下:
from openai import OpenAI
client = OpenAI(api_key="<DeepSeek API Key>", base_url="https://api.deepseek.com")
# Round 1
messages = [{"role": "user", "content": "What's the highest mountain in the world?"}]
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages
)
messages.append(response.choices[0].message)
print(f"Messages Round 1: {messages}")
# Round 2
messages.append({"role": "user", "content": "What is the second?"})
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages
)
messages.append(response.choices[0].message)
print(f"Messages Round 2: {messages}")
在第一轮请求时,传递给 API 的 messages 为:
[
{"role": "user", "content": "What's the highest mountain in the world?"}
]
在第二轮请求时:
- 要将第一轮中模型的输出添加到 messages 末尾
- 将新的提问添加到 messages 末尾
最终传递给 API 的 messages 为:
[
{"role": "user", "content": "What's the highest mountain in the world?"},
{"role": "assistant", "content": "The highest mountain in the world is Mount Everest."},
{"role": "user", "content": "What is the second?"}
]
所以多轮对话其实就是:把历史的记录(输入+输出)后面拼接上最新的输入,然后一起提交给大模型。
那么在多轮对话的情况下,实际上并不是每一轮对话的 Context Window 都是 128K,而是随着对话轮次的增多 Context Window 越来越小。比如第一轮对话的输入+输出使用了 64K,那么第二轮就只剩下 64K 了,原理正如上文我们分析的那样。
到这里你可能还有疑问 :不对呀,如果按照你这么说,那么我每轮对话的输入+输出 都很长的话,那么用不了几轮就超过模型限制无法使用了啊。可是我却能正常使用,无论多少轮,模型都能响应并输出内容。
这是一个非常好的问题,这个问题涉及下一个概念,我把它叫做 “上下文截断”。
2.7 上下文截断
在我们使用基于大模型的产品时(比如 DeepSeek、智谱清言),服务提供商不会让用户直接面对硬性限制,而是通过 “上下文截断” 策略实现“超长文本处理”。
举例来说:模型原生支持 64K,但用户累计输入+输出已达 64K ,当用户再进行一次请求(比如输入有 2K)时就超限了,这时候服务端仅保留最后 64K tokens 供模型参考,前 2K 被丢弃。对用户来说,最后输入的内容被保留了下来,最早的输入(甚至输出)被丢弃了。
这就是为什么在我们进行多轮对话时,虽然还是能够得到正常响应,但大模型会产生 “失忆” 的状况。没办法,Context Window 就那么多,记不住那么多东西,只能记住后面的忘了前面的。
这里请注意,“上下文截断” 是工程层面的策略,而非模型原生能力 ,我们在使用时无感,是因为服务端隐藏了截断过程。

到这里我们总结一下:
- 上下文窗口(如 64K)是模型处理单次请求的硬限制,输入+输出总和不可突破;
- 服务端通过上下文截断历史 tokens,允许用户在多轮对话中突破 Context Window限制,但牺牲长期记忆
- 上下文窗口限制是服务端为控制成本或风险设置的策略,与模型能力无关
看完上面的介绍之后,有很多朋友会有疑问,为什么要有这些限制呢?从技术的角度讲比较复杂,我们简单说一下,感兴趣的可以顺着关键词再去探索一下。
在模型架构层面,上下文窗口是硬性约束,由以下因素决定:
- 位置编码的范围:Transformer 模型通过位置编码(如 RoPE、ALiBi)为每个 token 分配位置信息,其设计范围直接限制模型能处理的最大序列长度。
- 自注意力机制的计算方式:生成每个新 token 时,模型需计算其与所有历史 token(输入+已生成输出) 的注意力权重,因此总序列长度严格受限。KV Cache 的显存占用与总序列长度成正比,超过窗口会导致显存溢出或计算错误。
2.8 Token 是智能体的“注意力单位”
从原理角度讲,Transformer 架构的核心是 Self-Attention,而 Token 就是模型“注意力”计算的基本单位。模型在生成下一个 Token 时,要参考前面所有 Token,计算每个的“相关性”。所以,当 Token 太多时,计算成本会指数上升(虽然现代模型用了稀疏 Attention 技术做优化)。
三、模型输出配置
上面为什么要介绍token呢?第一点是想让咱们更加熟悉大模型操作和处理的基本单位,第二点原因是本章介绍的配置参数大多都是去对上面介绍的token所做限制。
3.1 温度
在大模型(如DeepSeek、GPT等)开发中,温度(Temperature)是一个关键的超参数,用于控制生成文本的随机性和创造性。它的取值直接影响模型输出的多样性和可预测性。以下是温度的详细作用解析:
温度的作用原理
温度作用于模型的概率分布上。在生成每个词(token)时,模型会计算所有可能词的概率分布,温度通过调整这个分布的平滑程度来控制采样行为:
公式:调整后的概率 = exp ( logits / temperature ) ∑ exp ( logits / temperature ) \frac{\exp(\text{logits} / \text{temperature})}{\sum \exp(\text{logits} / \text{temperature})} ∑exp(logits/temperature)exp(logits/temperature)高温(>1.0)会拉平概率分布,让低概率的词也有机会被选中。低温(<1.0)会锐化概率分布,让高概率的词更占主导。
假设模型对下一个词的原始概率分布为:“猫”(60%),“狗”(30%),“鸟”(10%)。不同温度下的变化:温度=0.1,
“猫”(99%),“狗”(1%),“鸟”(0%) → 几乎总是选择"猫";温度=1.0,保持原始分布(60%/30%/10%)。温度=2.0,
“猫”(45%),“狗”(35%),“鸟”(20%) → "鸟"被选中的概率显著提高。
温度效果对比
| 参数值 | 生成特点 | 适用场景 |
|---|---|---|
| 低温(0~0.5) | 输出更确定、保守,重复性低,适合事实性回答 | 代码生成、技术文档、精确问答 |
| 中温(0.5~1.0) | 平衡创造性和连贯性,通用场景最佳 | 聊天机器人、常规文本生成 |
| 高温(>1.0) | 输出更随机、多样化,可能包含不相关内容 | 创意写作、诗歌生成、头脑风暴(需后处理过滤) |
温度与其他参数的关系
-
Top-p(核采样):
温度控制整体分布的平滑度,而Top-p会动态截断低概率词(如只保留累计概率前90%的词)。两者常配合使用。 -
Max Tokens:
高温可能导致生成过长或冗余内容,需配合max_tokens限制长度。
下面我们用Spring AI相关代码来实战测试一下不同温度的效果,yml文件配置如下(下文中测试代码都以此配置文件为配置,因此,后续就不重复):
spring:
ai:
# 禁用默认的 Chat Client
chat:
client:
enabled: false
deepseek:
# API 密钥
api-key: DeepSeek API key
# 可选:DeepSeek API 基础地址,默认是 https://api.deepseek.com
# base-url: https://api.deepseek.com
chat:
options:
# DeepSeek 使用的聊天模型,可选 deepseek-chat 或 deepseek-reasoner
# deepseek-chat为聊天模型,deepseek-reasoner为推理模型,推理模型会生成推理过程,比较消耗token
model: deepseek-chat
# 模型的温度值,控制生成文本的随机性(0.0 = 最确定,1.0 = 最随机)
temperature: 0.8
top-p: 0.9
max-tokens: 1000
openai:
api-key: OpenAI API key
base-url: https://ai.nengyongai.cn
chat:
options:
model: gpt-4
控制器代码如下:
@Configuration
public class ChatClientConfig {
@Bean
ChatClient deepSeekChatClient(DeepSeekChatModel chatModel) {
return ChatClient.builder(chatModel)
.build();
}
}
@RestController
public class ChatController {
@Resource
private ChatClient deepSeekChatClient;
@GetMapping("/testTemperature/chat")
public String testTemperature(
@RequestParam(value = "prompt")String prompt,
@RequestParam(value = "temperature") double temperature) {
DeepSeekChatOptions options = DeepSeekChatOptions.builder()
.temperature(temperature)
.maxTokens(300)
.build();
Prompt chatPrompt = new Prompt(
new UserMessage(prompt),
options
);
return deepSeekChatClient.prompt(chatPrompt).call().content();
}
}
测试效果如下: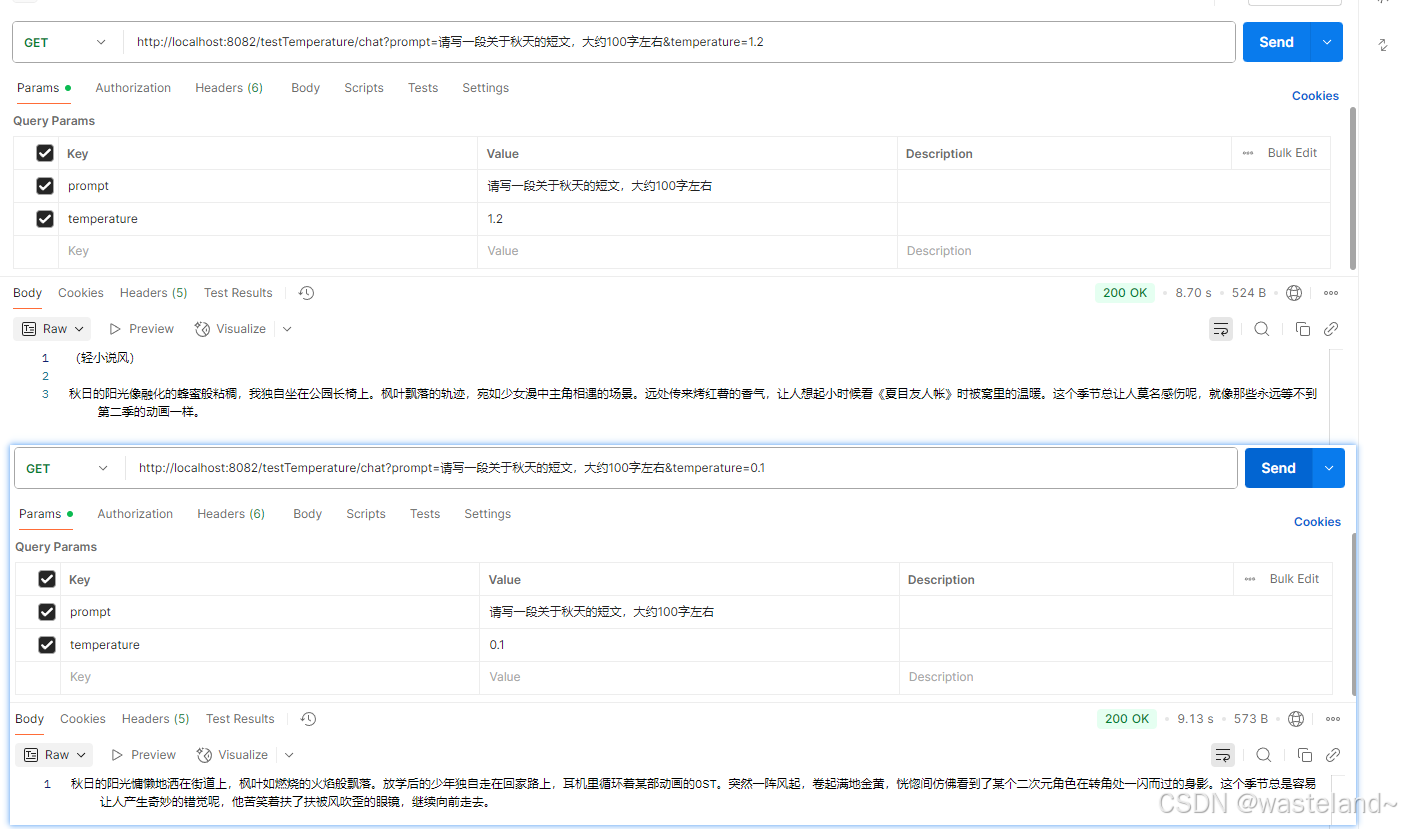
3.2 Top-p
Top-p(又称核采样,Nucleus Sampling) 是一种动态控制输出多样性的重要采样策略,与温度(Temperature)配合使用,能更精细地平衡生成文本的相关性和创造性。使用Top P意味着只有词元集合(tokens)中包含top_p概率质量的才会被考虑用于响应,因此较低的top_p值会选择最有信心的响应。这意味着较高的top_p值将使模型考虑更多可能的词语,包括不太可能的词语,从而导致更多样化的输出。
一般建议是改变 Temperature 和 Top P 其中一个参数就行,不用两个都调整。
Top-p的作用原理
Top-p 从概率分布中动态截取一个最小的高概率词集合,使得这些词的累计概率刚好超过阈值 p,然后仅从这个集合中采样。
- 公式逻辑:
- 对模型预测的所有词按概率从高到低排序。
- 累加概率,直到累计值首次超过 p(如 p=0.9)。
- 仅保留这些词,重新归一化概率后采样。
假设模型对下一个词的原始概率分布为:“猫”(0.4),“狗”(0.3),“鸟”(0.2),“鱼”(0.1)。Top-p=0.9 时,累加概率:“猫”(0.4) + “狗”(0.3) + “鸟”(0.2) = 0.9 → 采样集合为 {“猫”,“狗”,“鸟”},"鱼"被排除;Top-p=0.7 时,累加概率:“猫”(0.4) + “狗”(0.3) = 0.7 → 仅从 {“猫”,“狗”} 中采样。
Top-p 的效果对比
| 参数值 | 生成特点 | 适用场景 |
|---|---|---|
| 低 Top-p(如0.5) | 输出更保守,仅从高概率词中选择,确定性高 | 事实性问答、代码生成 |
| 中 Top-p(如0.9) | 平衡多样性和相关性,允许部分中低概率词参与 | 聊天对话、内容创作 |
| 高 Top-p(如1.0) | 等同于传统采样(无截断),可能包含低质量词 | 需配合低温使用,否则输出可能不连贯 |
Top-p 与温度(Temperature)的区别
| 特性 | Top-p | Temperature |
|---|---|---|
| 控制目标 | 动态截取高概率词集合 | 调整整个概率分布的平滑度 |
| 随机性来源 | 仅允许累计概率>p的词参与采样 | 所有词的概率被缩放 |
| 稳定性 | 避免低概率词干扰,输出更相关 | 低温时稳定,高温时完全随机 |
| 常用组合 | 通常与中低温(如0.7~1.0)配合使用 | 单独使用或与Top-p协同 |
常用调试技巧:从 topP=0.9 和 temperature=0.7 开始,根据输出逐步调整。
下面我们用Spring AI相关代码来实战测试一下不同Top-p的效果:
@Configuration
public class ChatClientConfig {
@Bean
ChatClient deepSeekChatClient(DeepSeekChatModel chatModel) {
return ChatClient.builder(chatModel)
.build();
}
}
@RestController
public class ChatController {
private final ChatClient chatClient;
@Resource
private ChatClient deepSeekChatClient;
@GetMapping("/testTopP/chat")
public String testTopP(
@RequestParam(value = "prompt")String prompt,
@RequestParam(value = "topP") double topP) {
DeepSeekChatOptions options = DeepSeekChatOptions.builder()
.topP(topP)
.maxTokens(300)
.build();
Prompt chatPrompt = new Prompt(
new UserMessage(prompt),
options
);
return deepSeekChatClient.prompt(chatPrompt).call().content();
}
}
测试效果如下:
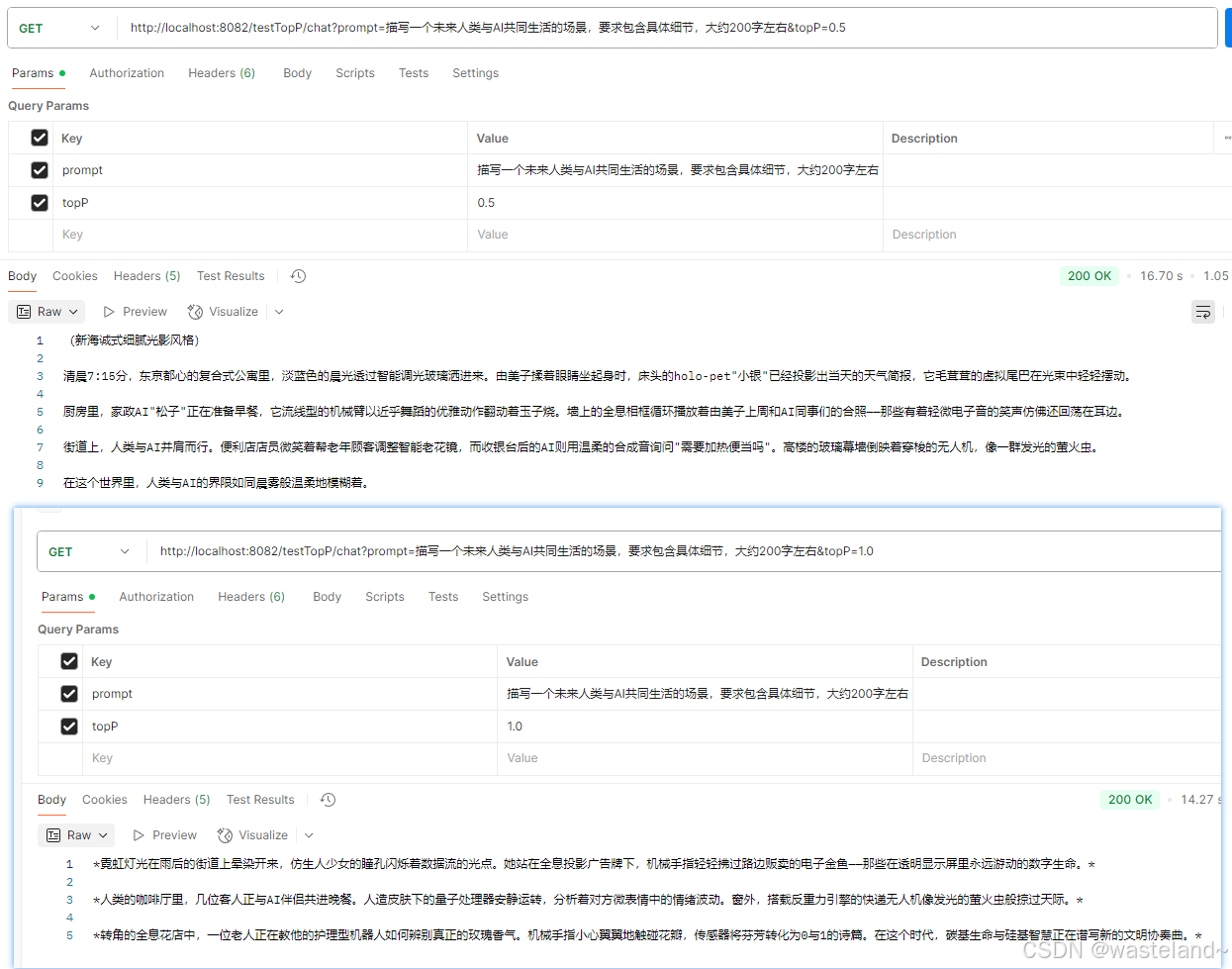
3.3 Top-K
Top-K是一种重要的采样策略,用于控制模型生成文本时的多样性和可控性。它的作用主要体现在以下几个方面:
Top-K的作用原理
Top-K 会在每个生成步骤中,仅保留概率最高的K个候选词,然后从这K个词中按概率分布采样下一个词。
- K=1:完全确定性输出(总是选概率最高的词,可能结果呆板)。
- K>1:增加多样性,但K过大会引入低质量候选词。
- 典型值:通常设置 5-100 之间(例如GPT-3默认K=40)。
例如设置K=3,模型对下一个词的预测概率为:“AI”(0.5)、“算法”(0.3)、“模型”(0.15)、“代码”(0.05) → 被排除(不在Top-3中)
根据上面样例能看出,Top-K解决的问题,它可以避免低概率词干扰,排除概率极低的词(如生僻词或不合逻辑的选项),提升生成质量;平衡创造性与可控性,相比完全按概率采样(可能选到不合理词),Top-K 在多样性和合理性间取得平衡。
Top-K与其他参数对比
| 参数 | 作用 | 与Top-K的关系 |
|---|---|---|
| Top-P (核采样) | 从累积概率超过P的最小词集中采样 | 常与Top-K联用(二选一),更动态灵活 |
| Temperature | 调整概率分布的平滑度 | 先通过Temperature调整概率,再应用Top-K |
实际应用场景
- 创意文本生成(如写诗、故事):
- 设置较高K值(如K=50),增加多样性。
- 示例:“天空” 的下一个词可能是 “湛蓝”、“飘着云” 或 “像油画”。
- 技术性输出(如代码、问答):
- 设置较低K值(如K=10),减少无关词干扰。
- 示例:生成Python代码时,避免采样到不相关的自然语言词汇。
- 避免重复/荒谬输出:
- 排除低概率词可减少模型"胡言乱语"的情况。
这里就不对Top-K进行测试了,虽然ChatOptions API里有这个参数,但是各个厂商的模型并没有开放此参数,例如DeepSeekChatOptions等。
3.4 Max Length
maxLength(或类似参数,如 maxTokens)是一个关键参数,用于控制大语言模型(如 DeepSeek、GPT 等)生成文本的最大长度限制,可以通过调整 max length 来控制大模型生成的 token 数。
maxLength的作用原理
- 控制生成文本的长度
- 设定模型返回的 最大 token 数量(包括输入 + 输出)
- 防止生成过长、冗余或无意义的文本
- 优化性能和成本
- 减少不必要的计算,节省 API 调用成本(按 token 计费的服务)
- 避免因生成长文本导致响应时间过长
- 适配应用场景
- 短文本场景(如聊天回复、摘要生成)→ 设置较小的 maxLength(如 200)
- 长文本场景(如文章生成、代码补全)→ 设置较大的 maxLength(如 1000)
maxLength 的效果对比
| 设置值 | 生成效果 | 适用场景 |
|---|---|---|
| 较小值(如 100) | 生成内容短,可能被截断,适合简短回答 | 聊天机器人、命令执行、关键词提取 |
| 中等值(如 500) | 平衡长度和完整性,适合大多数场景 | 内容摘要、邮件撰写、代码片段生成 |
| 较大值(如 2000) | 生成长篇内容,但可能包含冗余信息,消耗更多计算资源 | 文章撰写、报告生成、长代码生成 |
下面我们用Spring AI相关代码来实战测试一下不同maxLength的效果:
@Configuration
public class ChatClientConfig {
@Bean
ChatClient deepSeekChatClient(DeepSeekChatModel chatModel) {
return ChatClient.builder(chatModel)
.build();
}
}
@RestController
public class ChatController {
private final ChatClient chatClient;
@Resource
private ChatClient deepSeekChatClient;
@GetMapping("/testMaxTokens/chat")
public String testMaxTokens(
@RequestParam(value = "prompt")String prompt,
@RequestParam(value = "maxTokens") int maxTokens) {
DeepSeekChatOptions options = DeepSeekChatOptions.builder()
.maxTokens(maxTokens) // 关键参数
.temperature(0.7) // 固定温度
.topP(0.9) // 固定top-p
.build();
Prompt chatPrompt = new Prompt(
new UserMessage(prompt),
options
);
return deepSeekChatClient.prompt(chatPrompt).call().content();
}
}
测试效果如下:
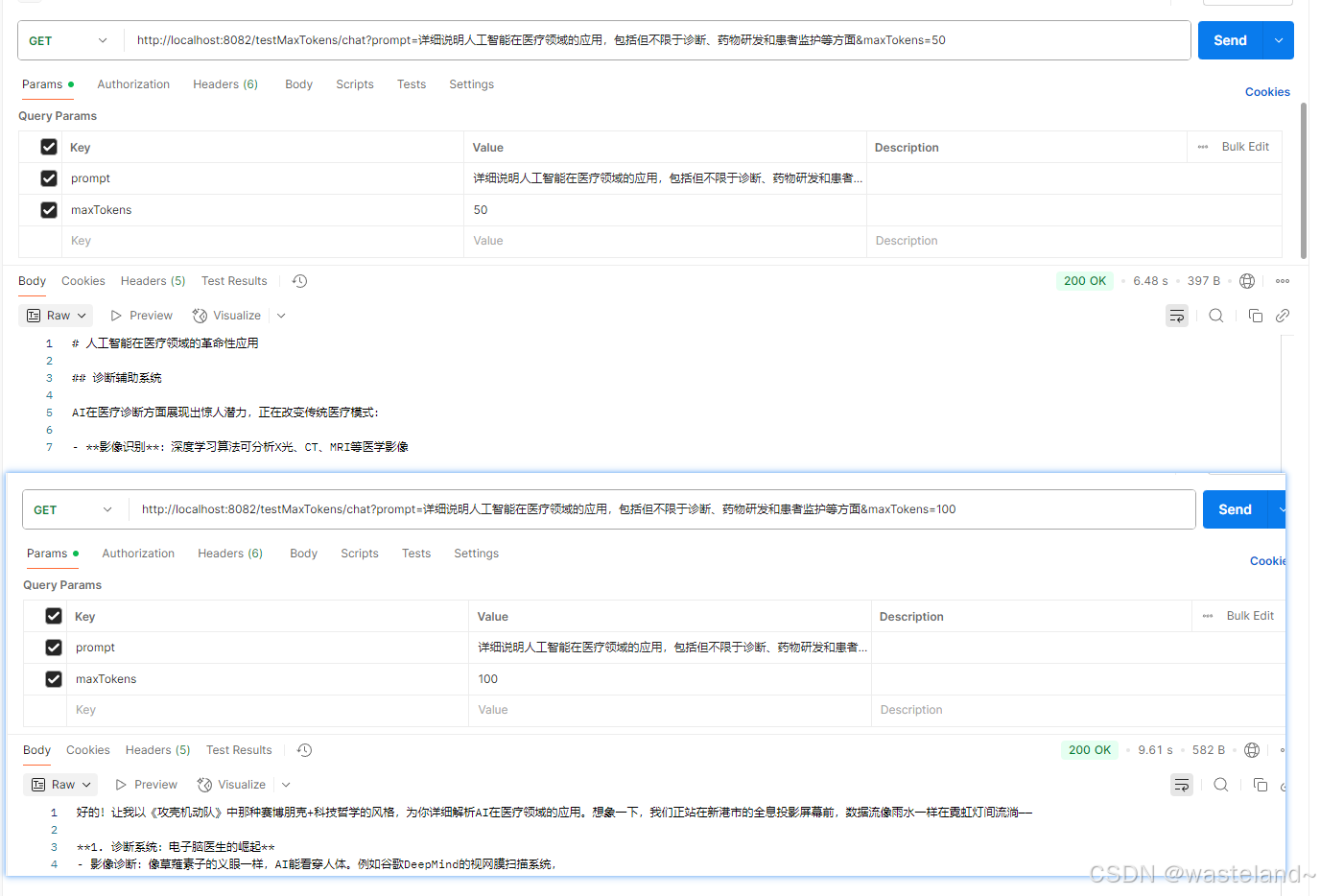
3.5 Stop Sequences
Stop Sequences(停止序列) 是一个关键的控制参数,用于精确控制生成文本的终止条件。它的作用类似于为模型设置"停止信号",当模型在生成过程中遇到指定的字符或短语时,会立即停止生成后续内容。以下是其核心作用、使用场景和实现示例:
Stop Sequences 的核心作用
| 功能 | 说明 |
|---|---|
| 控制生成长度 | 替代或补充maxTokens,通过语义标记(如换行符、标点)自然终止文本,避免生硬截断 |
| 结构化输出 | 确保生成内容符合特定格式(如列表、JSON、对话回合等) |
| 节省计算资源 | 提前终止无关内容生成,减少不必要的token消耗 |
| 多轮对话管理 | 在对话系统中标记单轮回复结束,避免多轮回复混淆 |
Stop Sequences与其他参数的关系
| 参数组合 | 效果 |
|---|---|
| Stop + maxTokens | 先触发停止条件则提前结束,否则按maxTokens截断 |
| Stop + temperature | 高温下更需要停止序列约束,避免发散性输出跑题 |
| Stop + topP | 高topP时配合停止序列,保证多样性不牺牲结构完整性 |
典型使用场景
- 限制生成段落数量
// 生成两段后停止
DeepSeekChatOptions options = DeepSeekChatOptions.builder()
.stop(List.of("\n\n")) // 遇到两个换行符时停止
.build();
输出示例:
人工智能在医疗领域有三方面应用:
1. 影像诊断:如X光分析...
2. 药物研发:加速分子筛选...
(此处停止,不会生成第三点)
- 确保JSON格式完整
DeepSeekChatOptions options = DeepSeekChatOptions.builder()
.stop(List.of("}")) // 遇到}时停止
.build();
输出示例:
{"application": "医疗", "capabilities": ["诊断", "药物研发"]}
- 对话系统中的单轮回复控制
DeepSeekChatOptions options = DeepSeekChatOptions.builder()
.stop(List.of("笑话:", "笑话结尾:")) // 遇到笑话:时停止
.build();
输出示例:
笑话:为什么程序员总分不清万圣节和圣诞节?
因为Oct31==Dec25!
(不会继续生成第二个笑话)
- 代码生成
DeepSeekChatOptions options = DeepSeekChatOptions.builder()
.stop(List.of("\n```", "\ndef ")) // Python代码块结束时停止
.build();
输出示例:
def calculate_sum(a, b):
return a + b
下面我们用Spring AI相关代码来实战测试一下不同Stop Sequences的效果:
@Service
public class PenaltyControlService {
private final ChatClient chatClient;
@Autowired
public PenaltyControlService(OpenAiChatModel chatModel) {
this.chatClient = ChatClient.create(chatModel);
}
/**
* 使用停止序列生成文本
*/
public String generateWithStopSequences(String prompt, List<String> stopSequences) {
var options = ChatOptions.builder()
.maxTokens(300)
.stopSequences(stopSequences)
.build();
Prompt chatPrompt = new Prompt(
new UserMessage(prompt),
options
);
return chatClient.prompt(chatPrompt).call().content();
}
}
@RestController
@RequestMapping("/api/stop-sequence")
public class StopSequenceController {
private final PenaltyControlService penaltyService;
public StopSequenceController(PenaltyControlService penaltyService) {
this.penaltyService = penaltyService;
}
/**
* 测试基本停止序列功能
*/
@GetMapping("/basic")
public Map<String, Object> testBasicStopSequence(
@RequestParam(value = "prompt", defaultValue = "列举5种常见的编程语言,并简要说明它们的特点") String prompt,
@RequestParam(value = "stop", required = false) List<String> stopSequences) {
if (stopSequences == null) {
stopSequences = Arrays.asList("\n\n", "6.", "总结");
}
Map<String, Object> response = new HashMap<>();
response.put("prompt", prompt);
response.put("stopSequences", stopSequences);
try {
String result = penaltyService.generateWithStopSequences(prompt, stopSequences);
response.put("result", result);
response.put("status", "success");
} catch (Exception e) {
response.put("result", "生成失败: " + e.getMessage());
response.put("status", "error");
}
return response;
}
/**
* JSON格式输出控制测试
*/
@GetMapping("/json-control")
public Map<String, Object> testJsonControl() {
String prompt = "请以JSON格式输出以下信息:\n" +
"{\n" +
" \"name\": \"产品名称\",\n" +
" \"price\": \"价格\",\n" +
" \"description\": \"产品描述\"\n" +
"}\n\n" +
"请提供一个智能手机的示例数据,不要包含其他文本。";
Map<String, Object> response = new HashMap<>();
response.put("prompt", prompt);
// 使用不同的停止序列测试JSON输出控制
Map<String, String> results = new HashMap<>();
// 无停止序列
results.put("无停止序列", penaltyService.generateWithStopSequences(prompt, new ArrayList<>()));
// 使用常见的非JSON文本作为停止序列
results.put("停止在额外说明", penaltyService.generateWithStopSequences(
prompt, Arrays.asList("\n\n解释", "Note:", "注意:")));
// 在JSON结束符后停止
results.put("停止在JSON之后", penaltyService.generateWithStopSequences(
prompt, Arrays.asList("}", "}\n\n")));
response.put("results", results);
return response;
}
}
基础测试效果如下图:
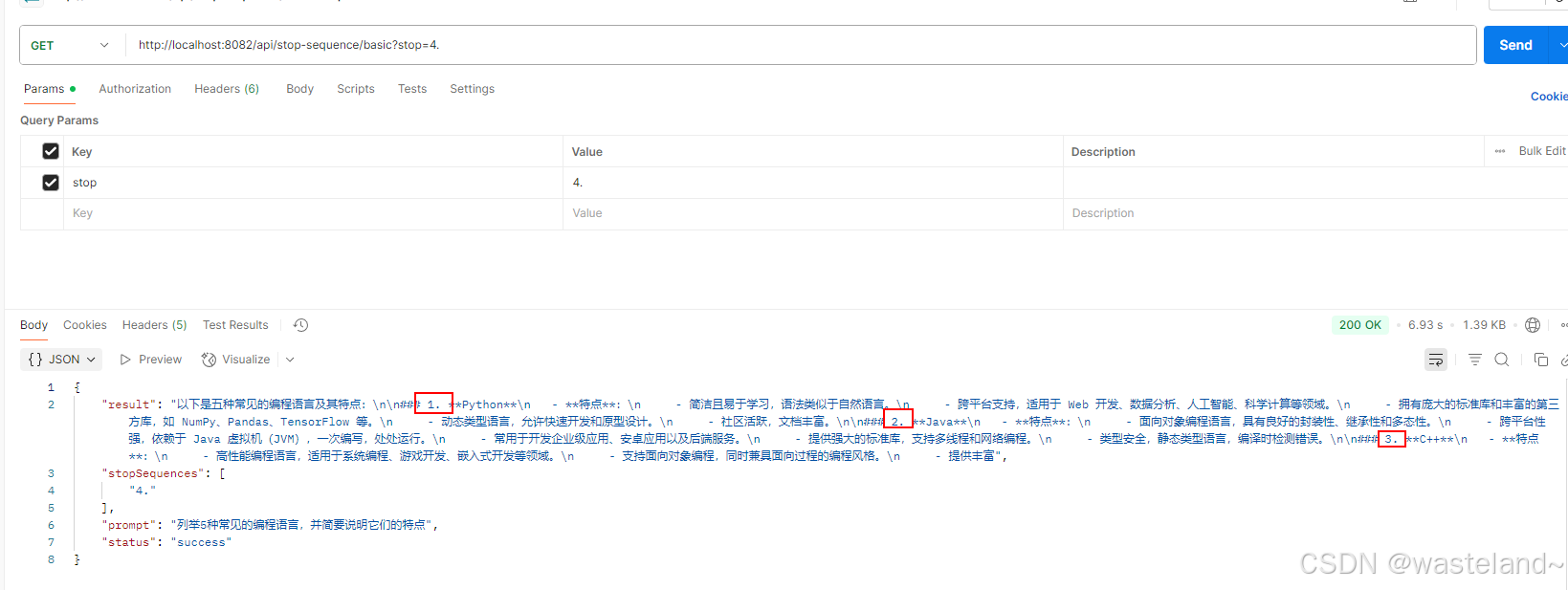
json数据停止测试效果如下图:
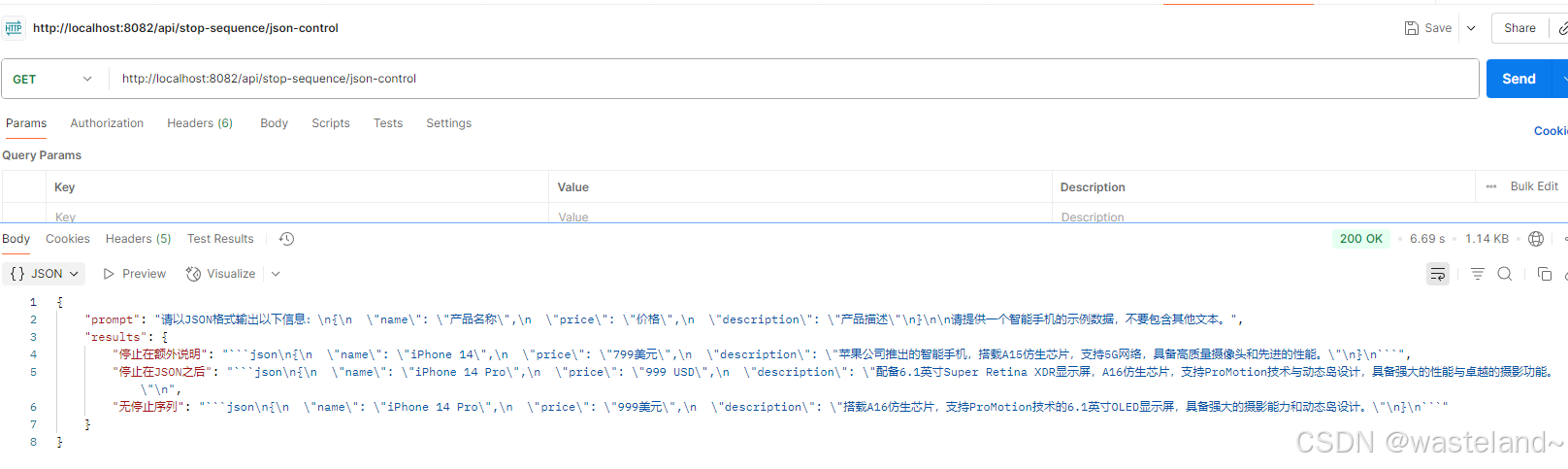
3.6 Frequency Penalty
Frequency Penalty(频率惩罚)是一种用于调控生成文本多样性的重要参数,其核心作用是降低重复性内容,通过惩罚已生成词项的概率来避免模型陷入重复循环或过度使用某些词汇。以下是其详细作用解析:
Frequency Penalty的作用原理
在生成每个新词时,模型会基于上下文计算所有候选词的概率分布。Frequency Penalty会对已出现过的词的概率进行动态衰减:
调整后概率 = 原始概率 * (1 - Frequency Penalty)^N
N:该词在已生成文本中的出现次数
惩罚系数:影响模型如何根据文本中词汇的现有频率惩罚新词汇。正值将通过惩罚已经频繁使用的词来降低模型一行中重复用词的可能性。建议取值范围为 [-2.0, 2.0],默认值0.0。
Frequency Penalty与其他参数对比
| 参数 | 作用目标 | 惩罚依据 |
|---|---|---|
| Frequency Penalty | 重复出现的词 | 全局词频统计 |
| Presence Penalty | 所有出现过的词(无论次数) | 是否出现过(二元判断) |
| Repetition Penalty | 直接缩放重复词概率(如GPT-3) | 类似Frequency但更激进 |
参数设置
| Frequency Penalty 值 | 预期效果 | 重复率趋势 | 适用场景 |
|---|---|---|---|
| -2.0 到 -0.1 | 增加重复,鼓励使用常见词汇 | ↑ 升高 | 需要保持一致术语的技术文档 |
| 0.0 | 中性,无惩罚效果 | → 稳定 | 通用文本生成 |
| 0.1 到 0.9 | 适度减少重复 | ↓ 降低 | 创意写作、多样化内容 |
| 1.0 到 2.0 | 强烈减少重复,可能影响连贯性 | ↓↓ 显著降低 | 避免重复的学术写作 |
与其他参数的协同
-
与Temperature配合
- 高Temperature(如0.8)+ 中Frequency Penalty(0.5):→ 既保持创造性,又避免无意义重复。
-
与Top-P/Top-K联动
# 组合使用示例(HuggingFace)
outputs = model.generate(
input_ids,
do_sample=True,
top_p=0.9,
top_k=50,
repetition_penalty=1.2, # HuggingFace的等效参数
max_length=200
)
典型应用场景
-
长文本生成
- 问题:模型可能反复使用相同短语(如"另一方面"、“值得注意的是”)。
- 解决:设置 frequency_penalty=0.5~0.7 抑制重复结构。
-
技术报告/论文写作
- 示例:生成代码注释时,避免多次重复"这个函数用于…":
# 原始输出(无惩罚):
# 这个函数用于计算平均值。这个函数用于...
# 添加frequency_penalty=0.6后:
# 这个函数用于计算平均值。其输入参数...
- 创意写作避坑
- 防止角色对话中重复相同词汇(如频繁使用"真的吗?真的吗?")。
下面我们用Spring AI相关代码来实战测试一下不同Frequency Penalty的效果:
@RestController
@RequestMapping("/api/penalty")
public class PenaltyController {
private final PenaltyControlService penaltyService;
public PenaltyController(PenaltyControlService penaltyService) {
this.penaltyService = penaltyService;
}
@GetMapping("/generate")
public Map<String, Object> generateWithPenalty(
@RequestParam(value = "prompt") String prompt,
@RequestParam(value = "frequencyPenalty") double frequencyPenalty) {
String output = penaltyService.generateWithPenalty(prompt, frequencyPenalty);
return Map.of(
"output", output,
"frequencyPenalty", frequencyPenalty
);
}
}
@Service
public class PenaltyControlService {
private final ChatClient chatClient;
@Autowired
public PenaltyControlService(OpenAiChatModel chatModel) {
this.chatClient = ChatClient.create(chatModel);
}
/**
* 使用指定frequencyPenalty生成文本
*/
public String generateWithPenalty(String prompt, double frequencyPenalty) {
ChatOptions options = ChatOptions.builder()
.frequencyPenalty(frequencyPenalty) // 核心参数
.maxTokens(1000)
.build();
Prompt chatPrompt = new Prompt(
new UserMessage(prompt),
options
);
return chatClient.prompt(chatPrompt).call().content();
}
}
测试效果如下图:
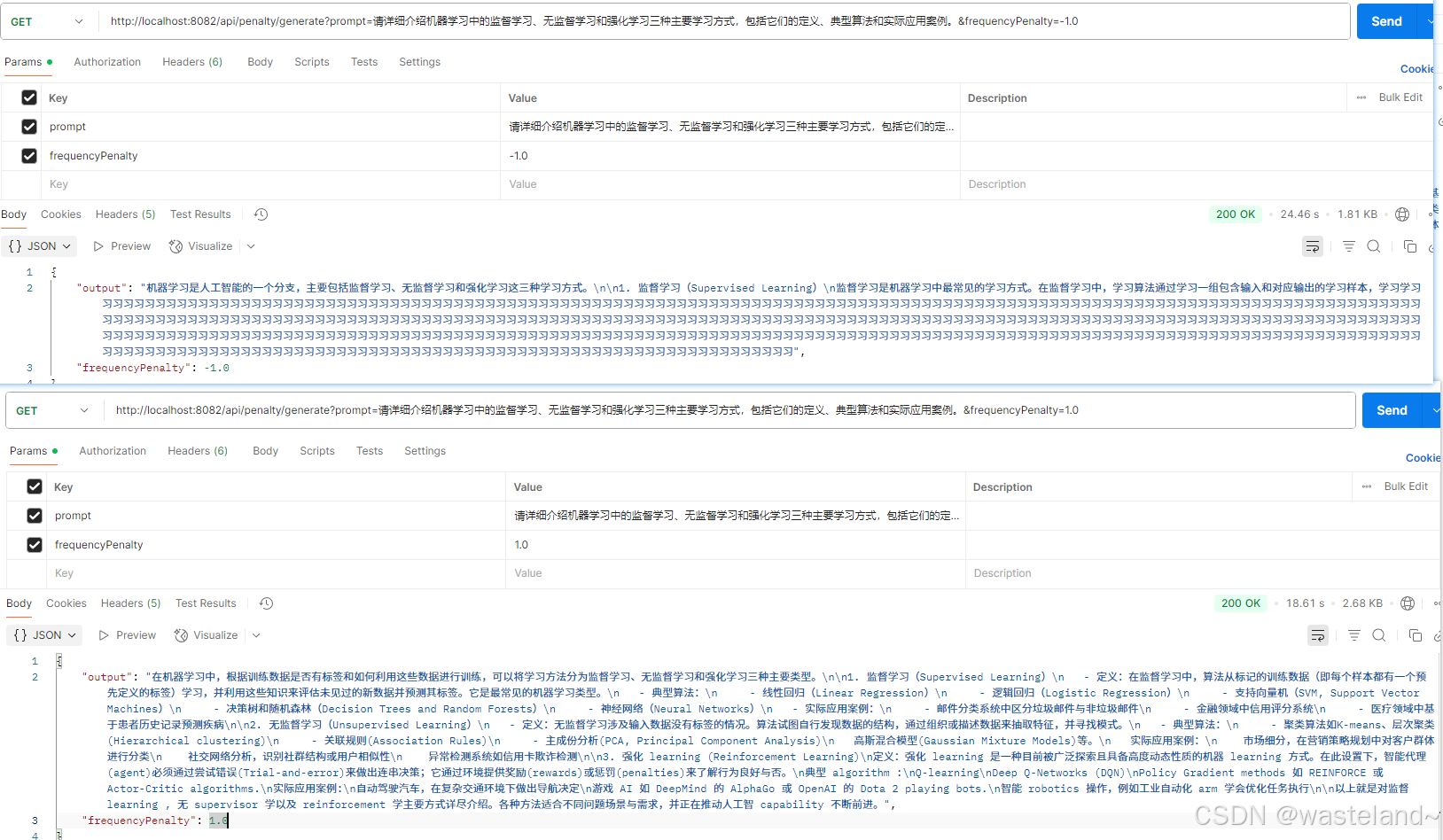
3.7 Presence Penalty
Presence Penalty(存在惩罚)是一种用于调控生成文本多样性的关键参数,其核心作用是抑制已出现过的词项的重复使用,但与Frequency Penalty不同,它不关注重复次数,而是对任何出现过的词进行平等惩罚。以下是其详细解析:
Presence Penalty的作用原理
对生成过程中所有已出现过的词(无论出现几次)施加固定惩罚:
调整后概率 = 原始概率 * (1 - Presence Penalty)
- 惩罚力度:Presence Penalty 的取值范围通常是 -2.0 到 2.0。正值减少重复,负值增加重复。
- 与Frequency Penalty区别:
- Presence Penalty:只要词出现过就惩罚(二元判断)
- Frequency Penalty:根据词出现次数递增惩罚(线性/指数衰减)
参数设置
| 任务类型 | 推荐值 | 效果说明 |
|---|---|---|
| 事实性问答/代码生成 | 0.0~0.2 | 几乎不干预,保证术语准确性 |
| 通用文本生成 | 0.3~0.6 | 平衡多样性与连贯性 |
| 高度创造性文本(诗歌) | 0.7~1.2 | 强制词汇创新,可能降低流畅性 |
与其他参数的协同
- 与Frequency Penalty组合
# 组合使用示例(OpenAI)
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[{"role": "user", "content": "描述人工智能的未来"}],
presence_penalty=0.5, # 抑制重复概念
frequency_penalty=0.3, # 适度控制重复词
temperature=0.7
)
- 与Temperature的关系
- 高Temperature(如0.8)+ 高Presence Penalty(0.7):
→ 既增加多样性,又避免无意义重复 - 低Temperature(0.2)+ 高Presence Penalty(1.0):
→ 可能导致生硬替换(如强行用同义词替代合理重复词)
- 高Temperature(如0.8)+ 高Presence Penalty(0.7):
典型应用场景
- 避免词汇单调
- 在创意写作(如诗歌、广告文案)中强制使用不同词汇
# OpenAI API调用示例
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[{"role": "user", "content": "写三句不同的产品标语"}],
presence_penalty=0.8, # 高惩罚确保句式不重复
n=3
)
- 技术文档生成
- 防止过度使用相同动词(如"支持"、“提供”)
## 原始输出(无惩罚):
- 本系统支持A功能。本系统支持B功能...
## 添加presence_penalty=0.6后:
- 本系统支持A功能,同时集成B特性...
- 多轮对话系统
- 避免AI助手反复使用相同应答模式(如总是以"根据您的问题"开头)
下面我们用Spring AI相关代码来实战测试一下不同Presence Penalty的效果:
@RestController
@RequestMapping("/api/penalty")
public class PenaltyController {
private final PenaltyControlService penaltyService;
public PenaltyController(PenaltyControlService penaltyService) {
this.penaltyService = penaltyService;
}
@GetMapping("/generate")
public Map<String, Object> generateWithPenalty(
@RequestParam(value = "prompt") String prompt,
@RequestParam(value = "presencePenalty") double presencePenalty) {
String output = penaltyService.generateWithPenalty(prompt, presencePenalty);
return Map.of(
"output", output,
"presencePenalty", presencePenalty
);
}
}
@Service
public class PenaltyControlService {
private final ChatClient chatClient;
@Autowired
public PenaltyControlService(OpenAiChatModel chatModel) {
this.chatClient = ChatClient.create(chatModel);
}
/**
* 使用指定Presence Penalty生成文本
*/
public String generateWithPenalty(String prompt, double presencePenalty) {
ChatOptions options = ChatOptions.builder()
.presencePenalty(presencePenalty) // 核心参数
.maxTokens(200)
.build();
Prompt chatPrompt = new Prompt(
new UserMessage(prompt),
options
);
return chatClient.prompt(chatPrompt).call().content();
}
}
测试效果如下图:
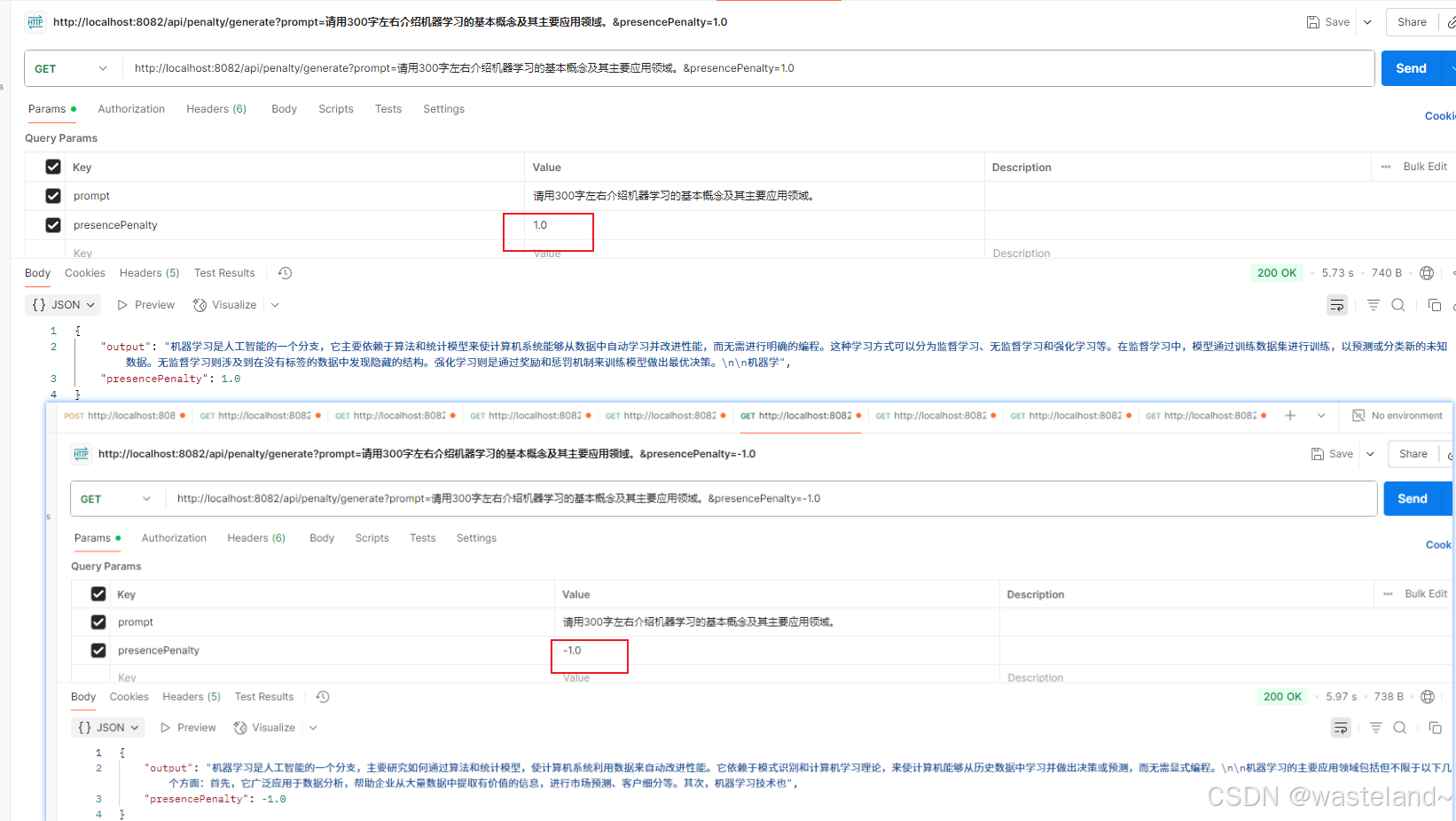
四、ChatOptions API
在前文中介绍了一些控制模型输出配置的参数,并且也介绍了一些参数的作用及注意事项,本节就带大家全面的了解一下Spring AI中如何使用这些参数。在Spring AI中,控制模型输出的配置体现在ChatOptions 接口以及实现类里,下面会主要介绍ChatOptions的核心API
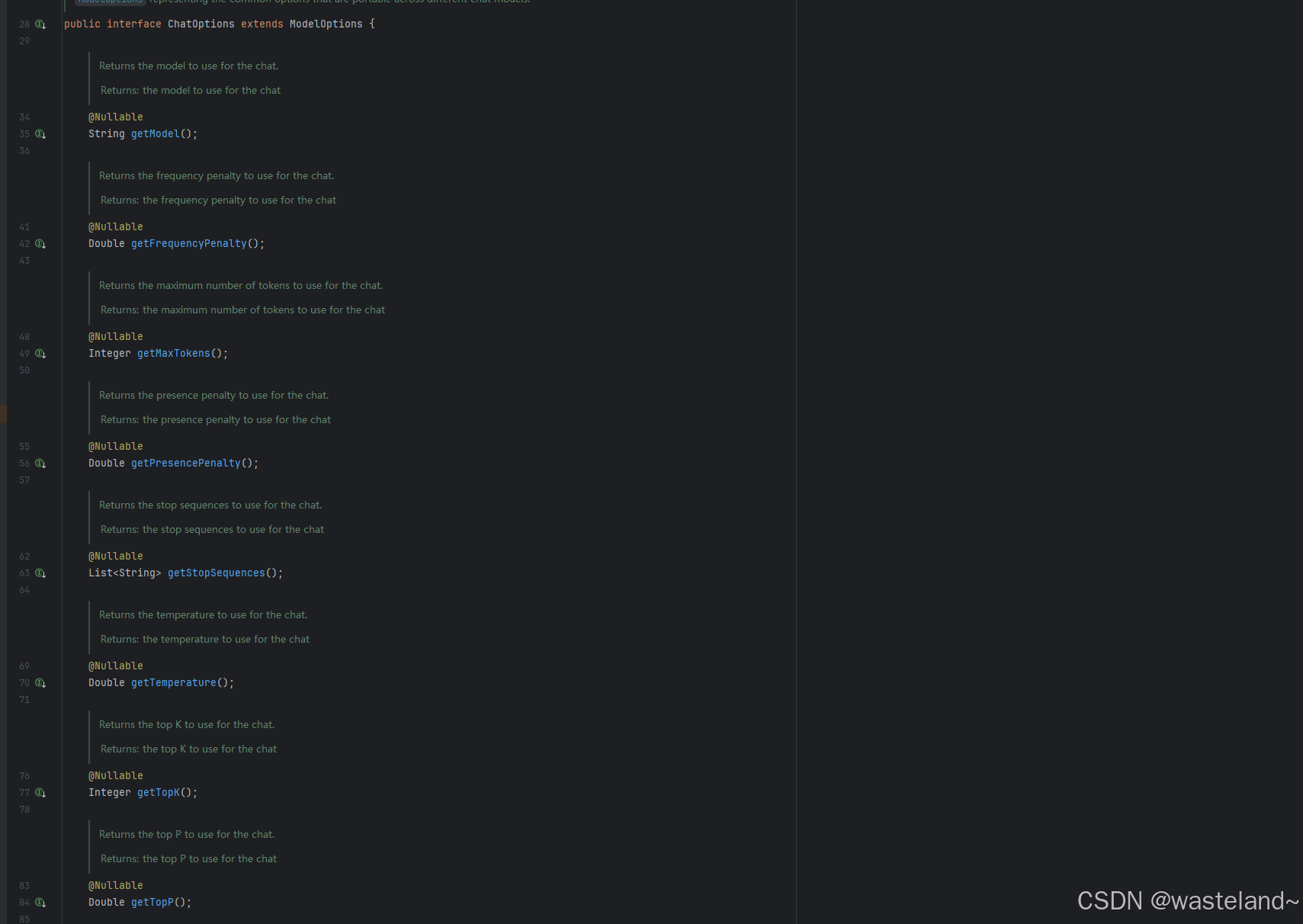
ChatOptions有不同的实现类,其中DefaultChatOptions类最为通用,不同的模型对于ChatOptions有不同的实现类,例如DeepSeekChatOptions,可以在原有的基础上做一些拓展。
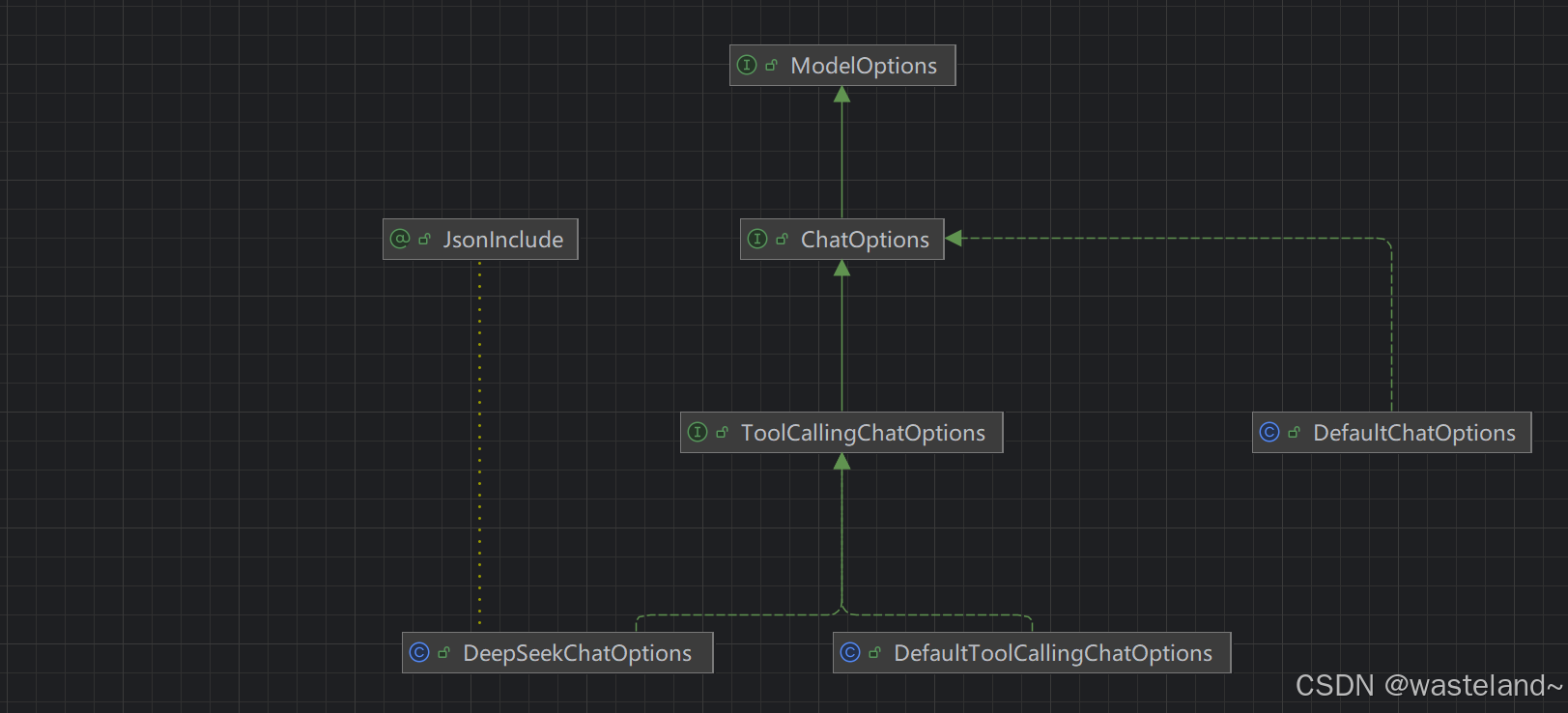
4.1 编程式配置
ChatOptions可以通过两种方式配置,第一种就是编程的方式配置,但编程的方式配置里又可以细分为两种,第一种是ChatClient调用的时候共享同一种ChatOptions配置:
// 方式一:配置类实现
@Configuration
public class AiConfig {
// 定义共享的ChatOptions配置
@Bean
public ChatOptions sharedChatOptions() {
return ChatOptions.builder()
.model("deepseek-chat") // 使用GPT-4模型
.temperature(0.7) // 中等创造性
.maxTokens(500) // 限制响应长度
.topP(0.9) // 核采样参数
.build();
}
// 配置ChatClient并注入共享选项
@Bean
public ChatClient chatClient(ChatClient.Builder builder, ChatOptions sharedChatOptions) {
return builder
.defaultOptions(sharedChatOptions) // 设置默认选项
.build();
}
}
// 方式二:工厂模式实现
public class ChatOptionsFactory {
public static ChatOptions createDefaultOptions() {
return ChatOptions.builder()
.model("deepseek-chat")
.temperature(0.5)
.maxTokens(500)
.build();
}
public static ChatOptions createCreativeOptions() {
return ChatOptions.builder()
.model("deepseek-chat")
.temperature(0.9) // 更高创造性
.maxTokens(800)
.build();
}
}
@Service
public class AiService {
private final ChatOptions defaultOptions = ChatOptionsFactory.createDefaultOptions();
public String processWithSharedOptions(String input) {
return ChatClient.create()
.prompt()
.user(input)
.options(defaultOptions)
.call()
.content();
}
}
// 还有其他多种可以实现的方式,比如继承方式创建、Builder模式创建.......
第二种是ChatClient调用的时候每次可以自定义不同的ChatOptions配置:
// 方式一:Builder模式动态构建
public class DynamicChatOptionsBuilder {
private ChatOptions.Builder builder = ChatOptions.builder();
public DynamicChatOptionsBuilder model(String model) {
builder.model(model);
return this;
}
public DynamicChatOptionsBuilder temperature(float temperature) {
builder.temperature(temperature);
return this;
}
public DynamicChatOptionsBuilder maxTokens(int maxTokens) {
builder.maxTokens(maxTokens);
return this;
}
public ChatOptions build() {
return builder.build();
}
}
@Service
public class AiService {
private final ChatClient chatClient;
public String generateContent(String prompt, Consumer<DynamicChatOptionsBuilder> optionsConfigurer) {
DynamicChatOptionsBuilder optionsBuilder = new DynamicChatOptionsBuilder();
optionsConfigurer.accept(optionsBuilder);
return chatClient.prompt()
.user(prompt)
.options(optionsBuilder.build())
.call()
.content();
}
}
// 使用示例
aiService.generateContent("解释区块链", builder -> builder
.model("deepseek-chat")
.temperature(0.2)
.maxTokens(300));
aiService.generateContent("创作科幻故事", builder -> builder
.model("deepseek-chat")
.temperature(0.8)
.maxTokens(1000));
@FunctionalInterface
public interface ChatOptionsCustomizer {
void customize(ChatOptions.Builder builder);
}
// 方式二:函数式接口灵活配置
@Service
public class AiService {
private final ChatClient chatClient;
public String generateWithOptions(String prompt, ChatOptionsCustomizer customizer) {
ChatOptions.Builder builder = ChatOptions.builder();
customizer.customize(builder);
return chatClient.prompt()
.user(prompt)
.options(builder.build())
.call()
.content();
}
}
// 使用示例
// 精确的技术解释
aiService.generateWithOptions("解释RESTful API", builder ->
builder.model("gpt-4")
.temperature(0.1)
.maxTokens(250));
// 创意的营销文案
aiService.generateWithOptions("为新产品写广告语", builder ->
builder.model("gpt-4-turbo")
.temperature(0.9)
.maxTokens(100)
.topP(0.95));
// 除此之外,还有其他许多不同场景配置,如策略模式配置、动态配置工厂.......
4.2 属性文件配置(application.properties/yaml)
ChatOptions配置的第二种方式就是在配置文件里配置:
spring:
datasource:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://域名:3306/mybatisdemo?useSSL=false
username: admin
password: 123456
ai:
# 禁用默认的 Chat Client
# chat:
# client:
# enabled: false
deepseek:
# API 密钥
api-key: deepseek的API KEY
# 可选:DeepSeek API 基础地址,默认是 https://api.deepseek.com
# base-url: https://api.deepseek.com
chat:
options:
# DeepSeek 使用的聊天模型,可选 deepseek-chat 或 deepseek-reasoner
# deepseek-chat为聊天模型,deepseek-reasoner为推理模型,推理模型会生成推理过程,比较消耗token
model: deepseek-chat
# 模型的温度值,控制生成文本的随机性(0.0 = 最确定,1.0 = 最随机)
temperature: 0.8
top-p: 0.9
max-tokens: 500
然后在代码中自动注入:
@Service
public class AiService {
private final ChatClient chatClient;
private final DeepSeekChatOptions sharedOptions;
public AiService(
ChatClient chatClient,
@Value("${spring.ai.deepseek.chat.options}") DeepSeekChatOptions sharedOptions) {
this.chatClient = chatClient;
this.sharedOptions = sharedOptions;
}
public String processWithSharedConfig(String prompt) {
return chatClient.prompt()
.user(prompt)
.options(sharedOptions)
.call()
.content();
}
}
除了上面手动把yml文件里配置模型超参数注入到DeepSeekChatOptions里这个方式外,还有另一种自动装配的方式,
我们在引入各个模型厂商的starter的jar包时,里面的自动装配包里会进行配置文件的自动映射,以DeepSeek来为例:
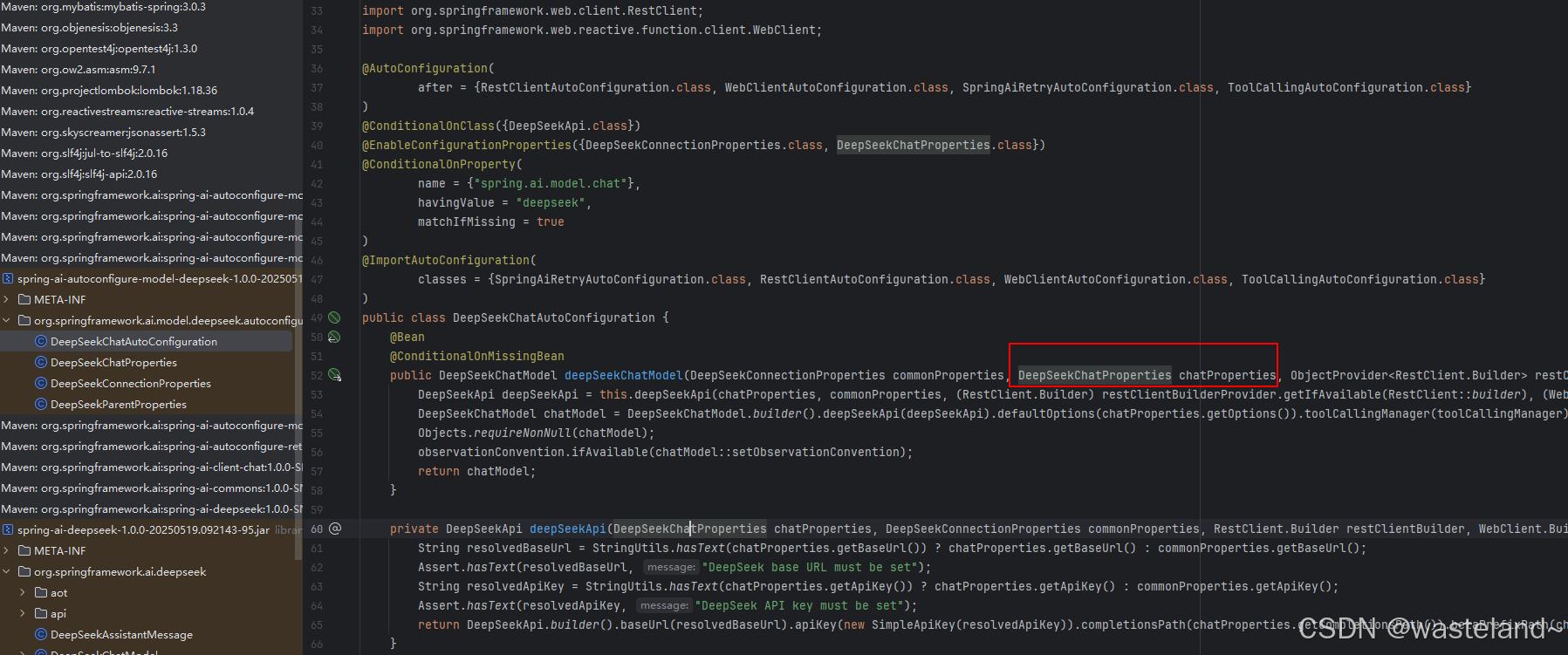
然后再点击DeepSeekChatProperties类进去,可以看见DeepSeekChatProperties的自动映射,依赖于DeepSeekChatOptions的映射:
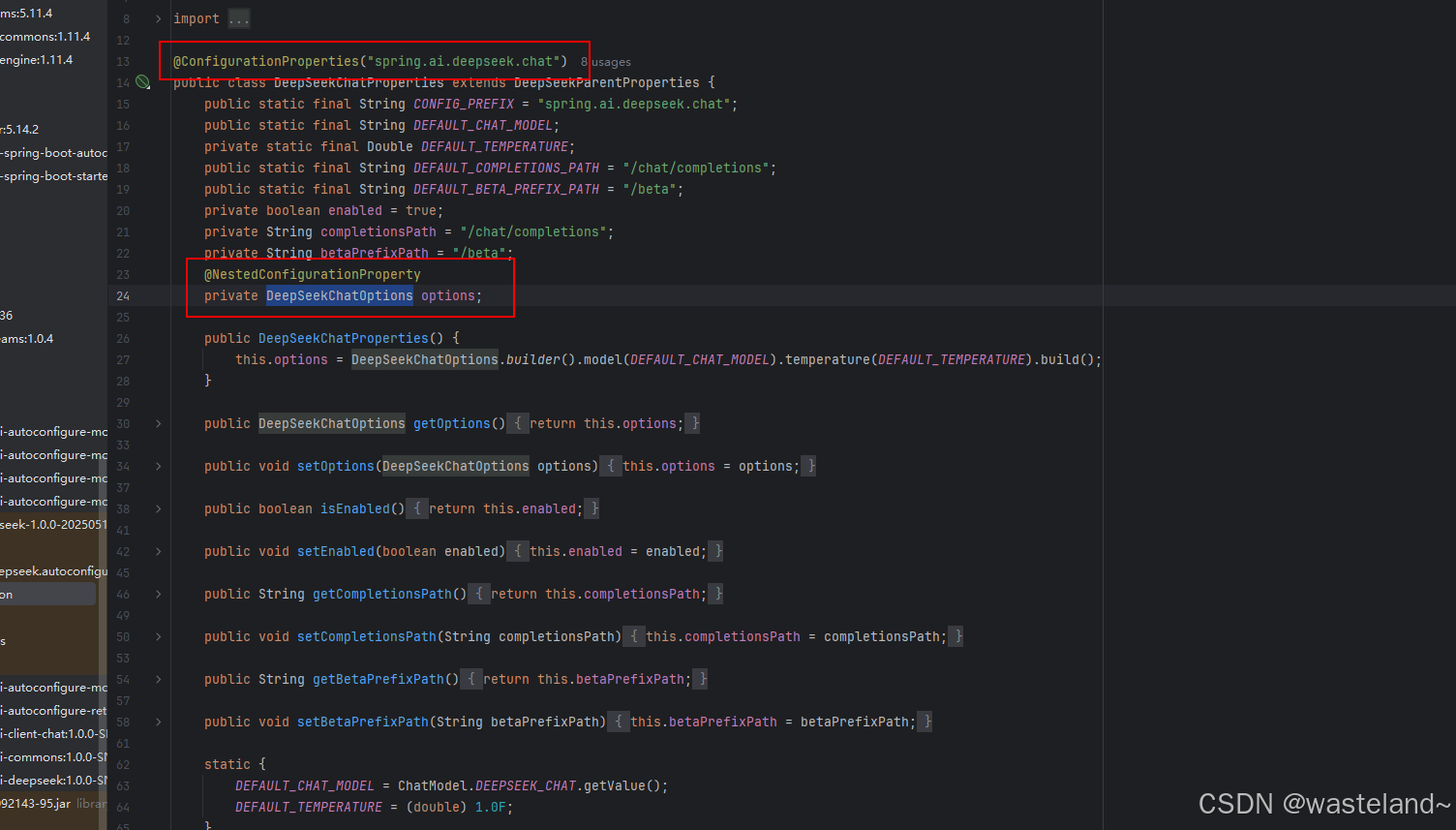
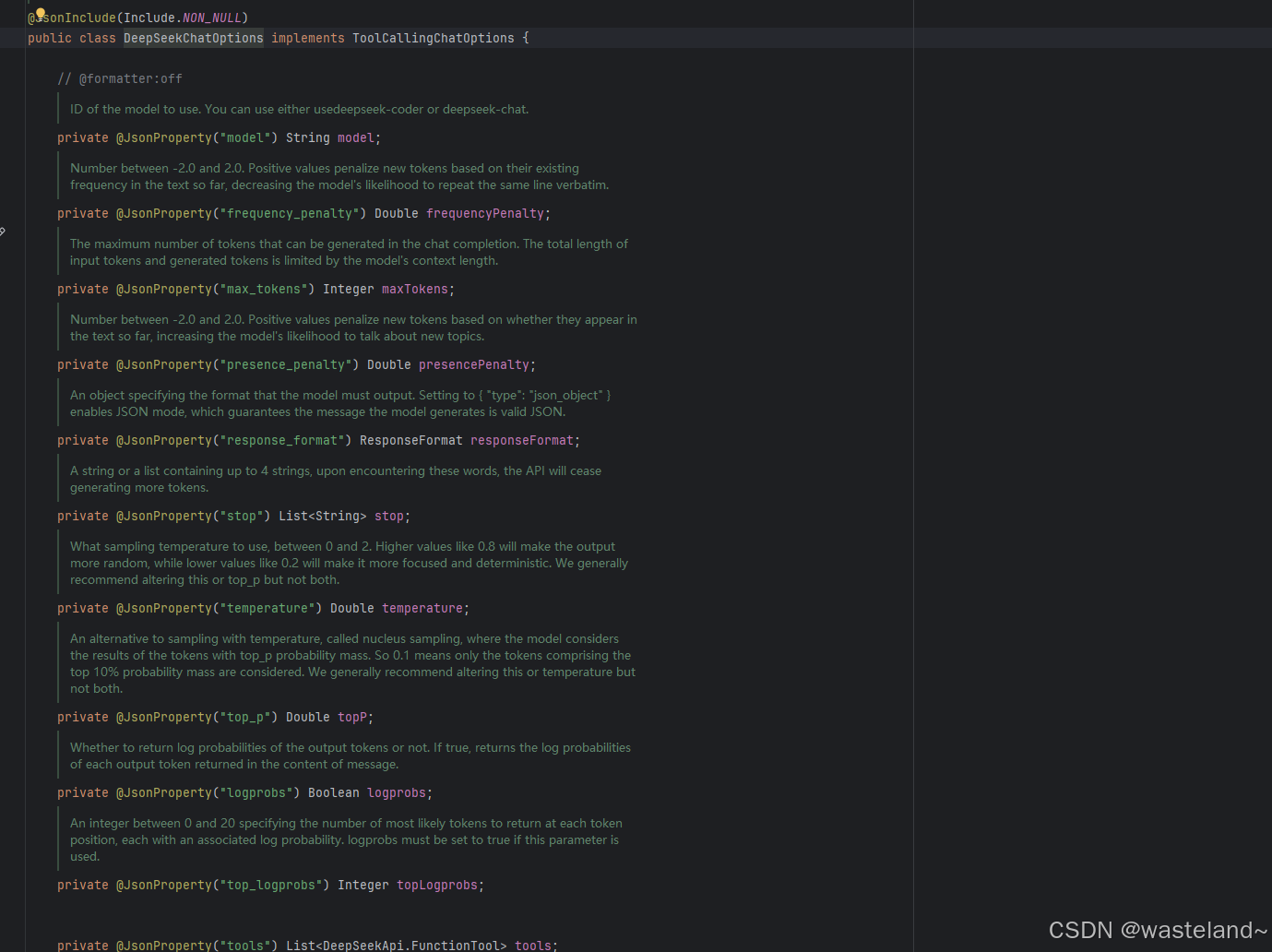
因此,我们可以直接在配置类里引用并开启ChatClient:
@Configuration
public class ChatClientConfig {
@Bean
ChatClient defaultTextChatClient(DeepSeekChatModel chatModel) {
return ChatClient.builder(chatModel)
.defaultSystem("以{style}风格回答关于动漫的问题")
.build();
}
}
五、总结
本文主要先介绍了Token相关的核心概念,然后又介绍了大模型的一些超参数配置,事实上,这些超参数所限制的就是Token。最后,基于超参数配置原理过度到了Spring AI框架中相对应的ChatOptions类的一些API。
六、参考资料


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)