运维存储/运维进阶必备:掌握这3个存储技术,年薪轻松破30W
在现代企业级Linux环境中,文件系统管理是运维工程师必须掌握的核心技能。随着数据量的爆炸式增长和业务连续性要求的提高,传统的单磁盘文件系统已经无法满足企业需求。本文将深入探讨三种关键的高级文件系统管理技术:LVM(逻辑卷管理)、RAID(独立磁盘冗余阵列)和NFS(网络文件系统),为运维工程师提供全面的技术指导。LVM是Linux环境下的逻辑卷管理器,它在物理磁盘和文件系统之间添加了一个逻辑层,
前言
在现代企业级Linux环境中,文件系统管理是运维工程师必须掌握的核心技能。随着数据量的爆炸式增长和业务连续性要求的提高,传统的单磁盘文件系统已经无法满足企业需求。本文将深入探讨三种关键的高级文件系统管理技术:LVM(逻辑卷管理)、RAID(独立磁盘冗余阵列)和NFS(网络文件系统),为运维工程师提供全面的技术指导。
一、LVM(逻辑卷管理)
1.1 LVM概述
LVM是Linux环境下的逻辑卷管理器,它在物理磁盘和文件系统之间添加了一个逻辑层,提供了灵活的磁盘管理方案。LVM的核心优势在于支持动态扩容、快照备份和磁盘迁移等高级功能。
1.2 LVM架构组件
LVM架构包含三个主要层次:
物理卷(Physical Volume, PV):将物理磁盘或分区初始化为LVM可识别的格式。每个PV包含一个卷组描述符区域(VGDA)和多个物理扩展(PE)。
卷组(Volume Group, VG):由一个或多个PV组成的存储池。VG是LVM管理的基本单位,类似于传统的磁盘分区表。
逻辑卷(Logical Volume, LV):从VG中分配空间创建的逻辑分区。LV可以跨越多个PV,为上层文件系统提供存储空间。
1.3 LVM实战配置
创建物理卷
# 创建PV
pvcreate /dev/sdb1 /dev/sdc1
# 查看PV状态
pvdisplay
pvs创建卷组
# 创建VG
vgcreate vg_data /dev/sdb1 /dev/sdc1
# 查看VG状态
vgdisplay vg_data
vgs创建逻辑卷
# 创建LV(指定大小)
lvcreate -L 10G -n lv_web vg_data
# 创建LV(指定PE数量)
lvcreate -l 100%FREE -n lv_database vg_data
# 查看LV状态
lvdisplay
lvs1.4 LVM高级管理
动态扩容
# 扩展LV
lvextend -L +5G /dev/vg_data/lv_web
# 或者扩展到指定大小
lvextend -L 15G /dev/vg_data/lv_web
# 同时扩展文件系统
lvextend -L +5G -r /dev/vg_data/lv_web创建快照
# 创建快照
lvcreate -L 2G -s -n lv_web_snapshot /dev/vg_data/lv_web
# 挂载快照进行备份
mount /dev/vg_data/lv_web_snapshot /mnt/backupPV迁移
# 迁移PV数据
pvmove /dev/sdb1 /dev/sdd1
# 从VG中移除PV
vgreduce vg_data /dev/sdb1二、RAID(独立磁盘冗余阵列)
2.1 RAID技术概述
RAID通过将多个物理磁盘组合成一个逻辑单元,提供数据冗余、性能提升或两者兼备的解决方案。根据数据分布和冗余策略的不同,RAID分为多个级别。
2.2 常用RAID级别详解
RAID 0(条带化)
-
• 特点:数据分条存储,无冗余
-
• 优势:读写性能翻倍,存储空间利用率100%
-
• 劣势:任何一块磁盘故障导致全部数据丢失
-
• 适用场景:临时数据存储,性能要求极高的场景
RAID 1(镜像)
-
• 特点:数据完全镜像,50%存储利用率
-
• 优势:高可靠性,单磁盘故障不影响服务
-
• 劣势:存储成本高,写入性能略有下降
-
• 适用场景:关键系统盘,重要数据存储
RAID 5(分布式奇偶校验)
-
• 特点:数据条带化 + 分布式奇偶校验
-
• 优势:平衡性能和冗余,存储利用率(n-1)/n
-
• 劣势:写入性能较差,重建时间长
-
• 适用场景:企业级数据存储,读多写少的应用
RAID 6(双奇偶校验)
-
• 特点:两个独立的奇偶校验信息
-
• 优势:可容忍两块磁盘同时故障
-
• 劣势:写入性能更差,存储利用率(n-2)/n
-
• 适用场景:大容量存储,对可靠性要求极高的场景
RAID 10(1+0)
-
• 特点:先镜像后条带化
-
• 优势:兼具RAID 0和RAID 1的优点
-
• 劣势:存储利用率仅50%,成本高
-
• 适用场景:数据库存储,高性能高可靠性要求
2.3 软RAID实战配置
使用mdadm创建RAID
# 创建RAID 1
mdadm --create /dev/md0 --level=1 --raid-devices=2 /dev/sdb /dev/sdc
# 创建RAID 5
mdadm --create /dev/md1 --level=5 --raid-devices=3 /dev/sdd /dev/sde /dev/sdf
# 创建RAID 10
mdadm --create /dev/md2 --level=10 --raid-devices=4 /dev/sdg /dev/sdh /dev/sdi /dev/sdjRAID状态监控
# 查看RAID状态
cat /proc/mdstat
mdadm --detail /dev/md0
# 监控RAID事件
mdadm --monitor --scan --daemoniseRAID维护操作
# 标记故障磁盘
mdadm --manage /dev/md0 --fail /dev/sdb
# 移除故障磁盘
mdadm --manage /dev/md0 --remove /dev/sdb
# 添加新磁盘
mdadm --manage /dev/md0 --add /dev/sdx
# 停止RAID
mdadm --stop /dev/md02.4 RAID最佳实践
性能优化
# 设置读取预读大小
echo 8192 > /sys/block/md0/md/stripe_cache_size
# 调整块设备队列深度
echo 32 > /sys/block/md0/queue/nr_requests监控告警
# 配置邮件告警
echo "MAILADDR admin@company.com" >> /etc/mdadm/mdadm.conf
echo "MAILFROM raid-monitor@company.com" >> /etc/mdadm/mdadm.conf三、NFS(网络文件系统)
3.1 NFS架构原理
NFS是基于RPC(远程过程调用)的分布式文件系统,允许网络中的计算机共享文件和目录。NFS采用客户端-服务器架构,通过网络透明地访问远程文件系统。
3.2 NFS版本对比
NFSv3特性
-
• 支持大文件(64位文件偏移量)
-
• 异步写入提升性能
-
• 支持TCP和UDP协议
-
• 弱一致性模型
NFSv4特性
-
• 集成安全机制(Kerberos支持)
-
• 状态化协议,提供文件锁定
-
• 支持委托(delegation)机制
-
• 复合操作减少网络延迟
-
• 国际化支持(UTF-8)
3.3 NFS服务器配置
安装NFS服务
# RHEL/CentOS
yum install -y nfs-utils rpcbind
# Ubuntu/Debian
apt-get install -y nfs-kernel-server配置NFS导出
# 编辑/etc/exports文件
/data/shared 192.168.1.0/24(rw,sync,no_subtree_check,no_root_squash)
/data/public *(ro,sync,no_subtree_check,all_squash,anonuid=65534,anongid=65534)
/data/backup 192.168.1.10(rw,sync,no_subtree_check,root_squash)导出选项详解
-
•
rw/ro:读写/只读权限 -
•
sync/async:同步/异步写入 -
•
no_subtree_check:禁用子目录检查 -
•
root_squash/no_root_squash:root用户权限映射 -
•
all_squash:所有用户映射为匿名用户 -
•
anonuid/anongid:匿名用户ID
启动NFS服务
# 启动服务
systemctl enable --now rpcbind nfs-server
# 重新加载导出配置
exportfs -ra
# 查看当前导出
exportfs -v
showmount -e localhost3.4 NFS客户端配置
挂载NFS共享
# 临时挂载
mount -t nfs -o vers=4,rsize=32768,wsize=32768,hard,intr 192.168.1.100:/data/shared /mnt/nfs
# 永久挂载(/etc/fstab)
192.168.1.100:/data/shared /mnt/nfs nfs vers=4,rsize=32768,wsize=32768,hard,intr 0 0挂载选项优化
-
•
vers=4:指定NFS版本 -
•
rsize/wsize:读写块大小 -
•
hard/soft:重试策略 -
•
intr:允许中断操作 -
•
timeo:超时时间 -
•
retrans:重传次数
3.5 NFS性能优化
网络优化
# 调整网络缓冲区大小
echo 'net.core.rmem_default = 262144' >> /etc/sysctl.conf
echo 'net.core.rmem_max = 16777216' >> /etc/sysctl.conf
echo 'net.core.wmem_default = 262144' >> /etc/sysctl.conf
echo 'net.core.wmem_max = 16777216' >> /etc/sysctl.conf
sysctl -pNFS服务器优化
# 增加NFS守护进程数量
echo 'RPCNFSDCOUNT=32' >> /etc/sysconfig/nfs
# 配置NFS缓存
echo 'vm.dirty_ratio = 5' >> /etc/sysctl.conf
echo 'vm.dirty_background_ratio = 2' >> /etc/sysctl.conf3.6 NFS安全配置
使用Kerberos认证
# 服务器端配置
/data/secure 192.168.1.0/24(rw,sync,sec=krb5p,no_subtree_check)
# 客户端挂载
mount -t nfs -o vers=4,sec=krb5p server:/data/secure /mnt/secure防火墙配置
# 固定NFS端口
echo 'STATD_PORT=32765' >> /etc/sysconfig/nfs
echo 'LOCKD_TCPPORT=32766' >> /etc/sysconfig/nfs
echo 'LOCKD_UDPPORT=32766' >> /etc/sysconfig/nfs
echo 'MOUNTD_PORT=32767' >> /etc/sysconfig/nfs
# 开放防火墙端口
firewall-cmd --permanent --add-service=nfs
firewall-cmd --permanent --add-service=rpc-bind
firewall-cmd --permanent --add-service=mountd
firewall-cmd --reload四、综合应用案例
4.1 企业级存储架构设计
在实际生产环境中,通常需要将LVM、RAID和NFS技术结合使用。以下是一个典型的企业级存储架构设计:
底层存储层(RAID)
# 创建RAID 10阵列作为高性能存储
mdadm --create /dev/md0 --level=10 --raid-devices=4 /dev/sdb /dev/sdc /dev/sdd /dev/sde
# 创建RAID 6阵列作为大容量存储
mdadm --create /dev/md1 --level=6 --raid-devices=6 /dev/sdf /dev/sdg /dev/sdh /dev/sdi /dev/sdj /dev/sdk逻辑卷管理层(LVM)
# 创建物理卷
pvcreate /dev/md0 /dev/md1
# 创建卷组
vgcreate vg_performance /dev/md0
vgcreate vg_capacity /dev/md1
# 创建逻辑卷
lvcreate -L 50G -n lv_database vg_performance
lvcreate -L 20G -n lv_logs vg_performance
lvcreate -L 500G -n lv_backup vg_capacity
lvcreate -L 1T -n lv_archive vg_capacity文件系统层
# 创建文件系统
mkfs.ext4 /dev/vg_performance/lv_database
mkfs.ext4 /dev/vg_performance/lv_logs
mkfs.xfs /dev/vg_capacity/lv_backup
mkfs.xfs /dev/vg_capacity/lv_archiveNFS共享层
# 配置NFS导出
echo '/data/database 192.168.1.0/24(rw,sync,no_subtree_check,no_root_squash)' >> /etc/exports
echo '/data/backup 192.168.1.0/24(rw,sync,no_subtree_check,root_squash)' >> /etc/exports
echo '/data/archive 192.168.1.0/24(ro,sync,no_subtree_check,all_squash)' >> /etc/exports4.2 自动化运维脚本
存储健康检查脚本
#!/bin/bash
# storage_health_check.sh
# 检查RAID状态
check_raid() {
echo "=== RAID Status ==="
cat /proc/mdstat
for md in $(ls /dev/md* 2>/dev/null); do
mdadm --detail $md | grep -E "(State|Failed|Spare)"
done
}
# 检查LVM状态
check_lvm() {
echo "=== LVM Status ==="
vgs --noheadings -o vg_name,vg_size,vg_free
lvs --noheadings -o lv_name,lv_size,lv_attr
}
# 检查NFS状态
check_nfs() {
echo "=== NFS Status ==="
exportfs -v
showmount -e localhost
}
# 磁盘空间检查
check_disk_space() {
echo "=== Disk Space ==="
df -h | grep -E "^/dev/(md|mapper)"
}
# 执行检查
check_raid
check_lvm
check_nfs
check_disk_space4.3 监控告警集成
Zabbix监控模板
# 创建自定义监控脚本
cat > /etc/zabbix/scripts/raid_status.sh << 'EOF'
#!/bin/bash
RAID_DEVICE=$1
if [ -z "$RAID_DEVICE" ]; then
echo "Usage: $0 <raid_device>"
exit 1
fi
STATUS=$(mdadm --detail $RAID_DEVICE | grep "State :" | awk '{print $3}')
if [ "$STATUS" = "clean" ]; then
echo 0
else
echo 1
fi
EOF
chmod +x /etc/zabbix/scripts/raid_status.sh五、故障处理与恢复
5.1 RAID故障处理
磁盘故障恢复
# 检查故障磁盘
mdadm --detail /dev/md0
# 热替换故障磁盘
mdadm --manage /dev/md0 --remove /dev/sdb
mdadm --manage /dev/md0 --add /dev/sdx
# 监控重建进程
watch -n 5 'cat /proc/mdstat'5.2 LVM故障处理
逻辑卷修复
# 检查LVM元数据
vgcfgbackup vg_data
vgcfgrestore -f /etc/lvm/backup/vg_data vg_data
# 激活逻辑卷
vgchange -ay vg_data5.3 NFS故障处理
NFS服务恢复
# 检查NFS服务状态
systemctl status nfs-server rpcbind
# 清理NFS锁定
rm -rf /var/lib/nfs/statd/sm/*
systemctl restart nfs-server六、最佳实践总结
6.1 设计原则
可靠性优先:关键数据必须有冗余保护,建议使用RAID 1或RAID 10
性能考虑:根据应用特性选择合适的RAID级别和文件系统
扩展性规划:使用LVM提供灵活的容量管理
监控告警:建立完善的监控体系,及时发现问题
6.2 运维规范
定期备份:制定备份策略,定期测试恢复流程
容量规划:监控存储增长趋势,提前进行容量扩展
性能调优:根据业务负载特性调整系统参数
文档记录:详细记录配置变更和故障处理过程
6.3 安全建议
访问控制:严格控制NFS访问权限,使用网络分段
数据加密:敏感数据传输使用加密协议
审计日志:启用文件系统审计,记录关键操作
定期检查:定期检查存储系统健康状态
结语
高级文件系统管理技术是现代运维工程师的核心技能之一。通过合理运用LVM、RAID和NFS技术,可以构建高可用、高性能、易管理的企业级存储系统。在实际应用中,需要根据具体业务需求和技术环境,制定合适的存储架构方案。
随着云计算和容器技术的发展,传统的存储管理方式也在不断演进。运维工程师需要持续学习新技术,将传统存储管理经验与现代基础设施相结合,为企业提供更加可靠和高效的存储解决方案。
持续的监控、定期的维护和及时的故障处理是保障存储系统稳定运行的关键。建议建立完善的运维流程和应急预案,确保在各种情况下都能快速响应和处理问题,最大限度地保障业务连续性。
这两年,IT行业面临经济周期波动与AI产业结构调整的双重压力,确实有很多运维与网络工程师因企业缩编或技术迭代而暂时失业。
很多人都在提运维网工失业后就只能去跑滴滴送外卖了,但我想分享的是,对于运维人员来说,即便失业以后仍然有很多副业可以尝试。
运维,千万不要再错过这些副业机会!
第一个是知识付费类副业:输出经验打造个人IP
在线教育平台讲师
操作路径:在慕课网、极客时间等平台开设《CCNA实战》《Linux运维从入门到精通》等课程,或与培训机构合作录制专题课。
收益模式:课程销售分成、企业内训。
技术博客与公众号运营
操作路径:撰写网络协议解析、故障排查案例、设备评测等深度文章,通过公众号广告、付费专栏及企业合作变现。
收益关键:每周更新2-3篇原创,结合SEO优化与社群运营。
第二个是技术类副业:深耕专业领域变现
企业网络设备配置与优化服务
操作路径:为中小型企业提供路由器、交换机、防火墙等设备的配置调试、性能优化及故障排查服务。可通过本地IT服务公司合作或自建线上接单平台获客。
收益模式:按项目收费或签订年度维护合同。
远程IT基础设施代维
操作路径:通过承接服务器监控、日志分析、备份恢复等远程代维任务。适合熟悉Zabbix、ELK等技术栈的工程师。
收益模式:按工时计费或包月服务。
网络安全顾问与渗透测试
操作路径:利用OWASP Top 10漏洞分析、Nmap/BurpSuite等工具,为企业提供漏洞扫描、渗透测试及安全加固方案。需考取CISP等认证提升资质。
收益模式:单次渗透测试报告收费;长期安全顾问年费。
比如不久前跟我一起聊天的一个粉丝,他自己之前是大四实习的时候做的运维,发现运维7*24小时待命受不了,就准备转网安,学了差不多2个月,然后开始挖漏洞,光是补天的漏洞奖励也有个四五千,他说自己每个月的房租和饭钱就够了。
为什么我会推荐你网安是运维人员的绝佳副业&转型方向?
1.你的经验是巨大优势: 你比任何人都懂系统、网络和架构。漏洞挖掘、内网渗透、应急响应,这些核心安全能力本质上是“攻击视角下的运维”。你的运维背景不是从零开始,而是降维打击。
2.越老越吃香,规避年龄危机: 安全行业极度依赖经验。你的排查思路、风险意识和对复杂系统的理解能力,会随着项目积累而愈发珍贵,真正做到“姜还是老的辣”。
3.职业选择极其灵活: 你可以加入企业成为安全专家,可以兼职“挖洞“获取丰厚奖金,甚至可以成为自由顾问。这种多样性为你提供了前所未有的抗风险能力。
4.市场需求爆发,前景广阔: 在国家级政策的推动下,从一线城市到二三线地区,安全人才缺口正在急剧扩大。现在布局,正是抢占未来先机的黄金时刻。
1. 阶段目标
你已经有运维经验了,所以操作系统、网络协议这些你不是零基础。但要学安全,得重新过一遍——只不过这次我们是带着“安全视角”去学。
2. 学习内容
**操作系统强化:**你需要重点学习 Windows、Linux 操作系统安全配置,对比运维工作中常规配置与安全配置的差异,深化系统安全认知(比如说日志审计配置,为应急响应日志分析打基础)。
**网络协议深化:**结合过往网络协议应用经验,聚焦 TCP/IP 协议簇中的安全漏洞及防护机制,如 ARP 欺骗、TCP 三次握手漏洞等(为 SRC 漏扫中协议层漏洞识别铺垫)。
**Web 与数据库基础:**补充 Web 架构、HTTP 协议及 MySQL、SQL Server 等数据库安全相关知识,了解 Web 应用与数据库在网安中的作用。
**编程语言入门:**学习 Python 基础语法,掌握简单脚本编写,为后续 SRC 漏扫自动化脚本开发及应急响应工具使用打基础。
**工具实战:**集中训练抓包工具(Wireshark)、渗透测试工具(Nmap)、漏洞扫描工具(Nessus 基础版)的使用,结合模拟场景练习工具应用(掌握基础扫描逻辑,为 SRC 漏扫工具进阶做准备)。
1. 阶段目标
这阶段是真正开始“动手”了。信息收集、漏洞分析、工具联动,一样不能少。
熟练运用漏洞挖掘及 SRC 漏扫工具,具备独立挖掘常见漏洞及 SRC 平台漏扫实战能力,尝试通过 SRC 挖洞搞钱,不管是低危漏洞还是高危漏洞,先挖到一个。
2. 学习内容
信息收集实战:结合运维中对网络拓扑、设备信息的了解,强化基本信息收集、网络空间搜索引擎(Shodan、ZoomEye)、域名及端口信息收集技巧,针对企业级网络场景开展信息收集练习(为 SRC 漏扫目标筛选提供支撑)。
漏洞原理与分析:深入学习 SQL 注入、CSRF、文件上传等常见漏洞的原理、危害及利用方法,结合运维工作中遇到的类似问题进行关联分析(明确 SRC 漏扫重点漏洞类型)。
工具进阶与 SRC 漏扫应用:
-
系统学习 SQLMap、BurpSuite、AWVS 等工具的高级功能,开展工具联用实战训练;
-
专项学习 SRC 漏扫流程:包括 SRC 平台规则解读(如漏洞提交规范、奖励机制)、漏扫目标范围界定、漏扫策略制定(全量扫描 vs 定向扫描)、漏扫结果验证与复现;
-
实战训练:使用 AWVS+BurpSuite 组合开展 SRC 平台目标漏扫,练习 “扫描 - 验证 - 漏洞报告撰写 - 平台提交” 全流程。
SRC 实战演练:选择合适的 SRC 平台(如补天、CNVD)进行漏洞挖掘与漏扫实战,积累实战经验,尝试获取挖洞收益。
恭喜你,如果学到这里,你基本可以下班搞搞副业创收了,并且具备渗透测试工程师必备的「渗透技巧」、「溯源能力」,让你在黑客盛行的年代别背锅,工作实现升职加薪的同时也能开创副业创收!
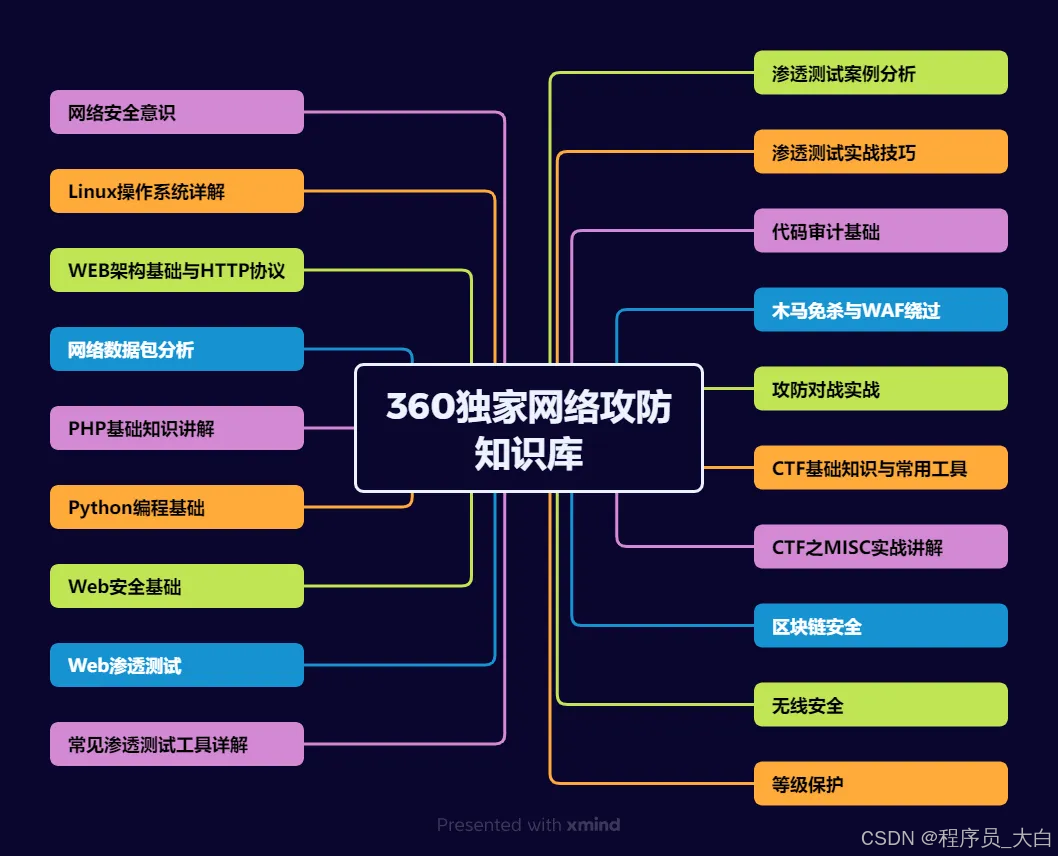
如果你想要入坑黑客&网络安全,笔者给大家准备了一份:全网最全的网络安全资料包需要保存下方图片,微信扫码即可前往获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
1. 阶段目标
全面掌握渗透测试理论与实战技能,能够独立完成渗透测试项目,编写规范的渗透测试报告,具备渗透测试工程师岗位能力,为护网红蓝对抗及应急响应提供技术支撑。
2. 学习内容
渗透测试核心理论:系统学习渗透测试流程、方法论及法律法规知识,明确渗透测试边界与规范(与红蓝对抗攻击边界要求一致)。
实战技能训练:开展漏洞扫描、漏洞利用、电商系统渗透测试、内网渗透、权限提升(Windows、Linux)、代码审计等实战训练,结合运维中熟悉的系统环境设计测试场景(强化红蓝对抗攻击端技术能力)。
工具开发实践:基于 Python 编程基础,学习渗透测试工具开发技巧,开发简单的自动化测试脚本(可拓展用于 SRC 漏扫自动化及应急响应辅助工具)。
报告编写指导:学习渗透测试报告的结构与编写规范,完成多个不同场景的渗透测试报告撰写练习(与 SRC 漏洞报告、应急响应报告撰写逻辑互通)。
1. 阶段目标
掌握企业级安全攻防、护网红蓝对抗及应急响应核心技能,考取网安行业相关证书。
2. 学习内容
护网红蓝对抗专项:
-
红蓝对抗基础:学习护网行动背景、红蓝对抗规则(攻击范围、禁止行为)、红蓝双方角色职责(红队:模拟攻击;蓝队:防御检测与应急处置);
-
红队实战技能:强化内网渗透、横向移动、权限维持、免杀攻击等高级技巧,模拟护网中常见攻击场景;
-
蓝队实战技能:学习安全设备(防火墙、IDS/IPS、WAF)联动防御配置、安全监控平台(SOC)使用、攻击行为研判与溯源方法;
-
模拟护网演练:参与团队式红蓝对抗演练,完整体验 “攻击 - 检测 - 防御 - 处置” 全流程。
应急响应专项: -
应急响应流程:学习应急响应 6 步流程(准备 - 检测 - 遏制 - 根除 - 恢复 - 总结),掌握各环节核心任务;
-
实战技能:开展操作系统入侵响应(如病毒木马清除、异常进程终止)、数据泄露应急处置、漏洞应急修补等实战训练;
-
工具应用:学习应急响应工具(如 Autoruns、Process Monitor、病毒分析工具)的使用,提升处置效率;
-
案例复盘:分析真实网络安全事件应急响应案例(如勒索病毒事件),总结处置经验。
其他企业级攻防技能:学习社工与钓鱼、CTF 夺旗赛解析等内容,结合运维中企业安全防护需求深化理解。
证书备考:针对网安行业相关证书考试内容(含红蓝对抗、应急响应考点)进行专项复习,参加模拟考试,查漏补缺。
网络安全这行,不是会几个工具就能搞定的。你得有体系,懂原理,能实战。尤其是从运维转过来的,别浪费你原来的经验——你比纯新人强多了。
但也要沉得住气,别学了两天Web安全就觉得自己是黑客了。内网、域渗透、代码审计、应急响应,要学的还多着呢。
如果你真的想转,按这个路子一步步走,没问题。如果你只是好奇,我劝你再想想——这行要持续学习,挺累的,但也是真有意思。
关于如何学习网络安全,笔者也给大家整理好了全套网络安全知识库,需要的可以扫码获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
1、网络安全意识
2、Linux操作系统
3、WEB架构基础与HTTP协议
4、Web渗透测试
5、渗透测试案例分享
6、渗透测试实战技巧
7、攻防对战实战
8、CTF之MISC实战讲解
关于如何学习网络安全,笔者也给大家整理好了全套网络安全知识库,需要的可以扫码获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 21
21 0
0- 0



 已为社区贡献105条内容
已为社区贡献105条内容

所有评论(0)