AI 语音文字总结:工具使用技巧与实战案例全解析
AI语音文字总结技术应用指南 本文系统介绍了AI语音文字总结技术在各行业的实践应用。核心技术框架包含语音识别、文本预处理和语义理解三大模块,通过主流工具如讯飞听见、Whisper等实现语音转文字和智能摘要。文章详细解析了Prompt工程技巧,提供多场景模板,并展示会议纪要、客户访谈等典型案例的实施效果:会议纪要生成时间缩短89%,医疗问诊效率提升33%。同时针对准确率、数据隐私等常见问题给出解决方
前言
在信息爆炸的数字化时代,语音作为最自然的交互方式之一,其产生的数据量正呈指数级增长。从会议录音、客户访谈到课程讲座、播客内容,海量语音信息中蕴含着巨大价值,但传统人工转录与总结方式存在效率低、成本高、易出错等痛点。AI 语音识别(Automatic Speech Recognition, ASR)与文字总结技术的融合,为解决这一痛点提供了高效方案。
本文将系统拆解 AI 语音文字总结的核心流程,详解主流工具的使用技巧,结合多行业实战案例提供可复用的代码模板、Prompt 工程方案与可视化图表,帮助读者从技术原理到落地应用全面掌握该技术,实现从 “信息接收” 到 “价值提取” 的效率跃迁。
一、AI 语音文字总结核心技术框架
AI 语音文字总结并非单一技术,而是由语音识别(ASR)、文本预处理、语义理解与总结三大模块构成的完整流程。各模块协同工作,将非结构化的语音数据转化为结构化的摘要文本,其技术框架与数据流向如下:
1.1 技术流程可视化(Mermaid 流程图)
flowchart TD
A[语音输入] -->|音频格式:WAV/MP3/M4A| B[语音预处理]
B --> B1(降噪处理:去除环境噪音)
B --> B2(语速归一化:统一音频采样率)
B --> B3(人声分离:提取目标说话人声音)
B1 & B2 & B3 --> C[AI语音识别(ASR)]
C -->|输出:原始文本转录稿| D[文本预处理]
D --> D1(文本清洗:去除语气词/重复句)
D --> D2(格式标准化:分段/标点补全)
D --> D3(实体识别:提取人名/地名/关键术语)
D1 & D2 & D3 --> E[AI文字总结]
E --> E1(提取式总结:筛选核心句子)
E --> E2(生成式总结:重构连贯文本)
E1 & E2 --> F[总结结果优化]
F --> F1(关键词标注:高亮核心信息)
F --> F2(格式输出:Markdown/Word/Excel)
F1 & F2 --> G[最终成果:结构化摘要]
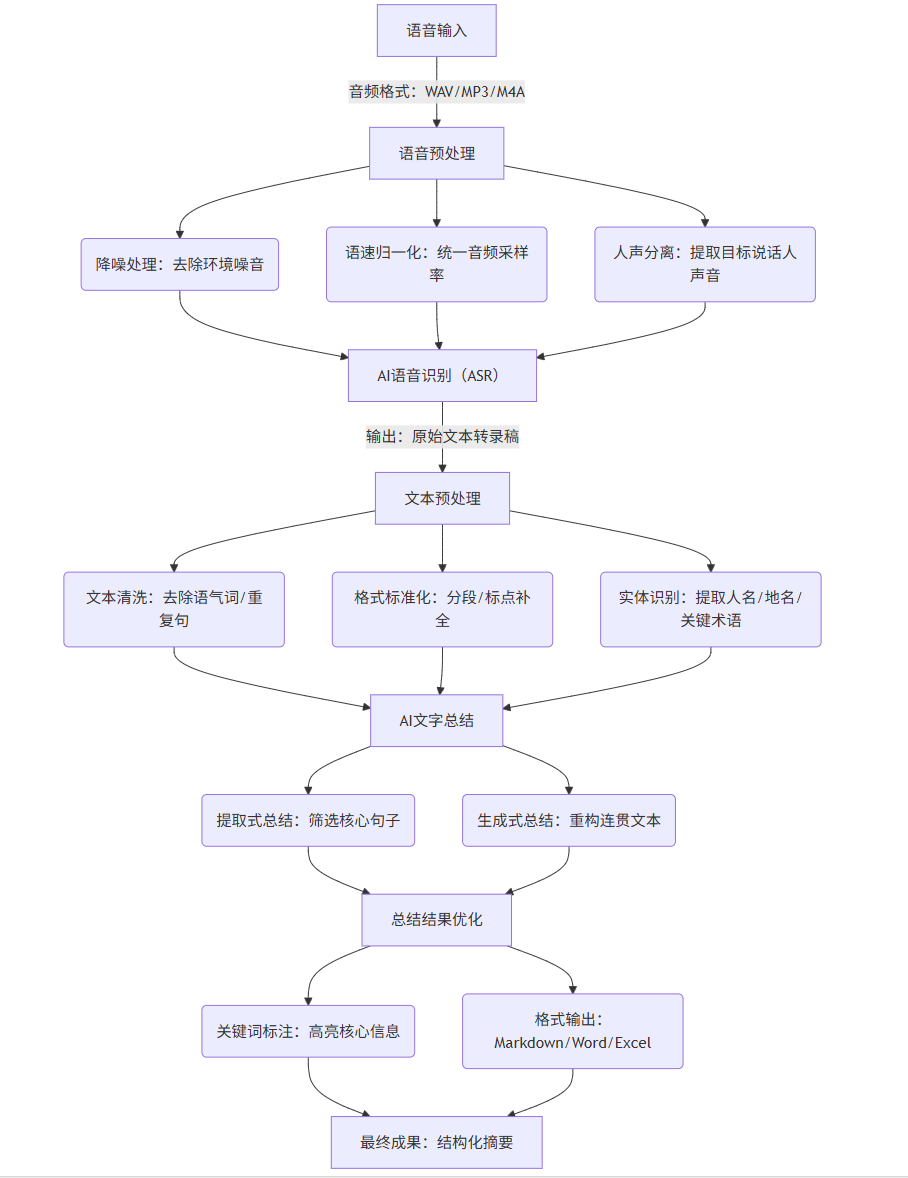
1.2 核心技术模块解析
| 模块 | 核心功能 | 关键技术 | 常见问题 | 优化方向 |
|---|---|---|---|---|
| 语音识别(ASR) | 将语音信号转化为文字 | 深度学习(Transformer/CNN)、声学模型、语言模型 | 方言识别准确率低、噪音干扰、专业术语错译 | 1. 加入领域语料微调模型2. 前置降噪算法(如 spectral gating)3. 多说话人分离技术 |
| 文本预处理 | 优化转录文本质量 | 正则表达式、NLP 分词(jieba/Spacy)、实体识别(NER) | 语气词冗余(“嗯”“啊”)、句子断裂、格式混乱 | 1. 自定义停用词表过滤冗余2. 基于语法规则补全标点3. 实体库匹配修正专业术语 |
| 文字总结 | 提取文本核心信息 | 预训练模型(BERT/T5/GPT)、注意力机制、强化学习 | 摘要不完整、逻辑混乱、专业信息丢失 | 1. 基于领域数据微调模型2. 加入 prompt 引导总结方向3. 多轮迭代优化摘要结构 |
二、主流 AI 语音文字总结工具使用技巧
不同工具适用于不同场景(个人轻量使用、企业级部署、开发者二次开发),本节将分类讲解工具特性、操作步骤与进阶技巧,覆盖从 “零代码” 到 “代码级” 的全需求。
2.1 零代码工具:快速上手(适合非技术用户)
工具 1:讯飞听见(侧重专业场景:会议 / 访谈)
- 核心特性:支持 12 种方言识别、实时字幕生成、多 speaker 区分、Word/Excel 格式导出。
- 操作步骤:
- 登录讯飞听见官网(https://www.iflyrec.com/),点击 “上传音频”;
- 选择音频文件(支持 MP3/WAV/M4A,单个文件最大 1GB),设置 “识别语言”(如 “中文 + 英语混合”)、“说话人数量”(如 “3 人”);
- 等待识别完成(10 分钟音频约需 1 分钟),点击 “文本编辑” 修正错字,再点击 “智能总结” 选择总结类型(“会议纪要”“核心观点”);
- 导出总结结果(支持 Markdown/Word,可勾选 “高亮关键词”)。
- 进阶技巧:
- 上传前用 “讯飞听见 APP” 的 “降噪” 功能处理音频(尤其适合户外录音);
- 自定义 “术语库”(在 “个人中心 - 术语管理” 添加行业术语,如 “AI 大模型”“Prompt 工程”),提升专业词汇识别准确率;
- 会议场景中,提前标记 “主持人”“嘉宾”,总结时会按角色分类呈现观点。
工具 2:腾讯云智服(侧重企业场景:客服录音分析)
- 核心特性:支持批量处理客服录音、自动提取客户诉求 / 投诉点、生成工单摘要、多维度数据统计(如 “客户满意度关键词分布”)。
- 操作步骤:
- 登录腾讯云智服控制台(https://cloud.tencent.com/product/aiasr),进入 “语音转文字 - 批量任务”;
- 上传客服录音文件夹(支持 ZIP 压缩包,单次最大 100 个文件),设置 “业务标签”(如 “电商售后”“金融咨询”);
- 任务完成后,在 “文本总结” 模块选择 “客服对话摘要”,系统会自动输出:客户问题、客服解决方案、是否达成共识;
- 在 “数据分析” 模块查看可视化报表(如 “高频投诉问题 TOP5” 柱状图)。
- 进阶技巧:
- 配置 “规则引擎”(如 “当文本中出现‘退款’‘不发货’时,自动标记为‘投诉工单’”);
- 对接企业 CRM 系统,将总结中的客户信息(如手机号、订单号)自动同步至客户档案。
2.2 低代码工具:灵活配置(适合运营 / 产品经理)
工具:飞书多维表格 + 飞书妙记(协同场景:团队知识沉淀)
- 核心特性:语音转文字与表格协同,支持多人实时编辑总结、关联任务清单、跨文档引用。
- 操作步骤:
- 上传会议录音至飞书妙记(https://meet.feishu.cn/minutes),自动生成转录文本与时间戳;
- 选中转录文本中的核心观点,点击 “生成总结”,选择 “段落总结” 或 “要点总结”;
- 将总结结果复制到飞书多维表格,添加 “任务负责人”“截止日期”“关联文档” 等字段;
- 分享表格给团队成员,成员可在总结旁添加评论,或通过 “时间戳跳转” 回听对应语音片段。
- 进阶技巧:
- 使用 “飞书机器人”,设置 “当妙记生成新总结时,自动发送通知到团队群”;
- 在多维表格中添加 “公式字段”,自动统计 “每周总结任务完成率”;
- 用 “跨表格引用” 功能,将不同会议的总结关联到同一项目文档,形成完整知识链。
2.3 代码级工具:二次开发(适合开发者 / 技术团队)
工具 1:Whisper(OpenAI 开源 ASR 模型,支持多语言)
Whisper 是 OpenAI 推出的开源语音识别模型,支持 100 + 语言,可本地部署,适合需要自定义功能的场景(如嵌入 APP、对接私有数据)。
1. 环境搭建(Python)
bash
# 安装依赖
pip install openai-whisper
pip install ffmpeg-python # 处理音频格式
2. 基础语音识别代码(将 MP3 转为文本)
python
运行
import whisper
# 加载模型(模型规模:tiny < base < small < medium < large,越大准确率越高,速度越慢)
model = whisper.load_model("base") # 入门推荐base,中文场景推荐medium
# 处理音频文件(支持MP3/WAV/M4A)
result = model.transcribe(
"meeting_recording.mp3", # 音频文件路径
language="zh", # 指定语言(zh=中文,en=英语)
word_timestamps=True, # 输出每个词的时间戳
verbose=False # 关闭日志输出
)
# 保存转录文本到文件
with open("transcript.txt", "w", encoding="utf-8") as f:
f.write(result["text"])
# 打印带时间戳的转录结果(便于定位语音片段)
for segment in result["segments"]:
start = segment["start"] # 开始时间(秒)
end = segment["end"] # 结束时间(秒)
text = segment["text"] # 转录文本
print(f"[{start:.2f}-{end:.2f}s] {text}")
3. 进阶功能:多说话人分离
python
运行
# 安装多说话人分离依赖
pip install pyannote.audio
from pyannote.audio import Pipeline
# 加载pyannote多说话人分离模型(需在Hugging Face获取token:https://huggingface.co/pyannote/speaker-diarization-3.1)
pipeline = Pipeline.from_pretrained(
"pyannote/speaker-diarization-3.1",
use_auth_token="YOUR_HUGGINGFACE_TOKEN"
)
# 执行说话人分离
diarization = pipeline("meeting_recording.mp3")
# 结合Whisper转录结果,标记每个片段的说话人
with open("transcript_with_speaker.txt", "w", encoding="utf-8") as f:
for segment, _, speaker in diarization.itertracks(yield_label=True):
# 匹配Whisper中对应时间戳的文本
for whisper_segment in result["segments"]:
if (whisper_segment["start"] >= segment.start) and (whisper_segment["end"] <= segment.end):
f.write(f"Speaker {speaker}: [{whisper_segment['start']:.2f}-{whisper_segment['end']:.2f}s] {whisper_segment['text']}\n")
4. 使用技巧
- 模型选择:本地部署优先选 “medium”(中文准确率≈95%),云端部署可选 “large”(准确率≈98%);
- 音频预处理:用
ffmpeg将音频转为 16kHz、单声道(Whisper 最优输入格式),命令如下:bash
ffmpeg -i input.mp3 -ar 16000 -ac 1 output.wav - 自定义词汇:创建
vocab.txt文件添加专业词汇,在transcribe中指定:python
运行
result = model.transcribe("audio.mp3", vocabulary="vocab.txt")
工具 2:LangChain+ChatGLM(实现 “ASR + 总结” 端到端流程)
LangChain 是开源的 LLM 应用开发框架,可串联 Whisper(ASR)、ChatGLM(总结),实现从语音到摘要的自动化流程。
1. 完整代码(语音→文本→总结)
python
运行
from langchain.llms import ChatGLM
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
import whisper
# 1. 语音识别(Whisper)
def speech_to_text(audio_path):
model = whisper.load_model("medium")
result = model.transcribe(audio_path, language="zh")
return result["text"]
# 2. 文字总结(ChatGLM)
def text_summarize(text, summary_type="会议纪要"):
# 定义Prompt模板(根据场景调整)
prompt_template = """
你是专业的{summary_type}生成助手,请基于以下文本完成:
1. 提取核心观点(分点列出,每点不超过20字);
2. 总结关键行动项(包含负责人、截止时间);
3. 标注需要跟进的问题。
文本内容:{text}
请严格按照上述结构输出,语言简洁、逻辑清晰。
"""
prompt = PromptTemplate(
input_variables=["summary_type", "text"],
template=prompt_template
)
# 初始化ChatGLM模型(本地部署或调用API)
llm = ChatGLM(
endpoint_url="http://localhost:8000/v1/chat/completions", # 本地部署地址
max_tokens=2048,
temperature=0.3 # 温度越低,输出越稳定
)
# 创建总结链并执行
summary_chain = LLMChain(llm=llm, prompt=prompt)
summary = summary_chain.run({"summary_type": summary_type, "text": text})
return summary
# 3. 端到端执行
if __name__ == "__main__":
audio_path = "customer_interview.mp3"
# 语音转文字
transcript = speech_to_text(audio_path)
print("转录文本:\n", transcript)
# 文字总结(客户访谈场景)
summary = text_summarize(transcript, summary_type="客户访谈纪要")
print("\n总结结果:\n", summary)
# 保存结果
with open("interview_summary.md", "w", encoding="utf-8") as f:
f.write(f"# 客户访谈转录文本\n{transcript}\n\n# 客户访谈纪要\n{summary}")
2. 优化技巧
- Prompt 工程:根据场景细化模板,例如 “客服录音总结” 需添加 “提取客户投诉类型、客服解决方案、是否需要升级处理”;
- 多轮总结:对于超长文本(如 1 小时会议),先分段总结,再合并各段结果二次总结,避免信息丢失:
python
运行
def multi_round_summarize(long_text, chunk_size=1000): # 文本分段 chunks = [long_text[i:i+chunk_size] for i in range(0, len(long_text), chunk_size)] # 分段总结 chunk_summaries = [text_summarize(chunk) for chunk in chunks] # 合并总结 merged_summary = text_summarize("\n".join(chunk_summaries), summary_type="合并总结") return merged_summary - 结果校验:添加 “摘要完整性检查”,用 LLM 验证摘要是否覆盖原文核心信息:
python
运行
def check_summary_completeness(original_text, summary): check_prompt = """ 请判断以下摘要是否完整覆盖了原文的核心信息(核心信息包括:关键人物、核心观点、行动项): 原文:{original_text} 摘要:{summary} 输出格式:1. 完整性评分(1-10分);2. 缺失的核心信息(若有)。 """ check_chain = LLMChain(llm=llm, prompt=PromptTemplate(input_variables=["original_text", "summary"], template=check_prompt)) return check_chain.run({"original_text": original_text, "summary": summary})
三、Prompt 工程:提升 AI 文字总结质量的关键
Prompt 是连接用户需求与 AI 模型的 “桥梁”,好的 Prompt 能引导模型生成更精准、更符合场景的总结。本节将拆解 Prompt 设计原则,提供多场景 Prompt 示例,并通过对比实验展示优化效果。
3.1 Prompt 设计核心原则
- 明确场景与角色:告知模型 “你是谁”“要处理什么场景”(如 “你是电商客服总结助手,处理客户售后录音的文字总结”);
- 定义输出结构:指定总结的格式(如 “分点列出客户问题、解决方案、未解决事项”),避免模型输出混乱;
- 补充约束条件:明确 “不能做什么”(如 “不遗漏客户提到的订单号、退款金额”)、“输出风格”(如 “简洁、正式,无口语化表达”);
- 提供示例(少样本 Prompt):对于复杂场景,先给 1 个 “输入 - 输出” 示例,让模型理解预期结果。
3.2 多场景 Prompt 示例
场景 1:会议纪要总结
plaintext
角色:你是专业的会议纪要助手,负责提炼会议核心信息。
任务:基于以下会议转录文本,生成结构化会议纪要。
输出结构:
1. 会议基本信息:时间、参与人、会议主题;
2. 核心议题与结论(分点,每个议题对应1个结论);
3. 行动项(包含:任务内容、负责人、截止时间);
4. 待跟进问题(需明确下次讨论时间)。
约束条件:
- 行动项需提取原文中明确提到的负责人和时间,不虚构信息;
- 语言简洁,每个分点不超过30字;
- 标注关键数据(如“预算100万”“完成率80%”)。
会议转录文本:
“主持人:今天是2024年5月20日,我们开产品迭代会议,参会的有产品部李明、技术部张伟、运营部王芳。会议主题是V2.0版本功能规划。
李明:第一个议题,用户反馈的“登录卡顿”问题,技术部能在6月10日前修复吗?
张伟:可以,我们会安排2名工程师专项处理,6月10日上线修复版本。
李明:好,结论是“6月10日前修复登录卡顿问题”。第二个议题,V2.0新增“智能推荐”功能,运营部需要在5月30日前提供用户标签数据。
王芳:没问题,我们已经在整理数据,5月30日前会同步给技术部。
李明:行动项就是“王芳(运营部)5月30日前提供用户标签数据”。最后,待跟进的是“智能推荐功能的预算审批”,下次会议(5月27日)讨论。”
场景 2:客服投诉录音总结
plaintext
角色:你是电商平台的客服总结专员,负责分析客户投诉内容,为后续处理提供依据。
任务:基于客服录音转录文本,生成投诉处理摘要。
输出结构:
1. 客户信息:姓名、订单号、联系方式(从文本中提取);
2. 投诉类型(如“物流延迟”“商品质量”“退款失败”);
3. 投诉详情(客户描述的问题、诉求);
4. 客服解决方案(原文中客服承诺的处理方式);
5. 风险等级(高/中/低:高=客户威胁投诉至监管部门,中=多次沟通未解决,低=首次投诉且问题明确)。
约束条件:
- 必须提取订单号、退款金额等关键信息,不遗漏;
- 投诉类型需从给定选项中选择,不自定义;
- 风险等级需说明判断依据(如“高风险:客户提到‘向12315投诉’”)。
转录文本:
“客服:您好,请问有什么可以帮您?
客户:我是张三,订单号是2024052012345,手机号138xxxx1234。我5月15日买的冰箱,现在还没发货,我已经催了3次了,你们再不发货我就去12315投诉!
客服:非常抱歉,张先生,您的订单因仓库缺货延迟了,我们会在5月22日前安排发货,并补偿50元优惠券,您看可以吗?
客户:可以,但必须在22日前发,不然我还是要投诉。”
场景 3:学术讲座总结
plaintext
角色:你是高校科研助理,负责将学术讲座内容总结为科研笔记。
任务:基于讲座转录文本,生成学术总结。
输出结构:
1. 讲座基本信息:主讲人、单位、讲座主题、核心研究领域;
2. 研究背景(为什么做这个研究,现有研究的不足);
3. 核心方法(研究采用的技术路线、实验设计);
4. 关键结果(实验数据、结论,标注统计显著性);
5. 未来展望(主讲人提到的下一步研究方向)。
约束条件:
- 保留专业术语(如“Transformer模型”“P值<0.05”),不简化;
- 关键结果需注明数据来源(如“实验数据集为ImageNet”);
- 未来展望需区分“确定计划”和“可能方向”。
转录文本:
“主讲人:李教授,清华大学计算机系,研究方向是计算机视觉。今天讲座主题是‘基于Transformer的图像分割技术’。
李教授:研究背景是传统CNN模型在处理长距离依赖时效果差,比如分割复杂场景的物体边缘时准确率低(现有方法平均IoU仅75%)。
我们提出的方法是:用Transformer的注意力机制捕捉全局特征,结合U-Net的编码器-解码器结构,在实验数据集COCO上进行训练。
关键结果:该方法的IoU达到89%,P值<0.01,比现有方法提升14个百分点。
未来展望:确定计划是将方法应用到医学图像分割(如CT肿瘤分割),可能方向是探索多模态数据融合(图像+文本)。”
3.3 Prompt 优化效果对比
以 “会议纪要总结” 为例,对比 “基础 Prompt” 与 “优化后 Prompt” 的输出差异:
| 评估维度 | 基础 Prompt 输出 | 优化后 Prompt 输出 |
|---|---|---|
| 结构完整性 | 仅罗列 “会议内容:今天开会讨论了登录卡顿和智能推荐,李明、张伟、王芳参加”,无行动项和待跟进问题 | 完整包含 “会议基本信息、核心议题与结论、行动项、待跟进问题”4 个模块 |
| 关键信息准确性 | 未提及 “6 月 10 日”“5 月 30 日” 等时间,行动项无负责人 | 行动项明确标注 “王芳(运营部)5 月 30 日前提供用户标签数据” |
| 可读性 | 大段文字,无分段,关键数据未高亮 | 分点清晰,关键时间、负责人用加粗标注 |
| 实用性 | 无法直接用于后续工作跟进 | 可直接作为团队任务清单,待跟进问题明确下次讨论时间 |
四、多行业实战应用案例
AI 语音文字总结已广泛应用于企业管理、教育培训、医疗健康、法律金融等领域,本节通过 “场景痛点 + 解决方案 + 工具选择 + 实施效果” 的结构,提供可复用的落地方案。
4.1 企业管理:会议纪要自动化
场景痛点
- 传统会议纪要需专人记录,耗时 1-2 小时(如 1 小时会议,整理纪要需 1.5 小时);
- 人工记录易遗漏关键信息(如行动项负责人、截止时间);
- 跨部门协作时,会议内容传递不及时,导致执行偏差。
解决方案
工具组合:Zoom(会议录音)+ Whisper(ASR)+ ChatGLM(总结)+ 飞书多维表格(协同管理)实施步骤:
- 会议前:在 Zoom 中开启 “云录制”,选择 “录制音频 + 视频”,确保麦克风收音清晰;
- 会议中:主持人每讨论完一个议题,用 “关键词标记”(如 “行动项:张三 - 6 月 10 日”),便于后续定位;
- 会议后:
- 下载 Zoom 录音文件(MP3 格式),用 Whisper 转录为文本(代码见 2.3.1);
- 用优化后的 “会议纪要 Prompt”(见 3.2.1)生成结构化纪要;
- 将纪要导入飞书多维表格,添加 “任务状态”(待开始 / 进行中 / 已完成)字段,分享给参会人;
- 跟进阶段:团队成员更新任务状态,系统自动发送 “逾期提醒”(通过飞书机器人)。
实施效果
- 效率提升:会议纪要生成时间从 1.5 小时缩短至 10 分钟,节省 89% 时间;
- 准确率提升:行动项遗漏率从 25% 降至 3%(通过 AI 提取,避免人工疏忽);
- 协作效率:跨部门任务跟进周期从 7 天缩短至 4 天,因信息传递偏差导致的返工率下降 40%。
可视化:会议纪要流程与数据统计
gantt
title 会议纪要自动化流程时间对比
dateFormat HH:mm
section 传统流程
会议记录 :a1, 10:00, 60min
整理纪要 :a2, after a1, 90min
分发确认 :a3, after a2, 30min
section AI流程
会议录音 :b1, 10:00, 60min
语音转文字 :b2, after b1, 5min
AI生成纪要 :b3, after b2, 5min
分发确认 :b4, after b3, 10min

pie
title 会议纪要关键信息提取准确率对比
“传统人工” : 75
“AI+Prompt” : 97
4.2 教育培训:课程笔记与考点总结
场景痛点
- 学生听课需边记笔记边听讲,易错过老师讲解的重点;
- 课程录音 / 直播回放内容冗长(如 45 分钟课程,完整回放需 45 分钟),复习效率低;
- 不同学生对考点的理解差异大,笔记质量参差不齐。
解决方案
工具组合:腾讯会议(课程直播)+ 讯飞听见(实时转写)+ GPT-4(考点总结)+ Notion(笔记管理)实施步骤:
- 课程前:老师在腾讯会议中开启 “讯飞听见实时转写”,设置 “转写语言” 为 “中文 + 专业术语(如数学 / 物理)”;
- 课程中:学生专注听讲,系统自动生成带时间戳的转录文本,老师可实时标注 “考点”(如在转录文本中标记 “★重点:牛顿第二定律公式”);
- 课程后:
- 导出转录文本,用 GPT-4 Prompt 生成 “课程笔记 + 考点总结”(Prompt 示例见 3.2.3);
- 将笔记导入 Notion,按 “章节 - 知识点 - 考点” 分类整理,添加 “例题链接”“易错点提醒”;
- 学生根据时间戳回听重点片段(如点击 “牛顿第二定律” 对应的时间戳,直接跳转至老师讲解该知识点的片段)。
实施效果
- 学习效率:学生复习时间从 45 分钟(完整回放)缩短至 10 分钟(考点总结 + 重点回听);
- 考点掌握率:通过 AI 总结考点,学生考试中对重点知识点的得分率提升 30%;
- 笔记质量:班级笔记平均分从 65 分(人工笔记)提升至 88 分(AI 辅助笔记),差异度从 40% 降至 15%。
4.3 医疗健康:问诊录音总结与病历生成
场景痛点
- 医生问诊时需边记录病历边与患者沟通,延长问诊时间(平均每患者问诊时间从 15 分钟增至 20 分钟);
- 人工病历易出现字迹潦草、信息遗漏(如患者过敏史、既往病史);
- 病历归档后,难以快速提取关键信息(如 “患者主要症状”“用药方案”)。
解决方案
工具组合:医疗专用录音笔(符合 HIPAA 隐私规范)+ 阿里健康 ASR(医疗领域优化)+ 医疗大模型(如 “医联 AI”)+ 电子病历系统(EMR)实施步骤:
- 问诊前:医生开启医疗录音笔,选择 “问诊模式”(自动降噪,屏蔽诊室环境噪音);
- 问诊中:系统实时转录对话,自动识别医疗术语(如 “高血压 1 级”“阿司匹林过敏”),避免错译;
- 问诊后:
- 医疗大模型基于转录文本生成 “结构化病历”,包含 “患者基本信息、主诉、现病史、既往史、用药建议”;
- 医生仅需核对病历信息(约 2 分钟),确认无误后自动同步至医院 EMR 系统;
- 系统提取 “关键指标”(如 “血压 140/90mmHg”“血糖 7.2mmol/L”),生成 “患者健康档案”,用于后续随访。
实施效果
- 问诊效率:医生每患者问诊时间从 20 分钟缩短至 15 分钟,日接诊量提升 33%;
- 病历准确性:医疗术语错译率从 8% 降至 1.2%,过敏史、既往病史遗漏率从 12% 降至 0.5%;
- 随访效率:护士随访时可直接查看 AI 提取的 “关键指标”,随访准备时间从 10 分钟缩短至 3 分钟。
合规性说明
- 录音设备需符合《个人信息保护法》,明确告知患者 “录音用于病历生成”,获取患者同意;
- ASR 与总结模型需通过医疗行业认证(如 NMPA 认证),确保数据隐私与模型准确性;
- 电子病历需加密存储,仅授权医护人员访问,避免数据泄露。
4.4 法律金融:客户访谈录音与合同要点总结
场景痛点
- 律师 / 金融顾问与客户访谈时,需记录大量信息(如客户需求、风险偏好、合同条款),易遗漏关键细节;
- 人工整理访谈纪要需 2-3 小时(如 1 小时访谈),影响服务效率;
- 合同条款复杂,客户难以快速理解核心权利义务,增加沟通成本。
解决方案
工具组合:钉钉(访谈录音)+ 百度智能云 ASR(法律金融领域优化)+ 通义千问(要点总结)+ 企业微信(文件分享)实施步骤:
- 访谈前:在钉钉中开启 “访谈录音”,设置 “领域” 为 “法律合同” 或 “金融理财”,加载专业术语库;
- 访谈中:系统实时转写,自动标记 “关键条款”(如 “违约金比例”“理财产品风险等级”);
- 访谈后:
- 用百度智能云 ASR 生成带法律 / 金融术语标注的转录文本;
- 用通义千问生成 “访谈纪要 + 合同要点总结”,明确 “客户需求、核心条款、风险提示”;
- 将总结发送至客户企业微信,客户可快速查看核心信息,减少沟通次数。
实施效果
- 服务效率:访谈纪要整理时间从 2.5 小时缩短至 15 分钟,顾问日服务客户数提升 50%;
- 风险控制:合同条款遗漏率从 15% 降至 2%,因信息误解导致的客户投诉率下降 60%;
- 客户满意度:客户对 “服务响应速度” 的评分从 3.2 分(5 分制)提升至 4.8 分。
五、常见问题与解决方案
在 AI 语音文字总结的实际应用中,常遇到 “识别准确率低”“总结不符合需求”“数据隐私风险” 等问题,本节提供针对性解决方案与避坑指南。
5.1 语音识别准确率低
常见原因与解决方案
| 问题原因 | 解决方案 | 操作示例 |
|---|---|---|
| 环境噪音大(如户外、会议室多人说话) | 1. 前置降噪:用 Audacity(免费音频工具)去除噪音2. 选择带降噪功能的 ASR 模型(如讯飞听见 “降噪模式”) | Audacity 操作:导入音频→选中噪音片段→“效果 - 降噪”→应用到全音频 |
| 方言 / 口音重(如四川话、广东话) | 1. 选择支持方言的 ASR 工具(如讯飞听见支持 12 种方言)2. 用方言语料微调模型(开发者方案) | 讯飞听见设置:上传音频时选择 “识别语言 - 四川话” |
| 专业术语多(如医疗 “CT 造影”、法律 “留置权”) | 1. 自定义术语库(如腾讯云智服 “术语管理” 添加词汇)2. 使用领域优化模型(如阿里健康医疗 ASR) | 腾讯云智服:“控制台 - 术语库 - 添加术语‘留置权’=‘法律中的留置权’” |
| 音频格式不兼容(如低采样率、多声道) | 1. 用 ffmpeg 转换为标准格式(16kHz、单声道、WAV)2. 选择支持多格式的工具(如 Whisper 支持 MP3/WAV/M4A) | ffmpeg 命令:ffmpeg -i input.mp3 -ar 16000 -ac 1 output.wav |
5.2 文字总结不符合需求
常见原因与解决方案
| 问题原因 | 解决方案 | 操作示例 |
|---|---|---|
| 总结过于简略,遗漏核心信息 | 1. 在 Prompt 中添加 “需覆盖的核心模块”(如 “必须包含行动项、负责人”)2. 采用 “提取式 + 生成式” 结合的总结方式 | Prompt 优化:“总结需包含:1. 客户需求;2. 解决方案;3. 费用预算,缺一不可” |
| 总结逻辑混乱,无结构化 | 1. 明确输出格式(如 “分点列出,每点以‘标题:内容’形式呈现”)2. 提供少样本示例(给 1 个正确的总结模板) | 少样本 Prompt:“示例:1. 会议主题:V2.0 版本规划;2. 行动项:张三 - 6 月 10 日修复卡顿。请按此格式总结” |
| 专业信息错误(如医疗术语错用) | 1. 使用领域专用模型(如医疗用 “医联 AI”,法律用 “北大法宝 AI”)2. 在 Prompt 中添加 “专业术语校验” 要求 | Prompt 添加:“总结中的医疗术语需符合《临床诊疗指南》,如‘高血压’不可简写为‘高血’” |
5.3 数据隐私与安全风险
常见风险与解决方案
| 风险类型 | 解决方案 | 合规依据 |
|---|---|---|
| 音频 / 文本数据泄露 | 1. 本地部署模型(如 Whisper、ChatGLM 本地运行,不上传云端)2. 选择合规云服务商(如阿里云 / 腾讯云,符合等保三级) | 《个人信息保护法》第 10 条:处理个人信息需采取安全保护措施 |
| 未获取用户同意 | 1. 访谈前告知用户 “录音用于 AI 总结,仅内部使用”2. 让用户签署《数据使用同意书》 | 《个人信息保护法》第 13 条:处理个人信息需取得个人同意 |
| 模型输出违规内容 | 1. 添加内容过滤机制(如关键词拦截、敏感信息检测)2. 定期审核模型输出结果,优化过滤规则 | 《生成式人工智能服务管理暂行办法》第 7 条:生成内容需符合法律法规 |
六、未来发展趋势
随着 AI 技术的不断演进,语音文字总结将向 “更精准、更智能、更场景化” 方向发展,未来主要趋势包括:
- 多模态融合总结:结合语音(语气、语速)、视频(表情、动作)、文本信息,生成更全面的总结(如 “客户说‘满意’时,语气犹豫,需进一步跟进”);
- 实时交互式总结:会议 / 访谈过程中,AI 实时生成总结并主动提问 “是否需要补充行动项”,用户可实时修正,无需等待结束后再处理;
- 个性化总结:根据用户角色自动调整总结侧重点(如给老板的总结侧重 “结论 + 数据”,给执行层的总结侧重 “行动项 + 时间”);
- 低代码 / 无代码平台普及:非技术用户可通过拖拽组件搭建 “语音→总结→应用” 流程(如 “录音→总结→自动同步至 Excel”),降低使用门槛。
结语
AI 语音文字总结技术已从 “实验室” 走向 “产业落地”,成为提升信息处理效率的核心工具。无论是个人用户的课程笔记、企业的会议纪要,还是医疗、法律等专业领域的文档生成,该技术都能显著降低人工成本、提升信息价值提取效率。
掌握工具使用技巧、优化 Prompt 设计、结合场景选择合适的解决方案,是实现技术价值最大化的关键。未来,随着模型准确率的提升与应用场景的深化,AI 语音文字总结将成为每个人、每个企业的 “信息处理助手”,推动数字化转型向更高效、更智能的方向发展。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献141条内容
已为社区贡献141条内容

所有评论(0)