自动驾驶大模型---小米&华科之DriveMonkey大模型
本文介绍了一种基于大型视觉语言模型(LVLM)的自动驾驶多任务交互框架DriveMonkey。该研究由小米汽车与华中科技大学联合开发,通过增强LVLM的时空推理能力、引入交互提示工程和多任务适应策略,解决了现有模型在动态场景理解、任务多样性处理和实时性等方面的不足。DriveMonkey结合类LLaVA架构的多模态大语言模型与3D空间处理器,有效整合了文本与视觉信息。实验结果表明,该框架在区域描述
1 前言
关于大模型的博客,笔者分为了两个系列:车企量产 + 科研论文。希望有兴趣的朋友能够从笔者的大模型博客系列当中收获一些知识或者idea。
车企量产:
科研论文:
本篇博客介绍一篇论文,将大型视觉语言模型(LVLM)扩展到自动驾驶多交互任务的框架。该研究通过增强 LVLM 的时空推理能力、引入交互提示工程和多任务适应策略,使模型能够处理自动驾驶中的多种复杂场景。
作者是小米汽车和华中科技大学,看来小米和华科在自动驾驶领域有着深度的合作,近两年发表了多篇论文。笔者还是比较鼓励校企合作的形式,能够弥补各自的缺点(学校的学术能力+企业的工程能力),一般都会取得不错的成果。
2 DriveMonkey
大型视觉语言模型(如 GPT-4V、Gemini-V)在通用场景理解上表现出色,但直接应用于自动驾驶存在以下挑战:
- 时空推理不足:自动驾驶需要理解连续帧中的动态变化(如车辆运动、行人轨迹)。
- 任务多样性:需同时处理目标检测、轨迹预测、决策解释等多种任务。
- 实时性要求:LVLM 的推理速度通常较慢,难以满足自动驾驶的实时性需求。
- 安全关键:决策需具有可解释性和高可靠性。
2.1 方法框架
该模型首先将输入的指令提示(instruction prompts)和多视角图像(multi-view images)编码为嵌入向量(embeddings)。这些嵌入向量与一组可学习查询(learnable queries)被输入至大型语言模型(LLM,Large Language Model)中,其输出的文本令牌(text tokens)用于生成相关联的语言输出。
空间解码器(spatial decoder)会接收来自空间编码器(spatial encoder)的空间特征,同时结合经 LLM 处理后的可学习查询,最终实现对相应 3D 目标位置的检测。
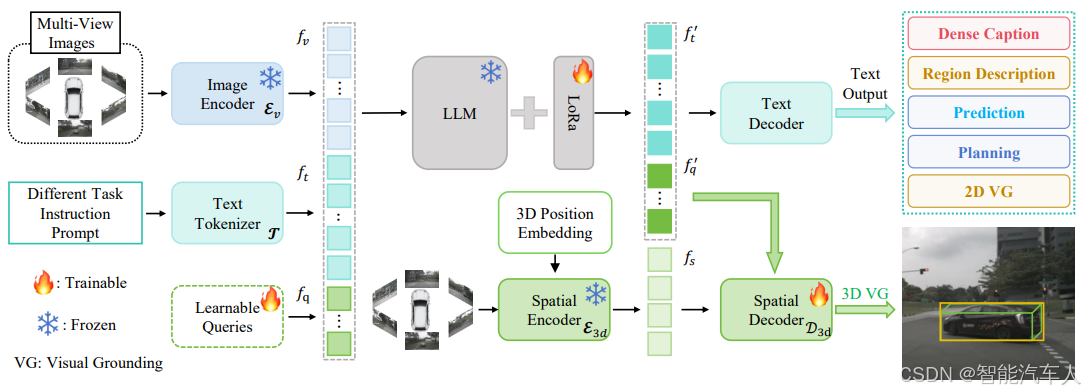
DriveMonkey 的整体架构如上图所示,主要包含两部分:类 LLaVA 架构的多模态大语言模型(LVLM,Language-Vision Large Model),以及带有编码器(encoder)和解码器(decoder)的空间处理器(spatial processor)。
(1)预训练多模态大语言模型(Pre-trained LVLMs)
我们采用预训练的类 LLaVA 模型作为多模态大语言模型(LVLM),该模型由图像编码器(Ev,image encoder)、投影器(P,projector)和大型语言模型(LLM,Large Language Model)三部分构成。给定多视角图像(multi-view images)后,这些图像首先经过图像编码器处理,再通过投影器映射到语言空间,最终生成多视角特征(multi-view features)。
(2)空间处理器(Spatial Processor)
主流的多模态大语言模型(LVLM)由于缺乏 3D 先验输入(例如深度、偏航角信息),往往难以从多视角图像中感知 3D 空间信息。与之相反,基于相机的 3D 目标检测器展现出了强大的多视角图像 3D 感知能力,能够生成精准的 3D 边界框,但无法处理文本输入以完成 3D 视觉 - 语言(3D VG,3D Visual Grounding)任务。
为解决这一局限,提出的 DriveMonkey 将 3D 检测器整合为空间处理器,以提供 3D 空间先验,并将其与大型语言模型(LLM)相结合。具体而言,采用 3D 目标检测器的图像主干网络(image backbone)和位置编码器(position encoder)作为空间编码器(E3d),同时将其目标解码器(object decoder)用作空间解码器(D3d)。此外,引入一组可学习查询(fq,learnable queries),作为 3D 检测器与 LLM 之间的 “通信桥梁”。
不同于专业检测器将可学习查询直接输入目标解码器的设计,首先在 LLM 内部对这些查询进行更新(以累积文本信息),再通过一个两层的多层感知机(MLP,Multi-Layer Perceptron)将更新后的查询映射到空间解码器的特征空间中。该技术不仅构建了高效的通信桥梁,还促进了多模态大语言模型(LVLM)与空间处理器之间的信息传递。
2.2 实验结果
(1)实验环境与参数
所有实验均在 8 台配备 80GB 显存的 NVIDIA A800 GPU 上进行,以 InternVL2-8B 作为主要基准模型(baseline)。具体参数设置如下:
- 输入预处理:图像在进入图像编码器处理前,均调整为 448×448 像素,以保证尺寸一致性。
- 空间处理器初始化:除非另有说明,空间处理器由预训练模型 PETR 初始化,并通过 30 个可学习查询(即 Q = 30)与多模态大语言模型(LVLM)连接。
- 训练阶段参数:
- 第一阶段:训练 1 个轮次(epoch),总批次大小(batch size)为 256;采用 AdamW [99] 作为优化器,权重衰减(weight decay)设为 0.1;学习率调度器采用余弦退火(cosine annealing)策略,最大学习率为 2×10⁻⁵。
- 第二阶段:同样训练 1 个轮次,总批次大小为 128;使用与第一阶段相同的优化器,峰值学习率为 4×10⁻⁵;对大型语言模型(LLM)进行微调时,设置 LoRA(低秩适应)的秩(rank)为 128,alpha 值为 256。
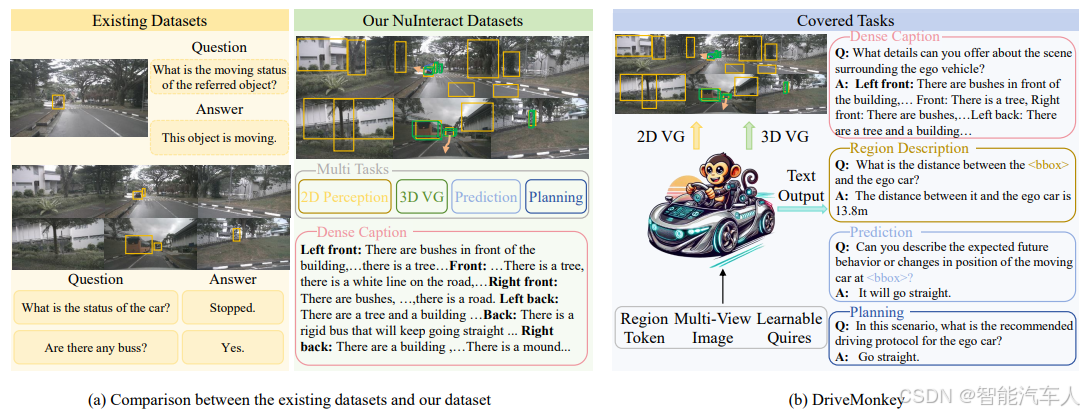
(2)数据集说明
- NuInteract 测试集
该数据集是评估 DriveMonkey 的主要数据集,基于第三节 A 部分(Sec. III-A)提出的数据生成流程,从 nuScenes 验证集中构建得到。
- DriveLM-nuScenes 数据集
为验证模型密集型描述(dense caption)功能的有效性,额外采用 DriveLM-nuScenes 数据集。
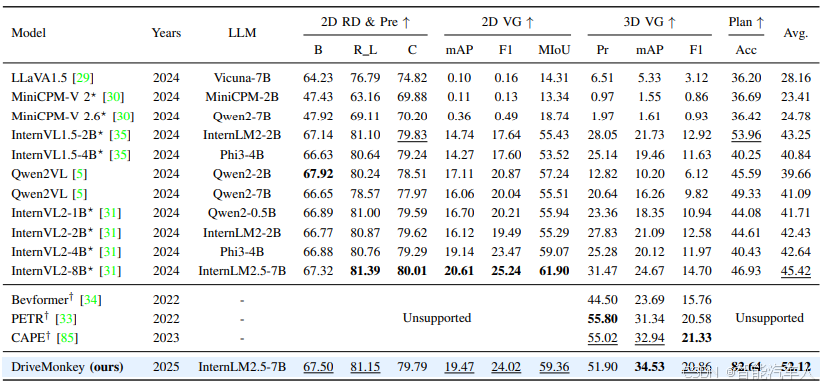
(3)实验结果
表中的英文简写如下所示:
- RD:区域描述(Region Description)
- Pre:预测(Prediction)
- VG:视觉 - 语言定位(Visual Grounding)
- Plan:规划(Planning)
- B:BLEU(机器翻译与文本生成领域常用的评估指标,用于衡量生成文本与参考文本的相似度)
- R L:ROUGE-L(文本摘要与生成领域评估指标,基于最长公共子序列衡量文本相似度)
- C:CIDER(图像描述生成领域评估指标,侧重捕捉文本的语义一致性)
- Pr:精度(Precision,分类与检测任务中衡量预测准确性的指标)
- Acc:准确率(Accuracy,衡量模型整体预测正确的比例)
3 总结
该研究通过扩展 LVLM 的时空推理能力、设计任务自适应架构和交互提示工程,成功将大型视觉语言模型应用于自动驾驶的多种交互任务。实验结果表明,模型在检测、预测和解释任务上均取得显著提升,为人机协作的自动驾驶系统提供了新的解决方案。
参考文献: 《Extending Large Vision-Language Model for Diverse Interactive Tasks in Autonomous Driving》

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)