【论文阅读】WebSailor: Navigating Super-human Reasoning for Web Agent
当人类面对浩如烟海的互联网信息时,我们总会被有限的记忆、短暂的注意力和串行搜索路径所束缚。OpenAI 的 DeepResearch 之所以被称为"超人",正因为它突破了这些生理天花板,在 BrowseComp 等极限基准上取得碾压式领先。问题是:开源社区能否复制这种"超级推理"?阿里巴巴通义实验室的最新力作 WebSailor 给出了响亮回答
https://arxiv.org/pdf/2507.02592
【导读】
当人类面对浩如烟海的互联网信息时,我们总会被有限的记忆、短暂的注意力和串行搜索路径所束缚。OpenAI 的 DeepResearch 之所以被称为"超人",正因为它突破了这些生理天花板,在 BrowseComp 等极限基准上取得碾压式领先。问题是:开源社区能否复制这种"超级推理"?
阿里巴巴通义实验室的最新力作 WebSailor 给出了响亮回答。团队首次把"不确定性消减"拆解为可训练的算法组件,通过三大创新让 3B~72B 开源模型集体逆袭:
- SailorFog-QA——用随机游走+信息掩码,自动合成 Level-3 级"超高不确定"任务,让模型在训练场就直面真实世界的混沌;
- 专家轨迹重构——用 QwQ、DeepSeek-R1 等开源强模型"打样",却只保留其工具调用骨架,再让轻量级模型重写简洁思考,兼顾效果与长度;
- DUPO 强化学习——提出"重复采样+组内优势估计"策略,训练速度提升 2~3 倍,在 50 步内即可稳定收敛。
结果如何?WebSailor-72B 在 BrowseComp-zh 上以 30.1% 的准确率追平字节跳动闭源产品豆包,把最强开源竞品直接拉开 15 个点;3B 小模型也能越级打平 32B 对手,真正做到了"参数小、推理大"。更难能可贵的是,它向下兼容 SimpleQA、GAIA 等简单任务,实现"一套权重打全场"。
这篇 论文不仅刷新了三项 SOTA,更给出了完整可复现的代码、数据与训练脚本,为开源社区打开了"超级网络智能体"的大门。如果你想让自己的模型也能像 DeepResearch 一样"翻遍全网找答案",或者想了解强化学习+工具调用如何擦出火花,这篇必读文章将带你拆解每一行关键公式、每一次工具调用背后的思考逻辑。
WebSailor: 为网络代理导航超人类推理
Kuan Li*, Zhongwang Zhang*, Huifeng Yin*(✉), Liwen Zhang*, Liu Ou*, Jialong Wu, Wenbiao Yin, Baixuan Li, Zhengwei Tao, Xinyu Wang, Weizhou Shen, Junkai Zhang, Dingchu Zhang, Xixi Wu, Yong Jiang(✉), Ming Yan, Pengjun Xie, Fei Huang, Jingren Zhou
Tongyi Lab G \mathfrak{G} G libaba Group
https://github.com/Alibaba- NLP/WebAgent
摘要
超越人类认知局限代表了LLM训练中的一个关键前沿。像DeepResearch这样的专有代理系统在极其复杂的寻信息基准测试(如BrowseComp)上展示了超人类能力,这是以前无法达到的成就。我们假设他们的成功依赖于开源模型中不存在的一种复杂推理模式:在导航广阔信息景观时系统地减少极端不确定性。基于这一见解,我们介绍了WebSailor,这是一种完整的后训练方法论,旨在培养这种关键能力。我们的方法通过结构化采样和信息模糊化、RFT冷启动以及高效的代理RL训练算法(复制采样策略优化,DUPO)生成新的高不确定性任务。通过这个集成流程,WebSailor在复杂的寻信息任务中显著优于所有开源代理,匹配专有代理的性能并缩小了能力差距。
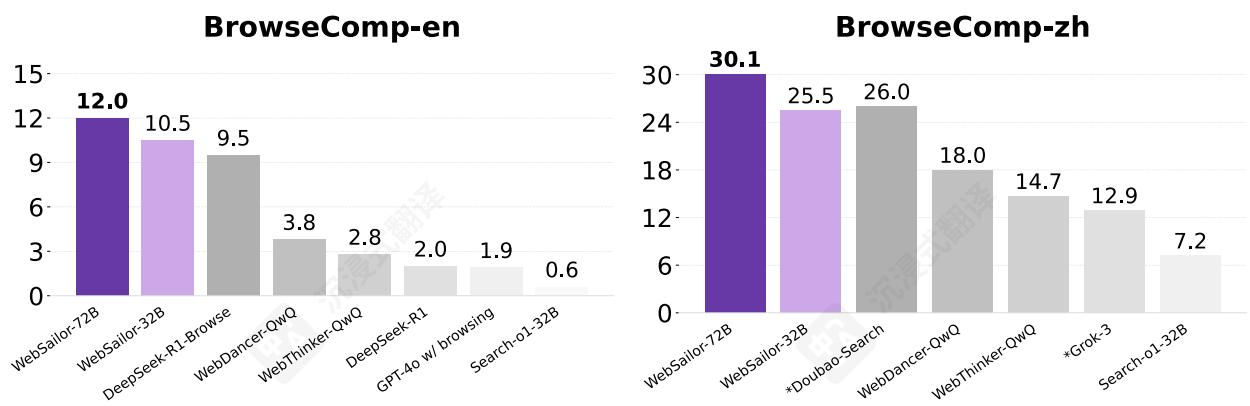
图1:在BrowseComp-en/zh基准测试上的性能。DeepSeek-R1-Browse是DeepSeek-R1通过ReAct框架配备的浏览工具,与我们的模型WebSailor共享相同的实现。Doubao-Search和Grok-3是专有的基于网络的产品(标记为*)。GPT-4o带浏览功能的结果来自OpenAI的官方出版物。
1简介
信息寻求,人类解决不确定性的基本驱动力,已经被互联网彻底改变(Wilson,1999;Jurado等人,2015)。然而,人类在导航这个庞大的数字世界时受到认知限制的束缚:有限的记忆、脆弱的注意力,以及在并行追求多条探索路径方面的无能。领先的专有代理系统,如Deep Research(OpenAI,2025a),表明大型语言模型(LLM)代理可以超越这些人类限制。它们在BrowseComp- en/zh等复杂网络基准测试上的超人类表现源于复杂的推理——内部或工具介导的——这种推理系统地将不确定性减少(Kapoor等人,2024;Huang等人,2023)。
然而,将这些高级推理能力植入开源代理仍然是一个未解决的问题。如图1所示,现有的开源LLM和网络代理在BrowseComp- en(Wu等人,2025a;Li等人,2025c;b;Song等人,2025)上的准确率接近于零。这种显著的性能差距是因为当前的训练范式专注于我们分类为1级和2级的任务:具有低不确定性(例如,单次搜索)或具有清晰、结构化解决路径的问题(例如,标准多跳问答)。这些数据集没有让模型接触到主导复杂基准的3级挑战——需要在没有预定义解决方案路径的复杂信息景观中要求强大的组合泛化(Wiedemer等人,2023)的场景。因此,模型无法发展出在它们中导航所需的复杂、多步推理能力。
为了引出这些超人类的推理模式,我们生成具有高且难以减少的内在不确定性的训练数据。我们的主要机制涉及从由随机游走生成的真实世界网站中的互联知识结构中采样子图。从组合泛化的角度来看(Google,2020),这些子图展示了已知实体和关系的新颖组合,迫使模型对以前未见过的组合进行推理,并推动其超越简单的启发式方法。这个过程生成了各种复杂、涌现的结构,这些结构难以预先定义,迫使模型发展出可能超越既定人类模式的推理过程。
我们进一步通过精心设计的信息混淆技术放大任务难度,这直接增加了初始的模糊性。结构复杂性和信息模糊性的结合创造了需要极其复杂的推理的任务。例如,我们生成的一些问题如此具有挑战性,以至于即使是强大的专有模型如c3(OpenAI,2025c)也需要高达40次工具调用才能得出解决方案,突显了所涉及的极端不确定性降低。
在获得问答对后,一个关键挑战是获取完整的监督。虽然像QwQ(Qwen团队,2025)和DeepSeek- R1(Guo等人,2025)这样强大的开源大型推理模型(LRMs)可以解决一些复杂的问答对,但它们的原生推理输出不适用于直接微调。这些模型表现出高度风格化和冗长的推理过程,如果模仿它们,可能会限制训练代理开发自己灵活、探索性策略的能力。此外,在需要几千次工具调用的长时程网络任务中(Li等人,2025a),它们冗长的推理链会迅速淹没上下文窗口,导致性能下降和可读性差(Yin等人,2025)。为了克服这一点,我们提出了一种新方法:我们利用这些开源LRMs生成成功的行动- 观察轨迹,但然后重建推理。通过为每一步推断简洁、以行动为导向的思考,我们创建了一个干净的、有效的监督信号,该信号捕获了解决方案的逻辑,而没有继承风格或冗长性相关的缺点。
在训练过程优化方面,尽管近期研究表明可以跳过SFT(Guo等人,2025;Chen等人,2025;Hu等人,2025),但我们证明,对于需要处理此类复杂任务的网页代理,适度的拒绝采样微调(RFT)冷启动是不可或缺的。一方面,这些场景中的RL奖励非常稀疏,最初往往产生近乎零的反馈。另一方面,我们的方法并不严重依赖蒸馏;仅用超过2k个高质量
的示例进行最小冷启动已被证明是有效的。由于多轮推理和大量工具使用,代理进行此类任务的RL训练速度非常慢。为此,我们提出了复制采样策略优化(DUPO),该策略结合了两个动态采样策略——一个在训练前,一个在训练中——以提高有效性和效率。
我们的WebSailor模型系列(3B、7B、32B和72B)在BrowseComp- en/zh上优于所有开源模型和代理方法,并且在与浏览能力结合时,也超越了Grok- 3(x.ai,2025)和DouBao(Doubao,2025)等专有LRMs,如图1所示。此外,我们发现基于复杂、不确定性驱动的推理模式的训练后改进表现出向下兼容性,在GAIA(Mialon等人,2023)、XBench- DeepSearch(Xbench- Team,2025)和SimpleQA(OpenAI,2025d)等更简单的任务上取得了有前景的性能。
2问题定义
我们采用ReAct(Yao等人,2023)作为代理的框架。在接收到一个问题时,代理执行多次思维- 行动- 观察的迭代。具体来说,在每次迭代中,基于现有上下文,LLM生成一个思维并执行一个可解析的行动(工具调用),然后等待环境返回一个观察。在WebTraverseX中,动作空间包括生成最终答案和两个工具:搜索和访问,分别对应使用多个查询调用搜索引擎和通过URL访问多个网页以检索其内容。这两个工具的详细信息在附录A.1中提供。搜索行动返回的观察包括每个搜索查询的10个标题、片段及其对应的URL。相比之下,访问行动的观察是网页的摘要,针对LLM行动中指定的“目标”进行定制。当LLM选择“最终答案”作为行动时,迭代终止。一个包含T次迭代的完整轨迹可以定义为:
H T = ( τ 0 , a 0 , o 0 , … , τ i , a i , o i , … , τ T , a T ) , (1) \mathcal{H}_T = (\tau_0,a_0,o_0,\ldots ,\tau_i,a_i,o_i,\ldots ,\tau_T,a_T), \tag{1} HT=(τ0,a0,o0,…,τi,ai,oi,…,τT,aT),(1)
在i- 轮中, τ i ∖ a i ∖ o i \tau_{\mathrm{i}}\setminus \mathrm{a}_{\mathrm{i}}\setminus \mathrm{o}_{\mathrm{i}} τi∖ai∖oi 分别代表思想、行动和观察。在步骤t时,从基于所有先前上下文的策略中采样思想 τ i \tau_{i} τi 和 a i \mathrm{a}_{i} ai ,即 π ( a , t ∣ H t − 1 ) \pi (\mathrm{a},\mathrm{t}|\mathcal{H}_{t - 1}) π(a,t∣Ht−1)
完成多跳问答(Yang等人,2018年;Ho等人,2020年)通常只需要一或两轮ReAct,因为每一步的行动非常明确,并不涉及太多战略规划。与此形成鲜明对比的是,BrowseComp将智能体沉浸在一个广阔、非结构化的信息空间中,其中解决方案路径没有预先定义。一种简单、蛮力的搜索在计算上不可行,可能需要数千次工具调用,这将使任何现代LLM的上下文窗口不堪重负。因此,成功的关键不在于遵循一个简单的脚本,而在于执行一种高度自适应的搜索策略。智能体必须动态地综合部分信息,修剪没有希望的探索路径,并将不同的事实整合起来以收敛到一个解决方案。将这个组合式巨大的搜索空间压缩成一个由几十个步骤组成的可处理的轨迹需要一条复杂的思维链(Wei等人,2022年)。正是这种战略导航和综合的过程体现了这项工作试图引出和建模的复杂、超人类的推理模式。
3大规模复杂推理训练数据合成
在本节中,我们从两个角度介绍了我们的训练数据构建:QA构建和推理轨迹生成。
3.1SailorFog-QA:可扩展图合成QA
回答一个问题所需的推理模式由其固有的不确定性和降低这种不确定性的复杂性决定。如图2所示,我们根据这两个维度将信息寻求型QA分类为
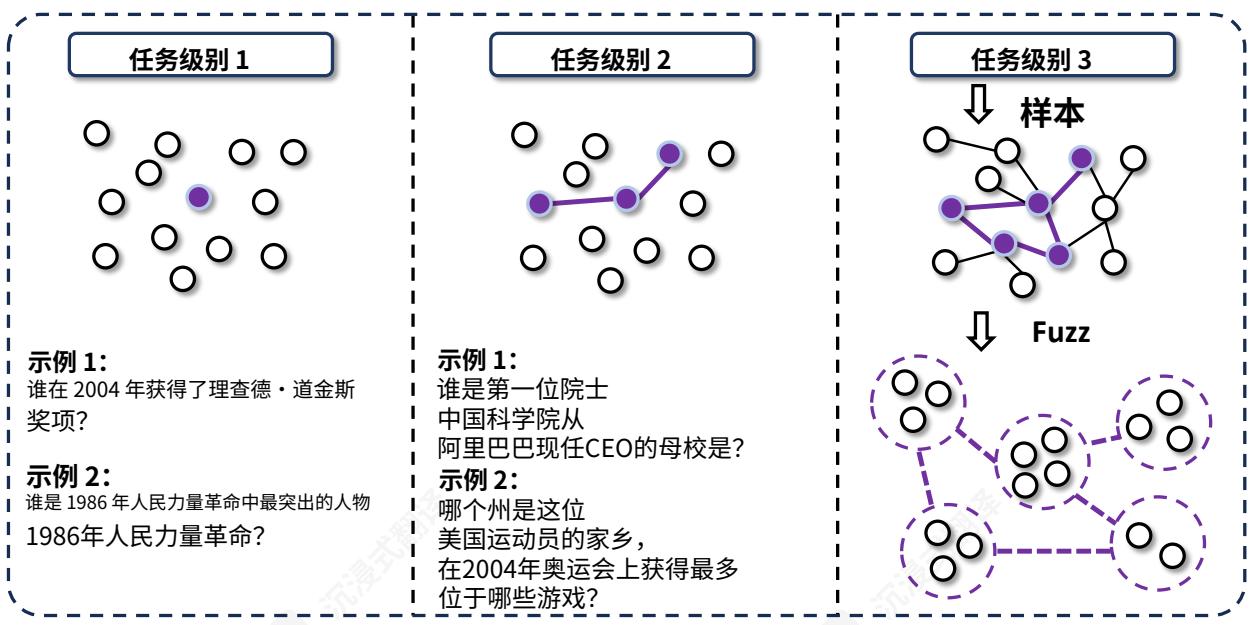
图2:信息获取任务可分为三个级别。级别1具有相对简单的逻辑结构,可以直接回答或通过单个、简单的工具调用回答。级别2类似于多跳问题,解决方案通过固定的推理步骤获得。级别3在模糊化后表现出最复杂和多变的拓扑结构,难以手动定义,其固有不确定性难以减少。
三个等级。
-
级别1:任务具有低不确定性,易于减少。这些包括可通过模型的内部知识或通过单个、简单的网络搜索回答的问题。- 级别2:任务,如多跳问答,具有高初始不确定性,但遵循清晰的解决路径。即使有许多步骤,实体也通过明确定义的逻辑连接,允许通过结构化的行动序列系统地减少不确定性。
-
级别3:我们工作的重点,涉及具有高不确定性和高减少难度的问题。在这里,实体以复杂、涌现的方式耦合,缺乏预定义的推理路径。解决这些问题需要创造性的探索和新的推理模式,这些模式难以手动指定。
构建难以降低不确定性的结构基础为了生成Level3任务,我们首先构建一个复杂的信息景观,其中不确定性本质上难以降低。我们的过程受随机游走启发,构建具有涌现、非线性行结构的知识图谱。我们首先从Wikidata的SPARQL服务中检索一个模糊实体来为图提供种子,以确保一个具有挑战性的起点。通过模拟网络浏览,我们从互联网上收集关于该实体的非结构化文本和特征。从这些原始信息中,我们提取相关实体以及连接它们的实体间关系,形成初始节点和边。关键步骤是迭代扩展:我们概率性地选择现有节点,并寻找新的、不同的实体来连接。这种随机过程抑制了简单的线性链(Level2任务的典型特征),并代之以培养一个密集互联的图,其中包含复杂、重叠的关系路径。生成的图作为缺乏预定义推理路径问题的结构基础,迫使代理在复杂的信息网络中导航,而不是遵循直线。
通过子图采样和混淆生成高不确定性问题以这些复杂的图为基础,我们生成具有高初始不确定性的问题。这是
通过采样具有不同拓扑结构的子图来实现的,每个子图代表一组耦合实体和关系的独特组合。然后我们根据子图制定一个问题和一个答案。关键在于,我们通过故意的信息混淆引入歧义。我们没有呈现清晰的事实,而是混淆了问题中的特征和关系。例如,一个精确的日期被转化为一个模糊的时期(“在2010年代初”),一个名字被部分掩盖(“由一个以‘F’开头的某人创立的机构”),或者一个定量属性被定性描述(“市场份额不到 1 % 1\% 1% )。这种混淆直接增加了初始不确定性,迫使代理进行推理、比较和综合信息,而不是简单地执行查找。我们将我们的合成训练数据命名为SailorFog- QA,它具有三个主要优势:
·数据基于真实世界的互联网,反映了代理在实践中面临的挑战。·不同的子图拓扑结构自然地产生需要一系列复杂推理模式的问题,从多步演绎到组合和比较分析。
·该方法具有高度可扩展性,因为潜在的子图数量——以及因此具有挑战性的问题——随着图的大小呈非线性增长,从而能够实现高效的大规模数据合成。
为了说明我们生成的Level3任务的特性,下面展示了两个示例。这些问题体现了我们的方法论:它们包含多个复杂耦合的实体和故意模糊的信息,例如模糊的时间参考(“大约在5世纪中期”、“21世纪初”)和非特定的描述(“一个著名的南美首都”、“一个受人尊敬的艺术机构”)。这种结构复杂性和信息模糊性的结合产生了高度初始的不确定性,这非常难以减少。事实上,我们的手动评估证实,在典型的时间限制下(例如,在两个小时之内),这些问题对于人类研究人员来说是难以解决的,因为它们缺乏明确的搜索起点,并且需要广泛、非线性的探索。有关我们QA生成过程的更多详细信息,请参阅附录A.2。
生成问题的示例
问题:有一位晚期古典主义作家创作了一首早期的基督教诗歌赞美诗,他死于公元5世纪中期。这位作家的去世之年与一种科学年代学的最后一年相吻合,这种年代学重建了现代时代之前的几个世纪的环境条件。这种年代学的名称是什么?答案:估计的树轮年代学:公元300- 450年。
问题:一首与南美一个著名者都有密切关联的音乐作品,其歌词由一位值得注意的人物创作,这位人物后来在21世纪初获得了一个当地的杰出市政荣誉。这首作品的旋律由一位在哥伦比亚西部一所受人尊敬的艺术机构接受过正规训练的音乐家创作。这首音乐作品的名称是什么?答案:圣日耳曼大道
3.2从专家LRM轨迹中重建推理
在综合了复杂的问答对之后,下一个挑战是为冷启动监督生成相应的解决方案轨迹。虽然像QwQ- 32B(Qwen团队,2025年)这样强大的开源LRM可以提供一些正确的轨迹,但直接使用它们的完整输出进行微调是有害的。我们确定了两个关键问题:
·风格污染:这些LRM在推理中具有强烈且通常长的风格先验。直接在这些输出上进行微调可能过于规定,扼杀代理发展自身探索策略和泛化到未见问题的能力。
·上下文过载:他们推理链的冗长性是复杂网络代理任务的实践性障碍。一个包含几十个工具调用的轨迹很容易生成一个超过上下文限制的历史记录,从而降低性能并使推理过程难以处理。
过程如下:首先,我们提示一个专家开源LRM生成一个完整的解决方案轨迹,包括其原生思考。从这个完整轨迹中,我们选择性地丢弃LRM的原始冗长思考,仅保留成功的行动- 观察序列 ( a 0 , o 0 , a 1 , o 1 , … ) (a_{0},o_{0},a_{1},o_{1},\ldots) (a0,o0,a1,o1,…) 。这个轨迹代表了解决方案路径的“什么”和“如何”,但不是“为什么”。
接下来,我们重构缺失的“原因”。对于行动轨迹中的每一步t,我们拥有直到前一步的历史记录 H t − 1 = ( τ ^ 0 , a 0 , o 0 , … , τ ^ t − 1 , a t − 1 , o t − 1 ) \mathcal{H}_{t - 1} = (\hat{\tau}_0,a_0,o_0,\ldots ,\hat{\tau}_{t - 1},a_{t - 1},o_{t - 1}) Ht−1=(τ^0,a0,o0,…,τ^t−1,at−1,ot−1) ,以及专家选择的行为 a t \mathbf{a}_t at 和后续观察 o t − o_{t - } ot− 。然后,我们提示一个独立的、强大的指令跟随模型 π ∗ \pi^{*} π∗ 生成一个新的思考 π t \pi_t πt ,它作为采取行动 a t \mathbf{a}_t at 的简洁、逻辑性理由:
τ ^ t ∼ π ∗ ( τ ∣ H t − 1 , a t , o t ) . (2) \hat{\tau}_t\sim \pi^* (\tau |\mathcal{H}_{t - 1},a_t,o_t). \tag{2} τ^t∼π∗(τ∣Ht−1,at,ot).(2)
通过迭代地应用于每一步,我们综合出一个完整、高质量的推理轨迹 H ^ T = ( τ ^ 0 , a 0 , o 0 , … , τ ^ T , a T , o T ) \hat{\mathcal{H}}_T = (\hat{\tau}_0,a_0,o_0,\ldots ,\hat{\tau}_T,a_T,o_T) H^T=(τ^0,a0,o0,…,τ^T,aT,oT) ,其中推理清晰且目标导向。对于这种重构,我们使用另一个LLM并强制采用“短- CoT”风格。这是一个关键的设计选择,确保最终的推理链足够紧凑,适用于长时程任务。这种方法使我们能够可扩展地生成监督数据,这些数据能够植入复杂的推理模式,而不会产生直接模仿的负面影响。
4带有冷启动的强化学习
我们的训练方法是一个两阶段过程。受近期在训练后(Chu等人,2025;Swamy等人,2025;Ye等人,2025)的进展的启发,这些进展强调了在更复杂的学习之前进行目标细调的有效性,我们首先采用一个适度的RFT阶段作为“冷启动”。这个初始阶段旨在使模型具备基本的工具使用能力和遵循长期推理骨架。随后,我们利用RL进一步优化代理的推理能力,提高其样本效率(Yue等人,2025),并实现我们高质量、复杂训练数据的更充分利用。
4.1拒绝采样微调
设置在一个完整的轨迹 H T \mathcal{H}_T HT 中,代理的想法 ( τ i ) (\tau_i) (τi) 被和标签包围。动作 ( a i ) (\mathbf{a}_i) (ai) 由<tool_call>和<tool_call>标记函数调用,或由和标记最终响应。工具调用的环境观察结果 ( o i ) (o_i) (oi) 被<tool_response>和<tool_response>标签包裹。不同的片段由这些特殊标记分隔。
过滤我们对专家生成的轨迹应用三阶段过滤过程。首先,为确保监督信号的正确性,我们进行拒绝采样,仅保留以正确最终答案结束的轨迹。其次,考虑到专家模型比我们的策略模型具有更优越的长上下文处理能力,我们丢弃任何超过32ktoken长度的轨迹。第三,我们根据任务复杂度进行过滤,保留那些包含超过5次工具调用的轨迹,因为复杂的推理模式和有效的规划策略通常通过更长的决策步骤序列来体现。
训练目标训练目标是专门提升代理的决策能力——即其生成有效思想和行动的能力。因此,对应于环境观察的token ( o i ) (o_i) (oi) 在损失计算中被掩码处理(Chen et al., 2023)。
4.2复制采样策略优化
在RFT冷启动阶段之后,该模型获得了基本的工具使用能力和遵循推理骨架的能力,我们提出了复制采样策略优化(DUPO)来进一步优化推理能力,提高样本效率(Yue等人,2025年)并最终引出
其内在潜力去发现和内化超越直接模仿的复杂问题解决策略。
代理的强化学习与传统推理任务的主要区别在于,rollout是一个涉及与环境交互(工具响应)的多回合过程(Sun等人,2024)。然而,与标准强化学习相比,代理强化学习的rollout速度要慢得多。DAPO(Yu等人,2025)采用动态采样来过滤掉完全正确或不正确的rollout,随后用新的问答填充批次至目标大小。虽然这对于数据管理很有效,但可能需要同一批次内不同案例的顺序rollout。这种顺序处理进一步加剧了代理强化学习特有的慢训练速度。
为了解决这个问题,我们在训练前首先过滤掉过于简单的案例(所有8个rollout都正确)。在训练期间,我们不使用填充来扩展批次,而是复制同一批次中标准差非零的样本。与DAPO的动态采样相比,这种方法实现了大约2- 3倍的加速。类似于SFT,在计算策略损失时也必须掩码观察值(Jin等人,2025)。我们遵循GPRO(Shao等人,2024)以相对群体的方式估计优势。我们还利用了DAPO中的token级策略梯度损失和更高裁剪技术。DUPO的训练目标定义如下:
I ( θ ) = E ( q , y ) ∼ D r , { o i } i = 1 G ∼ π θ o l d ( ⋅ ∣ c o n t e x t ) [ 1 ∑ i = 1 G ∣ o i ∣ ∑ t = 1 G ∑ i = 1 ∣ o i ∣ min ( r i , t ( θ ) A ^ i , t , c l i p ( r i , t ( θ ) , 1 − ϵ l o w , 1 + ϵ h i g h ) A ^ i , t ) ] s . t . 0 < { 0 i ∣ i s − y y ( y , 0 i ) } ∣ < G , (3) \begin{array}{rl}\mathcal{I}(\theta) = & \mathbb{E}_{(q,y)}\sim \mathcal{D}_{r,\{o_i\}_{i = 1}^G\sim \pi_{\theta_{\mathrm{old}}}(\cdot |context)}\\ & \left[\frac{1}{\sum_{i = 1}^G|o_i|}\sum_{t = 1}^G\sum_{i = 1}^{|o_i|}\min \left(r_{i,t}(\theta)\hat{A}_{i,t},\mathrm{clip}\left(r_{i,t}(\theta),1 - \epsilon_{low},1 + \epsilon_{high}\right)\hat{A}_{i,t}\right)\right]\\ \mathrm{s.t.} & 0< \left\{\mathbf{0}_i|\mathbf{is}_{-}\mathbf{y}\mathbf{y}(\mathbf{y},\mathbf{0}_i)\right\} \qquad \left|< G,\right. \end{array} \tag{3} I(θ)=s.t.E(q,y)∼Dr,{oi}i=1G∼πθold(⋅∣context)[∑i=1G∣oi∣1∑t=1G∑i=1∣oi∣min(ri,t(θ)A^i,t,clip(ri,t(θ),1−ϵlow,1+ϵhigh)A^i,t)]0<{0i∣is−yy(y,0i)}∣<G,(3)
其中 ( q , y ) (\mathbf{q},\mathbf{y}) (q,y) 是问答对, r i , t ( θ ) \mathbf{r}_i,t(\theta) ri,t(θ) 是重要性采样比率,而 A ^ i , t \hat{\mathbf{A}}_{i,t} A^i,t 是时间步t的优势估计值:
r i , t ( θ ) = π θ ( o i , t ∣ c o n t e x t ) π θ o l d ( o i , t ∣ c o n t e x t ) , A ^ i , t = R i − m e a n ( { R i } i = 1 G ) s t d ( { R i } i = 1 G ) . (4) r_{i,t}(\theta) = \frac{\pi_{\theta}(o_{i,t}\mid\mathrm{context})}{\pi_{\theta_{\mathrm{old}}}(\boldsymbol{o}_{i,t}\mid\mathrm{context})},\hat{A}_{i,t} = \frac{R_i - \mathrm{mean}(\{R_i\}_{i = 1}^G)}{\mathrm{std}(\{R_i\}_{i = 1}^G)}. \tag{4} ri,t(θ)=πθold(oi,t∣context)πθ(oi,t∣context),A^i,t=std({Ri}i=1G)Ri−mean({Ri}i=1G).(4)
值得注意的是,在公式4中, o i \mathbf{o}_i oi 表示模型生成的标记,但不是整个轨迹。同时,上下文包括模型生成和工具响应。标准差为0的情况(即所有rollout答案要么完全正确,要么完全错误)被移除。然后通过随机复制同一批次中标准差不为0的其他案例来填充这些批次中的槽位。
为了避免奖励攻击(Amodei等人,2016;OpenAI,2025c),我们采用基于规则的奖励,该奖励结合了格式验证和答案验证:
R i = 0.1 ∗ R i f o r m a t + 0.9 ∗ R i a n s w e r . (5) R_{i} = 0.1*R_{i}^{format} + 0.9*R_{i}^{answer}. \tag{5} Ri=0.1∗Riformat+0.9∗Rianswer.(5)
具体来说,格式分数验证rollout轨迹是否遵循预定义的格式,例如是否不同的内容片段被正确地用和<tool_call>等标签包裹,以及序列是否符合ReAct框架。答案分数使用一个LLM作为裁判来判断最终预测是否正确。
5实验
5.1设置
模型和基准我们在Qwen- 2.5- 3B,Qwen- 2.5- 7B,Qwen- 2.5- 32B,Qwen- 2.5- 72B上执行RFT和RL训练。我们主要在四个具有挑战性的基准上评估我们的方法:
·BrowseComp- en(Wei等人,2025年):OpenAI引入的最具挑战性的基准之一,用于评估AI代理在互联网上定位难以找到、通常多方面的信息的能力,这需要复杂的浏览策略和推理能力。
信息,这需要复杂的浏览策略和推理能力。
-
BrowseComp-zh (周等人,2025): 与 BrowseComp-en 类似,但问答(QAs)是中文。- GAIA (Mialon 等人,2023): 一个需要多模态和工具使用能力的基准。我们仅使用文本验证子集中的 103 个案例(Li 等人,2025c;Wu 等人,2025a)。
-
XbenchDeepSearch (Xbench-Team,2025): 一个新的、动态的、专业对齐的基准,专注于评估 AI 代理的工具使用能力,特别是在深度信息检索和复杂搜索任务中。
基线
我们将我们的方法与以下范式进行比较:
- 直接推理:模型根据其内部知识回答问题。对于非推理模型,我们选择 Qwen-2.5-32B,Qwen-2.5-72B(Yang 等人,2024),GPT-4o(OpenAI,2024),GPT-4.1(OpenAI,2025b),对于推理模型,我们选择 QWQ-32B(Qwen Team,2025),o4-mini(OpenAI,2025c),和 DeepSeek-R1(郭等人,2025)。我们不考虑较小的模型,因为它们在 BrowseComp 上的得分基本上是零。- 专有浏览代理:我们测试了 OpenAIDeepResearch (OpenAI, 2025a)、Grok-DeepResearch (x.ai, 2025) 和 Doubao with Deep Think and Search (Doubao, 2025);然而,由于并非所有这些代理都可以通过 API 完全访问,它们并未在所有基准测试和实验中进行测试。- 开源代理:我们将我们的方法与最近的开源网络/搜索代理进行了比较,包括 Search-ol (Li et al., 2025b)、WebThinker (Li et al., 2025c)、R1-Searcher (Song et al., 2025) 和 WebDancer (Wu et al., 2025a)。
指标和超参数我们默认使用 pass@k 评估 (Chen et al., 2021) 并报告使用非零温度的 pass@1,温度和 top- p 重置为 0.6 和 0.95。对于准确性,我们使用 LLM 作为评判者 (Liu et al., 2024; Wang et al., 2024)。pass@1 的计算方式如下:
p a s s @ 1 = 1 n ∑ i = 1 n p i , (6) \mathrm{pass@1} = \frac{1}{n}\sum_{i = 1}^{n}p_{i}, \tag{6} pass@1=n1i=1∑npi,(6)
where p i \mathfrak{p}_i pi 表示第 i 个响应的正确性。对于 pass@k, k > 1 \mathrm{k} > 1 k>1 我们重复生成 k \mathrm{k} k 次。
5.2 主要结果
我们的主要结果,如表 1 所示,揭示了几项关键见解。
直接推理在复杂信息获取中的不足仅依靠模型的内部知识和推理能力不足以解决复杂的信息检索任务。在所有模型中,包括强大的专有模型如 GPT- 4.1,在 BrowseComp- en/zh 上的表现都较差,准确率通常接近零。这鲜明地表明这些任务需要与外部信息源——互联网——进行动态交互以收集必要的证据。问题的固有不确定性和特定性远远超出了预训练知识的范围,突显了需要一个代理式、使用工具的框架的必要性。
高级推理模型展现出潜力在直接推理范式下,一个显著的例外是 DeepSeek- R1 和 o4- mini 等领先推理模型与其他基础模型相比表现出优越的性能。例如,DeepSeek- R1 在 BrowseComp- zh 上获得了 26.3 分的成绩,显著高于其同类其他模型。这表明它们先进的内在
表1:在四个具有挑战性的基准测试上的主要结果。†表示这些专有方法通过其网站进行手动评估(其中一些报告在相应的基准测试论文中)。- 表示由于成本限制,我们没有结果。
| Backbone | Paradign | BrowseComp-en | BrowseComp-zh | Xbench-DeepSearch | GAIA |
| 直接推理 | |||||
| Qwen-2.5-32B | 直接 | 0.6 | 3.9 | 8.7 | 13.6 |
| Qwen-2.5-72B | 直接 | 0.6 | 7.0 | 12.7 | 14.6 |
| GPT-4o | 直接 | 0.6 | 6.2 | 18.0 | 17.5 |
| GPT-4.1 | 直接 | 1.5 | 14.4 | 17.0 | 22.3 |
| QwQ-32B | 直接 | 0.5 | 10.0 | 10.7 | 22.3 |
| o4-mini | 直接 | 6.1 | 15.2 | 22.3 | 33.3 |
| DeepSeek-R1 | 直接 | 2.0 | 26.3 | 32.7 | 16.5 |
| 专有代理 | |||||
| Grok-3† | 浏览 | - | 12.9 | 50+ | - |
| 多巴‡ | 浏览 | - | 26.0 | 50+ | - |
| GPT-4o‡ | Browsin g | 1.9 | - | - | - |
| 深度研究‡ | 浏览 | 51.5 | 42.9 | - | 67.4 |
| 开源代理 | |||||
| R1-Searcher-7B | ReAct | 0.4 | 0.6 | 4.0 | 20.4 |
| Qwen-2.5-32B | Search-ol | 0.1 | 2.4 | 3.7 | 28.2 |
| WebDancer-32B | ReAct | 2.5 | 14.1 | 38.7 | 40.7 |
| QwQ-32B | Search-ol | 2.8 | 17.9 | 25.0 | 39.8 |
| WebThinker-RL | ReAct | 2.8 | 7.3 | 24.0 | 48.5 |
| WebDancer-QwQ | ReAct | 3.8 | 18.0 | 39.0 | 51.5 |
| WebSailor-3B | ReAct | 3.3 | 9.7 | 27.7 | 33.0 |
| WebSailor-7B | ReAct | 6.7 | 14.2 | 34.3 | 37.9 |
| WebSailor-32B | ReAct | 10.5 | 25.5 | 53.3 | 53.2 |
| WebSailor-72B | ReAct | 12.0 | 30.1 | 55.0 | 55.4 |
推理能力允许它们更好地分解复杂问题并在一定程度上减少不确定性,即使没有外部工具。
WebSailor建立了开源代理的新标杆WebSailor为开源代理设定了新的标杆,其优势在极具挑战性的BrowseComp- en和BrowseComp- zh基准测试上最为明显。这一结果验证了我们的核心假设:在体现复杂、难以减少的不确定性数据上进行训练,能够赋予代理稳健且可泛化的推理策略。我们的方法的有效性由WebSailor- 3B和WebSailor- 7B鲜明地展示。尽管规模不大,WebSailor- 7B在BrowseComp- en上达到了6.7的准确率,显著优于基于更大32B模型的代理,例如WebDancer- 32B(2.5)和WebThinker- RL(2.8)。这表明性能提升是由我们新颖的训练范式——复杂的数据合成和有针对性的强化学习——驱动的,而不仅仅是模型规模的产物。虽然WebSailor在所有基准测试中都表现强劲,但在GAIA上的优势较为温和。我们的手动检查揭示这是因为GAIA任务中很大一部分需要数学和计算能力,而WebSailor并未针对这些能力进行优化。然而,它在GAIA的纯信息检索子集上的准确率仍然非常高,再次证实了其专业领域的专长。
与专有系统实现同等水平也许最重要的发现是WebSailor弥合了开源系统与领先专有系统之间的差距。在BrowseComp- zh上,WebSailor- 72B的性能与百度——一个顶级专有代理——相当。虽然SOTA系统DeepResearch仍然保持领先,但WebSailor的性能代表了一个重要的里程碑,证明通过复杂的数据合成和有针对性的训练策略(如DUPO),开源模型可以达到此前仅限于封闭、专有系统才能实现的能力水平。
5.3 分析
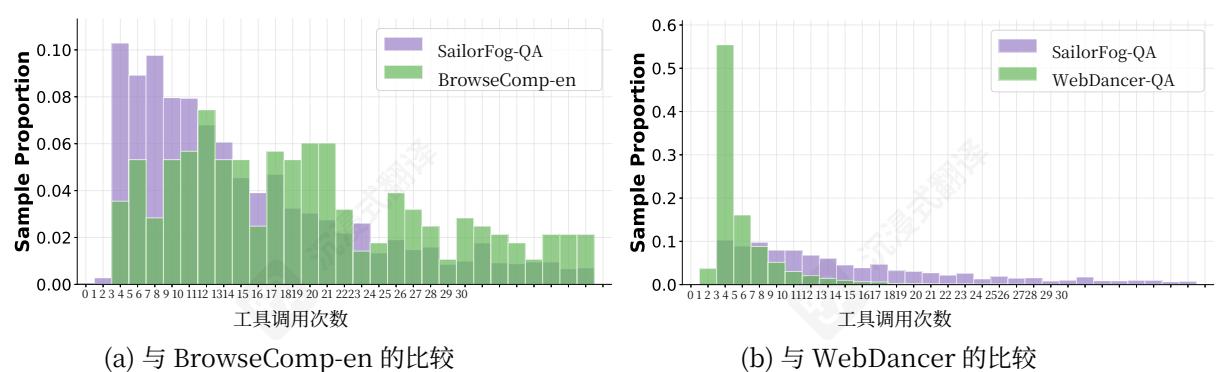
图3:我们训练集中的工具调用次数与WebDancer和BrowseComp-en训练集中的工具调用次数的比较。
SailorFog- QA图3展示了任务复杂性的定量分析,通过绘制我们专家生成的训练数据中工具调用次数的分布,并与BrowseComp- en基准和WebDancer训练集进行对比。我们使用工具调用次数作为衡量问题难度的代理指标。该分析基于拒绝采样中未过滤但正确的轨迹。WebDancer数据集严重偏向简单,其中超过 50 % 50\% 50% 的轨迹只需要两次工具调用,几乎没有任何轨迹超过十次。相比之下,我们合成的数据呈现出长尾分布,显著集中了需要超过五次工具调用的样本,并延伸到超过二十次交互的轨迹。关键在于,这种分布与BrowseComp- en基准本身的复杂性特征高度相似。需要注意的是,该图显示的是我们最终过滤阶段之前的数据,在最终过滤阶段,我们仅保留需要超过五次工具调用的轨迹。这种策略性数据构建确保我们的模型在训练时不仅处理复杂问题,而且其结构能够代表困难的推理任务,从而赋予模型强大的、多步骤的推理能力,这对于成功至关重要。
SailorFog- QA通过率为了进一步理解我们合成数据的难度,表2展示了SailorFog- QA在过滤前的pass@1准确率。DeepSeek- R1和o4- mini配备了浏览工具和ReAct框架。我们观察到,在过滤前,我们的数据比WebDancer训练集要难得多。尽管难度低于BrowseComp- en,但值得注意的是
表2:SailorFog- QA、WebDancer训练集和BrowseComp- en在ReAct框架下的pass@1准确率。
| Backbone | SailorFog-QA | WebDancer-QA | BrowseComp-en |
| o4-mini | 47.3 | 90.2 | 26.3 |
| DeepSeek-R1 | 38.9 | 84.4 | 9.5 |
BrowseComp- en过滤掉简单情况(Wei等人,2025)。通过人工检查,我们发现我们的数据准确率低,部分原因是其固有的难度,但也可能因为没有唯一的答案。信息中的模糊性可能导致多个条件的交叉,但无法得出一个明确的答案——这与BrowseComp- en的情况类似。然而,我们
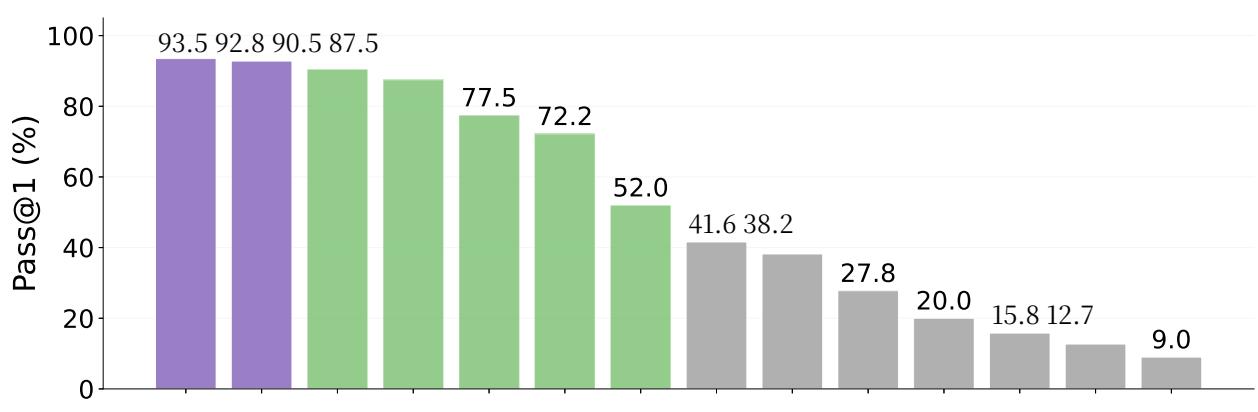
图4:在SimpleQA基准测试上的性能。
可以确保条件相对于答案的正确性,即,答案总是满足问题中指定的约束。
与简单任务的兼容性WebSailor仅在困难数据上训练,而BrowseComp- en/zh、GAIA和Xbench都可以被视为根据我们的定义属于级别- 2或级别- 3任务。为了验证WebSailor是否仍然在更简单的级别- 1任务上表现强劲,我们评估了它在SimpleQA基准测试子集上的性能(Wei等人,2024年)。完整的SimpleQA数据集包含4,326个问答对。由于在完整数据集上测试会过于耗时,我们随机抽取了200个问答对进行评估。这个基准测试的特点是高正确性和基于事实的简单条件问题,对于前沿LLM来说直接回答具有挑战性。如图4所示的结果表明,几乎所有基于代理的方法都优于直接回答。WebSailor超过了所有其他方法,展示了它即使在更简单的任务上也能保持兼容性和有效性。
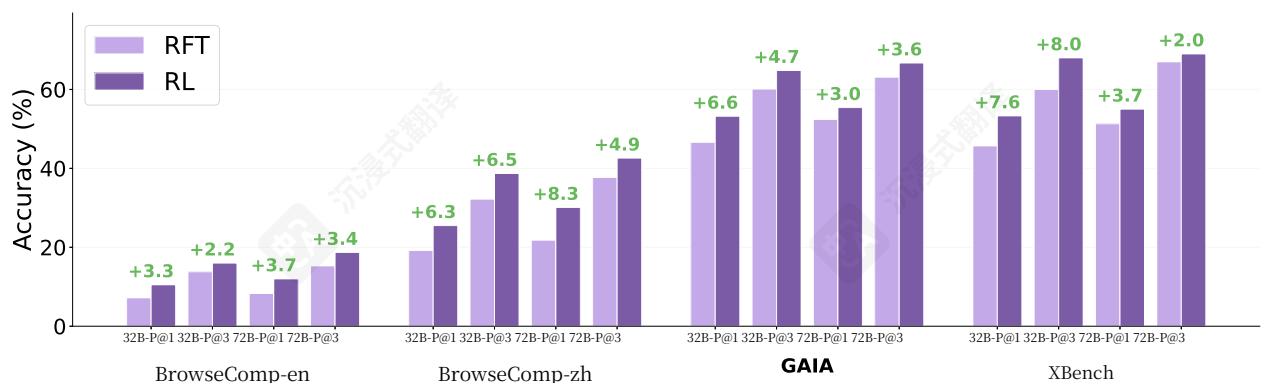
图5:使用Pass@1、Pass@3的详细评估结果。
Pass@1 vs Pass@3我们通过比较WebSailor在RL阶段前后(图5)的Pass@1和Pass@3性能来分析我们的RL训练的影响。结果表明,RL在所有基准测试中都带来了显著的改进,其中在高度困难的BrowseComp- en/zh任务上观察到的收益最为显著。这种差异是具有启示性的:BrowseComp的极端复杂性要求智能体生成非常长且复杂的轨迹,这使得稳定、可重复的成功具有挑战性(Sun等人,2025年)。这种不稳定性在Pass@1和Pass@3分数之间初始的巨大差距中明显表现出来。RL训练通过强化成功的策略并修剪无效的策略直接解决了这个问题,这显著提高了模型收敛到连贯解路径的能力。因此,模型的稳定性得到增强,在更难的基准测试上带来了更大的收益。此外,我们观察到Pass@1的改进比例远大于Pass@3,这表明RL大幅提高了样本效率(Yue等人,2025年),允许模型仅使用一个样本就能接近其全部潜力。
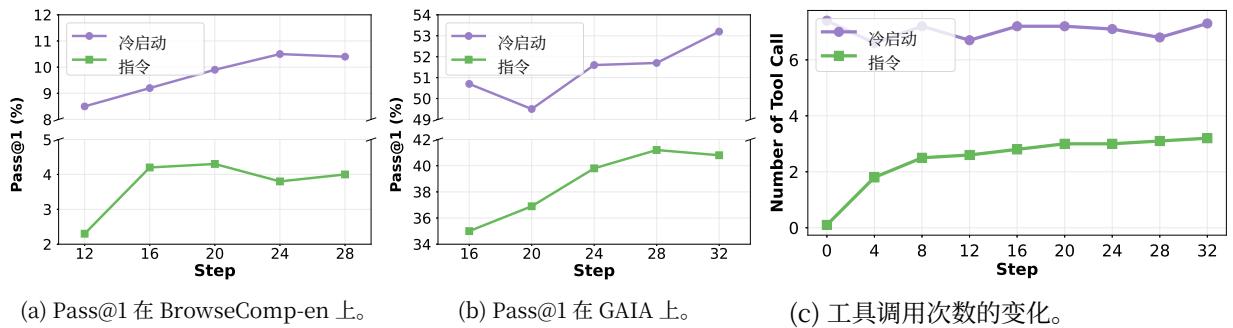
图6:比较Qwen-2.5-instruct-32B的直接RL训练与RFT冷启动后的RL训练。
策略和剪枝无效的部分,这显著提高了模型收敛到连贯解决方案路径的能力。因此,模型的稳定性得到增强,在更难的基准测试中取得了更大的收益。此外,我们观察到Pass@1的提升远大于Pass@3,表明强化学习(RL)极大地提高了样本效率(Yue等人,2025年),使模型仅用单个样本就能接近其全部潜力。
有/无冷启动为了评估我们的RFT冷启动策略的有效性,我们将它与直接RL训练基线进行比较,结果如图6所示。我们观察到,虽然直接RL方法在Pass@1准确率上表现出更大的提升,但经过RFT冷启动的模型的最终收敛性能明显更优。这种性能差距也反映在模型工具使用模式中。冷启动模型的工具调用次数在整个RL训练过程中保持高且稳定,而直接RL模型的工具调用次数尽管稳步增加,但始终显著较低,表明其无法掌握长时程推理能力。关键在于,冷启动的WebSailor与直接RL模型在BrowseComp- en上的性能差距要大得多。这表明,如果没有RFT冷启动,模型极难仅通过自我探索来获取复杂的推理模式——这些模式通常只在强大的LRMs中出现。冷启动对于用这些复杂策略引导模型至关重要,这些策略对于解决极具挑战性的任务来说是必要的。
5.4限制与未来工作
首先,我们决定将训练轨迹过滤到少于32k个token,虽然务实,但可能会限制模型处理更复杂问题的能力。我们对失败案例的分析表明,许多错误源于超出上下文限制,并且我们观察到随着推理长度的增加,性能会下降。此外,WebSailor可能会表现出"过度思考"的倾向,对看似简单的问题也应用多步工具调用。然而,这并不是一个明显的缺点;我们的定性分析表明,在许多此类情况下,代理并非盲目探索,而是在进行交叉验证,使用不同的信息来源来验证初始发现。最后,在训练方面,我们的RL过程限制在50步。这主要是由于同步RL框架的固有低效性;即使有了DUPO的优化,训练速度仍然是一个瓶颈。未来的工作将集中在迁移到异步训练框架以提高效率,并支持更广泛的RL训练。
6相关工作
信息检索基准信息检索基准的演变从具有易于减少的不确定性任务到需要复杂、非线性的推理任务(Wu等人,2025b)。早期的数据集如NQ(Kwiatkowski等人,2019)、TriviaQA(Joshi等人,2017)以及多跳变体如HotpotQA(Yang等人,2018)和Musique(Trivedi等人,2022)代表了可以通过结构化的查询序列甚至仅通过模型的参数化知识就能找到解决方案的问题。
更近期的基准提高了复杂性。GAIA (Mialon 等人,2023) 虽然是一个通才型多模态基准,但引入了接近复杂多跳问答的信息检索挑战。类似地,Xbench- DeepSearch (Xbench- Team,2025) 通过专业标注的动态任务专门针对代理的深度搜索和工具使用能力。在这个演变的顶峰是 BrowseComp- en/zh (Wei 等人,2025;Zhou 等人,2025) 这样的基准,它们体现了我们工作的核心级别3复杂性。这些任务的特点是实体之间错综复杂的耦合和故意的信息混淆,造成了极高的初始不确定性,极难减少。在 BrowseComp 上的成功需要定义超人类推理的那种复杂、非线性的探索和综合,使其成为高级网络代理的理想试验场。
Web agents 自主 Web 代理的发展从专有和开源社区都取得了显著进展 (Zhang et al., 2025a)。专有系统如 Deep- Research (OpenAI, 2025a)、豆包与 Deep Think (Doubao, 2025) 和 Grok- 3 (x.ai, 2025) 在复杂的 Web 导航和信息合成任务中表现出超人类的表现,但它们的内部架构和训练方法仍然不透明,阻碍了合作研究。相比之下,开源项目如 WebDancer (Wu et al., 2025a)、WebThinker (Li et al., 2025c) 和 R1- Searcher (Song et al., 2025),采用 ReAct 框架 (Yao et al., 2023),在简单任务中取得了进展,但在需要复杂的非线性推理的基准测试中存在巨大的性能差距。在训练方法方面,(Xu et al., 2019; 2024; 2025) 提出的训练动力学基础原理为训练提供了关键见解,通过强调训练方法对模型泛化能力的关键影响,指导超参数调整和算法设计。然而,虽然许多研究遵循 ReAct 范式使用监督微调 (SFT),纯 SFT 代理在自适应环境中难以泛化 (Zheng et al., 2025; Zhang et al., 2025b)。基于强化学习的方法 Song et al. (2025); Zheng et al. (2025) 通过学习的探索策略为高级搜索策略提供了希望,但在训练稳定性和样本效率方面遇到了挑战。
7 结论
在这项工作中,我们提出了 WebSailor。从信息检索中不确定性减少的角度来看,我们分析了为什么之前的开源网络代理没有达到专有系统的水平。我们的贡献涵盖从问答构建、综合训练数据合成、RFT 冷启动到改进 RL 算法效率,最终形成一个完整的代理后训练流程。WebSailor 在简单和复杂的信息检索基准测试中均表现出色,展现出推理和工具使用能力,超越了人类水平。
我们相信,自主后训练的关键在于进一步定义更复杂的任务,具有更高的不确定性,以及实现更有效率和更高效的RL训练。未来,我们将继续探索如何基于开源模型进一步增强智能体的能力,不仅在信息获取领域,也在追求跨更多维度的通用“超人类”性能目标上。
A 实验细节
A.1工具
WebSailor使用两种类型的工具,搜索和访问:
-
Search用于访问Google搜索引擎进行信息检索。Search的参数是搜索查询。它允许同时搜索多个查询,并为每个查询返回前10个结果。每个结果包含一个标题、一个摘要和相应的URL。
-
Visit用于访问特定网页。输入由多个网页及其对应的访问目标组成,每个网页都有一个专门的目标。首先使用Jina(jina.ai,2025)获取网页的完整内容,然后使用摘要模型根据目标提取相关信息。在本文中,我们使用Qwen-2.5-72B作为摘要模型。
A.2QA构建
我们的QA是通过从图中采样子图构建的。每个图是通过从稀有实体开始进行随机游走生成的。图中的节点表示实体,边表示实体之间的关系。构建图的一般过程如下:
-
我们使用Wikidata的SPARQL服务根据某些数据库规则获取罕见实体。2.使用搜索和访问工具获取初始节点的特征,并将初始节点设置为扩展节点。
-
基于扩展节点的特征获取一些相关实体,然后我们获取它们的特征。
-
以一定的概率,我们设置一个新的相关实体作为下一个扩展节点,或者从之前的节点中选择一个节点。5.重复步骤3和4,直到图中边的数量达到预定义值。
A.3ReAct轨迹
我们的ReAct框架通过Qwen- Agent<实现,并且我们限制工具调用的数量不超过30。完整的轨迹遵循以下格式:
用例轨迹
<思考>思考过程在这里</思考><工具_调用>“name”:“工具名称”,“arguments”:“参数名称”:参数值这里,“another参数名称”:另一个参数值这里,…</tool_调用><工具_响应>工具_响应在这里</工具_响应>(更多思考过程,工具调用和工具响应在这里)<思考>思考过程在这里</思考><答案>答案在这里</答案>
A.4训练详情
A.4 训练详情我们使用 Megatron (Shoeybi 等人, 2019) 进行 SFT, 并使用 verl (Sheng 等人, 2025) 进行 RL 训练。对于 SFT, 我们使用批大小为 32, 学习率为 5e-6(最小值为 1e-10),预热加余弦衰减调度,以及权重衰减为 0.1。对于 RL 训练,一个组中的 rollout 数量为 8,温度为 1.0, t o p p = 1.0 \mathrm{top}_p = 1.0 topp=1.0 ,批大小为 128,小批大小为 32,学习率为 1e-6。
A.5案例研究
Case Trajectory in BrowseComp-en
问题:有一位软件开发者,在2010年之后但2023年之前,声称设计并创造了一台太阳能冰箱。他们以2012年之后的质朴生活方式而闻名,并且据他们所说,住在“地图上的一个洞里”。他们从爱丁堡的开发者会议上获得了记忆,并且也以喜欢洞穴探险而闻名。他们在1980年代与父亲共同购买的第一台电脑是什么品牌和型号?
步骤1
<思考>
这个问题需要识别一位具有独特传记细节的软件开发者——他建造了一个太阳能冰箱,过着田园生活,将他们的住处描述为“地图上的一个洞”,记得在爱丁堡的开发者会议上的一些回忆,并且喜欢探险。为了取得进展,我需要通过在线搜索这些独特特征的交叉证据来三角测量这个人的身份…
<工具_调用>
{“name”.“search”,“arguments”:{“query”:[“软件开发者太阳能冰箱田园生活”,“软件开发者地图上的一个洞探险”…}]
</工具_调用>
<工具_响应>
在Google搜索“软件开发者太阳能冰箱乡村生活方式”中找到10个结果:1. [带温度控制和监测系统的太阳能冰箱使用…] (https://www.ijert.org/solar- fridge- with- temperature- control- and- monitoring- system- using- 蓝牙模块) 在这里我们设计了一个基于微型太阳能蓝牙的带温度控制的冰箱,带温度监测系统,它更便宜也更环保…
- [工程师, 嵌入式 软件 - EnPhase 能源 - Climatebase] (https://climatebase.org/job/6314385/engineer-embedded-software) Date 发布:2025年6月18日
EnphaseEnergy是一家全球能源技术公司,是太阳能、电池和以及电动汽车充电产品的领先供应商。
</工具_响应>
步骤2
<思考>
独特的生平标志的组合——例如一位有建造太阳能冰箱历史的软件开发者、自称为“地图上的洞”的乡村生活方式,以及在爱丁堡参加洞穴探险和开发者会议的背景——表明正确的方法是在更综合的搜索查询中交叉引用这些特征。通过将这些独特的元素组合成多部分搜索…
<工具_调用> {“name”:“search”,“arguments”:{“query”:[“软件开发者乡村生活方式洞穴会议”}} 爱丁堡", “太阳能冰箱洞穴会议爱丁堡乡村生活方式”…}}
</工具_调用>
</工具_调用>
在Google上搜索“软件开发者乡村生活方式洞穴会议爱丁堡”找到了3个结果
结果:
- [爱丁堡2025/2026开发者会议-dev.events](https://dev.events/EU/GB/
爱丁堡)
缺失:乡村生活方式洞穴探险
- 喜悦-红手文件 有些人将喜悦比作被玻璃灯笼供奉的火焰——无论风多么猛烈,闪烁依然完整。风如何吹拂,闪烁依然完整。
</工具_响应>
步骤3
<思考>
短语“地图上的洞”非常独特,很可能被相关人员或关于他们的描述中引用或释义。所涉及的个人或对其的描述。通过搜索涉及组合的内容他们的生活方式和技术项目…他们的生活方式和技术项目…他们的生活方式和技术项目…
</工具_响应>
</工具_响应> {“name”:“search”,“arguments”:{“query”:[“软件开发商太阳能冰箱”}} 洞在 map",软件开发者 地图上的洞乡村生活方式"…}}
</工具_调用>
</工具_调用>
对“软件开发者太阳能冰箱“地图上的洞”的谷歌搜索找到了5个结果:
-
[PDF] 观测 With The 绿色 Bank 望远镜 - Science](https://www.gb.nrao.edu/glangsto/GBTog.pdf) 发布日期:2011年10月11日地图上最大的“洞”大约是0.3倍地图半径。但它对焦平面阵列。语法:Daisy(位置,映射…)
0Fergus.pdf)
我能在壁炉西边的平原上,等高线之间,看到地图上一个微小的孔洞。我抬起我的护目镜,看向对应的位置上
</工具_响应>
步骤4
<思考>
LWN.net文章在搜索结果中浮现,其中包含关于“住在地图上的洞里”的直接引语,这与问题中的独特措辞相匹配,并且与乡村生活方式有很强的关联。这表明该文章可能包含关于该软件开发者的第一人称记述或采访,可能会揭示他们的身份,并提供诸如他们对洞穴探险、太阳能项目以及甚至早期计算机经历的记忆等生平细节…
<工具_调用>
{“name”: “访问”, “参数”: “url”: [“https://lwn.net/Articles/672352”], “目标”: “识别软件开发者,他们声称设计了一台太阳能冰箱,他们的粗犷生活方式提及,以及关于早期计算机购买的任何细节”}
</工具_调用>
<工具_响应>
在https://lwn.net/Articles/672352/中为用户目标识别软件的有用信息开发者,他们声称设计了一种太阳能冰箱,他们提到的粗犷生活方式,和任何关于早期计算机购买的详细信息,如下所示:…
</工具_响应>
步骤5
<认为>LWN.net上的访谈提供了强有力的证据,表明JoeyHess就是所提问题中的软件开发者,详细描述了他“地图上的一个洞”中的质朴生活方式以及早期的计算机经历。然而,虽然提到了太阳能电池板和离网生活,但目前还没有明确的确认表明他声称设计并制造了一台太阳能冰箱——这是完全验证他身份作为问题主题的重要细节…</认为><工具调用>{name": “search”,
arguments": {“query”: [“JoeyHess太阳能冰箱”,“JoeyHess太阳能冰箱创建”,“JoeyHess设计太阳能冰箱”,“JoeyHess冰箱太阳能”}</工具调用><工具_响应>对“JoeyHess太阳能冰箱”进行谷歌搜索找到了9个结果:1. [离网、太阳能驱动、零电池冰箱]
(https://www.notechmagazine.com/2019/0
9/off- grid- solar- powered- zero- battery- refrigerator.html)发布日期:2019年9月1日JoeyHess设计、建造和测试了一台离网、太阳能驱动的冰箱,没有电池组,使用一个廉价的卧式冰柜和一些改装。2. [Fridge0:一个无电池的开源硬件太阳能冰箱…]
(https://boingboing.net/2019/09/05/frozen- sunshine.html)发布日期:2019年9月5日JoeyHess一年前设计了第一个Fridge0:它使用一个标准的卧式冰柜,增加了热质量,一个简单的控制器,…</工具_响应>步骤6
<认为>要完全验证乔伊·赫斯是否与问题中所有传记线索相符,我需要确定他是否对爱丁堡的开发者会议有个人记忆,并且也以喜欢洞穴探险而闻名。这两个细节特别突出,将有助于确认他是问题的主题,特别是由于我已经对他粗犷的生活方式以及太阳能冰箱有很强的证据…</认为><工具调用>{name": “search”, “arguments”: {“query”: [“乔伊·赫斯 爱丁堡开发者会议 记忆”, “乔伊·赫斯 洞穴探险”}</工具调用></工具_响应>
在Google上搜索“JoeyHess开发者会议爱丁堡回忆”找到了9个结果:
-
离开Debian与JoeyHess-CoRecursivePodcast发布日期:2021年11月2日JoeyHess是我的嘉宾,他投入了成年后的大量时间在Debian上工作。他将分享那段经历是怎样的。
-
访谈 with FLOSS 开发者: Joey Hess i.am.z.grim.shelljoey-hess.html)发布日期:2015年2月28日我:德比安会议的一些难忘时刻?joeyh:太多了!野餐在波特兰农夫市场的浆果和玉米饼…
</工具响应>
步骤7
<思考>
为了确信乔伊·赫斯是否对爱丁堡的开发者会议有个人记忆——这是一个确认他与问题中所有独特线索匹配的重要细节——我需要他经历或提及此类事件的直接证据。在zgrimshell.github.io链接的访谈中,特别询问了乔伊·赫斯关于Debian会议的难忘时刻……
<工具_调用>
{“name”:“访问”,“参数”:{url":["https://zgrimshell.github.io/posts/interviews- with- floss- “}}developers- joey- hess.html”},“目标”:“查找爱丁堡和会议回忆的提及”}
</tool _call>
<工具响应>
https://zgrimshell.github.io/posts/interviews- with- floss- developers- 中的有用信息joey- hess.html用于用户目标查找提及爱丁堡和会议回忆,如下:…
</工具响应>
步骤8
<思考>
虽然我有强有力的证据将JoeyHess与rusticlifestyle、太阳能冰箱以及开发者会议的记忆联系起来,但关于洞穴探险的细节仍未经证实。由于“洞穴探险”可能是一个比喻或指代一项实际爱好,我想直接核实JoeyHess是否公开提到过洞穴探险或spelunking作为兴趣或活动…
</思考>
<工具_调用>{name":“搜索”,“参数”:“查询”:[“JoeyHess洞穴探险”,“JoeyHess洞穴”,“JoeyHess探洞”}</工具_调用>
<工具响应>
在Google上搜索“JoeyHesscaving”找到了9个结果:
- JoeHesson X:"所以出来 你的洞穴 走路 on your 双手…“所以走出你的洞穴,倒立行走,看看颠倒的世界…”#TheCave#Muford&Sons.3:10PM·2011年8月19日2. JoeHess(@jhessacx)·Instagram照片和视频第5天- 国度教会和多瑙河的3次浸信。浸信的见证候选人真心实意地见证浸信后的祷告…
</工具_响应>
步骤9
<思考>
为了确定与父亲共同购买的第一台电脑的型号和品牌,我需要找到一份JoeyHess直接讨论这段形成性经历的材料,最好是他的原话。提供的URL上的博客文章可能包含他的个人轶事和早期计算机历史的详细技术信息。这正是回答问题的所需信息…
</思考>
</工具_调用>
{“name”:“访问”,“arguments”:{“url”:[“http://joeyh.name/blog/entry/atari”], “目标”: “找到他父亲在1980年代购买的第一台电脑的制造商和型号”}
</工具_调用>
<工具_响应>
在http://joeyh.name/blog/entry/atari/中,对于用户目标找到他父亲在1980年代购买的第一台电脑的制造商和型号,有用的信息如下:…
</工具_响应>
第10步
<思考>
为了得到答案“Atari130XE”,我首先需要识别出问题中描述的软件开发者通过拼凑几个独特的生物特征:设计一个太阳能冰箱,过着“地图上的一个洞”的田园生活,拥有来自开发者在爱丁堡的开发者会议的记忆,以及享受洞穴探险。我的搜索让我找到了乔伊- 赫斯,他的采访在爱丁堡参加的会议,并且喜欢探险。我的搜索让我找到了乔伊- 赫斯,他的采访并且博客文章明确证实了他离网生活,“fridge0"太阳能冰箱的创建,以及关于Debian会议的美好回忆——包括在爱丁堡举行的一次活动。为了回答关于1980年代与父亲购买的第一台计算机的核心问题,我找到了Joey的博客条目,详细说明那是一台Atari130XE,大约在1986年与他的父亲共同购买的。这从他自己的写作中获得的直接证据使我能够自信地得出结论,Atari130XE是正确的答案。
他们一起买的第一台电脑是Atari130XE.

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 34
34 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)