揭秘梦境的 AI 架构师:Mamba 模型如何读懂你的睡眠密码?
你是否好奇整夜的睡眠中,大脑究竟经历了怎样的奇妙旅程?本文将带你从 N1 浅睡到 REM 梦境,深入探索睡眠各个阶段的奥秘及其对健康的重要性。更重要的是,我们将揭示为什么传统的 RNN 和 Transformer 在分析长达数小时的脑电(EEG)信号时力不从心,并隆重介绍新一代序列模型——Mamba——如何凭借其线性复杂度和选择性状态空间机制,成为睡眠分期任务的“新王”。读完本文,你不仅能收获硬核
你是否曾经有过这样的经历:明明睡足了 8 小时,醒来后却依然头昏脑胀,感觉像“睡了个假觉”?或者在某个清晨,你对一段光怪陆离的梦境记忆犹新,好奇它究竟发生在大脑的哪个角落?
这些日常的困惑都指向一个事实:睡眠的质量,远比时长更重要。睡眠并非简单的“关机”,而是一场由大脑精心编排、结构复杂的生理大戏。理解这场大戏的每一个幕间——也就是睡眠的各个阶段——是提升睡眠质量、乃至诊断睡眠障碍的关键。
在过去,这项工作高度依赖专业医生的人工判读。而今天,一个名为 Mamba 的新型 AI 模型,正以一种前所未有的高效与精准,帮助我们自动解码深藏在脑电波中的睡眠秘密。
读完本文,你将:
-
清晰地理解睡眠的 N1, N2, N3, REM 四个核心阶段及其意义。
-
了解为什么分析睡眠脑电(EEG)这样的长序列数据如此具有挑战性。
-
掌握 Mamba 模型的核心思想,以及它为什么是解决此类问题的“天选之子”。
一、睡眠:不止是休息,更是一场精心编排的“大脑修复剧”
把我们的睡眠想象成一位技艺高超的建筑师,在一夜之间对我们的大脑和身体进行分区、分阶段的维护和重建。这场“工程”的核心,就是睡眠周期。
一个完整的睡眠周期大约持续 90 到 110 分钟,一夜会循环 4-5 次。每个周期都由不同阶段组成:
-
NREM (非快速眼动期) - 身体的修复师
-
N1 期 (入睡期): 这是你从昏昏欲睡到真正睡着的过渡阶段。肌肉开始放松,心率减慢,你可能会经历肌肉突然抽动(入睡抽动)。此时的你,像一个刚把脚迈进影院的观众,很容易被一声咳嗽唤醒。
-
N2 期 (浅睡期): 你正式进入睡眠状态。大脑会产生独特的“睡眠纺锤波”和“K 复合波”,它们被认为在屏蔽外界干扰、巩固记忆方面扮演重要角色。这个阶段占据了整个睡眠时间的半壁江山。
-
N3 期 (深睡期): 这就是我们常说的“黄金睡眠”。大脑活动变得非常缓慢,身体进入深度放松。生长激素在此阶段大量分泌,身体进行组织修复、增强免疫系统。这也是为什么高质量的深睡后,你会感到精力充沛。
-
-
REM (快速眼动期) - 梦境的导演与记忆的剪辑师
-
在 N3 之后,我们并不会直接醒来,而是会返回 N2,然后进入一个神奇的阶段——REM。此时,你的身体肌肉处于“麻痹”状态(防止你把梦里的动作做出来),但你的大脑却异常活跃,甚至堪比清醒状态。你的眼球会在眼皮下快速转动,绝大多数生动的梦境都发生在这里。REM 阶段对于情绪调节、学习和记忆的整合至关重要。
-
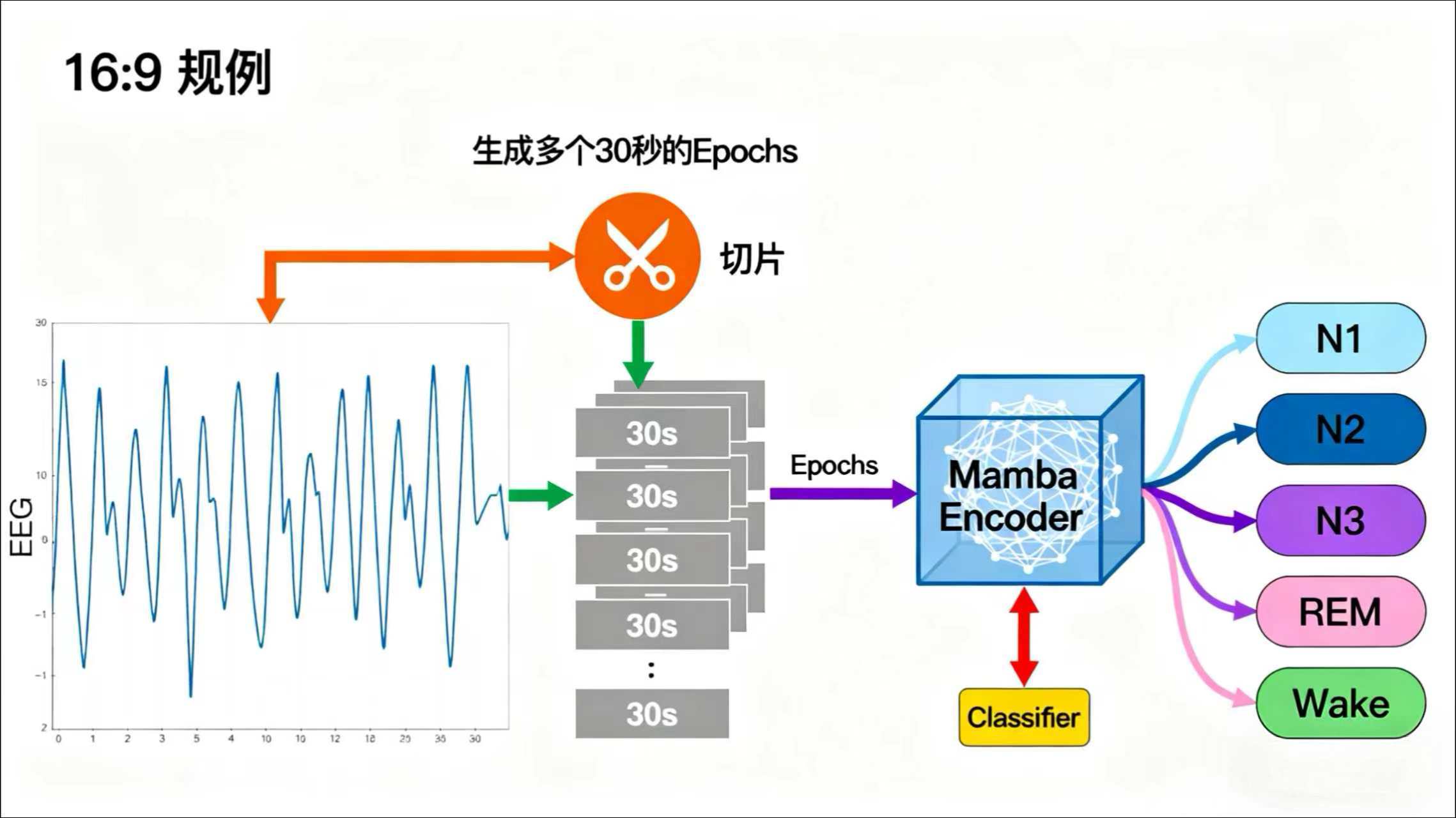
值得注意的是,每个人的睡眠结构都是独特的,这就是睡眠的异质性。年龄、压力、生活习惯都会影响每个阶段的时长和比例。因此,精准地识别这些阶段,是通往个性化睡眠健康管理的第一步。
二、解码睡眠的挑战:为什么 AI 也曾“失眠”?
要客观地分析睡眠阶段,科学家们依赖的是多导睡眠图(PSG),其中最核心的就是脑电图 (EEG) 信号。
想象一下,EEG 信号就是大脑在一整夜里持续不断、极其微弱的“心声”。我们需要分析这长达 8 小时、包含数百万个数据点的时间序列,然后给每 30 秒打上一个标签(N1, N2, N3, REM 或清醒)。
这项任务对于 AI 模型来说,是一个巨大的挑战:
-
RNN/LSTM 的“健忘症”: 循环神经网络(RNN)及其变体(如 LSTM)虽然为序列数据而生,但当序列过长时,它们会受困于梯度消失或爆炸问题。就像让一个人记住 8 小时前听到的一个细节一样,它们很难捕捉到跨越数小时的长期依赖关系。
-
Transformer 的“能耗危机”: Transformer 凭借其自注意力机制,彻底改变了自然语言处理领域,它能轻松捕捉全局信息。然而,这份强大是有代价的。它的计算和内存复杂度是序列长度 N 的二次方 (O(N2))。处理一晚上的高频采样 EEG 数据?对于大多数计算资源来说,这简直是一场灾难。

我们需要一个新物种:它既要有 RNN 的线性计算效率,又要有 Transformer 的长距离建模能力。
三、Mamba 登场:为超长序列而生的“效率之王”
就在大家快要“卷”不动 Transformer 的时候,Mamba 横空出世。它的核心思想发生了一个根本性的转变:从 Transformer 暴力地“关注所有 token”,转变为“有选择地记住关键信息”。
Mamba 的理论基石是状态空间模型 (State Space Model, SSM)。别被这个名字吓到,我们可以用一个简单的比喻来理解它:
想象你在读一本厚厚的小说。你不需要时刻记住前面所有章节的每一个字。相反,你的大脑会维持一个动态的、压缩后的“摘要”(这就是“状态”),包含了当前情节、人物关系、伏笔等关键信息。每当你读一个新的句子,你会根据这个句子的内容来更新你的“摘要”。
传统的 SSM 模型更新“摘要”的规则是固定的,不够灵活。而 Mamba 的“杀手锏”在于引入了选择性机制 (Selective SSM, 或称 S6)。
这意味着 Mamba 更新“摘要”的规则是内容感知的。它通过一系列受输入数据驱动的“门控”,来动态决定:
-
当前这个信息点是无关紧要的噪声吗?那就快速遗忘它。
-
这是一个关键的特征(比如 EEG 中的一个 K 复合波)吗?那就加倍记住它,并长期保留在“状态”里。
这种机制赋予了 Mamba 两大超能力:
-
线性复杂度 (O(N)): 它的计算过程更像 RNN,是顺序的、递归的,因此处理序列的成本随长度线性增长,对于超长序列极其友好。
-
强大的长程依赖捕捉: 通过选择性地维持状态,它可以将非常久远之前的重要信息一直传递下去,解决了 RNN 的“健忘”问题。
| 特性 | Transformer | Mamba (SSM) | 对睡眠分析的意义 |
| 计算复杂度 | O(N2) (二次方) | O(N) (线性) | 可以轻松处理整夜、高采样率的 EEG 数据,训练和推理速度极快。 |
| 内存占用 | O(N2) | O(N) | 同样的硬件可以处理更长的序列或更大的批量。 |
| 长距离依赖 | 强,通过全局自注意力 | 强,通过选择性状态压缩 | 能够捕捉到睡眠阶段转换的缓慢趋势和关键波形。 |
| 核心机制 | 并行的、基于 Token 间关系的矩阵运算 | 递归的、基于状态更新的序列运算 | 更符合生物信号随时间演化的内在逻辑。 |
四、实战演练:用 Mamba 搭建一个睡眠分期模型
理论讲了这么多,我们来看看 Mamba 在实践中如何应用。整个流程可以概括为以下几步:
-
数据准备: 使用公开的睡眠数据集(如 PhysioNet 的 Sleep-EDF),将连续的 EEG 信号按标准切分成 30 秒的片段(Epochs)。每个 Epoch 都有一个由专家标注的睡眠阶段标签。
-
模型构建: 搭建一个简单的分类模型,其核心就是 Mamba 层。
-
输入层: 接收一批 30 秒的 EEG 信号序列。
-
Mamba 层: 作为模型的主干,负责从复杂的 EEG 波形中提取有辨识度的时序特征。
-
输出层: 一个简单的全连接分类器,将 Mamba 提取的特征映射到
[清醒, N1, N2, N3, REM]这 5 个类别的概率上。
-
下面是一个极简的伪代码示例,展示了其结构是多么清晰:
import torch
from mamba_ssm import Mamba # 假设已安装官方或社区实现的 mamba 包
# 假设 eeg_epochs 的形状是 [batch_size, sequence_length, input_dim]
# 例如:[64, 3000, 1] -> 64个30秒的EEG片段,每秒100个采样点,1个通道
class SleepMambaClassifier(torch.nn.Module):
"""一个简单的基于 Mamba 的睡眠分期分类器"""
def __init__(self, d_model=128, n_classes=5):
super().__init__()
# Mamba 层是我们的核心特征编码器
# 它的参数 d_model 决定了模型的“思考深度”
self.mamba_layer = Mamba(
d_model=d_model, # 模型内部的隐藏维度
d_state=16, # 状态向量的维度,是 Mamba 的一个关键超参数
d_conv=4,
expand=2,
)
# 最后的分类头,将学到的特征映射到类别
self.classification_head = torch.nn.Linear(d_model, n_classes)
def forward(self, eeg_epochs):
# 1. Mamba 层对输入的 EEG 序列进行编码
# 输出包含了序列中每个时间步的隐藏状态
hidden_states = self.mamba_layer(eeg_epochs)
# 2. 我们通常取序列的最后一个时间步的输出作为整个序列的总结性表示
last_state = hidden_states[:, -1, :]
# 3. 将这个总结性表示送入分类头,得到最终的分类概率
logits = self.classification_head(last_state)
return logits
# --- 模型使用示例 ---
# 实例化模型
model = SleepMambaClassifier(d_model=64, n_classes=5) # 使用较小的 d_model 举例
# 创造一批伪造的 EEG 数据
# (batch_size, sequence_length, d_model)
# 注意:实际使用时,需要一个线性层将原始信号维度映射到 d_model
eeg_data = torch.randn(32, 3000, 64)
# 前向传播
predictions = model(eeg_data)
print(f"输出形状: {predictions.shape}") # 应该输出: torch.Size([32, 5])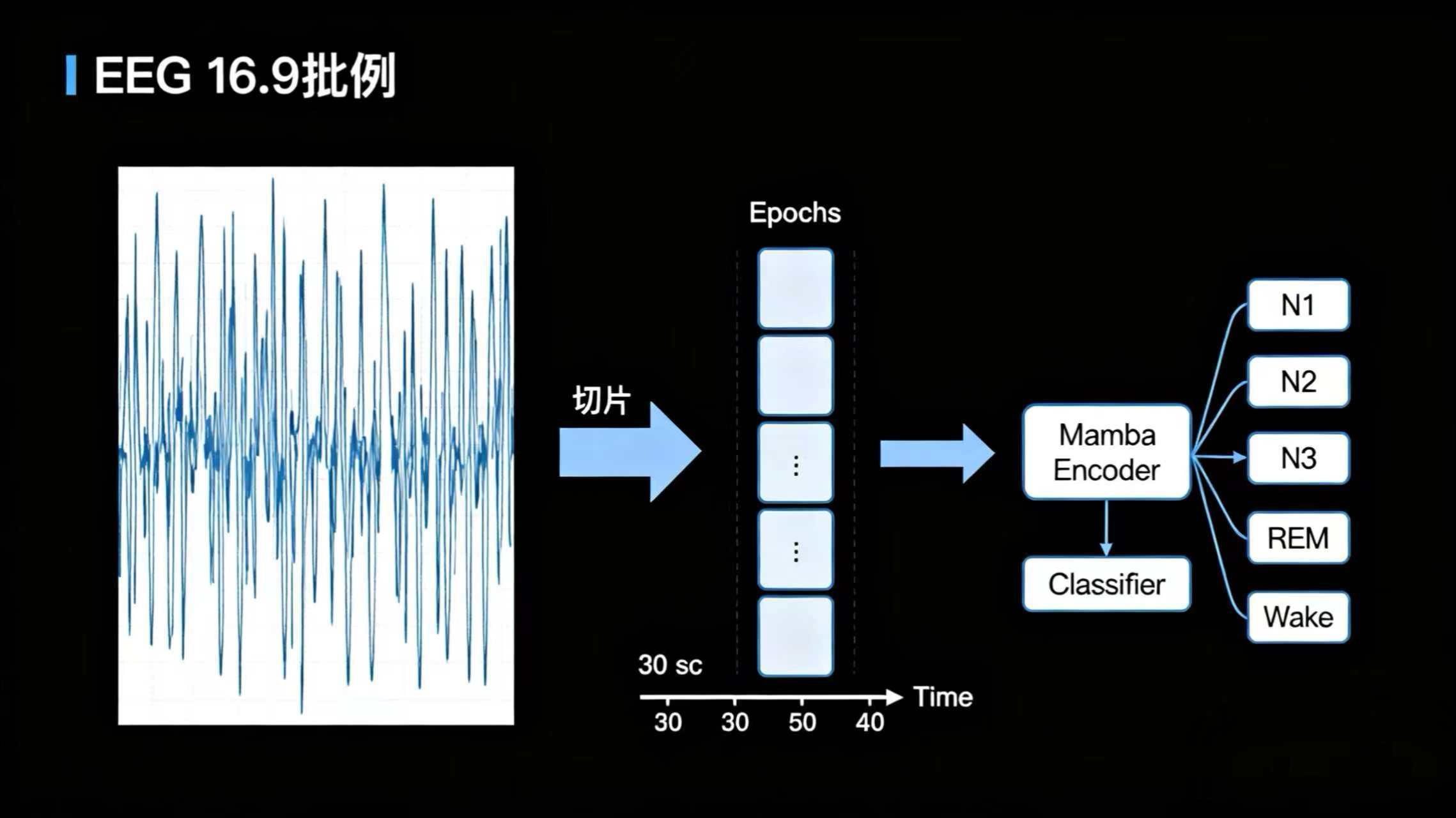
结论:拥抱 Mamba,睡个好觉
今晚,当你躺在床上时,可以想象你的大脑正在上演一场精妙的周期性戏剧。我们从 N1 的序幕,到 N3 的高潮,再到 REM 的华彩乐章,每一个阶段都不可或缺。
在技术世界里,我们同样见证了一场精彩的演出。我们目睹了传统模型在分析睡眠 EEG 这类超长序列数据时的挣扎,也迎来了 Mamba 模型带来的曙光。凭借其优雅的线性复杂度和强大的选择性状态机制,Mamba 不仅为精准、自动化的睡眠分析提供了强有力的工具,更为所有面临长时序数据挑战的领域——无论是金融市场预测、基因序列分析,还是长文本理解——都开辟了全新的可能性。
Mamba 的设计哲学,回归到了处理序列问题的本源,完美诠释了“简洁即力量”。
那么,你的研究或项目中是否也存在类似的超长序列难题呢?不妨给 Mamba 一个机会,看看它能否帮你“睡个好觉”。欢迎在评论区分享你的看法、遇到的挑战,或者你认为 Mamba 还能掀起哪些领域的革命!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 24
24 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)